
基于ResNet和领域自适应的轴承故障诊断研究
2022-01-12 11:50:40杨冰如沈长青朱忠奎
测控技术 2021年12期
杨冰如,李 奇,陈 良,沈长青,朱忠奎
(1.苏州大学 机电工程学院,江苏 苏州 215131;2.苏州大学 轨道交通学院,江苏 苏州 215131)
旋转机械是实际工业现场的重要部件之一,通常需要在恶劣的情况下长时间运转,很容易磨损滚动轴承等零部件,不可避免会形成故障[1]。而机械设备一旦发生故障,会导致大量的经济损失,严重时甚至会发生人身事故,因此可靠准确的轴承故障诊断方法的研究越来越重要,它能够对旋转机械的健康状态进行监测与诊断,从而保障机械设备的正常运行,降低故障风险。随着智能制造模式的发展,对工业过程中的故障检测提出了更高的要求[2]。
轴承振动信号是能为检测机械设备状态提供信息的高精度指标[3],因此大多数传统的基于信号处理的故障诊断方法都是从原始振动信号中提取故障信息,如经验模态分解(Empirical Mode Decomposition,EMD)[4]、小波包变换(Wavelet Packet Transform,WPT)[5]和其他时频域信号处理方法。Yu等[6]采用经验模态分解方法,根据固有模态函数计算振动信号的原始统计特征,再结合特征降维方法,实现了轴承的故障诊断。Wang等[7]将小波包变换和稀疏编码相结合,提出了一种有监督的基于稀疏小波变换的轴承故障检测方法。小波包变换可以检测到轴承信号发生的故障。基于结构化字典的稀疏编码可以找到信号的鲁棒表示,同时集成类别信息。基于信号处理的方法要求分析人员具有一定的先验知识的储备,包括机械方面的专业知识和数学基础,才能保证较好的信号处理效果[8]。
在实际运行过程中的设备状况会受到很多因素的影响,十分复杂,采用基于信号处理的诊断方法效果不明显,因此研究人员引入了机器学习模型来弥补这一不足。Zhang等[9]将经验模态分解和支持向量机(Support Vector Machines,SVM)相结合,揭示了振动信号多尺度内在特征。Mao等[10]针对故障数据比正常数据少得多的数据不平衡问题,提出了一种基于极限学习机的故障诊断在线时序预测方法。但机器学习诊断模型的性能也往往受到手工提取特征的限制,当数据结构复杂时,难以提取到有效特征。
随着深度学习(Deep Learning)[11]的发展,其自动特征提取的能力在故障诊断领域中有着良好的应用前景。Zhang等[12]提出了一种使用稀疏自动编码器(Sparse Auto Encoder,SAE)的新标签生成方法,它能够从训练样本中构造一个分布,并识别那些不属于已知类别的样本。Dong等[13]将无监督卷积神经网络(Convolutional Neural Networks,CNN)和深度信念网络(Deep Belief Network,DBN)相结合,提出了随机卷积深度信念网络,通过加入无监督成分,提高了模型的泛化能力。Shao等[14]利用生成对抗网络(Generative Adversarial Network,GAN)学习机械传感器信号并生成真实的带标签的合成信号,并将生成的信号作为扩展数据用于故障诊断。
然而,深度学习模型需要满足训练集和测试集服从同一分布的假设,并且需要大量有标签数据才能训练一个足够好的模型,这两个条件在实际工业现场都是难以满足的。机械设备在运行过程中会受到温度、负载、运行时间等因素的影响,导致采集的数据分布有差异,此时训练好的深度学习模型的诊断效果会大打折扣。并且为数据打标签是个耗时耗力的工作,很难收集到大量有标签的数据去训练模型。因此将迁移学习(Transfer Learning)模型用于机械故障诊断是近年来新兴起但发展较为迅速的一个研究方向,其目标在于能够将从源域学习到的知识用于解决目标域中新的相关的任务[15-16]。Wen等[17]提出了一种深度迁移学习网络,采用了一个无标签的第三数据集来辅助分类,能够在一定程度上提高分类效果。Zhang等[18]提出了域自适应卷积神经网络,将源域和目标域分别输入到各自的特征提取器中,使源域和目标域的实例样本在映射后具有相似的分布,实现了不同工作条件下的轴承故障诊断。Guo等[19]提出了深度卷积迁移学习网络,包括状态识别和域自适应两个模块,通过最大化域识别误差和最小化概率分布距离,使一维卷积神经网络更容易学习域不变特征。Li等[20]通过人工生成用于领域自适应的伪样本,能够在机器故障条件下的测试数据不能用于训练时提供可靠的跨领域诊断结果。
综上所述,基于信号处理的方法和机器学习方法都非常依赖先验知识的储备,深度学习模型需要满足的假设在实际工业现场难以满足,而目前大多数的迁移学习模型仅匹配一种分布差异,边缘分布差异或是条件分布差异,并且在匹配特征分布时,有些学者认为高层特征的可迁移性显著下降[21],而有些学者则认为低层特征更导致了领域分布差异[22]。针对上述问题,本文采用经过预训练的深度残差网络(Residual Network,ResNet)作为特征提取器,对4个残差块提取的源域和目标域特征计算最大均值差异(Maximum Mean Discrepancy,MMD)以匹配边缘分布,通过为目标域数据打伪标签匹配条件分布差异。经实验证明,在变工况的场景下,该模型能在提高诊断精度的同时,对轴承故障进行定性、定量诊断。
1 理论背景
1.1 领域自适应
迁移学习是目前受到众多研究人员广泛关注的一个研究方向,并已在图像识别[23]、语音识别[24]、文本识别[25]等领域成功应用。领域自适应(Domain Adaptation)可以看作是迁移学习中的一种特定的设置[26]。
领域D中包含样本空间X和样本的边缘分布P(X),可以表示为D={X,P(X)},即Ds≠Dt意味着Xs≠Xt或(和)Ps(X)≠Pt(X)。
任务T包含标签空间Y和目标预测函数f(·),可以表示为T={Y,f(·)},从概率的观点来看,f(·)也可以表示为条件分布P(Y|X),即Ts≠Tt意味着Ys≠Yt或(和)Ps(Y|X)≠Pt(Y|X)。
当Ds和Dt差距较大时,如图1(a)所示,此时Dt中每一类的中心都和Ds中的相距较远,匹配边缘分布更为重要。而当边缘分布比较接近时,如图1(b)所示,此时Dt中每一类的中心和Ds中的差距较小,则更应该关注匹配条件分布差异。在实际工业场景中,Ds和Dt的边缘分布和条件分布往往都会有差异,对领域自适应产生不同的影响,因此在本文中同时匹配边缘分布和条件分布,如图1(c)所示。

图1 边缘分布和条件分布对领域自适应的不同影响
1.2 深度残差网络
在2015年提出的深度残差网络(ResNet)[28]取得了当年ImageNet数据集[29]的分类比赛冠军。它解决了当深度网络层数增加时,网络准确率出现饱和甚至下降的问题,并且具有很强的特征提取能力。考虑到数据集的规模,采用ResNet18作为特征提取器,网络包含4个残差块,每个残差块的内部结构如图2所示,具体网络结构参数如表1所示。Conv代表一个卷积层(Convolutional Layer),BN代表批标准化(Batch Normalization),ReLU代表线性修正单元(Rectified Linear Unit),是一种激活函数,FC代表全连接层(Fully Connected Layer)。

图2 残差块内部结构

表1 ResNet18网络参数
原始结构的ResNet18在图像识别领域取得了巨大的成功,但在本文中,仅将ResNet18作为特征提取器,并且结合轴承信号的特性,对其进行一些改动。首先,为了匹配轴承信号维度,将Conv1的内核尺寸改为3×3;其次为了尽可能保留状态信息,去掉Max pool层;最后不需要ResNet18的分类功能,去掉FC层和Softmax层。修改后的具体网络参数如表2所示。

表2 修改后的ResNet18网络参数
1.3 最大均值差异(MMD)
为了寻找到合适的f(·),需要缩小Ds和Dt间的分布差异d(Xs,Xt),许多迁移学习方法中都采用MMD[30]来衡量边缘分布差异。
(1)
式中,U和V为两种分布样本;Hk为再生核希尔伯特空间(Reproducing Kernel Hilbert Space,RKHS),k为内核。内核的选择对于MMD有着重要的影响,因为不同的核可能会在不同的RKHSs中嵌入概率分布[31],并且有研究表明与单一内核相比,采用多核MMD(Multiple Kernel-Maximum Mean Discrepancy,MK-MMD)能够极大地提高自适应的效率[32],因此在本文中使用了多个内核的混合。
(2)
式中,G为内核数量;kθi为带宽为θi的高斯核(Gaussian kernel)。在本文中,使用了带宽分别为4,8,16,32和64的5个高斯核的混合。
2 基于多层领域自适应的故障诊断
2.1 模型设计
针对变工况场景下的轴承故障诊断问题,所设计的模型结构如图3所示。

图3 整体网络结构
首先,如1.2节所述,采用改进过的ResNet18作为特征提取器。来自Ds和Dt的数据进入同一个预训练好的特征提取器。为了能够提取到有效的可迁移特征,需要充分减小两个域之间的特征分布差异,因此采用1.3节中介绍的MK-MMD作为优化目标。虽然MMD距离已经在迁移学习方法中被广泛使用,但大多数研究只是最小化网络最后一层的分布差异,然而两个域之间的域偏移不仅仅会出现在最高层,因此只最小化单个层间的差异不能有效地匹配Ds和Dt间的偏差。在本文中,通过对每一个残差块提取的特征都计算MK-MMD距离进行多层适配,即对多个残差块层进行领域自适应,以匹配边缘分布差异。MK-MMD的损失可定义为
(3)
式中,Nl为计算MK-MMD的层数;K为高斯核的个数;Ul和Vl分别为第l个残差块提取的Ds和Dt的分布;MMDk(Ul,Vl)为通过式(2)计算的MK-MMD距离,k为内核。
在两个工况不同的域中,故障诊断的任务是相同的,即分类的类别是相同的。由于Ds的标签是已知的,可以最小化训练样本的分类误差,采用交叉熵作为优化目标:
(4)

通过多层领域适配,可以减小可迁移特征的分布差异,匹配边缘分布,但是Dt的无标签数据无法运用到训练中,因此引入伪标签来解决这个问题,匹配条件分布差异。伪标签的生成可以分为两步:标签的概率预测和伪标签转化[33]。在所提模型中,每个残差块后都有一个与之匹配的分类器(FC层),经过分类器和Softmax层给出的标签的预测概率分布计算式为

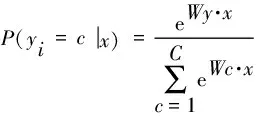
(5)
式中,yi为第i个样本;C为总的类别数;W为相应类别的权重。伪标签的转换可表示为
(6)

(7)
总的伪标签损失函数可计算如下:
(8)
由此可得,整体模型的损失函数可表示为
Ltotal=Lclf+λ1LMMD+λ2Lp
(9)
式中,λ1和λ2为权衡系数。
2.2 诊断流程
所提出的故障诊断模型的整体流程图如图4所示。

图4 故障诊断流程图
首先,从实验台上采集原始振动信号,对数据进行预处理,每个样本取2048个采样点经过快速傅里叶变换(Fast Fourier Transform,FFT)后转化为频域信号,由于经过FFT变换后的信号是对称的,所以取变换后频域信号的前1024个点作为模型的输入。将数据划分为有标签的源域数据集和无标签的目标域数据集,并进一步划分为训练集和测试集。另外,为了加速模型训练的进程,使用源域数据对ResNet18进行预训练,保存效果最好的网络参数,在训练模型时直接读取。
其次,在模型训练阶段,batch的大小设为64,即每次从源域和目标域数据中各取64个样本输入到模型中进行训练。通过预训练好的ResNet18提取可迁移特征,减小源域和目标域的分布差异。在网络的顶层,应用FC层作为分类器,利用模型学习到的可迁移特征,对轴承健康状态进行分类。引入Adam算法[34]对整体模型参数进行优化,加快模型收敛。
最后,当模型训练结束后,将目标域的测试集样本输入到模型中评估模型的能力,输出最终的故障诊断结果。
3 实验对比
3.1 数据集描述
研究轴承故障诊断方法需要使用真实、有效的轴承故障数据,以保障开展的实验和所验证研究方法的有效性和科学性。本文采用的是实验室自制轴承故障试验平台,如图5所示。该平台由驱动电机、梅花联轴器、健康轴承、测试轴承、测力器、加速度传感器和NIPXle-1082数据采集系统等装置组成,测试轴承型号为6205-2RS SKF。在不同负载情况下试验台中的加速度传感器负责采集轴承的振动信号。

图5 滚动轴承振动数据采集试验平台
该实验平台在采样频率为10 kHz和不同的电机负载(0 kN,1kN,2 kN,3 kN)情况下进行了故障模拟实验,采集到了不同工况下不同故障类型和不同故障尺寸的轴承振动信号数据,轴承健康状态包括正常状态(Normal)、内圈故障(Inner Race Fault,IF)、外圈故障(Outer Race Fault,OF)和滚动体故障(Ball Fault,BF)4种,轴承故障尺寸包括0.3 mm,0.4 mm和0.5 mm。
实验采用了4种不同电机负载的轴承故障数据。每种负载下包含了4种故障类型和3种故障尺寸,共10种健康状态,每种状态包括320个训练样本和160个测试样本,具体信息如表3所示。

表3 数据集设置
3.2 实验结果与对比分析
3.2.1 不同参数设置的对比
不同的参数设置会对实验结果产生不同程度的影响。在实验中,学习率设置为0.0001,λ1和λ2分别为1和0.1。首先,为了验证多层领域自适应的效果,设计了仅匹配第一个残差块的特征和仅匹配最高层特征的两组对比实验。其次,为了验证MMD距离多个内核的效果,将仅使用一个带宽为4的内核作为一组对比。另外,为了验证频域信号作为输入的优势,将直接输入时域信号作为对比。具体的对比实验结果如表4所示。其中,迁移方向指不同负载间的迁移,如0-1是指负载为0 kN的数据作为源域,迁移到负载为1 kN的目标域。用MK(1,2,3,4,fc,p)表示本文所提出的方法,MK代表多个内核,SK代表单个内核,数字代表特征匹配的残差块层,fc代表分类器,p代表伪标签。当只匹配单层的时候,只计算该层的MK-MMD距离和伪标签。T-MK(1,2,3,4,fc,p)代表用时域信号作为输入,其余实验都采用经过FFT处理的频域信号作为输入。
由表4可以看出,所提模型在所有的设置中获得了最高的平均准确率,能够达到99%。通过第1组和第2组的对比可以看出,低层特征和高层特征都会导致一定程度的域偏移,只匹配高层的特征比只匹配低层的特征能获得更好的准确率,说明高层特征所导致的分布差异更为严重,并且当源域和目标域分布差异比较大的时候,如0 kN和3 kN之间的迁移,多层特征匹配的优势比较明显。通过第3组实验设置的对比可以看出,单个MMD核也可以取得不错的效果,但当两个域之间分布差异较大时,所提出的模型依然可以取得较大的提升,证明了多个内核混合的效果较好。第4组对比的设置中去掉了伪标签,从结果中可以看出,伪标签在一定程度上能够提升分类的效果。直接输入时域信号的对比结果表明,输入经过FFT处理的频域信号能够取得更高的诊断精度。
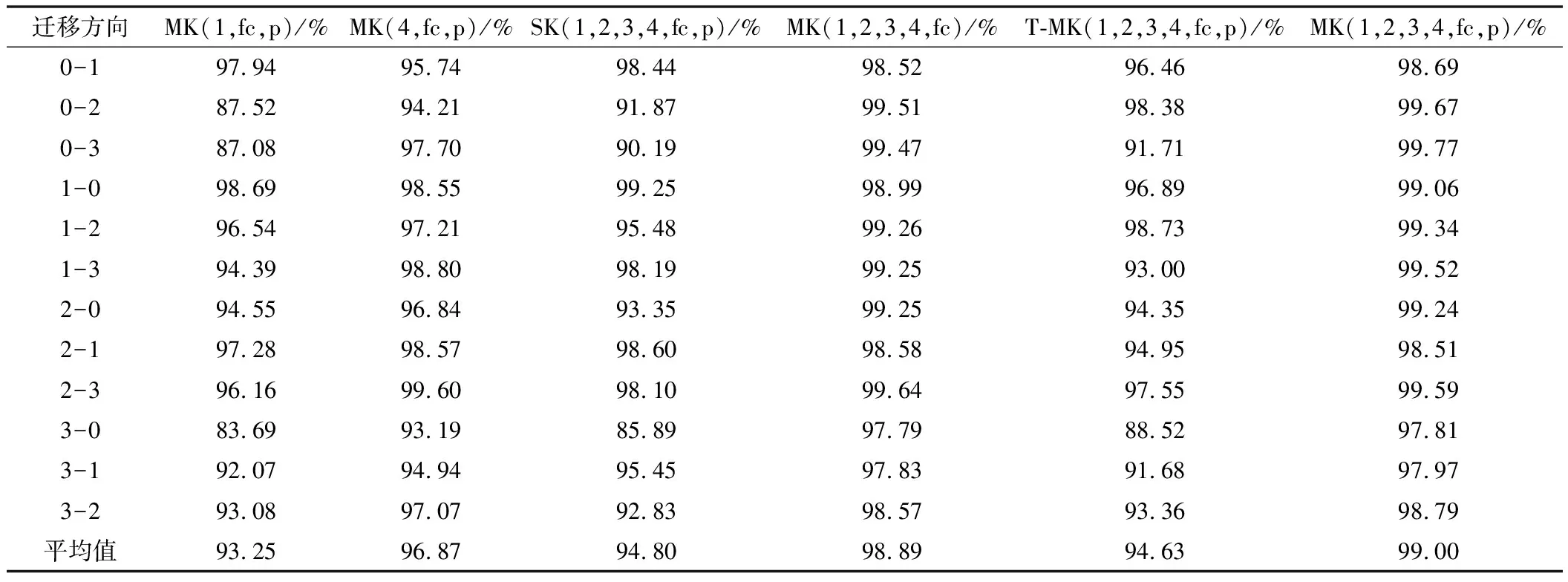
表4 不同参数实验对比结果
图6展示了不同参数设置的实验结果雷达图,从图中可以更直观地看出所提模型在所有参数设置中取得了整体的最好效果。
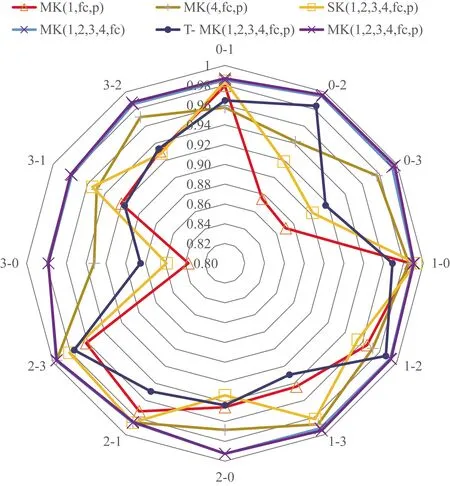
图6 不同参数实验对比雷达图
3.2.2 不同方法的对比
为了展示所提模型的效果,分别将其与迁移成分分析(Transfer Component Analysis,TCA)[26]、联合分布适配(Joint Distribution Adaptation,JDA)[35]、CORAL(Correlation Alignment)[36]和作为预训练模型的ResNet18相比较,对比实验结果如表5所示。

表5 不同方法的实验对比结果
前3种方法为传统的迁移学习方法,当源域和目标域分布差异比较小的时候,如0 kN和1 kN间相互迁移时,3种方法都能取得不错的效果。而当两个域之间分布差异较大时,迁移效果则会有明显下降,这说明工况变化的程度会影响数据分布的变化程度和所提取特征的泛化能力。而作为预训练模型的ResNet18,体现出了特征提取能力,而由于不具备迁移的能力,在不进行领域自适应的情况下难以直接对目标域进行诊断。
图7展示了不同方法的实验对比雷达图,可以看出,所提模型在12组迁移任务中都获得了最高的准确率,有较好的泛化能力。
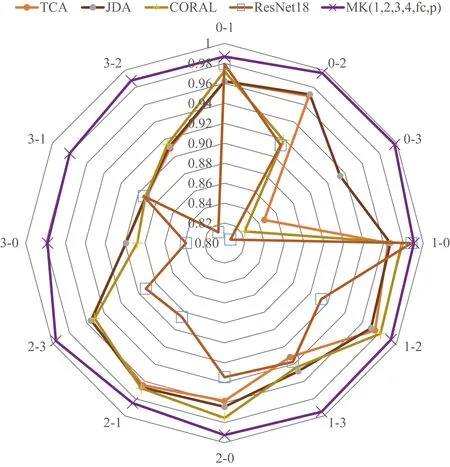
图7 不同方法实验对比雷达图
为了进一步确认所提模型是否提取到了可迁移特征,引入t-SNE[37]对各个方法提取的特征进行降维可视化,结果如图8所示,展示的是0 kN为源域,3 kN为目标域的迁移任务。可以看出,使用迁移学习的方法都能够在一定程度上匹配特征的分布差异,但是效果有限。相比之下,所提模型能够清晰地提取到可迁移特征,减小两个域之间的域偏移,将在源域学习到的知识有效地运用到了目标域中,实现高精度的故障诊断。
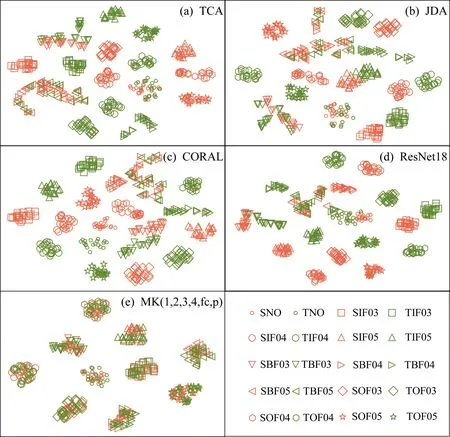
图8 特征可视化
4 结束语
针对变工况场景下的轴承故障诊断问题,提出了基于多层领域自适应的故障诊断模型,可以有效提取到可迁移性特征,对轴承进行定性、定量的故障诊断。首先,采用预训练好的ResNet18作为特征提取器,并对每个残差块提取的特征都计算MK-MMD距离,匹配边缘分布差异。其次,将每个残差块提取的特征输入与之匹配的分类器中,再通过Softmax层计算预测概率分布,并转化为伪标签,匹配条件分布差异。最后,引入Adam优化器,对整体模型参数进行优化,加快模型训练,提高模型收敛速度。通过12组迁移任务的实验表明,本文所提出的方法通过同时匹配高层和低层特征,能够有效减小域偏移,运用从源域数据集中学习到的知识对目标域数据进行有效的故障诊断,达到了较高的精度,并具有一定的泛化能力。
猜你喜欢
计算机技术与发展(2024年3期)2024-03-25 02:10:02
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
计算机技术与发展(2020年11期)2020-12-04 07:50:46
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28 07:43:58
电子与信息学报(2015年12期)2015-08-17 11:14:42
河南科技(2015年8期)2015-03-11 16:23:52
振动、测试与诊断(2014年5期)2014-03-01 01:14:21
机械与电子(2014年1期)2014-02-28 02:07:31
