
基于Git日志的即时软件质量分析框架
2022-01-21 08:08黄晓华钱柱中
吉林大学学报(理学版) 2022年1期
黄 纬, 黄晓华, 张 源, 陈 翔, 钱柱中
(1. 南京工程学院 计算机工程学院, 南京 211167; 2. 北京中电普华信息技术有限公司, 北京102208;3. 南通大学 信息科学技术学院, 江苏 南通 226019; 4. 南京大学 计算机科学与技术系, 南京 210023)
软件缺陷产生于开发人员的编码过程. 软件开发人员对软件需求的理解不正确、 对软件开发过程设计不合理或者开发人员自身的经验不足等因素都可能产生软件缺陷. 含有缺陷的软件在应用后会产生不可预知的结果, 从而影响软件的正常使用. 软件缺陷分析技术[1-5]是避免软件发生运行故障的一种可行方法, 在软件工程领域已得到广泛关注. 软件缺陷分析技术通过挖掘软件代码仓库(如缺陷跟踪系统和版本控制系统), 分析软件历史开发数据以及软件运行故障等信息, 借助机器学习等技术构建缺陷分析模型以识别新软件模块是否存在缺陷. 软件缺陷分析的目的是在软件正式发布前尽可能多地找到潜在的缺陷程序模块, 以便优化测试资源, 提高软件质量. 软件缺陷分析主要包括两个阶段: 模型构建阶段和模型应用阶段. 模型构建阶段首先挖掘并收集软件代码仓库和缺陷跟踪系统; 然后设计度量元指标并对程序模型进行度量元取值的量化以及对模块是否含有缺陷进行标注; 最后基于标注的数据集, 进行必要的数据预处理(如数据取值归一化、 特征选择、 噪声移除等)后, 使用特定的机器学习方法(如朴素Bayes和决策树等)完成模型的构建. 在模型应用阶段, 对新的程序模块, 首先对其按照度量元进行量化, 然后将其输入到模型中进行分析, 以判断新产生的模块是否含有缺陷.
目前, 研究人员已提出了多种软件缺陷分析方法, 并且验证了这些方法的有效性[6-9]. 但大多数的软件缺陷分析方法都只关注于识别粗粒度代码模块(类/文件/模块)中的缺陷. 尽管这些方法在一些情况下可行, 但其缺陷阻碍了其在实际场景中的应用, 特别是在测试资源受限的情况下. 因此, 研究人员又提出了新的软件缺陷分析方法, 这些方法能识别出细粒度代码模块(如代码变更)中存在的缺陷[10-14]. 近年, 基于代码变更的软件缺陷分析已引起研究人员的广泛关注, 因为其能精细、 及时地帮助开发人员识别软件中有缺陷倾向的模块[15-17].
基于代码变更的缺陷分析方法通常称为即时软件缺陷分析, 因为其能识别在软件更新瞬间引入缺陷的变更. 引入缺陷的变更是指引入一个或者一些缺陷使软件失效[18]的代码修改. 相比于粗粒度的缺陷分析, 即时软件缺陷分析有如下优点:
1) 在细粒度的级别进行分析, 被识别出引入缺陷的变更被链接到特定的代码修改部分, 极大的缩小了代码搜索的范围;
2) 将分析结果反馈给最合适的开发者, 被识别出的引入缺陷变更被链接到特定的代码修改部分, 能迅速地找到具体是哪一个开发者对这段代码进行的修改, 并将修复这些缺陷的任务指派给相应的开发者;
3) 在代码提交时进行分析, 新的代码变更在提交到代码仓库时, 能及时的被分类成有缺陷的或无缺陷的变更.
目前, 有监督的软件缺陷分析方法受到广泛关注. Kim等[25]提出了一个模型, 该模型利用文件名、 更改的元数据、 更改的日志等几个基于代码变更的特性分类一个代码变更是否含有缺陷; Yin等[26]在开源系统上(包括Linux,OpenSolaris,FreeBSD和成熟的商业软件)研究了引入缺陷的代码变更和修复缺陷的代码变更之间的关系; Shihab等[16]为更好地理解有缺陷的代码变更而开发了一个工具, 以帮助开发人员在提交代码变更的同时对其进行有缺陷或者无缺陷的标记. 在实际应用中, 由于资源受限, Kamei等[20]首先提出了代价感知方法EALR, 并在开源项目和商业项目上进行了大规模的实证研究, 他们使用修改的代码行数作为检查代码变更所需工作量的一种代理; Yang等[27-28]先后提出了两种方法, 倾向于使用先进和复杂的技术(即集成学习和深度学习)分析软件缺陷. Nayrolles等[29]使用代码克隆检测技术提出了一种可捕获具有缺陷倾向性的代码变更方法CLEVER, CLEVER包含两个阶段: 在第一阶段, CLEVER评估代码变更成为有缺陷变更的可能性; 在第二阶段, CLEVER采用克隆检测截获前一阶段识别出的易发生缺陷的代码变更. Huang等[11]提出了一个简单的改进有监督模型CBS, 该模型认为较小的模块会等比例地出现缺陷, 因此应被优先检查, CBS包括两个阶段: 构建分类器阶段和对用于测试的代码变更排序阶段. Huang等[12]进一步改进了CBS的性能并命名为CBS+. Fu等[9]提出了一个即时软件缺陷分析方法OneWay, 其包含两个阶段: 在第一阶段, OneWay根据类标信息选择最好的基于代码变更的特征; 在第二阶段, OneWay使用该特性构建一个模型在测试数据中识别含有缺陷的代码变更.
除有监督的即时软件缺陷分析方法外, 研究人员也提出了无监督的方法, 因为这些方法更简单, 并且性能也较好. Yang等[21]首先提出了一种简单的无监督方法LT, 并在6个广泛使用的开源项目上对有监督方法和无监督方法进行了比较. Liu等[13]提出了另一种无监督方法Code Churn, 实验结果表明, 该方法的性能优于之前提出的有监督方法和无监督方法.
Python作为最受欢迎的开发语言之一, 如何有效、 即时地识别Python项目中的潜在软件缺陷, 对提高软件质量具有重要意义. 针对该问题, 本文提出一个能自动收集、 抽取、 标注Python项目, 然后基于标记数据构建即时软件缺陷分析模型的框架GIF(a framework of Git based just-in-time software defect quality analysis). 该框架主要包含数据收集阶段和数据分析阶段. 在数据收集阶段, GIF从项目的代码仓库中复制项目, 从GIF日志中分析软件项目的变更特征, 使用SZZ算法[17]对代码变更进行标注, 并将其存储到数据库中. 在数据分析阶段, GIF基于标注的数据集进行缺陷分析模型的构建, 并对新产生的代码变更进行有无缺陷的分析. 本文收集了GitHub上最受欢迎的前10个用Python开发的项目(时间截止到2020-05-30), 使用随机森林(random forest, RF)、 逻辑回归(logistic regression, LR)和朴素Bayes(Naïve Bayes, NB)3种经典有监督方法, 在这10个项目上以AUC(area under the ROC curve)和F1值指标进行实证研究, 结果表明, GIF能有效地识别出基于Python语言开发项目中的软件缺陷.
1 GIF框架
为能自动化地抽取并标注基于代码变更的Python项目数据集, 本文提出一个即时软件质量分析的框架GIF. 该框架主要包括两个阶段: 数据收集阶段和数据分析阶段. 在数据收集阶段, GIF从项目的代码仓库中复制项目, 从Git日志中分析软件项目的变更特征, 使用SZZ算法对代码变更进行标注, 并将其存储到数据库中. 在数据分析阶段, GIF基于标注的数据集进行缺陷分析模型的构建, 并对新产生的代码变更进行有无缺陷的识别. GIF的框架结构如图1所示.
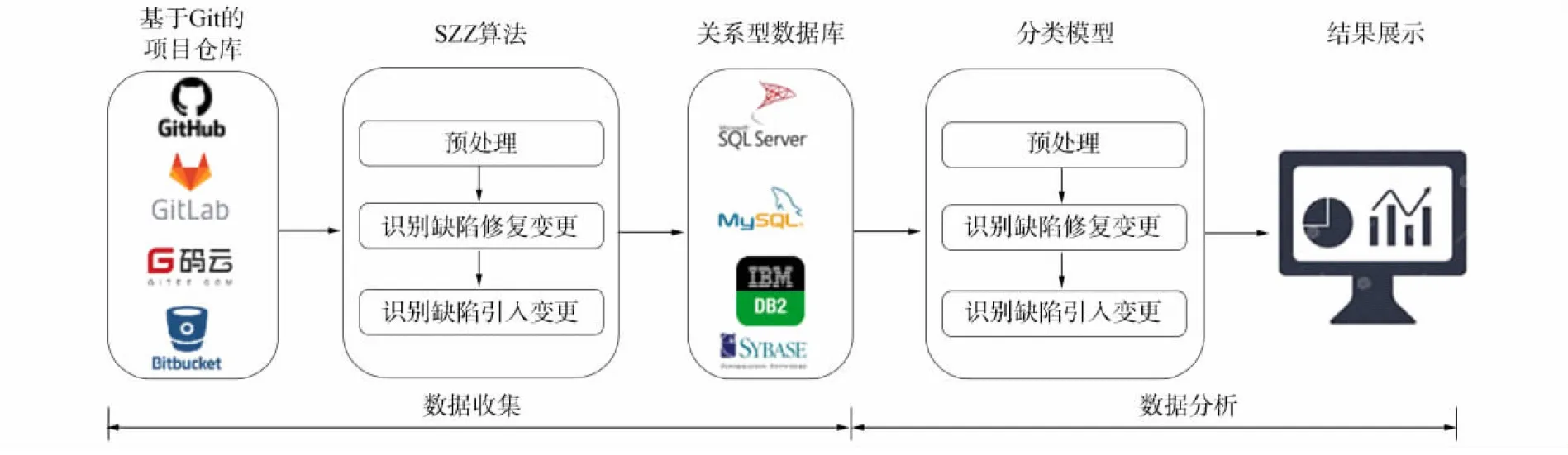
图1 GIF的框架结构Fig.1 Framework of GIF
1.1 数据收集阶段
在数据收集阶段, 首先需要为GIF提供一个有效的基于Git的远程代码仓库地址(如GitHub,GitLab,Gitee,Bitbucket等); 然后根据该地址, GIF将Python项目数据拷贝到本地, 使用SZZ算法对Git commit日志进行分析, 根据即时软件缺陷的特征对每个commit进行量化, 并标注每个commit是否有缺陷; 最后将标记好的数据存储到关系型数据库(如Mysql,Sql Server,DB2 Sybase等)中, 以备后续数据分析使用.
1) 识别修复缺陷的代码变更. SZZ算法利用一些特性搜索, 旨在修复以前缺陷的代码变更. 特别地, SZZ算法使用一些关键词(如bug,fix,wrong,error,fail,problem,patch)在代码变更的日志中搜索, 以标记该代码更改是否为进行缺陷修复的变更.
2) 识别引入缺陷的代码变更. 首先, 对每个候选修复缺陷的代码变更, SZZ算法使用Git diff命令标识之前对同一行代码进行修改的所有更改, 这些修改过的代码行被识别为导致缺陷的代码行; 然后, SZZ算法使用Git blame命令找出最后一次引入代码变更的修改, 这些修改引入了最后导致错误的内容, Git blame可显示文件每行的修改内容以及是谁对这些行做了修改; 最后, 这些代码变更被标记为引入缺陷的变更, 而其他变更则被标记为干净的变更.
1.2 数据分析阶段
在数据分析阶段, 基于GIF第一阶段标记的数据, 构建有监督的缺陷分析模型, 从而对新产生代码变更进行有无缺陷的分析.
在数据分析阶段, 主要有预处理、 模型构建和模型应用3个步骤. 预处理步骤对数据集进行预处理操作(如标准化和特征选择等), 以使数据集满足模型构建的需要, 提高数据集的质量; 在模型构建步骤中, 使用较成熟的机器学习模型或自定义一个新模型, 该模型能捕获数据的特征与类标特征之间的关系; 在模型应用步骤中, 首先对新产生的代码使用相同的特征指标进行量化, 然后对其进行必要的预处理, 分析其是否含有缺陷.
2 实 验
2.1 基于代码变更的特征
本文使用14个被广泛使用的基于代码变更的特征, 这些特征可分为5个类别: 扩散类别、 尺寸类别、 目标类别、 历史类别和经验类别. 表1列出了这些特征的统计信息, 包括名称、 描述以及所属类别.

表1 基于代码变更的特征
2.2 评测对象
本文先使用Python关键字在GitHub上进行搜索Python开发的项目, 然后使用most stars对搜索结果进行降序排序. 为选择最适合的项目, 本文设置了如下选择标准: 1) 以“.py”结尾的文件数量占整个项目中文件数量的比例不低于90%; 2) 这些文件不是教程、 使用Python实现的算法、 面试经验的收集和一些实用Python代码的集合这些类别的文件. 通过这些规则对搜索结果进行过滤后, 选取了排名前10的、 最受欢迎的Python项目. 表2列出了这些项目的统计特征.

表2 数据集特征
2.3 评测指标
本文使用AUC指标和F1值指标评估缺陷分析模型的效果. AUC为ROC曲线下的面积, 其取值范围为[0,1], 取值越接近于1, 表示对应的模型效果越好. 使用ROC曲线可考虑不同的阈值, 其中x轴表示TPR(true positive rate)值,y轴表示FPR(false positive rate)值. 根据不同阈值, 模型具有不同的TPR值和FPR值, 其对应坐标上的一个点, 将所有这些点进行连接即可得到ROC曲线.F1值是准确率p和查全率r的折中. 根据实例的实际类别和预测得到的类别, 可计算出真正率(true positives, TP)、 假正率(false positives, FP)、 真负率(true negatives, TN)和假负率(false negatives, FN). 然后基于以上4种情形, 可计算
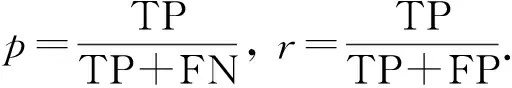
2.4 实验设置
2.4.1 实验方案
为更好评估方法的性能, 根据文献[11,23]的研究成果, 本文考虑时间敏感的十折交叉检验设置, 这种设置可保证用于训练的代码变更提交时间早于用于测试的代码变更. 即对于一个项目, 将其所有代码变更按时间的顺序进行升序排序, 然后将这些代码变更均匀地划分成12等份, 分别标记为第0~11份. 即第0份的代码变更是最早提交的代码变更, 而第11份的代码变更是最晚提交的代码变更. 对于其中的每一折i(i∈[1,10]), 其包含的训练数据为由从第0份到第(i-1)份中所有代码变更组合成的数据. 本文使用十折交叉检验上的结果计算每种方法的性能. 但本文并未考虑在第0份和第11份中的代码变更, 因为它们并不满足SZZ算法的要求. SZZ算法仅能识别出有父节点的代码变更, 并且其子节点被标记为修复的缺陷代码变更. 因此, 移除第0份的代码变更, 因为其并没有父节点的代码变更, 同时也移除第11份的代码变更, 因为其是最新被添加的代码变更, 可能尚未被正确标记.
2.4.2 模型方法
在经验性实验中, 为评估基于代码变更的特征是否能识别出Python语言开发项目中的缺陷, 本文采用广泛使用的机器学习包sklearn提供的方法, 包含如下3个经典方法: 随机森林(RF)、 逻辑回归(LR)和朴素Bayes(NB). 随机森林是一个包含多个决策树的集成分类器, 其输出类别由个别树输出类别的众数而定, 其中决策树又是一个基于规则的分类算法; 逻辑回归是一种广义线性模型, 其假设因变量类别服从Bernoulli分布, 逻辑回归与线性回归有很多相同之处, 是线性回归与Sigmoid映射函数的结合; 朴素Bayes是一组基于Bayes理论的有监督学习算法, 其假设每个特征与类标特征之间是条件独立的. 实验使用sklearn包中这3个模型的缺省参数, 即未对这些方法进行其他优化操作.
2.4.3 统计检验
为检验各方法之间的性能差异是否显著以及统计显著的程度, 本文使用无参的统计分析Wilcoxon无符号秩检验[30]和Cliff’s Delta效应检验[31].
2.5 结果分析
在GitHub中最受欢迎的前10个Python项目上对GIF框架进行实验测试, 使用3个基准模型(逻辑回归、 朴素Bayes和随机森林), 基于两个常用的性能评价指标(AUC和F1值)对软件缺陷分析技术在Python上的性能进行实证研究. 表3列出了3种基准方法在不同项目上的平均性能. 表4列出了不同方法的统计信息, 包括平均性能、 最好方法相对其他方法的性能提高比例(提升值)、 最好方法与其他方法之间的Wilcoxon统计结果(p值)以及Cliff’s Delta数值和相应的显著因子(规模).
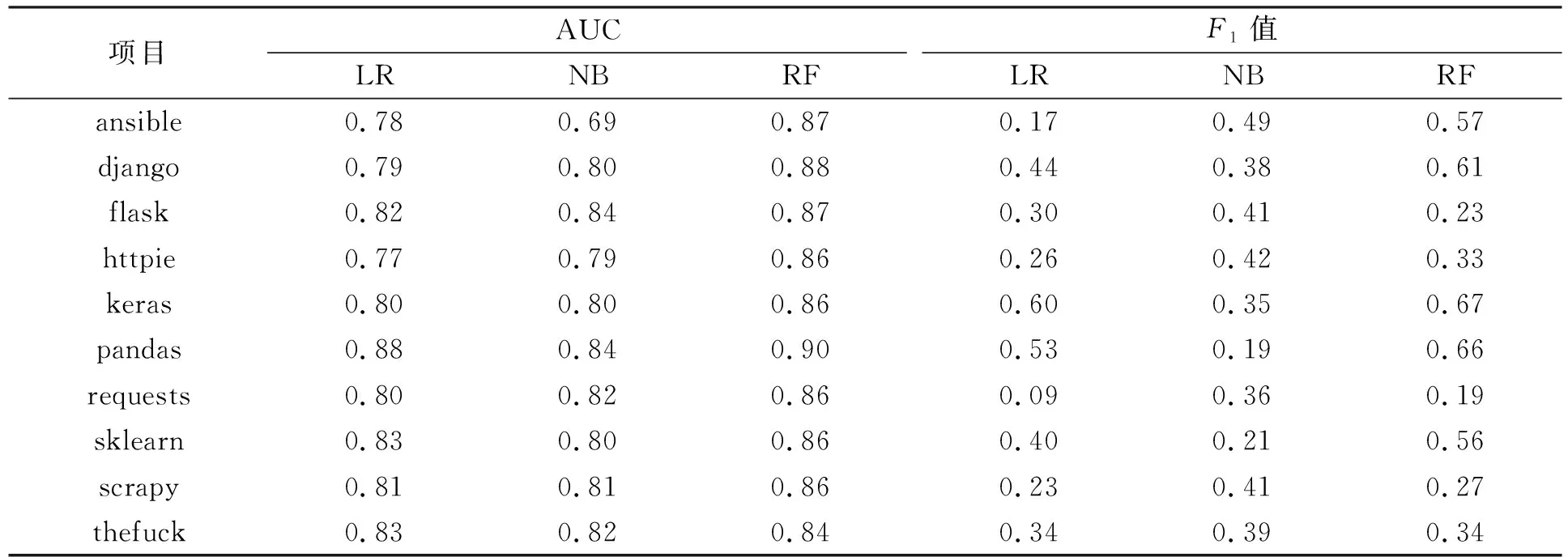
表3 3种基准方法在不同项目上的平均性能

表4 不同方法的统计信息
由表3和表4可见:
1) 3个基准方法在10个Python项目上能取得相似的平均性能. RF方法性能最好并且在统计上相比其他两种方法更具优势. 在AUC指标上, RF不低于中等级别的统计因子, 在统计上好于LR和NB. 在F1值指标上, RF在统计上好于LR和NB, 并且统计显著因子为小级别.
2) 文献[20]的研究表明, 在其他开发语言项目上, 使用LR能得到最好的AUC和F1值, 分别为0.76和0.45. 本文使用RF能得到AUC和F1值的最好结果分别是0.87和0.44. 表明本文提出的GIF框架能有效地识别出Python项目中的潜在缺陷.
2.6 有效性影响因素分析
影响本文研究结果有效性的因素主要包含三方面: 1) 内部有效性主要涉及到可能影响实验结果正确性的内部因素, 其中最主要因素是实验代码的实现是否正确, 因此, 为尽可能减小实现各方法过程中引入人为因素对实验结果产生的影响, 本文使用了成熟的框架, 例如来自sklearn中的机器学习包; 2) 外部有效性主要涉及到实验研究得到的结论是否具有一般性, 为确保实证研究结论的一般性, 本文抽取并标注了GitHub上最受欢迎的前10个开源项目, 这些项目涵盖了不同类型的应用场景, 可在一定程度上确保研究结论具有一定的代表性; 3) 结论有效性主要涉及到使用的评测指标是否合理, 本文考虑两个广泛使用的评价指标AUC和F1值, 可以更好地评估模型的性能.
综上所述, 本文针对目前现有技术无法自动抽取软件仓库、 标记数据、 构建质量分析模型和分析软件质量的问题, 提出了基于Git日志的即时软件缺陷分析框架GIF, 该框架可以自动抽取并标注数据集, 然后构建针对Python项目的即时缺陷分析模型. 此外, 本文收集并分享了使用Python语言开发的10个在GitHub上最受欢迎的项目数据集, 通过实证研究证明了GIF框架可有效地识别出使用Python语言开发项目中的缺陷.
猜你喜欢
河南教育·职成教(2022年5期)2022-05-06
课堂内外(高中版)(2021年8期)2021-01-17
少儿画王(3-6岁)(2020年4期)2020-09-13
莫愁(2019年36期)2019-11-13
东方教育(2018年20期)2018-08-22
新高考·高二数学(2016年7期)2017-01-23
中学生数理化·七年级数学人教版(2016年4期)2016-11-19
股市动态分析(2016年17期)2016-10-20
股市动态分析(2016年17期)2016-10-20
股市动态分析(2015年16期)2015-09-10
