
基于深度学习的盲道障碍物检测算法研究
2021-12-22 13:18段中兴丁青辉
计算机测量与控制 2021年12期
段中兴,王 剑,丁青辉,温 倩
(西安建筑科技大学 信息与控制工程学院,西安 710055)
0 引言
我国目前视力障碍人群总数高达1 731万,其中年轻人占比23.5%,视障人群作为弱势群体,他们的日常出行是不可忽视的问题。但目前城市对于道路规划不全面,又因机动车辆急剧增多等原因,致使一车“难停”。同时共享单车的兴起,使得公众私自占用盲道现象十分普遍,导致视障人群出行存在安全隐患,故解决盲道障碍问题不但有利于视障人群日常出行,同时有利于社会发展。
近些年,视觉处理技术得到突破,出现以卷积神经网络为代表的障碍物检测方法,Girshick等[1]提出R-CNN检测方法,通过利用深度卷积神经网络提取目标特征信息,获得良好的检测精度。R-CNN提出后,许多学者通过对其网络结构研究与优化,提出不同的目标检测算法以提高。主要包括SPP-Net[2],Fast R-CNN[3],Faster R-CNN[4]等检测算法,此类算法在应用到障碍物检测时需要将检测过程分为两段:先进行候选区域生成,然后进行目标分类,在障碍检测中尤其在无人驾驶、盲道障碍检测等实时性要求较高的方向上性能表现并不优越[5]。Redmon等[6]基于回归预测的思想提出了YOLO算法,直接在卷积神经网络中提取目标的相关特征来预测其位置信息,相比两阶段目标检测算法检测速度更快,但一阶段算法[7]由于追求速度而放弃对图像中小型目标的特征提取,导致精度不高。Liu等[8]提出SSD方法,网络引入先验框进行障碍物检测,提高了网络对于障碍目标的精度。Redmon[9]随后借鉴SSD算法提出YOLO V2算法,在检测精度上有明显提升,但是对于目标特征提取能力没有得到有效解决。为改善网络对于目标特征提取能力,YOLO V3[10]以及YOLO V4[11]等算法相继提出,网络通过残差结构提高对小型物体的特征提取能力,从而实现精度的提升。随着目标检测算法被应用到道路障碍检测中,更多学者针对目标的特性进行不同方面的改进,李鹏飞[12]等对YOLO9000模型提出改进,通过对模型算法参数进行调整来适合多目标检测。王建林[13]等针对目标检测精度低的问题对YOLO V2中卷积层采用密集连接方式来获取更好的目标信息,同时采用空间金字塔池化增强局部特征来提高网络的检测精度。郭进祥[14]等将YOLO V3骨干特征提取网络变为空洞卷积,保持较大感受野同时对非极大抑制算法进行优化,提高对遮掩目标的检测。孙佳等[15]提出K-means-threshold方法,弥补普通K-means算法对聚类中心初始位置敏感问题。鞠默然[16]等针对图像中小型障碍的像素相对较少,通过将YOLO V3网络输出层进行上采样,将高层特征与低层特征进行特征融合获得对障碍目标的位置信息。巩笑天[17]等对Tiny YOLOV3目标检测改进,增加2步长的卷积层代替最大池化,同时使用深度可分离卷积替换传统卷积增加网络模型精度。王伟锋[18]等通过增强网络对障碍目标的感受野来扩大卷积核对特征的提取范围及能力提高,同时将低层与高层的特征信息融合起来增加对小型障碍物的检测精度。而盲道障碍物以其背景复杂,障碍种类繁多,物体遮掩占比大等特点使得常见的目标检测算法在实际检测中存在对小型障碍物体、远距离物体、条形障碍物体的漏检、误检等问题。针对以上问题,本文基于深度学习的方法对盲道障碍物检测展开研究。对此本文网络提出改进:1)通过对盲道障碍物特性进行分析,针对远距离物体以及条形物体特征信息较少问题,增加非对称卷积模块(ACB)[19],在垂直方向与水平方向强化特征提取,将提取后的特征增加到方形卷积特征中,实现对条形物体以及远距离物体的特征加强;2)引入条形池化模块[20],减少方形池化过程中空白信息与污染信息的干扰,为兼顾长条形与非长条形障碍物的效果,将金字塔池化改进为混合池化模块(MPM);3)改变特征融合方式[21],将高级特征语义信息融入到低级特征的方式来解决复杂场景下盲道障碍物识别问题。
1 盲道障碍检测算法优化
1.1 特征提取结构
网络特征提取结构如图1所示,由CSPDarknet53,MPM池化模块,PANet[22]组成。CSPDarknet53作为骨干特征提取网络,由Darknet53和CSP局部交叉阶段组成。Darknet53主要由5个残差块构成,CSP局部交叉阶段能够增强CNN的特征提取能力,在轻量化的同时保持准确性,降低计算成本。MPM为混合池化模块,由Pyramid pooling与Strip Pooling 组成,主要作用为增大网络感受野,增强条形特征池化效果。PANet通过自下而上的路径增强较低层中定位信息流的准确性,建立底层特征和高层特征之间的信息路径,增强整个特征层次架构。
改进后的网络中将非对称卷积加入到骨干特征提取网络中,条形池化与金字塔池化构成MPM混合池化模块,在特征融合方式上改变传统concat融合操作,将高级特征的语义信息加入到低级特征中增强对小目标识别精度。
1.2 非对称卷积模块(ACB)
为使网络在实际场景下对盲道中条形障碍物与盲道中小目标障碍物有更好的检测效果,在网络方形卷积核的基础上增加非对称卷积模块,增强在图像水平与垂直方向上的特征提取。对于盲道障碍物检测中对于小目标障碍物与条形障碍物来说,十字区域信息尤为重要,因此将非对称卷积核中十字骨架部分特征信息提取后与原方形卷积核提取特征信息权重相叠加,提升网络对条形障碍物的检测精度,降低较远处障碍物的漏检率。
如图2所示,将非对称卷积(ACB)添加到网络残差块中,针对盲道中条形障碍物特征信息进行提取,并与方形卷积核提取的特征信息进行融合。

图2 卷积结构
图3公式如下,对于一个尺寸为H×W,通道数为D的卷积核,通道数为C的特征图作为输入,用F∈RH×W×C表示卷积核,M∈RU×V×C表示输入,O∈RR×T×D代表输出特征图,对于这个层的第j个卷积核,对应的输出特征映射通道为:
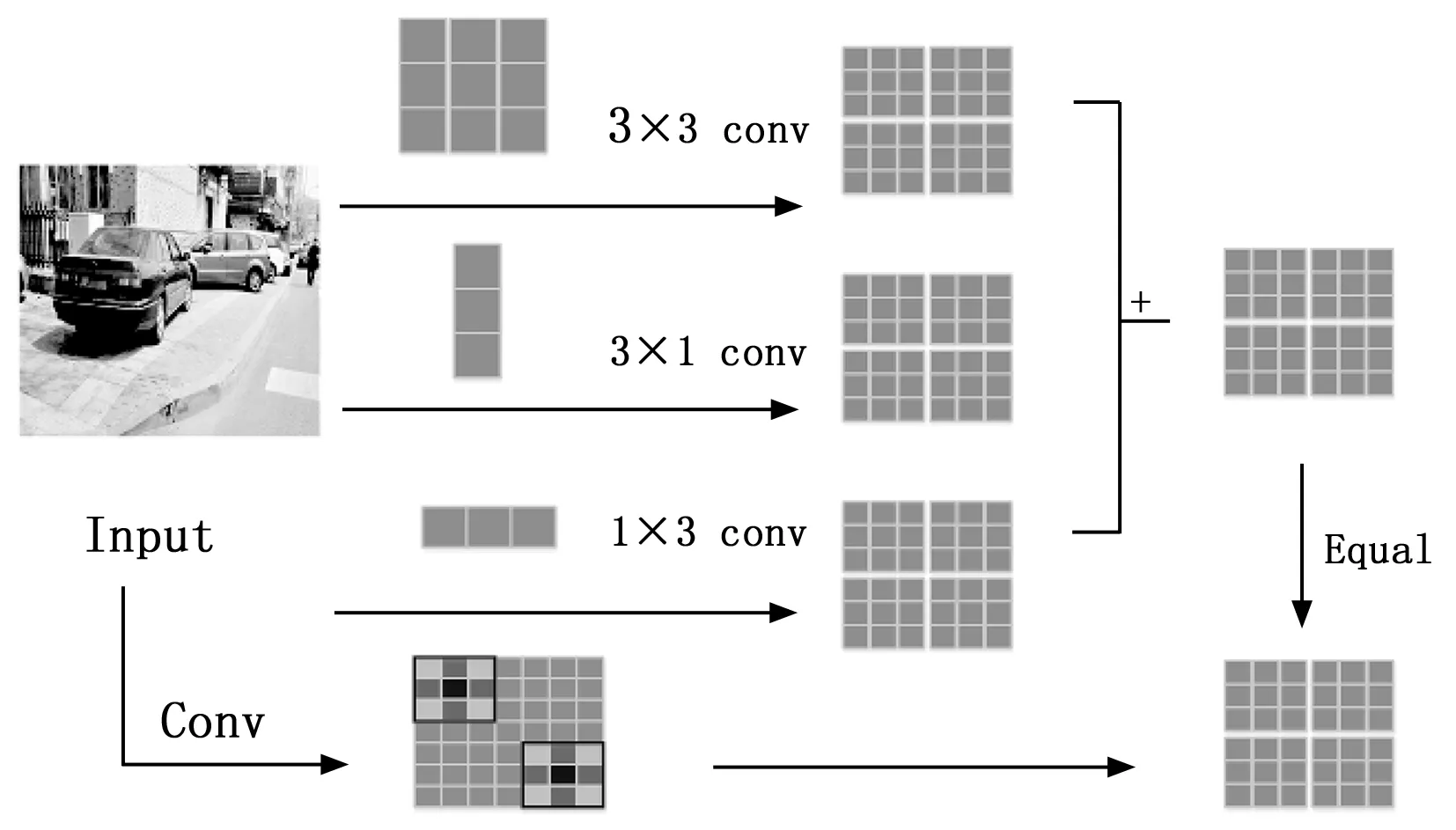
图3 卷积原理图

(1)
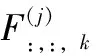
I*K(1)+I*K(2)=I*(K(1)⊕K(2))
(2)
其中:I是一个矩阵,k(1)和k(2)是具有兼容尺寸的两个2D核,⊕是在对应位置求和。图像经过非对称卷积模块(ACB)处理后,保留了目标水平与垂直方向上的特征,再通过与方形卷积后的特征对应位置像素叠加,实现对条形目标特征信息的增强,提高网络对条形障碍物目标的检测精度。
1.3 混合池化(MPM)
金字塔池化是为了获得更大的感受野,现阶段增大感受野的方法,可利用自注意力机制(self-attention)来建立长距离关系,也可以使用空洞卷积(dilated convolution)[19]或金字塔池化,但这几种方法在特征为方形条件下效果较好,本文经实验发现,在实际盲道场景中,金字塔池化对于长条形目标检测效果并不理想。针对于此问题,本文提出引入长条形池化模块,既可以丰富长条障碍物特征语义信息,同时避免了使用方形池化时引入的污染信息和空白无效信息。但全部使用条形池化又会导致方形障碍物目标的效果变差,因此设计了一种混合池化模块(mix pooling moudle),其结构如图4所示。

图4 特征融合
图5所示为混合池化模块,由金字塔池化与条形池化模块组成,其中条形池化公式如下,对于一个输入为H×W的特征图,其水平池化公式为:

图5 混合池化
(3)
同理垂直池化公式为:
(4)
其中:(h×u)代表池化范围,将池化后的特征图进行扩容,扩容后的特征图进行对应位置相加,再将条形池化后的特征权重增加到金字塔池化特征图上,实现对检测目标十字区域信息增强,提高对条形物体以及远距离物体的检测精度。
1.4 特征融合方式
常用的特征融合方法一般为concat,concat是进行通道扩容,物体特征增加但是每一维的特征信息没有改变,但是concat操作会导致计算量增大。而低级特征包含丰富的空间信息,高级特征拥有丰富的语义信息,因此本文引入一种特征融合方法[23],如图6所示。本文特征融合方法是将低级特征与上采样后的高级特征进行逐元素相乘。为防止网络训练过程中出现过拟合现象,提前进行归一化处理,从而使低级特征含有更多的语义信息,加强网络对于盲道中小目标物体特征信息的提取能力,提升网络对于盲道中小目标物体的检测精度。

图6 特征融合
图6为特征融合方式,其公式为:
yl=f(xl,xl+1)
(5)
yl表示特征融合输出,f表示矩阵运算,xl表示低级特征,xl+1表示高级特征,N1表示低级特征每一通道对应信息,N2表示高级特征每一通道对应信息,为使公式成立,xl与xl+1需满足大小相同,通道数相等,故利用卷积操作进行通道变换。改变传统的空间融合,利用高级与低级特征对应位置相乘的形式,加强每一位置的特征信息。
2 实验与结果分析
实验平台搭载Inter i7 9700K处理器, 1个NVIDIA 2080Ti显卡;深度学习框架采用pytorch-1.6.0,以及Nvidia公司CUDA10.1的GPU运算平台以及CUDNN深度学习GPU加速库。
2.1 盲道障碍物数据集
目前,由于盲道障碍物体种类复杂,用于深度学习的盲道障碍物数据集较为匮乏,已知的公共数据集都只包含部分盲道障碍物体类别。对此本文对于实际盲道场景进行调查,分析盲道主要出现的障碍物。城市主干道区域盲道障碍物主要以行人、共享单车为主;生活区域所在盲道上出现障碍物较多,主要以汽车、货车、共享单车、摩托车、行人、桌子、椅子等中大型物体出现,其中汽车、自行车、摩托车以及行人在盲道上出现频率较多且数量大。对于上述情况,本文采用视频拍摄方式,共采集不同场景下的37个视频段,通过将视频按帧率裁剪得到不同场景下的障碍物图像。图像主要分为两部分,一部分以生活区域为主的障碍物图像,该部分图像具有场景复杂、障碍物种类以及数量多、物体遮掩比大等特点;另一部分以主干道区域为主的障碍物图像,具有物体较为单一,轮廓完整等特点。本文通过裁剪获得图像共计3 380张,为丰富障碍物数据集,对图像进行数据增强方法扩充数据集,共计7 460张。

图7 盲道障碍数据集
2.2 定量与定性分析
本文为验证改进YOLO V4网络的有效性,将YOLO V4作为对比实验,初始化权值来自于VOC数据集预训练的结果,对盲道障碍物数据集进行训练,训练批次为64,衰减为0.000 5,最大迭代次数200。初次训练学习率为10-3,100 epochs后调整为10-4,150 epochs后调整为10-5。
为了对模型进行量化分析,对比两种方法对障碍物的检测效果,采用评价指标交并比GIOU、Objectness、Classification、Recall、mAP、F1作为定量评价指标,如图8所示。

图8 训练指标
图8分别表示YOLO V4模型与改进后的网络模型各个指标训练过程,同时加入第三章模型训练指标进行对比。图(a)表示GIoU训练过程,(b)表示Objectness训练过程,(c)表示Recall训练过程,(d) 表示F1训练过程, (e) 表示Classification训练过程, (f)表示mAP训练过程。
为更好地展现本文改进YOLO V4网络的性能,本文将FAST-RCNN、Faster-RCNN、MASK-RCNN、YOLO V3、YOLO V4网络进行综合对比,通过交叉展现对比结果,验证改进YOLOV4网络的性能。如表1所示。

表1 各模型在盲道障碍数据集的训练指标
通过对比YOLO V4与改进网络两个模型的各指标训练过程可以看出,改进模型在盲道障碍数据集GIOU为0.73,Objectness为0.421,Classification为0.007,Recall为0.975,MAP为0.976,F1为0.909,与YOLO V4模型在盲道障碍数据集上对应的指标分别提升了0.036,0.01,0.000 183,0.007,0.003,0.005。
通过对比改进YOLOV4网络与FAST-RCNN、Faster-RCNN、MASK-RCNN、YOLO V3、YOLO V4网络的GIOU指标分析发现,改进YOLO V4网络对于真实值包围框的下降曲线最快,可快速有效地定位图像中的真值区域,验证了数据集中障碍物集中分布于图像中十字区域,通过混合池化模块及先验定位策略,帮助网络快速定位图像中的IOU区域;对比Objectness指标发现,改进YOLOV4网络对于目标IOU区域的包裹紧密性较FAST-RCNN、Faster-RCNN、MASK-RCNN、YOLO V3、YOLO V4网络的损失值较小,证明改进YOLOV4网络中可以紧密的包围目标区域,去除背景噪声对于有效特征的干扰,得益于本文中混合池化模块及ACB模块组合效果对于图像IOU区域特征提取的精细程度,提取图像中细致特征信息;对比Classification指标可知,改进YOLO V4网络对于分类结果的快速有效性强于FAST-RCNN、Faster-RCNN、MASK-RCNN、YOLO V3、YOLO V4网络,可以准确有效的将障碍物类型进行区分,得益于非对称卷积模块对卷积核提取能力的加强,以及特征融合方式低层特征对高层特征补充的有效性;通过对Recall、mAP、F1共3个指标的分析可知,改进YOLOV4网络对于整体类别的正样本的召回率较FAST-RCNN、Faster-RCNN、MASK-RCNN、YOLO V3、YOLO V4网络提升较大,且对于单独类别的调和对比值F1有一定的提升,验证了网络在准确预估类别及检测过程中有较好的准确率和鲁棒性,对于mAP综合全局的验证指标分析可知,本文方法的混合池化模块、多尺度的特征融合方式及非对称卷积对于网络整体有较好的提升效果,三者组合交叉嵌入互相影响,综合提升网络对于障碍物目标的检测及识别能力,从而提升网络整体的检测精度及准确率,验证了改进网络的有效性。
表2分别表示YOLO V4与本文特征提取方法对盲道障碍物的效果。通过将非对称卷积加入骨干特征提取网络中,以及采样后的高级特征的信息与低级特征相融合。利用相乘的方式进一步增强障碍物的特征信息,可以看出本文特征融合方法相对于concat融合来说将障碍物目标信息表现更为明显。YOLO V4网络对图像中人以及电动车等目标信息提取较为模糊,而本文网络相较于YOLO V4网络提取效果更佳。

表2 特征提取对比
图9为YOLO V4与改进YOLO V4的识别效果,(a)、(a1)、(a2)表示YOLO V4模型检测效果,(b) 、(b1)、(b2)表示改进YOLO V4模型检测效果。

图9 场景测试对比
由图9可看出,通过引入非对称卷积模块,加强了对障碍物十字区域的特征提取能力,使得网络对较远处障碍物包括条形障碍物可以检测出来,同时有较好的检测精度,混合池化模块减少污染信息以及冗余特征信息对障碍目标信息的干扰,利用相乘的融合方式进一步增强条形以及小型障碍物的特征信息。改进YOLO V4模型相较于原YOLO V4模型能够将较远处条形以及小障碍物检测出来,提升了网络模型对障碍物的检测精度,对于含有部分特征信息以及特征信息不明显的障碍物目标,也能较为准确地检测出来。改进YOLO V4模型在盲道障碍物检测中提高了对条形障碍物的检测能力。同时非对称卷积以及混合池化模块也增强了非条形障碍物的特征信息,对近距离障碍目标的检测效果也有提升。
3 结束语
本文针对于目标检测算法在检测远距离盲道障碍物以及条形障碍物检测存在漏检误检问题,在YOLO V4模型基础上,加强骨干网络在水平与垂直方向上的提取能力,构建混合池化模块与特征融合部分使得网络对条形障碍物、小型障碍物检测精度提升并在盲道数据集上进行实验。实验表明条形目标以及远距离障碍目标能够以良好的精度识别出来,降低网络漏检率。结果表明改进后的网络模型对障碍物检测有更好效果。
猜你喜欢
计算机应用(2022年9期)2022-09-25
安徽农业科学(2022年7期)2022-04-19
软件导刊(2022年3期)2022-03-25
文萃报·周二版(2020年42期)2020-11-28
小作家报·教研博览(2020年36期)2020-09-10
青少年日记·小学生版(2019年2期)2019-09-02
智能计算机与应用(2018年2期)2018-05-23
娃娃画报(2016年3期)2016-04-05
数学大王·中高年级(2015年6期)2015-06-26
小学生作文·小学低年级适用(2014年7期)2014-09-10
