
ALBERT与双向GRU 的多标签灾情信息预测
2022-01-11 09:35杨百一李晓丽
科学技术与工程 2021年35期
李 忠, 杨百一, 李 莹, 李晓丽
(防灾科技学院应急管理学院, 廊坊 065201)
自然灾害事件具有紧急性和突发性的特点,往往会造成人员伤亡和社会经济的巨大损失。正因为如此,在巨灾发生时,如何快速、有序、高效、准确地收集灾情信息是迫切需要解决的问题。社交媒体作为在灾难响应和恢复阶段的重要部分,及时响应受害者的请求可以极大提高受害者的生存概率[1]。目前已经有很多研究人员运用灾难中社交媒体发布的数据来获取灾区的情况,但往往会存在信息获取能力不足的问题,包括不能全方位多角度地获取信息和信息关联能力不强,不能对收集上来的信息做出准确的划分,以至于错失许多关键信息[2]。社交媒体可以收集大量与灾情有关的信息,可以帮助应急管理人员面对不同规模、范围和性质的灾情。但是,关键信息的错误传递,可能会导致救援效率降低。如何指定有效的信息传递战略,是目前亟待解决的问题。为此中外人员针对社交应急响应数据作了相关研究。国外研究人员主要在推特上收集灾难响应数据,及时发现灾区情况,如Zahra等[3]利用在推特上收集的信息,以识别灾害发生后的目击者类别为目的建立文本分类器,以此来提高在灾难中识别具有价值的目击者报告;Benitez等[4]通过推特收集与灾害相关的信息对文本进行分类,针对数据量大、分类精度低等问题,利用遗传算法降低特征空间的维数,去除不相关的、冗余的特征以此来提高分类精度。中国研究人员主要以微博数据为依据,通过收集相关的灾难响应数据,进行文本分类以达到了解灾区灾情的目的。吴先华等[5]通过微博大数据获取有关暴雨内涝灾情的数据,利用TF-IDF(term frequency-inverse document frequency)进行特征选择,建立暴雨灾情内涝表,以此来获取灾区的灾情以及公众情绪。徐敬海等[6]以带有位置的地震灾情信息作为数据源,通过应用反距离空间差值法,实现微博灾情信息面状化。王琳等[7]针对地震应急信息,通过“关键词分类”将地震应急信息分为震前基础信息、震中灾情信息和应急援助信息,以达到地震应急信息自动分类的目的,提高对应急响应信息处理的效率。
虽然上述方法可以实现在大量灾难响应信息中获取关键内容,但同一条灾难响应消息可能存在多个标签。如何从一条相关灾难响应的社交媒体文本中提取所有关键信息,并根据匹配度对标签排序,需要对灾难响应文本数据进行多标签数据挖掘。现针对含有多标签的灾难响应信息,利用深度神经网络模型提取相应的标签信息,有效提高对灾难响应信息的利用效率,达到尽快实施救援的目的。
1 文本分类模型
文本分类研究是数据挖掘技术应用的一个重要领域,涉及特征提取、算法设计、软件开发等多个方面,前人已经做了很多基础性研究工作。
1.1 词嵌入模型
所谓词嵌入模型,就是将文本信息转化为数字向量的模式。最原始的算法是将文本信息转化为0-1模型,即one-hot编码,用0和1两个数字来表示字符是否出现在文本中,但这种方法会因为数据量变大而导致计算变得复杂。Salton等[8]提出TF-IDF模型,TF-IDF是计算特征词在文本中的权重,其取值范围在[0,1]之间,其中TF指该特征词在这篇文档中的词频。虽然这种方法可以提取出文本中的特征词,但是如果把所有词都作为特征项,会导致特征向量过大而使得计算速度下降,那么如何在不损害文本特征信息的同时降低特征性向量的维度呢?Karen等[9]提出了逆文档词频 (inverse document frequency,IDF),表示区分文本的能力。Mikolov等[10]提出了Word2Vec模型,一种利用神经网络进行词嵌入的学习方法,但该模型未能有效地利用所有文本信息。BERT(bidirectional encoder representation from transformers)模型,建立在Transformer之上,具有强大的语言表征能力和特征提取能力[11],但该模型可复现性差,模型收敛速度较慢,需要极高的算力才行。为改进BERT模型的收敛慢问题,Lan 等[12]提出了一种双向编码特征表示模型——ALBERT(a lite BERT)文本预训练语言模型,其先对大量文本数据进行预训练,再根据下游任务进行调整,达到提高下游预测效果的目的。ALBERT 预训练语言模型是基于BERT模型的双向Trandformer编码器的特征表示方式,可以在保证较少参数量的同时,提取文本的主要特征。
1.2 多标签分类模型
目前,关于多标签数据挖掘问题,主要分为两类:一类是多标签分类,另一类是多标签排序[12]。二者的不同在于后者可以返回类别标签的同时对标签匹配度进行排序。
从模型建立上看,文本的多标签分类一般有两种:一种是传统的机器学习模型,如SVM、DT、Naïve Bayes、DT、Xgboost等算法;另一种是深层网络机器学习模型,如RNN、CNN、LSTM和GRU等。从解决问题角度上看,文本的多标签分类包括问题转换法和算法适应法,其中问题转化法是将多标签文本分类转化为一个由多个单标签分类组合而成的问题,这样对多标签分类的问题求解就变成对单标签文本分类问题的求解,如BR(binary relevance)二元关系法和LP(label powerset)标签幂集法等[12]。而算法适应法则是通过对算法的改进,使二分类算法也可以解决多标签分类问题。本文中所使用的多标签分类算法是利用双向GRU神经网络对灾难响应信息的标签进行预测。
2 结合ALBERT和双向GRU的文本多标签分类
若要对文本信息进行多标签分类,需要先将文本进行预处理,再将预处理后的文本信息利用ALBERT预训练模型提取特征,得到词嵌入向量。根据提取的词嵌入向量,利用Attention机制的双向GRU神经网络进行训练,以到达多标签分类预测的目的。
2.1 ALBERT模型
为了利用模型对文本进行多标签预测,需要将一条文本信息利用向量来表示,这可以利用词嵌入模型实现。为了解决BERT参数量大的问题,ALBERT采用双向Transform的encoder结果表示文本的特征,模型结构图如图1所示。

图1 ALBERT模型结构图Fig.1 Structure diagram of ALBERT model
Ti表示句子中第i个词的特征向量,Ei表示文中第i个词的序列化字符。在BERT的基础上,ALBERT进行了3个方面的改进[13]。
2.1.1 词嵌入向量因式分解
通过对大的词特征嵌入矩阵分解,得到两个相对较小的矩阵,从而将隐含层分离出来。利用因式分解,将模型的复杂度从O(VH)降到O(VE+EH),复杂度变化为
O(VH)→O(VE+EH)
(1)
式(1)中:V表示词汇表长度;H表示隐含层大小;E表示词嵌入大小,当E≪H时参数量会明显减少。
2.1.2 跨参数共享
针对参数过多的问题,ALBERT利用多层参数共享策略减少参数,包括全连接层和注意力层的参数共享。这种做法可以避免当模型网络深度增加时,参数数量也随之增加。
2.1.3 段落连续任务
ALBERT对BERT中的NSP(next sentence prediction)任务进行改进,为了消除主题识别的影响,提出了SOP(sentence-order prediction )任务,可以在同一个文本中选取正负样本,不受句子顺序的影响。
2.2 双向GRU神经网络
传统的神经网络是单向的,状态从前向后传播。但是在多标签文本分类中,为了对文本进行更深层次的特征提取,让前一时刻的输出与后一时刻的输出联系在一起,采用双向GRU神经网络模型[14],其结构如图2所示。

图2 双向GRU神经网络结构图Fig.2 Structure diagram of bidirectional GRU neural network
从图2中可以看出,双向GRU可以看作两个单向GRU组合而成,在t时刻隐含层的状态由其前后时刻的隐含层状态决定,可表示为
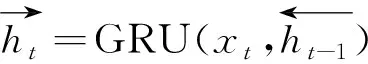
(2)
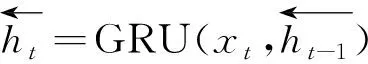
(3)
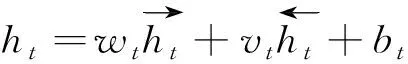
(4)

2.3 Self-Attention机制
Self-Attention机制是从大量的文本信息中提取出具有价值的信息,在自然语言问题中,需要对文本进行编码和解码[15]。编码器负责把文本转化为指定长度的词向量,即该文本的语义。解码器负责将词向量作为输入变量送入模型中,生成指定长度的序列。Self_Attention机制就是在解码的过程中对不同的字符赋予不同的权重,计算公式为
ut=vttanh(wh+wd)
(5)
at=softmax(ut)
(6)
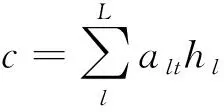
(7)
式中:ut表示输出向量与解码时状态的相似度计算;l表示向量的个数;w表示权重;h表示每一步的输出向量;d表示解码时每一时刻的状态;c是计算向量匹配度后的权值相加,计算后的向量用于解码器中每个时间步的输入;a表示向量匹配度softmax后的匹配权重。
2.4 模型建立
令输入样本表示为X={X1,X2,…,Xn},标签样本表示为Y={Y1,Y2,…,Ym},其中n表示有n条样本信息,m表示有m个类别的标签。Yi=1 时表示文本属于该标签,Y2=0表示不属于该标签。
首先利用ALBERT预处理模型对文本进行向量转化,转化后的向量矩阵用E=(E1,E2,…,En)表示,即词嵌入向量,Ei表示第Xi字符的向量表示。再将输出的词嵌入向量进行双向Transform编码,得到文本的特征向量T=(T1,T2,…,Tn),作为双向GRU网络的输入。结合Attention机制,进一步提取文本中的关键信息,最后,以交叉熵作为损失函数对神经网络模型进行编译。利用全连接层对结果进行归一化,得到响应信息的标签概率分布矩阵。计算流程如图3所示。

图3 网络结构图Fig.3 Network structure diagram
3 实验结果与分析
3.1 数据源
本文中采用开源数据集(Appen)中的多语言灾难响应数据。该数据集共有26 248条数据,来自于若干年关于自然灾害的新闻报道,包括2010年海地地震、2010 年智利地震、2010 年巴基斯坦洪灾、2012 年美国超级风暴桑迪等。作为标准数据集,其中训练集、测试集与验证集的数据量如表1所示。

表1 数据集划分
在该数据集中包含37个与应急响应信息相关的标签,每一条文本信息可以标记多个标签。根据数据集标签的属性,将其分为3个级别:一级标签为文本是否与灾情相关;二级标签将灾情信息分为五类,分别为援助相关、灾民相关、物资相关、灾况相关和灾区相关;三级标签为更具体的救灾信息分类。详细数据标签分类见表2。

表2 数据标签分类详情
3.2 评价指标
针对文本多标签分类问题,评价指标主要有准确率(accuracy)、汉明损失(Hamming loss)、微平均F1值(Micro_F1)。
3.2.1 准确率
准确率A体现计算预测标签是否完全与实际标签相符合,其计算公式为
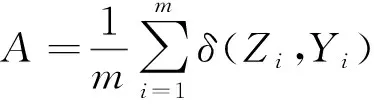
(8)
式(8)中:m为样本数量;Zi表示真实值;Yi表示预测值;δ(Zi,Yi)表示真实标签是否完全匹配预测标签,若完全匹配,则δ(Zi,Yi)为1,否则为0。
3.2.2 汉明损失
汉明损失(LHam)表示在所有预测的类别中错误样本的比例,数值越小,预测标签越准确。其计算公式为
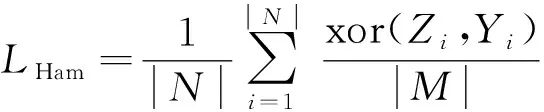
(9)
式(9)中:N为样本数量;M为标签个数;Zi表示真实值;Yi表示预测值;xor( )表示异或运算;Zi与Yi相同为0,不同为1。
3.2.3 Micro_F1
多标签前分类的F1-Score分为微平均Micro_F1和宏平均Macro_F1。其中微平均为计算所有类别标签的精确率和召回率后,再计算F1;宏平均为先计算出每一个类别标签的精确率和召回率,再计算平均的F1值,该值越大,分类效果越好。为表示模型对整体文本的预测效果,本文中以微平均作为评价标准,其计算公式为

(10)

(11)
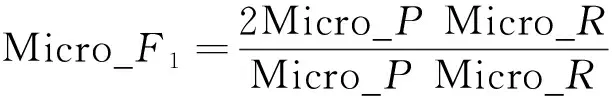
(12)
式中:TPi表示真实值为1、预测值也为1的样本数;FPi表示真实值为0、预测值为1 的样本数;FNi表示真实值为0、预测值为0的样本数;Micro_P表示预测的精确率;Micro_R表示预测的召回率;Micro_F1即为微平均F1。
3.3 参数设置
部分双向GRU网络参数设置如表3所示。表中Input_size表示输入特征维数,Hidden_size表示隐含层的维数,Embedding_size表示词嵌入大小,Output_size表示输出层维数。

表3 模型训练参数
3.4 结果与分析
训练结果如图4所示。从图4中可以看出,训练集的损失和测试集的损失均不断下降,说明双向GRU网络仍在学习,且学习效果较好。在迭代次数(echo)为10时,测试集的损失值为0.137,准确率达到95.6%,说明模型预测的效果较好。

图4 网络损失值与准确率变化趋势图Fig.4 Variationtrend of network loss value and accuracy
表4为不同词向量转化模型和文本模型的对比分析,其中词向量转化对比模型采用TF-IDF,预测对比模型采用逻辑回归、朴素贝叶斯和LSTM长短期记忆神经网络。从表4中可以看出,本文中提出的文本多标签分类模型在准确率、F1-Score、汉明损失上的效果均优于其他预测模型。

表4 不同模型训练效果对比
因本文中以Sigmoid作为双向GRU网络模型的激活函数,所以求得的结果为标签概率分布矩阵。若要达到标签自动分类的目的,需确定多标签分类阈值。本文中利用模拟退火算法对阈值求解,通过计算得出最优阈值为0.34。将结果与阈值为0.5和0.7的结果进行对比,如表5所示。从表5中可以看出,利用模拟退火算法计算的阈值多标签分类效果优于其他阈值效果。

表5 不同分类阈值预测效果对比
4 结论
在当今大数据时代,一旦有灾害发生,就会有若干人在社交媒体、数字网络等发布成千上万的灾难响应信息,如何识别出与灾情有关的信息并将请求帮助信息推送给救援组织,这对于提高救援质量和救援效率是非常重要的一项工作。从以下几点在分析了文本信息分类模型在灾后救援中的作用。
(1)针对大量的灾情响应信息,按照与灾害和救援相关的37个标签,提出了结合ALBERT和双向GRU神经网络的多标签文本信息分类模型,自动地对响应数据进行标签识别。
(2)以开源数据集(Appen)中的多语言灾难响应数据作为数据源进行计算,并将结果与逻辑回归、朴素Bayes和LSTM等方法的结果进行对比。
(3)实验结果显示,该模型可以有效地识别出文本的标签,准确率更高,汉明损失更小,能够更好地辨别灾情求助信息,提高救援效率。
猜你喜欢
出版人(2022年11期)2022-11-15
江苏安全生产(2022年8期)2022-11-01
新高考·高一数学(2022年3期)2022-04-28
今日农业(2021年19期)2021-11-27
数学小灵通(1-2年级)(2021年10期)2021-11-05
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
人大建设(2018年7期)2018-09-19
环球时报(2018-07-11)2018-07-11
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
