
基于Cesium时空三维可视化的数据调度与缓存机制
2022-01-11 09:33徐明瑞肖桂荣
科学技术与工程 2021年35期
徐明瑞, 肖桂荣
(福州大学数字中国研究院(福建), 福州 350108)
传统三维可视化受制于数据调度缓慢、集成度较低、信息化形式单一等问题,未能实现真正意义上的集成多种数据源数据的三维可视化。随着新一代数字地球、WebGL、三维GIS(geographic information system)等技术的深入发展,多种领域开始通过构建三维虚拟仿真平台来集成、模拟、管理多源地理信息和数据。国家公园具有物种、地理、生态等数据复杂多样性的区域特点,引入时空三维可视化是目前首批试点的国家公园数字化建设的一种重要应用方式,是国家公园体制建设的重要基础[1]。如何对国家公园大规模、多尺度的地理空间分布特征和生态环境监测指标等多源数据进行高效的集成管理,并在三维实景环境中进行流畅、快速的调度是目前亟待解决的问题。
目前通过三维可视化进行国家公园管理方案的设计尚处在试点阶段,已经运用到应用层面的较少。王丽娟等[2]基于ArcGIS、PostgreSQL设计并开发了三江源国家公园信息化平台,实现了三江源国家公园电子地图展示、公园信息概览、物种预测等功能。朱清等[3]提出黄山时空信息云平台的整体设计,通过构建时空大数据挖掘系统,建立知识服务与云服务体系,应用于智能感知时空数据汇聚展示。邱天等[4]提出采用Vue框架管理多源数据,组件式开发祁连山国家公园三维WebGIS的思路。但这些案例通常采用地图与文字的单一结合,与三维场景的集成度不高,未解决三维场景绘制效率低、数据调度加载慢等问题。现通过基于底层WebGL技术并继承WebGL的优良特性的三维图形引擎Cesium[5],从多源数据的组织管理、Web端的动态加载调度以及实时渲染过程中的缓存机制出发,提出双线程数据调度策略,并建立二级缓存机制与数据瓦片更新策略,实现对国家公园多源数据的快速调度和三维场景的流畅表达。
1 数据处理与模型搭建
武夷山国家公园位于福建省武夷山脉的北部,涉及福建省武夷山市、建阳区、光泽县和邵武市(均为南平市行政范围),总面积约为1 001.41 km2,园内包括国家级自然保护区、风景名胜区和介于二者之间的过渡区(九曲溪上游保护地带),是世界同纬度带最典型、最完整、面积最大的中亚热带原生性森林生态系统[6]。现有的武夷山国家公园数据需要从不同的途径进行收集获得,导致数据来源途径广,格式不统一。因此结合三维GIS、Cesium技术的优势,将不同坐标系以及不满足加载格式需求的多源数据进行规范整合,并进行参数化集成。通过对这些数据有效的存储、转换和调用,为研究武夷山国家公园时空三维可视化及生态保护管理奠定研究基础。如图1所示。其中多源数据包含矢量数据、地形数据、专题图与交互图表、监测数据等。

图1 武夷山国家公园多源数据Fig.1 Multi-source data of Wuyi mountain national park
1.1 TopoJSON数据转换
武夷山国家公园数据库包含了园区区划边界、功能区划矢量图、交通、水系、植被、监测站点等点线面要素构成的GIS矢量数据。由于这些GIS矢量数据是Cesium无法直接加载的Shp格式,因此将GIS矢量数据经过数据预处理转换成Cesium能够传输加载的JSON格式至关重要。GIS服务器负责从数据库提取相关空间数据并将相关矢量格式转换成JSON格式,GeoJSON是Web端传输过程中常见的基于JSON的网络矢量交换格式。GeoJSON的几何对象包括点、线、面以及由以上类型组合成的复合几何图形来表示矢量要素[7]。然而在面对国家公园有拓扑关系需求的矢量要素进行展示时GeoJSON表达能力以及传输效率存在明显不足,尤其是国家公园矢量数据需要拓扑化的过程中,难以保证要素之间的关系不发生变化。
为了改善这一问题,采用对多边形覆盖较好的TopoJSON格式作为矢量传输格式。TopoJSON是在GeoJSON的基础上进行扩展对拓扑进行编码,允许简化保留拓扑的形状,从而确保相邻特征在简化后保持连接,共享的弧段仅存储一次消除了数据冗余,相比GeoJSON最多可以节省80%的存储空间。通过数据处理工具CesiumLab将基础空间数据包含行政区划、功能区划矢量图、道路、水系、居民地、植被等shp文件转化为TopoJSON格式,按照TopoJSON的层次对获取到的矢量数据进行解析,使用TopoJSONDataSource对象的加载方法,并在其对象的DynamicObjectCollection中添加创建对象。解析完成之后,通过函数Cesium.Topojs.load将经过转换的矢量数据存入Cesium的数据源集合中。最后根据矢量要素的几何类型,创建对应类型的几何对象,并添加到三维场景viewer.scence对象的Collection属性中,完成矢量数据向TopoJSON格式的转换与三维可视化加载。
1.2 基于八叉树的三维数据组织模型
Cesium图形引擎本身支持STK World Terrain和Small Terrain两种由流式传输瓦片数据构成的基于mesh的地形类型[8]。STK World Terrain支持Cesiumion在线访问,但是由于该地形服务部署于外网,因数据量庞大受带宽和网络环境影响明显,导致应用过程中页面卡顿、无法加载等问题。由于地形的构建一般不会构建全球级别的地形数据,通常只构建感兴趣的区域数据[9]。通过选择武夷山国家公园区域的数字高程模型(digital elevation model, DEM),经过数据预处理叠加数字正射影像(digital orthophoto map, DOM)生成Small Terrain,并基于八叉树金字塔结构实现对地形数据的分层分块,将预处理后的数据以二进制的方式存储到数据库中,并设置相关索引,根据索引提取资源管理队列中的地形数据,按照请求实现地形数据的三维场景绘制渲染。
八叉树结构的地形金字塔模型的构建原理与四叉树结构思路相似,区别在于基于八叉树处理的基本单元是立方体而非矩形,即进行合并、分割的操作单元是立方体。如图2所示,自上而下每一层的节点都是其下一层8个节点的像素合成,在表示范围不变的情况下,分辨率越来越低,尺寸越来越小。

图2 八叉树金字塔结构Fig.2 Octree pyramid structure
将原始地形作为八叉树金字塔结构的最底层,可以根据地形尺寸的大小,确定一个完全包围地形大小的2N×2N的范围,获取地形数据尺寸的最长边terrian_max及高程数据中的最大值dem_max,由terrian_max/(dem_max-1)计算得到包含的高程子块个数k,然后求得2N×k的像素值落在具体的层级取正整数,即可得到地形块的大小。对于下一层级的地形分辨率是上一级地形分辨率的1/8为前提,则通过CesiumLab工具库的八叉树处理器重复实现,直至子块不能分割最顶层数据块分割时停止。
与适用于二维场景的四叉树结构相比,八叉树结构能够更好地应用于三维地形场景的快速几何运算,结合八叉树结构对地形数据的分块,能够实现快速进行最邻近区域或点的搜索[10]。利用CesiumLab将Web前端无法直接解析的数值高程模型TIFF格式使用ctb-tile指令加工成terrain文件,配置于CTB(cesium-terrain-builder)环境中,并部署于服务器端,通过Cesium接口调用得到分层分级显示的地形数据,能够便于客户端解析以及文件传输。相比于STK World Terrain的30 m分辨率,生成后的Small Terrain 90 m分辨率虽然略逊一筹,但是武夷山国家公园区域内96%的面积为山地和植被,对分辨率要求不高,满足本文中实现数据的本地部署和三维展示的研究,如图3所示为山区地形效果图。

图3 山区地形效果图Fig.3 Effect map of mountainous terrain
2 多源数据调度与缓存策略
2.1 双线程数据调度策略
三维场景实时绘制过程中,执行具体绘制操作的同时还需要根据视点位置等信息对参与绘制的数据进行调度。数据调度的效率在大范围的三维场景实时漫游过程中至关重要,一方面数据调度的效率取决于随视点信息变化而变化的场景数据调度次数,另一方面取决于执行相关绘制操作的时间。目前三维场景数据调度策略面临数据I/O读取时间过长、跳帧现象以及内存数据量无法动态平衡等三个主要问题[11]。从三维场景绘制过程中稳定性和流畅性出发,提出绘制线程与调度线程并行的双线程数据调度策略,具体流程如图4所示。
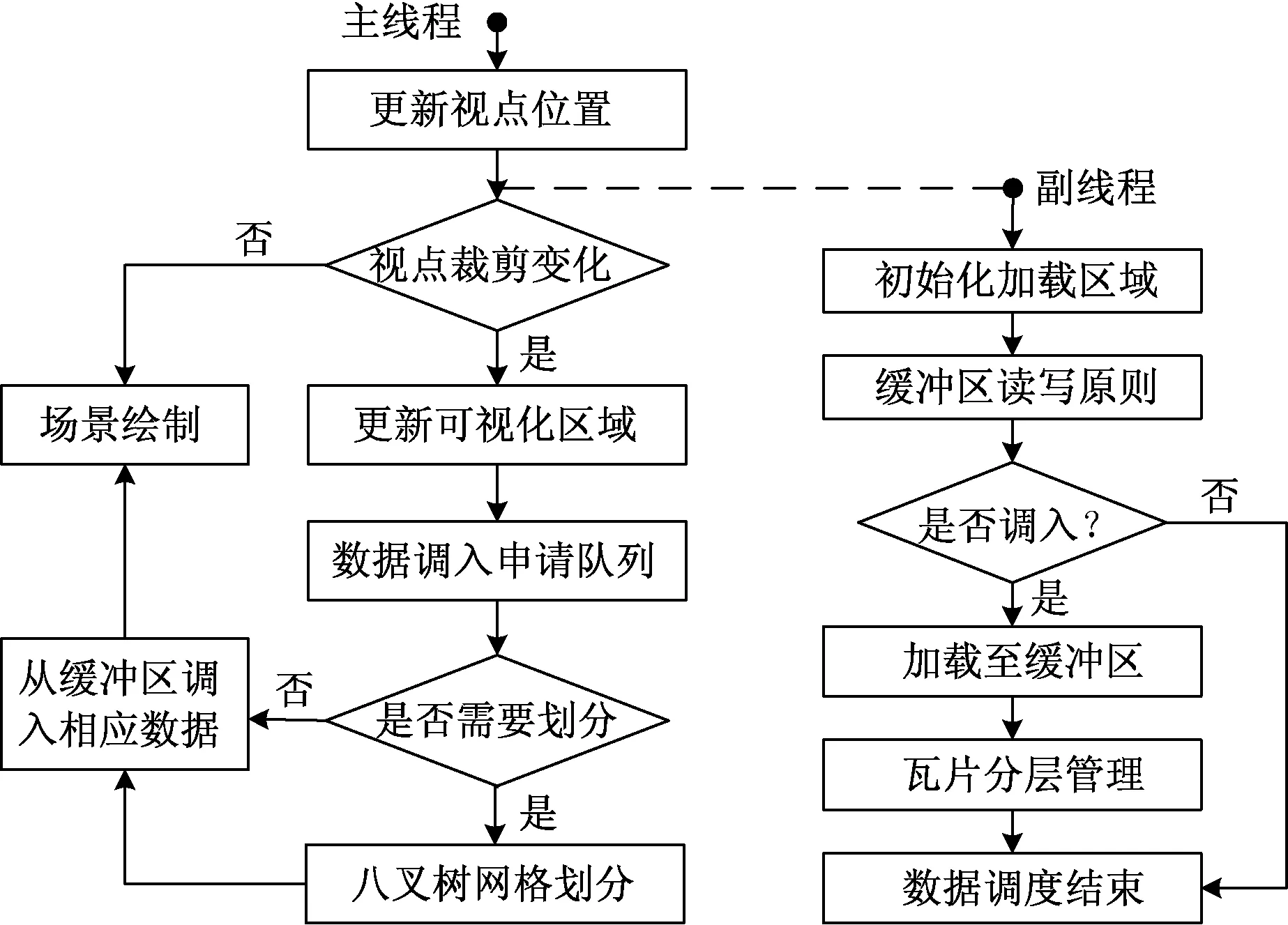
图4 双线程数据调度Fig.4 Two-threaded data scheduling
双线程数据调度策略即包括以绘制线程为主线程,调度线程为副线程的两种并行调度模式。
(1)在调度线程中,任务列表首先会根据实时任务信息生成相应的参数请求,更新当前相机视点的位置坐标初始化加载区域。然后根据缓冲区读写原则,判断是否需要调度相应瓦片数据加载至缓冲区。最后在数据加载之前将相应瓦片对象调入瓦片队列中,根据瓦片分类管理机制对瓦片进行分层管路和控制,完成对数据的调度任务。
(2)在绘制线程中,首先经过视点裁剪变化更新初始化区域,把缓冲区内视景体瓦片节点的编码和地形数据调入可视区域申请队列中。然后根据视点距离判断经过遍历可视化区域内的瓦片是否需要进一步划分,若不划分则直接从缓冲区调入相应瓦片数据,若需要划分,则另外创建一个堆栈,将该瓦片压入堆栈,并进行八叉树划分,划分结束之后弹出该节点。对于新产生的八个节点,按照逆时针重复划分步骤,直至所有节点都完全成为叶子节点。最后根据叶子节点所在瓦片的索引信息,解析出相应的层级、行号TileX、列号TileY等信息,并将其加载至显存中用于绘制。当等待队列中所有的瓦片请求全部执行完成上述步骤后,则清空队列,同时作为下一帧开始的请求队列使用。
2.2 二级缓存渲染机制
三维场景漫游过程中仅仅只有数据调度策略还不够,受内存大小的限制,即便将常用的数据筛选出来,在长时间漫游过程中仍然会产生大量冗余数据。实时渲染过程中的数据需要预先从外存调入内存,然后再从内存中传入到GPU(graphics processing unit)渲染管线,庞大的数据量不仅需要巨大的外存空间用于内外存之间的频繁调度,还需要较高的内存用于网络环境下的绘制渲染,在这一过程中任何一个阶段出现问题都会导致渲染效率低下。为了减轻服务器的负担和提高显示速度,通过在内存中设定一定大小的缓冲区建立二级缓存机制,将相关的数据暂存入缓冲区,从一定程度缓解实时渲染过程中I/O压力,同时能够提高实时渲染效率。
二级缓存机制与上一节双线程数据调度策略对照呼应,其目的是为了缓解实时渲染过程中数据I/O频繁的问题。其中第一级缓存的理论依据是操作系统局部性原理[12],即CPU(central processing unit)在读取存储器数据时,被访问的数据单元都需要趋于集中在一个连续的较小区域内,随着视点位置的变化,在连续的几帧中,视域内的瓦片块重复出现的概率较高。因此将这一类瓦片数据放在第一级缓存内可以有效地存储在邻近帧率中重复使用的瓦片概率,减少了重复调度的渲染时间。第二级缓存设计是通过GPU对相关数据的顶点、法线、图元和索引等要素进行编译与加载处理,将经过编译的瓦片数据存放于能够被GPU渲染队列快速调度的瓦片缓冲区中,从而减少因为视点的拉伸缩放而需GPU重复编译与加载的时间。
本文中建立的二级缓存机制中GPU渲染管线、外存数据与二级缓存三者之间的关系如图5所示,当视域变换后,根据视点判断当前范围内是否需要载入某一数据的请求,首先会从二级缓存队列中查找相关数据,根据当前视域数据判断结果,系统指令将会依次在一级缓存队列和外存队列中继续查找,直至成功调度到相关数据后,将数据交给GPU渲染管线进行实时渲染处理,主要包括顶点、图元、片元的处理,最终输出图像。
对于本文中武夷山国家公园的县市级数据而言,预处理后的高程数据瓦片块大小为65×65,瓦片块包含行号、列号、层号及高程值等信息,对应的影像数据子块大小为1 024×1 024,由此计算出每一影像数据子块大小为3.01 MB。可见,在内存中分配约100个瓦片数据块,即设置300 MB大小的缓冲区即可同时保存相对应的高程、影像及索引信息。同时通过最小堆栈结构实现缓冲区中瓦片数据块的优先级的升降,实现每隔一段时间缓存队列数据的更新。
2.3 瓦片数据更新策略
在三维地形动态可视化过程中,需要根据相机视点位置,更新动态可视化的地形瓦片数据,从而实现三维地形的实时更新。根据八叉树金字塔结构,具体的可视化判断是从第0层地形模型开始,当视点距离达到第N层时,判断视点到该层级第x行y列的瓦片Tn,x,y的视点距离dn,x,y与给定的阈值tn进行比较,若该距离在阈值区间内则显示该瓦片数据并停止判断,否则进入该瓦片数据的子节点继续判断。其中视点距离与阈值比较的区间是[tn,∞],而非[tn,tn-1],这是由于在层级变化过程中八叉树节点的Tn,x,y与Tn-1,x,y位置中心并不相同,按照后者阈值进行判断将会造成某些瓦片无法完全显示。
瓦片数据更新过程中视点距离阈值的设置,根据屏幕像素作为标准,即屏幕像素上的n个像素需要tn将三维地形中n个顶点与之对应,则
(1)
式(1)中:α为场景在垂直方向的夹角,通常为45°~60°;p为α相应维度的分辨率,通常为列分辨率;rn为N层地形模型的分辨率。
3 实验验证
3.1 渲染流畅性
为了验证本文数据调度策略与缓存方案在多源数据集成的三维可视化场景渲染过程的流畅性,在Cesium三维可视化场景漫游过程中开展相关实验。采用每秒渲染帧数 (frame per second,FPS)是有效检测渲染性能的方法,FPS的数值代表着图像每秒被渲染刷新的次数,反映了场景的流畅程度。FPS<15时场景显示卡顿,FPS>30时人眼视觉才会流畅,通常认为三维场景漫游过程中FPS的值不应低于30[13]。通过记录三维场景实时绘制漫游过程中,实施双线程调度策略与二级缓存机制后场景渲染的FPS和帧数,并与传统方法的加载结果进行对比,得到Web页面帧率统计结果如图6所示。
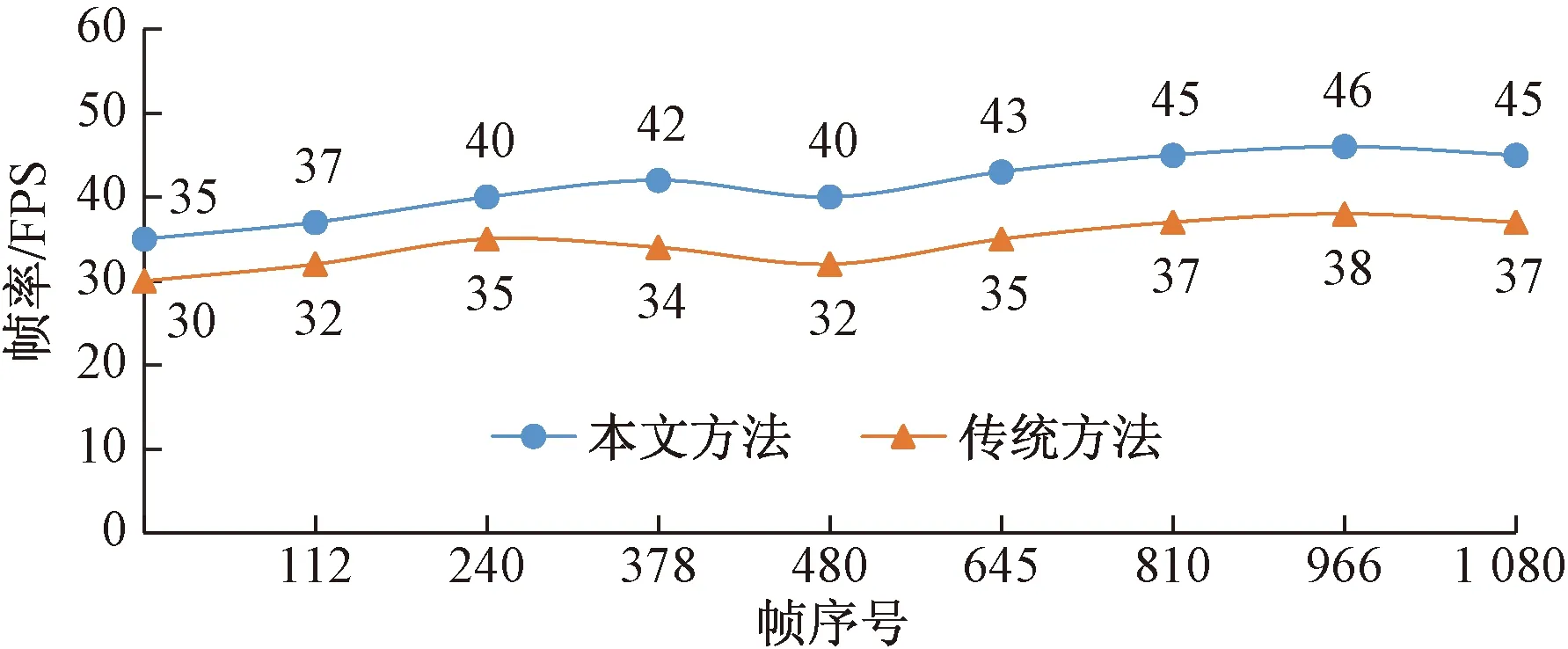
图6 Web绘制统计Fig.6 Web drawing statistics
根据在时空三维可视化场景漫游实时渲染绘制过程中的帧数和实时帧率变化情况显示,随页面初始阶段请求耗时与渲染准备逐步进行,帧率逐渐增加,当场景数据加载至消耗完毕后,FPS基本维持在45左右,且不受每帧绘制数目的影响。相对于传统方法的绘制结果,每一帧都有一定幅度的优化,达到了完全流畅漫游的条件,即满足了数据调度与实时渲染的平衡要求。
3.2 场景加载效率
本次实验漫游场景区域面积1 001.41 km2,DEM大小13 MB,高程子块大小65×65,影像数据1.3 GB,地图影像尺寸是256×256像素。实验记录在45左右的场景漫游过程中,随视点缓慢、无远距离跳跃式移动的情况下,Web场景请求加载数据量、实时加载数据量以及调度时间的变化情况,具体情况如表1所示。

表1 场景数据加载量及调度时间Table 1 Scene data loading and scheduling time
由表1可知,随着第一帧开始,所有的数据在实时加载之前,缓冲区内为空,实时加载的数据量等于请求加载的数据量。随着时间的进程,缓冲区中已经存在部分可视区域范围内的数据,这些数据将会根据二级缓存机制存入一二级缓冲区中,无需重复调度与加载,因此实时加载数据量不一定等于请求加载数据量,实时加载所需的数据量位于缓存区中无需再重复调度,直到下一个数据命令请求重新开始。
为了更形象直观地反映变化过程,将表1中的数据以折线图的形式展现,如图7所示。场景调度开始的第1帧,数据调度消耗时间最长,因为视点再缓慢的移动过程中请求加载数据与实时加载数据的变化不大,同时实时加载的数据量决定了调度时间,相较于第一帧之后的帧平均调度时间大幅下降,平均调度时间为0.111 s,而人眼视觉的暂留时间为0.05~0.2 s[14],所以本文系统场景能够达到平滑流畅的漫游条件。根据实验结果显示,本文中数据调度策略与二级缓存机制能够有效减少实时加载的数据量,缩短场景绘制时间,验证了本文方法的可行性,在数据快速调度与场景绘制效率方面有优势。
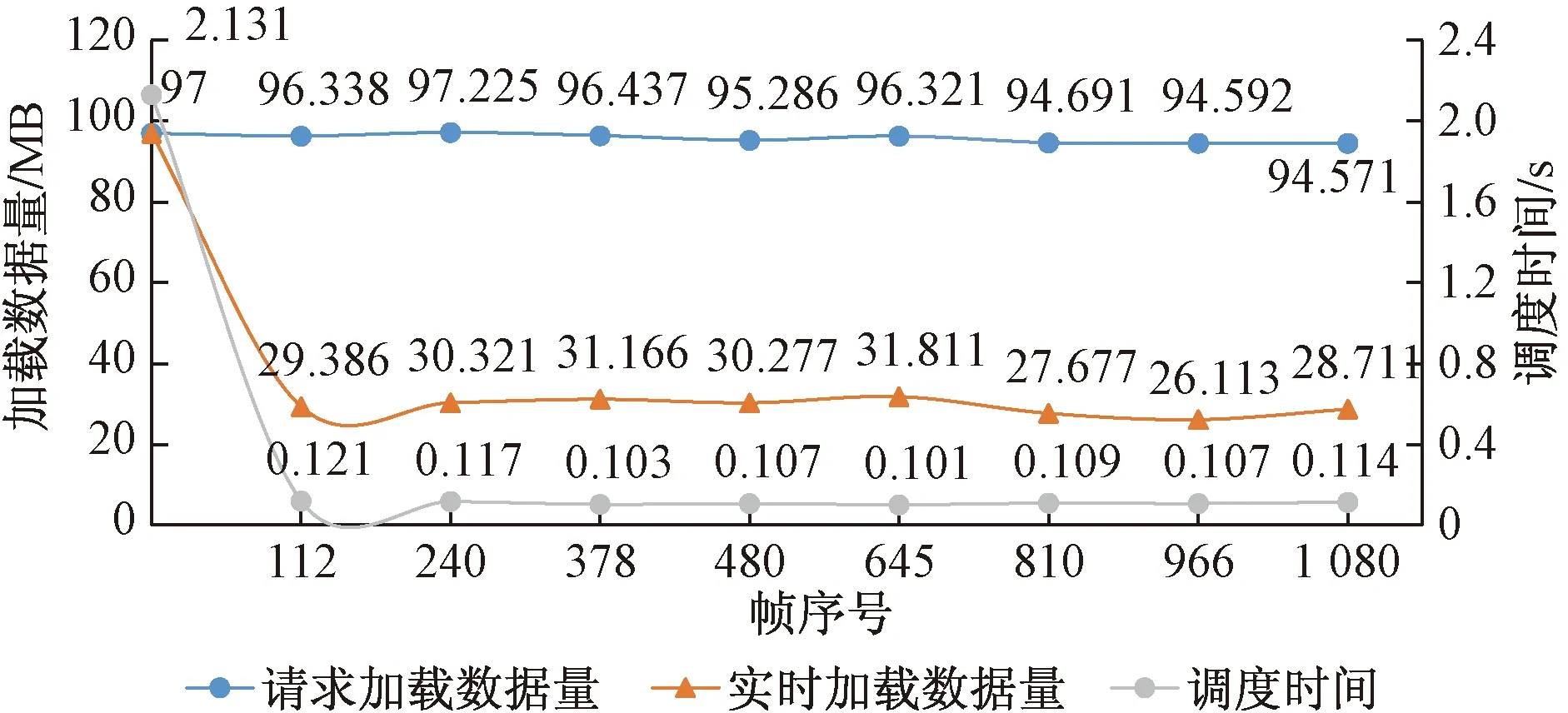
图7 数据加载量及调度时间图Fig.7 Data loading and scheduling time chart
4 系统实现与终端展示
4.1 系统设计与研发
为实现武夷山国家公园多源信息数据在三维场景有效表达,对经过预处理的多源数据结合双线程数据调度策略与二级缓存机制,选用Inter(R) Core(TM) i7-7700 CPU @ 3.60GHz系统,16 GB内存,2 GB显存,VS Code编译器、Apache服务器等实验配置,搭载三维图形引擎Cesium进行Web端系统开发。系统客户端由HTML和JavaScript建立,主要负责解析服务器端发送的JSON文件,由WebGL提供JavaScript接口,通过指令程序调用JSON对象生成绘制信息,并将指令传递给CPU、GPU处理,渲染绘制结果最终呈现在浏览器页面中。系统采用分层设计方案,整体架构包括基础层、数据层、服务层、展示层和用户层,系统架构如图8所示。

图8 系统架构Fig.8 System architecture
系统主界面是依托Cesium图形引擎以浏览器端数字地球为载体,使用天地图和高德等离线切片遥感影像数据,加载地形切片数据为三维场景底图数据,如图9和图10所示包含 “图层目录”“数据目录”“场景漫游”和“周边搜索”等功能交互按钮 ,提供了在Web端数字地球上展示物种信息查询、监测信息时空可视化、专题信息统计、周边搜索、三维漫游等功能,专题统计数据与监测信息的可视化具有动态和交互的特征,能够在三维场景中进行地理信息数据的交互展示。

图9 系统初始化页面Fig.9 System initialization page

图10 系统绘制加载页面Fig.10 System drawing loading page
4.2 跨终端展示
在Cesium图形引擎中集成武夷山国家公园多源数据进行三维展示,经终端实际测试,在PC端、手机及平板电脑端均可展示武夷山国家公园的多源数据信息,实现了对武夷山国家公园的全面化智慧管理与跨终端展示。在系统展示页面设计了国家公园各类多源数据的交互功能,已实现的交互功能包括光照分析、卷帘分析、时空查询、周边搜索、场景漫游等,实现了对武夷山国家公园物种信息数据、空间地理信息数据、监测数据等时空三维可视化展示,支撑起武夷山国家公园的全面数字化管理,如图11所示,分别为移动端的系统展示图。

图11 移动端系统展示Fig.11 Mobile system display
5 结论
采用TopoJSON作为Web端矢量传输格式、专题图与交互图表作为专题统计数据表达形式,在此基础上通过八叉树结构建立三维地形,实现了多分辨率的场景创建。另外通过建立双线程数据调度策略、二级缓存机制以及瓦片更新策略,保证了场景绘制的流畅性,提高了数据调度速度。探究并实现了基于Cesium图形引擎的多源数据参数化集成以及三维可视化表达,验证了武夷山国家公园时空三维可视化方法,得到以下结论。
(1)Cesium能够有效地将武夷山国家公园多源数据及GIS领域大场景数据参数化集成。赋予武夷山国家公园虚拟场景的三维地理位置,加强了管理者对国家公园从宏观到微观的把控,是适用于国家公园数字化、智慧化建设的开发工具。
(2)相比于传统方法,本文提出的双线程数据调度策略和二级缓存机制的组合方法,在场景三维可视化漫游过程中,能够快速调度数据并且场景显示流畅,占用外存空间较少,渲染绘制效率较高。
(3)运用WebGL和Cesium强大的三维可视化能力使得多源数据集成的成果可以跨终端、跨平台的在Web浏览器中展示,仅需交付一个网址或二维码作为设计成果,便可以利用手机、平板等移动终端随时对设计成果进行审查。
对武夷山国家公园多源数据集成的数据调度与缓存机制问题进行了探索与实验,提升了数据调度与场景绘制效率,开发了时空分析三维可视化系统,为国家公园时空三维可视化提供了一个新的解决方案,具有一定的实际应用价值。
猜你喜欢
小哥白尼(野生动物)(2022年5期)2022-08-15
扬子江(2021年4期)2021-08-09
散文百家(2019年2期)2019-03-13
扬子江(2019年1期)2019-03-08
环境(2016年7期)2016-05-14
新闻前哨(2015年2期)2015-03-11
岷峨诗稿(2014年3期)2014-11-15
大众考古(2014年10期)2014-06-21
中国校外教育(上旬)(2009年6期)2009-08-04
