
海底声学底质分类的ELM-AdaBoost方法
2022-01-11 06:17:56王嘉翀吴自银王明伟周洁琼赵荻能罗孝文
海洋学报 2021年12期
王嘉翀,吴自银*,王明伟,2,周洁琼,赵荻能,罗孝文
( 1. 自然资源部第二海洋研究所 自然资源部海底科学重点实验室,浙江 杭州 310012;2. 山东科技大学 测绘与空间信息学院,山东 青岛 266590)
1 引言
海底底质类型的分类识别是海洋科学、海洋资源探测以及海洋军事等领域的重要研究内容,快速、有效、准确地对海底底质进行识别和分类对于海洋科学研究和应用至关重要。基于传统的地质取样方法进行底质识别成本高、效率低[1],而多波束、侧扫声呐和浅地层剖面等海底浅表层声呐探测信号或图像中蕴含着丰富的海底底质信息,通过对上述海底探测声学信号或图像进行分类和识别,以快速揭示海底底质类型,已逐渐发展成一门前沿交叉学科[2]。
近年来,有不少文献将多种机器学习方法应用于海底底质类型的自动分类识别。文献[3-6]利用反向传播神经网络(Back Propagation,BP)对海底底质进行分类识别,但该方法存在收敛速度慢,易陷入局部最优化等问题[7]。文献[8-9]将学习向量量化网络(Learning Vector Quantization,LVQ)用于海底底质分类,但仍存在未充分使用神经元,对初始权值敏感等问题。文献[10-11]利用支持向量机算法(Support Vector Machine,SVM)对海底底质进行分类识别,虽分类精度高、鲁棒性强,但其对核函数的参数过于敏感,且难以解决多分类问题。此外,国内外学者还利用自组织神经网络(Self-Organizing Map,SOM)、ISODATA(Iterative Self-Organizing Data Analysis Techniques Algorithm)算法以及K-均值聚类算法等非监督分类手段[12-16],无需样本训练,分类过程简单,但由于输出数据没有标识,且对异常数据敏感,容易产生错误分类,鲁棒性较差。海底底质分类数据量大,在测量与数据采集过程中进行实时分类识别是其发展的必然趋势[17-18]。现有的海底底质分类方法多继承或改进已有分类器,以单一或两个分类器简单结合的方式往往无法同时满足海底底质快速、准确、实时分类的需求,利用适当的集成算法优化多个弱分类器形成强分类器有望同时满足上述需求。
增强学习或提升算法,能够将弱学习器增强为预测精度更高、预测结果更稳定的强学习器[19]。为实现海底底质快速分类,本文采用极限学习机(Extreme Learning Machine, ELM)作为分类器。该分类器分类效率高,适用于处理数据量较大的样本,已成功应用于水质预测[20]、遥感图像处理[21]等领域。利用自适应增强算法优化极限学习机(ELM-AdaBoost),在ELM高分类效率的基础上可提升其精度和鲁棒性。基于实测侧扫声呐灰度图像,提取均值、标准差、对比度等6个特征向量,对礁石、砂、泥3类典型海底底质进行分类识别,取得了较好的分类结果。
2 极限学习机基本原理
极限学习机算法最早于2005年由Huang等[22]提出,是一种针对SLFNs(即含单个隐含层的前馈型神经网络)的监督学习算法,其主要思想是:输入层与隐含层之间的权值参数,以及隐含层上的偏置向量参数是随机确定的(无需像其他基于梯度的学习算法一样通过迭代反复调整刷新),只需求解一个最小范数最小二乘问题(最终归化为求解一个矩阵的Moore-Penrose广义逆问题)。因此,该算法具有训练参数少、运行速度快、泛化性好等优点。
任意给定N个样本 (Xi,ti), 其中其中m,n分别表示样本数量和类别数。对于一个有L个隐含层节点的单隐层标准前馈型神经网络,可表示为

式 中,g(x)为 激 活 函 数;Wi=[wi1,wi2,···,win]T为 输 入 权重;βi为 输出权重;bi是第i个隐层单元的偏置。Wi·Xj表示Wi和Xj的内积。
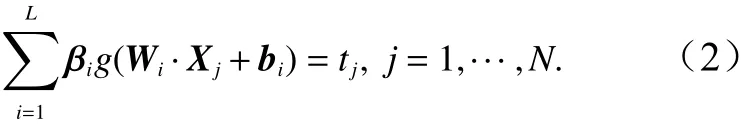
则式(2)可表示为

式中,H为隐含层输出矩阵;β为输出权重;T为输出期望。
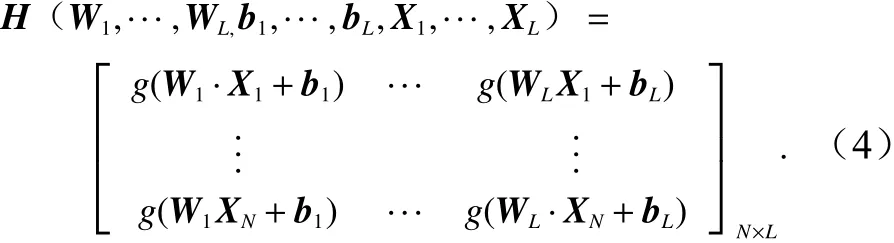
ELM的训练过程即选定隐层节点个数后,随机确定输入权重Wi和偏置bi,然后求式(3)的最小二乘解,可得其中,H+=(HTH)-1HT是矩阵的广义逆。ELM网络结构如图1所示。
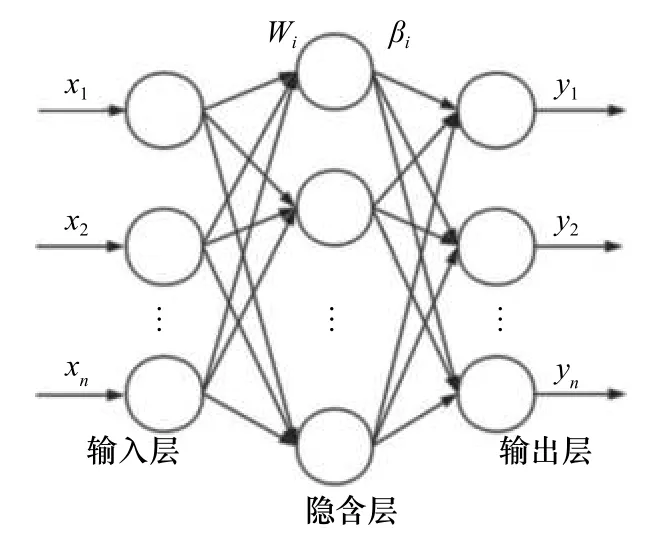
图1 ELM网络结构Fig. 1 Network structure of extreme learning machine
3 ELM-AdaBoost方法实现
自适应增强算法(Adaptive Boosting)是Freund和Schapire[23]于1995年提出的经典集成算法。其自适应性体现如下:前一个基本分类器样本如果被错误分类,它的权值会增大,而正确分类的样本的权值会减小,并用来训练下一个基本分类器。通过迭代、反复学习,组合调整弱分类器直到达到某个预定的错误率或达到预定的最大迭代次数才形成最终的强分类器。
本文采用侧扫声呐图像作为声学底质分类的数据源,基于侧扫图像采用ELM-AdaBoost方法进行海底底质的分类识别主要包括3大步骤:(1)声呐数据预处理;(2)特征向量提取;(3)ELM-AdaBoost网络构建和海底底质分类(图2)。
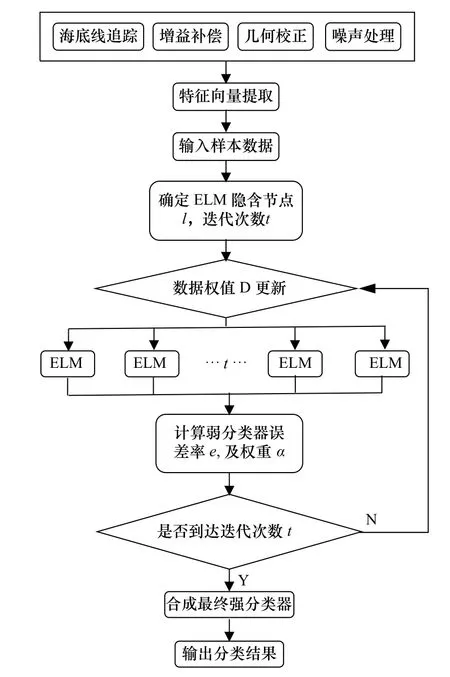
图2 基于ELM-AdaBoost方法的海底底质分类流程Fig. 2 Flow chart of seabed sediment classification based on ELM-AdaBoost method
3.1 声呐数据预处理
由于获取的原始散射数据畸变严重且含有大量噪声,所以需要对原始反向散射数据进行预处理[24-25],为此,本文进行了海底线跟踪、增益补偿和几何校正等预处理,同时通过图斑和条纹噪声滤波处理降低侧扫声呐噪声,提升鲁棒性,使声呐图像能真实反映底质情况,提高分类精度。
3.2 特征向量提取
特征向量作为分类器的输入向量,代表着不同底质各自的特征,是区分不同底质的标识。本文基于侧扫声呐图像进行底质分类,从基本统计量和灰度共生矩阵中提取多种图像纹理特征作为分类的特征向量。
由于纹理是由灰度分布在空间位置上反复出现而形成的,因而在图像空间中相隔一定距离的两像素之间会存在一定的灰度关系,即图像中灰度的空间相关特性。灰度共生矩阵就是通过研究一定方向(0°、45°、90°、135°)上间隔一定距离的灰度级像素之间的相互关系来揭示图像的某些纹理特征。矩阵元素的值就是沿一定方向间距为d时,灰度i和j的像素对出现的概率或频数[26]。Haralick等[27]在灰度共生矩阵的基础上提出了共14种量化纹理的特征向量,主要包括:灰度值、角二阶矩、熵、对比度、协方差等。
为了减少图像中相关性较少或者冗余的图像特征、减少数据维度、提高分类效率,需要进行特征向量降维。本文利用主成分分析方法(Principal Component Analysis,PCA)从所有特征向量中选择关联性较高的特征向量,确定了6个特征向量:
(1)对比度
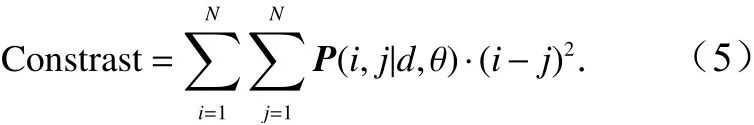
反映了图像的清晰度和纹理沟纹深浅的程度,纹理沟纹越深,其对比度越大,视觉效果越清晰。
(2)相关系数
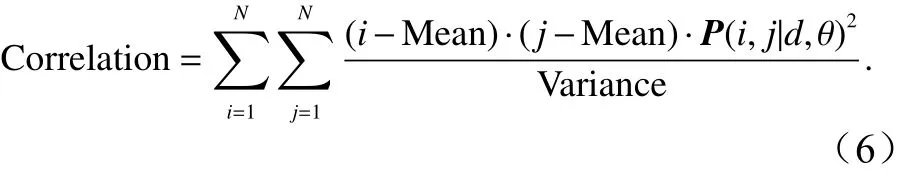
用以度量空间灰度共生矩阵元素在行或列方向上的相似程度。
(3)能量
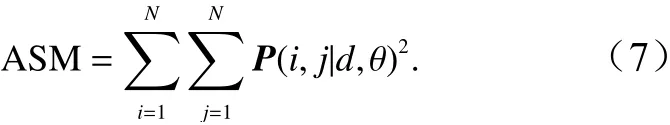
是灰度共生矩阵元素值的平方和,反映图像灰度分布均匀程度和纹理粗细度。
(4)熵
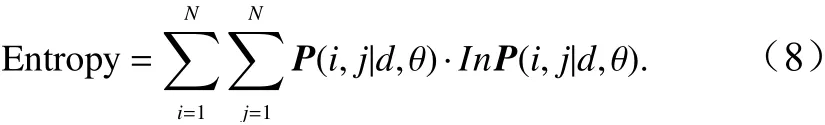
是图像所具有的信息量的度量,表示图像中纹理的非均匀程度或复杂程度。
(5)均值

构成对象所有像元的灰度平均值。
(6)标准差
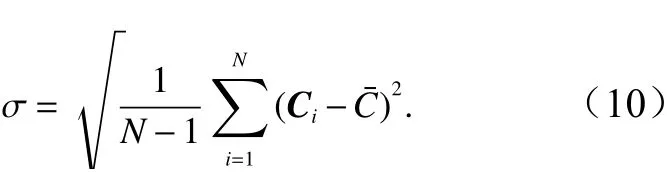
用以衡量对象灰度值的离散程度。
3.3 ELM-AdaBoost网络构建
ELM-AdaBoost网络构建,包括以下5个步骤。
(1)通过数据预处理后的图像提取6种特征向量,作为输入数据。给定训练数据T={(x1,y1),(x2,y2),···,(xi,yi)},i=1,···,n, 其中yi∈{1,-1},用于表示训练样本的类别标签。当xi=yi时,分类正确,类别标签为1;当xi≠yi时,分类错误,类别标签为-1。
(2)初始化训练数据的权值分布。每一个训练样本最开始都被赋予相同权值:训练样本集的初始权值分布如下:
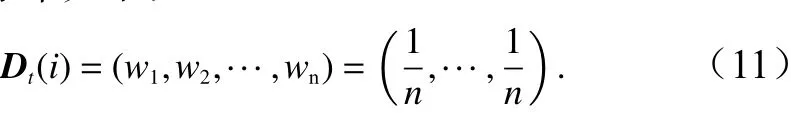
(3)选定ELM分类器的个数,确定迭代次数t,进行迭代:
a.使用初始化的训练集进行单个ELM训练学习以确定最佳隐含层节点个数l,同时得到基本分类器
b.计算分类器Ht(x) 数 据集上Dt的误差率
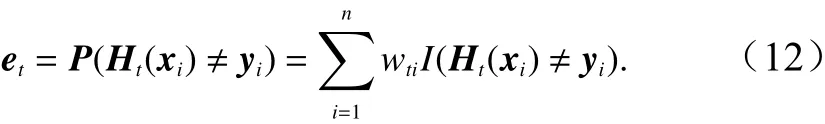
c.计算该基本分类器在最终ELM-AdaBoost强分类器中所占的权重
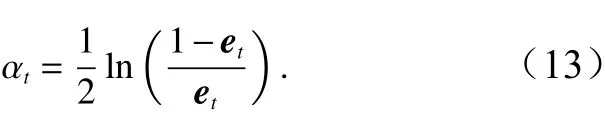
d.更新训练样本的权值分布
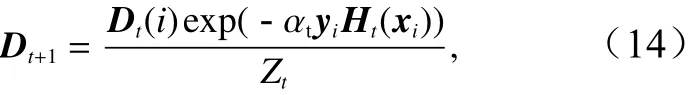
式中,Zt为 归一化常数即分类错误的样本获得更大的权值。
(4)全部迭代完成后,根据弱分类器权重αt组合各个ELM,即:
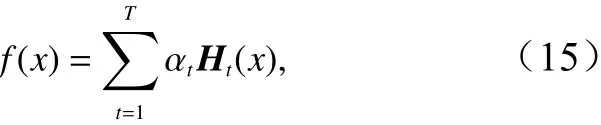
再通过符号函数sign得到最终强分类器ELM-Ada-Boost:

(5)最后利用ELM-AdaBoost分类器对测试样本进行特征向量分类,输出分类结果。
4 实验分析
为验证ELM-AdaBoost方法在海底底质分类中的可行性,本文实验数据来源于908专项海洋调查航次,利用Edgetech 2000DSS侧扫声呐系统在珠江口海区获取了侧扫声呐图像(图3a),其空间分辨率为0.5 m。珠江口海区微地貌类型多样,具有比较典型的礁石、砂、泥类底质,从获取的侧扫图像分析,河口分布有大片的沙波和礁石[28-31]。河口区丰富的底质类型如图3b至图3d所示,分别为礁石、砂和泥3种典型的底质灰度图像。

图3 研究区位置示意图(a)及礁石(b)、砂(c)和泥(d)3种典型底质的声呐图像Fig. 3 Location of study area (a) and three typical seabed sediment sonar images of rock (b), sand (c) and mud (d)
4.1 图像处理与特征提取
从图形校正和噪声处理后的侧扫声呐图像中截取典型的已知底质类型区域,并进行分割和归一化处理,将图像分割成12 ×12的像素单元,得到礁石样本360个,砂样本361个,泥样本322个,总计1 043个样本。
然后,利用主成分分析法选择其中识别精度较高的特征向量,最终确定了均值、标准差、对比度、相关系数、能量和熵6个特征向量(表1)。

表1 礁石、砂和泥3种底质的特征向量Table 1 Characteristic vectors of three types of seabed sediment of rock, sand, and mud
从部分数据中可以看出,礁石的标准差范围为[0.142 0~0.230 5],均值为0.186 2;砂的标准差范围为[0.104 7~0.127 6],均值为0.116 1;泥的标准差范围为[0.220 0~0.302 3],均值为0.261 1。可见不同底质之间特征向量具有差异性,分类器据此进行分类训练。
4.2 分类结果分析与讨论
从1 043个样本中随机挑选,其中700个用于训练,343个用于测试。首先构建单个ELM数据实验,以确定隐含层最佳节点数,结果如图4所示,选取隐含层节点个数l为200,迭代次数t为10次。
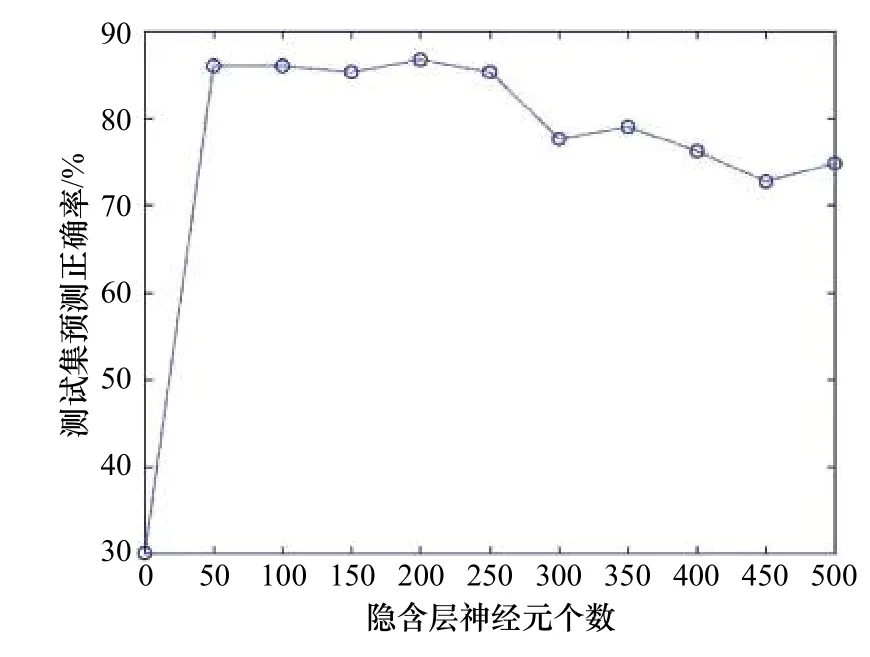
图4 隐含层神经元个数对ELM分类性能影响Fig. 4 The influence of the number of hidden layer neurons on the extreme learning machine classification performance
确定隐含层节点个数和迭代次数后,进行10组ELM-AdaBoost的网络训练,取其平均值作为最终分类结果。同时,为验证ELM-AdaBoost算法的可行性,基于同一组数据进行了多次BP、LVQ、PSO(Particle Swarm Optimization)-SVM和 单 独ELM的 网 络 训练,并取其结果平均值,测试结果如表2所示。
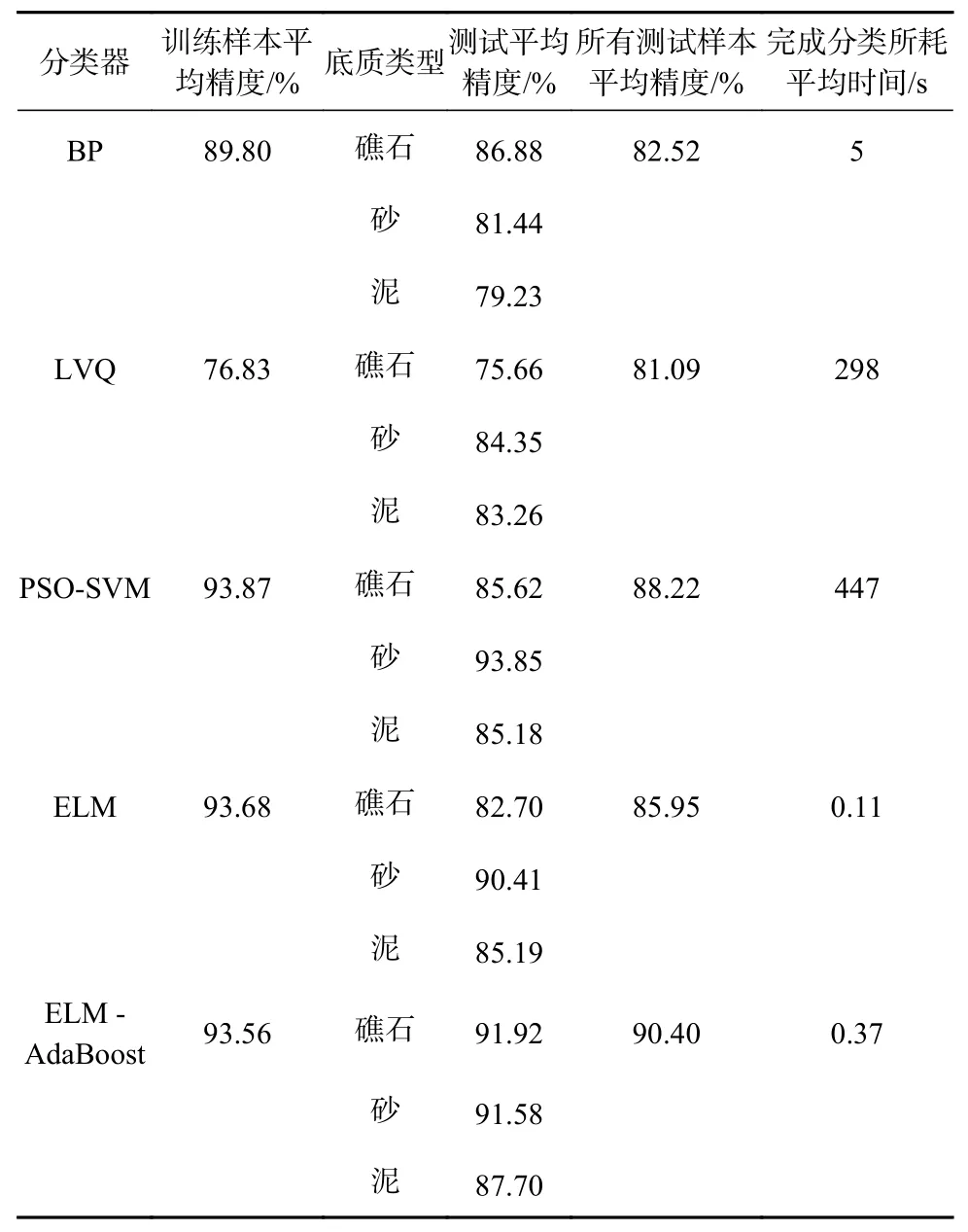
表2 5种分类器的分类性能对比表Table 2 Comparison of classification performance of five classifiers
结合表2和图5可看出,相比于单一ELM弱分类器,ELM-AdaBoost强分类器调整了各个ELM间的权重,即加大其中分类误差率小的分类器权重,使其在最终分类函数中起着较大的决定作用,从而减少了最终分类结果因错误分类所受的干扰,提高了分类的稳定性,最终分类精度提高约5%。
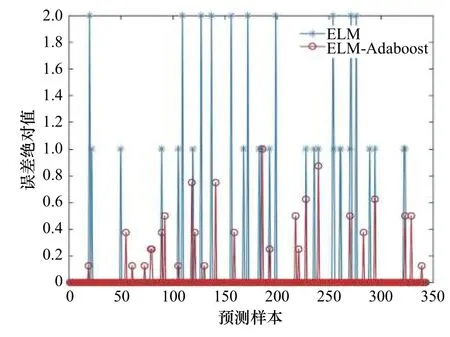
图5 ELM-AdaBoost和ELM误差绝对值对比Fig. 5 Comparison of absolute error value between extreme learning machine-adaptive boosting and extreme learning machine
结合表2和图6可看出,ELM-AdaBoost分类器对于砂、礁石的平均分类精度均超过90%,泥的平均分类精度也接近90%,相比于传统分类方法(BP为83%、LVQ为81%),分类精度有明显提高。从分类器的分类效率来看,ELM和ELM-AdaBoost分类器完成分类所耗时间仅为0.11 s和0.37 s,相比其他分类器有明显的优势。
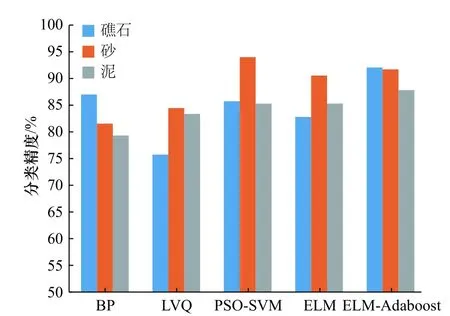
图6 5种分类器的分类精度对比Fig. 6 Comparison of classification accuracy of five classifiers
5 结论
本文充分利用了AdaBoost算法集成多个ELM,通过反复迭代调整各个ELM分类器之间的权值,加大其中分类误差率小的分类器权重,使其在最终分类函数中起较大的决定作用。最终克服了单个ELM输出波动大,模型不稳定的缺点,构建了具有强鲁棒性、高精度的ELM-AdaBoost强分类器。
基于实测珠江口侧扫声呐图像,利用灰度共生矩阵提取对比度、相关系数、熵等特征向量,通过改进的ELM-AdaBoost方法,实现对砂、礁石和泥3种海底底质的分类,其分类精度达到90%,优于单一ELM分类器的平均分类精度85.95%,也优于LVQ、BP等其他传统分类器。同时,在分类效率上,分类时间仅为0.37 s,也远少于其他传统分类器,验证了本文方法的可行性。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
中学生数理化·八年级物理人教版(2022年9期)2022-10-24 07:03:52
水生生物学报(2022年6期)2022-07-08 09:31:56
海洋通报(2022年2期)2022-06-30 06:06:28
保定学院学报(2022年2期)2022-04-07 02:26:50
海洋通报(2021年1期)2021-07-23 01:55:24
海洋信息技术与应用(2020年3期)2020-08-24 07:25:10
小学科学(学生版)(2019年10期)2019-11-16 08:55:14
许昌学院学报(2018年4期)2018-05-02 12:27:37
海洋渔业(2017年5期)2017-11-07 02:34:58
