
一类离散动态系统基于事件的迭代神经控制
2022-01-10 07:38:28王鼎
工程科学学报 2022年3期
王 鼎
1) 北京工业大学信息学部,北京 100124 2) 计算智能与智能系统北京市重点实验室,北京 100124 3) 智慧环保北京实验室,北京100124 4) 北京人工智能研究院,北京 100124
在许多数值计算过程中, 神经网络都被视为一种能够用于参数学习和函数逼近的重要方法.解决非线性最优反馈控制问题的关键在于如何求解复杂的Hamilton-Jacobi-Bellman (HJB)方程. 由于缺乏解析策略, 文献[1]构造了基于神经网络的自适应评判算法来获取满意的数值结果. 近年来,基于自适应评判结构的控制系统设计受到很多关注, 在解决优化调节, 跟踪控制, 鲁棒镇定, 干扰抑制, 零和博弈等方面取得不少成果[2-11]. 当考虑实现过程时, 自适应评判有三种基本类型的技术, 包括启发式动态规划(Heuristic dynamic programming,HDP), 二次启发式规划(Dual HDP, DHP)和全局二次启发式规划(Globalized DHP, GDHP)[1]. 近年来,离散时间情形下的迭代自适应评判结构已被分别用以处理包含HDP[12], DHP[13]和GDHP[14]结构的近似最优调节问题. 进而, 目标导向型迭代HDP设计的理论分析也在文献[15]中给出. 文献[16]提出一种用于离散时间未知非仿射非线性系统的在线学习最优控制方法, 并着重强调基于数据的自适应评判设计过程. 需要注意的是, 上述这些自适应评判算法是利用基于时间的更新方法来实现的,所设计的控制器在每个时刻都进行更新, 存在着一定的资源浪费现象.
与经典的时间驱动机制相比, 基于事件的方法已经成为提高资源利用效率的先进工具. 它不仅能够用于传统的反馈镇定[17]和容错控制[18], 而且已经在忆阻系统的脉冲控制中得到应用[19]. 针对传统时间驱动模式存在通信资源浪费的问题[20],文献[21]讨论了事件驱动环境下的神经控制实现方法. 值得注意的是, 在基于事件的控制框架中,一般根据指定的触发条件来更新控制信号. 文献[22]给出一种基于广义模糊双曲模型的非零和博弈事件触发设计. 另一方面, 基于文献[23]的工作, Dong等[24]针对非线性离散时间系统提出一种基于事件的HDP算法. 文献[25]则针对约束非线性系统基于事件的最优控制设计进行了扩展研究. 文献[26]设计一种实时事件驱动自适应评判控制器, 并将其应用于实际的电力系统中. 然而, 关于离散动态系统, 目前基于事件的迭代自适应评判控制的研究成果还比较少.
基于以上背景, 本文提出一种适用于离散时间最优调节问题的事件驱动迭代神经网络策略.通过收敛性分析和HDP实现, 得到基于事件环境下的迭代自适应评判算法. 然后为基于事件的离散时间动态系统设计一个实用的触发条件. 众所周知, 迭代自适应评判方法在学习近似最优控制方面具有重要意义, 而事件驱动机制在通信资源利用方面优势明显. 因此, 将这两种机制结合起来,可以得到一种有效的离散时间非线性系统的事件驱动迭代神经控制方法. 也就是说, 通过本文的研究, 迭代自适应评判控制和事件驱动控制的应用范围都将得到扩大.
在本文中,R是 所有实数的集合. Rn是所有n维实向量组成的欧氏空间. 设 Ω 是 Rn的一个紧集并且Ψ(Ω)是上容许控制律的集合. Rn×m是所有n×m维实矩阵组成的空间. ‖ ·‖是 Rn中向量的向量范数或Rn×m中矩阵的矩阵范数.In是n×n维的单位矩阵.N 代表所有非负整数的集合, 即 {0 ,1,2,...}. 上标“T”代表转置操作.
1 问题描述
本文考虑由下式描述的一类离散时间非线性动态系统:
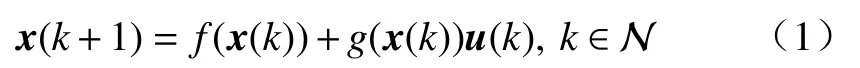
式中,x(k)∈Rn是状态变量,u(k)∈Rm是控制输入,f(·)和g(·)是可微的并且有f(0)=0. 通常令x(0)作为初始状态. 假设f+gu在 包含原点的集合 Ω ⊂Rn上是Lipschitz连续的. 此外,假设系统(1)可以在集合Ω上借助一个状态反馈控制律u(k)=μ(x(k))来镇定.

A(i+1)(x(k))-A(i)(x(k)), 最终可以得到.
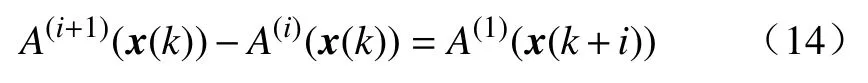
即有
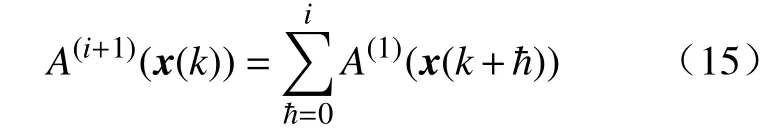
考虑到 ζ (x(sj))的容许性. 可知对于任意的迭代指标i, 都有A(i+1)(x(k))≤J成立. 由于式(11)中的迭代代价函数J(i+1)(x(k))包含了最小化运算, 可以进一步得到J(i+1)(x(k))≤A(i+1)(x(k))≤J. 于是, 考虑到代价函数的非负性, 可以得到 0 ≤J(i)(x(k))≤J ,i∈ N.证毕.
定理2迭代代价函数序列 {J(i)}是非减的, 即
证明. 为了方便起见, 定义一个新的序列{B(i)}且初始值B(0)(·)=0. 该序列中的元素更新方式如下:
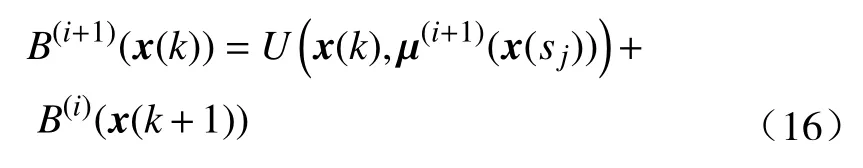

则有

因此, 可以得到对于任意i∈N, 都有成立, 这样就完成了数学归纳证明.
考虑到式(11)中代价函数J(i)(x(k))的导出方式, 则有J(i)(x(k))≤B(i)(x(k)). 因此, 最终得到不等式J(i)(x(k))≤B(i)(x(k))≤J(i+1)(x(k)). 证毕.
根据定理1和定理2, 迭代代价函数序列{J(i)}是收敛的. 令当i→∞时的迭代代价函数为J(∞).考虑式(11)且根据定理2的结论, 则有
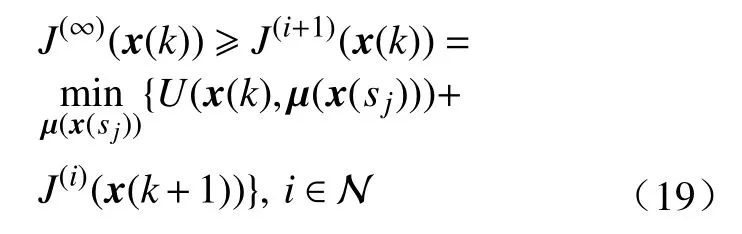
当i→ ∞时, 进一步有
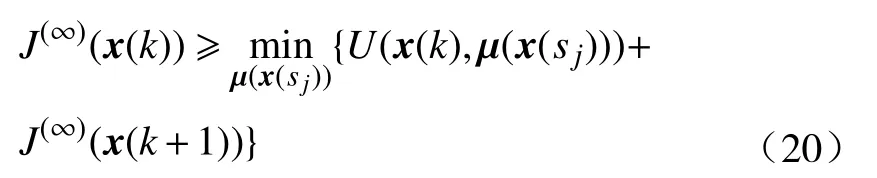
反之, 根据式(11)和定理2, 有下式成立:
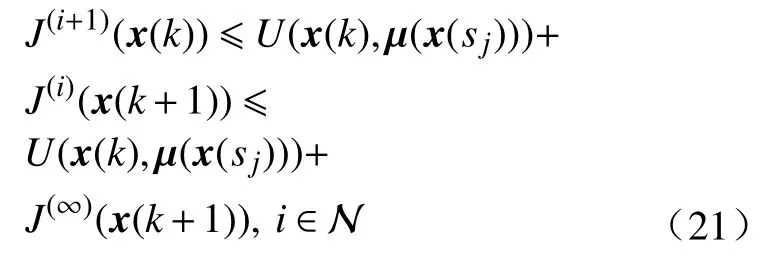
当i→ ∞时, 可得对于任意的 μ (x(sj)), 都有
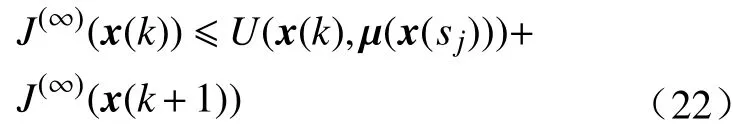
于是, 可得
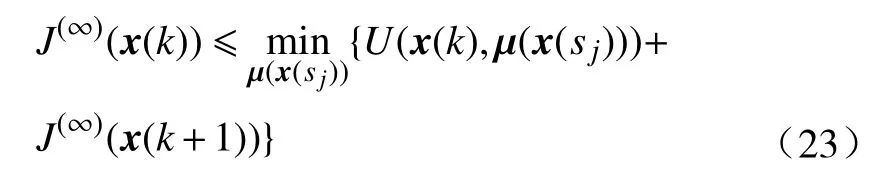
综合式(20)和(23),最终得到
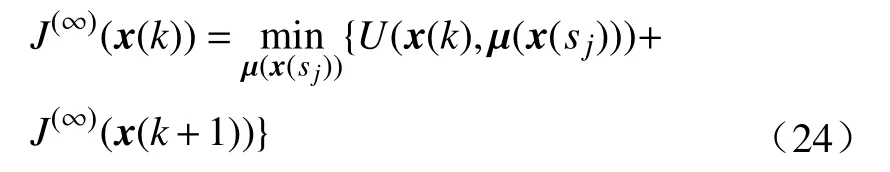
比较式(7)和(24), 可以得到迭代序列 {J(i)}的极限, 即J(∞), 正是代价函数的最优值. 因此, 有成 立 . 同 理 , 当i→ ∞时, 也有成立, 这可以看做一个推论.
2.2 基于神经网络的HDP技术实现
在实现迭代自适应评判算法时, 需要建立两个神经网络, 即评判网络和执行网络, 分别用于输出近似代价函数和近似控制律.
评判网络输出迭代代价函数的近似值, 即

结合式(12), 训练误差准则为

这里涉及的权重矩阵更新方式为

式中, ηc>0是评判网络的学习率,l是内循环的迭代指标. 其中是权重矩阵的第l次迭代值.
执行网络输出迭代控制函数的近似值, 即
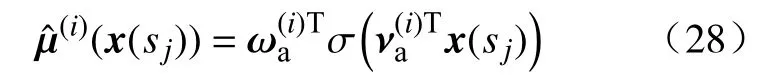
值得注意的是, 执行网络的输入是基于事件的状态x(sj), 这与传统评判网络的输入(基于时间的状态)不同. 学习过程的误差准则为

其中, 根据式(10)可以直接计算 μ(i)(x(sj)). 相似地,执行网络的权重更新算法为
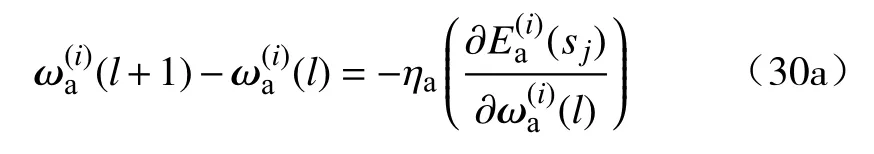

式中, ηa> 0是需要设计的学习率参数.
为清楚起见, 图1给出离散时间非线性系统基于事件的迭代HDP控制的结构简图. 其中, 实线代表信号流向, 虚线是两个神经网络的反向传播路径. 值得注意的是, 状态信息被传递到基于事件的模块用于转换信号状态, 传递到被控对象用于更新系统状态, 传递到评判网络用于计算代价函数. 因此, 系统状态组件包含三个重要角色.
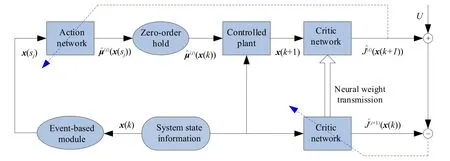
图1 离散动态系统基于事件的迭代HDP框架简图Fig.1 Simple diagram of the event-based iterative heuristic dynamic programming (HDP) framework with discrete dynamic plants
2.3 事件触发条件设计
为了确定非线性离散动态系统的具体事件触发条件, 这里给出文献[23-25]中使用的如下假设. 值得注意的是, 根据式(3),x(k+1)是关于x(k)和e(k)的函数.
假设1范数不等式成立, 其中,x(k+1)由式(3)给出, 这里的正常数 β ∈(0,0.5).
定理3如果假设1成立, 则触发条件
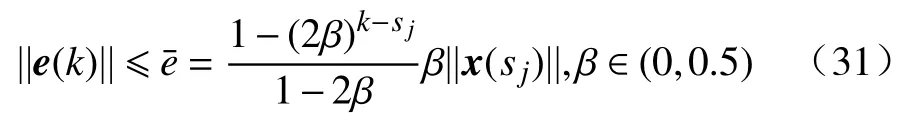
能够保证基于事件的控制器设计的可用性.
证明.考虑到式(3)给出的动态系统和假设1,可以得到
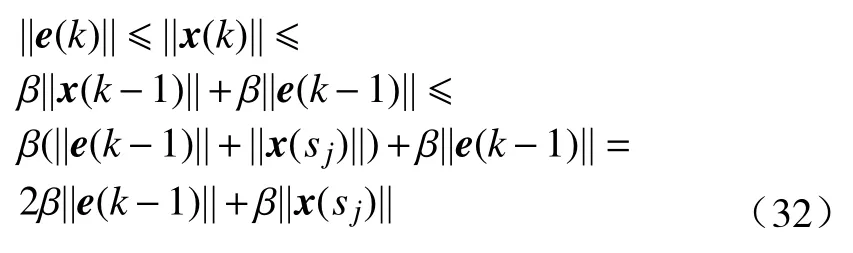
使用同样的方法, 易知

然后, 结合式(32)和式(33), 则有

利用e(sj)=0, 并如同式(34)一样扩展 ||e(k)||, 最终可以得到
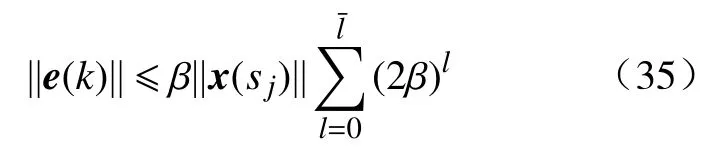
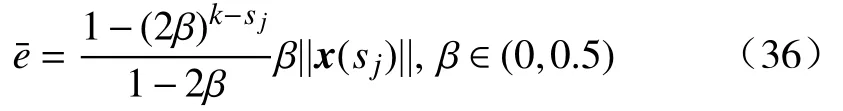
定理3提出的触发条件与假设1中的采样状态和预先指定的常数密切相关, 因此并不是唯一的. 这个条件是本文提出的事件驱动迭代自适应评判控制框架的设计基础. 为了表明触发条件的作用, 图2给出了执行迭代HDP算法之后的事件驱动控制实现, 其中,是已获得的近似最优控制器, 也就是用于事件驱动设计的实际控制律.图2的蓝色虚线代表下一步迭代的状态, 要与当前的状态区分. 当触发条件得以满足时(转向“Y”), 控制信号仍然保持之前的值然而, 当触发条件不被满足时(转向“N”), 控制信号将通过执行网络更新成为经过零阶保持器的作用之后, 事件驱动控制信号或中 的一 个将 被转 换成最 终就 可以应用于原始被控系统.
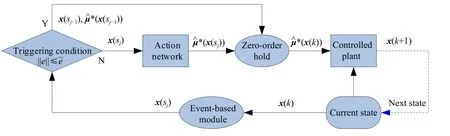
图2 执行迭代HDP算法之后的事件驱动控制实现过程Fig.2 Event-based control implementation process after conducting the iterative HDP algorithm
3 仿真研究
本节给出将基于事件迭代自适应评判方法应用到一些特定动态系统的仿真研究, 以验证近似最优控制性能.
例1考虑质量弹簧阻尼器系统的离散化形式[24]
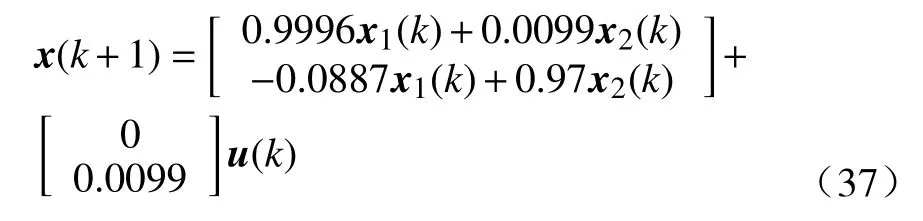
式中, 状态向量为x(k)=[x1(k),x2(k)]T, 控制变量是u(k). 为了解决基于事件的最优调节问题, 代价函数中的效用参数分别选为Q=0.01I2和P=I.
通过将网络结构预先分别设定为2-8-1(输入层, 隐藏层, 输出层神经元的个数)和2-8-1, 然后根据式(27)和式(30)在迭代框架中训练评判网络和执行网络. 在训练过程中, 选择初始状态x(0)=[1,0.5]T并且取学习率为 ηc= ηa=0.1. 评判网络和执行网络的初始权重分别在 [- 0.1,0.1]和 [- 0.5,0.5]中随机选取. 特别地, 需要将基于事件的机制应用于执行网络. 采用迭代HDP算法进行290轮迭代, 每轮迭代设定2000次训练. 如果达到预先指定的精度 ϵ =10-6, 就结束评判网络和执行网络的训练, 即获得满意的学习效果. 图3给出了迭代代价函数的收敛趋势, 也验证了定理1和定理2中的陈述.
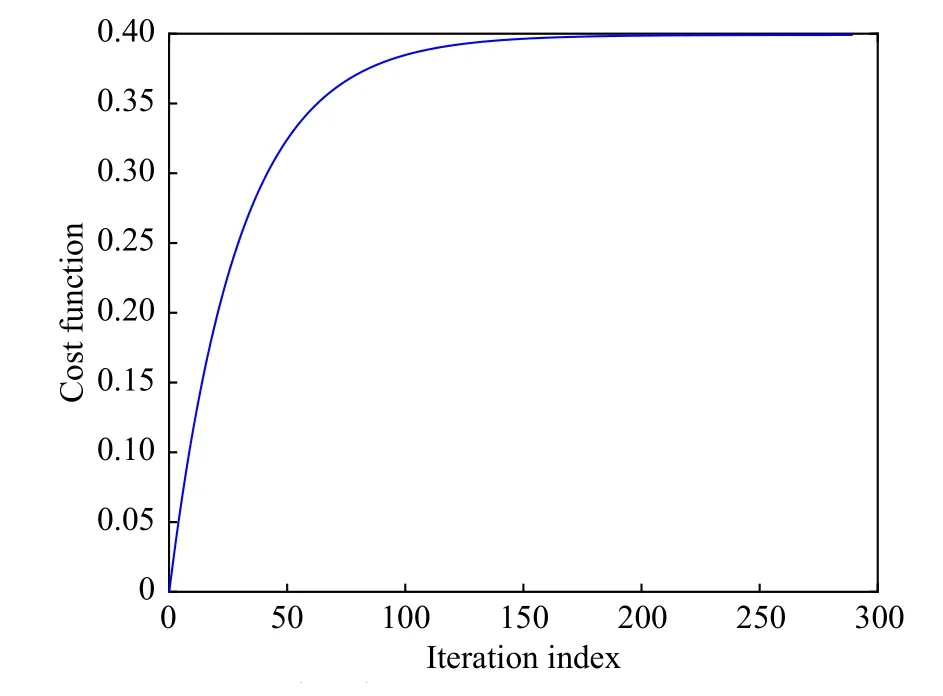
图3 迭代代价函数的收敛性(例1)Fig.3 Convergence of the iterative cost function (Example 1)
在基于事件的控制设计中, 令 β =0.1并且指定触发阈值表达式(36)具体如下:
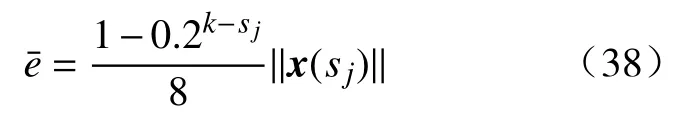
为了与传统时间驱动方法进行比较, 执行两种情况, 即事件驱动模式和时间驱动模式下的迭代HDP算法, 其中情况1(Case1)是本文提出的事件驱动模式, 情况2(Case2)是文献[12]中提出的传统时间驱动模式. 图4给出了应用事件驱动迭代自适应评判方法时的状态响应, 其中也给出了应用传统迭代HDP算法时的状态轨迹. 这里, 可以清楚地看到, 正如传统的迭代HDP算法一样, 基于事件情况下的系统状态也能够最终收敛到零向量.顺便指出, 触发阈值的变化曲线如图5所示, 它随着系统状态的变化也趋于零. 此外, 与传统的迭代HDP算法相比, 基于事件方法的控制曲线呈阶梯状, 如图6所示. 在仿真中, 基于时间情形下的控制输入更新了500个时间步, 然而在基于事件情况下, 仅仅需要222个时间步, 对应的驱动时刻间隔如图7所示. 因此, 这就验证了基于事件的迭代自适应评判方法的优越之处, 即通信资源的利用效率确实得以提高.

图4 两种情况下的状态轨迹(例1)Fig.4 State trajectory of the two cases (Example 1)
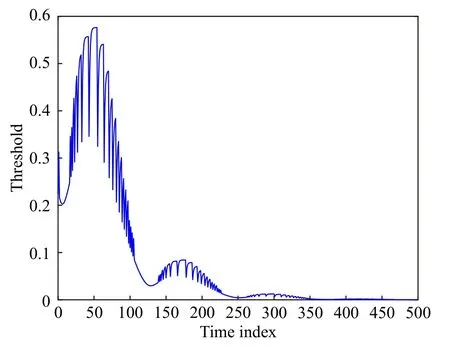
图5 触发阈值(例1)Fig.5 Triggering threshold (Example 1)

图6 两种情况下的控制输入(例1)Fig.6 Control input of the two cases (Example 1)
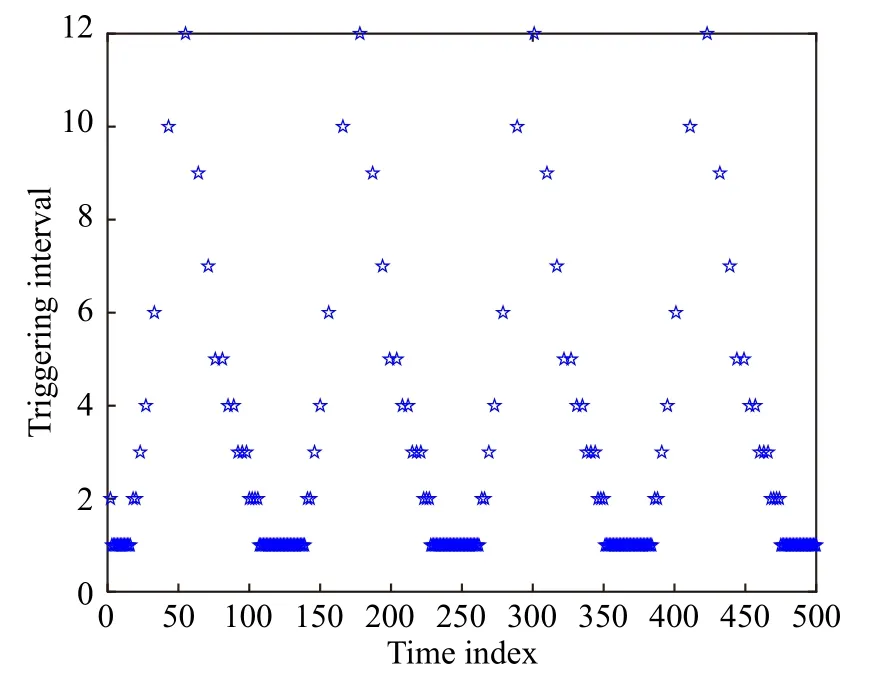
图7 驱动时刻间隔(例1)Fig.7 Triggering interval (Example 1)
例2这里引入非线性因素, 考虑如下离散时间非线性系统
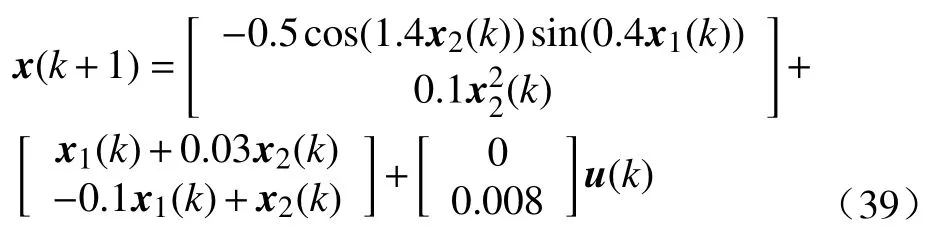
式中, 状态向量为x(k)=[x1(k),x2(k)]T, 控制变量是u(k). 为了解决事件驱动最优控制问题, 这里除了P=2I,x(0)=[1,-1]T, 以及在 [- 1,1]中随机选择执行网络的初始权值之外, 其他主要参数的设置都与例1一样. 在进行300轮迭代运算之后, 代价函数的收敛性如图8所示. 与文献[24]不同的是, 本文的方法可以很好地观察迭代代价函数的收敛性.当关注值函数学习过程时, 对收敛性能的观测就很有意义. 实际上, 这也是事件驱动环境下离散动态系统迭代自适应评判算法的优点之一.
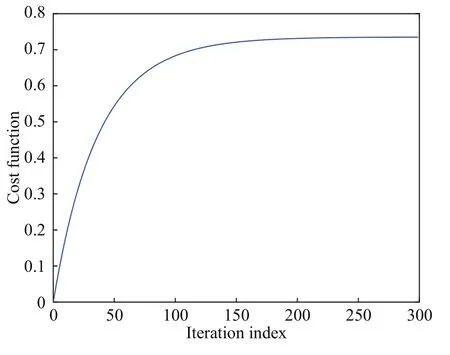
图8 迭代代价函数的收敛性(例2)Fig.8 Convergence of the iterative cost function (Example 2)
分别考虑基于事件和基于时间的控制模式, 图9给出两种情况下的状态轨迹. 可以看到, 图9中的两条轨迹非常接近, 都具有很好的稳定效果. 此外,触发阈值和控制输入分别如图10和图11所示. 与状态曲线不同, 两种情况下的控制轨迹具有明显区别. 在这个例子中, 基于时间和基于事件框架的控制输入分别更新了300次和85次, 这里的驱动时刻间隔如图12所示. 也就是说, 事件驱动结构使得控制信号更新次数下降了71.67%. 上述仿真结果表明, 基于事件的设计策略在保持较好稳定性能的前提下, 可以有效地减少控制信号的更新次数.
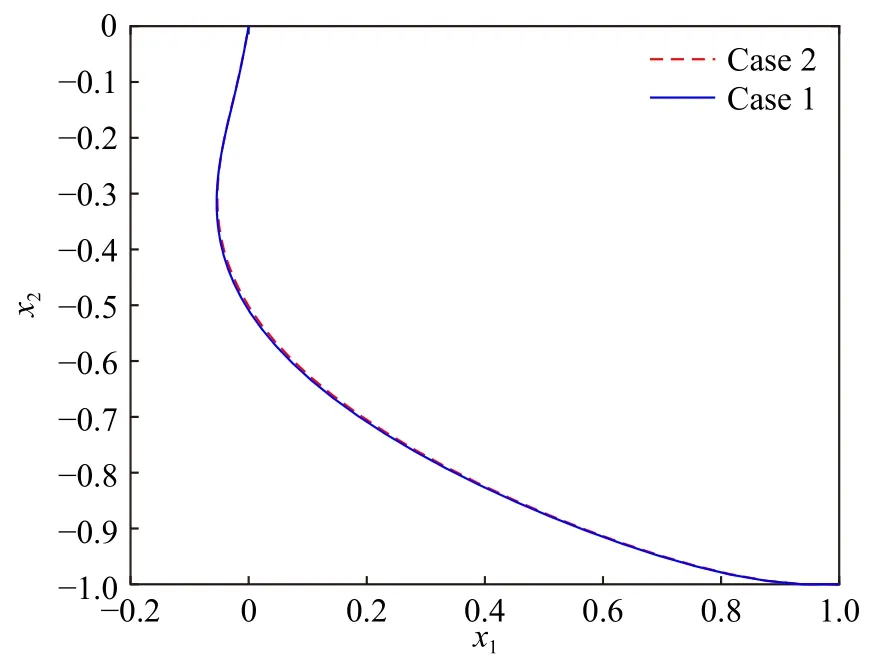
图9 两种情况下的状态轨迹(例2)Fig.9 State trajectory of the two cases (Example 2)
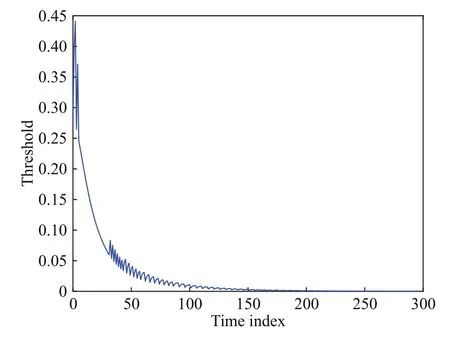
图10 触发阈值(例2)Fig.10 Triggering threshold (Example 2)
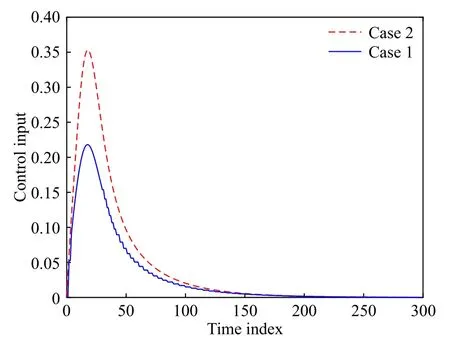
图11 两种情况下的控制输入(例2)Fig.11 Control input of the two cases (Example 2)
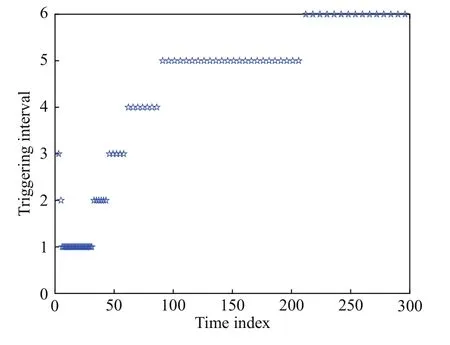
图12 驱动时刻间隔(例2)Fig.12 Triggering interval (Example 2)
4 结论
本文提出一种基于事件的迭代神经控制方法,用以解决离散动态系统的最优调节问题. 通过收敛性分析, 神经网络实现和触发阈值设计, 构造基于事件迭代自适应评判算法的完整框架. 通过仿真研究, 验证了事件驱动迭代神经控制方法的优越性能.
猜你喜欢
故事作文·高年级(2023年1期)2023-07-13 10:37:12
小学生作文(低年级适用)(2019年5期)2019-07-26 00:45:10
自动化学报(2019年6期)2019-07-23 01:18:18
读友·少年文学(清雅版)(2018年12期)2018-04-04 05:16:40
海峡姐妹(2017年12期)2018-01-31 02:12:22
作文与考试·初中版(2017年12期)2017-04-19 20:24:45
家庭百事通(2016年3期)2016-03-14 08:07:17
山东青年(2016年3期)2016-02-28 14:25:52
文学教育(2016年27期)2016-02-28 02:35:12
中学生(2015年12期)2015-03-01 03:43:53
