
基于知识蒸馏的轻量级人体姿态估计网络设计
2022-01-19 05:08缪宁杰董仲星郑树松王佳敏罗文东
机械设计与制造工程 2021年12期
方 芹,缪宁杰,董仲星,郑树松,王佳敏, 罗文东,周 霖
(1.国网浙江省电力有限公司双创中心,浙江 杭州 310051) (2.国网浙江省电力有限公司杭州供电公司,浙江 杭州 310009) (3.浙江光珀智能科技有限公司,浙江 杭州 311100) (4.杭州致成电子科技有限公司,浙江 杭州 310009) (5.北京大道合创科技有限责任公司,北京 100085)
一般来说,处理高度非线性的任务需要深层次的神经网络,因为深层次的网络模型能够拟合更为复杂的输入与输出之间的关系。密集预测获益于各种深度卷积神经网络的快速发展[1-2],骨干网络提取的特征越好,在后续密集预测时效果也越好。出于这个原因,许多学者通过不断加深骨干网络来获取输入图片高层次特征,然而这会导致模型推理效率低下,需要数十个浮点运算来计算每幅图像。另外,许多学者由于设备资源限制,无法训练这种深层次网络。
知识蒸馏的目的是研究不同神经网络之间的信息传递。Hinton等[3]首先提出了知识蒸馏的概念,通过训练一个大型网络(教师网络)来帮助小型网络(学生网络)训练。其基本原理是首先训练一个深层次的大型神经网络,然后使用教师网络的预测概率分布[3]、中间层的特征表示[4]或者网络的结构信息[5],作为学生网络的额外监督,以辅助学生网络完成自身的训练过程。这一原理最近也被应用于大规模分布式模型的训练过程[6-7],用于多层间或多个训练状态之间的知识传递。此外,知识蒸馏还被用来将容易训练的大网络提炼成更难训练的小网络[8]。
人体姿态估计是密集预测中的一项基本任务,其目的是在一幅图像中定位人的所有关键点(如手腕、手肘等),应用领域十分广泛,可应用于虚拟现实、人机交互、动作检测和自动驾驶等[9-11]。目前的人体姿态估计网络可以分为自顶向下和自下向上两类。
自顶向下:自顶向下的姿态估计网络分为两个阶段。首先用目标估计网络检测出图片中的人,并用包围盒把人框出来。然后对每个包围盒里的人用姿态估计网络估计出对应的姿态。文献[12]提出了深度高分辨网络HRNet,该网络在整个训练过程中保持特征图的分辨率,并在姿态估计任务中得到了较好的结果。文献[13]建议网络同时预测关节点热图和每个关节点与标签的偏差,然后利用偏差校正预测热图得到最终的预测结果。文献[14]用堆叠的沙漏网络与跳跃连接来提高整体性能。文献[15]使用金字塔残差模块来获取多尺度信息。文献[16]提出了一个简单的姿态估计网络,使用转置卷积来得到高分辨率热图。
自下而上:自下而上的网络直接预测图中的所有关节点,然后用算法将关节点组装成不同的人。文献[16]提出了两个分支多阶段的网络,一个用于关节热图预测,一个用于组合关节点。文献[17]使用空洞残差网络直接学习每个关节点的二维偏移向量来对关节点进行分组。文献[18]使用一个局部强度场来定位关节点,使用一个部件关联场来将身体的各个部件组合起来。文献[19]在HRNet的基础上提出了HigherHRNet,通过多分辨率监督的方式训练网络,然后使用文献[20]的网络对检测到的关节点进行分组。
尽管HRNet、HigherHRNet等网络在姿态估计的任务中得到了较高的精度,但它们的参数量十分庞大,以至于训练这些网络需要消耗很大的计算资源。由于知识蒸馏可以把大型网络的知识转移到小型网络中,并且不需要很多的计算资源,因此本文提出了一种基于知识蒸馏的轻量级人体姿态估计网络,以HigherHRNet作为教师网络来指导监督网络。
1 基于知识蒸馏的轻量级人体姿态估计分析
本文提出的基于知识蒸馏的轻量级人体姿态估计网络框架如图1所示,该框架主体由两个HigherHRNet构成:一个预训练好的HigherHRNet作为教师网络;一个简化版的HigherHRNet作为学生网络,学习教师网络中的结构知识和标签信息。
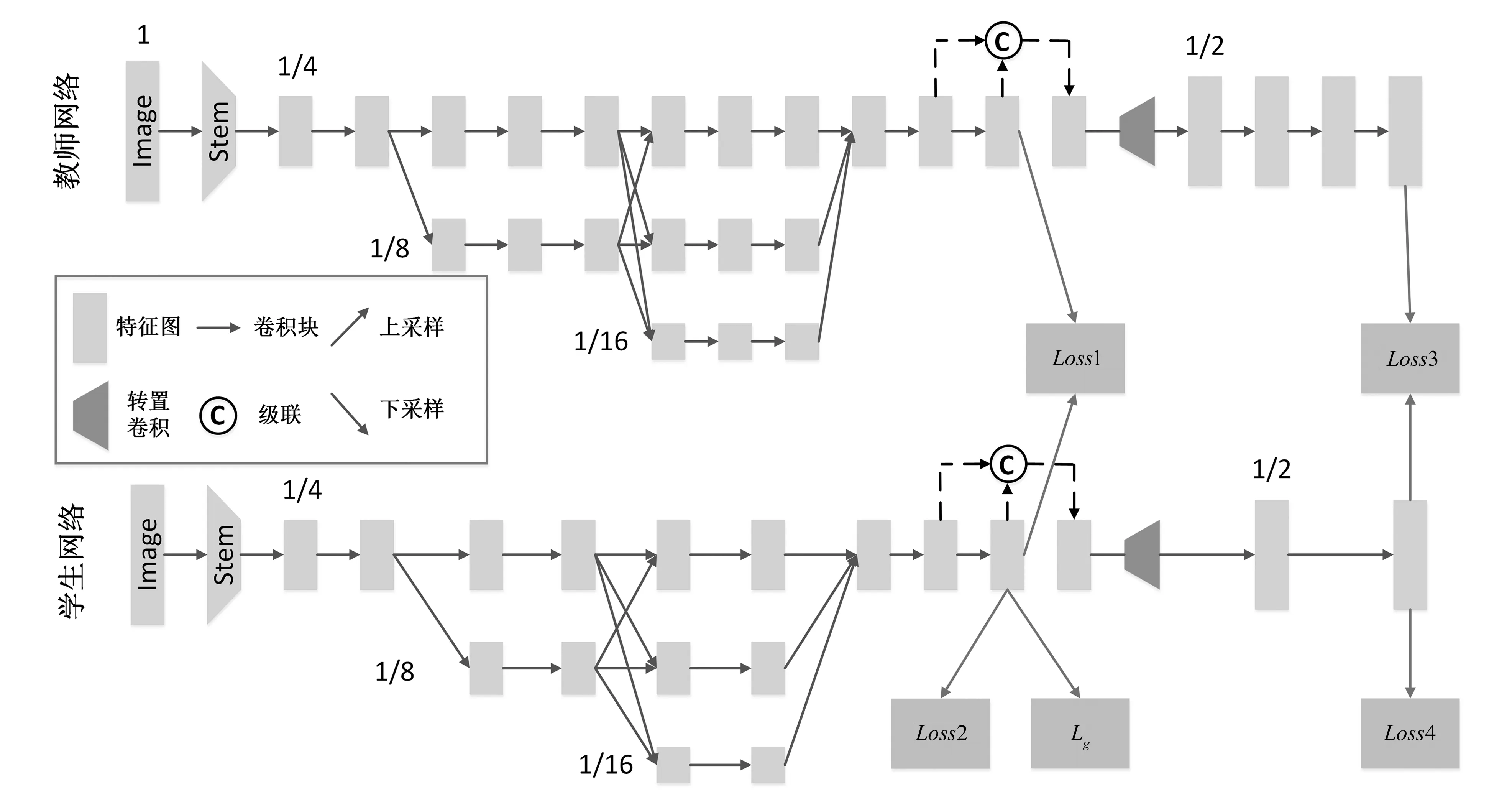
图1 基于知识蒸馏的轻量级人体姿态估计的网络框架流图
1.1 教师网络
HigherHRNet是目前最先进的姿态估计网络[21],该网络具有训练时多分辨率监督、推理时多分辨率融合预测的特点,能够较好地解决自下而上多人姿态估计中尺度变换的问题,并且能够精确定位出关节点。
教师网络的结构如图1的上半部分所示。首先,输入一张图片,以数字1表示图片完整的分辨率,经过Stem,图片的分辨率变为原图的1/4,Stem由两个卷积块和4个残差卷积模块构成。然后,以该分辨率的特征图作为网络的第一分支,从高分辨率到低分辨率,生成多个不同分辨率的分支(图1中有3个分支),并将这些分支并行地连接起来。通过反复地进行多尺度融合,从并行的分辨率特征图中可以学到知识,从而得到鲁棒性强的、丰富的高分辨率。
在得到图片的高分辨率表示之后(分辨率为1/4),HigherHRNet进行了第一阶段的预测,得到预测热图和分组热图。然后,将预测结果和上一步的特征图串联,通过1个转置卷积模块和多个残差卷积块得到第二个预测热图(分辨率为1/2)。最后,使用不同分辨率的关节热图标签来监督训练网络。
1.2 学生网络
人体姿态估计网络通常由多个具有相同结构的块组成,如Hourglass和HigherHRNet。由于在整体结构中部署了大量重复的块,因此现有的设计并不具有成本效益,从而导致了表达能力和计算成本之间的次优权衡。例如:Hourglass由8个沙漏结构堆叠而成,每个阶段结构都有9个残差块;HigherHRNet的每个分支由多个重复的残差块组成。
本文的学生网络采用简化版的教师网络,即简化版的HigherHRNet。学生网络中的残差卷积模块只有教师网络中的一半,因此训练只需要较少的计算资源。
1.3 训练细节
学生网络使用Pytorch进行训练,教师网络使用官网提供的预训练模型[22]。网络使用ADAM优化器,基础学习率为0.001,并分别在200和260个训练周期时降低学习率,一共训练300个周期,批量大小为12。
在图像推理阶段,使用与文献[19]一样的网络,通过多热图联合预测的方式来预测人体的姿态。学生网络预测了两个阶段的关节点热图,由于两个阶段预测热图的分辨率不一致,因此需要先对第一阶段的热图进行采样,然后把它与第二阶段的预测热图融合得到最终的人体姿态预测结果。
1.4 联合损失函数
假定网络的输入图片为X,X∈3×H×W,其中H和W分别代表输入图片的高和宽。教师网络和学生网络经过多分支多分辨率融合模块后,分别得到第一阶段的预测结果MT1和通道数34由前17张关节点热图和后17张分组热图组成。Loss1只使用教师网络的预测关节热图作为学生网络的额外监督,所以定义Loss1为:
(1)
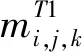
在得到学生网络第一阶段的预测结果MS1后,使用对应的关节标签监督预测结果MS1的前17张预测关节热图,因此定义Loss2为:
(2)
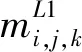
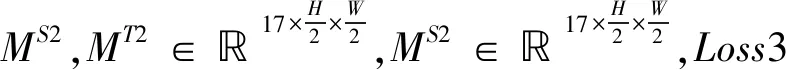
(3)
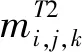
由此,学生网络的最终联合损失Loss定义为:
Loss=α·Loss1+β·Loss2+γ·Loss3+Lg
(4)
式中:α,β,γ分别为对应损失的权重,本文中α和γ设置为1/4,β设置为3/4;Lg为三元组损失,通常取1。
2 实验分析
2.1 数据集
COCO数据集是在复杂的环境干扰下收集得到的,因此要求网络能够在复杂的条件下估计定位出图片中所有人的关节点[23]。该数据集总共包含超过200 000张图像,250 000个带有17个关键点的人。该数据集被分为57 000个训练集、5 000个验证集和20 000个测试集。学生网络在训练集上进行训练,并报告了在验证集上的实验结果。
2.2 评价指标
COCO关键点相似度(object keypoint similarity,OKS),与目标检测中的IoU类似,OKS可以表示预测出来的关节点和标签图片中的关节点的重合程度,其值越接近1越好。
(5)
式中:exp()为指数函数;n为关节点的序号,dn为标注关节点和预测关节点之间的欧氏距离;s为所占面积;kn为第n个关节点的归一化因子,可通过对数据集进行标准差得到,反映了当前关节点对与整体的影响程度。
2.3 实验结果
首先在COCO数据集上对知识蒸馏出来的学生网络进行验证,实验结果见表1。表中:AP0.5为所有图像中人物预测的关键点位置和真实位置的相似性在0.5以上的平均准确率,AP0.75为所有图像中人物预测的关键点位置和真实位置的相似性在0.75以上的平均准确率,AP为AP0.5,AP0.55,AP0.6,AP0.65,AP0.7,AP0.75,AP0.8,AP0.85,AP0.9,AP0.95的平均准确率,APM表示像素面积在[32×32,96×96]的人物预测准确度,APL表示像素面积大于96×96的人物预测准确度。教师网络是一个大型的网络,所以它能够达到较高的精度。未蒸馏的学生网络是指直接使用标签数据进行训练,没有额外使用教师网络的预测特征图监督。基于蒸馏的学生网络即本文所设计的网络,使用标签和教师网络预测的特征图联合监督训练学生网络。可以看到,基于蒸馏的网络比未蒸馏的网络提高了1.3%,这说明教师网络的监督是有作用的。值得注意的是,虽然学生网络的精度比教师网络低了许多,但本文的目的是训练一个简单姿态估计网络,给训练资源不足的学者提供一个有效的蒸馏训练网络,该网络比直接训练学生网络具有更高的精度。另一方面,深层次的神经网络(教师网络)能够较好地处理姿态估计任务,而简化的网络(学生网络)并不能达到教师网络的精度。这也说明了姿态估计是一个高度非线性的任务,使用浅层网络并不能准确地对人体姿态进行预测。
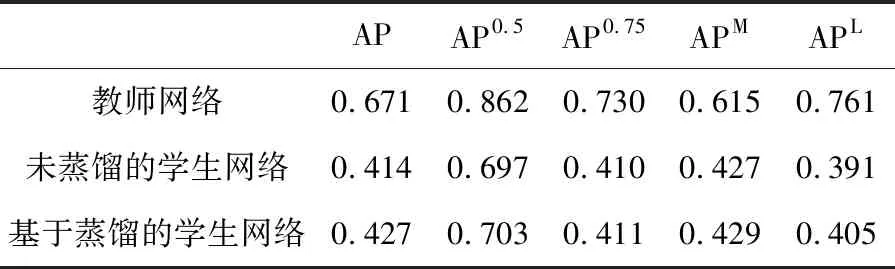
表1 COCO数据集上不同网络精度比较
除了定量分析,本文还进行了定性分析,结果如图2所示。从图中可以看出,教师网络预测的结果最好,未蒸馏的学生网络最差。

图2 预测结果可视化
图3为教师网络和学生网络预测的关节点,第一列为原始图片,第二至第十八列分别预测鼻子、左眼、右眼等。可以看到,深层次的教师网络的预测结果接近标签,而浅层次的学生网络仅能预测图片中一部分关节点。

图3 预测热图可视化
网络模型的参数量是一个十分重要的参数,表2中报告了教师网络和学生网络的模型参数量(Params)和网络需要计算的浮点运算数(giga floating-point operations per second, GFLOPs)。从表中可以看到,由于教师网络是深层次网络,所以它的模型参数量、浮点运算数和推理时间(Inference)都大于学生网络。因此,本文能够在计算资源不足的情况下训练学生网络。

表2 模型参数量、浮点运算数和推理时间
3 结束语
本文提出了一个基于知识蒸馏的轻量级姿态估计网络,该网络由标签和教师网络预测热图联合监督训练得到。通过知识蒸馏的方式训练的学生网络能够比直接训练得到的学生网络得到更高的人体姿态估计精度。此外,本文设计的学生网络是一个较为简单、常见的姿态估计网络,能够帮助学者在计算资源不足的情况下得到较好的姿态估计精度。研究结果表明,使用知识蒸馏得到的学生网络能够较为有效地估计出人体关节点。
猜你喜欢
科学技术创新(2021年19期)2021-07-16
沈阳航空航天大学学报(2020年6期)2021-01-27
学生天地(2020年3期)2020-08-25
汽车观察(2018年9期)2018-10-23
中国自行车(2018年8期)2018-09-26
军营文化天地(2017年6期)2017-06-28
智能系统学报(2017年1期)2017-06-01
摄影之友(2016年12期)2017-02-27
摄影之友(2016年8期)2016-05-14
阅读(中年级)(2009年11期)2009-04-14
