
基于改进自注意力机制的方面级情感分析
2022-01-21 04:24毛腾跃郑志鹏郑禄
中南民族大学学报(自然科学版) 2022年1期
毛腾跃,郑志鹏,郑禄
(中南民族大学 计算机科学学院&湖北省制造企业智能管理工程技术研究中心,武汉 430074)
情感分析(Sentiment Analysis,SA)是自然语言处理(Natural Language Processing,NLP)领域的重要研究方向之一,其中针对文本信息的方面级情感分析(Aspect-Based Sentiment Analysis,ABSA)是更加细粒度子任务,它不仅在学术界被广泛关注,在工业界中也应用广泛,亚马逊、淘宝等电商网站针对商品评论进行情感分析[1],可以为企业和用户提供实时反馈,改善产品服务和用户体验.
在方面级情感分析任务中,用户的评论往往会包含针对单个目标或多个目标的几个不同方面,例如:“The food is so good and so popular that waiting can really be a nightmare.”中,“food”方面的情感极性是积极的,但是针对“service”方面的情感极性是消极的.ABSA的任务就是识别实体对象在特定方面的细粒度情感极性[2].
早期的方面情感分析主要基于人工构建的情感词典、语法规则等相关特征,再结合朴素贝叶斯(NBM)[3]、支持向量机(SVM)[4]等模型来训练分类器,进而得到特定方面的情感极性.近年来,随着深度学习方法的广泛应用,ABSA任务目前大多采用的是诸如循环神经网络的相关模型;同时,由于注意力机制在文本分类上的显著效果,越来越多的研究人员开始使用注意力机制来挖掘方面词和上下文之间的关系[5].
目前有研究注意到,传统的应用于情感分析的注意力机制在训练时,对于出现频率高的情感词,注意力机制往往会倾向于给其分配较高的注意力权重,而对于出现频率低的情感词,注意力的权重分配不足[6].如表1所示,在列举的3个训练句中,由于句中情感词“small”往往以消极的情感极性出现,因此注意力机制对其消极的情感表示给予了更多的关注,分配了更高的注意力权重值,甚至直接将该情感词和负面情绪句子关联起来.传统注意力机制的这一特性,会导致对另外一个具有情感极性的情感词“crowded”关注不足,尽管该单词也具有消极的情感极性,但是训练过程中,由于其出现次数较少,注意力机制通常无法识别出来.因此,部分采用这种注意力机制的ABSA模型,就会错误预测示例中两个测试句子的情感极性:在第一个测试句中,一些ABSA模型无法捕捉“crowded”涉及的负面情绪;虽然在第二个测试句中,注意机制关注到了“small”,但是它与给定的方面无关,因此导致将方面“hotel”原本的积极情感极性错误预测为了消极.所以,本文认为目前的ABSA模型的注意力机制部分存在一定的改进空间.

表1 典型句子举例Tab.1 Examples of sentences
传统的结合注意力机制的ABSA模型进一步提升情感分类的效果有限.为了解决这一问题,本文使用改进后的自注意力机制,可以根据上一轮注意力信息指导下一轮注意力机制训练的过程.
1 相关工作
方面级情感分析是一种细粒度的情感分类任务,早期的方面级情感分析方法通常是基于词汇和句法特征的传统机器学习模型[7-9],这种模型的性能高度依赖于大量的人工标记的情感词典的质量.因此,近年来的研究提出了大量基于深度学习的情感分类方法,可分为以下5类:递归神经网络(Recursive Neural Network,RecNN)、循环神经网络(Recurrent Neural Network,RNN)、基于注意力的RNN、卷积神经网络(Convolutional Neural Network,CNN),以及记忆网络(Memory Network)[10].
DONG等人[11]第一次提出在方面级情感分析任务上使用RecNN,RecNN通过自下而上的方式递归生成父表示,进而获取短语的表示,最终得到整个句子的表示信息,该模型利用了句子的句法信息作为辅助模型来提高情感分类的效果.由于RNN模型在语言序列学习问题中展现出了显著作用,所以目前许多ABSA的解决方案都源于RNN模型.TANG等人[12]为了解决LSTM忽略目标词的问题,提出了Target-Dependent LSTM(TD-LSTM),在TD-LSTM的基础上,提出了Target-Connection LSTM(TC-LSTM),进一步加强了target-word与句子中每个token的关联.注意力机制已经成功应用于很多自然语言处理的任务,例如机器翻译、问答、阅读理解等.很多基于注意力的RNN模型也被用于方面级情感分析,使用注意力机制来强制执行RNN模型关注文本序列的重要部分.WANG等人[13]提出了基于注意力机制的LSTM模型(ATAE-LSTM),将输入的句子表示与方面词结合,采用LSTM进行编码获取隐向量表示,然后与方面词表示进行拼接,通过注意力机制对输出进行处理,最终得到情感分类的结果.对于基于注意力的RNN方法,MA等人[14]考虑了给定方案及其内容词之间的交互,提出了Interactive Attention Network(IAN),使用两个基于注意力机制的LSTM来交互地捕捉方面术语和上下文的联系,分别计算注意力权重分数,将单词和上下文表示拼接起来作为句子的向量表示,计算情感分类的结果.TANG等人[15]为了解决RNN、LSTM等网络记忆能力差的问题,首先基于ABSA的多跳注意力机制提出了深度记忆网络(MemNet),它维护了一个外部的记忆单元用于存储上一层的信息,而不是通过内部的隐状态.CHEN等人[16]在记忆网络的基础上,结合循环的注意力机制,提出了RAM模型,为了提取长距离的情感信息,该模型采用GRU网络对注意力进行多层的提取,将提取的多层注意力进行非线性组合得到目标方面的情感极性分类结果.
近期在方面级情感分类中表现较好的模型,大都使用了相应的注意力机制,但是这些模型为了获得给定方面在上下文句子中的重要性,其使用的注意力模型往往会存在关注高频情感词而忽略低频情感词的问题.本文为了解决传统注意力机制存在的问题,使用渐进式的自监督学习方法,自动挖掘语料库中的注意力权重信息对注意力机制训练过程进行改进,指导ABSA模型的情感分类.
2 模型
2.1 ATAE-LSTM(+AS)模型
本文使用的ATAE-LSTM(+AS)网络模型在ATAE-LSTM模型的基础上,对其注意力机制的训练过程进行了改进,如图1所示,分为输入层、双向LSTM层、注意力层和输出层.对于一个给定的评论语 句x=(x1,x2,...,xN)和 给 定 的 方 面 词w=(w1,w2,...,wT)[17],模型的目的是为了预测给定方面的情感极性.
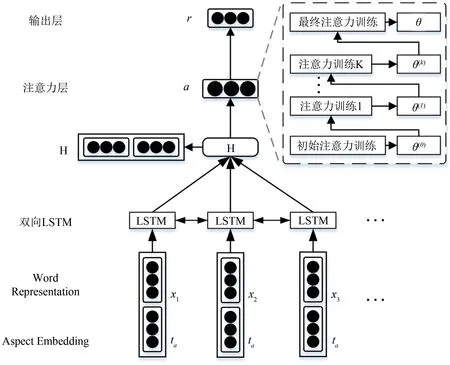
图1 网络模型Fig.1 The network model
输入层:对文本预处理之后,使用Glove词嵌入,获得每个词的词向量表示,然后将方面词的词向量与每个词的词向量进行拼接,作为模型的输入表示.
双向LSTM层:LSTM网络是一种特殊的RNN,能够学习到长期的依赖性.将文本词和方面词拼接后的词向量作为双向LSTM层的输入表示,使模型可以从前往后和从后往前两个方向对输入进行编码,提取文本的句子特征,得到单词和整体文本的隐向量表示.本文采用的模型使用了双向LSTM对句子进行编码,LSTM模型由3个门组成,分别是输入门、输出门和遗忘门[18].具体的LSTM单元计算过程的如公式(1)~(6)所示:
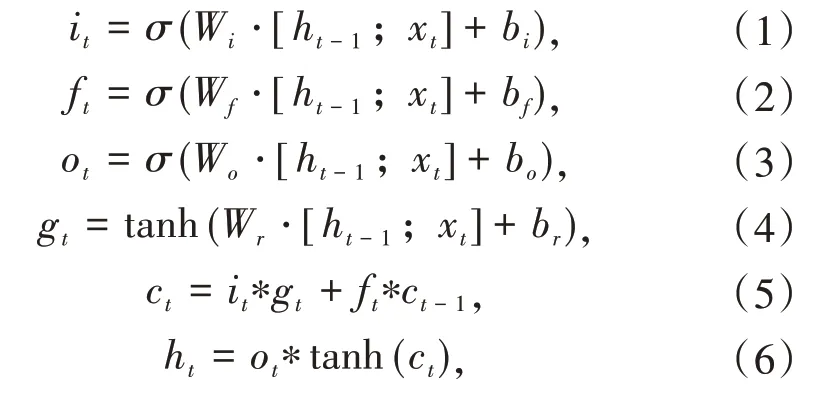
其中,t表示时间,xt是时间t的输入,ht是时间t的隐向量表示,*代表元素乘法,σ表示激活函数,Wi,bi是输入门的参数,Wf,bf是遗忘门的参数,Wo,bo是输出门的参数.ct-1和ct分别表示上一单元的状态和当前单元的状态.
注意力层:本文的目标是改进注意力机制的训练过程,在模型注意力训练的过程中增加额外K轮迭代训练,生成更加准确的注意力权重,指导最终的情感分类过程.
输出层:通过注意力层之后,经过全连接层和softmax函数后,得到最终的情感分类结果.
2.2 自注意力模块
在基于注意力机制的ABSA模型中,句子中的每一个上下文单词,对一个给定方面的重要性程度主要依赖于其注意力权重.因此,具有最大注意力权重的上下文词的情感极性对输入句的情感预测结果影响最大.所以,如果在训练句中,ABSA模型的预测是正确的,应该继续关注该上下文的情感词;反之,应该尽量减少对于该情感词的关注度,将其在下一轮训练中的预期注意力权重值设置为0.
如前所述,具有最大注意力权重的上下文词通常是具有强烈情感极性的.它一般会在训练语料库中频繁出现,因而在模型训练期间往往会被给予过度的关注,可能会导致对其他低频词,特别是那些具有情感极性的低频情感词的学习和训练不足.为了解决这个问题,一种较为直观的方法就是在本轮训练时,先屏蔽掉前面具有最强情感极性的上下文单词,使注意力模型在训练过程中,可以关注到具有情感极性的低频单词.
基于以上的分析,本文采用了一种渐进式的训练方法来自动挖掘当前训练句中的强情感极性的语境词,在原有注意力训练的基础上增加额外的K轮改进后的注意力迭代训练过程.首先使用初始的训练语料库D进行注意力机制的训练,得到初始的模型注意力参数θ(0),然后继续迭代训练,在每一次迭代中提取一个注意力权重值最高的情感词,循环直到K轮注意力训练结束或者当前句子中已经不存在对句子情感预测具有强烈影响的情感词为止.在此过程中,使用两个单词集合sa(x)、sm(x)来分别记录提取出的上下文单词.sa(x)是由对句子x的情绪预测正确的情感词组成的集合,希望在后续的模型训练中予以保留;sm(x)是由对x的情绪预测错误的情感词组成的集合,在后续的训练中,会减少对这些情感词的注意力权重.步骤1到步骤4是额外K轮注意力迭代训练的具体过程:
步骤1:使用前面轮次迭代产生的模型参数θ(k-1)来生成方面表示v(t),k∈[1,K],初始模型参数为θ(0).然后根据集合sa(x)和sm(x),将所有先前从x中提取的上下文单词屏蔽,来创建一个新的句子x',每个被屏蔽的单词被替换为一个特殊的标识“
步骤2:基于方面表示v(t)和单词表示h(x'),利用前一轮的模型参数θ(k-1)来预测句子x'的情感,记为yp,代表基于当前模型参数,预测得到的情感极性.其中单词的注意力权重分布为α(x')={α(x'1),整体加权和为
步骤3:使用熵E(α(x')),来表示α(x')的方差,这有助于模型确定句子x'中的高频情感词是否存在,公式如下:
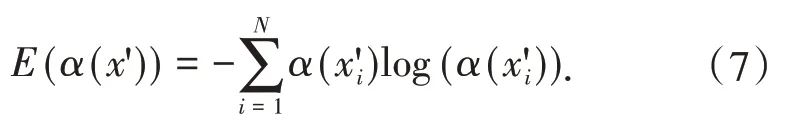
如果E(α(x'))小于阈值εα,本文认为当前句中存在对x'情感预测影响较大的情感词.因此,将对句子情感预测结果影响较大的情感词(记为x'm)提取出来,用于改善模型的训练.具体来说,根据预测的结果使用了两种策略:(1)如果预测是正确的,本文希望继续关注x'm,并且将其添加到集合sa(x);(2)如果预测是错误的,本文希望减少对于x'm的注意力权重,并且将其添加到集合sm(x).循环进行K轮注意力训练.
步骤4:在额外K轮训练之后,将x',t和y作为一个三元组,并将其与收集的集合组合成新的训练语料库D(k),利用D(k)执行最后一轮注意力训练.通过这种方式,可以让模型自动挖掘出对情感预测具有强烈影响力的上下文单词.
通过上述K轮的迭代,可以提取到所有训练实例中有影响力的上下文词.如表2所示,在此示例中,迭代地提取出了“small”,“crowded”和“great”3个上下文词.前两个单词包含在sa(x)中,而最后一个单词包含在sm(x)中.最后,每个训练实例中提取的上下文单词将被包含在D中,形成最终训练语料库的信息,该信息将用于执行最后一轮的注意力训练.

表2 挖掘情感词句子举例Tab.2 The example of mining emotional words
为了利用上下文词来优化针对ABSA模型的注意力机制的训练,本文使用了一种注意力优化器其中α(*)和表示sa(x)∪sm(x)所引起的注意力分布.是两者之间的欧氏距离损失,可用于消除之间的差异.
如前所述,本文希望在最终注意力训练期间,即第K轮迭代结束后,接着的一轮注意力训练时,同样继续关注sa(x)的上下文词.为此,将句子的预期注意力权重设置为相同的值,即为.通过这种方式,之前提取出的单词的注意力权重会被降低,后来提取的单词的注意力权重会相应增加,由此可以避免具有情感极性的高频上下文词的过度拟合,以及低频情感词在模型训练时被忽视的问题;另一方面,由于sm(x)中的单词对x的情感预测具有误导性的影响,因此减少它们的影响,直接将其预期的权 重 设 置 为0.以 表2中 句 子1为 例,“small”和“crowded”∈sa(x),所以被分配相同的预期注意力权重,即为0.5,“great”∈sm(x)的预期权重为0.
最后,使用添加了sa(x)和sm(x)中词的训练语料库Ds进行最后一轮注意力训练,如公式(8)、(9)所示:
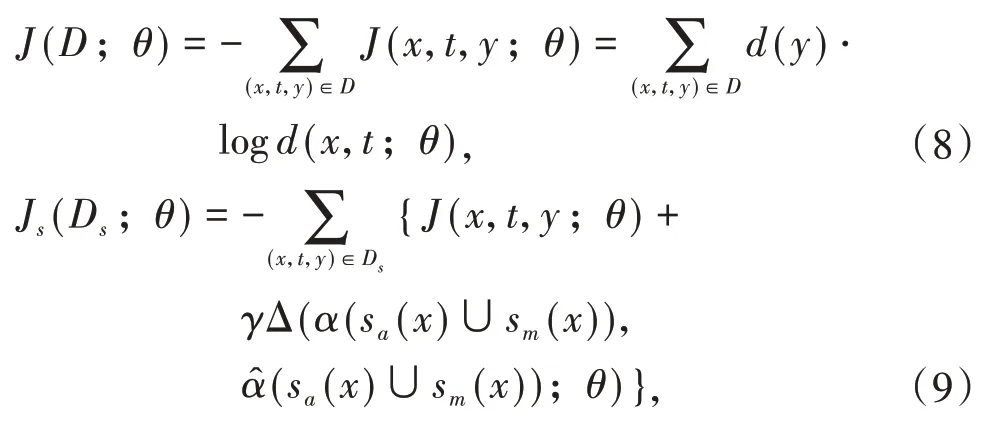
公式(8)表示常规训练目标,公式(9)表示最终在Ds语料库上的训练目标.其中D是训练语料库,d(y)是y的一维向量,d(x,t;θ)是模型对(x,t)预测的情感极性分布,γ是平衡常规损失函数和正则化术语之间差异的参数.除了利用监督信息以外,将这类信息添加到模型中,更容易解决梯度消失的问题.
3 实验
3.1 实验数据和评价指标
为了验证本文ATAE-LSTM(+AS)模型的效果,实验使用了SemEval 2014 Task4的两组公开数据集——Laptop和Restaurant领域的两个数据集,以及包含Twitter用户对多个方面项评论信息的Twitter数据集.3个公开数据集是目前方面级情感分析任务使用最多的数据集,由上下文语句、方面项、方面所对应的情感极性组成.本文使用的数据集中,方面情感极性包含积极、消极、中立3个方向,统计结果如表3所示.
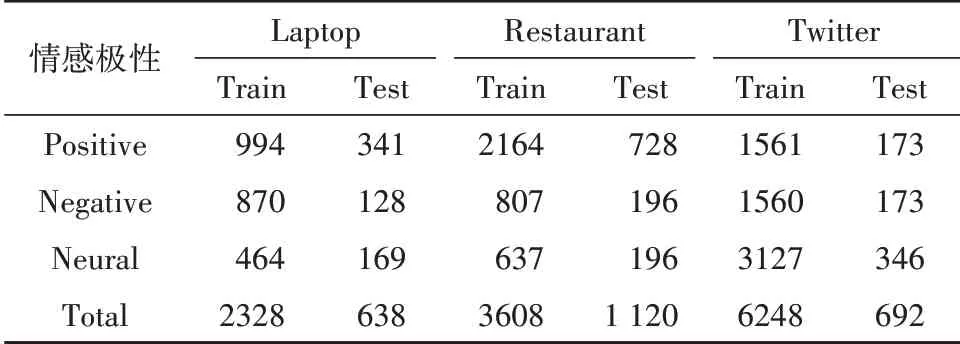
表3 基准数据集统计表Tab.3 The statistics of benchmark dataset
为了准确评估不同的方面级情感分析模型的性能,对本文采用的注意力机制的改进效果进行评估,本文采用情感分析领域常用的准确率(Accuracy)和Macro-F1值作为评价指标,公式如下:
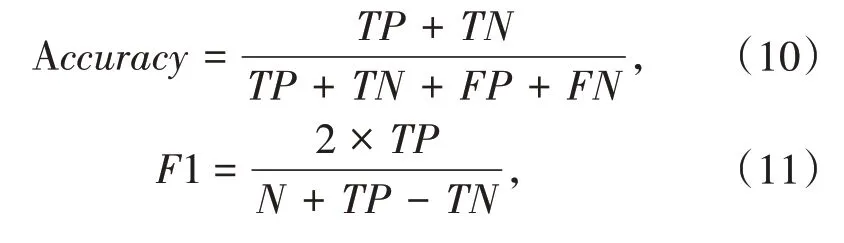
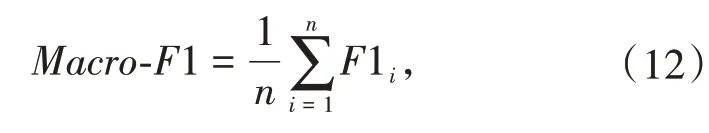
其中,TP表示正类情感极性标签被模型正确预测为正的样本数量;TN表示负类情感极性标签被模型正确预测为负的样本数量;FP表示负类情感极性标签被模型错误预测为正的样本数量;FN表示正类情感极性标签被模型错误预测为负的样本数量,N表示总的样本数量.
3.2 模型参数
在本文的实验中,采用了预训练的词向量对模型的输入进行处理,词向量的维度设置为300.对于词汇外的单词,在其均匀分布的[-0.25,0.25]范围内进行了词嵌入的随机采样.此外,在[-0.01,0.01]的范围内均匀地初始化了其他模型参数.根据实验经验数据,将最大迭代次数K设置为5.γ在Laptop数据集上设置为0.1,在Restaurant数据集上设置为0.5,在Twitter数据集上设置为0.1.所有的超参数都在注意力训练过程中进行20%左右的随机上调.使用Adam作为优化器,learning rate设置为0.001.
3.3 对比模型
本文对基于改进自注意力机制的ABSA模型(ATAE-LSTM(+AS))和 以下 的baseline方法 在SemEval 2014 Task4的两组公开数据集和Twitter数据集上进行了比较,以验证该方法的有效性.具体对比模型如下:
(1)SVM:Kiritchenko等将SVM与词典的方法相结合,在SemEval比赛中对方面情感分类任务上取得了优于之前方法的效果;
(2)LSTM:对句子中的token进行embedding之后作为模型的输入,经过多轮计算隐层和输入之后得到句子的隐向量表示,然后对这个向量进行softmax计算情感分类的概率;
(3)TD-LSTM:使用了两个LSTM,分为前向和后向,分别对目标词的左右两边的信息进行建模,将得到的隐状态融合之后得到整体句子的情感表示,用于情感分类;
(4)ATAE-LSTM:进一步利用了方面词嵌入的信息,将方面嵌入和上下文词嵌入共同组合作为模型的输入,使用LSTM模型计算上下文特征,结合注意力机制对隐藏层进行处理,得到针对方面的情感分类结果;
(5)ATAE-LSTM(+AS):本文提出的情感分类模型,在ATAE-LSTM的基础上,使用了改进后的自注意力机制,对注意力层进行额外的K+1轮训练,能更好地对上下文分配注意力权重,指导模型进行情感分类.
3.4 实验结果与分析
表4提供了上述5个模型的所有实验结果,为了证明本文方法的有效性,在3个基准数据集上重新实现了相应的对比模型,采用准确率和Macro-F1度量模型的效果.其中,SVM、LSTM和ATAE-LSTM都与原始论文中的实验结果相当.这些结果表明,重新实现的基线模型是具有可信度的.
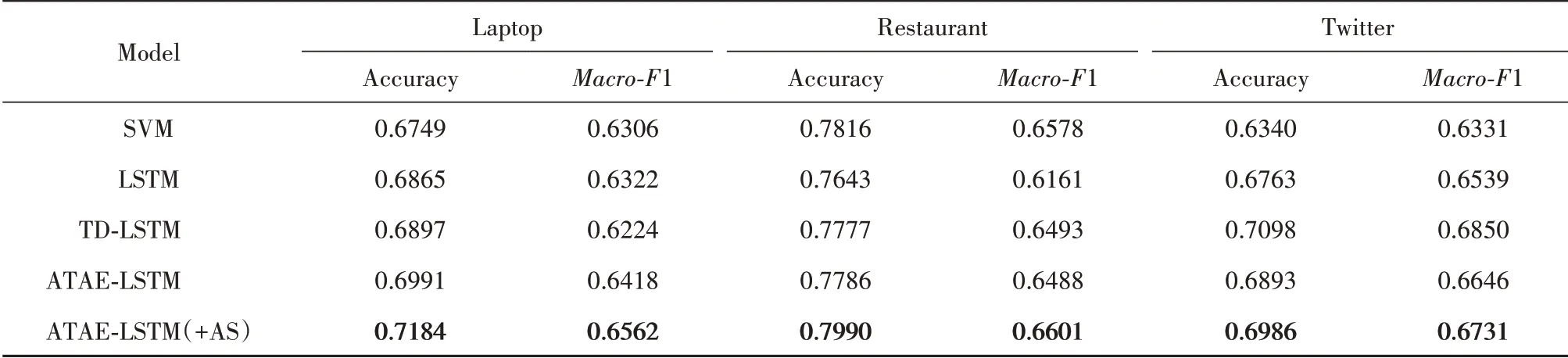
表4 各模型实验结果对比Tab.4 Experimental results comparison of different models
以上方法中,SVM的方法在Laptop数据集的表现与其他LSTM模型相当,在Restaurant数据集中性能相对还优于其他传统LSTM方法,说明传统机器学习与特征工程的方法依然具有应用价值,但是由于其需要大量的人工标记的情感词典,所以不适合大规模工业级数据的分析任务.在Laptop和Restaurant数据集上,ATAE-LSTM(+AS)都取得了较好的效果,由于本文对注意力机制的训练过程进行了改进,增加了额外的多轮训练,因此与原始的ATAE-LSTM模型相比,模型注意力参数更加合理,在Laptop、Restaurant和Twitter数据集上的准确率效果提升了1.93%、2.04%、0.93%.这一结果表明,本文采用的改进的注意力机制可以很好地与传统的基于注意力机制的方面级情感分析模型融合,提升了情感分类的准确率.
4 结语
本文研究了自监督的注意力机制算法,提出了用于方面级情感分类的改进的自注意力模型ATAE-LSTM(+AS),克服了当前ABSA模型中注意力机制的缺陷,如过度关注具有情感极性的高频情感词、对低频的情感词缺乏足够关注度,导致情感词的注意力权重分配不合理,影响了情感分类模型的性能.因此,本文采用了一种改进的注意力机制,将它应用于传统ATAE-LSTM模型中,在3种公开基准数据集上的实验结果表明:本文的方法有效提高了原始的方面情感分类模型的性能.
猜你喜欢
心理学报(2022年5期)2022-05-16
中学生报·教育教学研究(2022年1期)2022-04-18
小雪花·成长指南(2022年1期)2022-04-09
当代陕西(2020年17期)2020-10-28
时代英语·高一(2019年5期)2019-09-03
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
第二课堂(课外活动版)(2016年2期)2016-10-21
数理化学习·高一二版(2009年2期)2009-03-30
数理化学习·高一二版(2009年1期)2009-03-19
