
干扰条件下的水声目标线谱数据挖掘方法
2022-01-11 12:06吴姚振徐晓男李肖年
声学与电子工程 2021年4期
吴姚振 徐晓男 李肖年
(1.中国人民解放军91001部队,北京,100036;2.第七一五研究所,杭州,310023)
水声目标线谱是指由于机械动力装置的往复运动引起的周期性噪声成分,在噪声功率谱上表现为在固定频率位置上出现脉冲状窄带峰,强度大大超过附近频率成分。水声目标线谱具有能稳定观测、物理意义相对明确、低频线谱成分不易治理等特点,是水声目标探测识别中关键的特征[1-3]。水声目标的辐射噪声成因十分复杂,由多种因素决定,线谱成分并非一成不变。当目标采用不同的航速,或因工作需要开启不同机械动力设备的时候,噪声功率谱中可能会有部分线谱几乎不变,也会有部分线谱强度会变强、减弱,或完全消失、突然出现等。水声目标线谱组是指水声目标辐射噪声频谱中总是同时出现的结构性线谱序列,通常与特定的航行工况、机械动力结构相对应,在统计意义上能够准确反映水声目标辐射噪声的本质性特征,对水声目标探测、识别等技术研究具有重要意义。
要掌握水声目标的线谱组特征,直接的方法是对目标进行系统性测试,获得水声目标在各种条件下的理想数据,按照试验条件对数据进行简单的统计分析即可。但是对水声目标进行系统性测试的实现难度极大,代价极其高昂。一种可行的替代途径是采用各种渠道采集的“不理想”的水声目标噪声数据,从中挖掘水声目标辐射噪声线谱特征的分布规律,构建形成水声目标辐射噪声线谱组。但这种方式面临的主要问题在于,大多数据都是在非可控条件下获得,噪声数据中可能混叠了若干未知的干扰成分,同时缺少完整必要的标注说明,导致数据分析困难。
典型的如不具备方位分辨能力的无指向性水听器数据,在观测时会同时接收来自所有方位的信号,记录的时域噪声数据是不同距离和方位上的多个目标辐射噪声以及海洋环境噪声的线性叠加;在干扰过强或邻近目标方位时,具有一定孔径的声呐基阵数据也会受干扰目标的影响。所以,如何在未知干扰背景下分析线谱的分布规律、挖掘出属于目标的固有线谱特征,是水声数据分析处理中常见的难题。
因此,本文提出了一种干扰条件下的水声目标线谱数据挖掘方法,该方法以水声目标低频线谱数据作为样本,构建线谱特征的 FP-树,挖掘获取线谱组合的频繁项作为水声目标的固有线谱组合特征,并利用仿真数据对算法有效性进行了验证。
1 水声目标线谱分析
水声目标线谱分析一般是对来自水听器直接录取或来自声呐基阵目标跟踪波束录取的时域数据进行功率谱估计,从功率谱中提取[4-7]感兴趣目标的窄带线谱成分,用于对水声目标的检测、身份识别或特征建模。图1~2分别给出了海上试验的实际数据的处理结果。
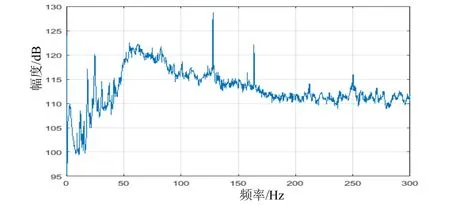
图1 实测水声目标辐射噪声功率谱

图2 水声目标功率谱瀑布图
从图1可以看出,在水声目标辐射噪声功率谱中会同时观测到多个线谱。有时能够通过先验信息已知录取的噪声数据中包含某种感兴趣目标,但是通常无法确定是否存在其他干扰(非感兴趣)目标的成分,更无法辨识这些线谱都分别对应于哪些目标。从图2的时频结果中能够看到有多个声源的干涉条纹,其中左侧低频部分的黄色矩形区域1中功率谱条纹几乎是竖直的,而区域2中功率谱条纹是倾斜的,根据水下声场多途干涉理论可知,区域 1中的噪声源与观测之间的径向距离几乎不变,而区域2中噪声源与观测设备之间存在快速的径向距离变化,显然这些噪声来自不同的目标源。事实上由于海洋中存在大量的水面舰、商船等高噪声目标,高强度的低频线谱经几十公里远距离传播衰减后仍能被水声设备观测,因此在水声目标数据中混入其他目标干扰是十分常见的。
在多数情况下,我们缺少足够先验信息对数据中的各种线谱进行标注,也很难利用传统方法从时间或空间上把目标线谱从干扰中辨识并提取出来。
2 水声目标线谱数据挖掘方法
面对已经获得的大量无准确标识的水声目标数据,我们迫切需要一种方法来解决从大量干扰中准确辨识挖掘出属于水声目标的线谱组合特征。舰艇目标在相同工况下的辐射噪声中存在固有的低频线谱序列,在水声目标数据中以固定成组的线谱形式存在。如果多批数据中包含同一目标,而该目标的噪声中存在稳定的线谱特征组合,那么数据中一定包含特定线谱组合的频繁模式(频繁地出现在数据集中的模式,如项集、子序列或子结构)。
因此,这里我们以FP-growth算法为基础,提出一种干扰条件下的水声目标线谱数据挖掘方法,通过挖掘大量水声目标数据的频繁项,获取高价值目标的固有低频线谱结构,并将其作为该型目标的特征模板,为提高对该目标的探测、识别性能提供技术支撑。
2.1 FP-growth算法
FP-growth算法[8]是一种挖掘频繁模式而不产生候选的增长方法,由Han、Pei和Yin于2000年提出。该算法挖掘频繁模式所采取的策略如下:首先,将代表频繁项集的数据库压缩到一棵频繁模式树(FP-树),该树仍保留项集的关联信息。然后,把这种压缩后的数据库划分成一组条件数据库(一种特殊类型的投影数据库),每个数据库关联一个频繁项或“模式段”,并分别挖掘每个条件数据库。对于每个“模式片段”,只需要考察与它相关联数据集。FP-growth算法流程如图3所示,输入为事务数据集D,输出为遍历循环后的FP树-T。
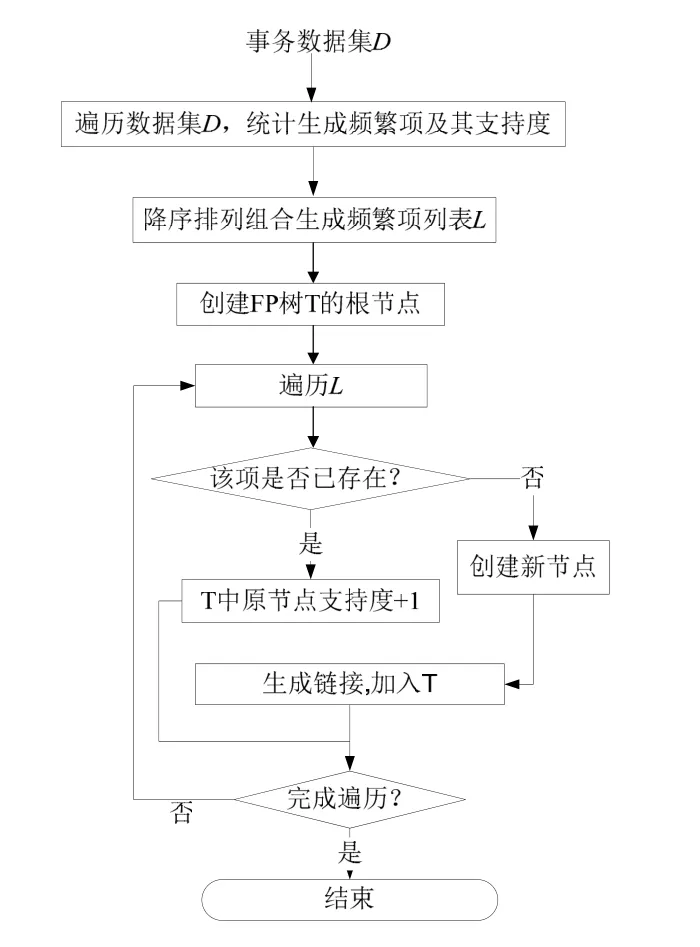
图3 FP-growth算法流程图
2.2 干扰背景下水声目标线谱特征挖掘算法
假定已经获得了一组有N个样本构成的水声目标辐射噪声数据集X={x0,x1,…,xN-1},已知该数据集中大部分都包含有感兴趣的某种目标噪声。但是由于试验条件限制,无法确切知晓哪些数据中有或哪些数据中没有;同时这些数据中还不可避免地混合了很多干扰成分。
为了从数据集中挖掘出感兴趣目标的线谱特征组合,本文所提出算法的处理流程如下:
(1)对每个数据样本进行功率谱分析,提取得到对应的低频线谱序列[3]特征di(0≤i<N);di=[di,0,di,1,…,di,m-1],其中m为变量(不同的样本数据能提取出的线谱数量各不相同),di,j,(j≥0)分别表示第i个样本的第j根线谱频率;
(2)利用 FP-growth算法对特征样本数据集D={d0,d1,…,dN-1}进行处理,构建FP-树;
(3)挖掘FP-树中的频繁项,作为感兴趣目标线谱组合特征:
①遍历并统计FP-树各特征线谱的支持度si(出现次数);
②设定频繁项阈值S,按Si>S对FP-树进行剪枝,得到新FP-树;
③提取新 FP-树中的所有模式,作为最终的感兴趣目标线谱特征。
3 仿真试验
数据样本来自多次的观测试验(仿真),每次观测的浮标和目标数量都是随机产生。典型的试验条件如下:在某海域有若干枚浮标对水声目标进行观测,相邻浮标间距为几公里~十几公里不等;浮标附近存在感兴趣的水声目标,在几十公里之外存在多个不感兴趣的水声目标。图4给出了典型试验条件的示意。
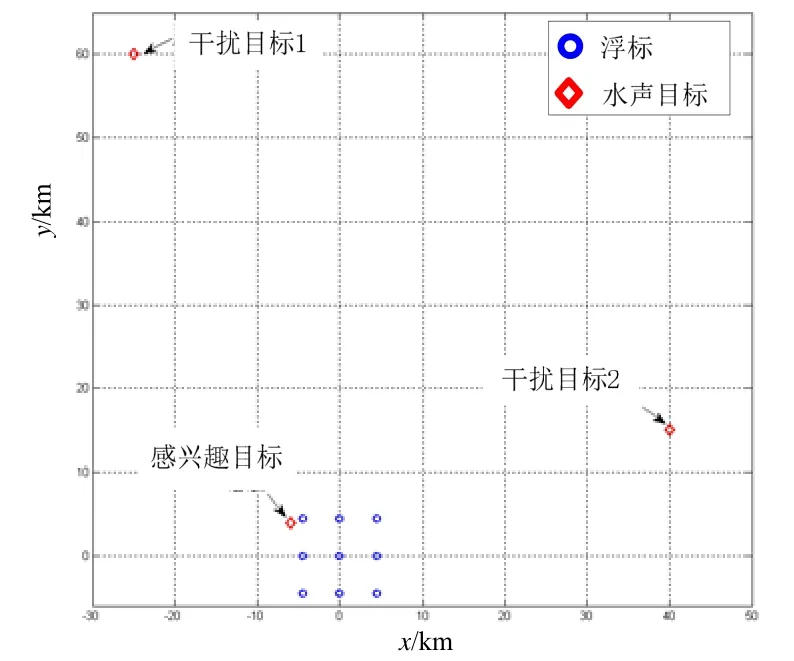
图4 试验条件示意
各种目标信号同时混叠在浮标数据中。海洋背景噪声为中等条件,68 dB @ 1 kHz,环境噪声按照6 dB/oct模型产生;感兴趣水声目标有2种工况,分别对应不同的线谱组合特征(随机设定,不具备实际意义),详见表1。考虑到海洋传播、背景噪声以及各浮标之间的系统差异,每个浮标接收到的线谱信息都存在2 dB方差的独立随机误差(与理想条件相比)。
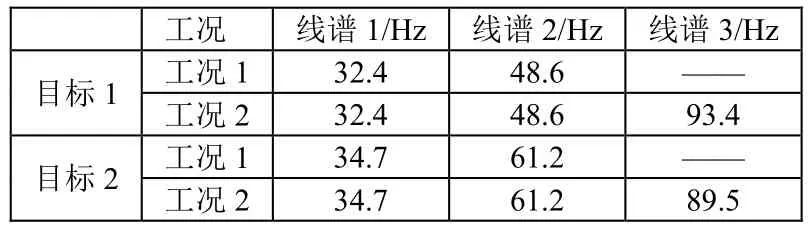
表1 水声目标低频线谱设定
在每次仿真试验中,感兴趣目标存在的概率为50%,对应的工况也是各占50%;不感兴趣水声目标数量M、每个舰船干扰的低频线谱数N及其线谱频率和强度都是随机产生,其中整数M、N都在1~3之间均匀分布,线谱频率分布范围5~150 Hz。一共产生了1000批数据,图5给出了试验中目标、干扰的空间位置分布,图6给出了对数据进行分析后提取的线谱特征的区间支持度,即线谱在该频率区间出现的次数。

图5 所有目标位置分布
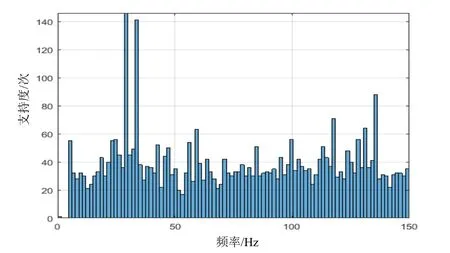
图6 数据样本线谱特征区间支持度
采用本文所提方法对数据集进行处理,图7~图10分别给出了在不同频繁项阈值S条件下得到的FP-树。图7给出了以1000组原始数据为基础构建的 FP-树结构,从图中可以看出由于干扰线谱的存在,原始 FP-树枝叶结构十分复杂,无法通过观察直接得到树的主干(感兴趣目标线谱组合特征)结构。

图7 S=0时(未剪枝)的FP-树
在对原始 FP-树进行剪枝,去掉支持度低(出现频次少)的枝叶留下了主要枝干后,情形得到了改观。图8~10中(a)为原始图,(b)是在(a)的基础上增加了节点名称(圆圈内的数字)与支持度(枝干上的蓝色数字)的标注图。从图8中可以看出,S=20时FP-树剪枝的程度不够,导致留下了很多属于干扰的枝叶,例如99.1 Hz、43.2 Hz、56.2 Hz和22.8 Hz,这种情形往往是由于某些干扰目标固定在观测海域附近活动导致其线谱特征也会频繁出现。图9中采用了更大力度的剪枝参数(S=50),有效地去除了干扰项,只保留了感兴趣目标的线谱特征。图10给出了S=150的结果,此时剪枝力度过大,感兴趣目标的89.5 Hz、93.4 Hz特征成分被当作干扰剪除了,但保留了感兴趣目标最稳定的两组线谱结构。
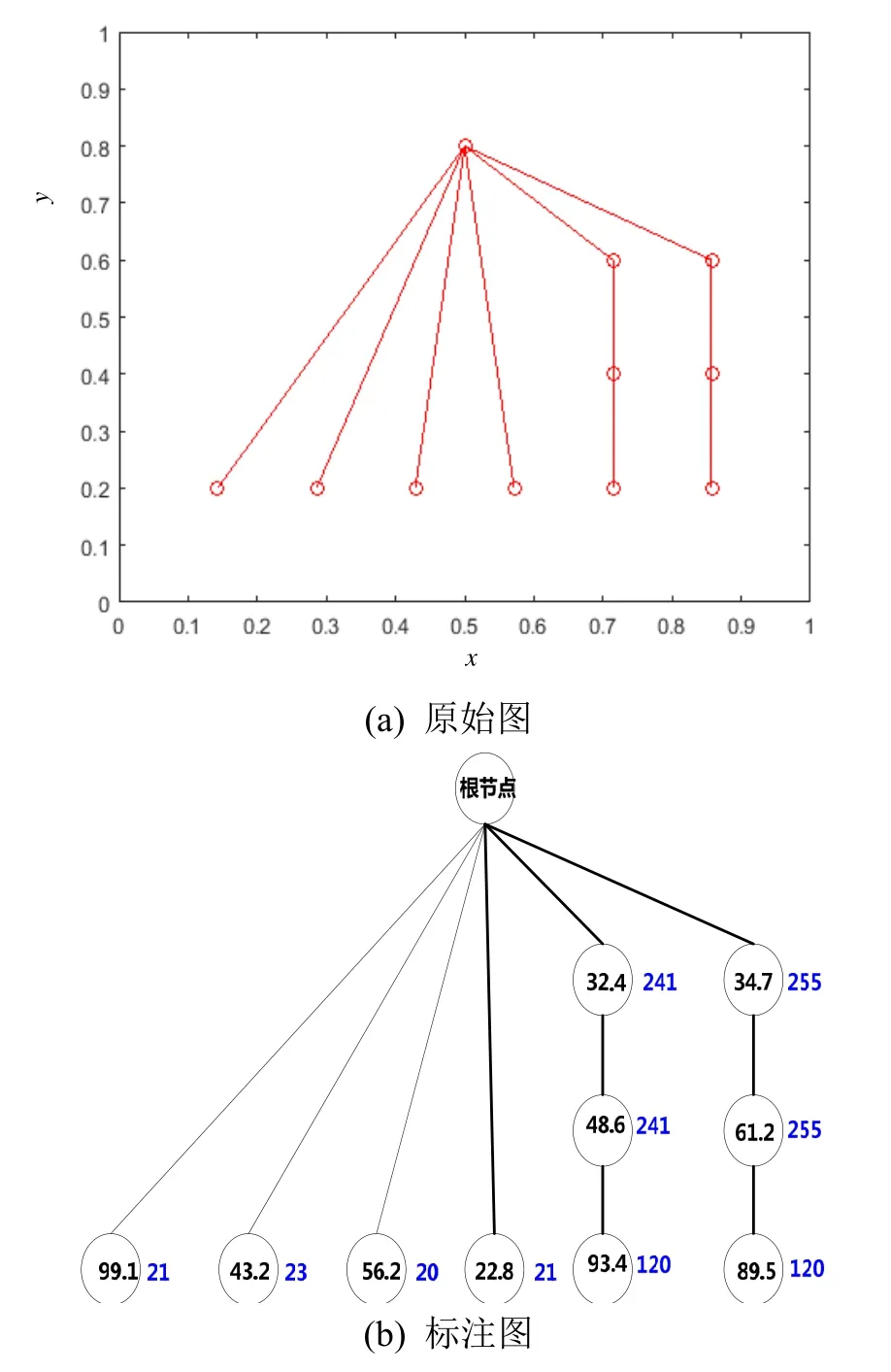
图8 S=20时FP-树
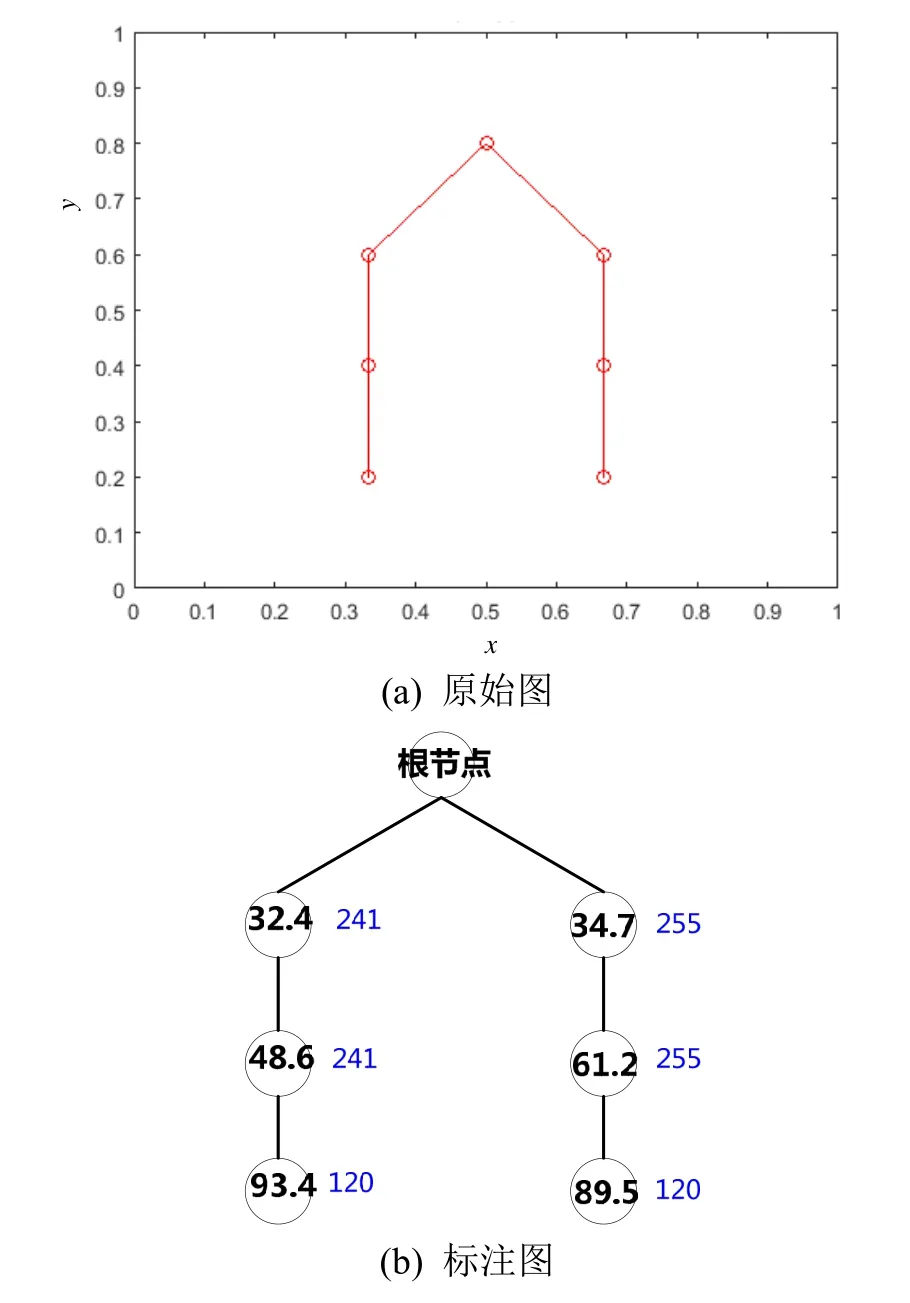
图9 S=50时FP-树

图10 S=150时FP-树
表2~4给出了从剪枝后的FP-树中挖掘得到的频繁模式(线谱组合模式)及其支持度。从表中可以看出,当S=20、S=50时都能获得感兴趣目标的所有线谱组合特征,区别在于S=20时还额外引入了4种干扰线谱的特征组合;S=150时,由于剪除了目标特定工况的线谱特征,只获得了最稳定的特征组合{34.7 Hz,61.2 Hz}、{32.4 Hz、48.6 Hz},其支持度变为真实工况支持度之和。
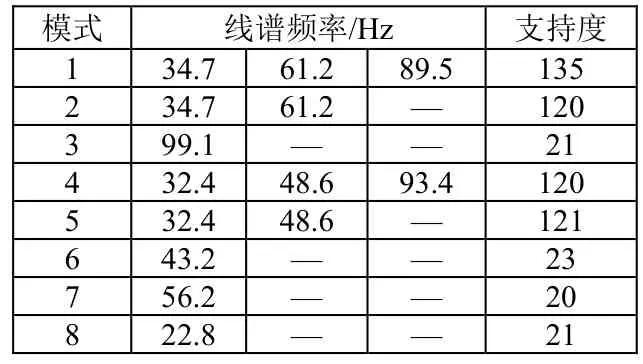
表2 阈值S=20

表3 阈值S=50
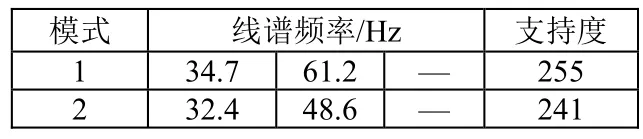
表4 阈值S=150
4 结论
实际环境中获取的水声目标数据中往往混有大量的干扰线谱成分,在缺乏先验知识的条件下常规方法往往难以准确提取感兴趣目标的线谱特征。利用本文提出的方法,能够在大量干扰背景下准确地挖掘出感兴趣目标固有的线谱特征组合及其对应的支持度,仿真试验处理结果证明了本文算法的有效性。本文提出的方法能够准确获取频繁接触的各类感兴趣水声目标的固有线谱组合模式,对提高水声目标的探测与识别具有重要意义。
本文算法需要设定支持度阈值对生成的 FP-树进行剪枝,支持度阈值的设定需要以数据集特性作为依据,例如数据集大小、感兴趣目标/干扰特征的集中度等,在挖掘分析过程中进行适应性调整,以实现去除干扰项和保留目标信息之间的平衡。
猜你喜欢
舰船科学技术(2022年21期)2022-12-12
舰船科学技术(2022年20期)2022-11-28
舰船科学技术(2022年10期)2022-06-17
保健医苑(2022年5期)2022-06-10
成都信息工程大学学报(2021年6期)2021-02-12
兵工学报(2020年9期)2020-11-24
计算机应用(2020年5期)2020-06-07
天津诗人(2017年2期)2017-03-16
电子制作(2017年22期)2017-02-02
电子制作(2017年19期)2017-02-02
