
基于DDPG算法的游船航行避碰路径规划
2022-01-14 01:39周怡袁传平谢海成羊箭锋
中国舰船研究 2021年6期
周怡,袁传平,谢海成,羊箭锋
苏州大学 电子信息学院, 江苏 苏州 215006
0 引 言
本文主要研究周庄水域的船舶航行安全。由于该水域急水港航道由4级升为3级,通行的各类货船无论是数量还是吨位都有明显的增加,而游船进出港穿越航道并与货船共线航行会增加游船的碰撞风险,人为驾驶因素也会引发碰撞事故,进而造成严重的经济损失和人员伤亡[1-2]。因此,开展船舶避碰研究,对推动水运行业安全发展具有积极意义。
现有的船舶避碰算法,例如遗传算法[3-4]、粒子群算法以及蚁群算法[5-6]等,都存在实时性差的问题,因为无法预先从样本数据中建立模型,所以在应用过程中需要重复进行路径优化搜索过程,造成大量无用的计算,且其依赖的评价函数较简单,在不同水域应用环境下的鲁棒性较差。所以,船舶避碰算法需能够从大量经验数据中学习避碰策略,同时保证在未知环境下依然可以保证避碰策略的准确性[7-10]。DDPG算法具有多维特征提取能力,能从大量样本中学习避碰模型及评价函数,而且具备良好的泛化应用能力[11-14],其采用的DQN(deep Q network)算法可根据不同应用环境选择合适的避碰策略[15-16],较现有的避碰算法有明显的优势。但DDPG训练收敛速度慢[17],训练过程所采用的经验池随机采样方式一定程度上降低了有效样本数据的利用率。针对此问题,陈希亮等[18]优化了优先缓存经验回放机制,提高了有效数据在学习时被选中的概率,提升了算法的学习效率。但上述对经验池回放机制的改进大都集中在提高样本的利用率方面,而忽略了智能体盲目探索时造成有效数据不足的问题。
鉴于以上存在的不足之处,本文将提出基于失败区域重点学习的DDPG算法改进策略,在训练过程中的失败区域扩大探索的随机性,有针对性地收集该区域的学习样本,提高避碰学习效率。同时,提出根据游船特征改进的船舶领域模型参数等方法,保障领域模型的正确性,进一步提高路径预测的准确性。
1 游船航道环境下的船舶领域模型
船舶领域模型被广泛应用于船舶的避碰分析中。上世纪60~70年代,Fujii等[19-20]提出了船舶领域的概念,将其定义为“绝大部分后续船舶驾驶人员避免侵入前一艘船舶周围的领域”。
我国内河流域水道狭窄弯曲,藤井(Fujii)提出的狭窄水域船舶领域模型对内河货船有着较好的适用性。本文的研究内容主要应用于周庄客货混合航道,航道长约1.5 km,宽约130 m。周庄水域中货船平均长宽为43和7 m,游船平均长宽为24和6 m(图1)。由于游船与货船在长宽比、尺度以及驾驶规范方面存在的差异,藤井狭窄船舶领域模型难以准确适用于游船。
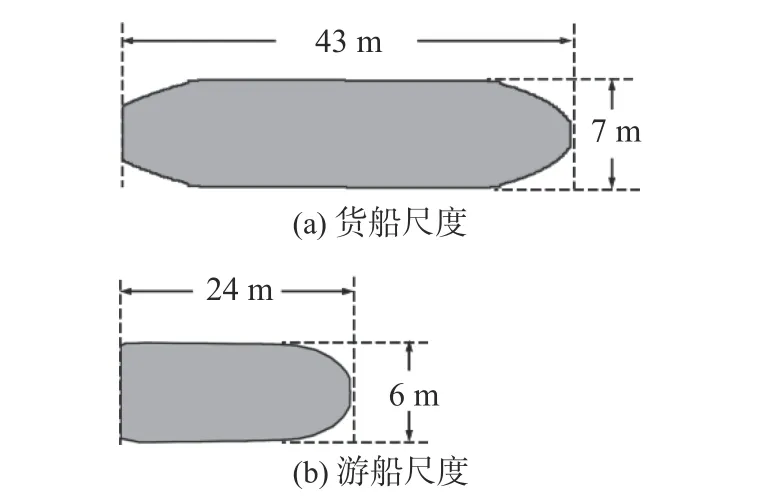
图1 货船、游船尺度对比Fig.1 Comparison of cargo ship and tourist ship
为进一步提高游船避碰路径规划的精度,本文在藤井狭窄船舶领域模型的基础上采用数据统计方式建立了游船的船舶领域改进模型。传统的数据统计主要依赖于船舶自动识别(AIS)系统,AIS系统虽能提供大量的船舶数据,但也存在覆盖率不足的问题,例如在游船水域存在大量未安装AIS系统的渔船。为提高船舶领域的精度,本文采用AIS与激光测距相结合的方式改进游船的船舶领域模型。以游船为参考坐标系,图2(a)所示为由AIS获取的周围船舶航行轨迹及确定的相对分布关系,图2(b)所示为运用激光测距方法对周围船舶进行方位角及距离测量及确定的相对分布关系。通过以上2种方法,收集得到大量游船的船舶领域周围船舶的真实分布数据。图3所示为游船船舶领域的建立过程图。其中,左侧图为游船的船舶分布数据叠加图,图中黑点为通过AIS获取的船舶分布信息,红色三角形为通过观察法获取的船舶分布信息;右侧图显示了通过最大密度法确定的游船船舶领域边界,图中蓝色点为游船周围船舶的分布边界,由其确定的椭圆区域为游船的船舶领域范围,椭圆船舶领域的长半轴为60.3 m,短半轴为25.2 m。
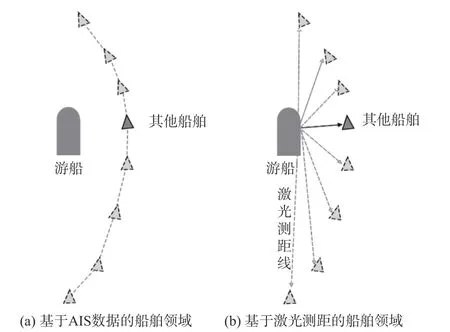
图2 不同方法计算的船舶领域Fig.2 The ship domain calculated by different methods
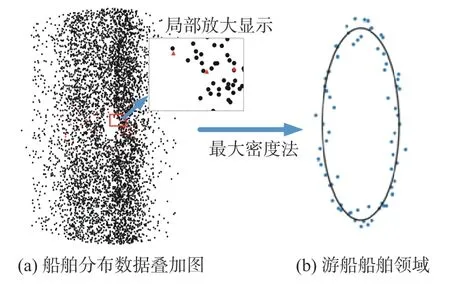
图3 游船船舶领域建立过程Fig.3 Establishment process of a tourist ship domain
藤井狭窄水域船舶领域的长轴为船长的6倍,短轴为船长的1.6倍,如图4所示,基于藤井模型的游船领域长轴为144 m,短轴为38.4 m,相较于传统藤井船舶领域模型,改进后的游船领域模型长轴更短,长宽比更小,体现出游船惯性小、驾驶更加灵活的特性,所以基于最大密度法改进的游船领域模型更符合游船航行的特征。
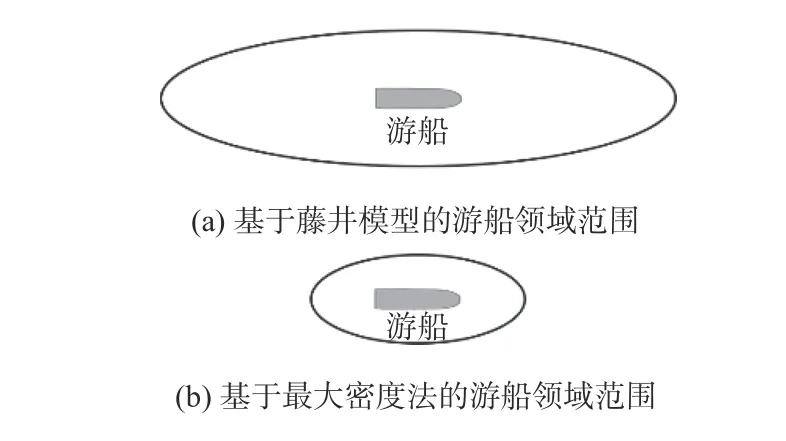
图4 修正后的船舶领域对比Fig.4 The comparison of Fujii model and revised model
2 DDPG船舶避碰路径规划算法设计
DDPG是基于Actor-Critic框架的深度确定性策略梯度(deep deterministic policy gradient)算法,其可有效解决复杂物理系统的控制和决策问题。如图5所示,强化学习智能体与系统环境交互的过程中,智能体根据当前状态st和环境奖励值rt选择下一步动作at, 达到新的状态st+1以及获取环境奖励值rt+1;而智能体根据当前状态,以最大化奖励期望值为目标,在与实际环境交互过程中不断学习并改进动作策略,其中DDPG使用深度神经网络拟合策略和价值函数,运用经验回放和目标网络技术提高算法的收敛性与稳定性。
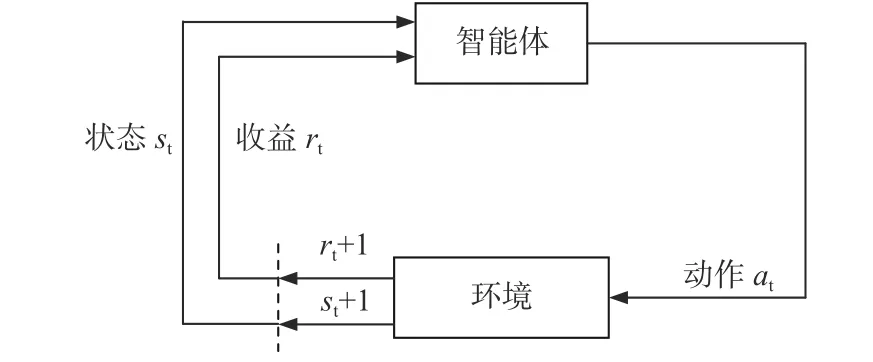
图5 强化学习决策过程中智能体与环境交互Fig.5 The interaction between the agent and the environment in the reinforcement learning decision process
本文的防碰撞系统通过AIS系统实时读取水域内所有船舶的真实经纬度信息,并同步到电子海图中。游船智能体依据当前周围船舶的分布及航道走向、长宽等信息来规划航线。当游船智能体规划的未来航线不可避免地与其他船舶发生碰撞时,防碰撞系统将给出告警提示,指挥中心调度员将对目标船舶进行紧急调度,通过预测航线实现船舶碰撞提前预警、紧急调度的功能,从而进一步保障游船的航行安全。本文模拟的船舶智能体主要通过DDPG算法对周围水域环境数据进行处理,输出船舶未来最佳行驶路径。如图6所示,DDPG算法的设计主要包括在船舶避碰路径规划过程中的状态设计、船舶动作设计和所获奖励值的设计。
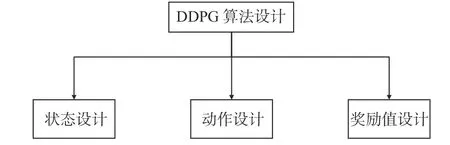
图6 DDPG算法设计框图Fig.6 Block diagram of DDPG algorithm design
1)DDPG算法的状态设计。
强化学习中智能体在决策时需要参考当前智能体自身状态及环境因素。船舶要从当前位置驶向目标点,避碰算法模型需考虑船舶当前的位置、速度、航向、目标点位置以及与周围障碍物之间的距离和方位等信息。
在船舶避碰仿真环境中,船舶的位置、速度及航向通过AIS系统获得;目标点位置的选取依赖于航行水域的环境信息;对于障碍物和其他船的船舶方位、距离等信息,采用模拟雷达的方式扫描周围环境获得。图7所示为模拟雷达的扫描障碍物图。图中,白色区域为水域,灰色区域为陆地,蓝色三角形为船舶,蓝色三角形附近椭圆区域为船舶领域范围。
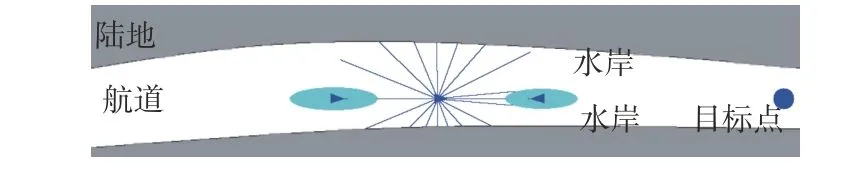
图7 船舶模拟雷达扫描障碍物Fig.7 Scanning obstacles of ship simulation radar
2)DDPG算法的动作设计。
在航行过程中遇到其他船舶或障碍物时,驾驶员通常采取改变航向的方式以避碰。船舶需要在舵的控制下才能改变航向。本文在仿真环境中设定船舶单位时间航向变化量在−θ到 +θ之间。通过对船舶进行直角转弯过程的实测数据分析,航向角变化约为1°/s。因此,本文将 θ设置为1°,使船舶智能体的转向输出更贴近实际情况。
3)DDPG算法的奖励值设计。
船舶避碰路径规划过程可以分为2个部分:一是船舶周围无危险障碍物时驶向目标点;二是船舶存在碰撞危险时进行避碰路径规划。本文使用的DDPG算法的奖励函数设计分别围绕以上内容展开。
图8所示为船舶在无碰撞危险时驶向目标点的学习过程。本文通过比较船舶与航标点形成的角度θ1和 船舶航向θ2来设置奖励函数。
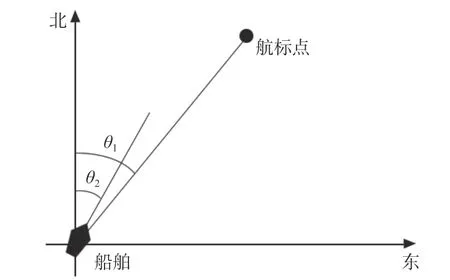
图8 船舶与航标点位置图Fig.8 Map of ships and navigation points
船舶航向θ2可以通过AIS系统获得,船舶与航标点形成的角度θ1可以通过船舶和目标点的相对位置获得。本文设定θ2和θ1的偏差为
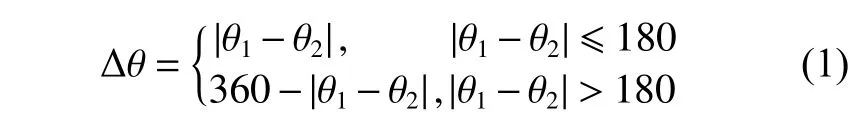
船舶驶向航标点任务的奖励函数设置为r1。经过对大量船舶偏航角的记录统计,发现在该水域正常船舶的偏航角在20°以内。据此,本文设定的偏航角小于20°将给出正奖励值,偏航角大于20°将给出负奖励值。设置船舶r1的值如式(2)所示:
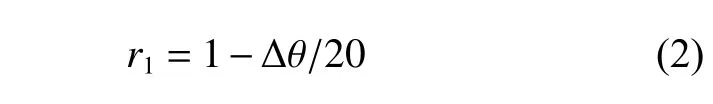
图9所示为船舶完成避碰任务的学习过程。本文通过对模拟雷达扫描获得的测量距离与本船船舶领域的范围进行比较来设计奖励函数,且适应不同的船舶领域模型。图中,线0~17为虚拟雷达探测线。
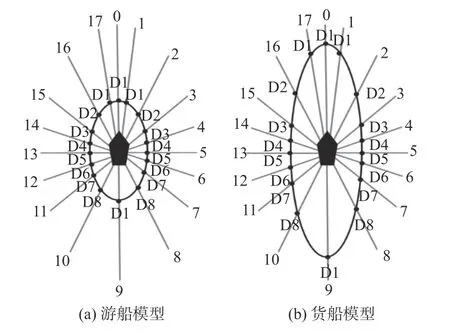
图9 模拟雷达与船舶领域的范围图Fig.9 Range map of simulated radar and ship domain
奖励函数r2根据船舶领域范围设置,表达式如式(3)所示:
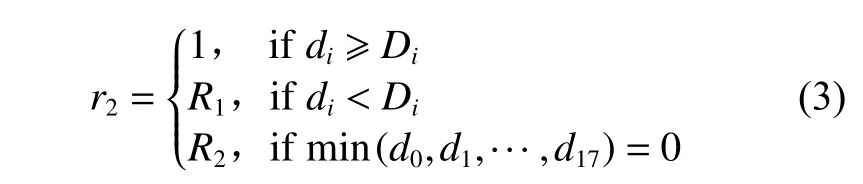
式中:di为图9中模拟雷达线第i条线扫描到障碍物距本船的距离;Di为第i条模拟雷达扫描线与船舶领域的交点距船中心的距离;R1为静态障碍物或他船船舶领域侵入本船船舶领域获得的奖励值。本文设置R1=−5+2min(di/Di),R2为船舶发生碰撞时的奖励值,R2=−50。当发生碰撞时,本回合结束;当无障碍物进入本船船舶领域时,奖励值为0。
(1)当静态障碍物或其他船舶距离本船舶超过2倍船舶领域距离时,代表航行安全,设置奖励值为1。
(3)当静态障碍物或他船舶距离等于0时,代表该与本船舶边缘发生接触,即发生碰撞,设置R2=−50。
由上述的奖励函数设置,再结合对船舶避碰状态的设计,可构建用于DDPG训练的状态s。状态s为{Type,v, θ1−θ2,L,d0,d1,···,d17}。其中:Type为训练船舶的类型,当Type为0时,表示训练船舶为货船;当Type为1时,表示训练船舶为游船:v为本船船速; θ1−θ2为航向偏差:L为本船船长:d0,d1,···,d17为模拟雷达扫描到障碍物距本船的距离。
3 DDPG算法改进
3.1 基于失败区域重点学习的改进DDPG算法
受人类学习过程的启发,针对智能体盲目探索时造成有效数据不足的问题,有学者提出了失败区域重点学习方法,该方法有以下几个要点:
1)失败区域的反复试错学习。
前期DDPG探索中,通过在行为的确定性策略上添加高斯噪声来使算法实现探索的随机性,如式(4)所示:

式中:at为 转向输出;EN为探索随机因子;a′t为具备随机探索性的转向输出。为了更好地得到高质量的训练数据,在DDPG训练过程中添加探索噪声为小幅度噪声,本文所采用的探索噪声如式(5)所示:
国有企业社会保险经济业务集约化管控系统是根据当下我国国有企业的实际需要,通过对单位信息,人员情况以及各个社会保险业务的产生背景的概述,不仅有数据的采集,还有控制业务流程以及分析综述合为一体的管理信息系统。
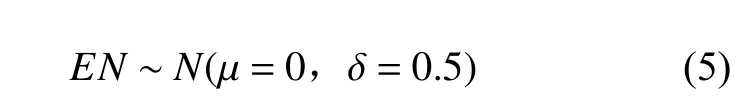
式中,N为随机探索噪声的概率密度函数,其中µ为随机探索噪声高斯分布的期望,δ为方差。
然而,实验显示DDPG算法在失败区域通常反复触发训练结束条件,使得无法获取有效的正样本数据。而且,因网络参数更新的局限性和随机探索幅度小,导致无法跳出失败区域,导致训练停滞。
为提高算法的学习效率,本文在失败区域提高了探索的随机性。在探索过程中,若某个区域重复触发训练结束条件,则增加该区域探索随机性的幅度。鉴于本文采取的动作区间为(−1°,1°),为加大随机探索幅度,将新的探索噪声设计为混合高斯模型,如式(6)所示:
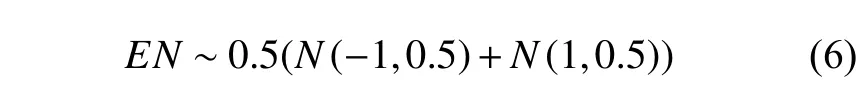
如图10所示,与原噪声相比,混合高斯随机探索幅度区间从[−0.5, 0.5]区间向两侧偏移到[−1.5, −0.5]和[0.5, 1.5],提高随机探索幅度,以加快跳出失败区域,从而获得充足的正样本数据。图中,x表示随机探索幅度,p(x)表示随机探索幅度x的概率密度,
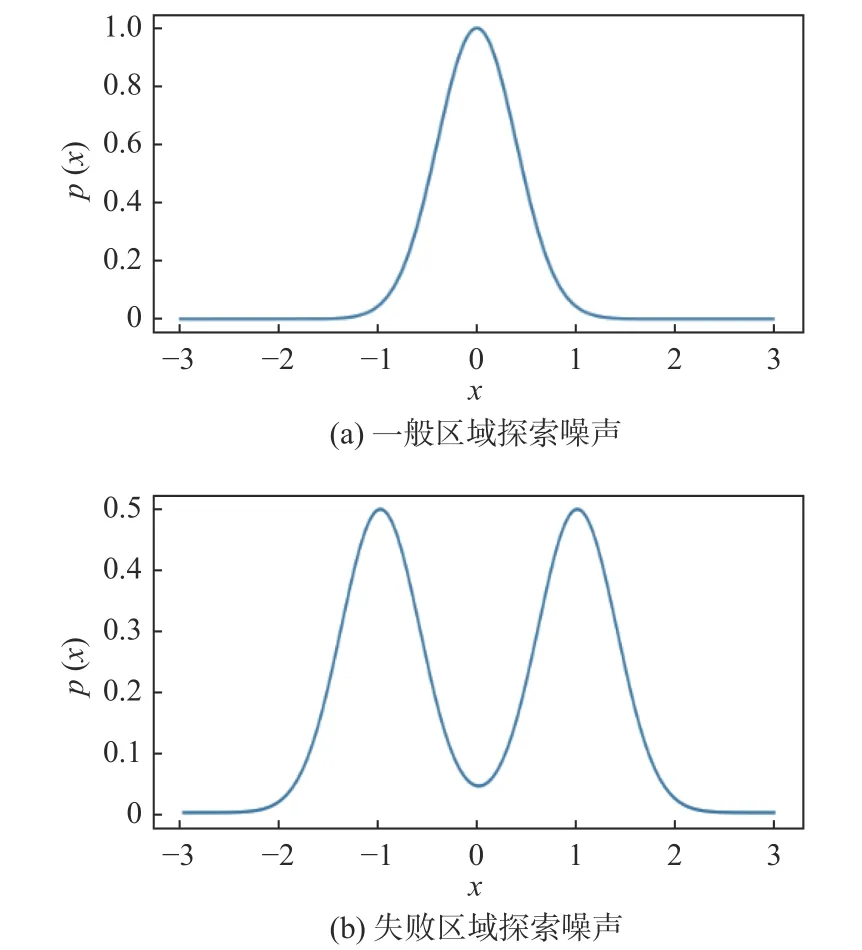
图10 不同区域探索噪声Fig.10 Explore noise for failure areas
在智能体跳出失败区域后,再继续对失败区域进行多次重复探索学习,以积累大量关键节点的成功和失败数据,以及增加经验池中该区域数据的多样性,保持在失败区域正、负样本数量的平衡,进而提高该区域的学习速度。图11为失败区域反复探索学习框图。
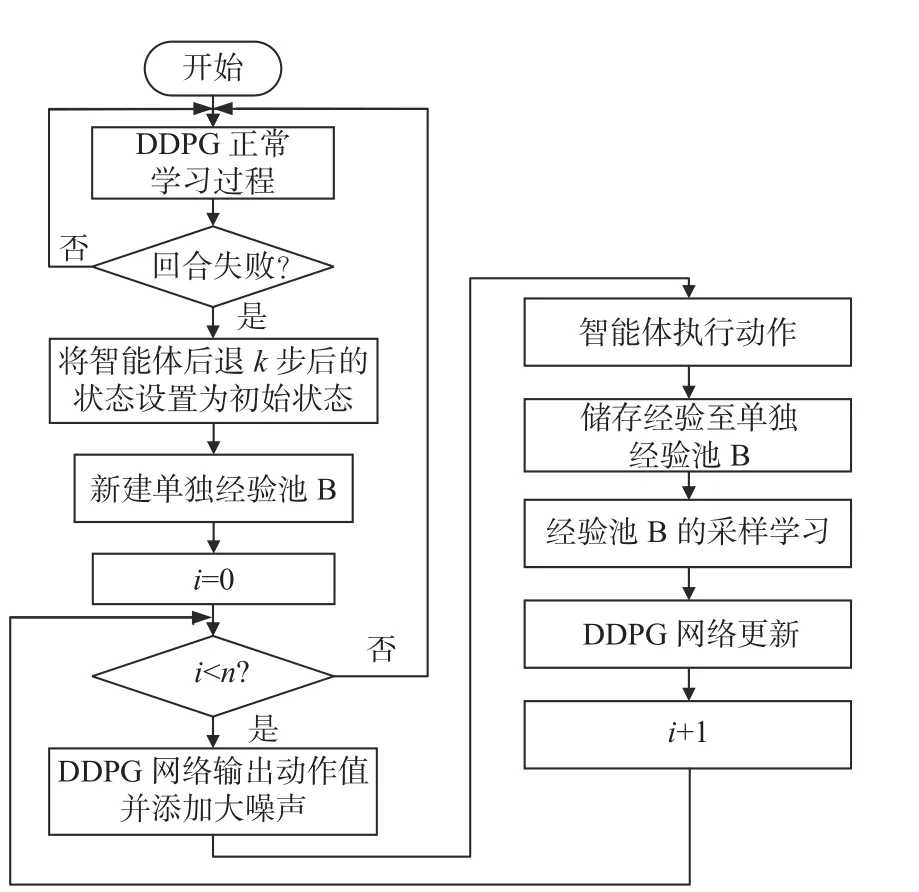
图11 失败区域反复探索学习框图Fig.11 Block diagram of repeated exploration and learning of failure areas
当智能体触碰即训练结束条件时,智能体将回退到前k步位置,在本文中根据船舶智能体行驶步进长度等参数设置k值为300,等效于回退5倍个船舶领域长度。智能体从回退的位置开始,进行失败区域反复试错学习过程,且采用幅度更大的随机探索策略以积累丰富的试错经验,并对此过程产生的数据建立单独的经验池,实现具有针对性的网络参数调整,加快失败区域策略的学习速度。
2)经验池分类。
为进一步增强算法对学习样本中有用数据的利用效率,本文采用了经验池分类的方法将主经验池A的样本数据分为2类:常规样本经验池和重点区域样本经验池。其中,常规样本经验池为正常探索时获得的样本数据,重点区域样本经验池为单独经验池B复制过来的反复试错的样本数据。图12所示为经验池分类采样图。
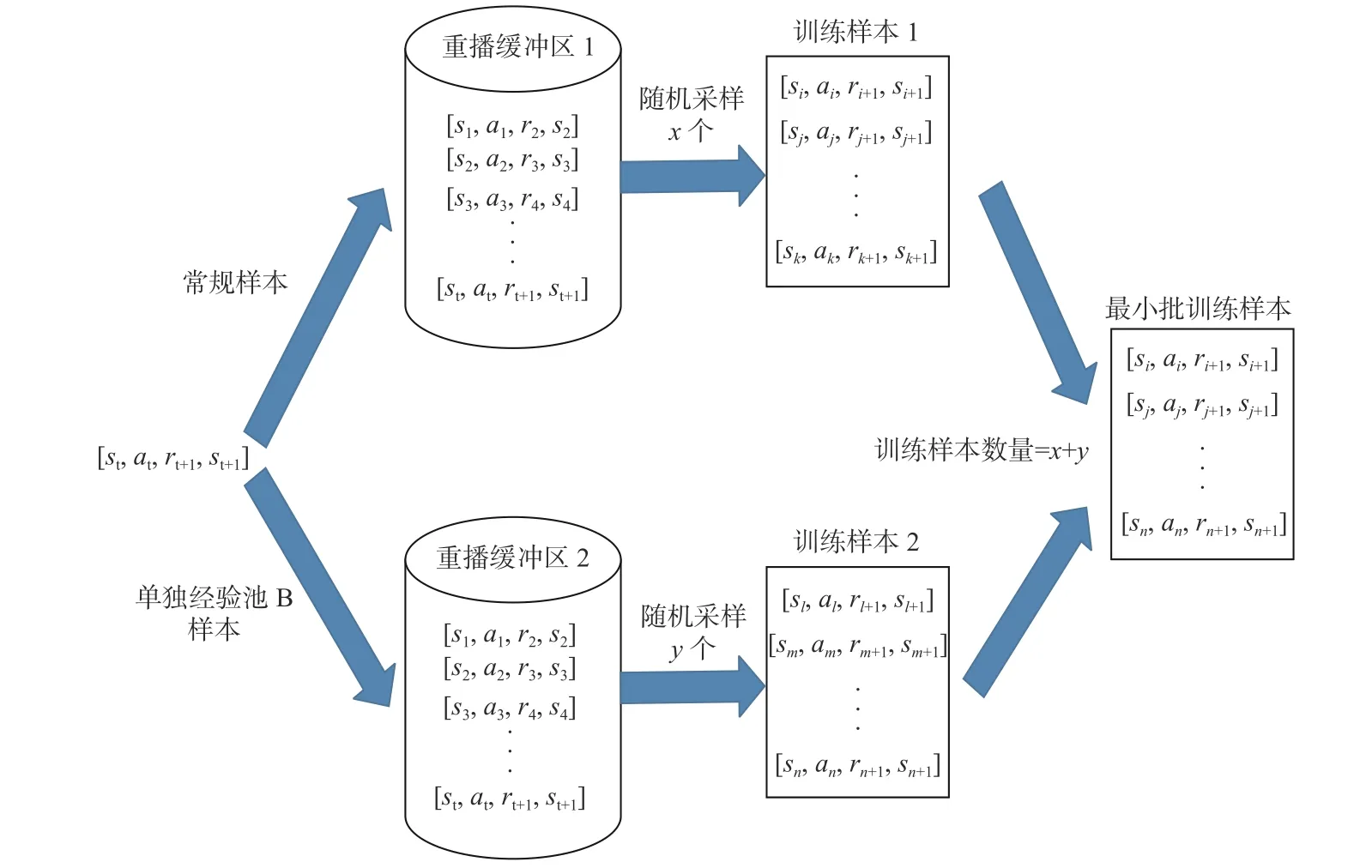
图12 经验池分类采样图Fig.12 Sample map of experience pool classification
3.2 改进算法会遇仿真实验
船舶在航行中会存在与其他船舶航线会遇的情况,这会增加碰撞风险。本文通过DDPG算法建立船舶会遇避碰路径规划模型,实现了船舶在会遇时的避碰路径规划,从而可以保障船舶航行安全。
船舶的会遇态势主要分为3种情况:追越、会遇和交叉相遇。船舶会遇态势图如图13所示。
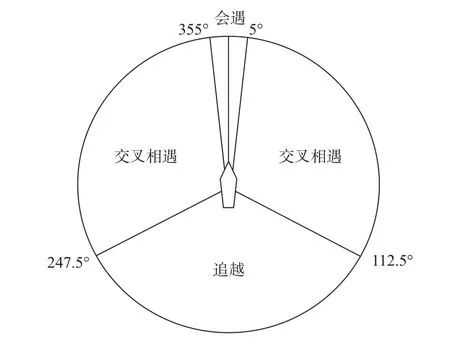
图13 船舶会遇态势图Fig.13 Illustration of ship encountering scenerio
本文的主要应用环境多为狭窄水域,在狭窄水域中会遇和追越的会遇情景居多,故本节主要展示在狭窄水域中船舶会遇和追越的仿真结果。
图14为在水域中船舶会遇、追越、交叉相遇情况下的仿真图,图中的仿真环境建立在16级瓦片地图上。图中,蓝船为仿真船舶,黑船为模拟的会遇船舶,虚线表示航线轨迹,船舶虚影表示其他时刻船舶位置。本次实验为蓝船在会遇、追越、交叉相遇情景下的路径规划,图中数字代表不同时间点,其中1为开始时间点。
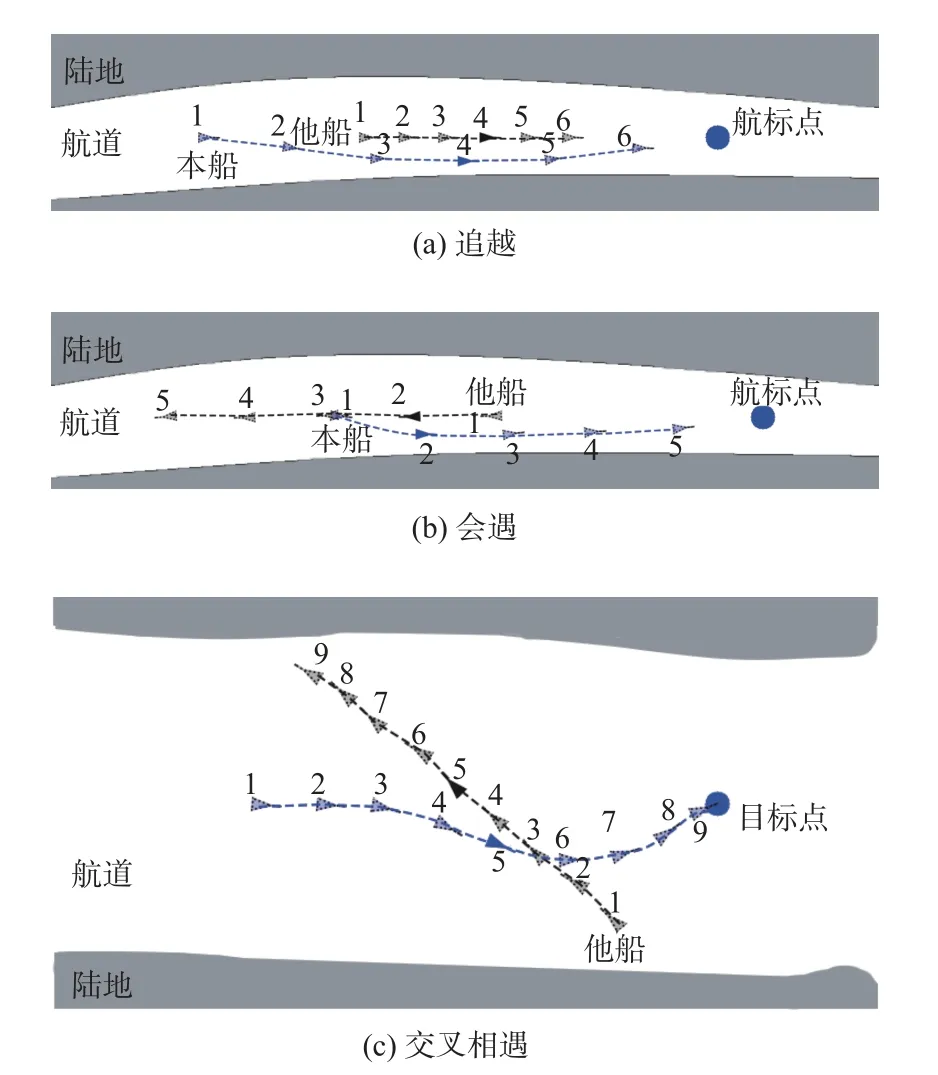
图14 船舶避碰路径规划仿真结果Fig.14 Simulation results of ship collision avoidance path planning
由图14(a)可知,在狭窄水域仿真环境中,船舶智能体可在追越他船的过程中实现避碰路径规划。图中,船舶智能体在时间点1和2之间开始转向避碰;在时间点3~5时与他船在不同航道中并向航行;在时间点6开始驶回原航道,完成追越情况下的路径规划。在时间点2,智能体与他船相距3.24倍船舶领域长半轴距离;在时间点4,智能体与他船舶相距1.35倍船舶领域短半轴距离,未发生侵入船舶领域的情况,追越避碰路径规划符合船舶航行安全要求。由图14(b)可知,在会遇情况下,船舶智能体在会遇的其他船舶未改变航向的情况下进行避碰路径规划。图中,船舶智能体在时间点1~2就开始右转避碰,在2时间点避碰完成后开始驶向航标点,实现对遇情况下的避碰路径规划。在时间点1,智能体与他船相距3.85倍船舶领域长半轴距离;在时间点2,智能体与他船舶相距1.12倍船舶领域短半轴距离,未发生侵入船舶领域的情况,对遇避碰路径规划符合船舶航行安全要求。由图14(c)可知,在交叉情况下,当船舶智能体在时间点3~4时,船舶智能体开始右转避碰;在时间点5时,船舶智能体开始转向并驶向目标点,完成在交叉情况下的船舶避碰路径规划。在时间点3,智能体与他船相距2.68倍船舶领域长半轴距离;在时间点4,智能体与他船舶相距1.45倍船舶领域短半轴距离,未发生侵入船舶领域的情况,交叉避碰路径规划符合船舶航行安全要求。
3.3 原始与改进的DDPG算法比较
为验证改进算法的有效性,本文分别从学习速率和学习效果这两个方面对原始算法和改进算法进行比较。其中,对学习速率的比较主要依据计算达到相同正确率的训练迭代次数;对学习效果的比较主要通过每步平均奖励值,每步平均奖励值越大表示学习效果越好。
图15所示为不同会遇情景下船舶避碰的成功率比较,图中,成功率表示的是每10 000次样本学习后在无噪声条件下测试的成功率。
由图15(a),原始DDPG算法经过14万步学习后才成功学会在不同会遇情景下的船舶避碰;由图15(b),改进DDPG算法在12万步时完全学会避碰策略。改进算法学习速度快于原始算法。
图16所示为每步平均奖励值的对比,从图中可以看出,在算法未完全学会避碰策略时,算法的每步平均奖励值随着训练步数的增加而增大;当算法已基本学会避碰策略时,算法的每步平均奖励值趋于稳定。对比改进DDPG算法与原始DDPG算法每步平均奖励值,容易看出,稳定后的改进算法的每步平均奖励值大于原始算法,即改进算法学习效果优于原始DDPG算法。
由图15和图16可知,改进算法无论是学习速率还是学习效果都优于原始算法。表1为原始算法与改进算法的仿真数据和真实数据对比。
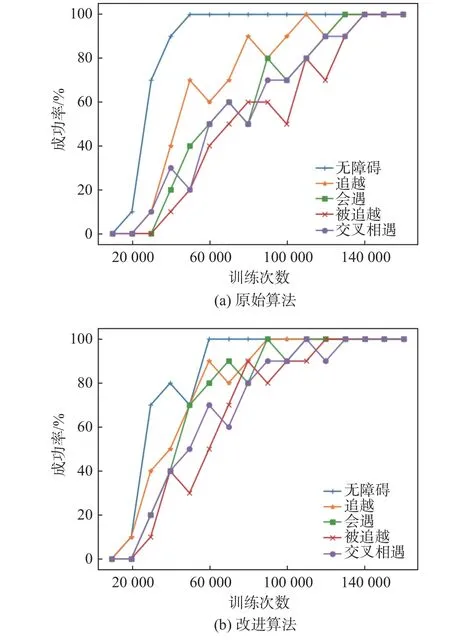
图15 不同会遇情景下船舶避碰成功率图Fig.15 The success rate of ship collision avoidance under different encounter scenarios
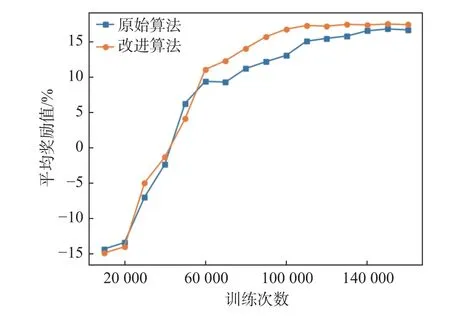
图16 算法的每步平均奖励值对比Fig.16 Comparison of the average reward value of each step of the algorithm
由表1可知,两种算法都能实现避碰路径规划,但相较于原始算法,改进算法的转向正确率提高了4.8%,航迹点的平均距离偏差降低了15.1%。图17所示为两种算法预测路径的对比。由图中可知,改进算法规划的避碰路径更接近于真实的避碰路径,符合一般船舶避碰路径规划场景的要求。
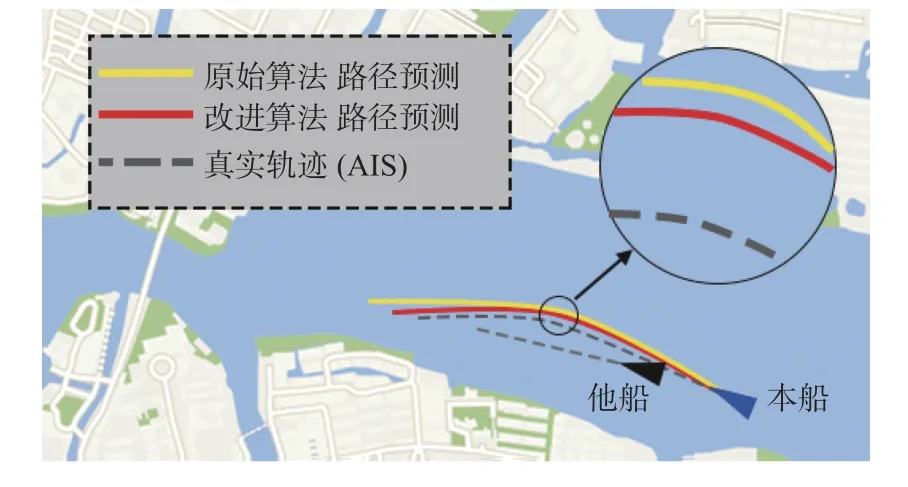
图17 原始算法与改进DDPG算法预测路径对比Fig.17 Comparison of prediction path between original and improved DDPG algorithm
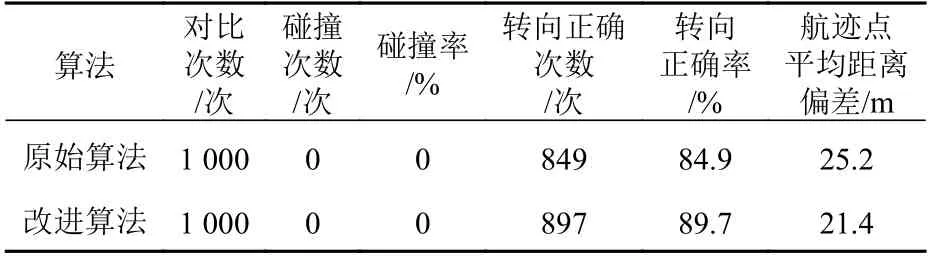
表1 原始与改进DDPG算法的仿真数据对比Table1 Comparison of simulation data between original and improved DDPG algorithms
4 结 语
本文将深度强化学习的DDPG算法与船舶领域模型相结合,利用改进的游船船舶领域模型,提出了基于失败区域重点学习的DDPG算法改进策略。通过仿真实验表明,基于失败区域重点学习的改进DDPG算法无论是在学习速率,还是在学习效果方面都优于原始的DDPG算法。通过对改进的算法预测路径与真实航迹的比较,结果显示,改进算法获得的航迹点平均距离偏差降低了15.1%,转向正确率提高了4.8%。将改进DDPG算法和游船船舶领域模型运用于周庄水域,实现了对游船的避碰路径规划,验证了改进算法在真实水域环境下的可行性。
猜你喜欢
军事文摘(2022年17期)2022-09-24
舰船科学技术(2022年11期)2022-07-15
舰船科学技术(2022年10期)2022-06-17
西江月(2021年3期)2021-12-21
家庭影院技术(2021年8期)2021-11-02
船舶(2021年4期)2021-09-07
科学与财富(2021年35期)2021-05-10
计算机世界(2020年50期)2020-01-15
青年生活(2019年23期)2019-09-10
广东第二课堂·初中(2019年8期)2019-08-13
