
隧道检测机器人的激光线中心的快速提取
2022-01-18 09:18:18王逸濠赵雪磊魏子哲张晓斌徐永安
机器人技术与应用 2021年4期
王逸濠 赵雪磊 魏子哲 张晓斌 徐永安
(扬州大学,江苏扬州,225009)
0 引言
随着地铁在国民经济中所起的作用越来越大,许多发展中国家都在大力发展地铁交通。在地铁施工、运营过程中,地铁隧道的混凝土预制件结构面的存在对隧道安全有着重要影响,在地铁的建设和运营过程中,为了评估隧道混凝土预制件稳定性和地质灾害防治,需要检测并获取混凝土预制件结构面数量、几何形状等参数。目前,获取地铁隧道混凝土预制件结构面信息以人工现场测量为主导,这种测量方式劳动强度大、检测效率低,难以满足快速测量要求。
在工业产品设计、制造过程中,非接触式表面测量技术应用很多,在数控加工、质量控制与检测等领域起到了至关重要的作用[1-2]。近年,随着非接触测量技术发展取得进展,国内外研究人员在高陡边坡的岩体结构面调查方面,开始尝试摄影测量和激光测量等技术,并取得了一定成果[3-5]。其中,刘昌军等人将该技术拓展应用于隧洞的岩体结构面检测上,取得了一定成果[4]。摄影测量方法需要一定的可见光强度,但是隧道内部往往存在可见光不足的问题。相较于摄影测量而言,激光测量方法不受到可见光的影响,因此在隧洞检测中得到广泛应用。
然而,激光和摄影等非接触测量技术应用在地铁隧道检测中,还存在一定的限制。首先,检测过程存在时间限制,地铁全年的白天一直都在运营,留给检修的时间往往只有3-4小时,检测人员需要在有限的时间内,完成几公里甚至十几公里的隧道检测;其次,需要检测的隧道截面大,目前国内地铁普遍采用的是6m的隧道,盾构机直径为6.3m左右,有些地铁隧道的直径甚至达到8m,单架相机难以覆盖整个隧道截面,为了覆盖整个截面,需要采用十几架甚至几十架相机;最后,检测精度要求高,地铁隧道是外压结构,在外部长时间的巨大压力之下,地铁隧道可能会发生蠕变,往往只有毫米甚至更小的尺度变形,这要求测量精度在该尺度上。
采用嵌入式设备对采集的图像进行预处理,能够满足地铁隧道的检测限制。采用高速相机快速采集图像数据是满足地铁隧道检测限制的一种途径,它既能满足检测精度的要求,也能在要求的测量时间内完成对地铁隧道的检测。在测量过程中,检测车每移动一定的距离,高速相机需要采集一张图像,该距离由测量精度决定,在本次研究中,该距离小于2mm。然而,多架高速相机同时采集图像,要求的数据传输速率远远超过了目前计算机总线能够达到的最高速度。
本次笔者采用嵌入式设备完成图像预处理,将需要传输的数据量降低2个数量级,若采用数据压缩技术,甚至可以将需传输的数据量降低3-4个数量级,从而使得采集的图像数据可以通过网络进行实时传输。针对地铁隧道检测过程中,图像数据传输的难点,笔者提出采用嵌入式设备对采集的图像数据进行预处理,大幅降低需要传输的数据量。
预处理的具体流程和方法如下:
1)首先利用高速相机获取隧道表面的图像数据;
2)采用Canny算法对可能存在激光线的区域进行边缘增强,得到激光线所在位置;
3)在原始图像数据上,根据上一步确定的激光线位置,向两侧分别延拓2-3个像素点,计算激光线的真实位置;
4)将整幅图像中激光线所在位置打包,并上传到上位机。
本文主要研究在激光和摄影测量过程中图像的预处理方法,目的是减少传输的数据量,满足现有环境下数据实时传输的要求。
1 技术原理
地铁隧道一般建在城市的人流量密集的区域,该区域往往建有大量高层建筑,这使得地铁隧道长时间承受巨大的压力,同时由于地铁运行,导致地铁隧道蠕变变形,破坏原有的结构面,产生新的结构面。因此,为达到正确评估地铁隧道的稳定性及防止地质灾害的目的,在地铁运营过程中,每隔一段时间,检测人员需要对隧道进行常规检测,获取地铁隧道结构面的相关信息,为结构面评估提供必要的基础数据。
在本研究中,笔者采用激光和摄影等非接触技术检测隧道的结构面,首先使用高速相机采集包含激光线的图像,接着从图像中提取激光中心线,最后将中心线上各点坐标由图像坐标变换为世界坐标下的坐标,该技术的原理如下。
1.1 激光和摄影检测技术原理
激光和摄影测量原理如图1所示,图中激光测量头由高速工业相机和环形激光器组成。基于小孔成像原理,高速工业相机与环形激光器之间的垂直安装距离满足式(1),

图1 激光测量原理示意图

当进行隧道表面测量时,环形线激光器投射在地铁隧道表面形成一条激光曲线,其包含了隧道表面几何信息。用多架高速工业相机实时拍摄并采集隧道表面激光线图像,该图像将用于计算地铁隧道表面轮廓线上各点在世界坐标系中坐标。
单架相机视觉测量隧道轮廓的模型简要说明如下[2],其中,OWXWYWZW为世界坐标系,OCXCYCZC为相机坐标系,OUxUyU为图像坐标系,PW(XYZ)为世界坐标系中地铁隧道与光平面相交的轮廓线(后文简称为地铁隧道截面)上一点,p(u,v)为图像上的点,中心投影的投影方程式为:


为建立相机图像坐标系OUxUyU与世界坐标系OWXWYWZW之间的联系,需对相机进行标定,求解其内部矩阵A、外部参数R和t。笔者采用整体标定测量技术,调整标定板位置,使标定板平面位于世界坐标系ZW=0的平面上,同时在工业相机拍摄范围内;以标定板平面中心为世界坐标系原点,标定板水平方向为x轴,垂直方向为 y轴,从而计算出标定板各个角点在世界坐标系中坐标
拍摄当前标定板图像,采用亚像素提取算法获取角点在不同相位上的图像坐标。建立标定平面与图像平面之间的投影方程[2,6]:

由激光检测原理可以知道,单次采集只能获取一个隧道截面上各点在世界坐标系下的坐标,整个隧道的检测需要采集大量图像。在检测正在运营的地铁隧道时,受检测时长的限制,需要在有限的时间内完成相关检测。一种可行的办法是在较短的时间内拍摄尽可能多的图像,如采用300-500 Fps的高速CCD工业相机,在较短时间内采集尽可能多的图像,以满足检测精度要求。然而,这也带来新的问题,即在极短的时间内需要将十几架,甚至几十架相机采集的图像及时上传到上位机。这将远远超出现代计算机的总线传输速率。
为了解决这个问题,笔者提出在图像采集端使用嵌入式板卡,采集到包含激光线的图像后,立即提取激光线的中心信息,只保留与后续计算有关的数据。实验结果显示,采用该策略后,传输的数据量降低两个数量级,能够满足数据传输的要求。
1.2 激光线的中心提取
地铁隧道经过长时间运营,在隧道下侧积累了大量灰尘,激光线照射在灰尘上面时,会发生漫反射现象,在采集端图像上,激光线的亮度明显下降,甚至变得不明显。因此,在提取激光线中心之前,需对图像进行边缘增强。笔者采用 Canny 算法对激光线边缘进行增强。
Canny算法边缘检测算法主要有以下几个步骤:
1)图像灰度化(降维处理);
2)高斯滤波(平滑和降噪);
3)计算图像梯度值和方向;
4)应用非极大值抑制NMS;
5)双阈值检测确定边界。
灰度化是一种降维的操作,将三个通道的像素值转换为单通道数据,即将彩色图像转变为灰度图像,达到减少计算量的目的。
1.2.1 高斯滤波
高斯滤波主要使图像变得平滑,减少噪声,但同时也有可能增大边缘的宽度。高斯滤波是取滤波器窗口内的像素的均值作为输出,其系数按照高斯函数离散化。考虑高斯核的大小为(2k+1,2k+1),则点(i,j)处的高斯滤波器的值可由式(5)得到,

1.2.2 计算梯度
所谓图像边缘,指的是灰度值变化较大的像素点的集合,灰度值变化程度和方向可以用梯度表示。将图像看成连续函数均匀采样后的结果,则可以通过前差分计算梯度。
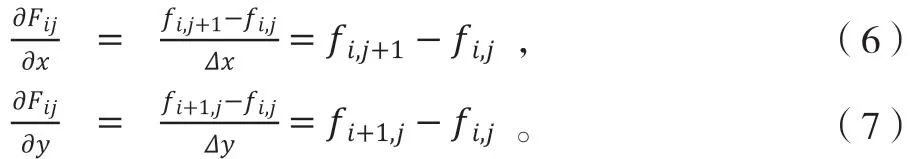
其中,W表示为图像宽度,T为图像高度。相应的,在y方向的梯度可以表示为:

此时,图像坐标(i,j)处像素点的梯度幅值Gij及方向可由下式得到:

1.2.3 非极大值抑制
该步骤过滤掉被误报为边缘的点,最终的边缘宽度尽量为1像素:遍历梯度矩阵,查找边缘方向上具有极大值的点,保留该点,过滤掉其余点(灰度值重置为0)。
由于边缘梯度是局部极大值而非全局极大值,同时在边缘检测中可能存在杂散响应。因此,为消除上述影响,实践中常采用NMS算法。
1.2.4 阈值处理
由于图像采集过程中可能存在某些干扰因素,某些平滑连续的图像可能会出现微小起伏,为消除这方面影响,在实践中常定义两个阈值,一个表示高阈值,一个表示低阈值。若像素点的梯度强度小于低阈值,则不是边缘点;大于高阈值的像素点为强边缘,是边缘点;介于两者之间的像素点则需做进一步检测(弱边缘)。
1.2.5 孤立弱边缘抑制
定义只要邻域像素有一个为强边缘像素点,则该弱边缘就可以保留为强边缘,即真实边缘点。
由于激光的强度往往大于普通光的强度,经过Canny边缘算法计算后,可以较为准确地确定当前图像中激光线的位置。
1.2.6 激光中心线的提取
边缘检测算法给出了激光线可能存在的位置。
在CCD 采集图像上,考虑到激光线的强度在垂直于激光线的方向上满足高斯分布,

根据 Canny 算法检测到的边缘,即激光线可能出现的位置,在原始图像中从该位置上分别向两侧拓展2-3个像素,然后采用式(14)对其进行拟合,计算得到激光中心线真正的位置。
2 并行提取激光中心线
在提取中心线的过程中,耗时最长的是边缘检测的过程,因此,加速边缘检测可以有效提升中心线提取速度。在嵌入式多核处理器上,考虑到在实际检测中使用CCD相机快速采集图像,笔者采用多线程策略,由每个线程处理一幅图像,为加速线程处理图像的速度,使用嵌入式芯片中的 SIMD 指令。
2.1 边缘检测算法的并行
如上边缘检测的算法可知,高斯滤波需要对整幅图像执行卷积运算,是整个算法中耗时最长的计算,故需要采用 SIMD 指令加速卷积计算。
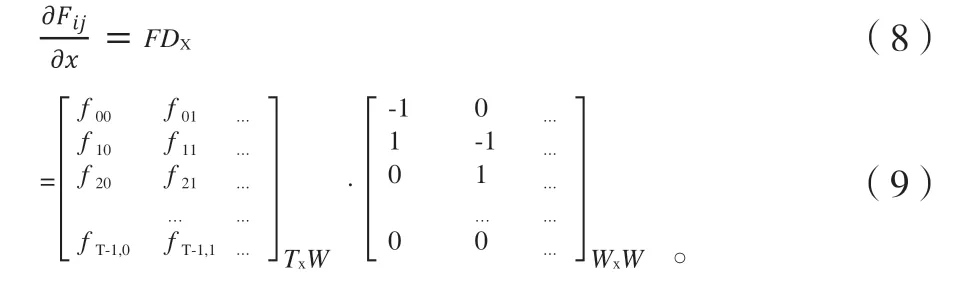
式(15)表示的是卷积运算应用于二维图像数据时的离散形式定义,其中A为输入,W为卷积核。

式(15)中,Fx,Fy分别为卷积核在x,y维度上的核宽度,sx和sy是沿着x和y的步幅,在本次研究中,设定其在x和y方向的步幅均为1。
2.2 卷积运算过程变换
对于式(15)中的计算,可以表示为:

卷积输出0的第i行行向量为0i=(0i,0,0i,1,…,0i,px-1)。其中,Px,Py分别为输出在x,y维度上的宽度。

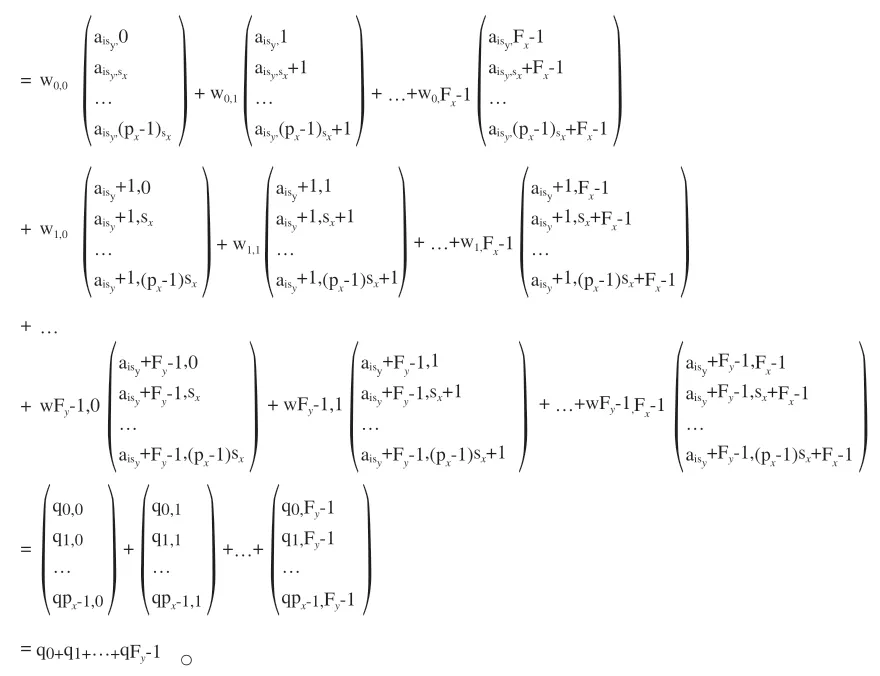
其中,

经过式(16)的变换过程,第i行的输出向量0i被转为 Fy个向量和。
2.3 计算qd的向量化
将式(16)中第d个向量qd展开,易得:
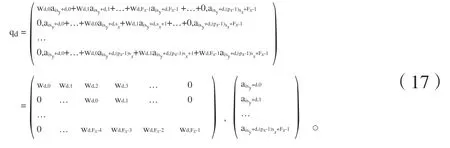
第d个分量qd转变为式(17)中的矩阵向量乘运算,该运算可以通过标准的矩阵向量乘并行[7]。
但是传统的矩阵向量乘并行并没有考虑式(17)计算的特殊性。因此,在现有矩阵向量乘并行算法的基础上,还可以进一步地优化。
由式(17)可知,qd中第j个元素是wd经过0拓展后,与输入向量aisy+d点积。
2.4 基于现代CPU核心的SIMD指令的卷积运算向量化
式(17)中矩阵填充了大量的0,特别当Nx>>Fx时,会导致太多的无效计算,故尽可能减少这类无效计算,快速提升计算性能。
2.4.1 SIMD指令的特点
SIMD指令具有“全局串行,局部并行”的特点,且存在如下数据依赖关系:局部数据空间内无数据依赖;全局数据空间内数据依赖关系满足前向依赖。一旦待处理数据满足上述两个特征中的一个,即可使用SIMD指令。
2.4.2 基于SIMD的运算加速
在计算式(16)中向量qd时,可重复分割行向量,提升运算效率。具体步骤如下。
1)计算向量。
向量wj在x维度的宽度为sx,将划分wj为子向量,子向量长度为sx,不足部分用0元素填充。将子向量重复px次(px为输出向量长度),然后用0填充其首尾,生成的新向量长度与输入数据在x维度的长度一致。具体划分过程如下例所示。
若存在卷积核w,w在x维上的长度Fx=5,w在第j个行向量,sx=2,按上述方式分割wj,将生成3个子向量其首尾分别填充0,生成的新向量的长度与行向量ai的长度一致,它们的长度均为。根据上述生成步骤,可以得到如图2所示的新向量。
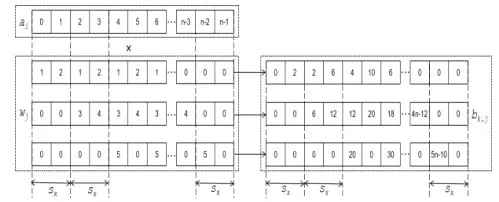
图2 步骤(1)卷积运算转变为向量运算
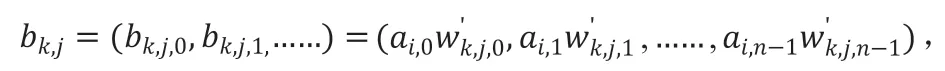
2)归并计算结果。
将 向左移位,第j个中间结果向量向左移 个元素位置;
结果向量:

计算过程如图 3所示。
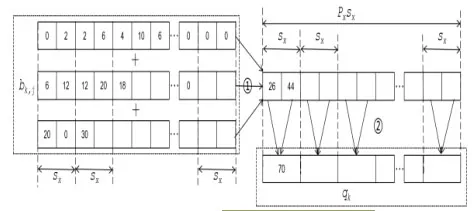
图3 步骤(2)卷积运算转变为向量运算
图2的向量经过移位计算后,生成图3中虚线方框中的中间结果。在实际计算中,只需要计算 中的有效数据长度(前 项)。
算法1为改进的向量乘算法。

算法 1 改进的向量乘算法输入:向量(宽度),第j行卷积核向量(宽度),中间结果向量 ,卷积运算在 维度上步长。输出: 。1.function ImproveVECTOR MULTIPLY(ai,wjqk.Nx,Fx,sx)2.n Fx/sx 3.z 0 //建立一个长度为Nx的临时向量4.Px=(Nx-Fx)/sx+1 5.fort=0 to n-1 do 6.b (wj,tsx,…,wj,(t+1)sx-1,) //不足部分补零7.v (b,b,…,b) //b重复Px次8.v ai×v //此处×表示按对应位置元素相乘9.v v左移t.sx个元素10.z z+v 11.end for 12.z的前PxSx个元素按长度为Sx进行分组,分别计 算各组之和13.u z的分组和 //每个分组和作为u中的一个元素14.qk qk+u 15.end function
改进的向量乘算法存在以下优点:
1)计算相关数据均在寄存器或Cache中,因此计算速度快;
2)算法设计中尽可能消除了局部数据依赖关系,满足SIMD指令的要求,因此能够使用高效的SIMD指令计算向量 ;
3)复用向量ai,提高了数据的复用率,避免从慢速的内存中重复加载;
4)向量ai可以是一整个向量,也可以是该向量的某个子向量,符合SIMD指令的短向量的要求。
2.4.3 基于计算机存储结构的改进
基于对现代计算机采用层次内存的存储结构的考虑,笔者主要考虑两个方面对算法进行改进:寄存器数据复用;优化Cache使用。
1)寄存器数据复用。
二维输入,大小为Nx×Ny,采用式(16)的卷积运算后,得到大小为Px×Py的输出特征0,其关系满足式(18):

为减少内存存取次数,复用向量寄存器中的数据是一个简单的途径:加载输入向量ai;执行所有直接使用ai的计算。由算法1可知,对于输出特征0中第k行向量,由输入向量计算得到。
对于输入向量ai,与多个行向量wj进行计算,其中,wj的下标满足式(19):
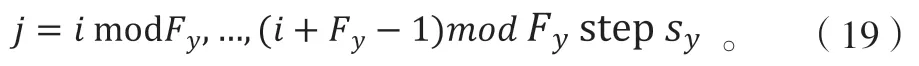
输出向量0k的下标k的取值范围满足式(20):

2)Cache的影响。
Cache是目前解决“内存墙”问题的一种措施。现代计算机处理器频率相较于之前明显提升,处理器频率的提升导致存储系统存储速度和处理器处理速度之间的差异增大。现代计算机采用了Cache、内存、外存三级存储结构(NUMA),尽可能减少“内存墙”对系统性能的影响。然而,这三级存储间存取速度存在很大差异,其中Cache速度是三者之中最快的,与之相对的,其容量是三者之中最小的。
Cache容量与主存容量相差较大,将计算中所有相关数据加载到Cache中是不可行的。因此,笔者采用只加载卷积核W和计算中间结果Q的方法来提高Cache的命中率,同时提升Cache的利用率。
2.4.4 改进算法
结合式(19)和式(20),可以分析得到关于ai的所有运算。因此,当输入数据行向量ai被加载后,可以一次性完成关于该向量的所有运算,具体步骤如算法2所示。

算法 2 计算输入向量产生的所有输出输入: 向量ai(宽度Nx,行号i),卷积核W(在x,y维度上的宽度Fx,Fy),中间结果Q,卷积运算在x,y维度上的步长sx, sy。输出: Q。 1.function Improve VECMATMULTIPL Y(ai,W,Q,Nx,Fy,sx,sy,i)2.lower max images/BZ_43_615_2916_637_2939.png

3.upper min//计算输出的上下界4.fort=lower to upper do 5.q Q中第t个行向量6.u i-t×sy 7.w w中第u个行向量8.Improve VECTOR MULTIPL Y(ai,w,q,Nx,Fx,sx)9.保存q至Q中第t行10.end for 11.end function
当循环次数较少时,可以将算法2中的循环进行展开,该算法存在以下优点:
1)向量ai加载之后,一次参与多个计算,可以避免从慢速内存中多次加载数据,提高向量寄存器的复用率,提升CPU的计算效率;
2)由于只需要加载一次向量ai,避免了Cache对计算数据的频繁调度,提高了Cache的利用率;
3)对向量ai的长度没有限制。因此可以将长向量划分为多个短向量进行运算。笔者将向量ai分成多次加载,满足SIMD指令的短向量的特点。
二维输入数据的卷积运算如算法 3所示。

算法 3 改进的卷积运算输入: 输入A(在 x, y 维度上的宽度 Nx, Ny),卷积核 W(在x, y 维度上的宽度 Fx, Fy),卷积结果 O,卷积运算在x, y维度上的步长 sx, sy。输出:卷积结果0。1.function Improve CONVOLUATIONMULTIPL Y(A,W,O,Nx,Ny,Fx,Fy,sx,sy)2.计算A中需要计算的行数,将结果保存在d中3.for i=0 to d do 4.ai A中第i行向量 //ai直接从内存加载到寄存器,不进入Cache 5.ImproveVECMATMULTIPLY(ai,W,O,Nx,Fx,Fy,sx,sy,i)6.end for 7.end function
3 实验结果与分析
笔者直接使用快速CCD采集数据,计算环境采用RK3399芯片,评估基准为串行Canny算法,编程语言为C++和ARM汇编语言。
在计算提取激光中心线加速比时,笔者在实验中验证了以下两种情况:
基于SIMD指令并考虑寄存器复用;基于SIMD指令但不考虑寄存器复用。基于SIMD指令的CNN训练的加速比结果如图 4所示 。
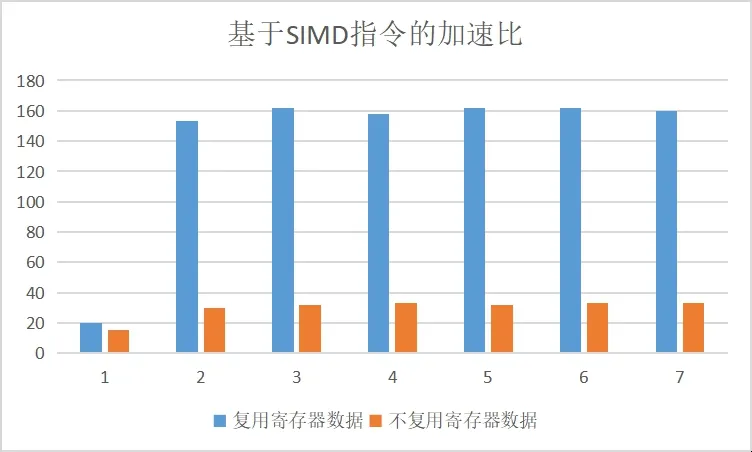
图4 基于SIMD的激光中心线提取的加速比
图4中,纵轴为加速比,横轴为处理的图像数据,分别 为(100、500、1000、5000、10000、50000和100000幅图像)。
由图4可知,不考虑寄存器复用的算法加速比显著低于寄存器复用的激光中心线的提取算法。这是因为在寄存器复用的情况下,计算相关数据被从内存加载到寄存器,并不进入Cache。Cache只用于保存局部中间结果和卷积核,通过提高Cache命中率提高了加速比。而不考虑寄存器复用的情况下,局部输入数据、局部中间结果和卷积核均会被加载到Cache中,而由于Cache容量较小,这些数据量远远超出 Cache自身的存储容量,导致Cache中的数据被频繁调度,计算效率明显下降。
4 结论
本文采用SIMD指令,实现高速提取激光中心线。结果显示,采用SIMD指令是完全可行的,并取得了很好的效果,在满足高速相机采集图像的同时,满足实时提取中心线的要求,有效降低了需要传输的数据量,故使得采用多架高速CCD采集图像成为可能。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2022年1期)2022-04-26 14:09:30
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
数学小灵通(1-2年级)(2020年6期)2020-06-24 05:57:54
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
中学生数理化·八年级数学人教版(2017年2期)2017-03-25 16:12:51
中学生数理化·七年级数学人教版(2016年9期)2016-12-07 08:18:09
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
