
融合注意力机制与双向长短时记忆网络的基于语音分析的抑郁识别方法
2022-01-18 02:00汪静莹耿馨佚朱廷劭王守岩
复旦学报(自然科学版) 2021年6期
赵 张,汪静莹,耿馨佚,朱廷劭,王守岩
(1. 复旦大学 类脑智能科学与技术研究院,上海 200433; 2. 复旦大学 计算神经科学与类脑智能教育部重点实验室,上海 200433; 3. 复旦大学 上海智能机器人工程技术研究中心,上海 200433; 4. 复旦大学 智能机器人教育部工程研究中心,上海 200433; 5. 中国科学院 心理研究所,北京 100101)
抑郁症是一种在世界范围内常见的精神疾病,全球患者人数超过2.64亿[1].抑郁症不同于通常的情绪波动,当情况比较严重并且持续时间长时会造成严重的健康问题,让患者在工作生活中承受巨大痛苦甚至无法工作,在最坏的情况下会导致患者自杀.
目前,抑郁症的评估方法主要依赖于患者的主观报告和医生的临床评分.这些方法需要患者准确地描述疾病,并且要求医生具有丰富的临床经验.为了帮助临床医生更准确地判断患者的病情,研究人员试图找寻一种客观有效的评估方法.语音是除表情之外情绪的另一种重要的外部表现,加之其方便获取,因此使其成为一种备受期待的评估手段[2].
过去基于语音识别抑郁的研究还有若干值得改进的地方.
首先,特征的特异性.随着人们对语音和抑郁之间关系研究的深入,越来越多的特征如韵律特征、频域特征等皆被用于建模识别抑郁.但这些特征并非专门针对抑郁设计的,不能完全反映声音中与抑郁相关的信息,建模识别效果有限,因此如何从语音中提取能够有效反映抑郁的特征尤为关键.近年来,深度学习在语音识别领域取得了突破性的进展[3],其中长短时记忆(Long Short-Term Memory, LSTM)网络通过“门”的概念建立了基于时间序列的长期联合记忆机制,避免了产生梯度消失现象,具备长时记忆的能力[4],神经网络的瓶颈层向量可用于表征抑郁相关的高维信息.
其次,权重系数.过去的研究对一段语音每个部分都给予相同的权重,但在实际中部分语音片段能集中地反应抑郁相关的信息.注意力机制[5]是一系列权重参数,对于一段语音并不是从头到尾每个部分都保持同样的关注度,而是通过自动学习的方式重点观察语音的某一些片段.最后,训练样本与测试样本的数据分布存在差异.不同语音之间的特征差异受到被试本人发声特点的影响,迁移学习[6]的方法则可以减小训练样本和测试样本之间数据分布差异对模型造成的影响.
据此,本文提出一种融合注意力机制与双向长短时记忆网络的卷积神经网络(Convolutional Neural Network, CNN)来提取深度学习特征,通过高维度的特征定义与选择结合迁移学习的方法来提升该算法基于语音分析的抑郁状态辨识的能力,并在抑郁症患者和健康被试者数据集上验证了该方法的效果.
1 语音分析抑郁识别方法介绍
基于语音分析的抑郁状态分类辨识算法的流程如图1所示,主要包括预处理、特征提取、特征选择、迁移学习、分类5个关键步骤.

图1 基于语音分析的抑郁识别方法的流程图Fig.1 Flow chart of depression recognition method based on acoustical signal processing
1.1 数据预处理
为避免低频噪音的干扰,采用截止频率为137.8 Hz的2阶巴特沃斯滤波器进行高通滤波.另外语音信号原始采样频率为44 100 Hz,为控制文件大小以方便未来对语音的流程化处理,采用librosa[7]将信号降采样到最常用的16 000 Hz.最后通过Pyaudioanalysis[8]对每份语音去除长时间的静音段(非语音片段),提取有声片段后合并成一个数据段.
1.2 特征提取
本文提取的特征包括6类: 声学特征、频域特征、停顿特征、Mel频率倒谱系数(Mel-Frequency Cepstrum Coefficient, MFCC)[9]特征、色度特征和深度学习特征.其中,前5类特征是常用的语音信号不同方面性质的特征,深度学习特征则是本文自主提出的针对语音分析的新特征.
1.2.1 常用语音特征的提取
声学特征包括基频、能量和过零率相关特征,共6个,其中能量特征包括声强和声强包络,过零率相关特征包括过零率、过零幅度(即两个过零点间信号的最大幅值)和过零间隔(即两个过零点间的时间间隔);频域特征包括频谱中心、频谱延展度、频谱通量、谱熵和频谱滚降点,共5个;MFCC特征将人耳的听觉感知特性和语音信号产生机制有效结合,共13个;色度[10]特征代表一段时间内12个音级中的能量,不同八度的同一音级能量累加,共12个;将原始语音中开头和结尾以外的静音段视作停顿片段,停顿相关的特征在数据预处理时提取,包括停顿次数、停顿比(停顿片段总时长/语音片段总时长)和平均停顿比(停顿片段平均时长/语音片段总时长)3个.
对于声学特征、频域特征、Mel频率倒谱系数特征和色度特征,采用提取特征统计量的方法来获取能够反映语音整体变化的特征信息.
选择不同的窗长和滑动步长会对特征提取的结果造成影响,为了获取能够反映语音整体变化的长时特征,采用提取特征统计量的方法来获取整体而非局部的特征信息.使用的12个统计量分别是: 最大值、最小值、极差、均值、中位数、线性回归的截距(时间作为自变量)、线性回归的系数(时间作为自变量)、线性回归的R2(时间作为自变量)、标准偏差、偏度、峰度和变异系数.
因此,本文提取的常用语音特征共有12×{6(声学)+5(频域)+12(色度)+13(MFCC)}+3(停顿相关)=435个.
1.2.2 深度学习特征的提取
深度学习技术在语音信号处理领域取得了良好的成果,它可以学习生成高级语音信息,丰富手工设计特征.本文设计的抑郁检测语音网络(Depression Detection Audio Net, DD-AudioNet)由卷积神经网络融合注意力机制与双向长短时记忆神经网络(Attention-Bi-LSTM)组成.如图2所示,DD-AudioNet将语音信号通过短时傅里叶变换映射到时频图作为神经网络的输入,水平轴代表时间,垂直轴代表频率,以语音对应的被试是否抑郁(0或1)作为标签训练神经网络,提取神经网络的瓶颈层特征作为深度学习的特征.

图2 抑郁检测语音网络Fig.2 Depression detection audionet
单向LSTM只利用到前向信息,而双向LSTM可以融合前向和后向语义信息.在卷积神经网络模式识别中,输入图像和卷积核都是2维的,而语音信号是1维的.为充分利用卷积的优势,采用短时傅里叶变换将语音映射到时频域.神经网络的输入维度必须一致否则无法训练,然而收集到的语音在时间上无法保证一致等长.因此将一段语音切分为以2 s为一个小段的多段,每2 s的小段经过短时傅里叶变换得到时频矩阵,放入网络中进行训练,对应的标签即表示所属被试是否抑郁.若语音时长不是2 s的整数倍,则去掉语音开头多余的时间,如一段5.4 s的语音去掉开头的1.4 s,剩余4 s以2 s为一个单位划分为两段,然后将这两段语音放入神经网络中进行训练.每个2 s的单位片段都会输出一个瓶颈层特征,所以每段语音可以得到若干个神经网络提取的瓶颈层特征.因此,语音无论被分为几个小片段都在瓶颈层维度上求平均值,由此保证不等长的语音片段得到的深度学习特征维度的一致性.本文所用的DD-AudioNet的损失函数设置为交叉熵,使用Adam优化器训练网络.LSTM的单元维度设置为64,双向LSTM的输出层是128维的向量.因此,本文提取的深度学习特征共有128个.
注意力机制结构如图3所示.将Bi-LSTM的输出通过一层的多层感知机得到ut,作为ht的隐式表达,之后用ut与整个语音段的矢量uω的相似性来衡量每一片段的重要性.然后通过一个Softmax函数得到标准化后的权重系数αt,最后语音矢量s经过ht加权求和得到.语音矢量s可以被视为一段语音的高维特征表示,类似于自然语音处理任务中对一段query经过循环神经网络提取到的特征.uω是通过训练学习得到的最终参数,初始时是随机的矢量.且

图3 注意力机制结构的示意图Fig.3 Schematic diagram of the structure of attention mechanism
其中:Wω,bω是随机初始化的可训练参数,会随着训练不断更新.
1.3 特征选择
Lasso[11]是一种基于一范式的特征选择方法,通过对系数的压缩舍弃系数低于阈值的变量,然后保留剩下的变量作为有效特征.本文的目标是分类任务,所以采用特征选择模型的本质是Lasso-Logistic回归[12],在Logistic回归模型参数固定的基础上比较不同的Lasso参数,根据最优的准确率确定参数[13].在本文所有实验中,模型惩罚系数λ设置为0.005,Lasso不仅能够准确地选择出与类标签强相关的变量,同时还具有特征选择的稳定性.
1.4 迁移学习
在分类算法中,为保证模型的准确性和鲁棒性,都假设训练样本与测试样本满足独立同分布的条件,但实际中这个条件往往无法满足.迁移学习的目的是通过迁移已有的知识来解决训练样本与测试样本分布不一致的问题[14].采用无监督的源适应迁移方法CORAL(Correlation Alignment)[15],通过对齐训练集特征和测试集特征之间的2阶协方差矩阵信息,拉近训练样本与测试样本的数据分布.CORAL算法的具体描述如下:
输入: 训练集特征DS为Ns×Nfeature的矩阵;测试集特征DT为NT×Nfeature的矩阵;训练集样本数Ns;测试集样本数NT;特征维度Nfeature
CS=cov(DS)+eye(size(DS,2))size(DS,2)为Nfeature矩阵的列数;eye(n)为n×n的单位矩阵;cov为协方差矩阵;CS为中间变量
CT=cov(DT)+eye(size(DT,2))CT为中间变量


1.5 分类模型
1.5.1 分类器
本文使用的分类模型包括逻辑回归、随机森林和XgBoost 3种.逻辑回归是一种广义线性模型,假设因变量y服从伯努利分布,是一种解决二分类问题常见的机器学习算法.高翔[29]的研究表明集成学习模型可以提升其分类效果,因此本文也采用随机森林、XgBoost这两种以二叉树为基分类器的集成学习算法.随机森林属于聚集类方法,通过加入属性扰动降低方差来提高性能,而XgBoost属于提升类方法,通过降低偏差来提升性能.
1.5.2 模型评价指标
模型所得分类结果的混淆矩阵如表1所示.用kTP表示事实为抑郁被试的语音被正确识别的数量;用kFP表示事实为正常被试的语音被错误识别为抑郁被试的数量;用kTN表示事实为正常被试的语音被正确识别的数量;用kFN表示事实为抑郁被试的语音被错误识别为正常被试的数量.

表1 分类结果的混淆矩阵Tab.1 The confusion matrix of classification result
本文采用的评价指标包括准确率λACC、F1分数F1和AUC(Area under curve)值SAUC.定义
2 抑郁语音识别实验
2.1 实验过程
语音数据采集自112名抑郁患者和69名健康被试,抑郁组和健康组之间的年龄和性别均无统计学意义上的差异.所有被试排除物质滥用、物质依赖、人格障碍等其他精神疾病,无严重的躯体疾病或自杀行为.本研究的语音任务“模拟访谈”,包括正、中、负3种诱发情绪.任务中,被试需要对不同的问题进行回答,从而获得语音数据.每名被试对每个问题的回答都会单独生成一段语音数据.模拟访谈任务的3种情绪条件下各有3道相同情绪效价的问题,因此每个被试产生9条语音片段,本研究一共采集181×9=1 629条语音片段.
从抑郁被试和健康被试中各随机抽取25人,共50人的语音片段作为测试集,其他131名被试的语音片段作为训练集.对于时长不足2 s的语音片段由于其信息量不足而不予采用,最终得到400个语音片段作为测试集,1 060个语音片段作为训练集,其中训练集和测试集中的语音片段来自于不同的被试.
2.2 实验结果
表2展示的是根据不同特征集分别建模的结果.无论哪种分类方法,深度学习特征的结果普遍优于其他类特征,其最高的准确率、F1分数、AUC分别为0.833、0.808、0.881.其他特征中表现较好的Mel频率倒谱系数和声学特征的准确率可以达到0.7以上.上述结果说明利用DD-AudioNet提取的深度学习特征相比其他特征有更好的效果.

表2 不同方法对6类特征的分类结果Tab.2 Classification results of six types of features by different methods
在比较6类特征分别建模的效果之外,将6类特征进行不同组合以比较不同组合的分布结果.特征组合包括3种: 1) 全特征组,通过Lasso对6类共563个特征进行特征选择后得到26个特征;2) 非深组,通过Lasso对深度学习特征以外的5类共435个特征进行特征选择后得到17个特征;3) 独立特征组,对6类特征分别进行特征选择,选择各类特征数目,如表2所示,再合并共得到77个特征.图4(见第738页)展示了3种特征组合的特征分布情况,深度学习特征在全特征组中的占比达到了84.6%,远高于其他各类特征之和.表3(见第738页)为3种特征组合的分类结果,发现当特征组合中有深度学习特征时准确率就能超过0.8,而特征组合中没有深度学习特征时准确率不及0.7.全特征组表现最佳,其最高的准确率、F1分数和AUC值分别为0.840、0.815和0.885.
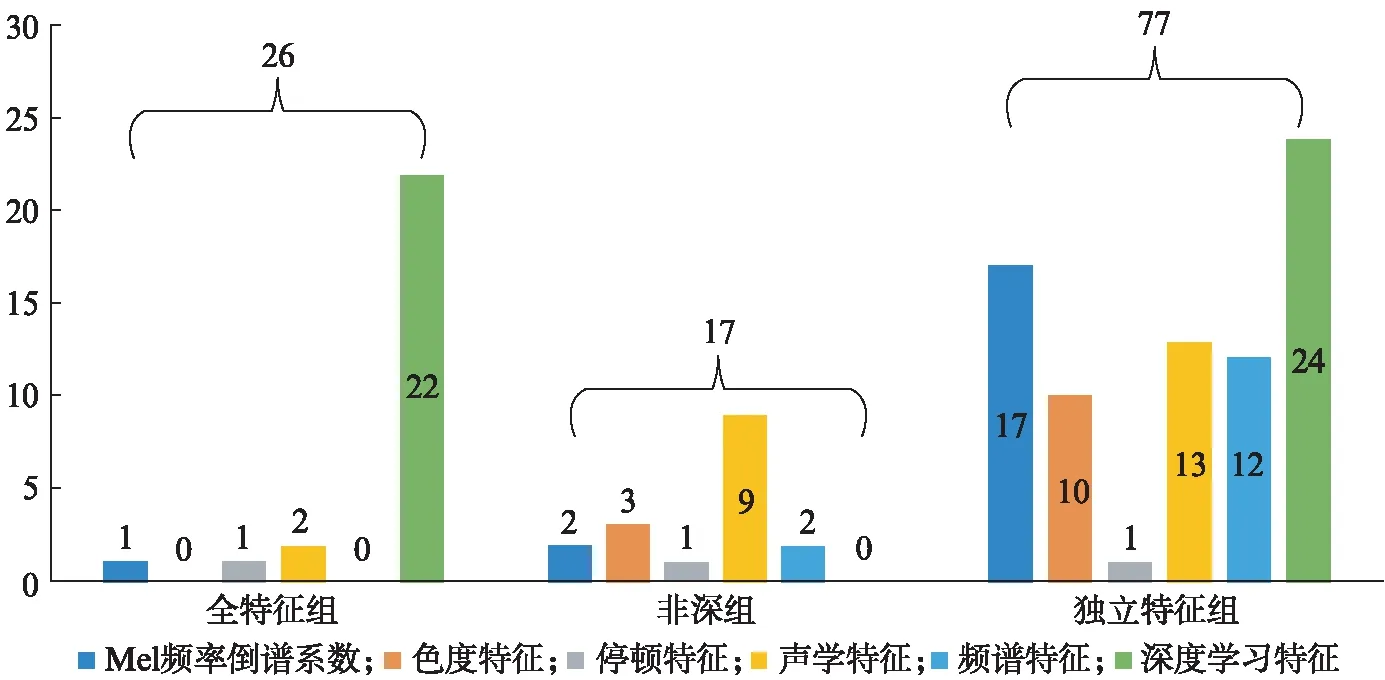
图4 特征组合特征的分布图Fig.4 Distribution of combined feature sets

表3 不同方法对特征组的分类结果
3 结 语
本文设计了一种用于抑郁识别的融合注意力机制与双向长短时记忆网络的算法.该算法的特点在于从网络结构中提取瓶颈层向量作为深度学习特征,并引入迁移学习来降低训练集和测试集数据分布差异带来的影响.经实验验证该算法在中文数据集上取得了较以往算法更好的预测效果.通过比较深度学习特征和常用的5类语音特征的预测效果,发现深度学习特征的识别效果最佳.特征组合的结果发现,特征选择后的特征集中保留的深度学习特征所占比例显著高于其他特征,说明其可能包涵更多抑郁的信息.进一步的分类结果也显示包含更多深度学习特征的特征组合的识别结果更佳.通过非侵入、易采集的信息去识别抑郁是实现抑郁快速筛查的基础,未来可尝试将本研究的算法应用于临床,实践其在真实就诊环境中的检测效果.
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年9期)2019-05-30
电子制作(2019年24期)2019-02-23
电子制作(2019年24期)2019-02-23
小说界(2018年5期)2018-11-26
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
