
基于迁移学习的少样本朝鲜语古籍文字的识别方法
2022-01-14 01:30:18薛春寒金小峰
延边大学学报(自然科学版) 2021年4期
薛春寒, 金小峰
( 延边大学 工学院, 吉林 延吉 133002 )
中国少数民族古籍数字化是“中华古籍数字资源库”的重要组成部分[1].与国内其他少数民族古籍数字化研究工作相比,中国朝鲜语古籍的数字化工作相对滞后,因此开展和推进中国朝鲜语古籍的数字化研究是一项迫切的任务.古籍文字自动识别作为古籍数字化总目标的基础性研究,是建设古籍全文索引库和提供信息检索服务的必要前期环节.传统的光学字符识别OCR(optical character recognition)技术由于过度依赖于样本底层视觉特征的选择和提取,使得分类器难以从中提取更高级别的语义特征.近年来,随着深度学习方法的发展,一些学者提出了基于LeNet5、AlexNet、VGGNet、ResNet等[2]的深度网络模型的文字识别方法.
与传统的模式识别方法相比,深度学习方法需要大规模数据集的支撑,而国内少数民族古籍普遍存在存量少、数据集不足的问题,这给利用基于深度学习的古籍文字识别方法研究少数民族古籍带来诸多困难.基于上述问题,一些学者提出了利用数据增强(data augmentation)和迁移学习(transfer learning)的方法来解决样本不足的问题,并取得了较好的研究结果[3-10].为此,本文结合数据增强和迁移学习方法,通过扩充数据集规模和知识迁移,提出了一种少样本朝鲜语古籍文字识别方法,并通过实验验证了本文方法的有效性.
1 朝鲜语古籍数据集的数据增强方法
朝鲜语古籍存在多语种文字混排、文字大小不同、相邻文字黏连等现象.本文中的朝鲜语古籍文本图像样本均是采用文献[11]的方法获取的(采用文字切分法获取每个文字区域的图像),所采用的数据增强方法均是指对文本图像进行的.图1为朝鲜语古籍图像的样张.

图1 朝鲜语古籍图像样张
1.1 基于图像变换的增强方法
数据增强方法主要是通过对数据进行多种变换来扩充训练集,以此实现对小数据集的样本扩充.本文采用随机仿射变换和弹性变换进行数据增强.随机仿射变换是将空间内的某一个向量随机映射到另一个向量空间,其映射过程相当于对图像进行平移、旋转、放缩、剪切、翻转等操作,或是这些操作的任意组合.一个集合的仿射变换可表示为y=Ax+b, 其中y为变换后得到的目标向量,A为变换矩阵,x为原始向量,b为平移向量.
弹性变换增强方法是首先在图像的像素点上的x、y方向上生成-1~1之间的随机数,这些随机数表示像素点在x、y方向的移动距离(记为Δx(x,y),Δy(x,y)),可表示为:
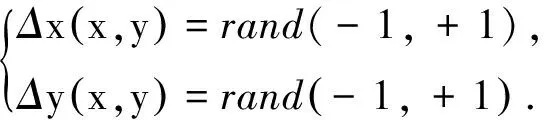
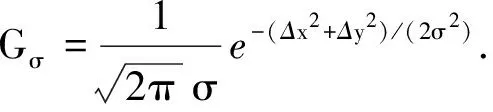
1.2 基于条件生成对抗网络的增强方法
由于在数据样本少和类别样本数严重不平衡时,采用基于图像变换的增强方法生成的新样本会极易陷入饱和状态,因此本文引入GAN方法以进一步增强数据.基础的GAN网络模型包含两个核心子网络:生成网络G(generator)和判别网络D(discriminator).G和D的学习实际上是一个博弈过程,G可以对任意的噪声z产生一个伪样本G(z), 而对于任意输入x,D(x)能够对其真伪进行判别.GAN方法的目的就是能够对真实样本x~Pdata(x)实现期望最大化logD(x), 而对于伪样本z~Pz(z)实现期望最小化log(1-D(G(z))),因此GAN的学习过程可表示为:
(1)
由于GAN网络学习过程所生成的样本是随机和不具有类别的信息,因此本文在式(1)的基础上加上一个类别信息y作为条件,以此得到具有类别信息的生成样本.增加类别信息y条件后, GAN网络变为CGAN网络, 其训练过程可表示为:
(2)
另外,为了提高GAN网络的特征提取能力、伪样本的生成质量和收敛速度,本文引入了条件深度卷积生成对抗网络(conditional deep convolution generative adversarial network,CDCGAN).图2是本文采用CDCGAN生成的网络和判别网络的结构图.
2 基于迁移学习的朝鲜语古籍文字识别方法
领域和任务是迁移学习中的两个重要概念.迁移学习的目的就是利用在源领域学到的知识实现其在目标领域上的学习任务,但迁移学习并不能适合于任何情况,如当源领域和目标领域差异过大时可能会发生负迁移.为此,本文使用己经训练好的预训练模型对全新的目标任务进行训练,即在不改变网络结构的前提下和保持预训练模型的参数基础上,以很小的学习率对模型进行微调,使得模型能够适应新的学习任务.本文提出的基于迁移学习的少样本朝鲜语古籍文字识别方法的流程图见图3.

(a) 生成网络 (b) 判别网络图2 基于CDCGAN生成的网络和判别网络的结构图

图3 基于迁移学习的少样本朝鲜语古籍文字识别方法的流程图
在进行迁移学习时,首先按1.1和1.2中的方法对数据进行增强,然后选取出样本较多的富数据集作为源域预训练模型的数据集,目标域则采用全类数据集(即增强前后的所有数据).源模型到中间模型的转变是一个典型的基于模型的迁移学习策略,该策略通过将预训练模型和层冻结方法相结合的方法来实现朝鲜语古籍文字识别的训练过程,该过程主要包括如下几个关键阶段:
第1阶段:保留预训练模型的权重参数,并将其作为第1阶段模型训练过程中的特征提取源.
第2阶段:加载预训练模型的参数和权重(除全连接分类层).定义目标数据集的类别数为c, 并将最后一层全连接层由原来的神经元数改为c元的softmax分类器,同时冻结预训练模型的卷积层以及池化层的参数和权重,并对新的分类器层进行训练.
第3阶段:将在源数据集上已经预训练过的模型的卷积和池化层保留的参数迁移到目标模型上,并与第2阶段中训练的新的全连接分类层进行对接,以此得到中间模型.
3 实验结果与分析
实验数据集采用文献[11]中的方法对朝鲜语古籍《同文类解》进行文字切分.经切分后共得到1 299种朝鲜语文字类别, 24 390个文字图像样本(每个样本均做人工类别标注).由于该数据集中很多的样本数量过于贫乏(样本数小于30个),因此该数据集具有少样本的特点.本文从数据集中选取了样本数较为充足的141个类别作为本文实验数据集,其中将样本数≥100的44类作为富数据集(记为S1),将剩余的97类作为少样本数据集(样本数为30~100,记为S2).
3.1 数据增强实验
采用1.1和1.2中的数据增强方法对S1数据集进行数据扩充,图像变换包括随机仿射结合弹性变换和随机仿射结合噪音扰动两种方法,其中噪音类型包括Gaussian、Salt&pepper和speckle.由于CDCGAN在训练时需要一定数量的样本,因此本文将变换得到的图像样本与原始样本进行合并,并将合并后的样本作为CDCGAN训练集.经实验优化, CDCGAN的超参数为: epochs=400, batch_size=20, learning rate=0.000 2.
数据增强扩充后的样例如表1所示.从表1可看出:传统的数据增强方法通过控制参数取值虽然能够有效地扩充新样本,但过度的形变和噪声扰动会使新样本严重失真;而CDCGAN产生的新样本能够丰富训练数据集,所以该方法可以避免模型训练过程出现的模式坍塌现象.

表1 数据增强后的样本样例
为了提高模型性能,对S1和S2分别进行数据增强,并将增强后的数据集分别记为N1和N2.N1和N2的样本分布以及数据集的划分情况见表2.由表2可以看出, 合并后的数据集(记为N)的样本数量(94 400)满足深度网络模型的训练要求.

表2 数据集N1和N2的样本划分和样本分布
3.2 预训练模型的对比实验
在数据集N1上分别利用VGG16、ResNet18和ResNet50卷积神经网络模型对数据进行预训练,并对这3种模型使用不同的优化方法和超参数进行调优.经训练和调优后,本文最终取batch_size=16, learning_rate=0.000 1.为了减轻模型的过拟合现象,本文使用L2正则化和dropout方法对模型进行约束,其中神经元失活率取0.5.为了提高训练效率,本文使用Adam优化方法对模型进行优化.图4是3种卷积神经网络模型总体的查准率和损失函数随迭代次数的变化情况.本文以交叉熵作为刻画预测值和真实值之间差距的损失函数.
由图4(a)可以看出:当3种模型的迭代次数小于10次时,其查准率均呈上升趋势;当迭代次数超过10次后,3种模型的查准率逐渐趋于稳定(说明训练模型已经收敛).由图4(b)可以看出,整体损失值随迭代次数的增加而不断下降,其中ResNet18和ResNet50的下降趋势相同,并优于VGG16.

(a) 查准率随迭代次数的变化 (b) 损失函数随迭代次数的变化图4 查准率和损失函数随迭代次数的变化情况
表3是3种模型在数据集N1上的实验结果.实验中查准率(presicion,P)的计算公式为:
(3)
其中TP是正确识别的样本数,FP是错误识别的样本数.由表3可以看出,3种模型在验证集和测试集上的分类精度均较高,且较为接近.这表明这3种模型在N1训练集中能够学习到有效的特征,扩充后的数据集规模能够满足3种网络模型的训练和分类要求,因此可将训练的结果作为迁移学习的预训练模型应用于少样本朝鲜语古籍文字的识别当中.

表3 3种模型在数据集N1上的实验结果
3.3 迁移学习的对比实验
由于数据集N2中的每类样本的数量都小于N1的规模,无法直接用于模型的学习,因此本文借助迁移学习中的预训练模型(基于N1得到的预训练模型)学习N2.为了证明同源迁移的优势,本文将基于ImageNet[12]的预训练模型用于N2的训练.在迁移学习的过程中,冻结除全连接层以外的所有网络参数,且迁移学习的训练只用于更新全连接层的参数.迁移学习的实验结果见表4.

表4 基于N1和ImageNet的预训练模型在N2数据集上的训练结果
由表4可以看出,基于N1的预训练模型的实验结果均明显优于基于ImageNet的预训练模型.ImageNet预训练模型的实验效果低的原因是ImageNet预训练模型的源域和目标域的图像结构差异较大,使得其在训练N2时只能从ImageNet预训练模型中获取图像的通用知识.
为了验证全类数据集的分类识别效果,本文采用在数据集N1上学习获得的预训练模型对测试集N进行分类实验,结果显示VGG16、ResNet18、ResNet50 3种网络模型的识别精度分别为99.54%、99.48%、99.72%.由此可以看出, 3种网络模型采用本文提出的迁移学习方法进行文字识别时均可达到良好的分类效果,其中ResNet50的识别精度最高(99.72%).这表明,采用这3种模型并利用N1数据集训练得到的预训练模型对少样本N2数据集进行迁移学习是有效的,因此这3种模型可用于识别少样本的朝鲜古籍文字图像.
4 结论
研究表明,本文提出的基于迁移学习的少样本朝鲜语古籍文字识别方法可有效解决少样本的朝鲜语古籍文字识别问题,且可为其他语种少样本的文字识别研究提供参考.本文在研究中只对类样本数 ≥ 30的数据集进行了数据增强和识别,在今后的研究中我们将对样本数少于30的数据集进行研究.
猜你喜欢
湖南林业科技(2021年3期)2021-12-02 21:15:32
汉字汉语研究(2021年3期)2021-11-24 01:34:10
韩国语教学与研究(2021年1期)2021-07-29 08:43:46
天一阁文丛(2020年0期)2020-11-05 08:28:06
天一阁文丛(2018年0期)2018-11-29 07:48:08
金桥(2017年5期)2017-07-05 08:14:41
韩国语教学与研究(2016年2期)2016-10-19 00:54:36
新闻传播(2016年4期)2016-07-18 10:59:20
计算机工程与应用(2015年19期)2015-04-16 08:51:36
韩国语教学与研究(2014年3期)2014-10-17 01:37:56
