
Feature Fusion Multi_XMNet Convolution Neural Network for Clothing Image Classification
2021-12-21 05:51:10ZHOUHongleiPENGZhifeiTAORanZHANGLu
ZHOU HongleiPENG ZhifeiTAO RanZHANG Lu
1 College of Fashion and Design, Donghua University, Shanghai 200051, China2 School of Computer Science and Technology, Donghua University, Shanghai 201620, China
Abstract: Faced with the massive amount of online shopping clothing images, how to classify them quickly and accurately is a challenging task in image classification. In this paper, we propose a novel method, named Multi_XMNet, to solve the clothing images classification problem. The proposed method mainly consists of two convolution neural network(CNN) branches. One branch extracts multiscale features from the whole expressional image by Multi_X which is designed by improving the Xception network, while the other extracts attention mechanism features from the whole expressional image by MobileNetV3-small network. Both multiscale and attention mechanism features are aggregated before making classification. Additionally, in the training stage, global average pooling(GAP), convolutional layers, and softmax classifiers are used instead of the fully connected layer to classify the final features, which speed up model training and alleviate the problem of overfitting caused by too many parameters. Experimental comparisons are made in the public DeepFashion dataset. The experimental results show that the classification accuracy of this method is 95.38%, which is better than InceptionV3, Xception and InceptionV3_Xception by 5.58%, 3.32%, and 2.22%, respectively. The proposed Multi_XMNet image classification model can help enterprises and researchers in the field of clothing e-commerce to automaticly, efficiently and accurately classify massive clothing images.
Key words: feature extraction; feature fusion; multiscale feature; convolution neural network(CNN); clothing image classification
Introduction
With the rapid development of the Internet and smart products, people's lifestyles have undergone earth-shaking changes, and online shopping has become the preferred way for people to shop[1]. In recent years, the scale of China's clothing market has continued to expand, and sales of clothing products have also increased year by year[2]. The classification of massive clothing images has become an urgent, arduous and challenging task.
In order to study automated classification methods to replace manual classification, domestic and foreign scholars achieved classification by studying global and local features such as shape and texture of clothing images. Willimonetal.[3]exploited color, texture, shape, and edge information from 2D and 3D local and global information for clothing classfication by useing a Kinect sensor. Surakarin and Chongstitvatana[4]first used GrabCut to segment clothing fabrics, and then fused the extracted local binary pattern(LBP) features and speeded up robust features(SURF), finally used support vector machine(SVM) for classification with an average classification accuracy of 73.57%. Thewsuwan and Horio[5]presented preprocessing techniques for clothing classification system based on Gabor filters and LBP, which improved the performance of clothing image classification to a certain extent. Wuetal.[6]matched the custom style feature descriptor with the extracted four underlying features such as histogram of oriented gradient(HOG), color histogram, LBP, and edge operator. A fine-grained classification method of clothing image based on style feature descriptor was proposed. Due to the noise of lighting changes, size scaling and other noises in clothing images, the accuracy of the above classification methods is generally low and excessively depended on manual design features.
With the development of convolution neural networks(CNNs), domestic and foreign scholars have widely used it in the field of image recognition and classification, and have made great progress. Many clothing image classification models based on CNNs have emerged. Liuetal.[7]proposed a clothing image classification model based on local key location features and global convolutional features of clothing images. By adding local key location features, the classification effect of the model was improved. Chenetal.[8]classified and recognized images by fusing the siamese network(SN) model and the binary CNN(B-CNN) model, which is better than SN and B-CNN models, respectively. Zhangetal.[9]proposed a texture and shape biased dual-stream network, one was texture biased flow and the other was shape biased flow. The features extracted from the two flows were spliced for clothing attribute prediction and category classification, and the performance was better than the previous structure. Chenetal.[10]designed a lightweight feature extraction network that used a multi-path structure to increase the network width and fused the extracted features of different sizes. The model was applied to image classification to achieve a low error rate. The above study improved the classification effect to a certain extent through feature fusion and adding local key point features, but the problems of low richness of extracted feature information, slow model training, and unsatisfactory classification effect still existed. Our contributions are summarized as follows.
(1) We proposed an optimal neural network model through a combination experiment of different feature extraction networks.
(2) We used different scale convolution kernels in Multi_X to extract features of different scales to improve the richness of feature information.
(3) We designed a novel network named Multi_XMNet to classify clothing images. We conduct extensive experiments on a challenging dataset(DeepFashion), and demonstrate that Multi_XMNet is superior than other models.
1 Related Works
In recent years, feature fusion has been widely used in clothing image classification. LÜetal.[11]classified clothing attributes by fusing the location-related features of the region of interest extracted by the pose estimation network and the global features of the original clothing image, and achieved good results. Zhangetal.[12]fused the key point attention mechanism and the channel attention mechanism to generate the final key point feature of clothing images, which effectively improved the accuracy of category classification and the recall rate of attribute prediction. Lietal.[13]improved the expressive ability of image features through the parallel combination of InceptionV3, MobileNet, Xception,etc. Chenetal.[14]embedded the Squeeze-and-Excitation(SE-Net) model in the Xception network, and used multiscale deep separable convolution to classify clothing images. Experimental results show that the richness of model feature information and the accuracy of clothing image classification are improved.
1.1 Xception model
InceptionV3[15]is the third-generation model in the Inception series, which uses different sizes of convolution kernels, so there are different sizes of receptive fields. The biggest advantage of the Inception network is to expand the convolution operation between layers[15]. Xception[16]is improved on the basis of InceptionV3, using deep separable convolution instead of standard convolution, then the processing process of spatial and channel correlation information is completely separate. In the depth separable convolution, depthwise convolves each input feature channel separately, and pointwise uses 1×1 ordinary convolution to complete the adjustment of the number of channels. The framework of the classification model studied in this paper is based on the Xception model. The overall structure of the Xception model is shown in Fig. 1.
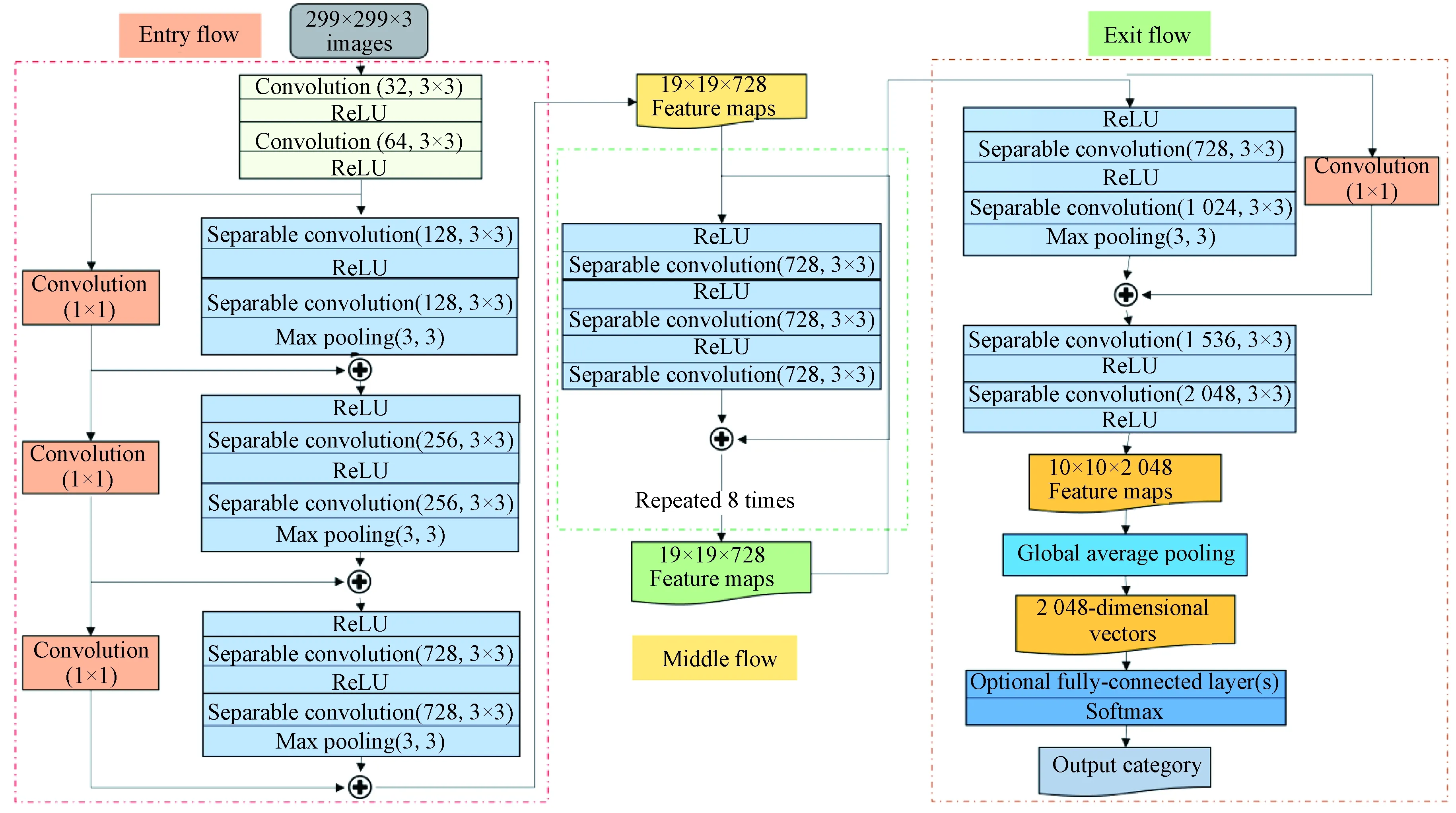
Fig. 1 Diagram of the Xception model
In Fig. 1, the Xception model consists of three main parts, namely entry flow, middle flow, and exit flow. It can be seen from Fig. 1 that there are 4 blocks in entry flow, 8 blocks in middle flow, and 2 blocks in exit flow. The main internal structure of the block is the residual convolutional network with the separable convolution layer. And rectified linear unit(ReLU) is used as the activation function.
In this paper, the single-scale convolution kernel of the Xception network is replaced with a multiscale convolution kernel to obtain a new network which is named Multi_X, where Multi represents the multiscale convolution kernel, and X represents Xception.
1.2 MobileNetV3-small
MobileNetV3[17]is a lightweight network structure which is searched out by network architecture search(NAS) and NetAdapt algorithms on the basis of MobileNetV2. There are two versions of MobileNetV3: MobileNetV3-large and MobileNetV3-small. The network structure of MobileNetV3-small is shown in Fig. 2.

Fig. 2 MobileNetV3-small network architecture
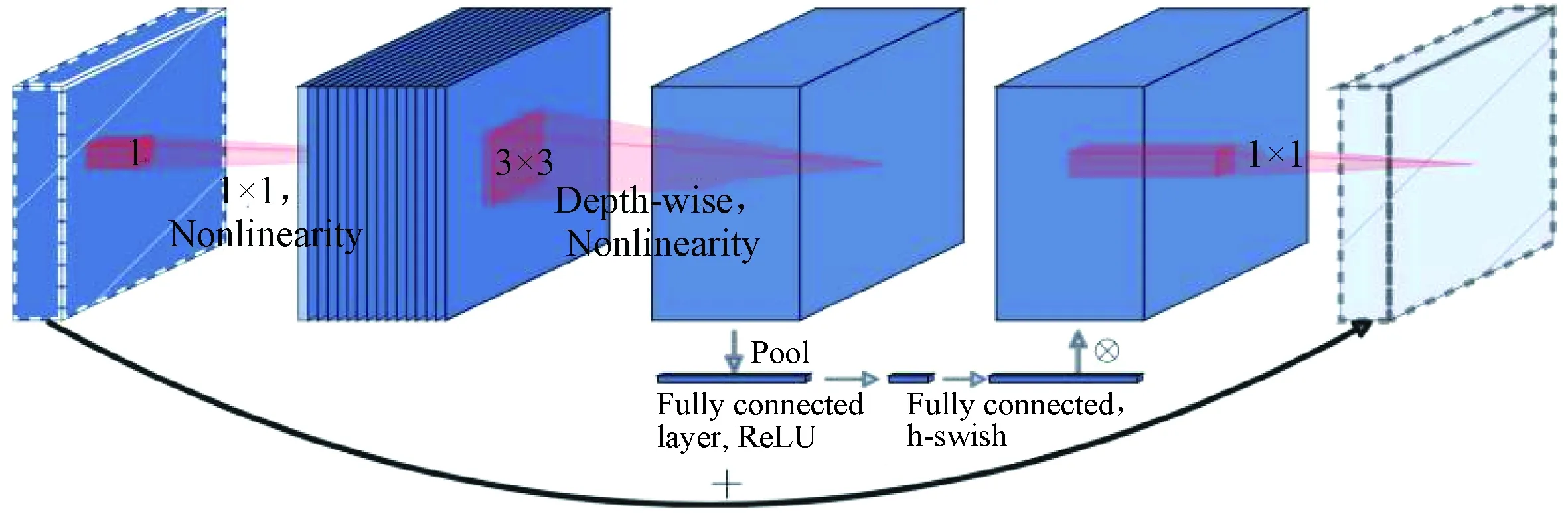
Fig. 3 Bottleneck structure of MobileNetV3-small
We can see from Fig. 2 that the SE-Net structure is added to the bottleneck structure of the MobileNetV3-small network, and a new activation function called hard-swish(h-swish) [shown in Eq.(1)] is used to replace the computationally intensive swish function, which improves the accuracy of the network.
(1)
whereAis the new activation function h-swish,R6is the activation function ReLU6, andxis the input of the activation function(tensor).
The main structure of the bottleneck of MobileNetV3-small is illustrated in Fig. 3. The bottleneck contains 1×1 expansion convolution, depth-wise convolutions, and 1×1 projection layer. Additionally, the structure also introduces lightweight attention modules based on squeeze and excitation. The input and output are connected with a residual connection if and only if they have the same number of channels. And the SE-Net module contains a global average pooling(GAP) and two fully connected layers.
This paper uses MobileNetV3-small as the feature extraction network to extract the clothing image features based on the attention mechanism and uses them in subsequent experiments.
2 Multi_XMNet: Feature Fusion Clothing Image Classification Model
We designed a Multi_XMNet feature extraction network for clothing image classification. The network includes two parts: Multi_X feature extraction network and MobileNetV3-small feature extraction network.
2.1 Proposed Multi_X feature extraction network based on Xception
The depth separable convolution of the original Xception network uses a single-scale 3×3 convolution kernel, resulting in a relatively single extracted feature information, which limits the richness of features to a certain extent. In order to extract feature information of different scales, this study replace the 3×3 convolution kernels in the depth-wise convolution of the depth separable convolution with convolution kernels of other scales, so that the network can finally fuse feature information of different scales, enrich feature information, improve the classification efficiency of clothing classification model.
Convolution kernels of different scales correspond to receptive fields of different sizes, and the ability to capture feature information at different scales means that the final features obtained are the fusion of features of different scales. Before we perform a separable convolution, we first use 1×1 pair convolution to compress the input feature map into a fixed size feature vector, and then perform depth-wise convolution of different scales. The corresponding convolution kernel size is 1 × 1, 3 × 3, 5 × 5. There is a target area on each scale, and finally the output features of multiscale convolution are spliced to obtain a feature map containing multiscale information.
The feature extraction process of the network model is shown in Fig. 4. In the Multi_X model, the input is uniformly normalized to the size of the clothing image. The network consists of 14 building blocks in total, and the output of each building block are used as the input of the next building block. The output of the 14th building block is the finally extracted multiscale features. The overall structure of the Multi_X network is shown in Table 1.

Fig. 4 Multi_X feature extraction process
Multi_X has a total of 14 building blocks, which are composed of multiple convolutions and a residual structure. We perform scale replacement of the 3×3 convolution kernel in the partial block of the depth separable convolution. The convolution kernels of block 2, block 3 and block 4 are replaced by 3×3 convolution kernel and 5×5 convolution kernel. And the single 3×3 convolution kernel in blocks 5-12 are replaced by 1×1, 3×3, 5×5 convolution kernels of different scales. The global maximum pooling and fully connected layer behind will be removed. The residual connection is used in block 2 to block 13, and the output of the previous layer is convolved and merged with the output of the current layer as the input of the next layer.
We combine the Multi_XMNet network and the MobileNetV3-small network to get the Multi_XMNet network of this paper.
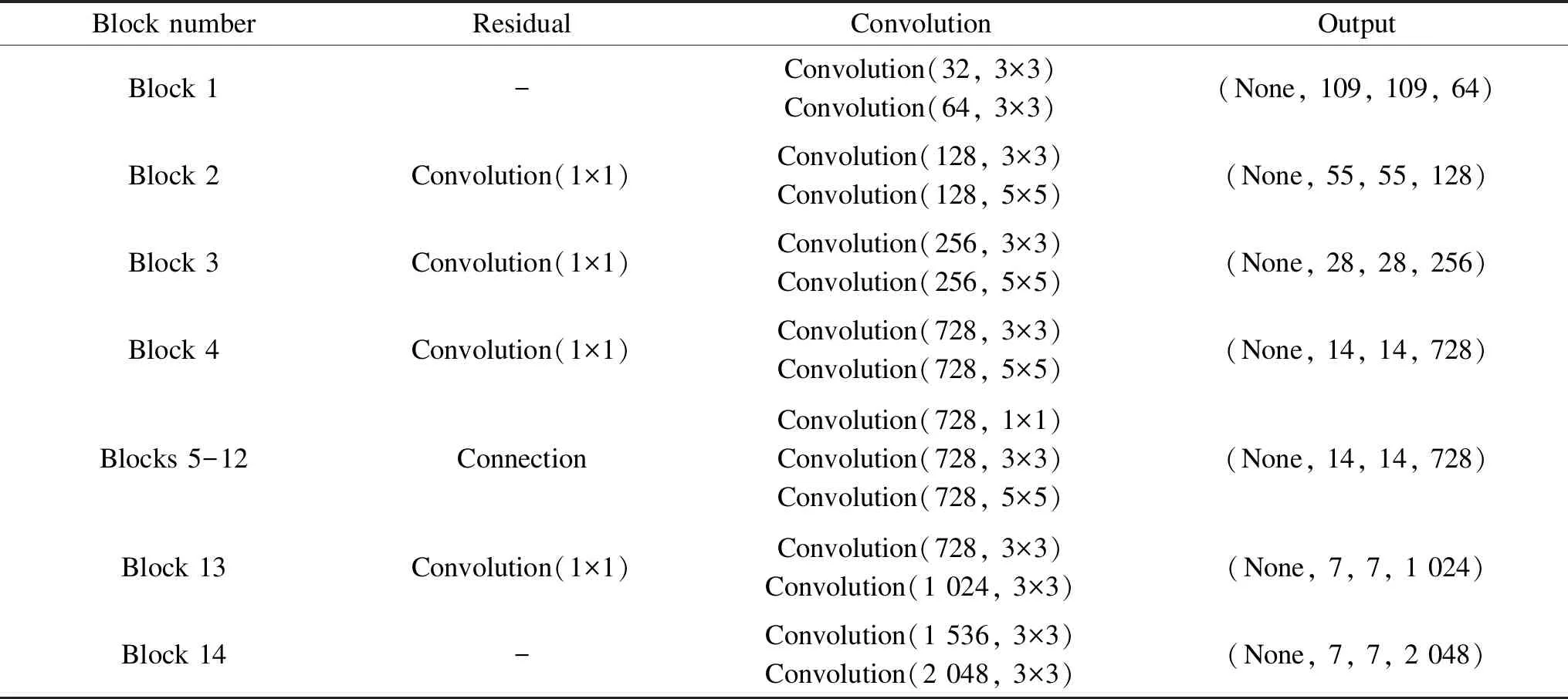
Table 1 Multi_X feature extraction network overall structure
2.2 Proposed Multi_XMNet
The Multi_XMNet uses two networks to perform feature extraction respectively, and then the final feature of prediction classification of clothing images is generated by fusing the extracted features. In order to accelerate the convergence of the network, this paper firstly performs GAP on the fusion features, and then uses convolution to replace the fully connected layer, finally, the softmax layer is added to train. The loss function of softmax is used to train and optimize the network model. Additionally, the prediction results of different categories are exported to compare with the true label, and the accuracy is obtained according to certain calculation. The model architecture is shown in Fig. 5.

Fig. 5 Multi_XMNet architecture
The Multi_X is a multiscale feature extraction network based on Xception designed in this paper. By improving the convolution operation, the single-scale convolution feature extraction of Xception is changed to multiscale feature extraction, which enhances the richness of feature information. Due to the small parameters of MobileNetV3-small and the introduction of a lightweight attention model, which can extract features with attention mechanism, this paper selects it as a feature extraction network.
We splice the features extracted by the two networks to improve the richness of feature information. In view of the fact that the traditional fully connected layer calculates global information, there are too many parameters, and it is easy to cause problems. This paper uses GAP and two convolutional layers to replace the fully connected layer to classify the final features. The local connection used in the convolution layer calculates local information, which can effectively reduce the amount of calculation and accelerate network training. Since each pixel in the output feature map corresponds to a certain area in the input, the use of a convolutional layer instead of a fully connected layer can retain more features and make the model classification more accurate[10].
3 Experimental Evaluation
3.1 Experiment dataset
This study used the DeepFashion dataset from the Chinese University of Hong Kong[7], which includes 50 categories, and 289 000 pictures. We selected 6 categories, 11 503 clothing pictures as the experiment dataset. The 81% of the dataset were selected as the training set, 9% as the validation set, and 10% as the test set.
3.2 Experiment preparation
The experiments used graphics processing unit(GPU) to speed up the training of the model, and the Adam optimizer was used to speed up the convergence of the model. In the training phase, the training cycle(epoch) was set to 150 times, and the number of images per batch was 32. The callback function ReduceLROnPlateau was used to optimize learning during the training process rate. Because the initial size of the experimental dataset was uneven and the amount of data was small, the following methods were used to preprocess the dataset to enhance the generalization ability of the model during the model training stage. The image datasets were expanded by randomly panning and flipping the image horizontally or vertically, and the image size was uniformly adjusted to 224 mm × 224 mm.
3.3 Experiment results and analysis
In order to verify the validity and practicability of the Multi_XMNet method, we compared the Multi_XMNet with mainstream clothing image classification algorithms. The accuracy comparison results of different methods on the DeepFashion public dataset were shown in Table 2.
The Table 2 shows that Multi_XMNet gets the best accuracy, which improves higher 2.27%, 3.32%, 1.12%, 6.81%, 2.22%, 1.26%, 5.58% than the MobileNetV3, Xception, Multi_SE_Xception_Net[14], F-ResNet[18], InceptionV3_Xception, Xception_MobileNetV3, and InceptionV3 models. Additionally, this paper compares the classification accuracy of different combination networks. The experimental results show that the Multi_XMNet combined network has improved accuracy compared with other structures.
In this paper, the training set and validation set of six types of clothing images are used for experiments to compare the classification accuracy of different category.

Table 2 Comparison of accuracy between Multi_XMNet and mainstream methods
The comparison results of the classification accuracy are shown in Fig. 6.
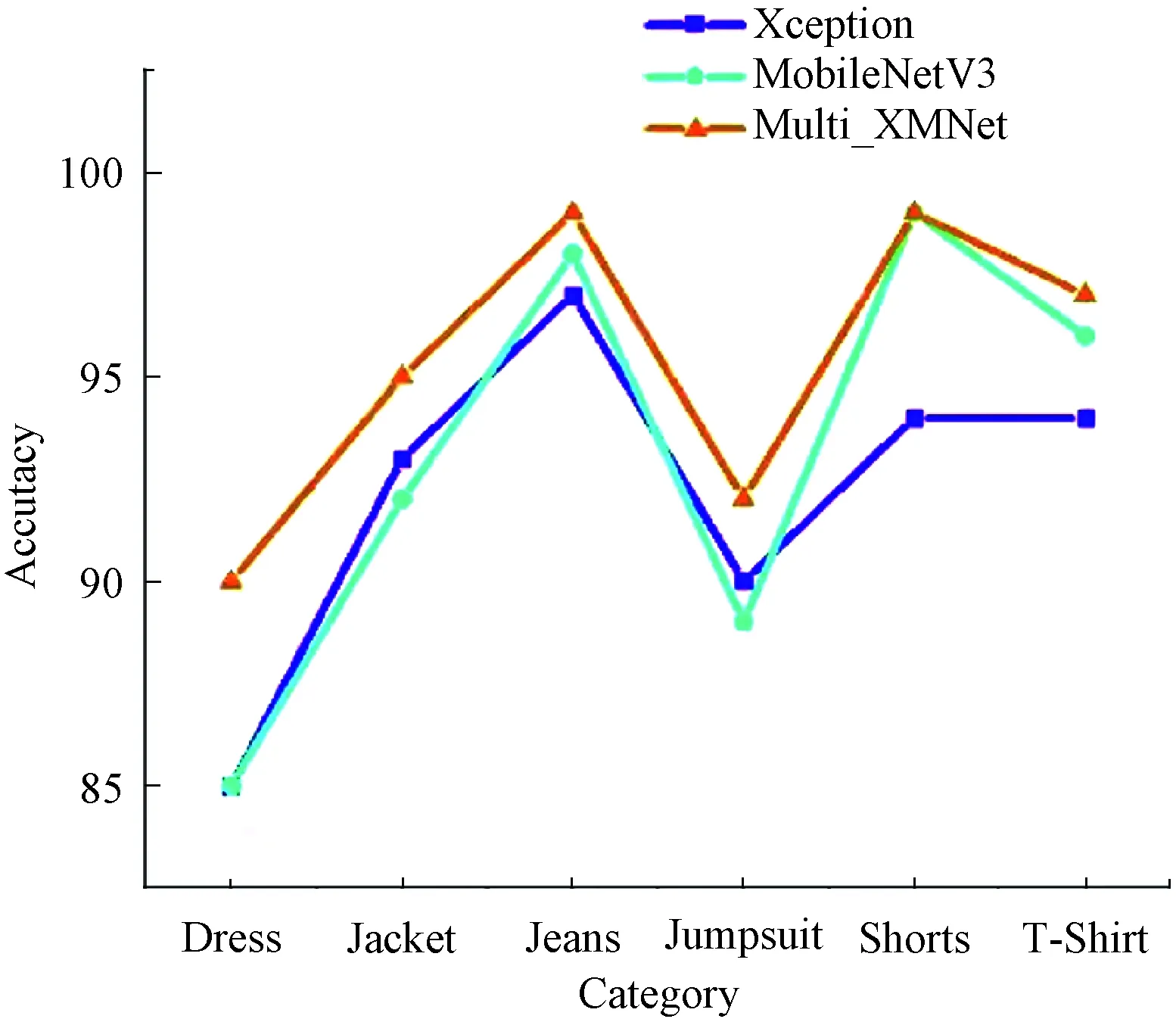
Fig. 6 Comparison of classification accuracy of different categories
Through Fig. 6, we can intuitively see that the classification accuracy of our Multi_XMNet for dress, jacket, jeans, jumpsuit, shorts, and T-shirt is higher than that of Xception and MobileNetV3 models. The shorts classification accuracies of Multi_XMNet and MobileNetV3 are the same, and both are higher than that of Xception model.
3.4 Model prediction classification with test dataset
We used the 81% training set and the 9% validation set to train the Multi_XMNet. The 10% test set were used to predict. The prediction results are shown in Table 3. We randomly select 15 images among them for visual display, and the result is shown in Fig. 7.

Table 3 Forecast results for each type of pictures
It can be seen from Table 3 that 13 images with the true label of dress are incorrectly predicted as jumpsuit, and 16 images with the true label of jumpsuit are incorrectly predicted as dress. Although the overall classification accuracy rate is high, there are still errors.

Fig. 7 Model prediction results
The true category(prediction category) results of each piece of clothing are shown in Fig. 7. The true category of the clothing image in Fig. 7(a) is jumpsuit, but it is misclassified as dress by Multi_XMNet. And the clothing image in Fig. 7(c) is incorrectly predicted as jumpsuit from the original true category dress. Additionally, the clothing images with checkmark in the upper right corner of the image are all the correct prediction results.
4 Discussion
Through the analysis of Table 3, we can conclude that 13 images in the true category of dress were misclassified as jumpsuit, and 16 images in the true category of jumpsuit were misclassified as dress. We analyze the reasons for misclassification from the aspects of style and heat map, and give corresponding ideas to solve the problem.
4.1 Misclassification of similar styles
According to Figs. 7(a) and 7(c), we can easily find that the jumpsuit is relatively loose, and the legs and dress are easy to confuse. We can improve the classification accuracy of dress and jumpsuit by increasing the amount of sample data.
4.2 Misclassification heat maps
From the two heat maps shown in Fig. 8, it can be seen that dress and jumpsuit are classified according to the knees. However, the knee position of the two images is similar, so the model classifies the two pictures into the same category. We can improve the model structure or replace the feature fusion method to extract representative features, and improve the accuracy of image classification.

Fig. 8 Heat maps of picture classification error
4.3 Correctly classify heat maps
In Fig. 9, jean is classified according to the crotch and waist, and short is the edge of the pants, so the two are classified correctly.

Fig. 9 Correction classification heat maps
5 Conclusions
This paper proposes a Multi_XMNet feature fusion image classification model. The model first acquires multiscale features through an improved Xception network, then acquires the attention mechanism features through a MobileNetV3-small, and finally merges the features through concat and performs clothing image classification. The GAP and two convolutional layers are used to replace the fully connected layer in the standard CNN, which speeds up convergence of the model. Compared with InceptionV3, Xception, and InceptionV3_Xception, this model has improved classification accuracy by 5.58%, 3.32%, and 2.22%, respectively. The proposed Multi_XMNet can be used to help industry managers and researchers perform rapid and effective automatic classification of clothing images. Additionally, this model can also help to establish image classification models and systems in other scenes.
 Journal of Donghua University(English Edition)2021年6期
Journal of Donghua University(English Edition)2021年6期
- Journal of Donghua University(English Edition)的其它文章
- Strain Pseudomonas putida PAO-1 Isolate with Polyphosphate Accumulating and Elongation Ability
- Theoretical Model on Transformation Factors of Scientific and Technological Achievements under the Belt and Road Initiative
- Exploitation of Waste Heat from a Solid Oxide Fuel Cell via an Alkali Metal Thermoelectric Converter and Electrochemical Cycles
- Gait Recognition System in Thermal Infrared Night Imaging by Using Deep Convolutional Neural Networks
- Data Augmentation Based Event Detection
- Reduced Switching-Frequency State of Charge Balancing Strategy for Battery Integrated Modular Multilevel Converter