
基于YOLOv3和注意力机制的野外蝴蝶种类识别
2022-01-17 01:58周文进
郑州大学学报(工学版) 2022年1期
周文进, 李 凡, 薛 峰
(昆明理工大学 信息工程与自动化学院,云南 昆明 650500)
0 引言
蝴蝶(锤角亚目),隶属于昆虫纲第二大目(鳞翅目),全世界已知鳞翅目昆虫数量多达20余万种,其中蝶类约占十分之一[1]。蝴蝶与人类关系密切,不同种类的蝴蝶品种会对人类生产生活产生有益或有害的影响。由于其对环境变化的敏感,近年来,珍稀品种的蝴蝶数量急剧减少,因此,探索一种环保、智能的蝴蝶分类鉴定方法具有十分重要的实际意义,也是保护众多珍稀蝴蝶品种的重要基础。
近年来,随着人工智能领域的突破与发展,越来越多的研究者投入到蝴蝶的识别研究中。传统的研究方法通过提取蝴蝶的颜色、纹理、形状等局部特征[2]并结合不同类型的分类器,在部分品种的蝴蝶标本自动识别研究中取得了一些成果。Li等[3]通过多尺度曲率直方图(HoMSC)和图像块的灰度共生矩阵(GLCMoIB)特征提取方法的设计,结合KNN分类器实现了50种蝴蝶标本图像的自动识别。Chen等[4]提出了一种新的特征描述方法(高斯卷积角)来描述蝴蝶标本图像中复杂的静脉特征和纹理特征,在公开数据集上对10种蝴蝶进行了有效识别。然而,蝴蝶翅面的自然形态、纹理特征十分复杂,很难通过函数表达或统计描述的方式进行精准表达,同时,这类算法复杂度大,当待识别种类数量增加时,模型运算量急剧增加,识别效率受到很大影响。
谢娟英等[5]制作了中国蝴蝶数据集,在Faster R-CNN基础上对94种蝴蝶进行了识别,其模型的mAP最低值接近60%;之后Xie等[6]又在其数据集的基础上提出新的数据划分方式与数据扩充技术,在RetinaNet模型上实现了最好mAP为79.7%的识别效果。魏宏彬等[7]在YOLOv3的基础上,结合新的边界框回归损失函数DIoU实现了蔬菜的自动识别。然而蝴蝶物种分类粒度极为细致,同一属中种类多且形态差异小,简单采用针对其他对象识别问题研发的网络模型,很难取得较好的特征学习效果,尤其针对亲缘关系较近的蝴蝶种类,有区分效果的细微局部差异更是无法获取。此外,现有的基于深度学习模型性能的提升主要通过增加网络层数实现,这将带来模型参数激增、训练过程冗长、不易收敛等问题。
综上,本文针对野外蝴蝶图像自动识别性能的提升问题,通过构建一个包含200种蝴蝶的混合数据集(其中包含野外拍摄的蝴蝶图像及室内拍摄的蝴蝶标本图像)的方式解决现有研究中高质量样本数据缺乏的情况,并在此基础上通过改进YOLOv3主干网络的方式,得到内嵌通道注意力MultiSE1D的识别网络,通过多尺度的方式提取高维特征,使网络具有多种感受野,并通过一维卷积代替压缩激励层的方式,在避免通道特征降维的同时,能有效降低模型参数量,提升模型总体效率。
1 实验对象及方法
1.1 数据集构成
本文构建的蝴蝶数据集收集自美国标本蝴蝶网站(http://www.butterfliesofamerica.com),蝴蝶分类层级为科、亚科、族、属、种,包含4科、96属、200种蝴蝶,每种蝴蝶均包含野外拍摄的图像和标本图像,共计5 374张图像。
数据集包含野外拍摄的自然状态蝴蝶图像3 612张,部分图像如图1所示。自然状态下的蝴蝶拟态性强,容易与周边的植物等环境发生混淆。这类蝴蝶图像数据会造成特征提取时涉及的蝴蝶主体信息太少,因此本文在为数据集选取野外图像时摈弃了只有一张图像的种类。野外蝴蝶各种类图像数量最少的有2张,最多的有117张,大多数蝴蝶种类图像在50张以内。

图1 6种野外蝴蝶图像Figure 1 6 kinds of wild butterfly images
蝴蝶数据集中的标本图像共有1 762张,部分标本图像如图2所示,图像呈现的是蝴蝶的正面与背面,背景统一为白色,纹理颜色都比较清晰,且每张标本图像只包含一只蝴蝶,与野外图像相比,标本图像包含了蝴蝶身体部位的全部信息。为了在实验中不制造额外的变量,本文在为数据集选取标本图像时摈弃了破损、褪色严重的标本。标本蝴蝶各种类图像中,绝大多数蝴蝶种类有10张图像,每个种类至少有正背面2张图像。

图2 标本图像中蝴蝶的正面与背面Figure 2 Front and back of butterfly in specimen image
1.2 数据集标注与划分
1.2.1 数据集标注
本文使用Labellmg标注工具对数据集图像进行位置标注,标注方式如图3所示,种类标注采用二名法(学名由属名与种名组成),如:Papilio indra。标注野外图像蝴蝶位置时尽量使标注区域包含触角,为了不引入太多不必要的背景,会摈弃过长的触角;标注标本图像蝴蝶位置时,只标注蝴蝶的主体位置,摈弃多余的白色背景,一方面与野外蝴蝶位置标注保持一致,另一方面提高蝴蝶主体特征提取效果。
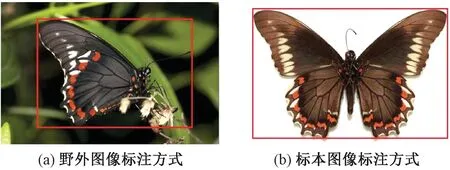
图3 蝴蝶图像中蝴蝶主体标注方式Figure 3 Annotation method of butterfly body in butterfly image
1.2.2 数据集划分
本文将蝴蝶数据集中野外图像按照训练集、测试集各80%、20%的比例进行划分。根据训练集的不同制作了3种数据集:数据集1中训练集包含2 806张野外图像,0张标本图像;数据集2中训练集包含0张野外图像,1 762张标本图像;数据集3中训练集包含2 806张野外图像与1 762张标本图像。本文的目标是野外蝴蝶的识别,因此上述3种数据集的测试集均为相同的野外蝴蝶图像,有806张图像。选择上述划分数据集的方式是因为通过分析野外图像与标本图像的特点,发现野外图像中的蝴蝶由于姿态、拍摄角度、遮挡、聚集等生物习性缺失了很多蝴蝶主体信息,而且有的种类野外图像资源非常少,特别是10张样本以内的,更加剧了蝴蝶主体信息的缺失,这样提取出来的特征不足以识别测试集中的样本,而且蝴蝶物种粒度极为细致,一个属下的种相似度非常高,甚至可能无法识别,而标本蝴蝶图像正反面提供了完整的蝴蝶主体信息,可以弥补野外蝴蝶图像缺失的特征。
1.3 模型网络结构
本文采用YOLOv3[8]作为所有提出的网络模型的基线架构,模型网络结构如图4所示,ConvBlock1~ConvBlock5为各阶段卷积块,括号内给出了每个卷积块的特征图边长、通道数,Conv2D为二维卷积,Pool表示最大池化。Backbone(主干网络)选用轻量高效的特征提取网络Tiny-darknet,特征提取网络共7个卷积层,相邻卷积层间夹杂最大池化层进行下采样,整个网络结构中没有全连接层,并在主干网络中加入了改进的基于SENet[9]通道注意力网络MultiSE1D。Neck(检测颈)为两级的特征金字塔结构。Detection head(检测头)接收Neck中输出的两种尺度的特征图对不同大小的目标进行检测:第一个尺度特征图下采样比较高,达到了32倍,适合于检测图像中等和大目标;另一个尺度特征图通过拼接得到,下采样倍数为16,此处的特征图感受视野一般,适用于较小目标检测。每种尺寸特征图的通道数C计算如下:
C=3(N+5)。
(1)
式中:3表示该尺度下每个网格中先验框的数量; 5表示预测框的5个参数,分别为坐标、宽高、置信度;N表示要预测的种类个数,在本文中N为200。
将改进SENet后的注意力网络(MultiSE1D)放置在主干网络的第7个卷积后,使得两个尺度的特征图都能共享到注意力网络的参数,同时高维特征经过注意力网络后的特征维度并没有发生改变,使其可以十分方便地移植到任何主干网络中。
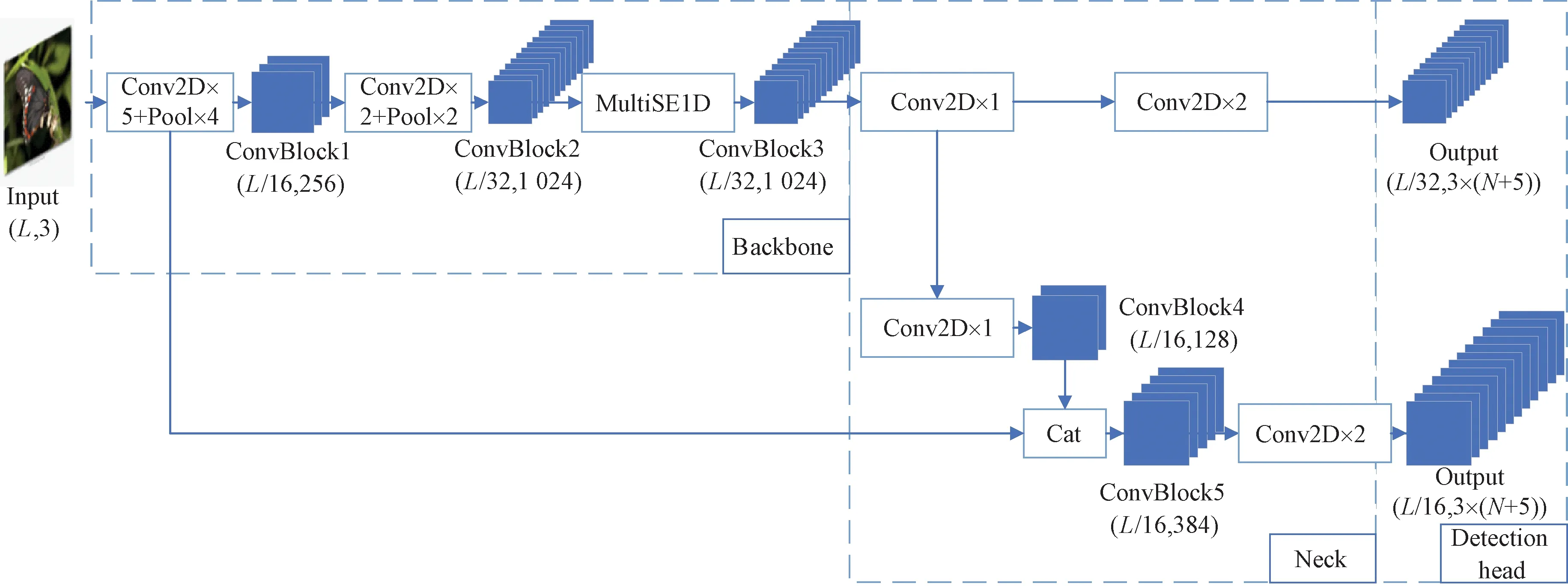
图4 模型网络结构Figure 4 Structure diagram of model network
1.4 MultiSE1D通道注意力网络
本文嵌入主干网络的MultiSE1D注意力网络如图5所示,Block1~Block6为各阶段卷积块,括号内给出了每个卷积块的特征图边长、通道数,Conv1D为一维卷积。卷积块Block1经过两种尺度的卷积提取得到2个卷积块Block2、Block3,为后面生成的通道注意力权重具有两种感受野信息提供依据,Block4由2个卷积块相加得到,具有两种感受野,可以更好地反映图像中局部信息与不同尺度的主体信息。Block4经池化后每个通道特征图边长变为1×1,由于一维卷积输入为三维,并且本文是对Block5通道作一维卷积,所以在Block5进入一维卷积之前要进行降维与转置操作,并在一维卷积之后进行转置与升维恢复原来形式,再通过Sigmoid函数得到通道注意力权重Block6,在这个过程中没有使用全连接层,并且Block5的通道进行一维卷积时没有发生降维,始终为1 024。网络最后得到的MultiSE1D与原始Block1的特征图相比获得了局部跨通道联系。
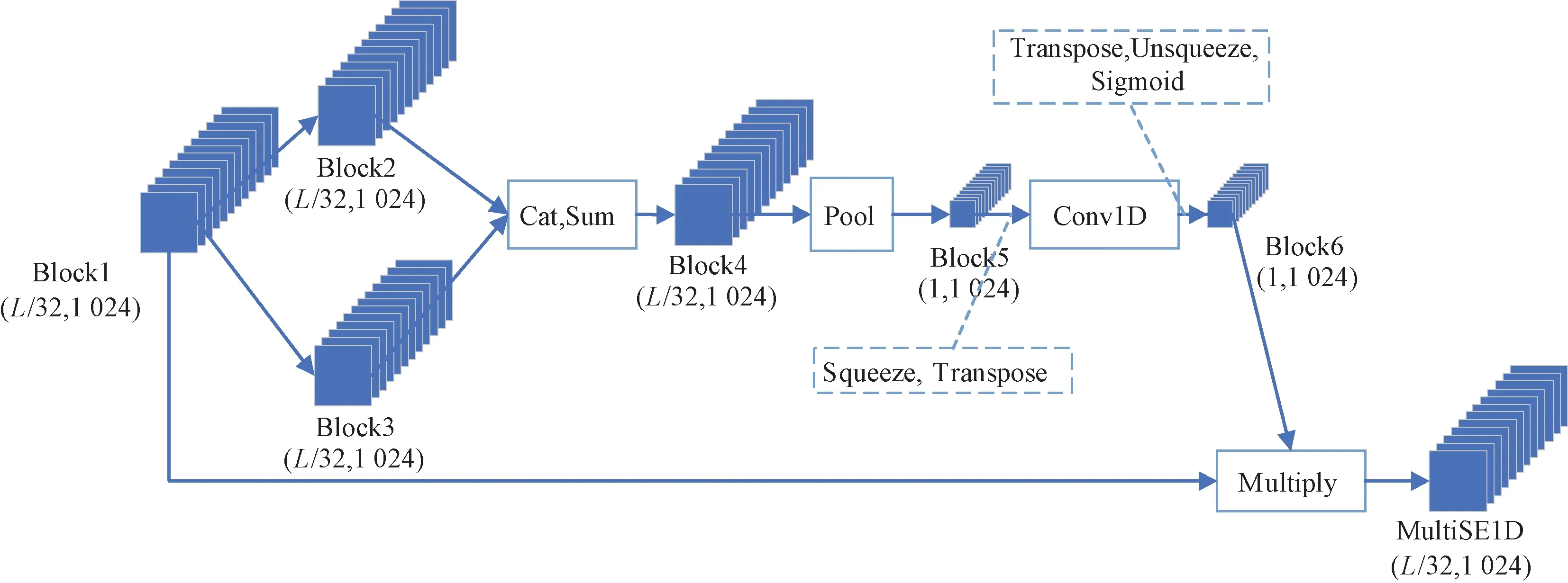
图5 MultiSE1D网络结构图Figure 5 Structure diagram of MultiSE1D network
1.4.1 多尺度通道注意力网络构建
由于压缩激励网络原始模型[9]可以有效地利用图像全局信息,因此本文首先对高维特征的每个独立通道采取了全局平均池化,并通过两个全连接层(压缩激励层)的结合,实现了非线性通道间的相互作用,最后经过一个Sigmoid函数生成了通道权重XSE:
XSE=σ(FC1RELUFC2(φ(X)))。
(2)
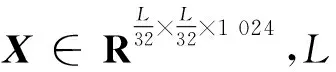
原始的通道注意力[9]在高维特征中提取通道相关性是通过单一支路用固定的卷积核卷积实现的,这意味着网络在提取特征时只能拥有单一的感受野,实际上可以用5×5、7×7等其他奇数卷积核来提取特征,参考Li等[11]使用不同的卷积核来获取不同的感受野方法,对通道注意力提取高维特征的方法作出调整,图5中Block2、Block3分别为使用两种卷积核的卷积提取特征得到的卷积块,这样网络获取了多种感受野,可以更好地反映图像中局部信息与不同尺度的主体信息,然后把多种感受野特征相加在一起作为通道注意力网络的输入,得到多尺度通道特征权重XMultiSE:
(3)
式中:n表示不同的卷积核尺度;fConv2D(·)表示二维卷积操作,为了不增加模型复杂度,在实验中直接选取了3×3、5×5的两种奇数卷积核。
1.4.2 非压缩-激励的通道注意力网络构建
通道注意力网络几乎都是通过压缩激励层(FC1RELUFC2)、Sigmoid函数来获得通道权重,然而网络中存在全连接层会导致模型参数大幅增加。空间注意力(CBAM)[10]将全连接层换成了卷积层来减少参数也取得了同样的检测效果。压缩激励层通常为了减少模型复杂度而进行降维,然而其通道特征首先被投影到低维空间,再将其映射回来,使得通道特征与其权重之间的对应是间接的,破坏了二者的直接对应关系,同时全连接层考虑了所有通道间的影响。本文更注重图像局部变化,而一维卷积操作具有局部性,充分考虑了相邻通道间的影响。考虑到以上问题,参考文献[12]方法,本文对多尺度通道注意力作出调整,图5中的Conv1D与原始通道注意力的区别主要体现在压缩激励层被自适应卷积核的一维卷积代替,因此式(2)中XSE调整为
(4)
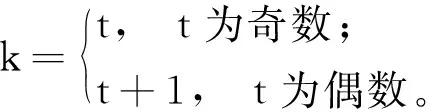
(5)
t=0.5log2C。
(6)
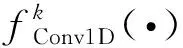
2 实验
本文使用Pytorch构建识别网络,在构建的3类数据集上实验。实验中的硬件条件为CPU:Inter CORE i5 9th Gen,8 GB RAM;GPU:NVIDA GeForce GTX 1050 (3G)。为加快模型收敛速度,实验中使用在ImageNet数据集上预训练过的权重并在本文数据集上进行微调,总共训练300个epoch,batch-size设为4,其他超参数使用默认值。模型初始学习率设置为0.01,学习率的调整策略采用余弦退火衰减[13],学习率随着epoch的增加而递减,刚开始学习率下降比较缓慢,当训练到一半时学习率下降速度变快,最终接近0.000 5,整个学习率变化类似于余弦曲线。
2.1 评价指标
本文采用交并比 (IoU)作为蝴蝶的定位指标,在本文中取IoU的阈值为0.5,真实框与其对应网格所有的先验框都产生IoU,取最大值为正例,正例产生置信度损失、检测框损失、类别损失,小于IoU阈值的预测框作为负例,只产生置信度损失;大于IoU阈值的预测框(正例除外)将作为忽略样例,不产生任何损失。本文采用平均精度均值mAP来评价野外蝴蝶的分类情况。mAP是一种衡量模型在所有类别上平均精度的指标,计算如下:
(7)
式中:N为测试集中的野外蝴蝶种数,在本文中N为200;AP为平均精度,为PR曲线的积分,即精度与召回率曲线下方的面积,可由式(8)~(10)计算

(8)
(9)
(10)
式中:P为PR曲线的纵坐标;R为PR曲线的横坐标;TP为被正确划分为正例的个数;FP为被错误划分为正例的个数;FN为被错误划分为负例的个数。
2.2 实验结果与分析
为了从本文提出的3个数据集中确定最佳数据集,使用原始的YOLOv3模型(实验中称为Baseline)分别在3种数据集上进行实验,实验结果如表1所示,在数据集1上的mAP达到了67.1%,在数据集2上的mAP只有18.1%,最后在数据集3上进行实验得到了80.7%的mAP,比在数据集1的结果提升了13.6百分点,提升幅度接近于在数据集2上的mAP,说明在训练集中加入标本图像可以很好地补充野外蝴蝶图像各种不可避免的特征损失,为野外蝴蝶的分类补充了关键因素。

表1 Baseline在不同数据集上的性能Table 1 Performance of Baseline on different datasets
确定好最佳数据集后,为Baseline添加通道注意力以进一步提升模型分类能力,实验结果如表2所示。表2中SENet为文献[9]原始的压缩激励网络,添加到Baseline后在数据集1上mAP提升了2.3百分点,然而在数据集3上的mAP没有提升,反降了1.2百分点,说明原始的通道注意力并不能很好地适应含有标本图像的数据集。

表2 SENet、MultiSE、MultiSE1D分别加入Baseline在数据集上的性能Table 2 Performance of SENet, MultiSE and MultiSE1D on dataset 3 after adding Baseline
分析数据集3中同一物种的野外图像与标本图像,野外照中蝴蝶主体大致占据整张图像的1/3,而标本照中蝴蝶主体基本占据了整张图像,这样训练集中就有两种截然不同的蝴蝶主体尺寸,SENet中提取高维特征直接对每个通道进行全局平均池化,这样显然不符合数据集3的情况,没有多尺度的特征提取与之对应。MultiSE为采用多尺度提取特征的注意力网络,在数据集3上的mAP达到了82.2%,相较SENet提升了2.7百分点,说明多尺度提取的方法可以更好地提取图像特征,更适合标本与野外蝴蝶图像混合的数据集。
然而性能的提升却带来模型参数的增加,如表2参数量所示,MultiSE比SENet参数增加了近4倍,为了减少模型参数,同时避免注意力网络中的压缩激励层的降维,调整MultiSE得到没有全连接层同时不需要降维的MultiSE1D,在数据集3上的mAP达到了83.2%,较调整前提升了1百分点,参数量减少了1.6×106,说明一维卷积和避免降维的方法是有效的。
为了进一步验证本文注意力网络MultiSE1D的有效性,在Baseline中加入其他注意力网络:SESADRN[14]、GCNet[15],在本文数据集3上的实验结果如表3所示,加入SESADRN、GCNet 之后模型的mAP出现不同程度的小幅下降,MultiSE1D的mAP比二者都高了近3百分点。由于采用的数据集不同,本文只使用两种注意力网络的核心方法,其他实验因素无法保证一致,表3中实验数据只说明其方法在本文数据集上的一般性,MultiSE1D更适用于标本与野外图像混合的数据集。

表3 SESADRN、GCNet、MultiSE1D加入Baseline在数据集3上的性能Table 3 Performance of SESADRN, GCNetand MultiSE1D on dataset 3 after adding Baseline
最后分别选取目标检测网络Faster R-CNN[16]、SSD[17]、YOLOv3[8]、EfficientDet[18]、YOLOv4[19]在数据集3上进行实验,实验时控制上述网络输入图像尺寸、学习率、epoch、batch-size与本文实验保持一致,实验的硬件环境也一致,均没有使用数据在线扩增策略,不同点在于网络模型使用的主干网络不同,不同网络的Neck与Detection head也不同,实验结果以及每个检测模型使用的主干网络如表4所示。结果表明,本文内嵌通道注意力MultiSE1D的识别网络对野外蝴蝶的识别是有效的。

表4 不同目标检测网络模型在数据集3上的性能Table 4 Performance of different target detection network models on dataset 3
3 结论
针对野外蝴蝶数字图像分类粒度细致、同属间分类特征差异小、与周边环境容易混淆等特点,本文提出了一种改进YOLOv3主干网络的方案,实现了内嵌通道注意力的MultiSE1D识别网络模型。该模型通过多尺度提取特征使网络具有多种感受野,能更好地学习图像中各种尺度的蝴蝶主体特征及局部分类特征;通过将全连接层替换为一维卷积的方式,有效避免了通道特征的降维,在获得通道特征与通道权重直接联系的同时,有效降低了模型参数量。该模型通过在本文自建混合数据集上的训练及参数优化,获得了分辨亲缘关系较近的不同蝴蝶种类野外图像的能力。从本文对比实验结果可以看出,该方法可实现200种蝴蝶的野外图像自动识别,取得了mAP最高为83.2%的识别效果。相较于现有方法,本文改进的识别网络可以有效提升原模型提取蝴蝶图像特征的准确性及细节特征的学习能力,能为野外蝴蝶数字图像的种类识别问题提供有效的解决方案。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
社会科学战线(2022年7期)2022-08-26
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
青少年科技博览(中学版)(2021年6期)2021-08-30
现代仪器与医疗(2021年1期)2021-06-09
中国信息化周报(2015年1期)2015-04-09
时代英语·高三(2014年5期)2014-08-26
现代园艺(2012年24期)2013-03-25
