
数据聚合与共享技术在电子医疗病历中的应用
2022-01-13 00:51刘佳欣李启康施炎峰柳亚男
南京理工大学学报 2021年6期
邱 硕,刘佳欣,李启康,施炎峰,柳亚男,张 正
(1.金陵科技学院 网络安全学院,江苏 南京 211169;2.南京工程学院 计算机工程学院,江苏 南京 211167)
随着数据存储、计算平台以及移动互联网的发展,我国医疗系统已初具规模,许多医院都建有自己的医疗信息系统,为我国电子医疗病历(Electronic medical record,EMR)的研究提供了市场需求[1]。李克强总理也强调,发展并应用好健康医疗大数据,有利于提高医疗服务效率和质量,促进健康产业发展,改善民生[2]。目前,EMR数据形式复杂多样,医疗大数据爆发,使得对EMR数据的处理已经远远超出传统的信息处理能力。要实现多家医疗机构的信息共享,必须引入创新型的聚类算法,实现对大量数据进行数据聚类分析,将复杂的数据简单化、具体化、类别化。此外,由于我国的人口和地理因素,各个区域尤其是偏远地区医疗设施分配不合理,导致了大量的长尾需求,这也促进了基于EMR数据解决医疗服务问题的相关研究。
随着信息化技术的广泛应用,EMR中记录着病人健康管理过程产生的所有信息,除了包括个人基本信息外,还包括一些健康信息、病史记录、检查结果等,大多数属于不希望被外人所知的敏感信息。一旦信息被泄露,可能使病人遭受社会负面评价、歧视侮辱等不良影响。综上,在对EMR数据进行聚类时,一方面考虑数据聚类的高效性,另一方面考虑聚类后数据共享的安全性。由于EMR具有多样性、不完整性、序列性、多因素影响、多资源信息等数据特点[3],使得对EMR的研究成为一个非常有价值且具挑战性的工作[4]。Jensen等[5]认为,通过对电子病历的数据挖掘可以形成新的患者群体的划分,还能发现疾病之间的相互作用关系;Zhou等[6]提出了Pacifier(Patient record densifier)方法,用于从电子病历中发现患者的表性特征;Liang等[7]通过卷积深度网络对患者的电子病历进行深度特征提取。虽然国外对EMR中的数据挖掘已取得一定的成果,但我国在这方面还有所欠缺[8-10]。同时目前已有的一些数据挖掘技术大都是在医院内部进行的,无法有效地实现数据共享、提升数据的使用率。针对我国还有部分地区医疗水平低的现状,需要结合患者的特点给出较佳的治疗方案。同时,由于电子病历中包含了患者的隐私信息,一旦泄露出去,就会影响患者的个人生活[11-14]。陈鹤群等[12-16]总结了医疗数据共享中的安全与隐私保护技术。
直接通过改进K中心和K均值算法得到动态数据聚类算法,对于处理规模较大的数据具有不可忽视的局限性,比如实时性低、效率低、准确率低等问题[17]。然而传统的近邻传播(Affinity propagation, AP)聚类的局限性在于其无法处理动态数据,这不符合电子病历的需求[18-20]。Sreedhar等[19]采用基于k-centroid的相似度计算实现用户聚类,并利用哈希技术实现对聚类数据的隐私保护;随后,Swathi等[20]提出了优化方案,提升了聚类方案的安全性。但以上方案均无法支持动态数据更新的聚类计算。本文为提高共享效率,考虑EMR中数据聚类后的安全共享问题,主要做了以下工作:结合已有的高效增量式AP聚类算法,实现了对EMR中患者群体的划分;结合快速AP聚类算法,以相似度为标准实现治疗方案的个性化推荐;采用高效的加密算法,实现不同EMR聚类结果之间的共享,从而得到更好的推荐治疗方案,并且保障了数据共享过程中的隐私保护。
1 AP算法
为了使得数据形式更加统一化,提高算法的执行效率,本文对EMR中的数据进行预处理。
1.1 增量式AP聚类
本节中所描述的增量式AP聚类算法基于消息传递式的K中心增量式AP聚类算法。引用了标准AP聚类中常用的吸引度矩阵R和归属度矩阵A作为消息传递的类型。图1为消息传递过程。

图1 消息传递过程图
图1(a)为消息传递的过程,矩阵结点ci表示变量,dj表示函数。图1(b)中ci到dj的连线表示数据对象i将选择的代表点告知代表点j,dj到ci的连线表示j将聚簇的新的代表点告诉i。图1(b)为消息传递的内容,r(i,j)表示吸引度矩阵R中的元素,a(i,j)表示归属度矩阵A中的元素。图1中每一个结点都可以进行消息传递,计算自己得到的消息,并将结果沿着边发给其他结点。变量结点ci的计算公式为

(1)
式中:M={m1,m2,…,mk}是当前代表点的集合,s(i,j)表示数据对象i和数据对象j之间的相似度。式(1)表示对象结点ci根据所得到的消息找到与之最近的1个点作为归属,并将结果告诉函数结点dj。而函数结点dj的计算公式为
(2)
式中:如果i=j,则f(i,j)=1,否则,f(i,j)=0。∑f(ci,mj)s(i,q)表示选择数据对象q作为聚簇j的代表点的相似度之和。式(2)表示聚簇j选择新的代表点。
基于消息传递式的K中心增量式AP聚类算法见算法1。其中,Gt-1表示上一次聚类的数据对象,ct-1表示上一次聚类的结果,Dt表示新的数据对象。当t=1时,采用标准AP聚类算法对G0进行聚类,聚类结果为c0。本算法将用于患者群体划分。

算法1基于K中心的增量式AP聚类
输入:Gt-1,ct-1,Dt
输出:ct
(1)在当前代表点的集合中,为Dt找到代表点,记为c′t
Gt=Gt-1∪Dtct=ct-1c′t
(2)根据式(1)和式(2)进行消息传递;
(3)重复步骤(2)直至收敛,输出ct为聚类结果。
1.2 快速AP聚类
由于电子病历的规模大,引用基于因子图(Factor graph)的快速AP聚类来提高聚类的效率。其主要思想为:对因子图进行压缩和稀疏,最后通过消息传递实现最终的聚类结果。其中,因子图是一种用来描述变量之间关系的概率图,包括函数结点、变量结点和对应的函数关系。在概率图模型中,可以将贝叶斯网络和马尔可夫随机场转换为因子图,可以高效地求得各个变量的边缘分布。首先,在对因子图进行压缩时,本文采用潜在代表点选择法,具体见算法2。
算法2潜在代表点选择算法
输入:相似度矩阵S,压缩比率w
输出:潜在代表点集合M′
(1)每个数据对象作为代表点代表1个小簇;
(2)每个小簇通过因子图算法与其相邻的小簇进行聚类,相似度为每个小簇中代表点的相似度;
(3)相似度最高的2个代表点集合组成1个微簇,融合为1个新簇Cnew。
(4)根据
计算新簇的代表点,其中mnew为新簇的代表点。
(5)如果微簇的数量小于w,则输出新簇代表点集合M′={mnew},否则返回步骤(2)。
其次,由于快速AP中的消息传递经常会导致某一局域的微簇过于密集,代表点数量过多,因此本文采用K近邻(K-nearest neighbor,KNN)算法稀疏相似度矩阵[21,22],即每个数据对象只保存与它临近的k个小簇的相似度,其他小簇的相似度均删除。最后,实现快速AP聚类算法,如算法3所示。
算法3快速AP聚类算法
输入:相似度矩阵S,压缩比率w
输出:聚类结果c
(1)根据输入S、w,执行潜在代表点选择算法,构建压缩后的相似度矩阵S′。
(2)通过KNN算法将S′进行稀疏,得到S″,S″为稀疏矩阵。
(3)构造稀疏因子图,并在其中进行消息传递。
(4)重复步骤(3),直至收敛得到最终的聚类结果c。
经过分析,基于因子图得到的压缩稀疏后的相似度矩阵,可大幅度减少消息在因子图中传递过程中的归属度矩阵和吸引度矩阵中的数据,减少AP聚类过程中的计算量,大大提升了效率。
1.3 数据库预处理
为了解决直接对电子病历数据库中的数据进行处理所造成的浪费计算机资源且效率低的问题,对数据库进行预处理。本文所用的数据库中包含多种信息,如患者信息(身份证号码、性别、年龄、职业、籍贯、居住地、个人病史、家族病史等)、诊断信息(疾病的名称以及严重度)、医嘱信息(治疗期间的用药记录)、治疗记录(患者每个治疗疗程的记录)、治疗结果(治愈、好转、无效果、恶化)等等。
以皮肤癌为例,采用决策树进行保留特征数据的选择。数据库中保留的信息有患者的年龄、性别、职业、疾病严重度,用药的名称、剂量、途径、频次和时间以及治疗方式。本文主要研究年龄为11~75岁的患者,每5岁划分为1个阶段,如:年龄为11~15记为1,年龄16~20记为2,以此类推,直至年龄为71~75记为13。性别为男记为1,女记为0。疾病严重度,“轻度”记为1,“中度”记为2,“重度”记为3。用药名称的预处理见表1,职业的预处理见表2,用药途径的预处理见表3,治疗方式的预处理见表4。
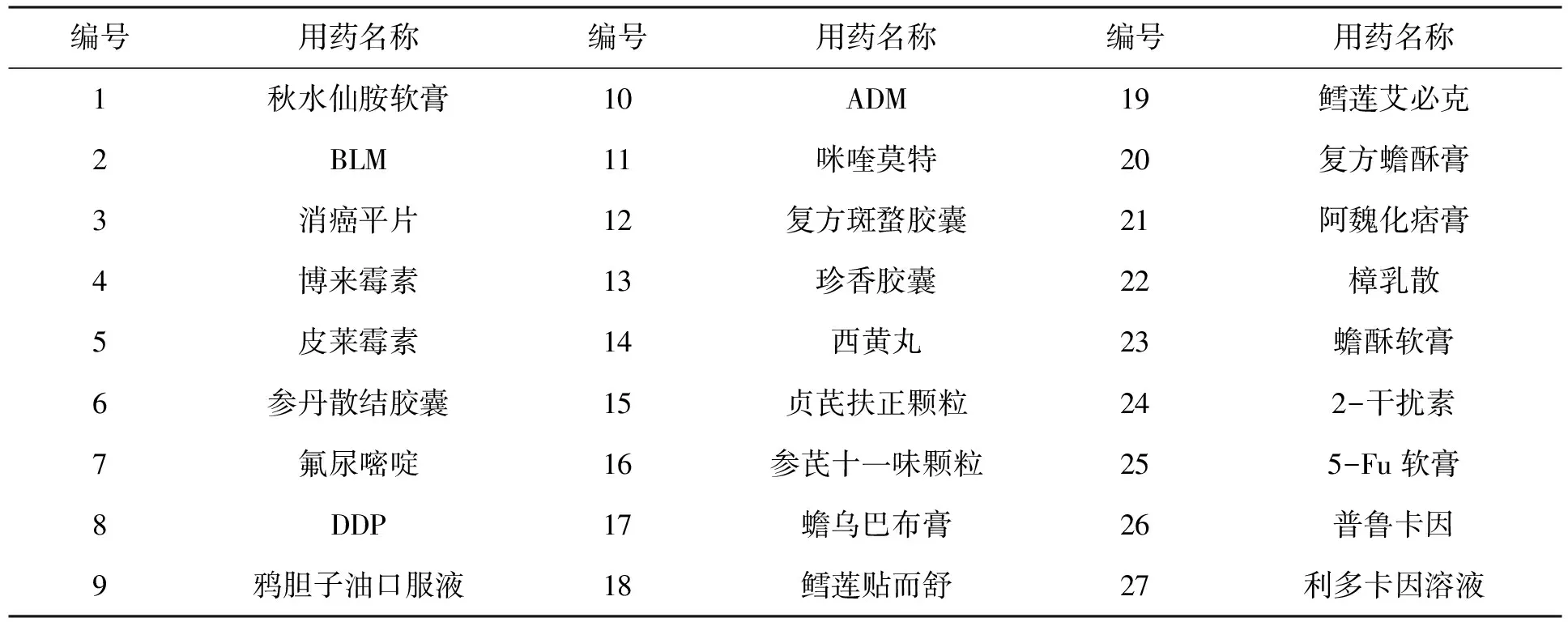
表1 用药名称的预处理表

表2 职业的预处理表

表3 用药途径的预处理表
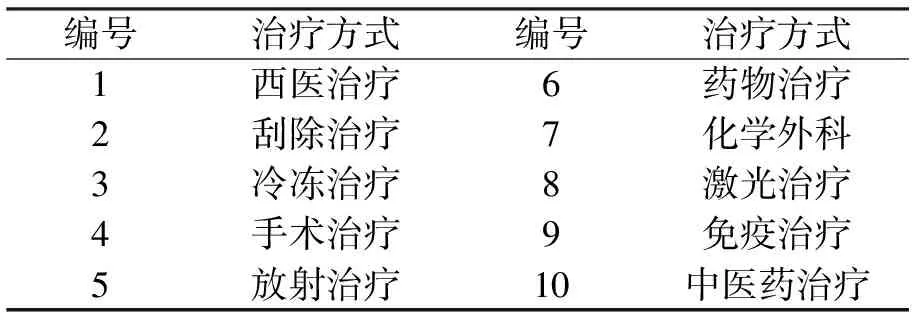
表4 治疗方式的预处理表
2 EMR中的数据聚类
将从2个方面对EMR中的信息进行聚类。首先,对患者的年龄、性别、职业、居住地、疾病严重程度聚类,实现患者类别的划分。接着,根据划分好的患者类别,对患者治疗记录聚类,得到治疗方案,实现为特定类别患者找到个性化治疗方案的目的。聚类流程图如图2所示。

图2 聚类流程图
2.1 患者群体的划分
患者群体指的是具有相似医学特征的1组患者。根据1.3小节中给出的数据库预处理标准,选择年龄、性别、职业、居住地、疾病严重程度共5个属性计算患者之间的相似度。在数据预处理后,若2个特征值相等则记属性相似度为1。若2个患者的性别都为“女”,则记性别属性相似度为1,否则为0。最后患者的相似度取每一个属性相似度的加权平均值。
以相似度为聚类标准进行患者群体的划分。患者群体的划分是一个动态的过程,本文基于增量式AP聚类算法,每隔一段时间,对新加进来的数据对象进行更新,根据聚类结果确定是否产生新的群体,或者判断某个患者是否属于某个群体,实现完整的患者群体的划分。
2.2 典型治疗方案的个性化推荐
治疗方案是指疾病在治疗过程中的药物选择、药物使用方式、药物使用剂量、药物使用频次、药物使用周期以及表4中的治疗方式选择。个性化推荐是指为每个不同的患者群体提供本群落典型的治疗方案。算法核心思想:首先,对治疗记录进行相似度计算;然后,以相似度为参考标准进行聚类,典型的治疗方案即为聚类结果核心区域中的治疗记录;最后,根据划分的患者群体,为指定的患者群体提供较佳的治疗方案。详细算法步骤如下:
(1)治疗记录相似度计算。
根据1.3小节对EMR数据库的预处理,治疗记录的相似度可以近似为用药元素之间的相似度与治疗方式相似度的加权平均值。治疗方式的相似度用ψ(Pqg,Pqh)表示,如果治疗方式相同,则ψ(Pqg,Pqh)=1,否则ψ(Pqg,Pqh)=0,其中Pqg表示记录g中疗程q的治疗方式,Pqh同理。用药元素之间的相似度需要考虑药物名称、用药途径、使用剂量3个方面。
OiqgN表示治疗记录g中的疗程q的用药元素i的药物名称,OjqhN同理。用μ(OiqgN,OjqhN)表示相似度,如果药品名称不同,则μ(OiqgN,OjqhN)=0;否则,还需通过2个因素进一步计算,若用药途径和使用剂量相同,则μ(ΟiqgN,ΟjqhN)=1,否则μ(ΟiqgN,ΟjqhN)=0。OiqgT表示治疗记录g中的疗程q的用药元素i的用药途径,OjqhT同理。用ν(OiqgT,OjqhT)表示相似度,如果相同,则ν(OiqgT,OjqhT)=1,否则,ν(OiqgT,OjqhT)=0。记每日服用药物剂量为DD,每次剂量记为Dosage,每日服用的频次记为Freq。易得DD=Dosage×Freq,2个用药元素之间使用剂量的相似度可以定义为
式中:DDiqg表示治疗记录g中的疗程q的用药元素i的用药剂量,DDjqh同理。因此,2个用药元素之间的相似度定义为
s(Oiqg,Ojqh)=

综上所述,治疗记录的相似度为
(2)快速AP聚类算法。
在海量条治疗记录中,存在一些异常的治疗记录,无法成为聚类的聚簇中心。针对此问题,本文先筛选出这些异常记录,并根据某条记录周围区域的数据密度作为排除条件,治疗记录i周围区域的数据密度可以表示为
式中:γi是与治疗记录Ki最相似的治疗记录的集合。从筛选后的治疗记录中选取潜在的代表记录,并得到矩阵S′。通过S′构建不完全因子图,在因子图上进行消息传递,得到最终的聚类结果。
(3)治疗方案提取。
治疗记录是非常复杂的数据集合,即便这条治疗记录是聚簇中心,也难以用1条治疗记录作为1类治疗记录的代表。针对该问题,本文提取核心区域的治疗方案,首先通过寻找1条治疗记录作为所在簇的代表点,接着在其周围寻找其最近邻,1个簇的中心区域由其代表点和最近邻组成,可以表示为
Corei={Kj|sj,mi≥τi}
式中:Kj表示治疗记录,mi表示第i类治疗记录的代表点,τi是mi与其最近邻的相似度。通过计算各药物在聚簇中的相似度,提取中心区域的个性化治疗方案。
3 隐私保护下聚类结果的数据共享
通过上述聚类算法的结合,可以实现EMR中典型治疗方案的个性化推荐,为患者输出推荐的治疗方案。为了使推荐的治疗方案更具有代表性,不同研究机构之间需要对聚类的结果进行联合研究。由于EMR的敏感性,直接在各医疗机构之间共享数据会泄露患者的隐私信息。结合高效的加密算法,客户端将EMR本地得到的聚类结果进行加密,然后发送给可信的第三方,由第三方对加密后的集合进行交集和并集运算,最后将运算结果返回客户端。
具体系统模型中包含3个实体:2个客户端包括医疗机构Alice和Bob,第三方服务器为Server。Alice(Bob)加密各自得出的聚类集合,并将密文发送给Server;Server收到密文后,首先对密文集合进行并集运算,得到某一疾病在某个群落中尽可能多的治疗方案,为新的治疗提供更多的选择;另一方面也可以对密文集合进行交集运算,得到某一疾病在小范围中的更为精确的治疗方案和病症;最后,Server将得到的结果返回Alice和Bob。具体描述如算法4。
算法4隐私保护下聚类结果的数据共享
初始化:设确定性加密DE={KeyGen,Enc,Dec},α和β分别为Alice和Bob通过
聚类算法得到的聚类结果。Alice和Bob共享对称密钥
sk←DE.KeyGen(1λ)
(1)Alice(Bob)在本地加密集合α和β,得到对应密文如下
TA←DE.Enc(sk,α),TB←DE.Enc(sk,β)
然后将TA、TB发送给Server。
(2)Server对密文集合进行交集与并集运算。由于聚类结果根据提前设定
好的属性顺序,根据确定性加密算法DE的特性,Server可直接对密文集合中
的元素进行相等性判断。设集合TA与TB中的元素个数均为n,表示为
TA={tA,1,…,tA,n}和TB={tB,1,…,tB,n},则对于i=1,…,n,有
Λ=TA∩TB={tA,i|tA,i=tB,i}
Ω=TA∪TB={tA,i∨tB,i|tB,i≠tA,i}
将结果Λ、Ω发送至Alice(Bob)。
(3)Alice(Bob)分别解密Λ、Ω,得到最后的结果。
由于加密算法的隐私性,在对称密钥没有泄露的前提下,第三方平台只能对密文进行操作,无法得到明文的任何信息,保证了数据在运算过程中的安全性。
4 性能分析
本文采用的实验测试环境配置为:服务器和客户端均运行在Linux、64位操作系统、运行内存8 GB、i5处理器、2.50 GHz CPU的配置平台上。测试数据库取样于ipums中的医疗数据库,加密算法采用PBC库中156 bit安全的高级加密标准-密码分块链接(Advanced encryption standard-cipher-block chaining,AES-CBC)加密。
图3为聚类算法的执行时间。从图3中可以直观地看出,在聚类算法中,患者群里划分时间与治疗记录提取时间均随着记录条数呈线性增长趋势,与理论分析保持一致,能够有效地满足实际应用需求。譬如,当记录条数达到104条时,算法能在1 min内执行完毕。图4为隐私保护下数据共享执行时间。

图3 聚类算法执行时间图

图4 隐私保护下数据共享执行时间图
针对聚类后的数据共享,从算法4中可明显看出,共享数据的加解密效率主要取决于AES-CBC算法的效率,密文上的交集与并集运算效率与集合元素个数呈线性关系,执行时间复杂度均为O(n),其中n为聚类集合中数据元素个数。根据图3实验数据显示,当数据集合大小达到107时,其加解密时间在1 min左右,集合的交集与并集运算仅需1 s左右,其执行效率切实可行。
另外,聚类精度是评价聚类结果的更加直观的指标,用来评估聚类结果和真实类别的一致性。根据研究,在大多数情况下,标准AP聚类算法与本文中的增量式AP、快速AP聚类效果基本相当,即数据量一致的情况下,本文的聚类算法与标准AP具有相似的聚类精度[18]。
5 结束语
本文使用增量式AP聚类算法实现了患者群体的划分,并且可以实时更新患者群体。采用快速AP聚类算法,提取典型治疗方案,从而能够为指定的患者群体找到合适的治疗方案。通过数据加密技术,确保了多家医院在共享数据聚类结果过程中的数据安全性。本文根据电子病历的特点,优化了传统的AP聚类算法,提高了EMR数据聚类的效率,实现了隐私保护下数据聚类结果的共享,为科研和临床提供了实际应用价值。但是,本文算法也有一定的局限性,比如在数据聚类中,将用药分析直接归于治疗记录聚类中,这对核心用药的研究造成了一定的困难,也是后续研究的一个方向。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
材料与冶金学报(2022年2期)2022-08-10
温州大学学报(自然科学版)(2022年2期)2022-05-30
粉末冶金技术(2021年3期)2021-07-28
计算机应用与软件(2021年7期)2021-07-16
建材发展导向(2021年23期)2021-03-08
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
读与写·教育教学版(2017年10期)2017-11-10
互联网天地(2016年1期)2016-05-04
南都周刊(2015年4期)2015-09-10
