
求解烟草配送路径规划问题的新型智能优化算法
2022-01-21 04:24:32高怡杰何湘竹石英王建树
中南民族大学学报(自然科学版) 2022年1期
高怡杰,何湘竹*,石英,王建树
(1 中南民族大学 电子信息工程学院,武汉 430074;2 湖北省烟草公司 物流处,武汉 430074)
近年,烟草行业在我国财政收入中占比不断加大,然而,作为其核心业务的烟草物流,目前仍主要采用传统的配送方式,导致出现:从业人员数量大,配送车辆以及送货线路多,单车日送货客户数明显不足的问题.究其原因之一,为缺乏对配送车辆及配送线路的改良及优化[1].针对此,本文研究新型智能优化算法,对烟草配送方式及路径进行优化,以提高配送效率,节约配送成本.
近年来,随着人工智能技术的发展,研究者从仿真机制中得到了求解该问题的启示,提出了一系列智能优化算法.高等[2]梳理了许多针对TSP问题的算法方案,如遗传算法(GA),模拟退火算法(SA),蚁群算法(ACO),禁忌搜索算法(TS)等,并求解于TSP问题.周等[3]中提出了离散型萤火虫群优化算法(DGSO)算法,该算法一方面结合TSP问题本身的特点,提出了一种新的有效编码方法,并给出其相应的解码方法,同时定义个体间距离计算公式和编码更新公式,另一方面算法使用了2-opt优化算子,该算法在种群规模较小,迭代次数较少的情况下可以收敛得到最优解,但仍有提升空间.马等[4]提出了一种求解旅行商问题的文化混合优化算法,该算法将遗传算法和模拟退火算法相结合并纳入文化算法体系,并将算法求解空间分为种群空间和信度空间,通过两个空间的相互配合引导种群进化,该算法优化效果虽然有一定提升,但非常有限.
TLBO(Teaching-Learning-Based Optimization)算法是RAO受课堂知识传授现象启发于2010年提出的一种新智能算法[5],控制参数少且全局寻优能力强大,已成功求解许多连续优化问题[6-9].然而,TLBO算法在组合优化领域的应用研究却相对较少,XIE[10]和SHEN[11]等人尝试将TLBO算法本身进行改进或者与其它算法混合,并用于求解车间调度问题,均取得很好的效果.WU[12]等将TLBO离散化,提出离散教与学优化算法并用来解决旅行商问题,但其实验验证部分的结果表明,TLBO算法还有很大的改进空间.
本文针对烟草配送路径规划问题,基于传统TLBO算法的基本框架,提出了一种新型智能优化(Improved Teaching-Learning-Based Optimization,ITLBO)算法并用于求解该问题.首先,重新定义了学生的表示方式,具体到TSP问题,班级中的每个学生都对应一个由访问城市编码组成的序列.其次,考虑到组合优化问题的特点,重新设计新的学习方式,引入线性顺序交叉[13](Linear order crossover,LOX)算子模拟教师授课和学生互动的学习过程.另外,为了有效平衡算法搜索过程中的集中性和多样性,新开发了教师培训、学生自学以及教师反向学习阶段,并引入多种算子,结合自适应退火机制和禁忌策略,实现算法的学习进化过程.基于TSPLIB标准测试用例的仿真实验,及某市烟草公司烟草配送单车辆及多车辆的路径规划求解,均验证了所提出的ITLBO算法的有效性.
1 烟草配送路径规划问题建模
烟草配送路径规划可建模为车辆路径问题,其中单车辆路径规划问题可描述为:在已知N个客户及各个客户间距离的前提下,一配送车辆从仓库出发,访问完N个客户之后再回到出发仓库,如何寻找到一条最短访问路径,保证每一个客户都被访问到且只被访问一次,其数学模型如下:
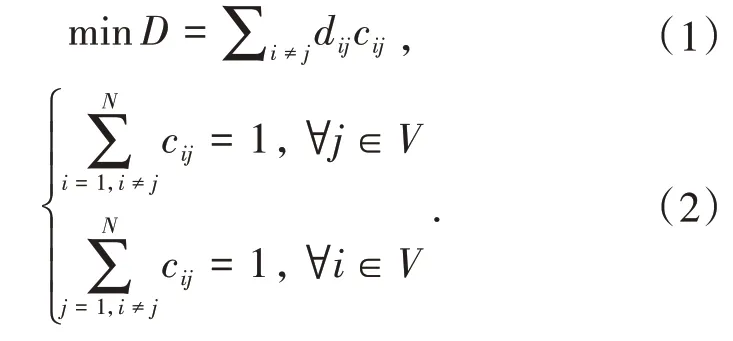
其中,i,j∈{1,2,...N}=V,cij代表车辆从第i个客户访问第j个客户,cij∈{0,1},取值为1表明i到j的边属于访问路径,0则代表不属于,dij代表i和j两个客户之间的距离,D为访问路线的总距离.式(1)为目标函数,表明路径规划问题优化的目标为总路径长度最短,式(2)为约束条件,意味着每个客户只能被访问一次.本文中,客户i的位置用二维平面的坐标对(xi,yi)表示,两个相邻客户之间的距离dij采用欧式距离公式计算.
2 传统TLBO算法
TLBO算法是RAO于2010年提出的一种自然启发式算法,该算法模拟课堂教学过程,通过教师教授知识和同学互助学习来提高整个班级的成绩.TLBO算法的主要过程如下[5].
第一步初始化班级.首先,随机生成N个学生,每个学生代表问题的一个解.所有学生通过成绩好坏来评价.成绩最好的学生被选为教师,其余均作为该教师的学生,教师和学生一起构成一个班级.
第二步教学阶段.此阶段模拟教师授课过程,班级形成后,教师向学生传授知识,通过采用让班级中的每一个学生都向教师学习的方式,使整个班级成绩得以提高.这一过程中的每一次迭代均可通过式(3)和式(4)实现,其中,r是一个[0,1]之间的随机数,c是教学因子,用来反映教师的教学水平.Ms代表整个班级学生的平均值,T代表教师,通过式(3)求出班级平均水平和教师之间的差距Diff,之后再根据式(4)将每位同学的原值加上差距Diff获得新值.
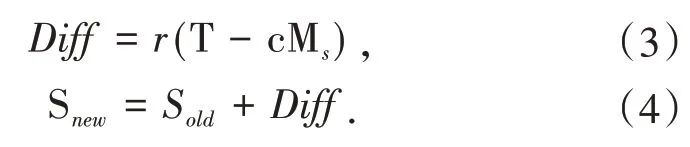
最后一步学习阶段.此阶段模拟学生相互学习的过程.随机选取班级中的一个学生,该生通过与班级中另一位学生交流,来提升自身水平.这一阶段的学习过程可通过式(5)实现,Si和Sj代表随机挑选的两个学生,比较他们的成绩,选出成绩较好的学生,成绩较差的学生通过向其学习提高原有成绩.
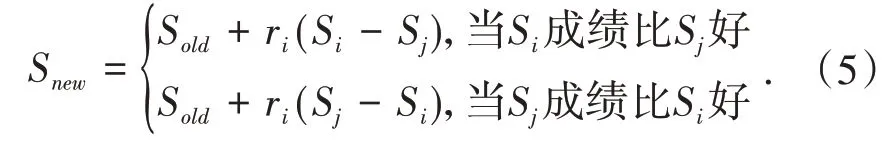
TLBO算法运行时,先进行第一个阶段的初始化,再通过多次重复第二个阶段和第三个阶段完成教与学过程迭代,使得整个班级的成绩进化,最终寻找到全局范围内的最优解.
3 ITLBO算法
本文针对路径规划问题,在对传统TLBO改进和重构的基础上提出ITLBO算法,具体措施如下.
第一,传统TLBO中,学生是一个由连续值组成的向量,这种表达不适用与组合优化问题.针对此现状,在ITLBO算法中,重新定义学生的表示方式,在对将各个城市统一编码后,将学生表示为由访问城市对应编码组成的正整数序列.
第二,传统TLBO中,无论是教学阶段还是学习阶段,其学习方式均是通过给学生原有的成绩加上他与教师(或同学)之间的差值来实现,这种学习方式无法直接应用于组合优化问题.针对此现状,ITLBO算法中重新设计学习方式,保留了传统TLBO中教与学的基本原理,但将学习过程更新为解结构更相似的进化过程,并通过引入LOX算子实现学生向教师学习及学生之间的相互学习.
第三,传统TLBO中,只包含教学阶段和学习阶段两个进化步骤,学习方式过于单一,影响了算法的全局寻优能力.针对此缺陷,ITLBO算法将TLBO中原有的两个阶段的教学过程扩展优化为教师培训、教师教学、学生互学、学生自学、教师反向学习五个阶段.首先在教学阶段之前增加教师培训阶段,该过程的作用为,对选出的教师进行岗前培训并择优上岗,引入激励竞争机制以提高教师的教学水平,也保证在后续的教学环节中,学生能从老师那里获得更为丰富的知识,从而增强算法的寻优能力.其次在学习阶段之后增加学生自学阶段,除了教师传授及同学间互助,学生还可以通过自身的努力来快速提高成绩,这一阶段利用2-opt算子[14],实现学生的自我优化操作,从而加快算法的收敛速度.最后,在自学阶段之后增加教师反向学习阶段.通过引入禁忌策略,限制教师在禁忌时间内再次当选,且允许教师在禁忌期间向最差的学生反向学习以获取新知识,从而有效增加算法的多样性,平衡其全局勘探和局部搜索的能力.
第四,传统TLBO中,采用了单一的精英策略,使得搜索方向过于集中,算法缺乏多样性且容易“早熟”.针对此缺陷,ITLBO算法中,设计自适应模拟退火机制并将其引入各个学习阶段,每次迭代前计算班级的最好与最差成绩,以此为依据求出退火温度t,采用Metropolis准则[15]以一定概率接收寻优过程中的差解,避免算法过早收敛而陷入局部最优.
3.1 初始化阶段
在初始化阶段,算法随机生成N个学生Si,并将其禁忌时间Time(Si)置为0.之后,依据公式(6)计算每位Si的成绩.

其中,gi表示第i个学生的成绩,Pi表示第i个学生对应的访问城市序列,dis(Pi)表示此访问顺序下求出的路径总长度.
3.2 培训阶段
在培训阶段,教师通过对自身解结构进行变换来实现自我优化.首先,根据成绩选出排名靠前的Nt个学生做为备用教师,之后采用迭代变换法[16]对其培训,最终选出成绩最好的教师参加后续教学活动,具体步骤如下.
Step1:按照成绩好坏对个体从大到小排序,计算最大路径长度dismax与最短路径长度dismin,设置退火温度t=dismax-dismin.并选择排名前Nt且禁忌时间为0的Nt个学生作为培训备选教师.
Step2:从Nt个备选教师中选择一个教师Ti参加培训,并设置计数器count记录未参加培训的老师个数,count初值为Nt.
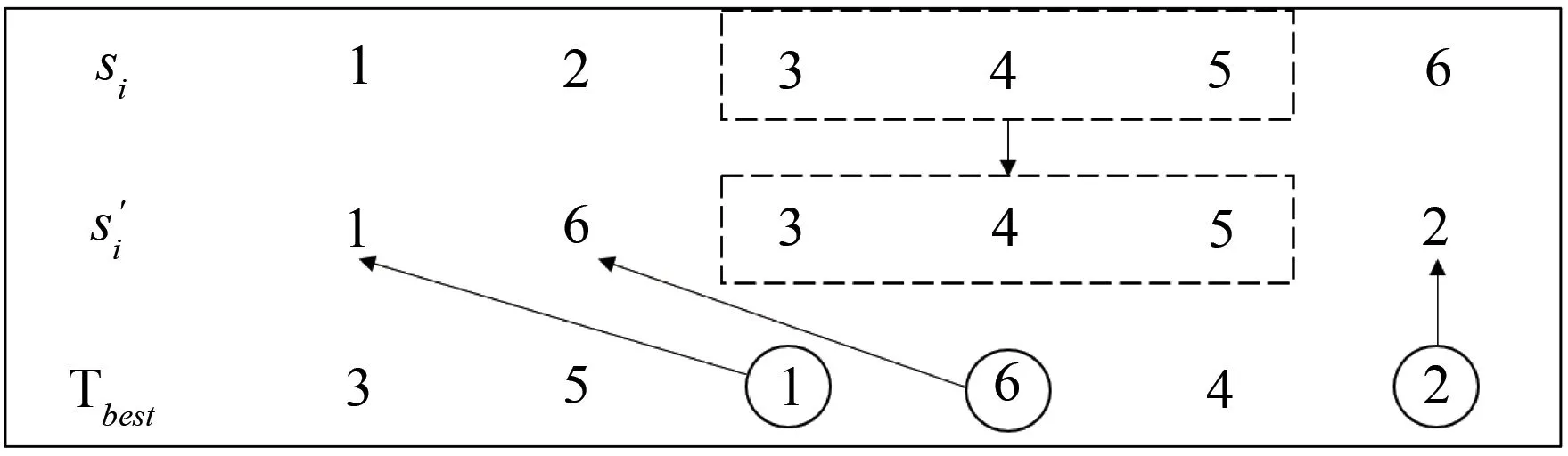
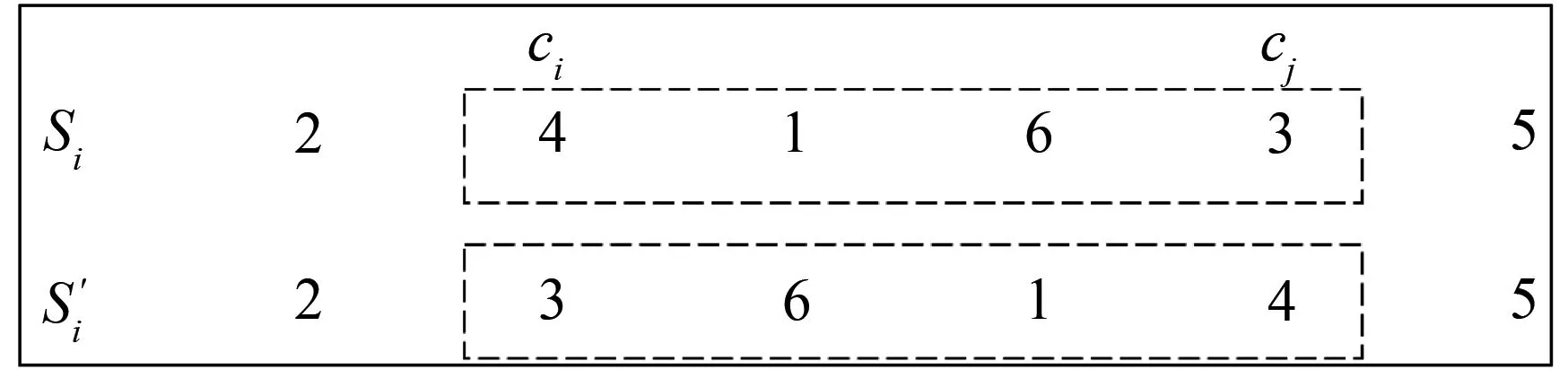
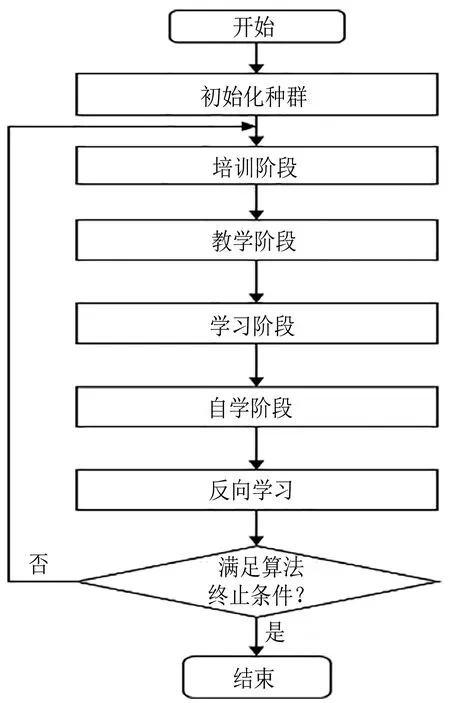
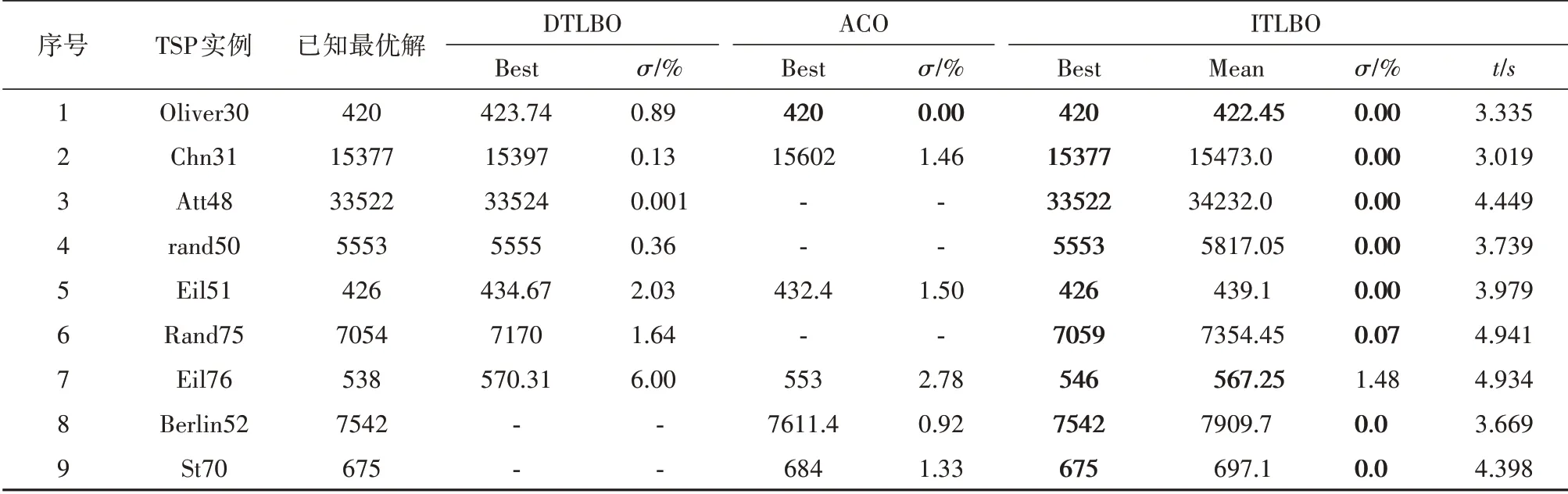
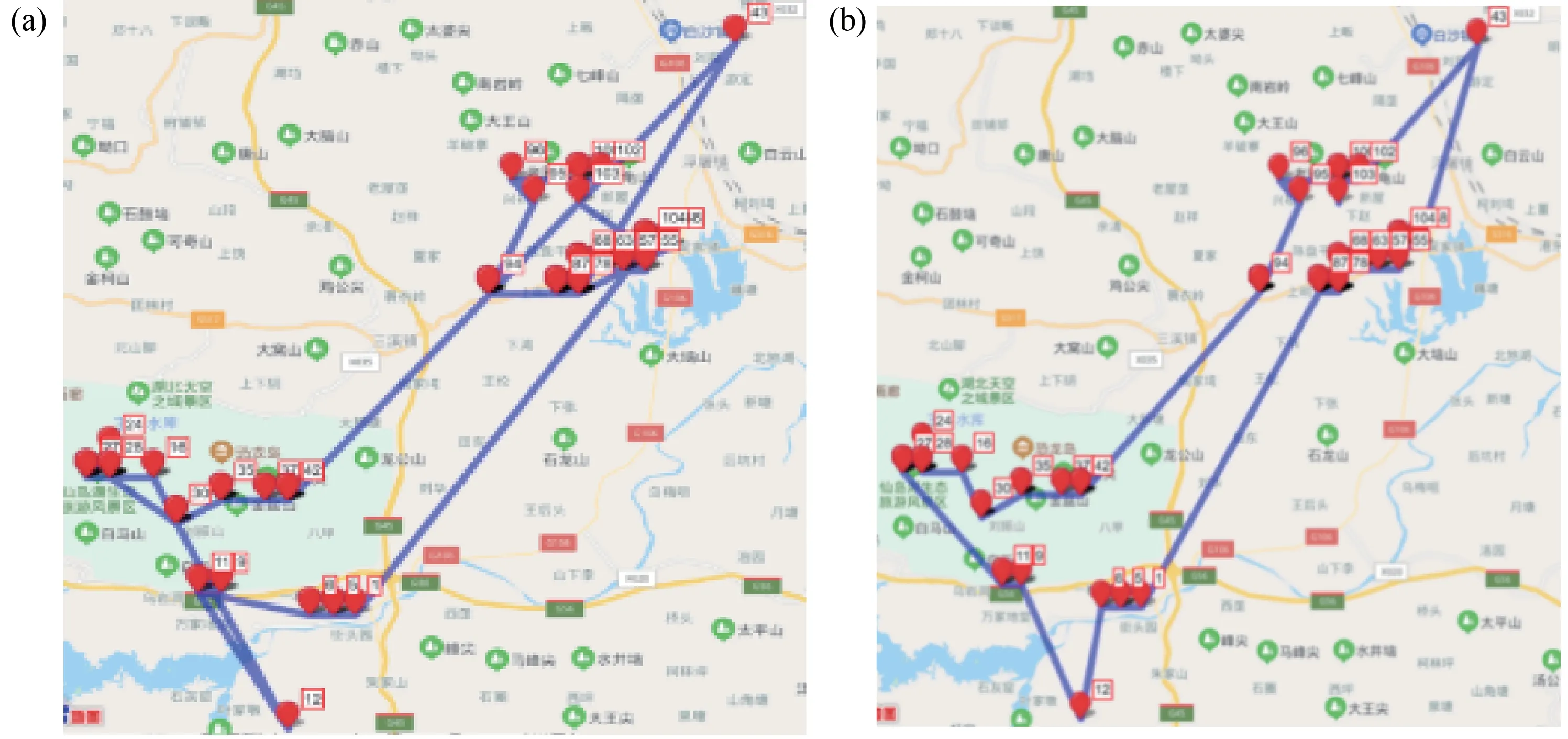
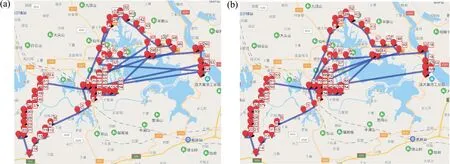
Step3:从Ti中随机选出两个交换城市ci和cj,其中,1 Step4:交换ci和cj处城市产生一个备选解T1i. Step5:分别将ci和cj处的城市与其前后的城市交换,产生四个邻域解T2i,T3i,T4i,T5i. Step6:计算Step3和Step4中产生的5个解的成绩,比较后得到成绩最好的新解Ti′. Step7:比较新解Ti′和原解Ti的成绩,若Ti′成绩优于Ti,用Ti′替换Ti,否则Ti保持不变. Step8:count=count-1,若count≠0,重复执行Step2-Step8,否则转入Step9. Step9:对培训结束的Nt个教师按成绩排序,选出成绩最好的教师Tbest作为下一个阶段的授课教师,并将其禁忌时间Time(Tbest)设置为一个常数T,以限制其在禁忌期再次当选. 上述步骤中,Step3至Step5的具体示例如图1所示. 图1 培训阶段迭代变换示意图Fig.1 Iterative transformation in the training phase 在教学阶段,每位学生通过模仿教师Tbest的结构来实现优化.本算法采用LOX算子实现教学过程,具体步骤如下. Step1:从Ns个学生中选一个学生Si参加教学阶段的学习,并设置计数器count记录未参加教学过程的学生个数,其中,Ns=N-1,count初值为Ns. Step2:在Si中随机选择一段保留序列; Step3:从Tbest中删除Si保留序列内的城市坐标; Step4:将Si保留序列按原位复制到Si′,再将Tbest剩余城市按先后顺序依次插入到Si′的空缺位置. Step5:计算教学前后该学生的路径长度之差ΔC=dis(Si)-dis(Si′). Step6:若ΔC>0,Snewi=Si′.否则,产生随机数r∈[0,1],当满足r≤min{1,exp(-ΔC/t)}时,Snewi=Si′,不满足时,Snewi=Si. Step7:count=count-1,若count≠0重复执行Step1-Step6,否则结束教学阶段. 上述步骤中,Step2至Step4的具体示例如图2. 图2 教学阶段LOX算子示意图Fig.2 LOX operator in the teaching phase 教学阶段中,Step5和Step6为自适应退火机制,其目的在于增加解的多样性,避免算法过早陷入局部最优. 在学习阶段,较差的学生通过模仿较好学生的结构以提高成绩.与教学阶段类似,采用LOX算子,将每个学生与随机选择的其它学生进行交叉,具体过程如下. Step1:从Ns个学生中选出一名参加学习的学生Si,设置计数器count记录未参加学习的学生个数,count初值为Ns. Step2:从其它学生中随机选择另一名学生Sj. Step3:将Si与Sj以类似于图2的方式进行LOX交叉,得到Si′. Step4:执行与教学阶段类似的自适应退火步骤,得到学习后的新解Snewi. Step5:count=count-1,若count≠0重复执行Step1-Step4,否则结束学习阶段. 在自学阶段,学生主动改善自身成绩以实现快速自我优化.本文采用2-opt算子对学生的结构进行调整,具体步骤如下. Step1:从Ns个学生中选择成绩排名前50%的学生参加自学. Step2:对每一个参加自学的学生个体Si,随机选择两个交换城市ci和cj,反转ci和cj及其之间的城市得到Si′. Step3:执行自适应退火步骤,得到新解Snewi. Step4:重复执行Step1-Step3,直到Step1中的所有学生都完成自学. 上述步骤中,Step2具体示例如图3所示. 图3 自学阶段2-opt算子示意图Fig.3 2-opt operator in the self-learning phase 在反向学习阶段,所有禁忌时间不为0的教师,均通过LOX算子向班级中成绩最差的学生反向学生,具体步骤如下. Step1:对Time(Ti)≠0将其与班级成绩最差的学生LOX交叉得到Ti′,并比较Ti′和Ti的成绩.若Ti′成绩大于Ti的成绩,则T newi=Ti′,否则T newi=Ti. Step2:Time(Ti)=Time(Ti)-1 ITLBO算法流程图如图4所示. 图4 ITLBO算法流程图Fig.4 Flow-chart of ITLBO 从两个方面对所提出ITLBO算法的性能进行验证和分析.针对9个TSPLIB标准用例,将ITLBO与未改进前的基本DTLBO算法及ACO算法的计算结果进行比较分析;将算法用于某市烟草物流配送路径优化,为其提供有效的决策指导.本文实验环境为MATLAB2018b,操作系统为Windows10,处理器为主频2.50 GHz,内存4GB内存的Intel(R)Core(TM)i5-7200U. 本节将所提出的ITLBO算法与ACO[17]、DTLBO算法[12]进行比较,以证明改进的必要性和有效性.参数设置与DTLBO保持一致,即:N=100,G=500,对于每一个实例算法均独立运行20次,比较结果见表1. 表1 ITLBO与DTLBO及ACO比较Tab.1 ITLBO compared with DTLBO and ACO 表1中,Best代表最好解,Mean代表算法独立运行20的平均解,σ代表偏差率,t代表平均运行时间.偏差率计算公式为算法所得解与最优解的差值除以最优解.DTLBO和ACO文献中只给出了最优解,ITLBO算法对于每一个实例均统计了最优解、平均解和平均运行时间.分析表1可知,针对表中9个测试样例,ITLBO的最优解均优于DTLBO算法,其中,DTLBO仅在Att48和Chn31测试样例中取得了较好的结果,但对于其它用例,尤其是Rand75,Eil51和Eil76,算法偏差率均在1%以上,意味着没有获得最优解.相反,ITLBO算法除了Eil76偏差率在1%以上,除Rand75接近最优解外,其他测试用例都取得了全局最优解.ACO除了在Oliver30和Berkin52测试样例中较优外,其他用例均差于ITL⁃BO.同时,观察ITLBO算法的平均解可以发现,针对Oliver30和Eil76算例,ITLBO获得的平均解甚至比DTLBO的最优解都好,对Chn31和Eil51其平均解也接近DTLBO的最优解,这说明ITLBO算法稳定性较DTLBO更强. 为了探索算法在实际问题中的应用,以某市烟草公司旺季期间烟草配送为实例,首先,选取一个仓库及其辐射到的104个客户的数据;其次,将仓库即客户位置的经纬度数据转换为距离;然后,采用ITLBO算法求取最优送货路径,并和烟草公司现采用的未优化前的配送路径进行比对;最后,通过百度地图API将配送路径可视化,优化前后的配送路径对比如图5所示.结果分析可知,未优化前该车辆配送完所有顾客的行驶距离为140.46 km,经过ITL⁃BO算法优化后,配送路径为99.81 km,较之前减少了40.65 km,节省了28.94%的距离成本.使用经纬度数据虽不能准确的反映现实中的路径规划,但对经纬坐标相对距离的规划仍对现实中的路径规划具有指导意义. 图5 优化前后配送路径对比图Fig.5 Comparison of distribution routes before and after optimization 实际烟草公司配送系统中,往往不止一辆车,所以多辆车的路径规划显得尤为重要且更为实际,本环节基于新型智能优化算法对前述烟草公司的多车辆烟草配送路径求解,结果如图6所示.本环节求解多车辆路径规划的框架是基于TSP问题,并辅以聚类算法实现,其中车辆路径规划节点由聚类算法对送货客户聚类后获得,之后利用ITLBO算法对配送车辆路径进行优化,未优化前路线较为杂乱,优化后路径更为清晰.计算优化前后路径可得,优化前该公司4辆车总行驶236.47 km,优化后为175.48 km,较之前减少了60.99 km,节省了25.79%的距离成本. 图6 多车辆配送路径优化前后对比图Fig.6 Comparison of multiple vehicle distribution routes before and after optimization TLBO算法是一种新型自然启发式算法,由于其控制参数少且实现简单,已被广泛应用于求解各类连续优化问题.为了使该算法更好的应用于烟草路径规划问题求解,本文基于传统TLBO算法的框架,提出了一种新型的智能优化算法ITLBO.重新定义了一种有效的学生表达方法;教学和学习阶段采用LOX算子离散化学习过程,以提高算法的集中性;加入教师培训阶段,引入迭代变换法提高解的质量;增加学生自学过程,加快算法的收敛速度;采用教师反向学习方式,改善种群的多样性;在教学、学习及自学阶段引入自适应模拟退火机制,有效平衡算法的局部搜索和全局勘探能力. 针对某市烟草公司的单车辆和多车辆烟草配送路径问题,所设计的ITLBO算法求出的优化路径大幅缩短了配送距离,降低了配送成本.未来将结合更多算例对ITLBO进行改进,并开展参数设置对算法性能影响的研究工作,同时,将ITLBO算法应用于求解更多的车辆路径问题,如:带时间窗的送货路径规划等.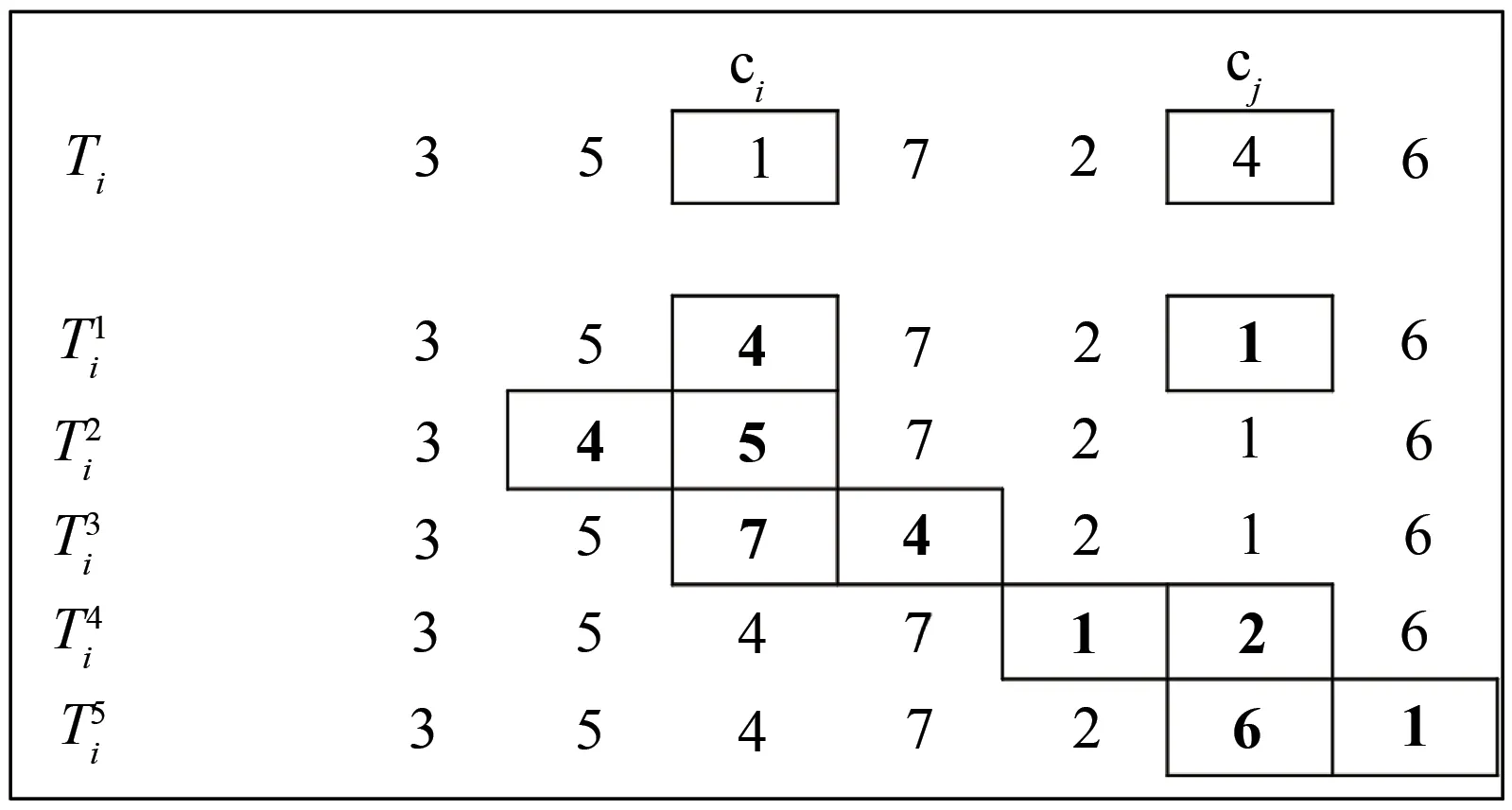
3.3 教学阶段
3.4 学习阶段
3.5 自学阶段
3.6 反向学习阶段
3.7 ITLBO算法流程
4 基于ITLBO算法的烟草物流路径规划
4.1 ITLBO算法与DTLBO及ACO算法比较
4.2 单一车辆烟草配送路径规划
4.3 多车辆烟草配送路径规划
5 结语
猜你喜欢
奥秘(创新大赛)(2023年3期)2023-05-06 01:48:20
科学与社会(2022年1期)2022-04-19 11:38:42
小读者(2021年4期)2021-11-24 10:49:03
甘肃教育(2020年22期)2020-04-13 08:10:52
莫愁(2019年36期)2019-11-13 20:26:16
浙江中西医结合杂志(2017年2期)2017-01-12 18:23:59
快乐语文(2016年7期)2016-11-07 09:43:56
当代化工研究(2016年9期)2016-03-20 16:22:08
营销界(2015年22期)2015-02-28 22:05:18
海峡姐妹(2015年6期)2015-02-27 15:11:19
