
基于数据湖的环境大数据存储模型
2022-01-13 06:29卢华明
北京信息科技大学学报(自然科学版) 2021年6期
李 硕,卢华明
(北京信息科技大学 信息管理学院,北京 100192)
0 引言
环境大数据的应用目前还处于起步的阶段[1],面临着一系列挑战:环境管理信息系统已经积累了一定数量的环境数据,但数据往往分散地存储在多个信息系统,存在数据孤岛现象;在物联网技术的发展下,资源环境大数据的类型不再仅仅局限于传统的结构化形式,更多的是以文本、项目报告等半结构化与非结构化的形式来呈现;多种数据来源的存储没有统一的技术规范,存储同一种数据的格式不尽相同,存在大量的异构化数据[2]。
针对相关领域结构化、半结构化和非结构化等异构数据增加,数据来源越来越多元化的现状,James Dixon提出数据湖作为一种大数据存储处理和共享服务机制[3]。数据湖是一种能够保存数据原始格式的新型存储架构[4-6],它将所有结构化和非结构化数据存储在一个集中式存储库中,支持分布式地存储海量的结构化数据、半结构化数据和非结构化数据。Sawadogo P.等[7]总结了一种数据湖的3层存储治理模型,数据湖设计成原始数据层、处理层和访问层。针对相关领域大数据多源异构特性,Joseph Mesterhazy等[8]搭建了数据湖用于存储医学影像,使得研究可以快速周转。Chao-Tung Yang等[9]提出将Spark应用于搭建电量使用数据湖。刘志勇等[10]构建了电信数据的数据湖架构,可将原始数据总体压缩44%。亚马逊、微软、阿里云等国内外领先云计算与人工智能企业基于数据湖技术需求,分别提出了AWS Lake Formation、Azure Data Lake、阿里云云原生数据湖分析(data lake analytics,DLA)等技术。相关研究表明DLA相较于Spark,在同等性能条件下成本可节约90%[11]。
目前,对于环境领域大数据的存储管理问题,张文信等[12]对数据的集成及应用提出了较为系统的建设思路,仲阳等[13]科学分析了自然资源数据生产加工现状,提出以数据湖为核心的数据组织体系构建框架。然而开展环境大数据挖掘分析研究需要数据驱动,一方面数据所占用的存储空间与日俱增,另一方面对查询速度和响应时间有更高要求。本文提出了一种基于DLA的数据存储模型,将数据湖应用于环境大数据,研究构建多源异构数据存储策略,在存储空间和查询时间2个方面进行实验验证。
1 环境数据源分析
环境数据来源多样、类型复杂、结构多种,本文分析选取的环境数据源包括空气质量数据、水质数据、实时人口位置数据、联合国贸易统计数据库UN Comtrade等数据源。对已有环境数据从4个维度进行归纳总结,如表1所示。
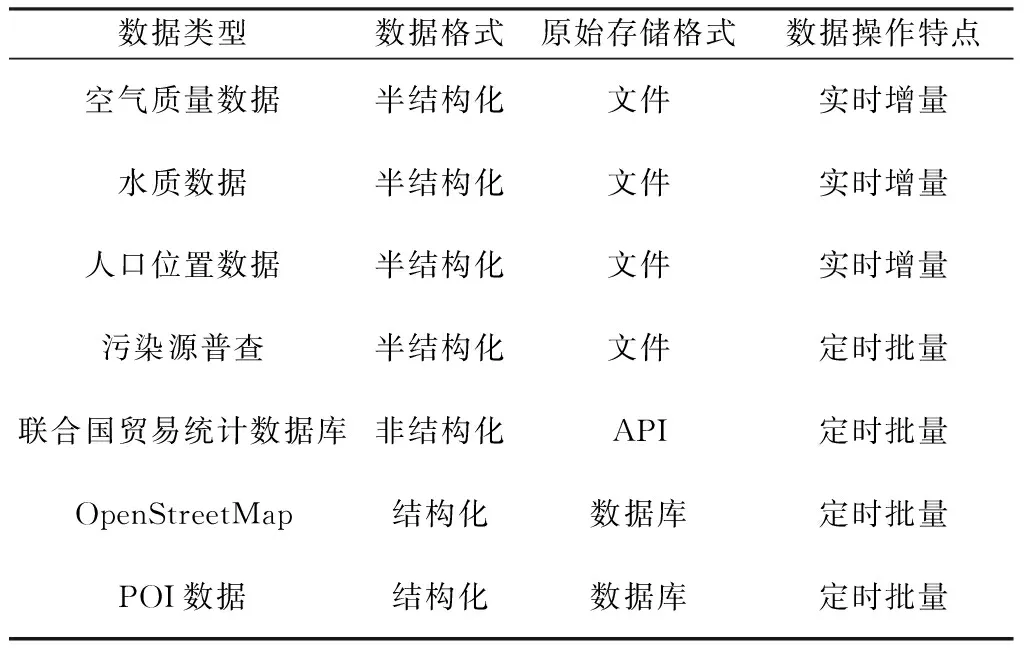
表1 环境数据类型分析
2 数据湖存储总体框架
2.1 数据管理架构
针对环境大数据多源异构的特点和数据孤岛问题,本文在对环境数据组成进行数据源分析的基础上,提出环境数据存储的资源管理层、存储层和分析层的3层数据管理架构,存储模型如图1所示。为适应环境大数据具有的增长变化快和数据来源种类众多的特点,在Fatemeh Nargesian等[14]提出数据湖作为数据的中间存储层的基础上,基于函数计算实现了事件驱动的数据采集获取,使用对象存储统一了数据存储层。
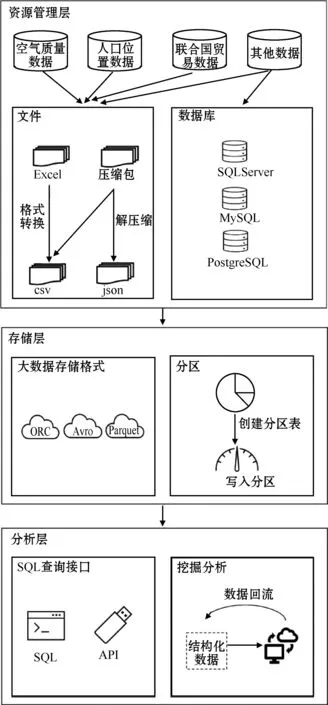
图1 数据湖存储模型
2.1.1 资源管理层
DLA原生支持csv、json等文件格式,也支持关联MySQL、PostgreSQL等关系型数据库,针对多源异构的环境数据,在资源管理层采用Python脚本等方式完成数据处理,环境数据流入数据湖。
2.1.2 存储层
使用对象存储技术支持多种数据格式的存储,采用Avro、Parquet等为大数据优化的数据格式缩短数据查询时间和节约存储空间,应用分区存储策略将开放存储服务(open storage service,OSS)存储层数据与数据湖建立映射。
2.1.3 分析层
数据湖采用读时模式,已建立好挖掘关联关系的数据回流到数据库等结构化或关系型存储,同时支持Flink等计算模型直接访问存储层。
2.2 数据流入数据湖
在资源管理层实现环境数据从其他数据源到数据湖的迁移,即数据流入数据湖。数据处理流程如图2所示。
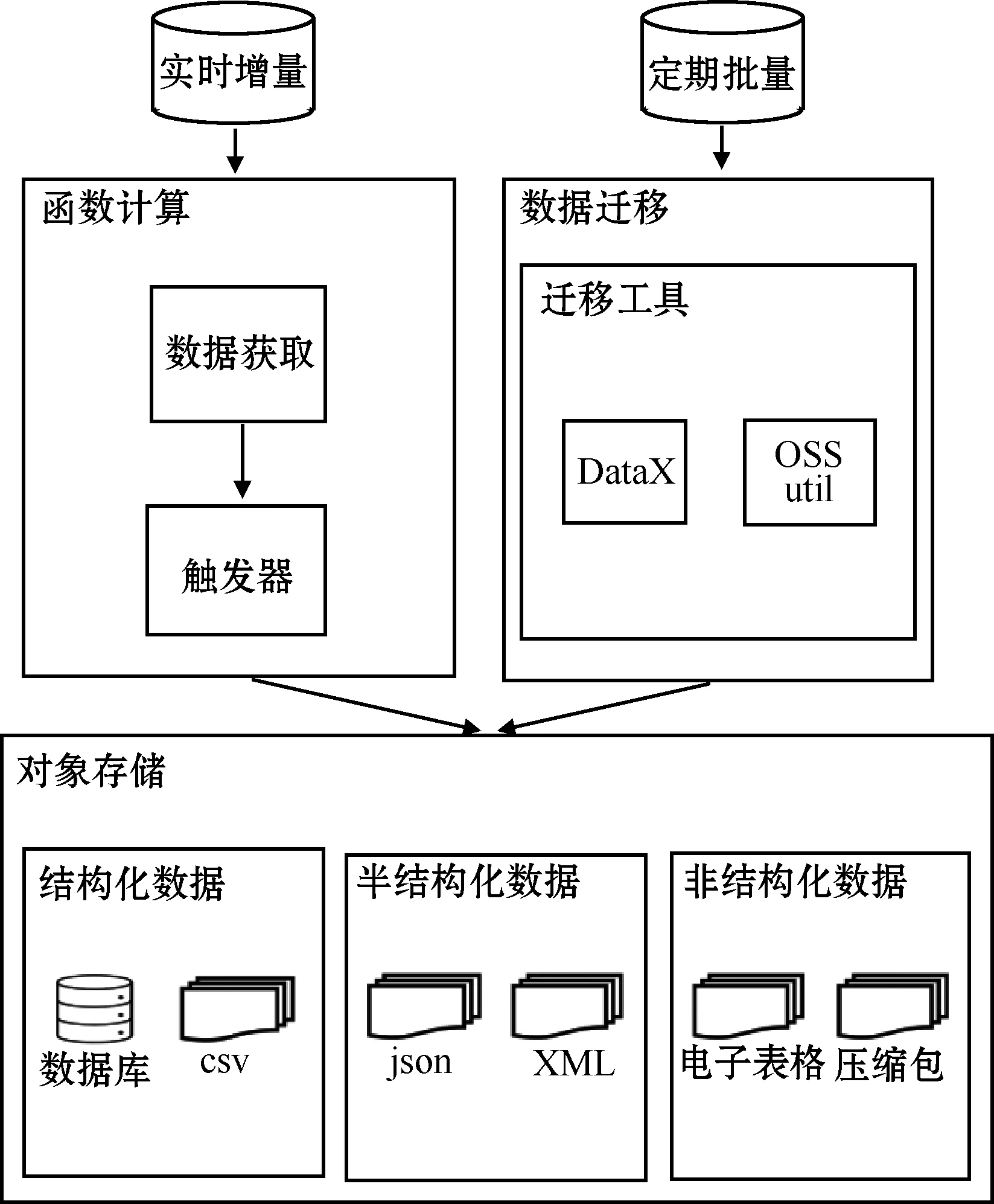
图2 数据湖的数据处理流程
根据环境数据源分析,数据按照其操作特点可划分为实时增量和定时批量。对于实时增量数据,利用函数计算的触发器,基于事件驱动(functions as a service,FaaS)进行触发。以人口位置数据为例,触发器监测到更新的数据,每15 min自动触发执行1次,完成数据获取。对于定时批量更新的数据,数据更新上传的频率一般较低,往往数月完成1次更新上传,采用的数据迁移工具有DataX和OSSutil。DataX是阿里开源的一款数据同步工具,支持OSS等多种数据源,作为中间传输载体负责连接各种数据源。OSSutil是OSS迁移工具,用于关联和建立OSS的连接,将存放原始数据的服务器连接公网,配置服务器本地数据源为源数据,将数据文件定时批量迁移至OSS存储。
结构化数据包括数据库数据源和csv文件两类。利用DLA可以加载SQL Server、MySQL、PostgreSQL等关系型数据库写入OSS,并可以将查询结果或更改通过数据回流写回数据库。对于非结构化数据,本文所研究的主要有两大类,分别是Excel电子表格数据和Zip压缩包,电子表格需转换成csv格式,二进制格式的压缩包需完成解压,上述操作使用Python程序完成自动处理。
2.3 数据流出数据湖
在查询分析层通过调用灵活的数据分析接口,为环境数据挖掘提供存储和分析支撑,即数据流出数据湖。传统大数据平台采用写时模式的数据处理方式[15],必须经过提取、转换、加载等步骤。采用DLA存储的数据,由于可以按原样存储,可以采取更为灵活的处理方式。不同于传统数据仓库的schema on write(写时模式)策略,DLA原生支持schema on read(读时模式)策略,无需将其转换为预先定义的数据结构。在Sawadogo P.所总结的模型基础上,为了将异构数据转换成可管理的数据,通过读时模式和写时模式策略,增加了数据流出数据湖,支持将原始数据通过数据模型,加工成特定结构化、规整化的形态进行存储处理。读时模式和写时模式的对比分析如表2所示。
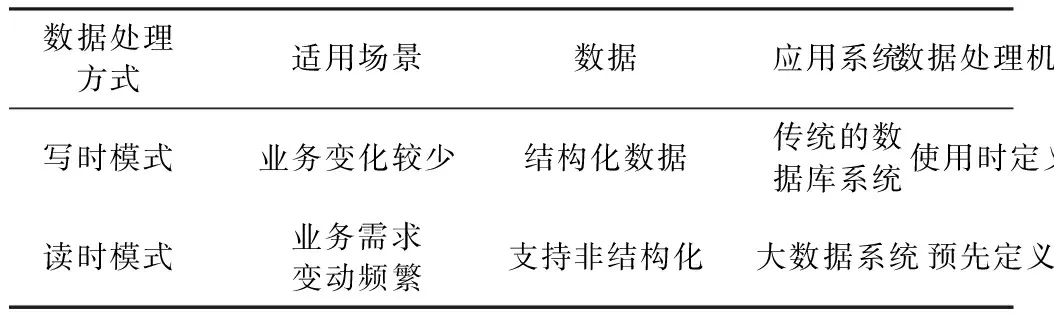
表2 读时模式和写时模式对比
基于集中式数据存储的OSS构建环境数据存储层,环境数据以本源格式保存,包括结构化的csv、半结构化的json等格式。首先采用读时模式,在使用数据时定义环境数据的模型结构,提高数据模型定义的灵活性,满足多样性、可变性的数据分析诉求。传统的写时模式有稳定的存储和处理能力,但难以应对大量数据快速产生且数据类型不同的情况,不适合大数据存储,而DLA能完整存储大量异构数据,支持灵活的读时模式策略,可以将数据转换成需要使用分析的类型。读时模式和写时模式相辅相成,利用DLA结合OSS在环境大数据探索初期采用读时模式进行数据挖掘,在环境数据建立挖掘关联关系后形成有价值的信息,通过数据回流写入结构化数据存储。同时Flink等计算引擎也支持直接访问OSS进行运算分析。
3 环境数据存储策略
3.1 数据转换
通过格式转换方式对原始数据进行处理,在OSS存储层把原始数据的格式转换为高性能格式,在使用DLA扫描数据时使用转换后的数据,可以节省一定的存储空间。DLA支持Apache ORC、Parquet和Avro这类高性能数据格式。其中,ORC和Parquet是列式存储的数据格式,Avro是一种行式存储的数据格式。可以把原始数据转换为上述3类格式,然后只扫描需要的数据列,无需扫描所有数据,从而节省扫描时间。DLA支持处理各类数据文件的序列化和反序列化(serialize/deserilize,SerDe),配置示例如下:
CREATE EXTERNAL TABLE comtrade
(pfcode varchar(400),
yr varchar(400),
period varchar(400),
……)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ′|′
STORED AS TEXTFILE
LOCATION ′oss://test-bucket/comtrade′;
TBLPROPERTIES
(′skip.header.line.count′= ′1′,);
这个配置是在DLA连接OSS加载原始数据时,通过stored as指定OSS上的数据文件格式。
3.2 分区数据管理
环境数据中文件类型的数据,会被周期性地直接上传到OSS。但这些存储在OSS上的文件缺少元数据管理,造成分析的困难。通过编制分区元数据管理存储策略,元数据发现任务可以为OSS的环境数据文件新建和修改数据湖元数据。在DLA中使用分区表对OSS中的环境大数据进行细化处理,缩短查询响应时间。将存储在OSS中的资源环境生态数据映射成一张分区表,分区列对应OSS中的目录,在编制目录时遵循命名规则,分区列对应表所在OSS路径下的一个子目录,目录的命名规则为分区列名对应分区列值。
OSS中一个目录结构的示例如下:
oss://xxx...xxx/weatherSchema/weatherTable/
file1.csv
oss://xxx...xxx/weatherSchema/weatherTable/
file2.csv
……
oss://xxx...xxx/weatherSchema/weatherPoint Table/file1.csv
oss://xxx...xxx/weatherSchema/ weatherPointTable/file2.csv
……
oss://xxx...xxx/comtradeSchema/HS0Table/year=2020/month=01/file1.json
oss://xxx...xxx/comtradeSchema/HS0Table/year=
2020/month=01/file2.json
……
oss://xxx...xxx/waterSchema/waterTable/file1.json
oss://xxx...xxx/waterSchema/waterTable/file2.json
OSS作为一个可以容纳多种格式、多种来源数据的开放文件系统,为了高效地构建基于环境数据的数据湖,数据源路径需遵循一定的规范格式。如图3所示,OSS数据源的元信息发现支持的格式为库、表、文件或者库、表、分区、文件的格式,OSS路径的第一级对应元信息的schema,第二级对应table,OSS路径的子目录名需要与元信息的表名进行映射,如果还存在三级及以上的目录则与元信息的分区对应。
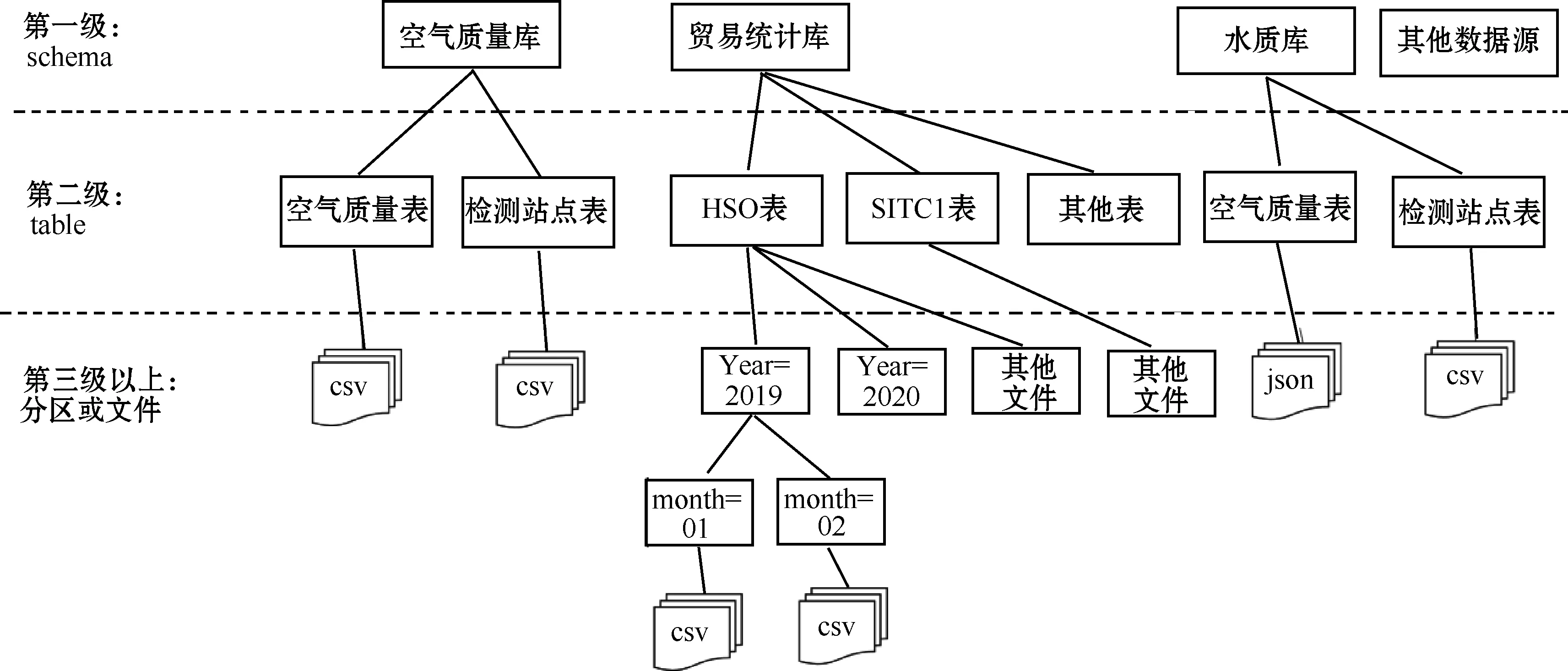
图3 分区元数据管理存储策略
以空气质量库、联合国贸易统计数据库和水质库为样例,在OSS路径根目录oss://xxx...xxx/下有3个子目录weatherSchema、comtradeSchema、waterSchema分别对应空气质量库、贸易统计库和水质库,其中weatherSchema、waterSchema有二级OSS子目录,把oss://xxx...xxx/weatherSchema/weatherTable/与空气质量库下的空气质量表建立映射,oss://xxx...xxx/weatherSchema/weatherPointTable/与空气质量检测站点表做映射,完成第二级table级别的数据管理。对于空气质量数据和水质数据由于只有三级OSS路径,最高级第三级路径存储文件粒度数据,贸易统计数据相较于前两者,在第二级table之上增加了按年和按月分区,OSS的路径和元信息的表结构也相应增加两级。
4 实验验证
为验证数据转换策略优化效果,将原始格式为csv的样本转换为ORC、Parquet、Avro格式在DLA中进行数据扫描,然后在存储空间和查询速度两方面进行对比。首先进行存储空间方面的实验,测试分成3个样本,每个样本中包含不同年份世界全部汇报国家的联合国贸易统计数据:样本1为2000年,样本2为2000-2004年,样本3为2000-2009年。3个样本的数据格式均为csv,数据占用存储空间分别为3.402 GB、18.248 GB和30.669 GB。
实验环境如下:
测试数据:联合国贸易统计数据库
数据湖:Data Lake Analytics 1.2.0
计算引擎:Alibaba Cloud AnalyticDB
对象存储:OSS标准类型
结构化数据源:RDS for MySQL 1核1G内存通用型
测试结果如表3所示。ORC、Avro、Parquet相较于csv在3个样本所占用的存储空间均有优化,其中ORC格式占用的存储空间最小,在3个样本上的表现相比csv分别节省约90.4%、90.3%、90.3%,因此在数据湖存储中选用ORC等格式可以节约存储空间。
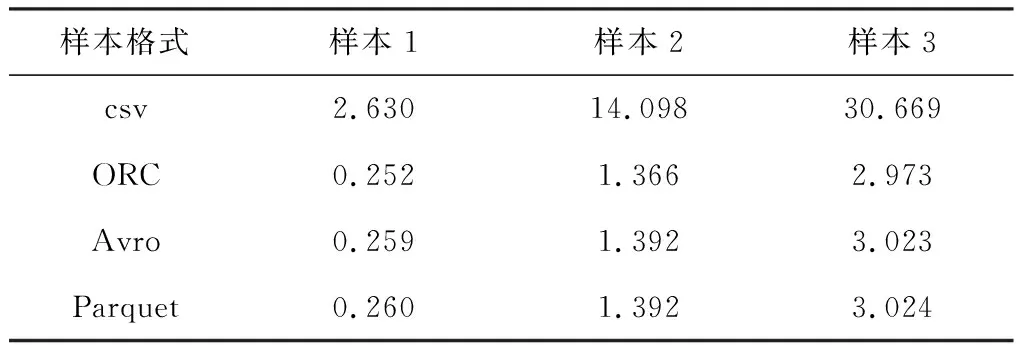
表3 存储空间测试 GB
进一步验证几种格式的查询速度性能。在上述实验的基础上,选取样本3中编号为270111的无烟煤和编号为270112的烟煤两种煤矿资源数据回流到RDS for MySQL结构化数据进行查询速度的扫描测试。测试结果如图4所示。
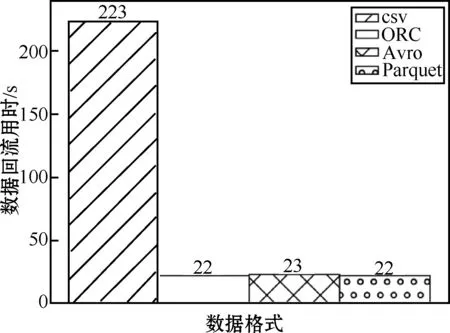
图4 数据回流性能测试
由图可知,ORC、Avro、Parquet三种数据格式相比csv格式在数据湖扫描速度上均有90%以上提升,其中ORC、Parquet格式扫描速度最快,可节省约90.1%的查询时间。
5 结束语
针对环境大数据多源异构的存储需求,本文提出了一种基于数据湖的环境大数据存储模型。模型具有整合多种环境数据源的能力,既支持不同类型环境数据的灵活存储,又提供了查询访问功能,相较于传统数据湖方案,在DLA的基础上采用格式转换策略,在存储空间和扫描速度上达到优化90%以上的效果,可以为下一阶段环境数据挖掘分析研究提供数据存储支撑,满足多样化、灵活性的数据分析需求。
猜你喜欢
智能计算机与应用(2021年6期)2021-12-17
综艺报(2020年21期)2020-11-30
电脑爱好者(2019年17期)2019-10-30
科学与财富(2017年33期)2017-12-19
科技创新与应用(2017年17期)2017-06-16
电脑知识与技术(2017年6期)2017-04-26
科技与创新(2016年17期)2016-11-04
教学月刊·中学版(教学参考)(2016年5期)2016-06-14
