
基于支持向量机和ReliefF算法的玉米品种抗倒伏预测
2021-12-30 03:00张天亮张东兴丁友强解春季杜兆辉钟翔君
农业工程学报 2021年20期
张天亮,张东兴,崔 涛,杨 丽,丁友强,解春季,杜兆辉,钟翔君
基于支持向量机和ReliefF算法的玉米品种抗倒伏预测
张天亮,张东兴,崔 涛,杨 丽※,丁友强,解春季,杜兆辉,钟翔君
(1. 中国农业大学工学院,北京 100083;2. 农业部土壤-机器-植物系统技术重点实验室,北京 100083)
针对目前玉米品种抗倒伏鉴定方法费时、费力,玉米抗倒伏品种选育周期长的问题,该研究采用高光谱成像技术结合统计学习方法在玉米营养生长期开展品种抗倒伏预测。于2018年和2019年开展田间试验采集不同抗倒伏的8个玉米品种的高光谱成像数据,基于区域识别方法提取感兴趣区域(Region of Interest,ROI)的光谱曲线,分析抗倒样本和不抗倒样本的数据特性;然后分别采用过滤式特征选择算法ReliefF(Relevant Features)和主成分分析(Principal Component Analysis,PCA)结合ReliefF算法的方式,挖掘抗倒品种和不抗倒品种的光谱分类特征;最后使用交叉验证的方式,对ReliefF方法选择的原始光谱数据特征数量和PCAReliefF方法选择的主成分特征数量进行优化,分别建立ReliefF-SVM和PCAReliefF-SVM支持向量机(Support Vector Machines,SVM)分类模型,并对SVM模型的惩罚参数和核参数进行优化,以获得更好的模型预测效果。结果表明:经过特征优化,2018年试验和2019年试验分别选择了40和50个特征参与建模,且使用PCAReliefF方法选择的主成分特征与使用ReliefF方法选择的原始光谱数据特征相比,几乎不含有冗余特征;通过对支持向量机模型的惩罚参数和核参数进行优化,2018年试验ReliefF-SVM和PCAReliefF-SVM模型对预测集样本的抗倒伏分类预测正确率分别为84.17%和85.00%,2019年试验模型分类预测正确率分别为84.17%和85.83%。可见,采用高光谱成像数据和统计学习方法可以实现对玉米品种抗倒伏的早期预测,使用PCAReliefF-SVM模型比ReliefF-SVM分类模型综合性能更优,试验可为玉米抗倒伏品种的高效筛选提供方法和借鉴。
主成分分析;品种;支持向量机;玉米;抗倒;ReliefF
0 引 言
玉米是中国三大粮食作物之一,保障玉米的高产高效对国家粮食安全有重大意义。玉米倒伏是影响粮食产量和机械化收获效率的重要因素,研究预测玉米抗倒伏的方法,对于筛选抗倒伏的玉米品种、缩短育种周期有重要意义。
影响玉米倒伏的因素主要有内因(遗传、植株形态、茎秆和根系特性等)和外因(自然条件和栽培措施等)[1-2],目前国内外对玉米品种抗倒伏评价的研究主要集中在玉米生殖生长期,通过对倒伏性状的多基因定位[3]、冠层光照强度[4]茎秆的力学特性和显微结构冠层植株形态[9]的研究等来反映玉米品种的抗倒伏能力。例如:Wei等[3]研究了与玉米株高、穗高、叶角、茎秆强度等有关的玉米ZmSPL(Zea mays Squamosa-Promoter Binding Protein-Like)基因家族,用基因选择的方法来识别和评价具有抗倒伏耐密植特性的玉米品种;Xue等[4]研究了冠层光照环境对秸秆强度和倒伏率的影响,研究表明上部冠层叶片较小、中部冠层叶片较大、下部冠层叶片中等的玉米品种抗倒伏能力较强;Zhang等[5]研究了茎节处的微观解剖特征与茎秆生物力学特性的关系,证明茎秆微表型是预测秸秆机械特性,评价品种抗倒伏能力的重要指标。玉米在生殖生长期更容易发生倒伏,研究此时玉米的相关性状可以直观地表征玉米品种的抗倒伏能力。但生殖生长期试验需要的周期长、成本高,费时又费力,如果能在玉米生长发育早期如九叶期时,更早地预测出玉米品种是否抗倒伏,对于提高玉米抗倒品种的筛选效率具有重要意义。
高光谱成像技术是光谱技术和成像技术的融合,具有图谱合一的特点,既可以观测植物的外在表型也能测量其内在理化特性。目前高光谱技术已经用于研究玉米的品种鉴别、胁迫研究和生理监测等[10-14],但鲜有将高光谱成像技术应用于对玉米品种抗倒伏预测的研究。本研究拟采用高光谱成像技术结合统计学习方法在玉米营养生长期研究玉米品种的抗倒特性,实现对抗倒伏和不抗倒伏玉米品种的早期预测,以期为玉米抗倒伏品种的高效筛选提供方法和借鉴。
1 材料与方法
1.1 田间试验
1.1.1 试验过程
2018年和2019年在河北省沧州市吴桥县中国农业大学吴桥试验站(37°41′02″N,116°37′23″E)开展试验,供试玉米杂交种为适宜黄淮海区域种植的8个夏玉米品种:登海605(DH605)、京丹28(JD28)、蠡玉37(LY37)、隆平206(LP206)、隆平208(LP208)、圣瑞999(SR999)、沃玉964(WY964)、先玉335(XY335)。试验为单一因素的品种试验,采用随机区组试验设计,研究不同品种玉米抗倒伏性的早期预测问题。每小区5 m长,4.8 m宽,种9行玉米,行长5 m,人工播种,设定株距22.2 cm,行距60 cm(种植密度约为75 000 株/hm2),各品种3次重复,共24个小区。分别于2018年6月15日、2019年6月16日在田间播种,播后一次性侧施复合肥720 kg/hm2(N∶P2O5∶K2O=24∶8∶10,有效成分质量分数≥42%),在玉米生长周期内禁止使用生长调节剂类的药物,其他的田间管理措施同当地的大田种植方式。
1.1.2 玉米倒伏特性指标
在玉米成熟后人工统计每个品种的田间实际倒伏率,包括根倒伏、茎弯曲、茎折断3种情况[1-2],作为判断品种抗倒伏的依据。
在蜡熟期统计各品种的田间倒伏率:发生倒伏的株数占各品种小区总株数(不含边行)的百分比,%。选择5%倒伏率作为区分抗倒伏(Lodging Resistant,LR)和不抗倒伏(Lodging,L)品种的评价标准,具体结果见表1。各品种在2 a间的倒伏率相差不大,抗倒伏品种和不抗倒伏品种各占4个。
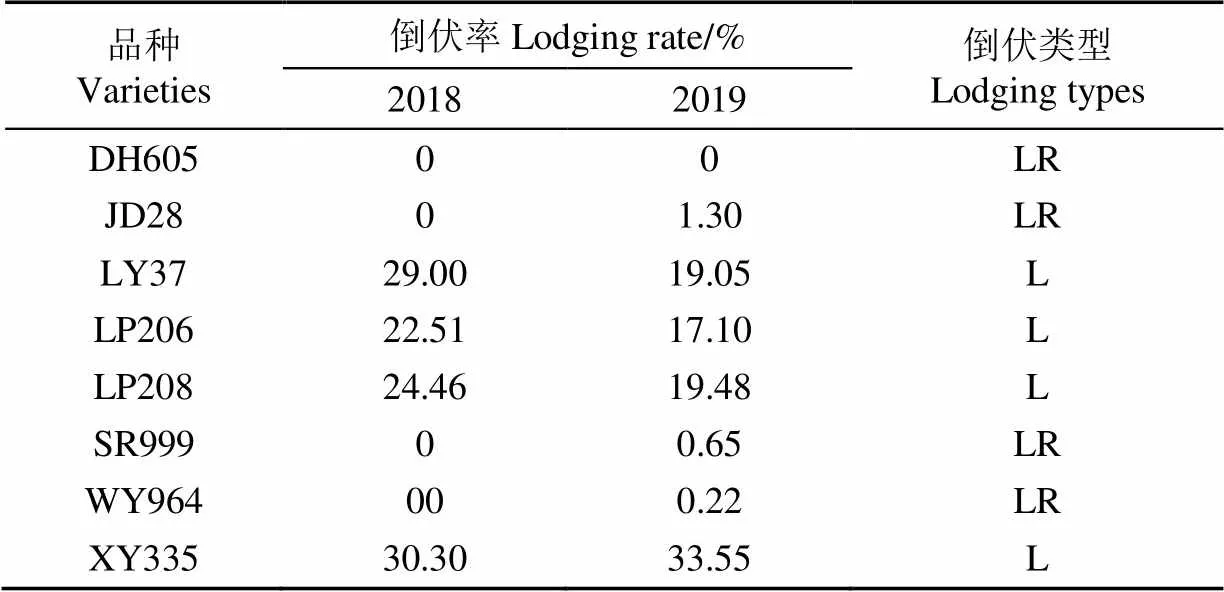
表1 2018和2019年不同品种玉米的倒伏率
注:LR:抗倒伏;L:不抗倒伏;下同。
Note: LR: lodging-resistant; L: lodging; Same below.
1.2 高光谱数据采集
1.2.1 高光谱图像获取
玉米生长到九叶期时,在每个小区内(不含小区最外边的一行,避免边行生长优势)随机采集玉米的第9片完全展开叶。在24个小区每个小区各取样21片,共504个叶片样本。将每小区的样本分别用自封袋密封好后放入盛有冰袋的保鲜盒中,带回试验站,在试验室内拍摄图像。如图1所示,试验使用的高光谱成像系统包括高光谱成像光谱仪SOC710VP(Surface Optics Corporation,美国)及配套的数据采集软件HyperScanner、数据处理软件SRAnal710、光源E27(4个卤素钕灯,100 W/220 V,Sun Glo公司,美国)、光学暗箱和载物升降平台。
高光谱成像光谱仪(SOC710VP)采用内置平移推扫的方式拍摄图像,波长范围374~1038 nm,光谱分辨率4.68 nm,可以一次性拍摄128个波段的灰度图像,也可以从图像上的每个像素点提取出1条128个数据点的光谱曲线。为了提高拍摄效率,每次同时拍摄3个叶片样本,每小区拍摄7次,后续再通过图像处理方法单独提取出每个叶片样本的光谱曲线。拍摄时将叶片和标准板同时放置在载物台上,仪器位于叶片正上方距离75 cm处,垂直于叶片拍摄。然后调整好焦距和曝光时间,用HyperScanner软件控制相机拍摄并保存文件。
1.2.2 数据反射率提取
拍摄完成后用SRAnal710软件进行光谱标定、辐射标定和反射率转换操作,其反射率转换公式如下:

式中为校正后图像的反射率;是原始图像的反射强度,cd;std是标准板区域的反射强度,cd;std是标准板区域的反射率,且标准板的反射率为已知。经过校正后最终获得需要的高光谱图像文件。
与单个像素的光谱相比,使用平均光谱可以减少数据量,避免不同类别样本之间存在的相似像素光谱对模型分类产生干扰,避免叶片曲面边缘处的像素产生错误分类,影响模型效果[15]。由于玉米叶片表面不平整,试验拍摄的图像中存在正常反射区、暗反射区以及叶脉区(图2a)等。为了提取到目标区域即正常反射区的光谱曲线,需要进行图像分割和聚类,并计算正常反射区的平均光谱作为该叶片的光谱曲线。以一组叶片样本的光谱数据反射率提取为例说明提取流程(图2):1)分析样本叶片的RGB彩图(图2a),找到叶片图像中正常反射区、暗反射区以及叶脉区等;2)分析各类别区域的光谱曲线(图2b)选择阈值分割波段,如图2b所示,在779 nm处各叶片目标类的光谱反射率显著高于其他类别,在470 nm处3个叶片目标类之间又有明显的区分,因此选择470、779 nm处的波段图像进行阈值分割;3)进行分割:如图2 c所示,首先在779 nm图像上提取反射率大于0.3的区域作为3个叶片区,然后在470 nm图像上对每个叶片区用K-means算法[16-18]进行聚类并分割成3类:正常反射区如图2d中的绿色区域、暗反射区如图2d中的蓝色区域、叶脉区如图2d中的红色区域;4)提取正常反射区的平均光谱作为该叶片的反射光谱曲线(图 2e)。
1.2.3 高光谱数据预处理
经过对每个叶片样本进行反射率提取,每年各获得504条样本光谱曲线,人工剔除其中明显偏离数据中心的异常样本。然后单独对每个品种的样本数据使用Kennard Stone算法进行样本排序,并按照3∶1的比例将其划分为训练集样本和测试集样本两部分。最后将各品种的划分结果组合成最终的训练集数据和测试集数据,以保证训练集和测试集在各品种上分布均匀。最终2018年试验得到378个训练集样本和120个测试集样本,2019年试验得到383个训练集样本和120个测试集样本。具体样本划分结果如表2所示。
使用多元散射校正(Multiplicative Scatter Correction,MSC)方法对每个筛选后的训练集样本光谱曲线进行预处理,以消除样本间散射影响所导致的基线平移和偏移现象,同时尽可能保留光谱中与化学成分有关的信息。然后对训练集数据的各波段变量进行标准化处理,通过等比缩放各波段特征,突出光谱间特征差异,提高模型的预测能力。最后,基于测试集与训练集同分布的假设,使用训练集数据的相关参数对测试集的数据进行MSC和标准化处理。其中,MSC与标准化处理过程的转换公式如下:
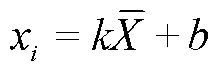
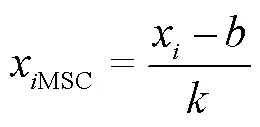
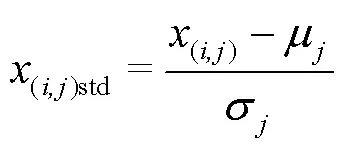
式中(i,j)是第个样本的第个变量,(i,j)std是其标准化处理后的数据,μ是训练集第个特征变量的平均值,σ是训练集第个特征变量的标准差。
1.3 基于ReliefF算法和支持向量机的玉米抗倒伏预测模型构建方法
1.3.1 特征选择与提取
本文采用2种方法进行特征变量提取:1)ReliefF(Relevant Features)方法;2)PCAReliefF方法,即主成分分析(Principal Component Analysis,PCA)方法结合ReliefF方法。
1)ReliefF方法
ReliefF是一种典型的过滤式特征选择方法,它通过相关统计量来度量每个特征的重要性并赋予不同的权重值。其基本思想是评估各特征变量对个最近邻样本的区分能力,然后增大对区分异类样本有益的特征变量的相关统计量分量,减小对区分异类样本有负面作用的特征变量的相关统计量分量,最终对基于各样本得到的估计结果进行平均,权重值越大的分量对应的特征变量的分类能力就越强。通常最近邻样本数会影响特征变量的权重值,如果太小则权重值的估计容易受到噪声数据的影响,如果太大也可能找不到重要的特征变量,因此需要取不同的值,通过观察特征变量的稳定性来选择特征[19-20]。ReliefF算法关于权重值的更新公式如下:
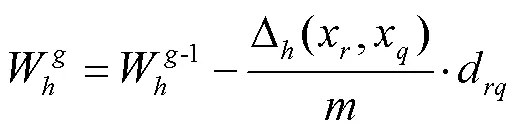
2)基于ReliefF算法和主成分分析的特征选择与提取
PCA方法是将一组相关变量通过线性变换转换到一个新的坐标系,它沿着样本矩阵的协方差最大的方向由高维空间向低维空间投影,并使得第一大方差在第一坐标轴上,第二大方差在第二坐标轴上,以此类推。PCA得到的各主成分之间相互正交,且包含的信息也不重叠,可以有效解决光谱数据普遍存在的多重共线性问题,去除冗余特征[21-22]。在实际中只需要保留方差贡献率最大的前几个主成分就可以包含原始数据中的主要信息。
综上可知,ReliefF算法会赋予所有和类别相关的特征较高的权值,而不管该特征是否是冗余特征;同时PCA方法可以消除特征间的相关性,但它只根据样本数据集本身的特性提取了信息,而没有与样本的类别属性相关联。本文尝试结合2种方法的优点,构造PCAReliefF特征选择方法。首先使用主成分分析对样本数据进行空间投影,消除特征间的共线性,然后再用ReliefF方法选择与样本类别高度相关的主成分特征参与建模,以达到更好的建模和预测效果。
1.3.2 模型构建
将使用ReliefF方法选择的原始光谱特征与使用PCAReliefF方法选择的主成分特征,输入支持向量机(Support Vector Machines,SVM)模型进行训练,并使用交叉验证法进行特征个数优化。SVM模型构建及模型参数优化是使用libSVM工具包[23]执行的。
支持向量机方法适用于解决小样本、非线性及高维度的数据分类问题。它通过支持向量来确定分类超平面,需要的数据少;且低维空间里线性不可分的数据在高维空间中有更大的概率被分开,当维度无限时概率为1。SVM的基本原理是先将特征空间中线性不可分的数据映射到更高维的空间,使其具有线性可分性;然后在高维空间中寻找一个最优超平面线性分隔各类数据,且使得分类的间隔最大化[24-27]。本质上支持向量机要解决的优化问题如下:
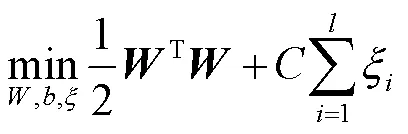

惩罚参数和核参数是SVM方法的2个重要参数,将很大程度上影响模型的学习能力和预测效果。
本研究以模型在测试集上的预测准确率(Accuracy,ACC)作为模型的评价指标。准确率是指总体样本中将抗倒样本和不抗倒样本都预测正确的样本所占的比例。同时绘制以真正率(True Positive Rate,TPR)和假正率(False Positive Rate,FPR)为坐标轴的受试者工作特征曲线(Receiver Operating Characteristic Curve,ROC),对比不同模型的预测效果。真正率是真实抗倒样本总预测正确的比例,假正率是真实不抗倒样本中预测正确的比例[16]。ROC曲线用于对不同的模型性能进行综合比较,曲线下面积越大则模型性能越好[28-30]。
2 结果与分析
2.1 玉米倒伏敏感波段分析
图3所示是2a试验的样本光谱曲线,用四分位数曲线(Quartile Curve)分别将原始光谱数据中抗倒样本和不抗倒样本的谱带分布表示出来,用变异系数(Coefficient of Variation)曲线表示各波长特征在抗倒样本和不抗倒样本中的变异程度。从四分位数曲线图可以看出,抗倒样本和不抗倒样本在原始光谱上的变化趋势基本一致,但在光谱分布上有很大程度的重叠,光谱区分并不明显。从变异系数曲线图可以看出,同年试验抗倒样本和不抗倒样本的变异系数曲线的变化趋势一致,但在400~700 nm范围内不抗倒样本的变异系数曲线明显高于抗倒样本,说明在此范围内抗倒样本的光谱数据分布要比不抗倒样本更为集中,400~700 nm波段有可能是区分抗倒样本和不抗倒样本的敏感波段。
2.2 分类特征分析
对训练集的光谱数据使用ReliefF算法,设置不同的最近邻个数,计算各波长的分类权重值;对训练集数据先进行主成分分析,再设置不同的值对各主成分进行权重计算。经过代入不同的值计算特征权重发现,当≥38(2018年数据)和≥39(2019年数据)时,各波长、各主成分的权重值均趋于稳定,不再随值变化而变化,此时的权重值可以作为分类特征的选择依据。各波段权重如图4a所示,2a间各波段的权重值相对不同,但其变化趋势基本一致,其中400、750和1 000 nm波长附近分类权重值比较高,是比较重要的分类特征波段。将各主成分按主成分贡献率由高到低排序并绘制各主成分对应的分类权重如图4b所示。可以看到大部分分类权重高的主成分都集中在前60个主成分以内,整体上随着主成分贡献率的降低各主成分的分类权重也在降低,但贡献率高的主成分对应的分类权重不一定高。对比图4a和图4b可以发现,各主成分权重的曲线都是陡峭的“尖峰”,各相邻主成分间基本没有相关性且对应的各主成分权重相差较大;而各波长权重的曲线波峰相对平缓,相邻波长的相关性高、权重值也接近。这说明ReliefF算法经常选中相邻波段相关性高的冗余特征,而PCAReliefF方法选择的特征则基本不含有冗余特征。
2.3 玉米抗倒伏预测模型建立
将各波长和主成分按分类权重值由高到低排序,共128个特征变量,以5为特征个数步长值,分成21组,依次把选中的特征波长和主成分分别代入模型。采用libSVM工具包[23]训练支持向量机模型,基于网格搜索(Grid Search)法对惩罚参数和核参数进行优化选择,用20折交叉验证法对各训练模型进行评价。惩罚参数的搜索范围是2-5, 2-3, …, 229,核参数的搜索范围是2-27, 2-25, …, 213。对每组特征的建模过程都进行参数和的优化选择,选择交叉验证正确率最高的参数组合作为最佳参数组合,如图5所示,惩罚参数和核参数最佳组合为2-9和213,对应的交叉验证正确率为91.01%。
然后将每组特征的最佳参数组合所对应的交叉验证正确率绘制成曲线,从图6可以看出,交叉验证正确率曲线起点的分类正确率都在65%以上,说明特征选择算法找到的前5个特征分类权重都比较高、分类效果明显;PCAReliefF的特征选择方法可以更迅速地找到关键分类特征,达到较高的分类正确率;而ReliefF的方法则是随着特征数量的增加分类精度逐渐提高,说明该方法选出的冗余特征较多。综合考虑模型的正确率和计算的复杂度,对2018年和2019年数据分别选择40和50个特征作为最终建立模型的特征个数。分别将2 a试验分类权重最高的前40和50个特征代入模型并在相应的最佳参数附近再次进行局部的参数优化,确定建模的最终参数如表3。
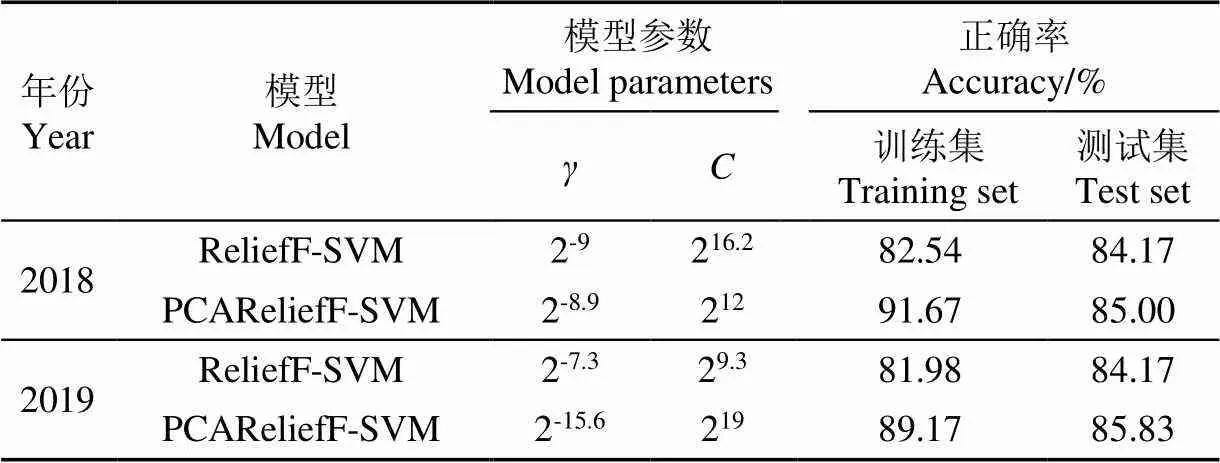
表3 最终模型参数及模型预测效果
最后用训练集的所有样本和选定的最终参数进行模型训练,并用测试集数据对模型进行测试,训练集和测试集模型的预测正确率如表3所示,模型预测结果混淆矩阵如表4所示,模型预测结果ROC曲线如图7所示。由表3可知,PCAReliefF-SVM模型2a的测试集预测正确率为85.00%和85.83%,ReliefF-SVM模型2a的测试集预测正确率均为84.17%,PCAReliefF-SVM模型预测效果更好;同时从模型对测试集预测结果的混淆矩阵可知,各个模型对不抗倒伏样本L的识别错误率都要高于抗倒伏样本LR,即各模型的假正例个数FP都要高于假反例个数FN,模型对不抗倒伏样本的敏感度相对较低。使用ROC曲线对模型性能进行评价,PCAReliefF-SVM建模方法的ROC曲线几乎完全“包住”了ReliefF-SVM方法的ROC曲线,模型综合性能更好;当认为真正率(把抗倒样本预测为抗倒样本)和假正率(把不抗倒样本预测为抗倒样本)同样重要时,即同时使真正率最大、假正率最小,此时PCAReliefF-SVM模型的性能依然优于ReliefF-SVM模型。
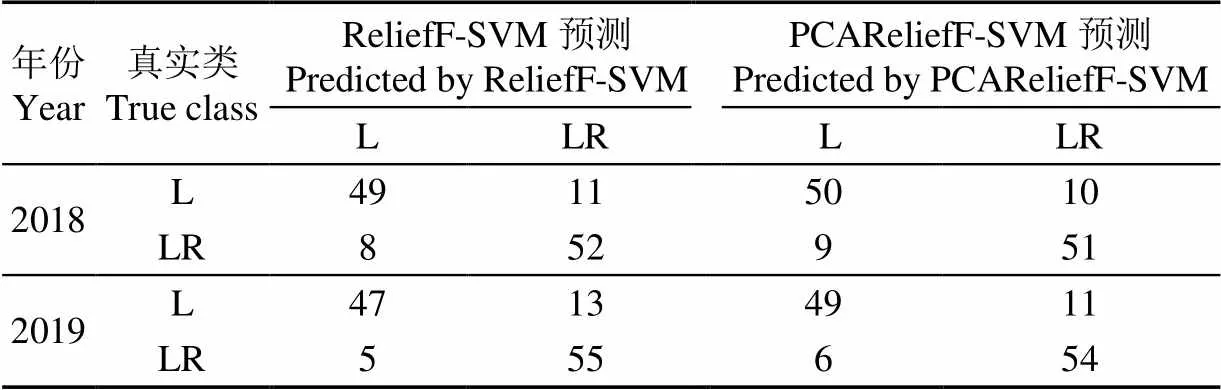
表4 最终模型预测结果混淆矩阵
以上结果表明:经过主成分分析的PCAReliefF方法比ReliefF算法能更迅速地找到主要分类特征,PCAReliefF-SVM的建模方法各项指标均优于ReliefF-SVM建模方法,PCAReliefF-SVM模型建模效率更高,模型的综合性能也比ReliefF-SVM模型更好。
3 结 论
本研究采用高光谱成像技术对玉米品种的抗倒伏进行早期分类和预测,提出了光谱提取、特征分析和建模预测方法,提前了玉米抗倒伏的检测时间,提高了玉米品种抗倒伏的筛选效率。主要结论如下:
1)提出了一种基于类别区域识别的精确光谱反射率提取方法,实现了对玉米叶片高光谱图像感兴趣区域光谱的自动提取,相对于人工获取目标区域高光谱数据方法提高了处理效率;
2)采用光谱主成分分析和ReliefF算法的过滤式特征提取方法,既可以直接挖掘出抗倒样本和不抗倒样本数据的典型分类特征,又避免了冗余特征,降低了计算复杂度,提高了模型效率;
3)结合精确优化参数的高斯核支持向量机建模方法PCAReliefF-SVM,对未知抗倒伏的样本进行预测,预测正确率不低于85.00%。
研究成果为玉米抗倒伏的研究提供了可靠的思路,证明了高光谱成像技术在玉米抗倒伏早期预测方面的应用潜力,对于提高玉米抗倒伏品种的选育工作效率有重要意义。
[1] 杨德光,马德志,于乔乔,等. 玉米倒伏的影响因素及抗倒伏性研究进展[J]. 中国农业大学学报,2020,25(7):28-38.
Yang Deguang, Ma Dezhi, Yu Qiaoqiao, et al. Research progress on influencing factors of lodging and lodging resistance in maize[J]. Journal of China Agricultural University, 2020, 25(7): 28-38. (in Chinese with English abstract)
[2] Xue J, Xie R Z, Zhang W F, et al. Research progress on reduced lodging of high-yield and -density maize[J]. Journal of Integrative Agriculture, 2017, 16(12): 2717-2725.
[3] Wei H B, Zhao Y P, Xie Y R, et al. Exploiting SPL genes to improve maize plant architecture tailored for high-density planting[J]. Journal of Experimental Botany, 2018, 69(20): 4675-4688.
[4] Xue J, Gou L, Zhao Y S, et al. Effects of light intensity within the canopy on maize lodging[J]. Field Crops Research, 2016, 188: 133-141.
[5] Zhang Y, Du J J, Wang J L, et al. High-throughput micro-phenotyping measurements applied to assess stalk lodging in maize (. )[J]. Biological Research, 2018, 51: 40.
[6] Al-Zube L A, Robertson D J, Edwards J N, et al. Measuring the compressive modulus of elasticity of pith ‑ filled plant stems[J]. Plant Methods, 2017, 13: 99.
[7] Huang J L, Liu W Y, Zhou F, et al. Mechanical properties of maize fibre bundles and their contribution to lodging resistance[J]. Biosystems Engineering, 2016, 151: 298-307.
[8] Al-Zube L, Sun W, Robertson D, et al. The elastic modulus for maize stems[J]. Plant Methods, 2018, 14: 11.
[9] 苌建峰,张海红,李鸿萍,等. 不同行距配置方式对夏玉米冠层结构和群体抗性的影响[J]. 作物学报,2016,42(1):104-112.
Chang Jianfeng, Zhang Haihong, Li Hongping, et al. Effects of different row spaces on canopy structure and resistance of summer maize[J]. 2016, 42(1): 104-112. (in Chinese with English abstract)
[10] Xia C, Yang S, Huang M, et al. Maize seed classification using hyperspectral image coupled with multi-linear discriminant analysis[J/OL]. Infrared Physics & Technology, 2019. [2019-10-14]. https: //doi. org/10. 1016/j. infrared. 2019. 103077.
[11] Zhang F, Zhou G. Estimation of vegetation water content using hyperspectral vegetation indices: A comparison of crop water indicators in response to water stress treatments for summer maize[J]. BMC Ecology, 2019, 19: 18.
[12] Trachsel S, Dhliwayo T, Perez L G, et al. Estimation of Physiological Genomic Estimated Breeding Values (PGEBV) combining full hyperspectral and marker data across environments for grain yield under combined heat and drought stress in tropical maize (. )[J/OL]. Plos One, 2019, 14(3). [2019-03-20]. https: //pubmed. ncbi. nlm. nih. gov/30893307/.
[13] Qin H M, Wang C, Zhao K G, et al. Estimation of the fraction of absorbed Photosynthetically Active Radiation (fPAR) in maize canopies using LiDAR data and hyperspectral imagery[J/OL]. Plos One, 2018, 13(5). [2018-05-29]. https: //pubmed. ncbi. nlm. nih. gov/29813094/.
[14] Feng L, Zhu S S, Zhang C, et al. Identification of maize kernel vigor under different accelerated aging times using hyperspectral imaging[J]. Molecules, 2018, 23(12): 3078.
[15] Munera S, Amigo J M, Aleixos N, et al. Potential of VIS-NIR hyperspectral imaging and chemometric methods to identify similar cultivars of nectarine[J]. Food Control, 2018, 86: 1-10.
[16] 谢文涌,柴琴琴,甘勇辉,等. 基于多特征提取和Stacking集成学习的金线莲品系分类[J]. 农业工程学报,2020,36(14):203-210. Xie Wenyong, Chai Qinqin, Gan Yonghui, et al. Strains classification of anoectochilus roxburghii using multi-feature extraction and Stacking ensemble learning[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2020, 36(14): 203-210. (in Chinese with English abstract)
[17] Arthur D, Vassilvitskii S. K-means++: The advantages of careful seeding[C]. Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms. New Orleans, LA: ACM, 2007.
[18] 王俊,张海洋,赵凯旋,等. 基于最优二叉决策树分类模型的奶牛运动行为识别[J]. 农业工程学报,2018,34(18):202-210.
Wang Jun, Zhang Haiyang, Zhao Kaixuan, et al. Cow movement behavior classification based on optimal binary decision-tree classification model[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2018, 34(18): 202-210. (in Chinese with English abstract)
[19] Robnik-Sikonja M, Kononenko I. Theoretical and empirical analysis of ReliefF and RReliefF[J]. Machine Learning, 2003, 53(1/2): 23–69.
[20] 戴建国,张国顺,郭鹏,等. 基于无人机遥感可见光影像的北疆主要农作物分类方法[J]. 农业工程学报,2018,34(18):122-129.
Dai Jianguo, Zhang Guoshun, Guo Peng, et al. Classification method of main crops in northern Xinjiang based on UAV visible waveband images[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2018, 34(18): 122-129. (in Chinese with English abstract)
[21] Li X B, Wang Y S, Fu L H. Monitoring lettuce growth using K-means color image segmentation and principal component analysis method[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2016, 32(12): 179-186. (in English with Chinese abstract)
[22] Chen Y S, Zhao X, Jia X P. Spectral–spatial classification of hyperspectral data based on deep belief network[C]. 2015 IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing. Piscataway, N Y: IEEE Press, 2015, 8(6): 2381-2392.
[23] Chang C C, Lin C J. LIBSVM: A library for support vector machines[J]. ACM Transactions on Intelligent Systems and Technology, 2007, 2(3): 1-27.
[24] Cruz-Tirado J P, Pierna J A F, Rogez H, et al. Authentication of cocoa () bean hybrids by NIR-hyperspectral imaging and chemometrics[J/OL]. Food Control, 2020, 118: 107445. [2020-06-28]. https: //doi. org/10. 1016/j. foodcont. 2020. 107445.
[25] Zhang N, Wang Y T, Zhang X L. Extraction of tree crowns damaged by Dendrolimus tabulaeformis Tsai et Liu via spectral-spatial classification using UAV-based hyperspectral images[J]. Plant Methods, 2020, 16(1): 1-19.
[26] Li L Q, Huang J, Wang Y J, et al. Intelligent evaluation of storage period of green tea based on VNIR hyperspectral imaging combined with chemometric analysis[J/OL]. Infrared Physics & Technology, 2020, 110. [2020-08-06]. https: //doi. org/10. 1016/j. infrared. 2020. 103450.
[27] Xu Z P, Jiang Y M, Ji J L, et al. Classification, identification, and growth stage estimation of microalgae based on transmission hyperspectral microscopic imaging and machine learning[J/OL]. Optics Express, 2020, 28(21). [2020-10-12]. https: //doi. org/10. 1364/OE. 406036.
[28] Hu M H, Dong Q L, Liu B L. Classification and characterization of blueberry mechanical damage with time evolution using reflectance, transmittance and interactance imaging spectroscopy[J]. Computers and Electronics in Agriculture, 2016, 122: 19-28.
[29] Wang L, Chang C I, Lee L C, et al. Band subset selection for anomaly detection in hyperspectral imagery[J]. IEEE Transactions on Geoscience and Remote Sensing, 2017, 55(9): 4887-4898.
[30] Wu Y F, Sebastián L, Zhang B, et al. Approximate computing for onboard anomaly detection from hyperspectral images[J]. Journal of Real-Time Image Processing, 2019, 16(1): 99-114.
中国农业工程学会会员:杨丽(E041200411S)
Lodging resistance prediction of maize varieties based on support vector machine and ReliefF algorithm
Zhang Tianliang, Zhang Dongxing, Cui Tao, Yang Li※, Ding Youqiang, Xie Chunji, Du Zhaohui, Zhong Xiangjun
(1.,,100083,; 2.,100083,)
Maize is one of the main food crops in the world. The lodging of maize has posed a serious challenge on the yield and mechanized harvesting in modern agriculture. Current identification methods cannot fully meet the lodging resistance and long breeding cycle of maize varieties, due to the time-consuming and laborious tasks. In this study, hyperspectral imaging technology was combined with statistical learning to predict the lodging resistance of maize varieties during the vegetative growth period. A field trial was also carried out in 2018 and 2019. The hyperspectral images were then collected for the top leaves of 8 corn varieties with and without lodging resistance at the 9-leaf stage. The experimental procedure was as follows. A threshold segmentation was first utilized to identify the leaf area. The K-means clustering was then used to divide the leaf into three areas: normal reflection, dark reflection, and leaf vein area. The average spectral curve was finally extracted in the normal reflection area, in order to analyze the data characteristics of lodging-resistant and lodging samples. The Kennard Stone was selected to sort the sample data of each species. Two parts of the set sample were also divided, including the training and test set at a ratio of 3:1. The division of each variety was integrated into the final training and test set data, in order to obtain an evenly distributed dataset of each variety. As such, there were 378 training and 120 test set samples in the 2018 test, while there were 383 training and 120 test set samples in the 2019 test. The filtering feature selection Relevant Features (ReliefF) and Principal Component Analysis (PCA) were selected to mine the spectral classification features of lodging-resistant varieties and lodging varieties. Specifically, a different number of the nearest neighbors in ReliefF was set to determine some features, according to the stability of feature variables. The redundant features were often selected with a high correlation in adjacent bands. Correspondingly, the PCA was first performed on the spectral data, thereby selecting principal components without redundant features using the ReliefF. The classification models of ReliefF- Support Vector Machine (SVM) and PCAReliefF-SVM were established, where the original spectral data features were selected by the ReliefF, and the principal component features were selected by the PCAReliefF. The grid search was also selected to optimize the penalty and kernel parameters in the SVM model for a better prediction of the model. First, cross-validation was used on the training set data to optimize the number of selected features. 40 and 50 features in the trials in 2018 and 2019 were selected to build the model, in order to balance the accuracy of the model and the complexity of calculation. All the samples were then used in the training set, where the final parameters were used for model training. The accuracy rates of prediction in the PCAReliefF-SVM model were 85.00% and 85.83% in 2018 and 2019, respectively. In the ReliefF-SVM model, the prediction accuracy rates were 84.17% and 84.17% in 2018 and 2019, respectively. It indicated that the PCAReliefF-SVM model performed better prediction. The ROC curve was also used to evaluate the performance of the model. It was found that the ROC curve in the PCAReliefF-SVM modeling almost completely "enclosed" the ROC curve in the ReliefF-SVM, indicating a better performance of the PCAReliefF-SVM model. As such, hyperspectral imaging was used for the early classification of maize varieties, particularly for the overwhelm resistance. Consequently, the findings can provide a reliable idea for the maize resistance to overwhelm using spectral extraction, feature analysis, and modeling prediction.
principal component analysis; variety; support vector machine; maize; lodging resistant; ReliefF
10.11975/j.issn.1002-6819.2021.20.026
S126
A
1002-6819(2021)-20-0226-08
张天亮,张东兴,崔涛,等. 基于支持向量机和ReliefF算法的玉米品种抗倒伏预测[J]. 农业工程学报,2021,37(20):226-233.doi:10.11975/j.issn.1002-6819.2021.20.026 http://www.tcsae.org
Zhang Tianliang, Zhang Dongxing, Cui Tao, et al. Lodging resistance prediction of maize varieties based on support vector machine and ReliefF algorithm[J]. Transactions of the Chinese Society of Agricultural Engineering (Transactions of the CSAE), 2021, 37(20): 226-233. (in Chinese with English abstract) doi:10.11975/j.issn.1002-6819.2021.20.026 http://www.tcsae.org
2020-10-24
2021-09-10
国家重点研发计划项目(2016YFD0300302);玉米产业技术体系建设项目(CARS-02)
张天亮,博士生,研究方向为高光谱农业应用与植物表型检测。Email:tianliangzn@163.com
杨丽,教授,博士生导师,研究方向为农业装备智能化和高光谱农业应用。Email:yl_hb68@ 126.com
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
黑龙江大学自然科学学报(2022年1期)2022-03-29
中学生数理化(高中版.高一使用)(2021年2期)2021-03-19
领导决策信息(2018年16期)2018-09-27
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
数学学习与研究(2017年3期)2017-03-09
食品工业科技(2014年23期)2014-03-11
西南学林(2011年0期)2011-11-12
