
射电望远镜控制系统中的数据传输序列化分析*
2022-01-10 07:23刘志勇宋祎宁王吉利
天文研究与技术 2022年1期
李 军,王 娜,刘志勇,宋祎宁,杨 垒,王吉利
(1. 中国科学院新疆天文台,新疆 乌鲁木齐 830011;2. 中国科学院大学,北京 100049;3. 中国科学院射电天文重点实验室,江苏 南京 210033)
射电望远镜是射电天文研究的基础,它由天线、接收机、终端、监测和控制等系统组成,其中,具有连接、集成和管理功能的控制系统是射电望远镜的重要组成部分[1]。数据交换是控制系统的基本功能之一,在望远镜控制与多终端数据交换过程中,需要保证稳定可靠的同时兼备高效和通用。对于将要建设的新疆奇台110 m射电望远镜(QiTai Radio Telescope, QTT),各设备之间通信数据大小由观测波段和观测模式决定,它们之间的单次数据通信量一般小于1 kB。天线伺服控制的数据通信最频繁,数据交换频率约为20 Hz,单次数据交换大小约200 B,其他设备的数据交换频率约1 Hz。主动面运行时,数据通信量约10 kB,电磁监测的数据通信量一般为10~100 kB。110 m射电望远镜控制系统拟采用分布式架构,各子系统之间的数据交换包含多种方式,如Linux,Windows,VxWorks,Unix和嵌入式等系统之间的信息传输;网络的大端模式与机器的小端模式之间的信息传输;C++与Python之间的信息交换等。其中,大端模式的机器与小端模式的机器传输信息时,long类型数据的前后字节互换。为了解决系统之间传输信息的数据格式问题,序列化工具将射电望远镜系统之间的传输信息编码为统一格式。因此,序列化工具作为控制系统传输信息格式的基础,可以实现射电望远镜软硬件系统之间的信息传输。
现有的射电望远镜控制系统大多使用序列化技术[2]。如阿塔卡马大型毫米阵列(Atacama Large Millimeter Array, ALMA)的控制系统架构结合文本序列化工具XML(Extensible Markup Language)作为控制系统传输信息编码和解码的基础[3];澳大利亚平方公里矩阵探路者(Australian Square Kilometre Array Pathfinder, ASKAP)的监控系统使用网络通信引擎(Internet Communications Engine, ICE)提供的序列化技术,完成不同射电望远镜软硬件系统之间的信息传输[4];巨型米波射电望远镜(Giant Metrewave Radio Telescope, GMRT)监控系统以Tango控制系统为基础,结合XML实现系统传输信息的编码和解码[5]。为了解决望远镜控制系统之间信息传输的格式问题,文[6]提出了以通信中间件ZeroMQ和文本序列化工具JSON(JavaScript Object Notation)为望远镜自动控制系统的通信框架。
序列化工具中,XML和JSON是文本型序列化工具,广泛应用于互联网软件系统,以及早期射电望远镜控制系统的应用层与服务层之间的数据交换。在射电望远镜控制系统的使用过程中,我们发现XML和JSON存在一些不足,如内存使用率高,数据类型精度易缺失,难以实现底层设备驱动程序与服务之间的数据交换[7]。于是实验物理装置、射电望远镜等底层与服务层之间的通信逐渐被二进制序列化工具Msgpack,Protobuf和Flatbuffers[8-9]替代,它们可以更好地解决数据精度缺失、底层与服务层之间的数据交换效率等问题。本文着重分析Msgpack,Protobuf和Flatbuffers 3款二进制序列化工具的编码原理、特性,通过测试、比较和分析它们的序列化数据大小、序列化时间和中央处理器利用率,兼顾底层、服务层和应用层,选择适合射电望远镜控制系统的序列化工具,以提高控制系统的信息传输效率,保证射电望远镜系统信息传输格式的统一性和兼容性。
1 序列化工具
序列化工具由编码(又称序列化)和解码(又称反序列化)构成。序列化是将结构化数据(或对象)编码为字节流;反序列化则是将字节流还原成原始的结构化数据(或对象)。
使用序列化工具构建射电望远镜控制系统时,我们需要分析它的编码原理和特性。不同的编码方式影响序列化数据大小、序列化时间、中央处理器利用率等。本节后续部分以图1的JSON数据为例分析Msgpack,Protobuf和Flatbuffers的编码原理。

图1 JSON格式示例Fig.1 An example of JSON schema
1.1 Msgpack
Msgpack是一款支持多语言、跨平台、具有动态编译的二进制序列化工具,编码对象(或结构化数据)之后的字节流具有紧凑、简洁的特点。字节流由头字节、前缀字节和数据字节构成。头字节表示之后紧跟的数据类型和类型个数;前缀字节表示其后的数据类型;数据字节表示对象的内容,如基本类型bin,float和uint,结构化类型str,array和map,扩展类型ext和fixext等。其中,字符串str不使用任何标记(或任何转义字符)表示内容结束。
Msgpack的编码方式包括两种:第1种方式使用Msgpack编码key-value值(这种方式简写为MSGP-M),需要先编码key值,再编码value值。图2和图3分别表示MSGP-M编码图1的JSON数据之后得到的逻辑图和字节流图。逻辑图为编码之后的数据表示形式;字节流图则是编码之后各字节的先后顺序,如83为第1个字节。字节流由7部分组成:(1)第1个字节(83)的前4位(1000)表示编码的数据类型为map,后4位(0011)表示后续包含3个map对象。(2)第2个字节为第1个map对象中key值的前缀字节(A5),表示后续包含5个str对象;第3~第7个字节以ASCII码表示map对象中的key值 “names”。(3)第8个字节(A5)表示后续包含5个字符串;第9~第13个字节使用ASCII码表示字符串 “zhang”。(4)第14个字节表示第2个map对象中key值的前缀字节(A3),表明后续包含3个字符串;第15~第17个字节以ASCII码表示字符串 “num”。(5)第18个字节为第2个map对象value值的前缀字节(CD),表明其后紧跟2个字节的无符号整数;第19~第20个字节则以大端模式表示数字 “1331”。(6)第21个字节表示第3个map对象的key值前缀字节(A8),表示后续包含8个字符串;第22~第29字节使用ASCII表示字符串 “descript”。(7)第30个字节(AF)为第3个map对象的value值的前缀字节(A5),表示后续包含15个字符串;第31~第45字节表示字符串 “inthefirstnicks”。

图2 MSGP-M对JSON格式中key-value值编码之后的逻辑图Fig.2 Logic diagram after MSGP-M encodes the key-value in JSON format

图3 MSGP-M对JSON格式中key-value值编码之后的字节流图Fig.3 MSGP-M encodes byte stream after the key-value in the JSON format
第2种使用Msgpack编码JSON格式中的value值(序列化结果以数组表示)。这种方式的Msgpack缩写为MSGP-D。MSGP-D编码图1的JSON数据之后得到的逻辑图和字节流图如图4和图5,包括4部分:(1)第1个字节(0X93)表示后续包含3个array对象。(2)第2个字节(0XA5)表示后续包含5个字符串;第3~第7字节使用ASCII表示字符串 “zhang”。(3)第8个字节(0XCD)表明后续包含一个16位无符号整数;第9~第16字节以大端模式的二进制形式表示数字 “1331”。(4)第11字节(0XAF)后续包含15个字符串;第12~第26字节用ASCII表示字符串 “inthefirstnicks”。
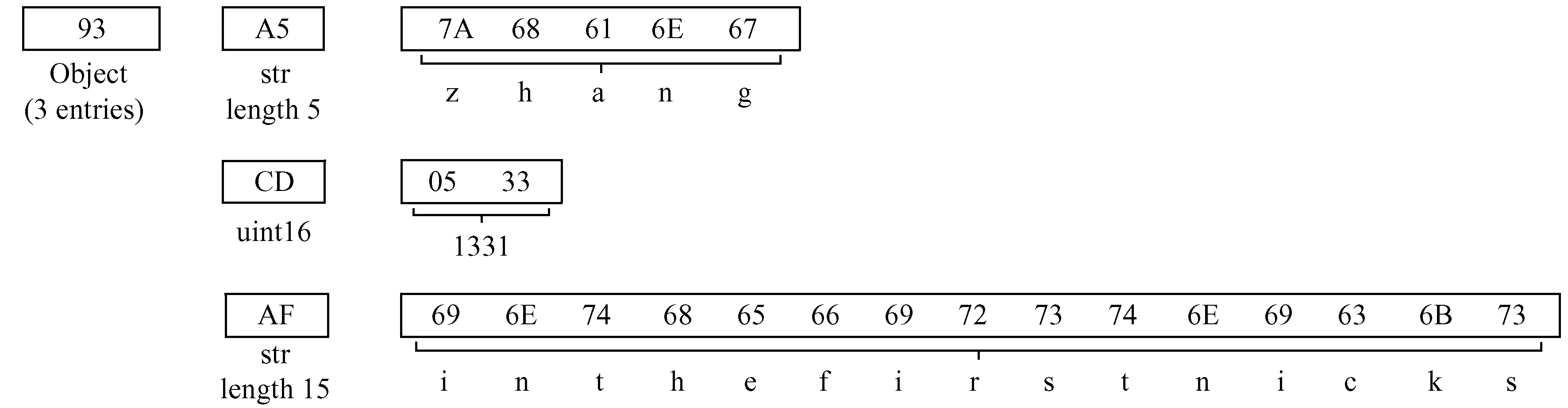
图4 MSGP-D对JSON格式中value值编码后的逻辑图Fig.4 Logic diagram after MSGP-D encodes value in JSON format
1.2 Protobuf
Protobuf(PB)是一款开源、支持多语言、跨平台、提供接口描述语言(Interactive Data Language, IDL)的二进制序列化工具。PB编码传输信息时,需定义IDL的键和字段,以生成指定编程语言代码,如C++,Python等。使用PB编码数据后,得到的字节流由键、前缀字节和数据字节组成。键分为标记数字和标记类型,标记数字将常用元素标记为1~15,不常用元素标记为16~2047;标记类型包括string,float等。键可以对IDL文件中的数据类型进行唯一标记,标记后的数据类型不能更改。
图6和图7分别为PB编码图1的JSON数据之后得到的逻辑图和字节流图。其中,字节流占用空间为27字节,由3部分组成:(1)第1个字节(0A)中的第2位到第5位(0001)为数字标记,后3位(010)表示数据类型为string;第2个字节(05)表示后续包含5个string对象;第3~第7字节以ASCII的形式表示字符串 “zhang”。(2)第8个字节(10)表示后续包含一个整型的数据;第9~第10个字节是以小端模式表示16位的无符号整数 “1331”。(3)第11个字节(10)表示后续包含字符串;第12个字节(0F)则表示后续包含15个字符串;第13~第27字节表示字符串 “inthefirstnicks”。

图7 Protobuf对JSON格式中value值编码后的字节流图Fig.7 Protobuf encodes the result of value in JSON format
1.3 Flatbuffers
Flatbuffers(FB)是一款支持多语言、跨平台、提供IDL的二进制序列化工具。FB具备良好的兼容性,如系统添加新功能时,新字段只能在IDL文件末尾添加,且旧字段仍会正常读取;数据在内存中的格式与编码格式一致;反序列化过程支持零拷贝,便于快速读取数据。FB序列化字节流包括int,string等标量和struct,table等矢量。标量由固定长度的以小端模式表示的整型(8~64位)和浮点型构成;矢量由字符串和数组构成,开头必须是一个32位长度的VECTOR SIZE来指明矢量长度(不包括 ‘�’和本身占用空间大小)。其中,字符串和数组的唯一区别是字符串包含一个结束符 “�”。
图8为FB对JSON格式中value值编码后的字节流图。字节流占用空间大小为62字节,由3部分组成:(1)第1~第4字节root offset(10 00 00 00)为根偏移量,偏移16个字节之后为编码数据;第5~第6字节align(00 00)具有填充作用。(2)第7~第8字节vtable size(0A 00)为表示vtable的字节大小,包括vtable size,object size,offset num,offset descript和offset names占用的空间大小;第9~第10字节object size(10 00)表示在表中存储数据占用的空间偏移大小,包括vtable offset,int offset,1331和string offset;第11~第12字节offset num(04 00)表示num在字节流中的位置,offset只需移动4个字节便能找到num的偏移量;第13~第14字节offset descript(08 00)为descript的位置,通过vtable offset和int offset便能找到descript的位置;第15~第16字节offset name(0C 00)表示vtable offset,int offset和string offset之后为name对象。(3)第17~第20字节vtable offset(0A 00 00 00)与vtable size具有相同的大小,唯一的区别是后者占2个字节;第21~第28字节分别表示num的前缀和以小端模式表示的数字 “1331”;第29~第32字节(0F 00 00 00)表示后续类型为string;第33~第36字节(0F 00 00 00)表明后续包含15个字符串;第37~第52字节中包含15个以ASCII表示的 “inthefirstnicks” 和一个结束字符 “�”;第53~第62字节与第33~第52字节的编码原理相同。
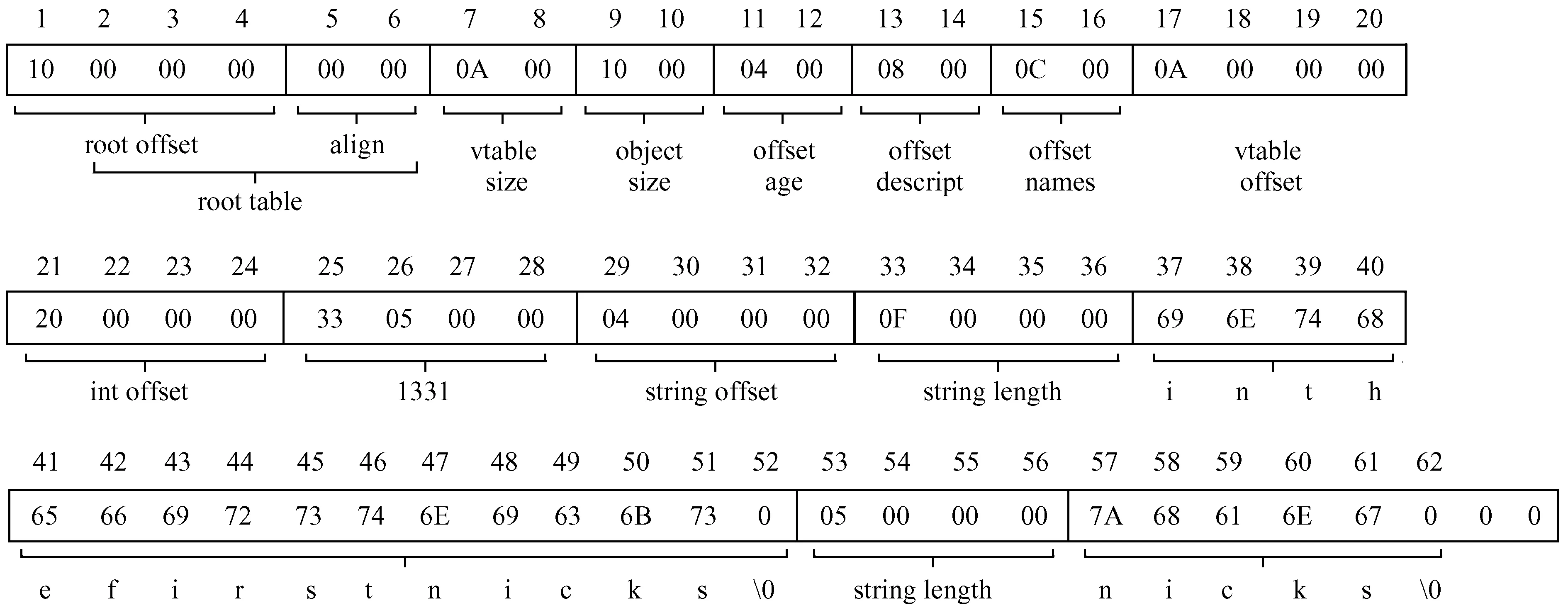
图8 Flatbuffers对JSON格式中value值编码后的字节流图Fig.8 Flatbuffers encodes the byte stream of the value in JSON format
1.4 编码原理分析与对比
对于3款二进制序列化工具,Msgpack不使用IDL预先设置数据结构,可以手动编写字段,具有两种编码方式;Protobuf和Flatbuffers在IDL中定义传输的信息字段,使用IDL编译器生成对应的编程语言接口,且只有一种编码方式。3款二进制序列化工具的编码原理不同,编码之后的字节流占用空间大小不同。Msgpack编码的字节流只有头字节,以及一一对应的前缀字节和数据字节。Protobuf的字节流中包含一一对应的键、前缀字节和数据字节,其中,只有数据类型使用键和数据字节。Flatbuffers序列化之后的字节流与数据在内存中的存储格式一致,Flatbuffers字节流中不仅包括前缀字节和数据字节,还包括root offset,object size和vtable offset等不能表示内容的字节。对同一数据编码格式,MSGP-M序列化JSON格式的全部数据,占用空间大。MSGP-D编码之后的字节流占用空间最小,字节流不用于表示信息的只有头字节和前缀字节。Protobuf占用的空间稍大,字节流中不能表达数据信息,只包含一一对应的键和前缀字节。Flatbuffers占用空间大,字节流中包含大量不能表达数据的信息。
2 实验结果与分析
Msgpack,Protobuf和Flatbuffers不仅可以在Linux,Windows等操作系统上运行,还支持C,C++ 和Python等编程语言。然而,控制系统开发往往使用多种编程语言,其中,C和C++用于底层驱动程序开发和通信;Python用于服务端的开发以及数据处理等。因此,对于3款二进制序列化工具的测试,测试环境的中央处理器为2.0 GHz的Intel Core i7-4750,内存为8 GB,操作系统为Ubuntu 16.04。编译环境的GCC版本为5.3.1,Python版本为3.7.3。Msgpack,Flatbuffers和Protobuf的版本分别为1.2.1,1.1.0和3.7.1。
图9为射电望远镜系统之间的数据传输格式,所传输的信息为控制系统中射电望远镜的状态信息编码。TelStatus为射电望远镜的状态信息,主要包括天线方位标签AzFlag、天线俯仰标签ElFlag、子系统时间标签TimeFlag、望远镜状态标签ServerFlag和天线位置标签PositionFlag等。Weather表示天文台站周围的气象信息,如气象设备状态、日期、风塔、气象仪器和风玫瑰图。WindTower表示气象仪器的温度、气压、湿度、风速和风向等要素。Plot表示风玫瑰图用于统计台站周围一段时期内的风向、风速等。控制系统只对传输的数据进行一次编解码。由于传输的数据中包含浮点型和双精度型数据,编码之后的数据在控制系统中不能以ASCII编码传输。下面以图9为例,使用C++和Python测试3款二进制序列化工具的序列化数据大小、序列化时间和中央处理器利用率。
2.1 序列化数据大小
Msgpack有两种编解码方式,既能编码和解码JSON格式中的key-value值,又能编码和解码JSON格式中的value值。我们使用3款二进制序列化工具分别测试图9的数据,得到MSGP-M,MSGP-D,Protobuf和Flatbuffers的字节流大小分别为713 B,460 B,520 B和794 B。因此,序列化数据大小与编码原理密切相关。MSGP-M较MSGP-D占用空间大,是因为MSGP-D只编码图1中的key值。MSGP-D的字节流表示为一个头字节、一一对应的前缀字节和数据字节,而Protobuf的字节流包含一一对应的键、前缀字节和数据字节。Flatbuffers占用空间大是因为其不仅编码key-value中的value值,还包括非数据值,如root offset,int offset和float offset等。因此,MSGP-D比Protobuf和Flatbuffers输出格式更紧凑,占用空间更小。

图9 射电望远镜系统之间的数据传输格式Fig.9 Data transmission format between radio telescope systems
2.2 序列化时间
Msgpack,Protobuf和Flatbuffers的编解码原理不同,序列化时间和反序列化时间存在差异。以图9为例,3款二进制序列化工具迭代100 000次之后,它们的单次平均序列化时间见图10。MSGP-M(C++)的序列化时间为22.425 μs,反序列化时间为52.491 μs;Python的序列化时间为15.566 μs,反序列化时间为10.896 μs。其中,C++的序列化时间比反序列化时间短,Python的序列化时间比反序列化时间长,是因C++的基本数据类型多,解码时间长;而Python基本类型少,能更好匹配key-value值,解码时间短。MSGP-M(C++)的序列化时间为22.425 μs较MSGP-D(C++)的13.321 μs时间长,是因为MSGP-M需要编码key-value,而MSGP-D只需编码value值。同理,解码与编码的原理相似。Protobuf(C++)序列化时间为10.514 μs,反序列化时间为17.163 μs;Python的序列化时间为86.506 μs,反序列化时间为62.431 μs,两种编程语言各自的序列化和反序列化时间接近,是由PB的IDL决定。Flatbuffers(C++)序列化时间为5.446 μs,反序列化时间为0.344 μs;Python的序列化时间为203.719 μs,反序列化时间为2.130 μs。Flatbuffers的序列化时间比反序列化时间长,是因为编码之后的字节流与其在内存中的数据格式一致,解码不需要时间,只需读取输入输出的时间。
从图10可知,对于同一种二进制序列化工具的不同编程语言,Flatbuffers(C++)的序列化速度比Python的快40倍。Protobuf(Python)的序列化时间是C++的8倍以上。MSGP-M或MSGP-D同一种编码方式的C++和Python的序列化时间与反序列化时间接近,不会因编程语言不同造成序列化和反序列时间的不平衡。
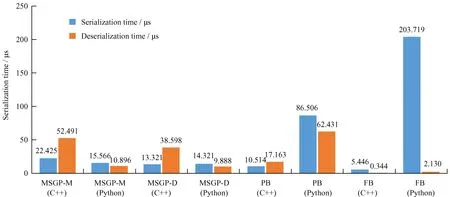
图10 3款二进制序列化工具的执行时间Fig.10 Execution time for three binary serialization tools
2.3 中央处理器利用率
中央处理器利用率的高低会影响程序运行。以图9展示的数据为例,测试3款二进制序列化工具得到表1的结果。由表1可知,无论是C++还是Python,Msgpack编解码的中央处理器利用率均在12.4%左右,Protobuf的中央处理器利用率也是12.4%。然而,Flatbuffers编码和解码的中央处理器利用率却存在差异。在编码时,Flatbuffers的Python中央处理器利用率达到25.9%,远高于Msgpack和Protobuf编码时C++和Python的中央处理器利用率;而解码时,Flatbuffers的中央处理器利用率相比Msgpack和Protobuf略低。因此,Msgpack和Protobuf适用于服务端和客户端内存充足的场景,而Flatbuffers可以应用于服务端内存充足、客户端内存不足的情况。然而,射电望远镜控制系统在实际应用中的服务端和客户端内存相似,在中央处理器利用率方面,Msgpack和Protobuf的总体性能明显优于Flatbuffers。

表1 3款二进制序列化工具的中央处理器利用率Table 1 CPU utilization of three binary serialization tools
3 总 结
本文分析比较了Msgpack,Flatbuffers和Protobuf的编码原理和特性,并对它们进行了测试。Msgpack不需要IDL,只需开发人员编写代码实现编解码的功能;而Flatbuffers和Protobuf使用IDL对传输的信息进行编解码。它们对同一信息编解码时,MSGP-D字节流的大小和多语言的序列化时间优于Protobuf,且明显优于Flatbuffers。MSGP-M对需求变化大的小数据编码具有优势,可以对同一数据以任意顺序的key-value数据进行编解码,但Protobuf和Flatbuffers却不能对这种方式进行解码。根据射电望远镜控制系统的开发情况,当通信的数据格式确定时,可使用MSGP-D;而通信的数据格式变化较大时,可使用MSGP-M。总之,通过分析3款二进制序列化工具,Msgpack更适合射电望远镜控制系统的信息传输,有助于射电望远镜的硬件系统、软件系统、操作系统、编程语言和网络之间的信息交换,系统的扩展性好,移植性强。
猜你喜欢
军事文摘(2022年12期)2022-07-13
儿童故事画报·自然探秘(2022年6期)2022-07-05
军事文摘(2021年22期)2022-01-18
无线互联科技(2020年11期)2020-12-01
启迪与智慧·教育版(2016年12期)2017-01-12
科教导刊·电子版(2016年30期)2016-12-26
中国新通信(2016年17期)2016-11-17
太空探索(2016年9期)2016-07-12
中学教学参考·语英版(2016年6期)2016-07-07
小学教学参考(语文)(2016年6期)2016-06-24
