
基于Python语言的类C编译器的设计与实现
2022-01-07 09:59:32许高建徐浩宇
洛阳理工学院学报(自然科学版) 2021年4期
许高建, 徐浩宇
(安徽农业大学 信息与计算机学院, 安徽 合肥 230036)
编译原理是计算机科学与技术专业本科生的必修课程,原理相对复杂,课时较长,基本概念抽象,本科生理解比较困难,在教学的过程中需要探索出一种更好的教学方式。程序设计语言中的编译技术,是把高级语言编写的程序翻译成等价的目标程序或机器语言,在计算机领域中很多方面得到应用[1]。例如:文本编辑器、信息检索系统、模式识别器、排版和绘图系统。为了让大学本科生更好地理解编译原理,在本课程后期带领学生使用面向对象的程序设计语言Python从零开发出一款类C语言编译器,让学生更好地理解编译原理。
1 编译器的分析与设计
该编译器主要由两大模块组成:文法分析模块与语法分析模块。
文法分析模块:由用户将类C文法文件输入程序,可以实现求first集和follow集,最终生成LL分析表等功能。该模块嵌入到main.py中,按照其特性进行递归匹配、生成。
语法分析模块:用户将类C程序文档输入程序,按照顺序进行词法分析、语法分析,生成四元式,最终生成汇编语言。词法分析器作为一个函数提供给语法分析器。该函数对关键字、标识符、常数、运算符和分界符等分别进行编号,并对输入程序进行匹配,在每次调用时返回词法分析后的字符串和词法属性。
LL分析法主要识别结构简单但是需要处理较多细节的部分。该方法对于文法的要求很高,不能有左递归和公共左因子。为了减少代码修改,对于输入文法,经过预处理后,自动求得该文法的LL分析表,不需要对分析器本身进行修改。语义分析上采用了属性文法的方法,归约时执行语义动作。
目标代码生成采用寄存器分配方法。首先分配寄存器,处理操作数寻址方式,生成对应的目标代码,然后生成运算部分的目标代码。处理了算法细节使算法更加健壮完备,生成基于IntelX8086的汇编指令代码。
2 算法设计
2.1 文法分析模块算法流程
文法分析模块流程图如图1所示。
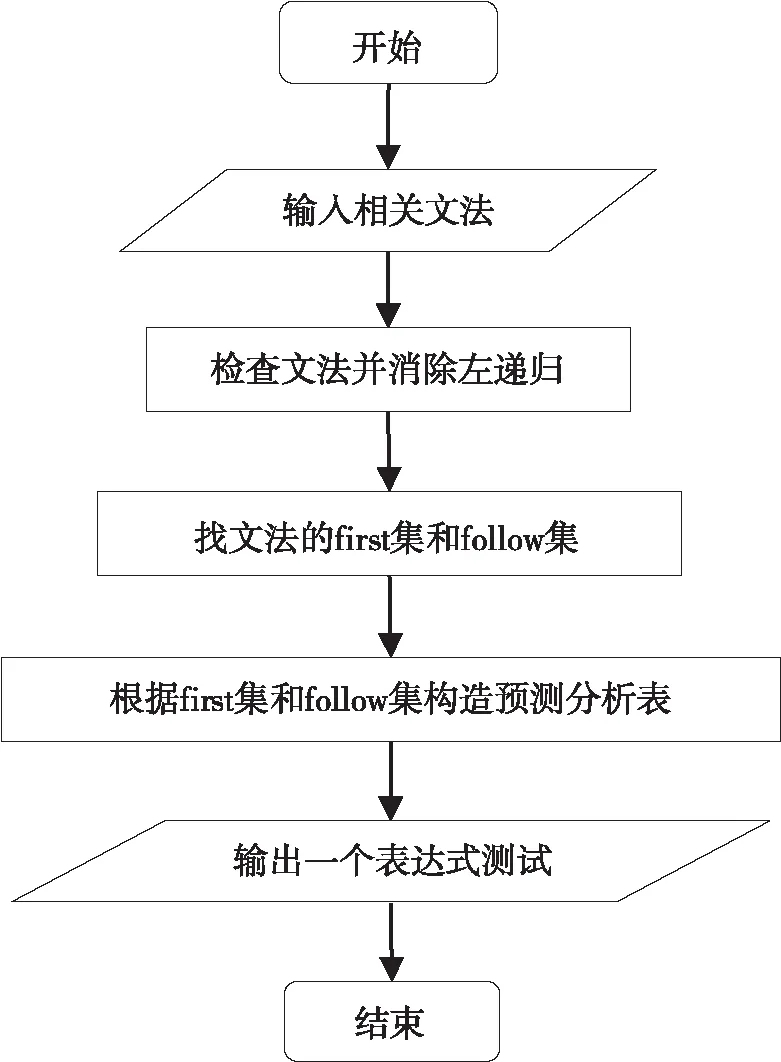
图1 文法分析流程图
(1) first集、follow集、LL分析表算法
① 求first集
文法G的任何符号串a=X1,X2,X3…Xn构造集合first(a)[2]。置first(a)=first(X1)/e(e为空串);若对任何1≤j≤i-1,e属于first(Xj),就把first(Xj)中e以外的元素加到first(a)中;若所有first(Xj)均含有e,1≤j≤n,则将e加至first(a)中。流程图如图2所示。
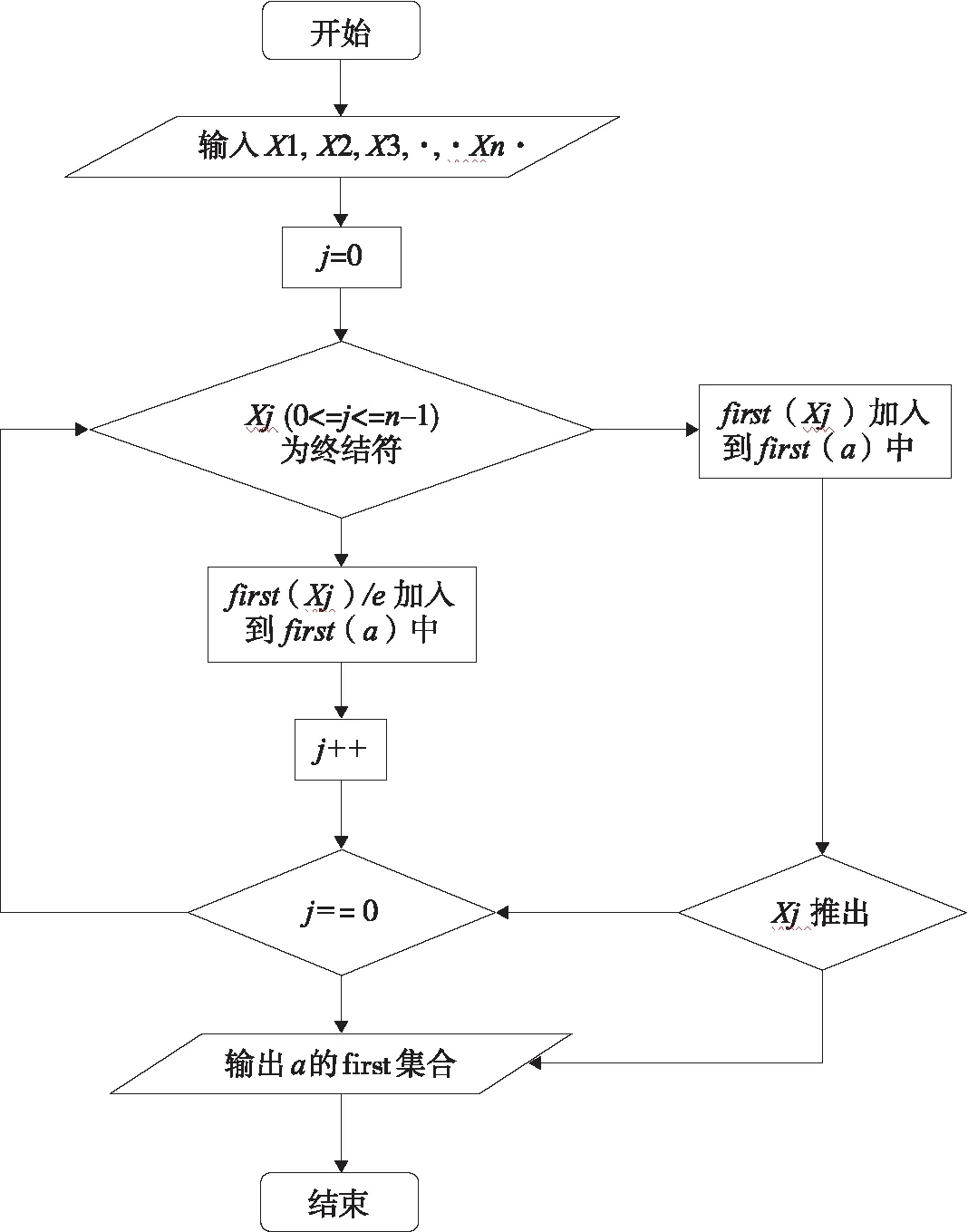
图2 求first集流程图
② 求follow集
对于文法的开始符号S,置#到follow中;若A→aBb是一个产生式,则将first(B)/e加到first(B)中;若A→aB是一个产生式,或者A→aBb是一个产生式,而b的first集合中包含空串,则将follow(A)加到follow(B)中。求follow集流程图如图3所示。
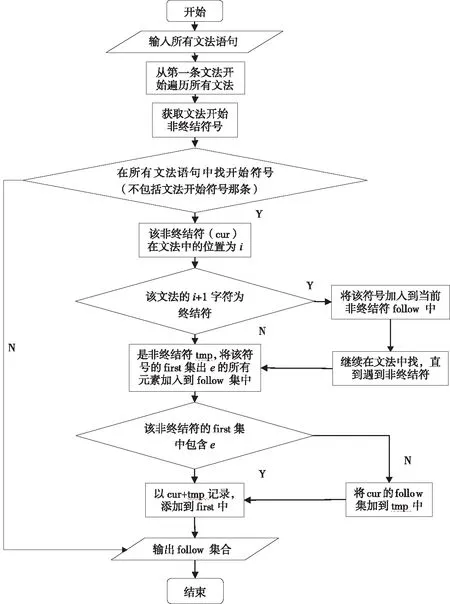
图3 求follow集流程图
③ 求LL分析表
预测分析表示一个M(A,a)形式的矩阵,其中A为非终结符,a为终结符或者‘#’。矩阵元素M(A,a)中存放着一条关于A的产生式,指出当A面临输入符号a时所应采用的候选。M(A,a)中也可能存放一个“出错标志”,指出A根本不该面临输入符号a。LL分析表算法如表1所示。

表1 LL分析表算法
2.2 编译器
(1) 算法的总体思路
编译器的逻辑阶段必不可少的部分:词法分析、语法分析、语义分析和目标代码生成。 编译器前端使用了以语法分析为中心的方法。词法分析器作为一个封装类提供给语法分析器,词法分析器的输入为文档,输出为下一步LL语法分析所需字符串。LL分析法中,采用了上一步产生的LL分析表,将语法动作插入到产生式中。在分析过程中填写符号表,进行类型检查的判断。只需将符号表传递给后端,降低了编码复杂性。
在LL部分,修改与新建文法只需要修改储存文法的文件即可,不需要对分析器本身进行修改。
通过得到四元式序列,目标代码生成算法处理序列得到目标汇编指令。目标代码生成分配寄存器,处理操作数寻址方式,并生成对应的目标代码,然后生成运算部分的目标代码[3]。
(2) 词法分析器
词法分析器主要功能是为语法分析器提供转义字符串[4]。词法分析器将准备编译的源代码作为输入,利用设计好的有限自动机的状态转移函数(关键字与文法符号转换),实现状态的转移和对语句的分词功能。根据终结状态将分词划分为五大类:关键字、标识符、界符、运算符和常数。
词法分析器从左往右进行扫描源程序,分离出一个个单词,识别其类别,并按照二元式(类别,单词值)进行输出,流程图如图4所示。
词法结构定义:
##关键字
key_world_list = ["while","if","else","return","void","main","printf","int","scanf"]
key_translate_list = ["t","w","u","s","z","y","r","x","f"]
##标识符
flag_world_list = [chr(i) for i in range(97,122)] #添加a-z
##常数
constant_world_list = [chr(i) for i in range(48,57)] #添加0-9
##运算符
operator_world_list = ["+","-","*","/","=",">","<","==","!="]
##界符
delimiter_world_list = [";","{","}","(",")"]
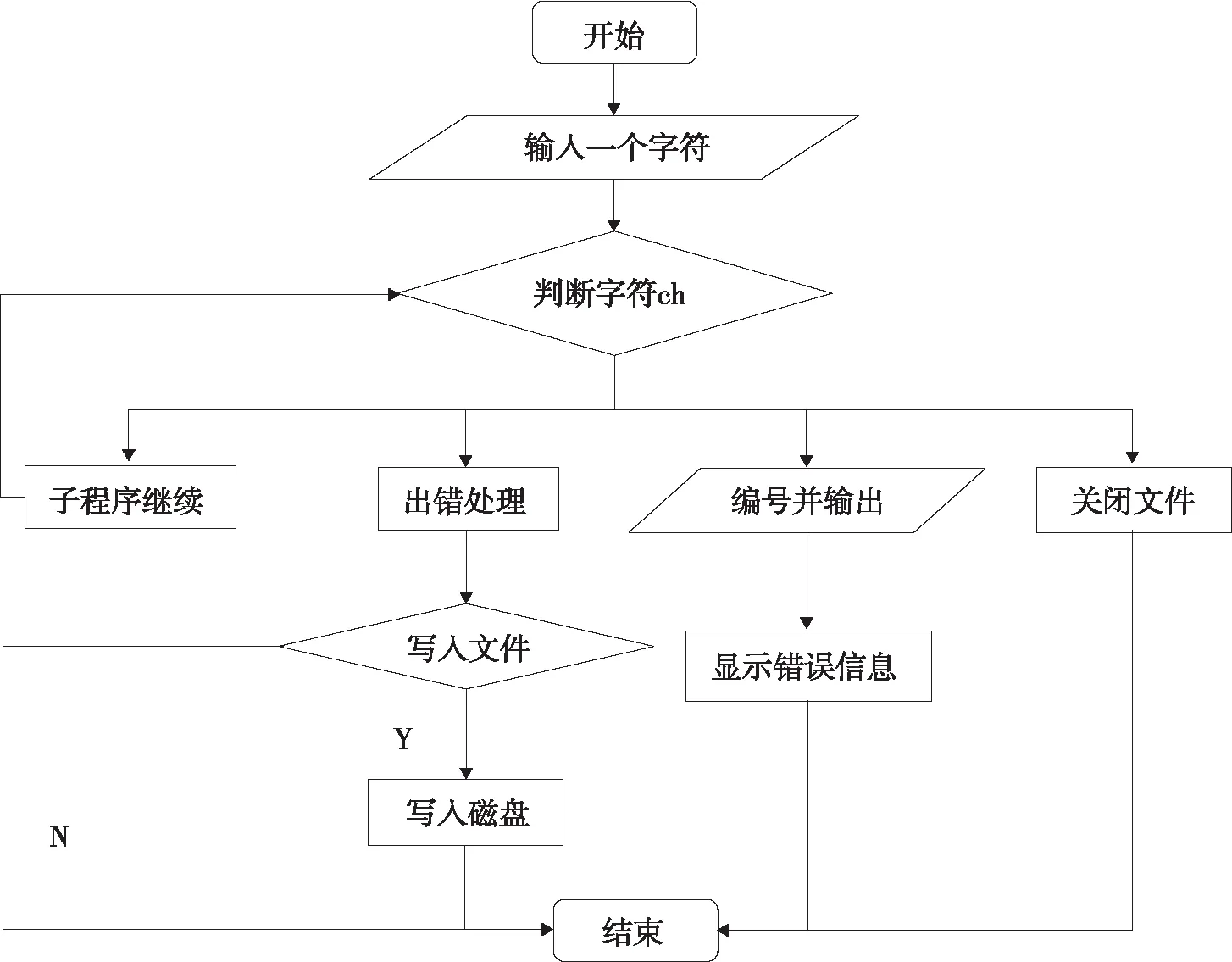
图4 词法分析流程图
(3)语法分析器
语法分析的任务是接收词法分析的结果,按照定义的语法规则检查语句的合法性。语法分析也叫层次分析,按照语法的层次,可以由下而上,也可以自上而下进行语法分析。
本文设计的语法分析器,选择自上而下分析法,文法必须是LL文法,输入为词法分析器产生的转义字符串,根据文法分析器生成的LL分析表,进行语法分析,为后续的四元式产生及语义分析做前置准备工作。语法分析的同时可以利用符号表中的信息进行类型检查。
(4)语义分析与中间代码生成(产生四元式)
语义分析是依据规则对识别出的各种语法分析其含义,进行初步翻译,生成中间代码。语义分析分为静态和动态分析两种,静态主要是检查语义成分的合法性,比如操作数的类型是否一致等;动态主要是检查语义成分的作用域、运行时的存储器分配等。
根据输入的语义动作进行语法制导翻译,通过文法分析中自动生成的LL分析表,将动作当作文法右部变元同等处理,逆序压入栈,当遇到语义动作的非终结符时,执行相应的语义动作,同时将产生的四元式输出并存储,作为代码生成的输入部分,产生四元式。
(5)目标代码生成
目标代码生成模块将四元式和对应的变量活跃信息作为输入,生成表达式语句、条件语句if-else、循环语句while和跳转语句goto的目标代码(汇编语言),生成的目标代码为基于单寄存器的类汇编语言代码。
3 编译器实现
3.1 编译器程序设计流程图
Python语言是面向对象、解释性特别好的脚本语言,同时也是可读性强、功能强大而完善的通用型语言[6]。本设计中使用递归下降法自顶向下进行编写,程序设计流程图如图5所示。

图5 程序设计流程图
3.2 程序设计说明
总体算法设计已在上一节详述,这里不再详述,文法的设计由于“void main”类似设计比较麻烦,这里进行了处理,如图6所示。
图6 wenfa界面图
4 系统测试
基于Python语言实现的编译器GUI界面简洁,操作简单,可以实现“文法分析”与“C语言编译”功能如图7所示。测试文件为“wenfa.txt”,在载入文法文件“wenfa.txt”之后可以实现“产生式信息”、“求first集”、“求follow集”及“LL分析表”等功能,如图8所示。
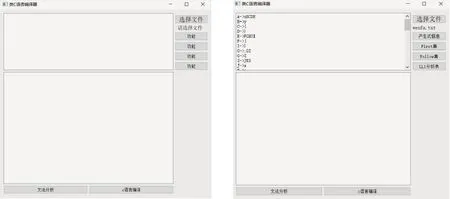
图7 程序界面 图8 载入wenfa.txt文件图
该系统中所有功能均可以正常使用,最终生成的汇编代码如图9所示。
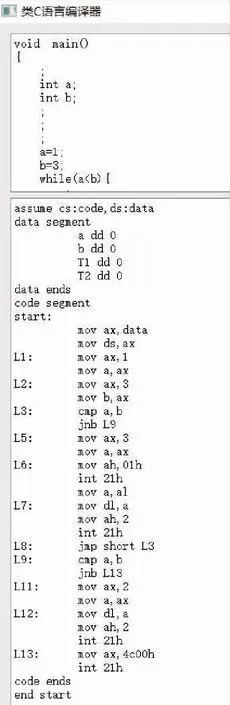
图9 汇编代码生成示意图
5 结 语
本编译器中只能实现简单的赋值、循环和逻辑运算,标识符分别为a、b和c,未能实现加、减、乘、除等数学运算,系统的可扩展性较好。编译器容错性较高,但是在Mac操作系统上运行速度并没有达到预期效果,与项目整体规模和算法设计有很大的关系。总体来说达到了教学目的,算法设计有很大的改进空间。可以指导学生在此基础上把加、减、乘、除、逻辑运算和位运算等功能分批加入到该编译器中,完善编译器的功能,优化其编译速度,培养学生的实践动手能力。在实验过程中可以让学生花费较短的时间掌握编译器的原理,让学生积极参与课堂教学,活跃课堂氛围,改变传统的教学方式,让学生更好地理解编译原理,达到教学目的。
猜你喜欢
仪器仪表用户(2020年5期)2020-05-04 12:36:18
阅读(科学探秘)(2019年6期)2019-10-17 10:32:13
分析化学(2018年12期)2018-01-22 12:31:46
科技经济市场(2017年5期)2017-09-16 19:20:11
海外华文教育(2016年3期)2017-01-20 08:22:19
电子世界(2016年15期)2016-08-29 02:14:28
电子科技(2015年2期)2015-12-20 01:09:20
中学生英语高效课堂探究(2011年4期)2011-07-07 01:48:30
湖北大学学报(自然科学版)(2010年2期)2010-11-26 01:06:56
吉林大学学报(理学版)(2005年6期)2005-04-29 00:44:03
