
基于集成学习的不平衡交通事故风险研究
2022-01-13 06:29方方,王昕
北京信息科技大学学报(自然科学版) 2021年6期
方 方,王 昕
(北京信息科技大学 理学院,北京 100192)
0 引言
近年来,交通事故频繁发生,人员伤亡不断,但其发生并不是完全随机的,而是受到多种因素的影响。因此,可以通过研究交通事故历史数据,对交通事故风险进行预测。
国内外学者主要使用统计建模方法和机器学习方法展开研究。如二元Logit或Probit模型[1-2],多项式Logit或Probit模型[3-4]。此外,考虑到事故风险严重程度的有序性,有序Probit和Logit模型具有更好的性能[4-5]。Chen等[6]利用有序Probit模型确定影响上海越江隧道卡车事故严重程度的主要因素。Hu等[7]提出一种带逐步变量选择的广义Logit模型识别影响铁路交叉口事故严重程度的主要因素。Wang等[8]建立了Logistic回归模型研究美国道路和环境因素对事故严重程度的影响。同时,基于树的模型如随机森林等用于事故严重程度建模和预测,其性能令人满意[9]。Iranitalab等[10]不仅比较了4种统计和机器学习方法在事故严重程度预测中的性能,且研究了K均值聚类和潜类别聚类两种聚类方法对预测模型性能的影响。Yu等[11]提出了一种基于随机项模型的融合卷积神经网络来分析驾驶员受伤严重程度,其中子神经网络结构处理分类特征,多层卷积神经网络结构捕捉特征和严重程度之间潜在的非线性关系。Chen等[12]提出了一种数据驱动的Copula贝叶斯网络,研究危险变道和跟驰两种基本危险驾驶行为与事故风险的因果关系,该模型有效降低了过拟合,具有良好的预测性能。Wang等[13]利用了一个基于决策树的系统机器学习框架来预测先前涉及违规/事故记录的驾驶员的未来驾驶风险。
然而,以往研究较少考虑到事故类别不平衡且含大量分类特征的情况。交通事故普遍存在样本类别不平衡现象,即非严重事故比严重事故数量多,而将严重事故错分为非严重事故比将非严重事故错分为严重事故的代价高得多。若忽略了这一点,可能导致构建的预测模型有偏差,重采样是解决这两个问题的常见方法。传统方法如简单随机欠采样和过采样[14-15]容易造成重要信息丢失和过拟合,改进的合成数据方法如合成少数类过采样(synthetic minority oversampling technique,SMOTE)、自适应合成采样(adaptive synthetic sampling,ADASYN)、NearMiss[16]等无法处理含大量分类特征的情况。已有研究表明,结合重采样技术和集成学习的模型具有更好的预测性能[17]。且极端梯度提升(extreme gradient boosting,XGBoost)作为一种改进的梯度提升算法,具有运算速度快、鲁棒性好、预测精度高等优点,能较好地解决收敛速度慢、过拟合、易陷入局部最优等问题[18]。
针对不平衡交通事故中存在大量分类特征的情况,本文采用随机欠采样(random undersampling,RUS)结合XGBoost[19]构建一种基于RUS-XGBoost的类别不平衡事故风险预测模型,对事故严重程度进行预测,该模型还可给出影响事故风险的主要因素。
1 模型构建
1.1 XGBoost原理
XGBoost是一种集成模型,可通过构建多个基学习器提升机器学习效果,提高预测精度。给定一个具有N个样本和m个特征的数据集D={xi,yi}(│D│=N,xi∈m,yi∈),XGBoost定义为如下的K个CART回归树组成的加法模型:
(1)
τ={fk(X)=wq(X)}(q:m→{1,2,…,T},w∈T)
(2)
式中:τ为CART回归树的所有可能集合;q为树模型,表示将一个样本映射到相应的叶结点;T为树q的叶结点个数;wq(x)为树q的所有叶结点权重组成的向量;每个子模型fk对应一棵独立的树模型q和叶结点权重w。其目标函数为:

(3)
(4)
式中γ和λ为正则化参数,能够有效防止过拟合。
采用前向分步算法学习模型,在第t步时,对目标函数进行二阶泰勒展开:
σ(ft)+c
(5)
(6)
省去前t-1的常数项l(yi,(t-1))和c后,再令Ij={i|q(Xi)=j}为属于第j个叶结点的所有样本的集合。通过最小化(5)式可以求得第t个子模型的第j个叶结点的最优权重和相应的最优目标函数值:
(7)
且树的结构由切分前后的增益值确定:
(8)
1.2 基于RUS-XGBoost的类别不平衡事故风险预测模型
由于简单地使用原始训练集得到的多个基分类器的性能较差,而XGBoost作为集成模型相较于线性分类器,很容易通过扰动提高基分类器的精度和多样性,因此本文进一步采取3种扰动方法:
1)样本扰动:采取5折交叉验证,对于其中4个子集组成的不平衡训练数据集,从多数类中随机欠采样与少数类样本等量的样本个数,组成新的类别平衡训练数据集;
2)特征扰动:对特征空间的不同划分提供了观察数据的不同视角,因此对特征进行按比例随机采样;
3)参数扰动:包括学习率范围,树的深度范围,迭代次数范围。
本文提出的基于RUS-XGBoost的类别不平衡事故风险预测模型,主要包括3个部分:
1)平衡训练子集的构建。给定多数类数据集M和少数类数据集N,通过随机欠采样(不放回)的方式从M中采样T个子集,使其与N中的样本等量,即│Mi│=│N│,分别和全部少数类样本构成平衡的训练子集D1,D2,…,DT;
2)子模型的构建。用不同的训练子集,结合特征扰动和参数扰动,使用XGBoost训练得到T个差异化的RUS-XGBoost子模型;
3)子模型的集成。由于子模型的类型相近,因此使用简单平均法整合T个子模型的预测概率。
模型的整体结构如图1所示。
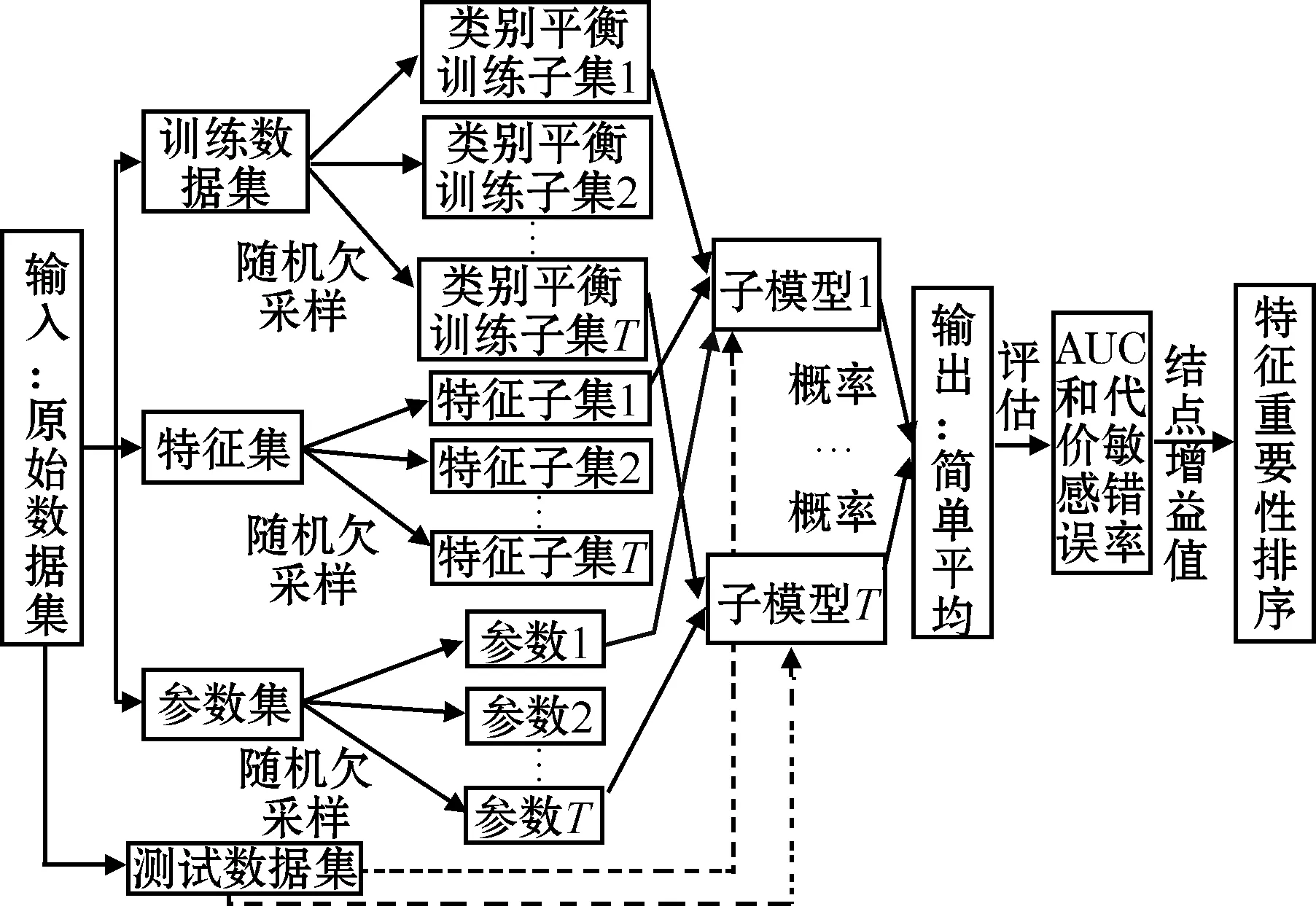
图1 模型整体结构
2 验证与分析
2.1 数据分布与预处理
从英国政府公开的交通事故数据库(dft.bov.uk)中收集了2017-2019年共370 153条事故记录作为数据集,含53个与事故和车辆相关的特征,且提供了3个事故严重程度等级:1)致命伤害:至少有1人死亡;2)严重伤害:严重的人身伤害,需要在医院待两天以上;3)轻微伤害:在不到两天的时间内可以很容易地用药物治疗。
统计事故严重程度分布,如图2所示,可以看出轻微伤害的事故最多,共296 027起;其次是严重伤害的事故,共69 121起;致命伤害的事故最少,只有5 005起。因此,该事故数据集是一个类别不平衡的数据集。

图2 事故严重程度分布
因为与包含其他类型交通使用者和交通方式的事故相比,两辆车的事故具有相对更同质的数据集,因此最终的数据集选择了仅涉及两辆车的事故。该数据集共245 588个样本,由于致命伤害样本太少,且本文仅关心事故是否严重,故与严重伤害合并为一类共41 789个样本,轻微伤害共203 799个样本。
由于分类、聚类之类的算法常根据欧氏距离衡量不同样本之间的相似性,为避免算法将分类特征的离散取值当作连续数据进行计算,采用one-hot编码,即将一个分类特征替换为多个取值为0和1的新特征,转化为图3的稀疏型数据表形式,使得样本的分类特征之间的距离都是0或1。
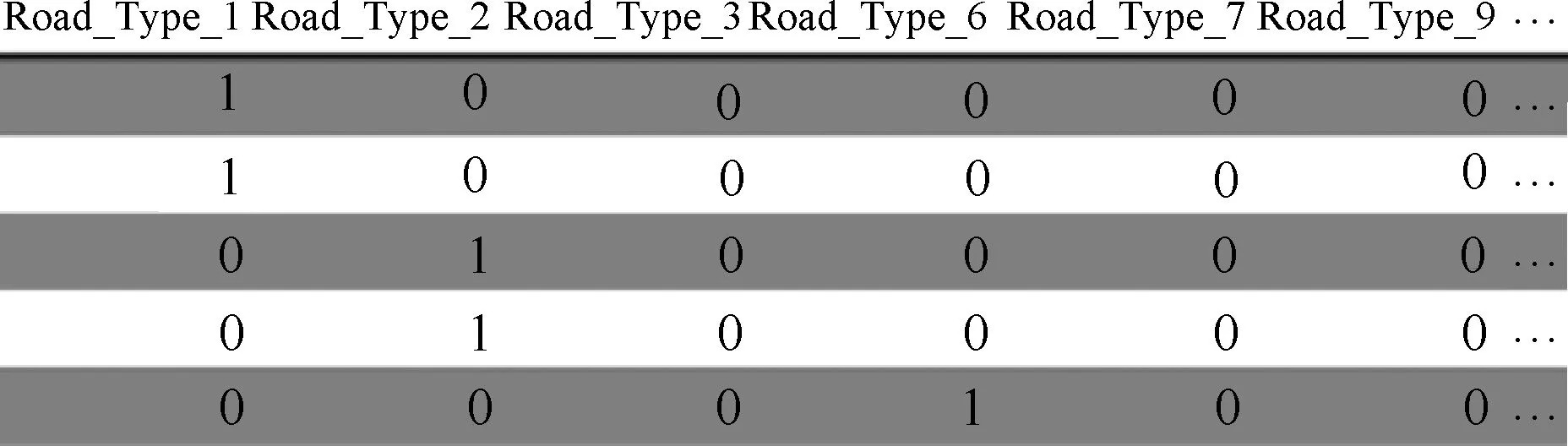
图3 one-hot编码后的特征(以道路类型为例)
2.2 特征选择及评价指标
对数据集中的53个特征进行特征选择。首先,去除含有大量缺失值的特征;其次,一些较为复杂的地理位置特征如经纬度、街道名称、所属管辖区等也被去除。最终得到了24个特征,分为4类:1)驾驶员因素:性别、年龄;2)车辆因素:车辆类型、车辆年龄、引擎容量等;3)道路因素:道路类型、道路限速、交叉口细节等;4)环境因素:光照条件、天气条件等。
对于类别不平衡问题,使用准确率评价模型的性能是不恰当的,假设训练数据的非严重和严重事故样本比为95∶5,分类器简单地把所有样本都分为非严重事故,能达到95%的准确率,这显然不合理,因为其忽视了少数类对分类性能评价的影响。AUC即ROC曲线下面积,是独立于类别分布的评价指标,适用于不平衡问题。AUC一般在0.5~1之间,越接近1分类器性能越好,越接近0.5性能越差。
此外,根据错分代价的不同,还应该使用代价敏感错误率作为评价指标。代价敏感错误率的定义依赖于代价敏感矩阵,如表1所示。

表1 代价敏感矩阵
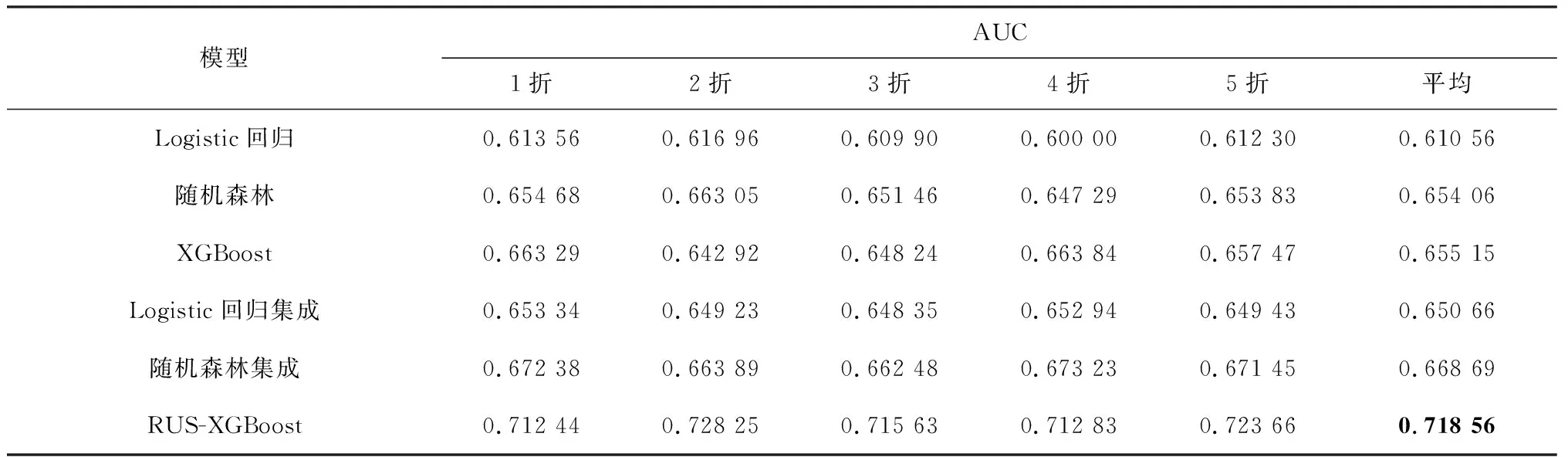
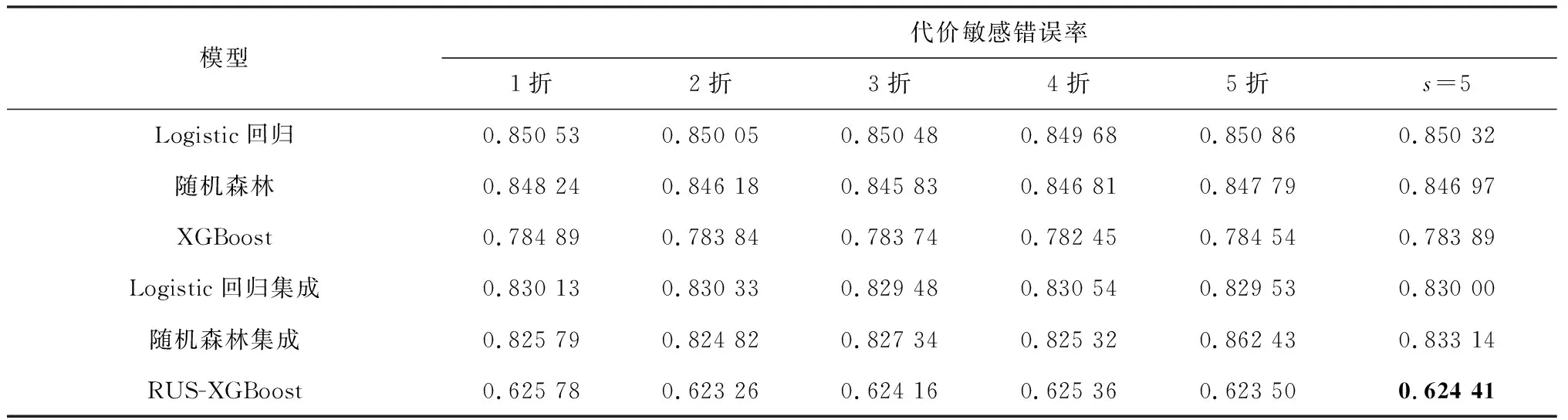
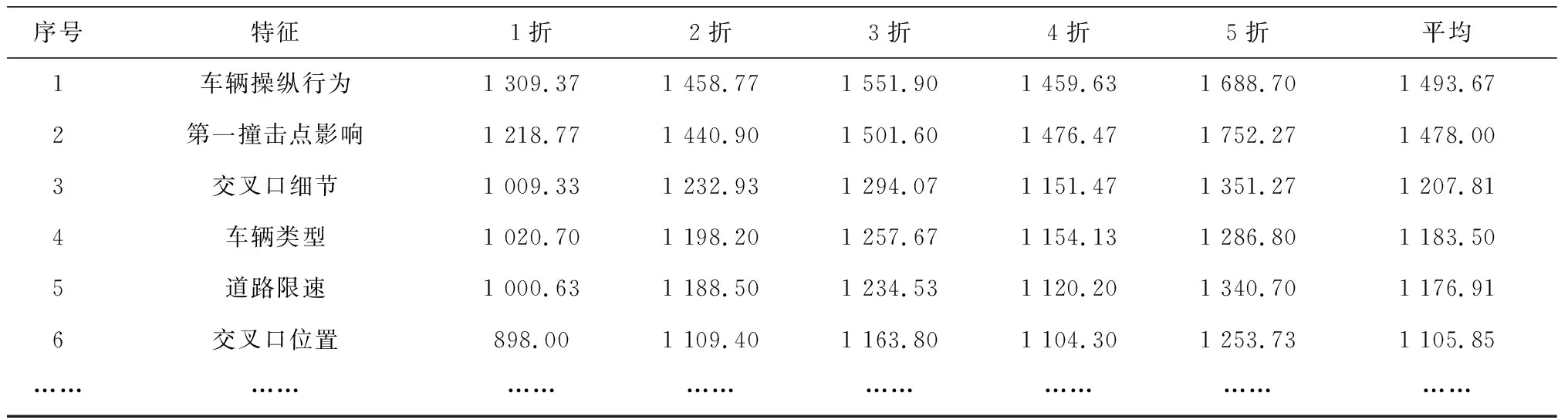
设类别标签为{0,1},分为两类。其中c01表示为将非严重事故误判为严重事故的惩罚代价系数,c10表示将严重事故误判为非严重事故的惩罚代价系数,显然有c01 (9) 本研究设计的基分类器的输出结果为每个输入样本属于严重事故的概率,即P(y=1)。对于得到的多个随机欠采样结合XGBoost的子模型,记为RUS-XGBoost子模型,具体步骤如下: 输入:多数类数据集M,少数类数据集N,且│N│<│M│;子模型的个数T;学习率范围α,树的深度范围d,迭代次数范围n,特征比例采样范围δ。 过程:fori=1,2,…,T: 1)从M中随机不放回采样一个子集Mi,使得│Mi│=│N│,且Mi∪N=Di; 2)从α、d、n、δ中各随机取一个值; 3)将Di作为新的训练数据集,使用上述参数和特征子集训练一个子模型hi(x)。 输出:预测概率,并对结果进行分类。 (10) 测试数据集共49 116个样本,其中严重事故40 759个,非严重事故8 357个。实验时采用以下两种模型进行对比:单模型:仅使用5折交叉验证,包括Logistic回归、随机森林和XGBoost;集成模型:重新构建T个平衡的训练子集,包括Logistic回归集成、随机森林集成和本文提出的RUS-XGBoost。 经过参数调优,XGBoost的学习率为0.07,树的深度为6,迭代次数为120;RUS-XGBoost的子模型个数为T=30,学习率范围α=[0.001,0.1],树的深度范围d=[6,8],迭代次数范围n=[100,150],特征采样比例范围δ=[0.8,0.9]。此外,设c01和c10的代价比为5,即c01=1,c10=5。可以得到各个模型的AUC和代价敏感错误率如表2、表3所示。 表2 各个模型的AUC 表3 各个模型的代价敏感错误率 由表2、表3可以看出:1)集成模型的预测效果比单模型好,这是因为使用随机欠采样构建新的平衡训练集,极大地改善了少数类的预测,而不妨碍多数类的预测,从而提高模型的泛化能力和预测性能;2)本文提出的RUS-XGBoost模型具有最高的AUC为0.718 56,说明预测偏差小,预测效果优于其他模型。当代价比为5,即将严重事故误判为非严重事故的代价是将非严重事故误判为严重事故代价的5倍时,RUS-XGBoost模型的代价敏感错误率最低为0.624 41,也可以说明当误判代价不同时,其预测效果比其他模型好。 最后,利用RUS-XGBoost模型计算的增益值,对输入特征的重要性进行排序,如表4所示。 表4 RUS-XGBoost的特征重要性 重要性排前6的特征中,车辆操纵行为、第一撞击点影响和车辆类型属于车辆因素,交叉口细节、道路限速和交叉口位置属于道路因素。由此可以看出,车辆因素和道路因素对交通事故严重程度的影响较大,这与我们直观上的感受是一致的。 针对实际交通事故中存在的类别不平衡且含有大量分类特征的情况,本文建立一种基于RUS-XGBoost的类别不平衡事故风险预测模型。实验结果表明:通过样本扰动、特征扰动和参数扰动结合XGBoost得到多个差异化的子模型,预测结果与单模型如Logistic回归、随机森林和XGBoost,集成模型如Logistic回归集成、随机森林集成相比,具有较高的AUC和较低的代价敏感错误率,说明该模型能够有效降低不平衡数据集对预测性能的负面影响,提高模型的泛化能力和预测性能,从而为制定道路安全政策提供参考,减少交通事故风险带来的损失。 特征选择对模型的预测性能有一定的影响,因此是否应该选择对少数类样本更有利的特征,可以作为下一步研究的课题。2.3 模型训练与预测结果分析
3 结束语
猜你喜欢
上海师范大学学报·自然科学版(2022年3期)2022-07-11
汽车实用技术(2022年5期)2022-04-02
北京航空航天大学学报(2021年7期)2021-08-13
少儿画王(3-6岁)(2020年4期)2020-09-13
东方教育(2018年20期)2018-08-22
海峡姐妹(2017年12期)2018-01-31
语文世界(初中版)(2017年5期)2017-06-22
作文与考试·初中版(2017年12期)2017-04-19
湖南师范大学学报·自然科学版(2014年5期)2014-11-14
微型计算机(2009年4期)2009-12-23
