
一种基于Azure Kinect的目标跟踪定位方法*
2022-01-17 09:19:16张啸天瞿畅刘苏苏张小萍张文波
传感技术学报 2021年11期
张啸天瞿 畅刘苏苏张小萍张文波
(南通大学机械工程学院,江苏 南通 226019)
Kinect是微软推出的3D体感摄像机,具有彩色相机和深度传感器,能够以较高的帧率同时获取彩色(RGB)、红外(IR)和深度图像,由于其低廉的价格和强大的功能,许多研究者将其应用到机器人、医疗康复、安保监控、智能交互等领域[1-2]。由于Kinect可获取物体的深度信息,其在目标跟踪领域也表现出了独特的优势。
Tomasz等人[3]利用Kinect传感器,通过预先标记颜色来识别目标,能够实现基于颜色的三维目标跟踪。Gulalkari等人[4]设计了一种基于Kinect的六足机器人目标跟踪系统,通过三角法和Kinect深度数据识别和定位特定的蓝色目标物。Jurado等人[5]利用Kinect提供的颜色和深度信息,基于HSV颜色模型识别跟踪目标,提出了一种三维空间目标跟踪方法。Jaramillo等人[6]基于Kinect提出了一种新的基于描述符的目标跟踪方法,并基于时间序列和深度信息对目标进行预测,能够解决目标被遮挡的问题。Sergio等人[7]通过Kinect采集点云数据,结合神经网络跟踪三维物体的运动,能够完成对象分割、表示、运动分析和跟踪等多种任务。Liu等人[8]结合Kinect开发了羽毛球机器人,基于图像特征向量和深度信息对羽毛球进行跟踪定位,预测羽毛球的落点,并通过机器人完成击球任务。谭艳等人[9]使用Kinect获取RGB图像,利用Camshift算法跟踪目标物体,能够在目标和背景空间存在一定差异时实时跟踪目标物体,并获取其三维坐标。万琴等人[10]利用Kinect提供的RGB图像和深度信息分别建立了目标颜色模型和三维空间模型,并通过马氏距离(Mahalanobis)算法实现了多目标实时跟踪。
上述采用Kinect的目标跟踪方法大多基于颜色特征,这种跟踪方法需要预先标记跟踪目标,操作不便,当目标物和背景颜色相似时,易受相似颜色干扰,跟踪效果不理想。为此,本文提出了一种基于Azure Kinect的目标跟踪方法。在建立目标物“颜色-形状”模型的基础上,基于深度方差实现了目标物与背景的分割,通过形状偏差率和直方图巴氏距离完成了目标物识别,并设计了单摆实验,验证了该方法对于相似颜色背景具有较强的抗干扰能力。
1 目标物提取
针对目前基于颜色的跟踪算法需要人工预先标记跟踪目标的问题,本文运用点云对跟踪目标进行提取,通过坐标映射,实现点云到深度图和彩色图的转换,快速提取跟踪目标。
1.1 目标物三维点云分割与提取
Azure Kinect是继微软推出Kinect V1、Kinect V2后,专门针对开发者推出的最新一代Kinect产品,它由深度传感器,RGB摄像头,7麦克风阵列,加速计和陀螺仪(IMU),以及可同步多个Kinect设备的外部同步引脚组成[11],其RGB摄像头最高分辨率可达3 840×2 140,红外摄像头的最高分辨率为1 024×1 024。相较于一、二代产品,Azure Kinect在宽视场角(WFOV)模式下,可以提供0.25 m~2.88的深度数据;在窄视场角(NFOV)模式下,可以提供0.5 m~5.46 m的深度数据。由于Azure Kinect在窄视场角模式下,一部分RGB图像没有深度数据,本文设置Azure Kinect深度传感器为WFOV模式,以红外相机分辨率为512×512,RGB相机分辨率为1 920×1 080,以30 frame/s的速度采集图像。以待跟踪目标置于桌面为例,通过Azure Kinect采集的三维点云如图1所示。
由于Azure Kinect采集的点云数据中存在大量无效背景数据,不利于后续的平面分割与目标提取。为此,首先利用直通滤波法(PTF)对初始点云进行预处理,通过测量桌面到相机的距离,在Azure Kinect深度传感器坐标系下(如图1所示)分别设置X、Y、Z三个方向的阈值区间[x1,x2]、[y1,y2]、[z1,z2],确定桌面及桌面上的目标物在初始点云中的三维空间包围盒,剔除阈值区间外的无效点云,保留桌面及桌面内物体点云。

图1 Azure Kinect及采集的点云
随后采用随机采样一致算法(RANSAC)识别点云中的平面特征,分离出工作平面,再对桌面上的点云进行欧式聚类,去除内点数量少于阈值的聚类,最终提取目标物点云。
1.2 目标物点云映射
为了能够基于彩色和深度图像对目标物进行跟踪,需要将目标物点云映射到二维图像上,便于进一步地提取目标特征。通过读取Azure Kinect内、外参,可以对点云、深度图和彩色图中的任意点进行转换[12]。首先,在深度传感器坐标系下将目标物点云中的三维点P ir=[X i rY irZ ir]T转换到深度图中的对应点Q i r=[uv1]T,转换公式如下:

其次将深度传感器坐标系下的三维点Q ir转换为彩色相机坐标系下的三维点Prgb=[XrgbYrgbZrgb]T,最后转换为彩色图对应点Qrgb=[mn1]T,完成点云到彩色图的映射,如式(2)所示。

式中:R为3×3的旋转矩阵,T为3×1的平移矩阵,为彩色相机内参。
点云映射结果如图2所示,点云映射区域即为目标物在二维图像中的位置,将该区域从未处理过的二维图像中分割出来,并在后续的步骤中建立目标跟踪模型。

图2 目标物点云映射
2 目标物“颜色-形状”模型建立
颜色阈值区间和颜色直方图是在基于颜色的目标跟踪中常使用的两种方法,但它们都容易受相似颜色干扰。为了准确地对目标物进行描述,本文将颜色和形状结合,建立了融合深度的目标物“颜色-形状”模型。
2.1 HSV颜色模型
HSV颜色空间通过色度(H)、饱和度(S)、亮度(V)来描述图像中像素的颜色特性,当物体颜色受到亮度变化等因素影响而改变时,S和V会产生波动,而H分量的变化很小,因此在HSV颜色空间下计算目标物颜色阈值区间和颜色直方图,可以准确地提取目标的颜色信息。
由于Azure Kinect使用了RGB颜色空间,首先将图像从RGB颜色空间转换到HSV颜色空间,如式(3)所示。

式中:H∈[0°,360°),S∈(0,1),V∈(0,1)。
为了更准确地在HSV颜色空间确定颜色阈值区间,本文基于二分法进行两次迭代,对由点云分割出的目标物(如图3(a)所示)进一步的过滤,以消除点云映射过程中的偏差。具体方法如下:
Step 1 将目标物彩色图转换至HSV颜色空间下,并提取其H通道下的灰度图像;
Step 2 遍历图像中的非0像素点,记录图像中最大灰度值Hmax,最小灰度值Hmin,并计算其中值Hm;
Step 3 设置区间[Hmin,Hm]和[H m,Hmax],遍历图像并分别统计区间中点的个数;
Step 4 将比重较小区间内的点过滤,去除灰度值大于(小于)目标物的点;
Step 5 重复步骤(2)、步骤(3),去除灰度值小于(大于)目标物的点。
将干扰点过滤后的目标物(如图3(b)所示)转到HSV颜色空间,分别计算其三通道图像的灰度均值,以三个均值为中值设置区间,建立目标物颜色阈值区间。

图3 点云-彩色图映射偏差点过滤
颜色直方图通过统计图像中某一颜色的频数,能够反应图像中颜色的统计分布和基本色调,其矢量维数很多,直接计算复杂且效果不好。根据人眼描述图像的重要程度[13],将色调H分为8份,饱和度S分为2份,亮度V分为1份,根据色彩不同范围进行量化,生成20柄一维直方图,建立目标物颜色直方图模型。
2.2 融合深度信息的形状模型
目标跟踪时,目标物最小外接矩形的长、宽比常被用来描述物体的形状,当干扰物和目标物形状相似时,这种描述方式是不合适的。本文基于物体深度和其实际大小之间的线性关系,建立了目标物的形状模型。在实时跟踪过程中,目标不断运动,其深度也在不断变化,根据目标物在图像中的大小和深度呈反比的关系[14],以检测到的目标物前三帧平均深度值D M和平均长、宽值(L M、W M),计算出当前帧下,深度值为Dt的跟踪目标的长、宽值(L t、Wt)建立形状模型,如式(4)所示。
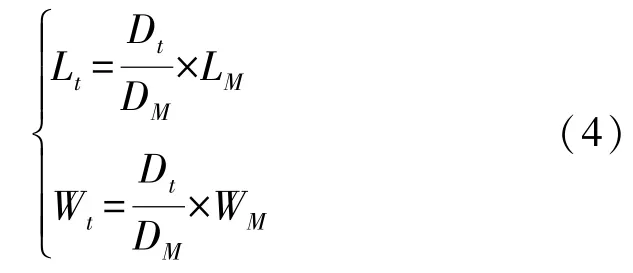
3 基于深度方差的目标跟踪定位
基于上述目标物“颜色-形状”模型,将颜色阈值区间与深度数据结合,运用深度方差分割潜在目标物。将颜色直方图与形状模型结合,根据目标物形状偏差率和颜色直方图巴氏距离进行目标物识别;最后依据目标物质心区域的深度均值完成目标跟踪定位。
3.1 跟踪图像的预处理
为获取潜在目标轮廓,首先对图像进行深度过滤,一方面可以排除大部分背景区域,另一方面可以降低后续计算复杂程度。Azure Kinect对运动目标进行实时跟踪过程中,由于每两帧之间时间间隔很短,目标物在相邻帧之间运动变化缓慢,其深度不会发生剧烈变化,可以认为下一帧中深度值远大于当前帧目标物深度的像素区域都为干扰背景。根据跟踪过程中实时获得的目标物深度值D L,通过上文所述的点云映射公式,计算彩色图像任意一点的深度值D r,由公式5对图像进行深度过滤。

式中:f(i,j)为彩色图像,d为预设值,D r(i,j)为彩色图对应点深度。
过滤完成后,根据颜色模型由颜色阈值区间提取与目标物颜色相似的对象,符合阈值区间的像素为255,其余则为0。由于物体本身存在非设定色块以及光照不均匀的影响,直接由颜色阈值提取得到的二值图像中存在很多细小的空洞,本文通过形态学操作对二值图像先膨胀后腐蚀,弥合较窄的间断和细长的沟壑,消除断裂的轮廓线,获取较为完整的符合颜色阈值区间的轮廓,完成对跟踪图像的预处理。
3.2 基于深度方差的目标物连通域分割
当目标物和背景中相似颜色的干扰物重叠时,通过颜色阈值和形态学处理提取的轮廓中存在多个潜在跟踪目标。为完成目标识别,本文运用深度方差分割潜在目标物,通过深度模板与轮廓图像进行卷积运算,将模板在图像中逐像素点移动,遍历图像中每一个连通域,计算深度模板中心像素所在位置的方差值,计算公式如下:
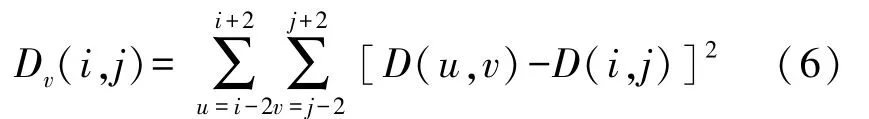
式中:D v(i,j)表示模板中心方差值,D(u,v)表示模板内各像素点的深度值,D(i,j)表示模板中心像素点的深度值。
完成对所有轮廓的遍历后,轮廓内深度方差较大的像素点可以认为是目标物、干扰物以及背景交界处的点,而方差较小的点则是每个物体内部的点。选择合适的阈值,将二值图像中所有深度方差大于阈值的点置为黑色。如果一个连通域是由空间中多个相似颜色的物体重叠构成的,通过深度方差提取轮廓后,会被分割成多个连通域。由此完成目标物与相似颜色干扰物的连通域分割,分割结果如图4所示。

图4 连通域分割
3.3 目标物识别与定位
连通域分割完成后,每个连通域即为潜在跟踪目标,将颜色直方图与上述形状模型结合,过滤形状偏差过大的潜在目标后,进行直方图相似度匹配,完成目标识别、定位。
目标相似度包括形状相似度和颜色相似度。形状相似度δ1用当前帧检测到的潜在目标的长、宽值(L d、W d)与目标物前三帧平均长宽值(L M、W M)的偏差率描述,偏差率越接近于0,目标形状相似程度越高,计算公式如下:

颜色相似度δ2用组数为i的潜在目标直方图Q M与目标颜色直方图Q T的巴氏距离来描述,巴氏距离越接近于1,直方图相似程度越高,计算公式如下:

选择合适的阈值δTH与δTC,当δ1<δTH时,计算该区域的颜色相似度δ2,当δ2>δTC时则判断为目标识别成功。识别结果如图5所示。

图5 目标识别结果
目标物识别成功后,以质心深度均值完成目标定位。由于Kinect深度传感器无法采集反光点的深度信息,为了防止目标质心点和反光点重合而无深度数据,质心深度均值的计算选取以质心D S(i,j)为中心的9×9像素区域进行,统计该区域深度非0点的个数,如果存在0值则将质心上移9个像素,直到不存在0值。目标物深度值D K计算公式如下:

4 实验验证
为了验证该跟踪定位方法对相似颜色背景的抗干扰能力,设计了如图6所示的单摆实验。图中小球为待跟踪目标,基准面1为单摆平面,基准面2为正对着Azure Kinect的投影平面,两平面成一定夹角,让小球在基准面1内作稳定的单摆运动,通过Azure Kinect实时跟踪并记录小球的位置。

图6 实验示意图
小球稳定运动过程中,其实际深度变化应符合单摆运动周期性规律。若跟踪定位方法在跟踪时不能区分相似颜色的目标物和背景,则其定位质心坐标相对于目标物实际质心坐标会发生较大的偏移,进一步地,由质心位置计算得到的深度值也会发生较大的波动。通过验证小球稳定运动时,检测得到的目标物深度值的变化规律,可以验证跟踪方法对相似颜色背景的抗干扰能力。
图7为实际实验场景,Azure Kinect与基准面2距离为L A,基准面1与基准面2夹角为θ,单摆摆长L B为25 cm,小球直径5 cm,单摆平面存在相似颜色的干扰背景。以向左摆动为正方向,小球摆动过程中的深度值D T与摆角φ有如下关系:

图7 实验场景图

分别改变夹角θ和距离L A,使红色小球从水平位置A下落,一段时间后开始稳定的单摆运动,以小球竖直位置B时的深度为起始值,记录小球运动中的深度值及其与位置B的深度差。
当θ=30°时,L A分别为0.5 m,1 m,1.5 m时检测得到的小球深度值与理论计算值的对比如图8所示,检测值与计算值最大偏差σs如表1所示。当小球处于不同检测距离时,图中曲线均不存在明显的离散点,且σs小于目标小球半径,跟踪定位未受干扰物影响。

图8 相同角度、不同距离时深度值对比

表1 相同角度、不同距离时深度最大偏差值
当L A=1 m时,θ分别为30°,45°,60°时小球的深度差随时间变化规律如图9所示,平均周期T如表2所示。当小球处于不同的摆动平面时,深度差随时间变化规律符合单摆运动的周期性规律,且深度差峰值逐渐减小与小球运动衰减的现象相符,摆动周期相对误差小于3%。
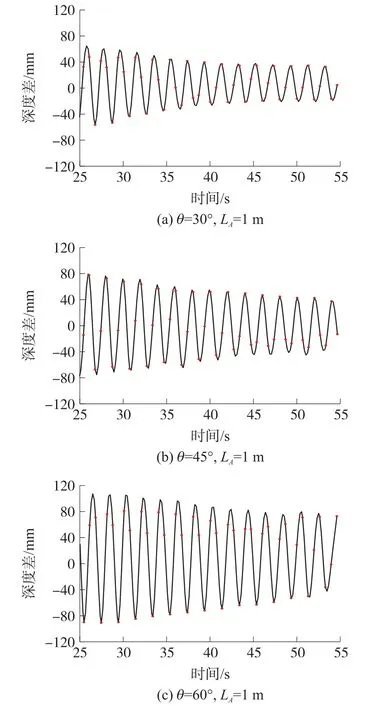
图9 不同角度、相同距离时深度差-时间关系

表2 不同角度、相同距离时单摆运动平均周期
为了进一步验证跟踪方法在干扰物与目标物颜色、形状都相似时的稳定性,设计了如图10所示的抗干扰试验。图中目标物为黄色乒乓球,干扰物分别为颜色和形状相似的圆形物体(如图10(a)所示),本文的跟踪算法依然可以准确地识别目标对象(如图10(b)所示)。

图10 颜色、形状相似的抗干扰实验
这是由于干扰物与目标物虽然颜色、形状相似,但其颜色直方图与目标物存在一定的区别,此时本文方法仍能够准确识别目标物;但当干扰物与目标物颜色、形状完全相同时,识别失败。
实验表明,本文方法能够有效克服相似颜色背景的干扰,对目标物进行实时跟踪定位,当干扰物和目标物颜色、形状都相似时,方法仍有较高的稳定性,但无法识别完全相同的两个目标。
5 结束语
本文提出了一种基于Azure Kinect的目标跟踪定位方法,在完成目标物三维点云分割,建立融合深度的目标物“颜色-形状”模型的基础上,运用深度方差进行潜在目标连通域分割,通过目标物相似度匹配完成了目标识别、定位。该方法融合了图像深度信息,能够有效的对目标进行实时定位,在存在相似颜色背景时具有较强的抗干扰能力,当干扰物和目标物颜色、形状都相似时,方法仍有较高的稳定性。
猜你喜欢
高中数理化(2024年1期)2024-03-02 17:52:40
湘潭大学自然科学学报(2022年2期)2022-07-28 05:26:40
小型微型计算机系统(2021年4期)2021-04-12 09:50:54
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14 07:36:02
动漫界·幼教365(中班)(2020年8期)2020-06-29 07:28:25
家教世界·创新阅读(2020年4期)2020-06-03 04:38:56
家教世界(2020年10期)2020-06-01 11:49:26
摄影之友(影像视觉)(2018年12期)2019-01-28 09:01:02
计算机应用(2017年4期)2017-06-27 08:10:42
计算机应用与软件(2016年11期)2016-12-26 08:33:20
