
面向地址数据基于ISM理论构建数据清洗规则链方法研究
2022-01-13 05:35:34殷滋伟王佳慧马利民
北京信息科技大学学报(自然科学版) 2021年6期
殷滋伟,张 伟,2,王佳慧,马利民,2
(1.北京信息科技大学 计算机学院,北京 100101;2.北京信息科技大学 北京材料基因工程高精尖创新中心,北京 100101;3.国家信息中心 信息与网络安全部,北京 100045)
0 引言
2019年全球爆发新冠疫情,中国借助大数据等技术对感染者、疑似感染者轨迹进行追踪定位,使得疫情得到了有效防控,可见地址数据非常重要。现实生活中存在着大量以自然语言描述的地址数据,由于缺乏对地址及地址模型概念框架的有效研究,导致地址数据格式不统一,数据的存储和管理秩序混乱,造成极大不便[1]。数据清洗最早起源于20世纪50年代,从美国的社会保险号纠错开始[2]。数据清洗能有效提高数据质量,但地址数据不同于一般数据——因复杂的历史、地域、人为因素,其具有易出错的特点,同时海量的地址数据导致数据治理难度更大。
当前对于数据清洗的研究主要集中在数据挖掘、数据清洗效率和清洗框架上,将数据挖掘的方法应用在数据清洗上,采用统计、机器学习的方法来检测和消除脏数据。杨尚林[3]针对多源异构数据存在数据不精确的问题,设计了基于贝叶斯网络和粗糙集属性约减联合清洗模型;郭开彦等[4]用主动学习的方法,利用用户交互,提高数据清洗效率。何俊等[5]利用petri网建立规则链组合模型,提出一种规则链自动组合与检测方法;谢文阁等[6]引入全文索引技术对邻近排序算法(sorted-neighborhood method,SNM)算法进行改进,以此提高重复记录查找的速度和准确率,从而提升SNM算法的性能;张培根等[7]对于传统SNM方法不适合中文数据的问题,引入编辑距离来计算近似度,提高中文数据去重效率;为了解决新兴的众包技术时间和代价成本高的问题,齐志鑫[8]提出知识库优化的众包数据清洗框架COSSET+,并以代价敏感决策树缩小清洗数据的范围,实现按需清洗。对数据清洗框架的研究,潘彬[9]提出了ECL-TL框架,引入中间库将数据清洗和数据转换完全分离,降低各组件之间的耦合度。
中文和西文的地址数据的处理方式不同[10],国外对于西文数据的处理依靠空格和标点符号,对每一个单词进行词干还原和词形还原,如经典的波特算法(Porter algorithm)。而由于中文词语之间没有规范的分隔符,中文数据处理起来非常困难[11]。国内对于地址数据的研究主要在地址分词上。因为地址数据的组成要素复杂多元,造成地址分词十分困难。中文分词的方法主要分为3类:1)基于统计的分词方法;2)基于词典的方法;3)基于语义的方法。梁东阳[12]基于统计的思想,通过自然语言处理技术结合地址词典,合理推断出用户想要的地址。赵成等[13]利用中文地址词典结合逆向最大匹配算法实现中文地址分词。李晓林等[14]提出一种基于地址语义理解的地址位置信息识别方法,不依赖地名词典和词性标注。但是以上研究都是针对比较完整的地址数据进行的。对于非规范的地址数据,许也等[15]提出了一种条件随机场的非规范化中文地址解析方法,实现对地址要素的自动解析。李晓林等[16]采用“路”特征词来提取信息,并通过行政区划字典和移动窗口最大匹配算法来进行地址的匹配。以上方法只能针对特定的场景,且只是对地址进行分词等操作,不能满足当前地址数据准确的数据解析和门牌级用户关联。
数据清洗是检测数据中存在的异常数据(如错误数据、缺失数据和不一致数据等),并纠正和补全以提高数据质量的过程。当前数据清洗规则的研究多是面向特定领域、结构相同或者相似的数据集,可重用率低,可扩展性差。而对于地址数据,组成结构复杂,处理难度增大。随着业务场景越来越复杂,数据组成要素增多,数据清洗规则之间由于操作的字段存在相关性,造成数据清洗规则逻辑相关,主观分析的执行顺序对于场景复杂的数据清洗场景,容易出现执行顺序的逻辑冲突,从而造成数据清洗质量降低。
本文以北京某燃气公司数据关联项目为背景,展开以下工作:分析地址数据,结合地址数据的特点,构建多层次语义模型和地址规则库;采用解析结构模型(interpretative structural modeling method,ISM)对数据清洗规则的执行顺序进行建模,推导和建立无冲突的规则链;最后通过实验,对比传统顺序执行方法和本文的基于ISM理论推导规则链执行方法,验证方法的优越性。
1 解析结构模型
解析结构模型ISM是系统工程较为成熟的理论。它能根据系统各要素的关系来对系统进行分析和建模,从而解决实际问题。
ISM是结构模型中的静态定性模型,构建过程如图1所示。它的基本理论是图论的重构理论,通过一些基本假设和图、矩阵的有关运算,得到可达性矩阵,然后通过人机结合,分析可达性矩阵,使复杂的系统分解成多级递阶结构形式。这种思想与将规则之间的二元关系转化为多元关系从而构造无冲突规则链的思想非常契合,所以本文将基于ISM来进行规则链的推导。
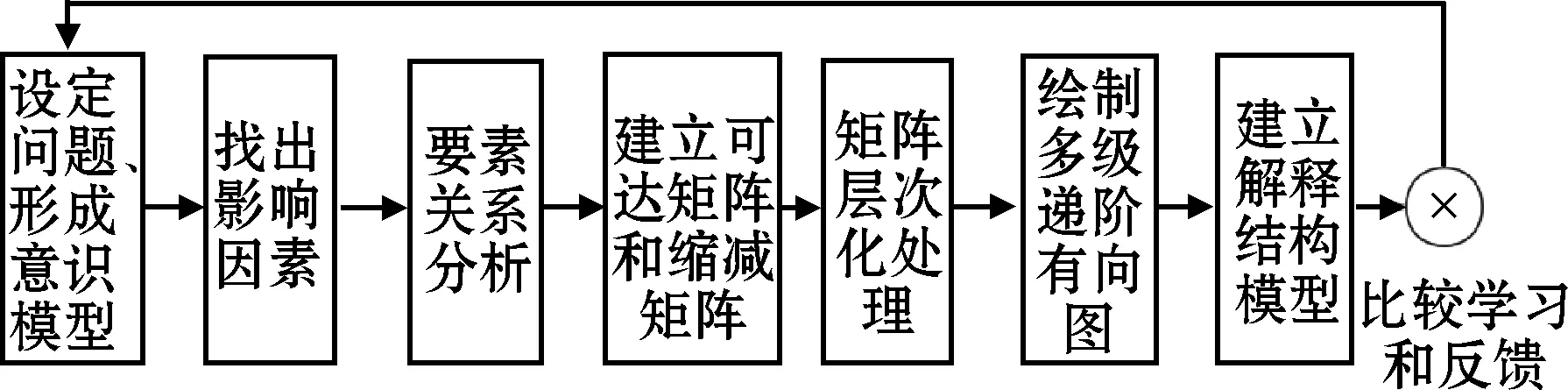
图1 结构模型构建过程
2 地址规则库建设
2.1 多层要素地址语义模型
随着社会经济的发展,基于位置的服务(location based services,LBS)广泛应用在日常生活的方方面面。地名地址数据作为最常用的社会公共信息资源之一,是政府行政管理、经济建设中不可或缺的基础信息资源。所以加快建立涵盖各行业各专题数据的标准地址库有着重要战略意义[17]。根据国内的研究,学者们普遍认为中文地址要素排列是基于层次关系的模型[18]。根据国家标准GB/T23705—2009[19],中文地址的粒度宜分为行政区域、基本区域限定物、局部点位置 3 个层次。规范的地址应准确地将人类日常生活的位置描述与实际地理坐标相对应。而地址是融合地理坐标和地址要素的综合体。对地址数据的解析是对地址要素的识别,是把地址要素和要素的关系结构从地址数据中提炼出来作为唯一识别地理位置的过程。
由于地域、时间的问题,地址模型难以统一。以北京市居民地址为例,大部分用房住户的地址如“北京市—区—街道—小区—楼—单元—户”的模式,但是部分地址存在要素缺省的情况,街道划分复杂,居民住宅类型多样。由于缺乏基于小区的标准的地址字典,基于门牌级的地址匹配非常困难。图2为多层语义模型图,对地址特征进行分析,地址要素的解析不能完全统一,需要建立多层次的要素语义模型,对地址要素进行分级管理,来对地址数据进行规范,预防出现地址要素缺省、冗余的问题。

图2 多层语义模型
2.2 地址规则库构建流程
地址数据是泛化的地理数据,包括文字描述和位置描述,即语义地址信息和空间地址信息[20]。为加快和整合市政府各部门和单位的地址信息资源,实现数据共享和信息交换已成为迫切要求。地址信息由于在不同业务系统中来源不同,容易出现数据的孤立,难以形成标准的管理格式和准确的定位,导致地址信息难以共享利用以挖掘有用的信息。
地址编码是建立地址描述与坐标对应关系的过程[21]。而地址数据不能完全跟地理位置一一对应的原因如下:1)规范的地理命名技术尚未普及,地址数据缺乏统一命名规范;2)缺乏规范的分隔符,难以对要素进行切割;3)由于历史和地域原因,地名存在别名;4)人为因素,存在缩写、错写、要素缺失、要素错位等问题。
地址匹配技术将一般描述的地址数据转换成对应的地理空间信息,从而实现空间信息和社会经济信息的整合[22]。人为获取的地址数据存在大量的问题,数据的使用效率低,需要对数据进行清洗和标准化后,借助地址匹配技术进行关联。对于大规模数据、复杂数据需要建立规范的数据处理规则集。
地址规则库构建流程如图3所示。对于多源地址数据需要进行标准化的处理,建立统一的语义库,实现统一的地址标准库。
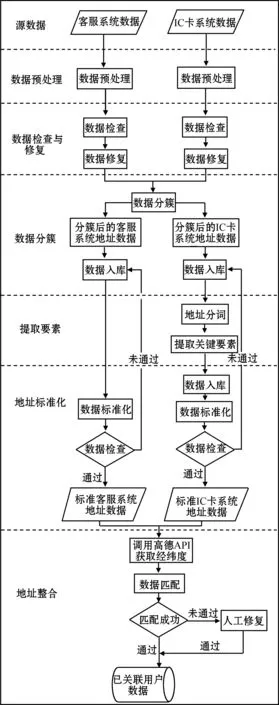
图3 地址规则库构建流程
2.2.1 数据预处理
对待进入数据清洗系统的源数据做数据解析。对数据进行摸底抽查,了解数据的基本情况,如数据缺失情况、元数据情况等,以确定字段操作范围、字段优先级和规范其数据格式,方便数据正确地读入和进行下一步处理。
2.2.2 数据检查与修复
对地址分词和其中关键要素进行抽取,从而提高数据的利用率。数据检查是对地址数据中重要字段数据缺失、错误数据的筛选和标示。数据修复是对对应的数据问题通过特定的方法进行完善和修改,以提高数据利用率。
2.2.3 数据分簇
对处理后的数据按照关键地址要素划分成小区域数据集,缩小地址关联比对范围。本文关联通过小区名进行聚簇,将数据按照小区名称划分。
2.2.4 提取要素
按照本文2.1部分提出的多层级地址语义模型,地址通过小区名聚簇,以“院(或分区)+楼栋+单元+户”进行地址要素数据的提取。地址的组合方式不是唯一的,对不规范的地址按照地址组成要素的层级进行分词以提取其中的结构化的语义信息,如“28楼”、“3单元”、“301户”,从而实现对地址要素进行结构化的存储。
2.2.5 地址标准化
对提取出语义信息的地址要素及其他关键信息中存在的脏数据进行处理并对数据问题进一步核验。地址标准化实现关键要素缺失补全、要素内容格式标准化、去除特殊字符等,从而对数据不规范问题进行纠错,以保证地址数据格式统一,内容完善,从而提高地址整合精度。
2.2.6 地址整合
按照地理、语义信息的聚合,把地理属性相近、语义特征相似的地址进行关联匹配。地理属性通过调用地图API获取经纬度,地址的相似度通过计算获得地址向量的余弦值来做判断。语义信息通过计算和比较地址关键要素数据的编辑距离来进行关联匹配。
3 基于ISM构建规则链
数据清洗是对数据集中的脏数据进行规范。数据集中的清洗规则由多个规则组成,规则集为S={R1,R2,…,Rn}。规则的执行顺序需要考虑规则之间的逻辑关系。一定场景下,地址数据清洗的执行顺序可以是“全角转半角→地址楼号缺失及补全→去除楼号、单元号、门号字段完全相同的数据”,如果改为第二条最先执行,则存在全角半角格式不一致导致程序操作报错而无法执行下去的情况;如果规则三先于规则二执行,则会存在数据缺失修复后仍有可能存在地址多要素重复的情况,需要重复执行第三条规则。所以数据清洗规则存在关联性,对于规则数量少、情况比较简单的问题,人为判断规则的执行顺序简单有效,但是当数据清洗问题比较复杂、数据量较多时,人为主观判断容易造成清洗规则逻辑冲突,数据清洗效率非常低,数据质量差。所以需要借助ISM对规则的执行过程进行建模,将规则之间的关系通过邻接矩阵进行描述,对规则按照层间要素划分层次关系,构建最优的数据清洗规则链,以解决数据清洗人力成本高、效率低、出错率高的问题。
本文采用ISM理论构建有向图从而生成规则链,具体包括构建可达矩阵、区域划分、级位划分、骨架矩阵提取和多级递阶规则链生成等步骤。
1)建立清洗规则集S={R1,R2,…,Rn}的邻接矩阵A=(aij)n×n。其中:
2)建立可达矩阵M=(mij)n×n,其中:
可达矩阵M可通过邻接矩阵与单位矩阵的布尔矩阵运算法则计算得到:
M=(A+I)t=(A+I)t+1≠(A+I)1≠
(A+I)2≠…≠(A+I)t-1
当t=1表示Ri自身可到达,即规则满足自反性;当t≥2表示Ri与Rj经传递可达。
3)集合划分独立区域。求得可达集R(Ri)、先行集A(Ri)、共同集C(Ri)、起始集B(Ri),按照起始集要素是否有交集划分区域P1、P2、…、Pm。
判断规则集之间是否分层。如果B(Ri)为空,则只有一个区域;如果不为空,就判断起始集B(Ri)中的规则及其可达集R(Ri)是否独立可以分割。判断的标准是,起始集∀Ri,Rj∈B(Ri)满足:
①如果R(Ri)∩R(Rj)≠Ø,Ri、Rj及R(Ri)、R(Rj)属于同一区域,区域不可分;
②如果R(Ri)∩R(Rj)=Ø,Ri、Rj及R(Ri)、R(Rj)不属于同一区域,对应R(Ri)、R(Rj)可以分割成至少两个区域。
4)级位划分。L0=Ø,S0=S,Lj={Rk∈Sj-1|Cj(Rk)=Rj(Rk)},Sj=Sj-1-Lj。对每个区域Pm提取R(Rk)=C(Rk)的Rk作为第一级,然后依次去掉上级提取的Rk;对剩余规则循环这一过程,直至所有区域和要素划分完毕,即Sj=Ø,按照分级顺序构造重组可达矩阵M′。
5)提取骨架矩阵。对上面的可达矩阵进行缩减和检出,对强连接要素保留同级的一个要素,其他同级进行剔除,并去掉要素间的越级二元关系和单位矩阵,构造新的矩阵M″。
6)生成多级递阶有向图。根据规则链的邻接矩阵,按照层次连接规则,强连接规则关系平等,顺序不分先后,所以按编号插入,最终得到规则链S。
基于ISM理论推导规则链及按照规则链顺序进行数据清洗的流程如算法1和算法2。
算法1 基于ISM的规则链生成算法
输入:规则集合S(R1,R2,…,Rn),邻接矩阵A,各规则的先行集A(Ri)、共同集C(Ri)、起始集B(Ri),可达集R(Ri)
输出:规则链
1.M=(A+I)t≠(A+I)t-1;
2.i=0;
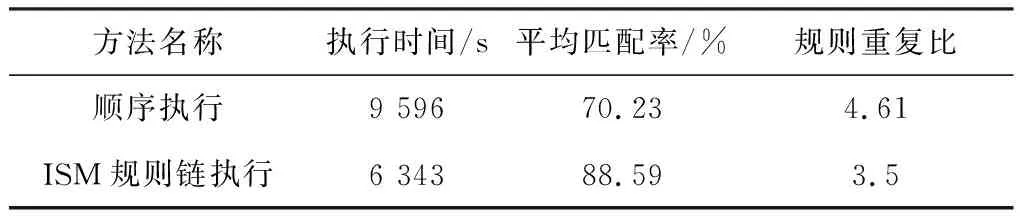
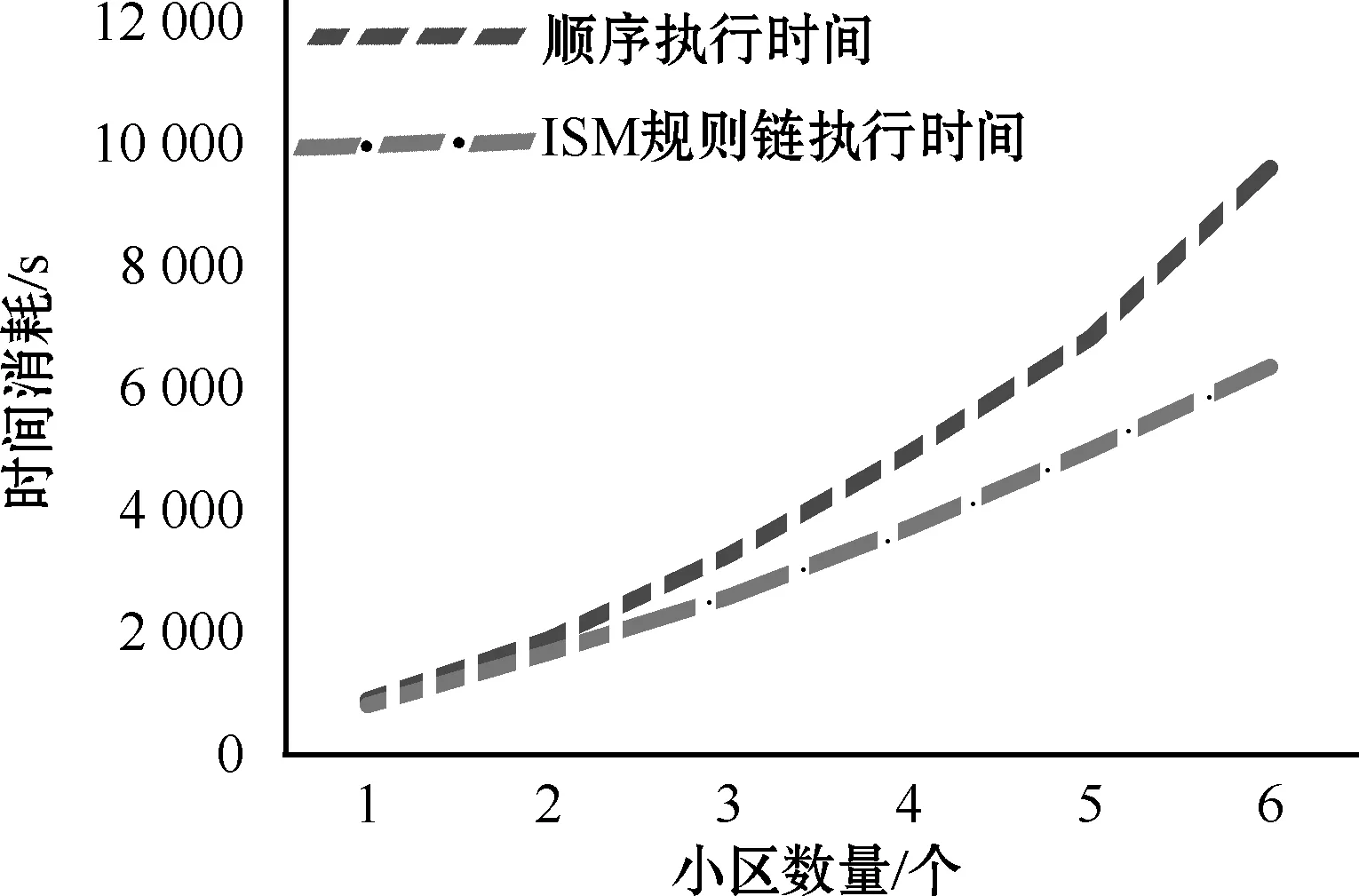
3.whileRi∈S and i 4. if B(Ri)≠Ø: 5. Pt[]add (Ri); 6. i++; 7.end do; 8.P ={}; 9.if Pt!=[]: 10.p=0,q=0; 11.while Rp∈Pt and p 12. while Rq∈Pt and q if R(Rp)∩R(Rq)=Ø: 13. P add(R(Rp),R(Rq));//划分独立区域 14. else P add(S); 15. p++; 16. q++; 17.end do; 18.L0=Ø,S0=S,m=1,x=1,j=1; 19.while Pm∈P and m 20. while Rx∈Pmand x 21. if Pm≠Ø: 22. Lj={Rk∈Sj-1|Cj(Rk)=Rj(Rk)}; 23. Sj=Sj-1-Lj; 24. x++; 25. j++; 26.m++; 27.M′=check(M);//重组可达矩阵 28.M″=check(M′);//提取骨架矩阵 29.seq add(Ri);//将骨架矩阵转化为队列 30.end 算法2 基于规则链的数据清洗 输入:原始数据集data,规则集合S(R1,R2,…,Rn),规则链S 输出:干净的数据集data′ 1.i=0; 2. while Ri∈S and i 3. find(Ri); 4. configure(Ri)://配置规则 5. data′=CleanRule(Ri,data′); 6. i++; 7. end 实验以北京某燃气公司真实用户数据作为数据集,以Pycharm作为实验平台,对11 717户居民地址数据进行分析和建立地址规则库。规则执行顺序采用顺序执行和基于ISM推导的规则链执行两种方法。顺序执行方法规则采用主观组合的方式,相对于基于ISM推导的规则链执行顺序缺少一致性验证。实际执行结果如表1所示。 表1 两种方法对比 实验证明,基于ISM理论推导的规则链清洗时间低于传统的顺序执行方法,并且随着小区数量及用户数据的增加,执行时间优势更加明显,两种方法时间对比如图4所示。其核心原因是基于ISM推导的规则链执行方法的规则复用率更低,降低了规则之间逻辑关联的影响,执行时间更少,从而提高了清洗效率。 图4 两种方法时间对比 本文提出了一种基于ISM理论推导生成规则链的方法。通过建立数据清洗规则库,对规则库中规则的逻辑关系采用ISM的方法进行建模,构造无冲突的规则链。对比顺序执行方法和基于ISM推导的规则链执行方法,验证了后者匹配率更高,执行速度更快,规则复用率低,能有效地降低规则之间的逻辑冲突,从而提高数据处理的准确性。之后将针对如何降低规则的重复比和规则的可扩展性进行研究,以进一步提高数据清洗的效率。4 实验
5 结束语
猜你喜欢
小猕猴智力画刊(2022年3期)2022-03-29 01:09:42数学小灵通(1-2年级)(2021年4期)2021-06-09 06:26:14当代水产(2020年4期)2020-06-16 03:23:30开放教育研究(2020年2期)2020-03-31 01:54:14现代园艺(2017年22期)2018-01-19 05:07:22Coco薇(2017年11期)2018-01-03 20:59:57河北书画研究(2017年1期)2017-08-22 12:11:50暨南学报(哲学社会科学版)(2016年9期)2017-01-15 13:52:02现代语文(2016年21期)2016-05-25 13:13:44山东青年(2016年2期)2016-02-28 14:25:36
