
用户评分的扬州星级酒店个性化推荐分析
2021-12-29 11:53徐蓉艳缪德俊
当代旅游 2021年4期
徐蓉艳 缪德俊
1.扬州市职业大学旅游学院,江苏扬州 225009;2.扬州市职业大学电气与汽车工程学院,江苏扬州 225009
引言
个性化推荐系统目前得到了越来越多的学者的关注,推荐系统的研究包含很多学科知识,例如管理、营销、机器学习及大数据等,推荐技术通过多门学科的融合迅速发展,很多推荐系统应运而生[1],基于项目的协同过滤算法根据相似的项目向用户推荐是目前运用较为广泛的一种算法,另一种是根据相似用户进行推荐的协同过滤算法,这两种算法都比较成功,但数据稀疏性、精确度以及扩展性等方面需要进一步优化[2]。现有的大部分推荐系统的推荐依据是通过用户在各个平台上对产品各方面的评价信息,用户的评价信息被表示成其对评分项目在单一维度上的偏好等级,单一维度上的评分信息不能表示不同用户对产品需求的差异,会影响到推荐系统的推荐准确性。对于用户来说,因为生活环境、性格及经济能力等不同,他们对星级酒店服务需求也不同。因此所制定的推荐系统需要根据用户不同需求向他们推荐最符合他们要求的星级酒店,这种准确的个性化推荐系统可以节约时间成本,并且满足用户需求的同时使其对此系统产生信任与依赖。
目前酒店推荐系统着力于分析基于用户的购买历史以及浏览信息,包括一些注册信息、购物信息等,现有推荐系统是采集用户访问的酒店信息包括提交的对酒店的需求信息等。文献采用聚类的方法来分析用户的兴趣和产品之间的相似性,从而具体定位符合用户需求的产品[3]。文献通过简单通俗的匹配算法使得产品和用户的兴趣特征量化,这种方法需要列举产品的特征,但是有些产品特征不容易被量化则被忽略不计[4]。文献提出采用一种线下评估的方式,首先提取网站上关于产品的用户评论,得到项目特征矩阵,采用协同过滤算法,推荐速度得以加快,冷启动问题得到优化但是没有从根本上解决,这种方法离线资源需要持续被更新[5-8]。目前现有的推荐系统存在些许问题,例如对用户行为缺乏分析、冷启动、数据量少[9]。决定用户兴趣的人性化数据却很少挖掘,难以推荐用户真正心仪的酒店资源[10]。以上推荐系统多使用的是单一维度评分的推荐系统,推荐的准确性效果不是太好,而采用多维度并且计及用户特征相对于单一维度评分来说,反应出的信息更具体,能更加准确定位用户感兴趣的星级酒店。计入用户特征到推荐系统中,能从性格、观念、知识、经历等多个维度来找准用户的喜好,分析得到准确的用户偏好,并且这样既能提高算法的准确性,又对扬州星级酒店的销售额有很大的增加。
一 基于多维用户项目评分的协同过滤算法
基于多维用户项目评分的协同过滤推荐(Colla borative Filteringalgorithm on multi-dimensional user project scoring),主要是收集系统记录的酒店用户评分信息,根据不同酒店用户对某些项目的多角度评分之间的相似性来确定目标用户的邻居用户。两个项目的关系由项目评分分析确定,再通过项目之间确定关系进行推荐;其中包括通过爬虫技术得到的网站上所有的酒店的基本信息,用户对酒店各方面评分的信息等。目标用户的对各个项目的预估评分可以由邻居用户来确定,系统推荐项目按照评分来定,例如计算评价项目X和评价项目Y之间的所有用户的相似程度,首先收集各大评分网站上的评分信息,选取同时对项目X和Y的评分用户,然后计算这些用户间的相似性。
(一)用户多维项目评分矩阵
本文使用的是Python编程语言编写的爬虫程序从携程网站获取旅游者对扬州星级酒店的评论。根据携程网对已有的扬州星级酒店评价内容中提取的关键词,确定分别从酒店的地理位置、酒店价格、房间舒适度、酒店食物、酒店设备设施与员工服务态度六个属性进行评分数据爬取和收集,并且利用Myeclipse平台,存入收集到的数据到Mysql当中。
首先是网页的抓取,收集并抓取酒店的URL放入队列当中,选取一些扬州比较流行的星级酒店的URL,因其评论信息比较多。将这些星级酒店的URL装入待抓取的队列中。从待抓取的酒店URL队列中,依次取出酒店的URL,解析得到域名服务器得到IP地址,并把URL对应的网页下载到已下载网页库当中,已经抓取过得不再重复下载。将数据进行循环,直至URL抓取完为止。然后对酒店评分数据的进行解析。根据每个大类事先确定的关键词,判断酒店评论中是否含有该关键词以及所属类别,计算分值。解析出来的数据首先存入Mysql再通过Mysql的转入Excel。在对数据进行处理时,对它进行数据集的划分。根据划分出的数据集 ,可以得到酒店的地理位置、酒店价格、房间舒适度、酒店食物、酒店设备设施与员工服务态度多维的项目评分矩阵。
(二)Pearson相关系数计算相似度
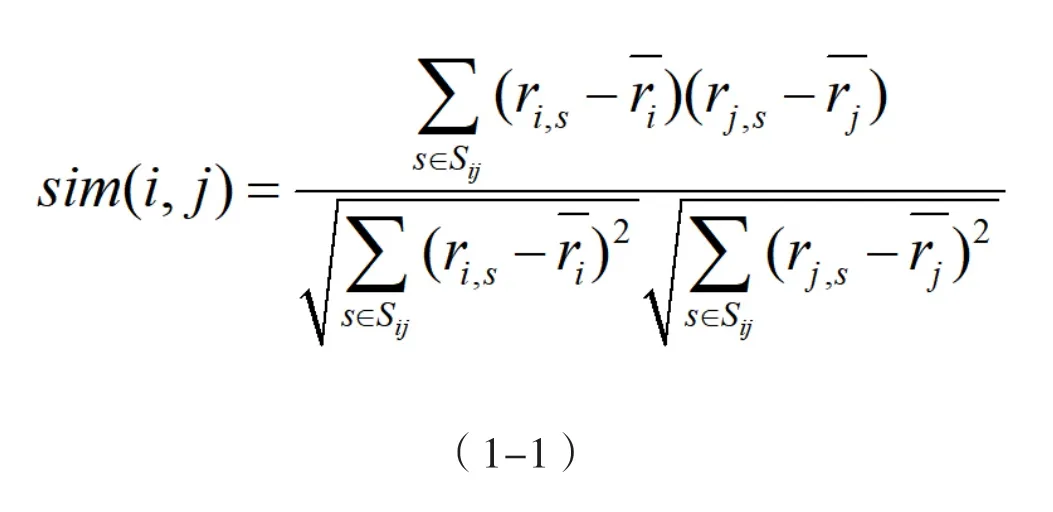
sim(i,j)表示项目i与项目j的相关性,,ri,s为用户S对共同评分项目i的评分,rj,s为用户S对共同评分项目j的评分,和分别表示项目i和j的平均评分。
(三)多维用户项目评分相似度计算
通过多维度信息准确计算用户评论的近邻集,相似度的融合采用融合调节因子的方式:

式 中α、β、λ为 权 重 因 子,其 中α+β+λ=1,simobj1(m,n)表示用户的自身属性相似度,simobj2(m,n)表示用户项目评分相似度,simobj3(m,n)表示用户项目评论的相似度,各项相似度取值范围均为(0,1)。
(四)确定用户的K个邻居用户
根据(1-2)得出的相似性来确定最近邻居集合S={S1,S2,S3...Sk},S1,S2,S3...Sk相似性按从小到大的排列。如何确定邻居用户通常有两种方式:第一种是目标用户的推荐邻居利用相似性的值选择K个近邻用户。第二种是邻居用户利用相似性的大小确定;
(五)为用户推荐相关列表
进行预测评分的计算,评分预测方法如公式(1-2)所示,用户U与用户V之间的相似程度由式中的simuv表示,用户V对项目i评分用Rvi,表示,则计算得到该目标用户对项目i的评分值如公式(1-2):

然后可以根据预测的评分进行top-n推荐。
二 星级酒店推荐系统的准确性
如何评价在推荐系统中获得用户的信任需要算法的评估指标,评价指标越好,用户对推荐系统的依赖性就越大。如果推荐星级酒店系统推荐的酒店不符合顾客要求,也就是说,用户的需求未得到满足,用户容易对该酒店的推荐系统感到厌倦,并且如果觉得该推荐系统不值得信任,最终将不会使用该推荐系统。因此,推荐系统应当确保推荐的准确性,准确性是数据挖掘过程中十分重要的性质。在推荐系统中,准确性越高,代表用户对推荐系统推荐的产品越感兴趣, 也同时表示用户对推荐系统越信赖。通常评价推荐系统准确性的指标主要包括:准确率、召回率和MAE。MAE(平均绝对误差)代表的是预测准确率下的指标,它通过计算预测评分与实际评分差的绝对值来表示统计的精度。在每对评分数和预测评分〈pi ,qi〉中,都有N个评分对,平均绝对误差是每个分数和预测分数的分数总和的平均值。
其具体公式表达如公式(2-1)所示:
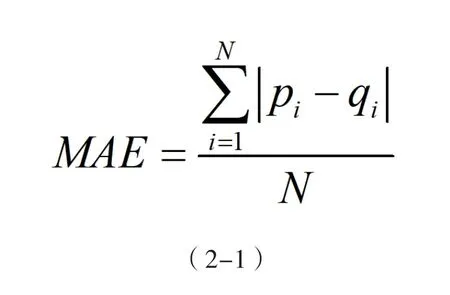
其中MAE的值越低,代表推荐系统准确性越高。
三 实验结果与分析
通过的收集和处理相关数据,进行多维项目评分过滤与计算,能够得到最终的推荐结果。推荐的准确性通常是指用户感兴趣的项目在推荐列表项目中所占的比例,代表推荐系统准确推荐的能力;召回率通常是指用户感兴趣的推荐项目在列表中所占的比例,用来代表采用不同值时系统的完全推荐能力。其中n表示n个相似用户,当n的值不同时,推荐的结果如表1所示。

表1 n个相似用户的推荐结果
由表1可见,当n≤5时,准确率和召回率随着数值n的增大逐渐升高,当n≥5时,各项指标的上升幅度较小,且上升空间极为有限。
由表2可见,本文提出的基于多维用户项目评分的协同过滤算法能在保障较好准确率的情况下,提高召回率,推荐系统的推荐效率变得更高,系统也更易拓展出其他功能。用户可以通过输入个人信息,旅行目的地和出发时间等更多偏好,在客户端上提交筛选条件后,利用多维用户项目评分协作算法进行筛选和搜索,服务器就能准确推荐出符合输入条件的星级酒店,最后将筛选结果推送到客户端,并按评分标准依次排列,用户可以更方便的从平台筛选结果中做进一步的筛选,最终选择适合自己的住星级酒店。

表2 实验结果的指标对比
四 结语
在国内电子商务平台中,几乎都能找到用户对产品的评价。用户在进行消费之前,往往首先会浏览平台对相应的产品介绍,再根据已消费用户对产品的主观评价,判断浏览的产品项目是否真实为自己所需。产品的评论具有很大的用户消费导向,满意度较高的评价往往能带动更多的用户进行消费,于是网络平台迫切需要了解用户对平台产品的确切感受,需要挖掘出更多的用户消费偏好、用户评价和一些有用的信息。
本文基于酒店推荐系统,通过处理评论信息,通过挖掘项目特征的方法对用户的评论进行提取,对用户的包含项目属性多维评价与客观表达进行保留,结构化处理项目属性。利用爬虫工具挖掘从多个网页获取对国内某酒店实际评论数据,通过进行实验,分析实验结果,比较两种算法的准确性和召回率,验证了基于多维用户项目评分的协同过滤算法具有较好的准确性。
猜你喜欢
现代仪器与医疗(2022年2期)2022-08-11
汽车实用技术(2022年10期)2022-06-09
中国典型病例大全(2022年12期)2022-05-13
中国典型病例大全(2022年7期)2022-04-22
无线互联科技(2021年18期)2021-11-02
中国药学药品知识仓库(2021年18期)2021-02-28
世界汽车(2019年2期)2019-03-01
世界汽车(2019年2期)2019-03-01
世界汽车(2019年2期)2019-03-01
世界汽车(2019年2期)2019-03-01
