
Gait Recognition System in Thermal Infrared Night Imaging by Using Deep Convolutional Neural Networks
2021-12-21 05:51MANSSORSamahFSUNShaoyuanZHAOGuoshunQUBinjie
MANSSOR Samah A FSUN ShaoyuanZHAO GuoshunQU Binjie
1 College of Information Science & Technology, Donghua University, Shanghai 201620, China2 Faculty of Engineering and Technology, University of Gezira, Wad Madni 22211, Sudan
Abstract: Gait is an essential biomedical feature that distinguishes individuals through walking. This feature automatically stimulates the need for remote human recognition in security-sensitive visual monitoring applications. However, there is still a lack of sufficient accuracy of gait recognition at night, in addition to taking some critical factors that affect the performances of the recognition algorithm. Therefore, a novel approach is proposed to automatically identify individuals from thermal infrared (TIR) images according to their gaits captured at night. This approach uses a new night gait network (NGaitNet) based on similarity deep convolutional neural networks (CNNs) method to enhance gait recognition at night. First, the TIR image is represented via personal movements and enhanced body skeleton segments. Then, the state-space method with a Hough transform is used to extract gait features to obtain skeletal joints′ angles. These features are trained to identify the most discriminating gait patterns that indicate a change in human identity. To verify the proposed method, the experimental results are performed by using learning and validation curves via being connected by the Visdom website. The proposed thermal infrared imaging night gait recognition (TIRNGaitNet) approach has achieved the highest gait recognition accuracy rates (99.5%, 97.0%), especially under normal walking conditions on the Chinese Academy of Sciences Institute of Automation infrared night gait dataset (CASIA C) and Donghua University thermal infrared night gait database (DHU night gait dataset). On the same dataset, the results of the TIRNGaitNet approach provide the record scores of (98.0%, 87.0%) under the slow walking condition and (94.0%, 86.0%) for the quick walking condition.
Key words: gait recognition; thermal infrared (TIR) image; silhouette; feature extraction; convolutional neural network (CNN)
Introduction
Recently, computer vision research has focused on gait recognition[1]. The gait has a lot of advantages of being hard to hide, available even at a distance from the camera, and less likely to be obscured than other biometric features. Additionally, gait is a remote behavioral biometric feature that has been captured easily without pedestrians' attention. This feature stimulates the need for automatic isolated human recognition in security-sensitive visual monitoring applications. Human gait recognition tends to discriminate individuals depending on the way of their walk[2]. This type of recognition is not unfair because it is implemented remotely and does not require cooperation from the person. The general gait recognition system stimulates the need for automatic personal recognition[3], as depicted in Fig. 1. When watching a subject in the view, the digital camera captures a raw image of the clip. This image is preprocessed and then passed to the feature extraction stage in order to obtain gait features from the input image sequence. Moreover, these features are passed to the recognition module for classification. So, the gait classifier is used to match those features with the features stored in the database in order to identify a person (such as a human identification (HID)) as the output.
In recent years, some researchers have started leveraging three-dimensional (3D) options for the identification of multi-view gait advancing issues from two-dimensional (2D) image classification[4]. Further, the approaches in Refs.[5-6] have carried out the transformation of gait sequences into commonly desired viewpoints. Feng and Luo[7]used long short-term memory (LSTM) networks to save and extract a person's walking pattern by correctly extracting data from the heat map. Yuetal.[8]demonstrated how one could use the generative adversarial network (GAN) to produce a gait energy image (GEI) and then learn the person's gait features. Souza and Stemmer[9]developed a gait recognition system with a Microsoft Kinect sensor to obtain parameters. Besides, gait recognition systems were improved with a view-invariant gait recognition network (VGR-Net)[6]and masked region-based convolutional neural network (Masked RCNN)[10]under multiple views, and conducted comprehensive processes for testing and training. Previous research indicates that the performance of human gait recognition is quite limited. The limited performance is because that the gait is vulnerable to standard variables,i.e., occlusion, view angles, carrying, and clothing conditions. For the above reasons, gait recognition strategies have difficulties achieving satisfactory performance[11]. Besides that, most crimes happen at night; so night surveillance is very important. Therefore, some gait recognition models in thermal infrared (TIR) images or video sequences have been proposed, for example, the models based on GEI frameworks and template matching methods (TMM)[11]. However, these models do not have a high recognition accuracy rate from thermal imagery under different walking conditions. Therefore, it is difficult to identify a human being accurately under current vision technologies, although humans are easily detected. Furthermore, TIR images need precise processing to obtain more accurate features. Despite the challenges of thermal imaging, recent studies have been focused to deal with the problems of person detection and recognition in thermal infrared imagery[12-13]. It also encouraged the results to recognize humans in infrared imaging because it had a good performance at night in terms of time, space, and accuracy. From the above discussion, previous methods are somewhat ineffective with the high recognition accuracy rate at night from a distance. Finally, to improve the performance of gait recognition at night, a novel deep CNN method is proposed to similarity gait biometrics from thermal data obtained under different walking conditions.

Fig. 1 A general gait recognition system
This paper proposes a novel approach that deals with the TIR night gait recognition problem in big data called the TIRNGaitNet approach. This work aims to achieve a higher recognition accuracy rate for gait recognition at night times. Therefore, a new night gait network (NGaitNet) structural network is designed via deep learning CNNs architecture, which is different from others in the depth layers. It has four deep convolution layers, and it is easier to train than other recent architecture[11]. A single CNN can process and analyze a batch of sequential TIR images based on shared weights and translation fixed features in order to obtain more complex gait features from thermal images in the deep layers[14]. Besides, the network will allow to learn gait features from a large dataset and have a high level of abstraction by applying a convolution operation to the input data compared to the shorter networks. The two thermal databases, namely the Chinese Academy of Sciences Institute of Automation infrared night gait dataset (CASIA C) and the Donghua University thermal infrared night gait database (DHU night gait dataset), are used to simulate the night vision conditions. In two datasets, 10 different walking speeds are carefully selected with a high resolution corresponding to all subjects in the data and then feed into the NGaitNet. When the data are passed from layer to layer, the receptive field will increase, and the filters will obtain TIR gait features under various speeds under different walking conditions. The proposed method can then recognize the changing gait patterns′ consecutive features to predict similarities between pairs of silhouettes that refer to the same human gait.
1 Proposed Approach
A novel TIRNGaitNet approach is proposed for human gait recognition from TIR imaging under night walking conditions. This approach aims to achieve a higher accuracy rate for night gait recognition. This goal is achieved by designing a new NGaitNet network based on the deep architecture of CNNs with a multi-task. This network takes a pair of silhouettes (or thermal images) of the same person as an input. The key differences between deep CNN and other CNNs are that the hierarchical patch-based convolution operations are used in deep CNNs, which reduces the computational cost and then abstracts images on different feature levels. In addition, deep learning deals with a complex neural network with multiple layers. Thus, deep CNN layers in the NGaitNetcan acquire a high level of gait features from the thermal images and then simulate data to learn these features based on human walking speeds for recognition. Our methods involve the following procedures, as depicted in Fig. 2.
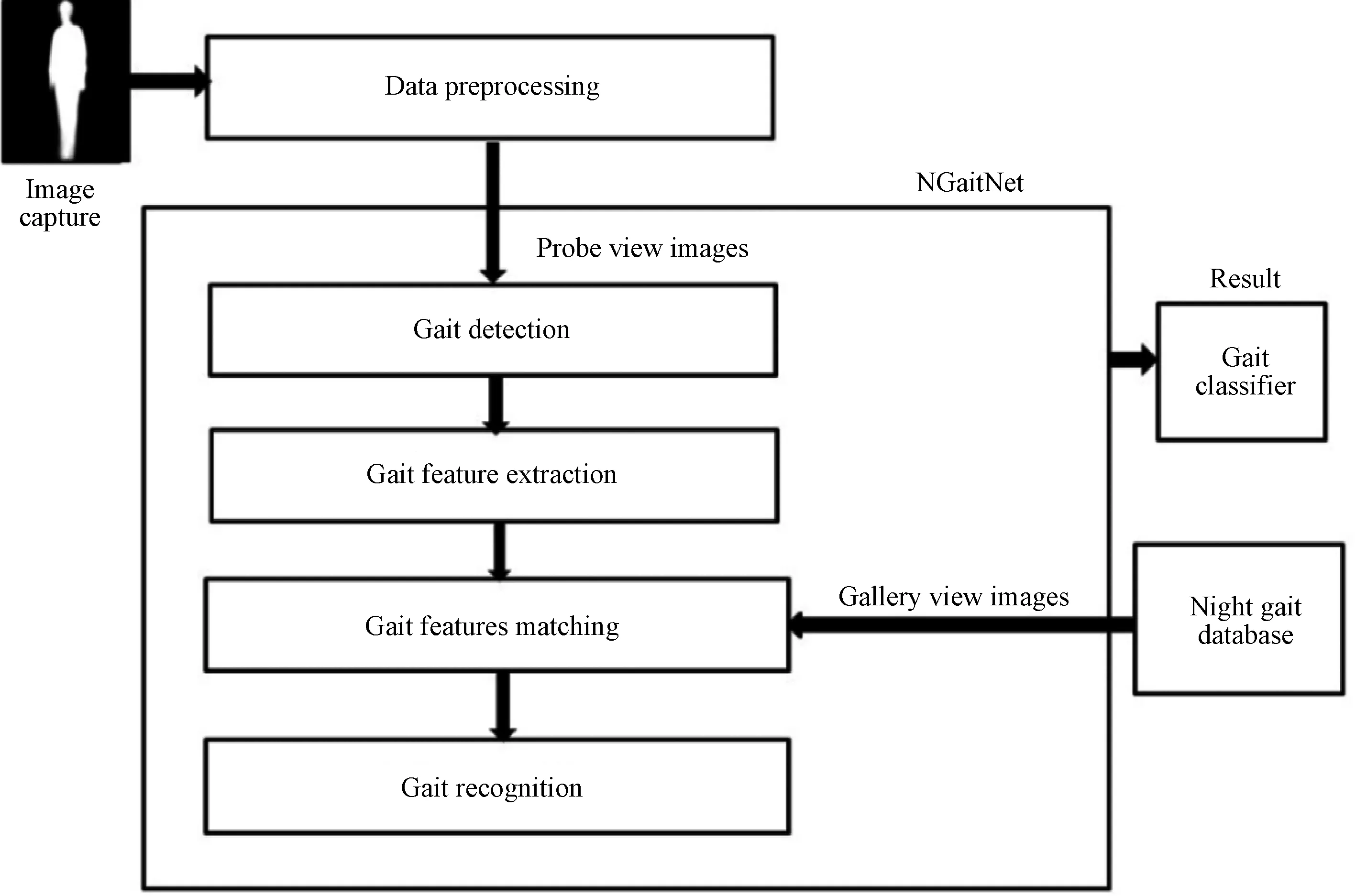
Fig. 2 A flowchart of the proposed method
Firstly, a captured TIR image as input is pre-processed and optimized to obtain a skeleton with background modeling according to the Gaussian mixture model (GMM) method[15-16]. Secondly, the noise is removed from the thermal images as it passes through the filters to facilitate human detection using the modeling of the target body structure supported by biomechanical measurements of human gait. Thirdly, the state-space method (SSM)[17]and the Hough transform technique[9]are used to extract features from a human gait image, and then the human gait is assessed according to the previous detection results. Fourthly, the gait features obtained from previous operations are matched with the features previously stored in the night gait dataset to achieve the best matching results. Finally, the proposed network will automatically recognize the features of most changing gait patterns to predict the pair's similarity that indicates the same human identity.
1.1 Network architecture
The proposed NGaitNet network is inspired by a slightly modified version of some studies conducted on gait databases, for example, the works in Refs.[2,4,6,18]. Specifically, the proposed NGaitNet architecture involves deep CNN layers and non-linear matching methods. Besides, NGaitNet analysis and internal design differ from other related methods[2]. NGaitNet is a smaller version of deep CNNs, which has four deep convolution layers, and it is easier to train than other recent architecture mentioned in Ref. [11]. The deep layers in NGaitNet perform max-pooling and sampling, and they act as corresponding decoders of the sample of inputs using the received maximal clustering indices. A rectified linear unit (ReLU) non-linear activation function is used in the first three layers to perform the padding (or encoding). Batch normalization (BN) is used after each convolutional layer to accelerate the convergence of deep layers and is also used when decoding. Furthermore, the NGaitNet network in this form is designed because the TIR image needs more depth to obtain (or extract) more complex features of a human gait and then recognize it. The NGaitNet is adjusted according to weights to improve performance and achieve a state of sophistication in night gait recognition and scene classification.
Figure 3 shows the NGaitNet architecture, which utilizes silhouette gait sequences at various speeds (or steps) to analyze and classify the spatiotemporal features. In our case, the two-axis accelerometer of the TIR image frames was arranged at 10 kinds of walking speeds. Next, the 10 speed gait data is represented as ordered signals and time-series signals. The deep CNN layers obtain the gait features, and exploit the space and time domains by applying a convolution operation on the input data (image frames). As a result, deep CNN can process these data effectively. To fully utilize the network's strengths, the deep CNN layers are employed correspondingly, to learn the gait features and perform information fusion to improve representational strength. Specifically, the fusion process is performed in a concatenation manner for the extracted features from a person. A fusion process is closely related to the fully connected layer which is connected to the successive layer for gait classification. An attempt is made to determine gait based on speed and then classify the image for personal identification.
The NGaitNet architecture contains four convolution (Conv) layers, three-bath normalization (Norm) layers, three max-pooling (Pool) layers, and one fully-connected (FC) layer, followed by a Sigmoid classification layer, as shown in Table 1.
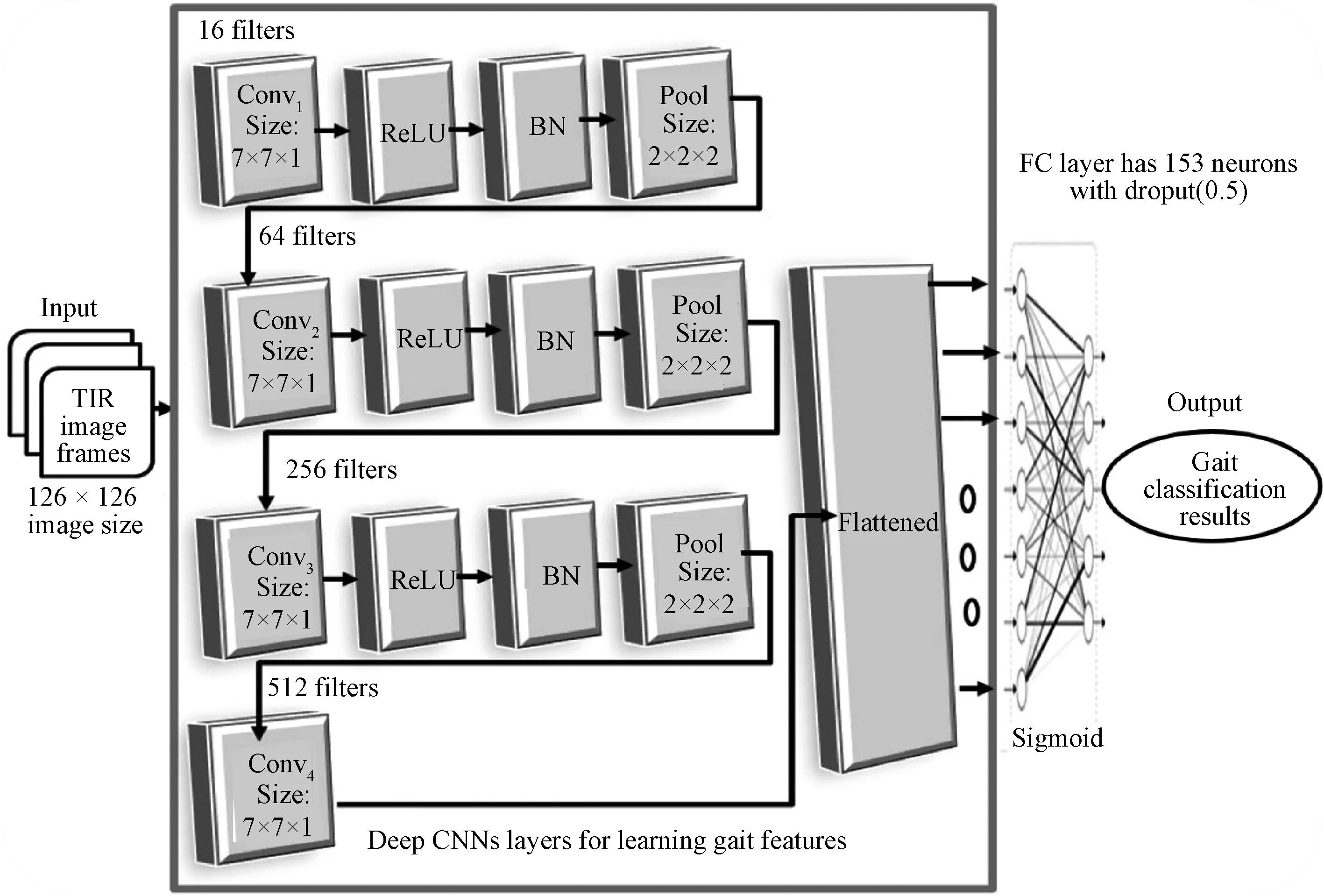
Fig. 3 NGaitNet architecture for gait recognition at night

Table 1 Description of NGaitNet layers
Besides, the gait recognition tasks are processed by using NGaitNet as shown in Fig. 4. The NGaitNet takes a pair of silhouettes (or GEI's) images and starts to match the silhouette's features with local or global features. The left side processes static images in the network. The right side is the lateral counterpart that offers gait features and then calculates two gait images. Furthermore, the NGaitNet is built with different kinds of layers which are denoted by using the rectangles in Fig. 4,i.e., Conv, Norm, Pool, and FC layers. Two adjacent rectangles filled with numbers 0 and 1 together denote a linear classifier and indicate that this layer applies the dropout (Drop) technique. The right side next to each of Conv and FC letters indicates the index number of the corresponding layer of the complementary network. The following numbers for a Conv layer are named filters size, stride, and feature map dimensions. Likewise, the numbers following the "Pool" word are titled pooling cell size, stride, and down-sampled feature map dimensions. The numeral following FC denotes the neurons. Also, the equivalence of group sparsity is applied to their Conv layers. For example, filters are used for 16 channels in the first Pool, 64 channels in the second Pool, and 256 channels in the third Pool.
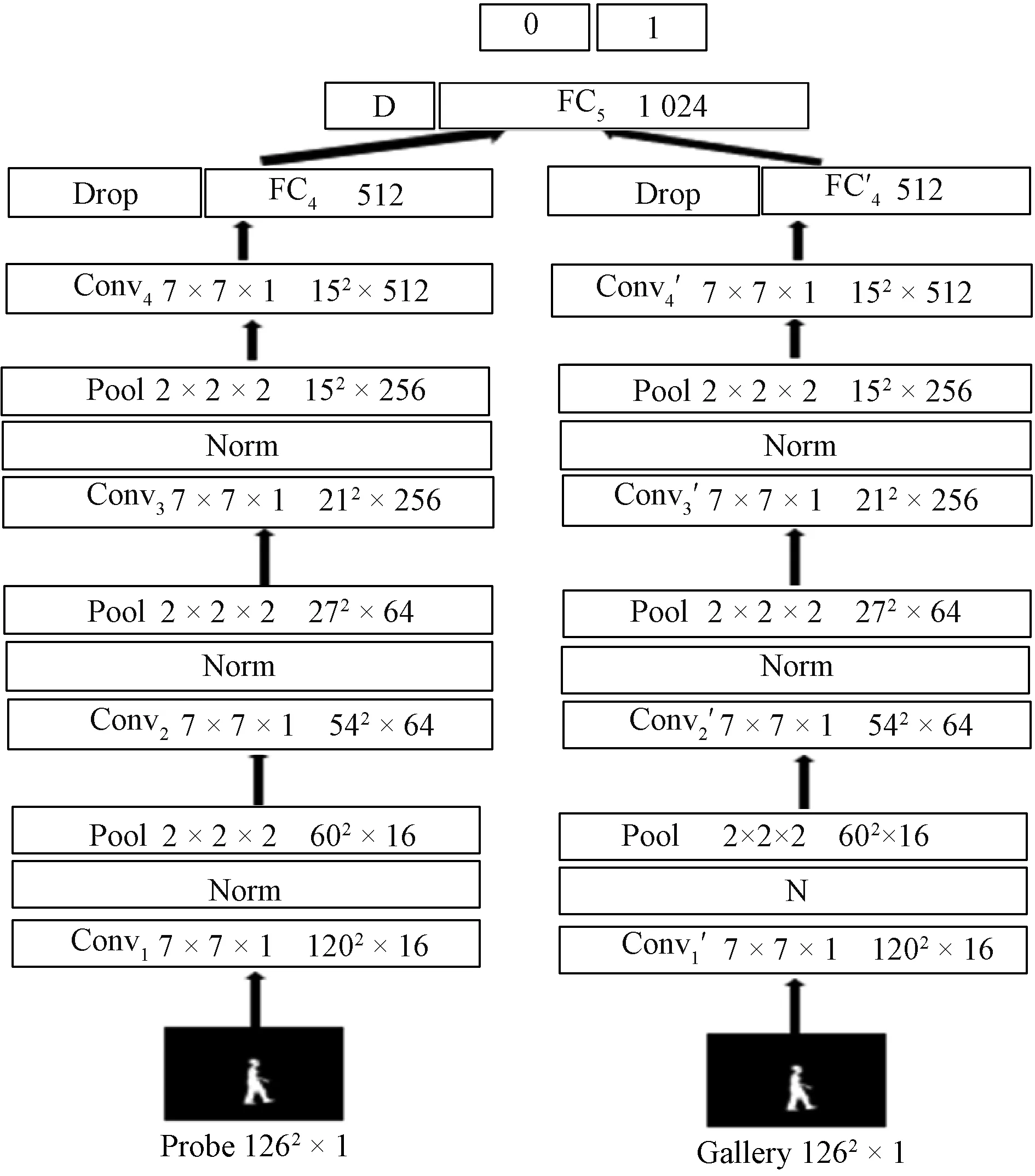
Fig. 4 NGaitNet recognition process
1.2 Data pre-processing
In this stage, the data are pre-processed before being fed into the NGaitNet. The resolution of the TIR image in the data (320×240 or 1 920×1 080) is too large compared with the input size (126×126) of the NGaitNet. Therefore, the TIR image has been resized and then optimized to obtain a skeleton from background modeling. Moreover, the data were pre-processed to make data smoother or less Pixelated for human gait recognition, as shown in Fig. 5.
1.3 Feature extraction process
Feature extraction is an important step in the gait recognition system. This work used the Gabor filter function[19]to detect the edges and extract gait features from a GEI[20]. The 2D Gabor filter obtains the optimal localization in the spatial and frequency domains, so it describes the local structure information of an image corresponding to the spatial scale, spatial location, and direction selectivity. The frequency and direction representations of a Gabor filter are close to those of the human visual system and are often used to represent and describe texture features in
(1)
Moreover, the GEI was normalized in a complete cycle[21]. The GEI is the average silhouette of a gait cycle. The random noise of the image sequence in the periodic process is suppressed in the process of averaging the image. The obtained average image is robust and contains rich static and dynamic information. To extract gait features from the GEI, it is defined in
(2)
whereNis the number of frames of the silhouette image in a period, andBt(x,y) is the gait silhouette at the timet.
Besides, gait features were represented from successive infrared thermal images by using the state-space method with a Hough transform technique. According to motion-based gait sequences and their classification, the state-space method represents the human gait from a series of fixed gait (or walking speeds). Moreover, non-overlapping clips of images are used for optimization, and the gait representation is suggested to describe gait signatures for recognition.
The feature extraction process involves six steps. Firstly, the TIR image is processed through Gabor filters by opening or closing-based grey-level morphological reconstruction (GMR)[22]to smooth intricate background clutter (or noise) while maintaining the human body and gait features. Secondly, the person's size (e.g., width and height) in an image is measured to determine a ratio that measures the number of pixels per a given scale. Thirdly, the processed image was divided into segments based on the human body's specific anatomical parts. Fourthly, the body-segment dimensions (e.g., the distances between the right leg and the left leg) for the Morphologic skeleton joint are calculated by using the Hough transform technique[23-24]to obtain the new representation of gait. Fifthly, the new representation (average of the silhouette sequences in one complete cycle) is projected onto the low dimension based on the principal component analysis (PCA). Finally, the joint and walking speeds are combined with the person's width and height and then used for gait analysis.
1.4 Gait recognition process
After computing the gait features, the resulting data stream was segmented according to its gait cycles for each data sample. Any single example contains only the data from a single gait cycle. Therefore, ak-nearest neighbor's rule is implemented to estimate an appropriate topology of the hidden Markov model (HMM)[25]for gait recognition. In the nearest neighbor's rule, the recognition task is performed by simulating the stereoscopic human body (silhouettes) of TIR images to match gait features based on multi-view walking speed points. The walking speed point is determined by temporal and spatial representations of a human's gait parameters. Gait recognition accuracy rate heavily depends on several factors, such as the resolution of the input image, landscape heterogeneity, design of the training set, the number and type of layers, hyper-parameters, and the number of iterations for training. In this method, the gait features extracted (hyper-parameters and model parameters) from a silhouette image are compared with those previously stored in the dataset to classify different gait patterns to predict pair similarity that indicates the same human identity, and then achieve the best results. The human image was classified based on walking speed points by applying the Sigmoid activation function in the classification layer to minimize the error function and maximize the margin between boundaries and data points for its identification. The main reason to use the Sigmoid function is that it exists from 0 to 1 to predict the probability as an output. Equation (3) defines the logistic Sigmoid function,
(3)
wherexis the input, andS(x) is the output.
2 Evaluation
To configure the experimental environment, powerful computing software (Python) was used on a GPU computer. GPU operates under Windows 10 Professional with 64-bit Operating System, Intel ® Core (TM) I5-6600 CPU @ 3.30 GHz, 3.30 GH, 16.00 GB RAM, NVIDIA GPU GeForce GTX 10701, and CUDA 9.0. First and foremost, we make sure that Python (version 3.7.6) is installed with some support libraries like Pytorch 0.4.0 (or above), Visdom 0.1.8.9, and OpenCV 4.2.0.34 (or above). The software enables the acquisition of TIR images, data processing, balanced sampling, and training the gait features extracted from those samples for recognition to achieve good results in night gait recognition.
2.1 Dataset
Many databases have been designed for human gait recognition research[26]. However, there is still a lack and unavailable (or dearth) of databases for night gait imagery containing a sufficient number of subjects and considering some critical factors influencing gait recognition algorithm performances. Therefore, two suitable thermal imaging gait databases were used to evaluate the performance of the TIRNGaitNet approach, in which template-based infrared images match efficient night gait recognition.
2.1.1DHUnightgaitdataset
A DHU night gait dataset is a thermal infrared database that consists of 6 500 video sequences filmed via an infrared thermo-vision camera to record TIR images for each person separately under different walking conditions at night[27,29]. All videos are filmed exclusively in indoor settings and include college and lab environments with a mix of stationary and moving cameras. The DHU night gait dataset contains 10 subjects (six males and four females), and an average of 650 images per person. There are about 10 different sequences of varying lengths, amounting to a total frame count of roughly 6 500. All sequences originate from camera filming in a 2D thermal image, with a resolution of 1 920 × 1 080 pixels, in the JPG type, which is mounted on a tripod at the height of 150 cm.
2.1.2CASIAinfrarednightgaitdataset(DatasetCorCASIAC)
In CASIA C, all images and videos (10 sequences of gait data) were recorded side-view outdoors at night using a thermal infrared camera with a resolution of 320 × 240 at a rate of 25 frames per second[28-29]. Therefore, each image in the dataset is only observed at a single angle (or sagittal). The CASIA C dataset contains 153 subjects: 23 females and 130 males. Each subject has four walking conditions: normal walking four times (fn00,fn01,fn02,fn03), slow walking two times (fs00,fs01), quick walking two times (fq00,fq01), and normal walking with a bag two times (fb00,fb01). Hence the total number of gait sequences becomes 1 530 sequences of gait data.
In the two-night databases, walking speeds within the identical sequences are still different for all subjects. Such dispersion impedes the modeling of walking speeds via the shifting feature space transformation. Therefore, it does not contribute to improving the performance of gait recognition. The reason lies in the dataset itself, which has not been designed to analyze walking speed changes. We carefully prepared data by choosing 10 different walking speeds under various walking conditions to avoid this problem. These speeds were selected with a high resolution corresponding to all subjects on the dataset in order to create balanced training samples. As a result, data sampling provides a better balance in the class distribution. In this method, the random over-sampling technique is used to balance an imbalanced classification dataset. This technique involves the simplest over-sampling method to randomly duplicate examples from a minority class in a training set. In the silhouette sampling process, each silhouette image is normalized to the same size of 126 × 126. Then, the size-normalized silhouette was projected in positive and negative diagonal directions, respectively.
Meanwhile, the maximum value of each direction is evaluated, indicating the maximum number of forwarding pixels along that direction in this frame. Moreover, two maximums are used to normalize the respective projections. We combined the two standard projections of human walking representation in the frame and referred to this representation as a silhouette training sample. Figure 6 illustrated the representation of the silhouette training sampling process.

Fig. 6 Silhouette's training sampling process: (a) a silhouette from the training set; (b) a silhouette normalization; (c) a silhouette training sample
To prepare balanced training samples, a dataset was distributed according to the 10 kinds of walking speeds as follows. 50% of the total dataset represents the training set that is used to fit the gait parameters (or weights) of the model. 26% of the dataset represents the validation set, which is used to predict the responses to the observations in the fitted model and provides an impartial assessment of a model fit on the training set when tuning the hyper-parameters (e.g., the number of hidden layers) in the network of the model. The remaining 24% of the dataset represents the testing set, which is a subset to test the trained model, and unbiased evaluation of a final model fit training set.
Furthermore, the method picks a randomized subject comprising all the subject-specific sequences (samples) with 10 kinds of walking speeds for training. Thus, 10 sequences of the gallery set and 10 different sequences for the probe set are used for training; six sequences of the gallery set and four different sequences for the probe set are used for validation. Likewise, the four sequences of the gallery set and two different probe set sequences are used for testing except for picking sequences. Finally, balanced training samples constitute more than half of the dataset (train and valid sets) and then are fed into the NGaitNet network to perform training.
2.2 Parameters and training
Any pair of silhouette samples in the training set is treated as one-channel input into the NGaitNet network to optimize the model. Moreover, several kernels (or cores) are used in each convolution layer to learn the gait features, starting with selecting the initial weights (0.5, -0.5) and then improving the weights later to adjust the pattern; thus, training and processing time is reduced. A combined gait asymmetry metric (CGAM)[30]is used to integrate human gait movements, synthesize and coordinate spatial, temporal, and kinematic gait parameters. There are two types of distinct parameters used to learn gait features, namely the hyper-parameters and model parameters.
(1) Hyper-parameters: they are parameters arbitrarily set by the user before training begins, for example, step length, step width, stride length, and foot angles. The hyper-parameter set aims to find the right set of their values, which can help find a minimum loss function or maximum accuracy. This can be especially useful in evaluating that the model is performing on a large dataset.
(2) Model parameters: they are parameters in the model that must be determined using the training set. These are the fitted parameters that have been learned during the training, such as neural network weights and linear regression. They are often used to estimate input data features to produce the desired output and are used for inference by tuning specific predictive modeling.
During training, walking-speed features are used as our performance parameters. First and foremost, the walking speed was determined for any video to all subjects in balanced training samples. Then, two silhouette frames with balanced training samples are uniformly taken from the video sequence to pass through the NGaitNet network. A separate interface is assigned to train the video clips relevant to all the subjects for each 10 different viewing walking speeds. The error is computed and re-propagated by applying it to each video clips' basic facts, with logistic regression loss. The weights are then updated, and a small frame (size of 126 × 126) is fed to the NGaitNet network with an optimizer learning rate of 0.000 1 for 10 000 iterations and decreases to 0.000 5 for the next 200 iterations to take advantage of the dual diminished learning rate for rapid convergence but momentum stable at 0.9. Besides that, the grey-scale silhouettes are fine-tuned to stereo images to create a new representation frame. These representations are created by stacking one image over the other and finding the difference between the two images at the pixel level. Hence the two video frames can be fed back-to-back to create a merged stereo image adjusted according to the training and validation results. Next, the deep CNN layers of NGaitNet automatically learn gait features from low-level motion parameters between adjacent frames rather than the gait sequence's periodic motion signal to fit non-linear boundaries for TIR images. After training, the network can represent temporal and spatial gait features in different layers and hierarchies to determine the later walking speed. This is near proportionate to the efficiency and the overall accuracy proposed for our network.
3 Experimental Results
The performance of the TIRNGaitNet is evaluated on different night gait databases. The training and testing process was automatically evaluated by remote connection to the Visdom server via running the command (pipinstallvisdom==server-id) on the Python console. Then, the learning curve and validation curve results are shown on the Visdom website. The learning curve (or training curve) shows the estimator's training and validation score for varying numbers of training samples. The training curve tool determines how much the model can benefit from additional training data and if the estimator suffers more from the variance error or a bias error. A good fit learning curve is identified by training and validation loss that decreases to a stable point with a minimal gap between the two final loss values. The model loss is almost always less on the training set than the validation set. This means that some gap is expected between the training iterations and the validation loss, which is referred to as the generalization gap.
Figure 7 shows the training curve of the TIRNGaitNet approach. This curve indicates that the validation loss (error) value gradually decreases (from 0.7 to 0) with increasing training iterations to reach the point of stability. In addition, the iteration is almost zero when it reaches 20 000 on the DHU night gait dataset and 200 000 on CASIA C. Therefore, the number of iterations was determined to be the best trial period (close to zero) to pause training and reach the ideal state. It is continued training of a good fit that will likely lead to an overfit.

Fig. 7 TIRNGaitNet training curve: (a) DHU night gait dataset; (b) CASIA C dataset
Besides, we evaluate the method according to the validation curve. In this curve, the accuracy ratePAis defined as the generated score while generalizing the class. It is represented as a percentage by
(4)
the model predicted true positive data points and was defined by the recallRin
R=Tp/(Tp+Fn),
(5)
precisionPtells about the model's positive data point, which can be calculated by
P=Tp/(Tp+Fp),
(6)
where p stands for positive; n stands for negative;Tprepresents the case of the person in true positive where the positive class is predicted as positive by the model;Tnrepresents the case of the person in true negative where a negative class is predicted as the negative by the model;Fprepresents the case of the person in false positive where a negative (0) class predicted as positive (1) class by the model;Fnrepresents the case of the person in false negative where a class is positive, but the model predicted the class as negative.
On both night databases, the gait recognition accuracy rates are measured under different walking conditions (e.g., normal, normal with a bag, quick, and slow). As a result, Figs. 8 and 9 show the accuracy validation curve for the TIRNGaitNet approach according to various probe and gallery walking-speed configurations.

Fig. 8 Accuracy rate for the DHU night gait validation set (gallery, probe): (a) normal walking (fn, fn); (b) slow walking (fn, fs); (c) quick walking (fn, fq)

Fig. 9 Accuracy rate for the CASIA C validation set (gallery, probe): (a) normal walking (fn, fn); (b) normal walking with a bag (fn, fb); (c) slow walking (fn, fs); (d) quick walking (fn, fq)
According to the training process's iterations, the model displays the sensitivity between changes in the accuracy rate with changes in some model's score parameters. Moreover, the score (metric) is weighted to balance each parameter's effect by normalizing the data for more equal weights. In all cases, the highest accuracy rate is taken as the maximum performance obtained in the specified walking condition.
During the testing, the trained model attempts to predict a new image by pre-processing the test image to identify the gait. To test a random sample, a sample walking speed is determined from the probe set tuned sequences and modeled with one of the trained data speeds from the walking sequence recorded in the gallery set. However, in each test case, the gait sequences recorded in the gallery must be at the same walking speed. The trained model is also used to independently predict each syllable's related topic within the voting system. The speed-based classification method and the feature-space transformation method received the most votes from clips and marked the final prediction. Next, the proposed method identifies the changing gait patterns' consecutive features to predict similarities between pairs that refer to the same human gait. Thus, the TIRNGaitNet method achieves a new result in gait recognition at night.
To better compare and analyze test results, we sometimes iterate the possible probe and gallery view walking speed to cover all the cross-view combinations. The energy efficiency resource standard (EERS) recognition rates are considered with a cooperative setting, as shown in Table 2. This table fixes the probe view speed and reports the average recognition rates while the gallery view speed varies. Besides, multi-view speeds of gallery and probe subjects (10 gallery views × 10 probe views) are the same among enrolled subjects in a collaborative setting.
Moreover, the proposed method's performance was evaluated in the thermal imaging databases. Table 3 reports the night gait recognition rates for the TIRNGaitNet approach compared with the other related methods on the same CASIA C dataset. The gait recognition accuracy rate of the TIRNGaitNet method (PA= 99.5%) is superior when compared with the GEI+ 2D locality preserving projections (2DLPP)[30]and frame-based classification[31]methods; however, it is less than the RSM (PA= 100%) and without RSM (PA= 100%) methods[32-33], especially with normal (fn,fn) walking conditions. The results conclude that the TIRNGaitNet approach achieves a slightly lower performance rate when the gallery and probe's walking speeds are the same. This is due to recognizing humans with differences in walking speeds between matching pairs (fn,fn) that cause a significant decrease in performance in gait recognition. Although different gait positions ((fn,fb), (fn,fq), and (fn,fs)) are making gait recognition furthermore challenging, the TIRNGaitNet approach succeeds in achieving the highest rate for gait recognition in different pairs of walking conditions. Hence, the accuracy rate increased to a maximum of 86.0% compared with the RSM method in the pair of normal and normal with a bag (fn,fb). Moreover, it also achieved a better accuracy rate (98.0%) in the pair of normal and slow walking (fn,fs) condition. In contrast, it has achieved less accuracy rate (94.0%) in the pair of normal and quick walking (fn,fq) conditions. It is concluded that the accuracy rate is improved when the walking is slow. Meanwhile, the accuracy rate decreases (somewhat satisfactory) under the quick walking condition. This is because it is difficult to calculate the distance between the legs (step) with slow walking.

Table 2 EERs of multi-view speed pairs for a cooperative setting

Table 3 Comparisons of recognition accuracy rates for the TIRNGaitNet method with those for other related methods on the same CASIA C dataset
On the other hand, the TIRNGaitNet approach was evaluated on the DHU night gait dataset, as shown in Table 4. This approach achieved a recognition accuracy rate of 97.0% when the gallery and probe's walking speeds were the same as (fn,fn). Meanwhile, it achieved 86.0% in (fn,fq), and 87.0% in (fn,fs), and no result was achieved in (fn,fb); because the DHU night dataset does not have subjects in normal walking with the bag.
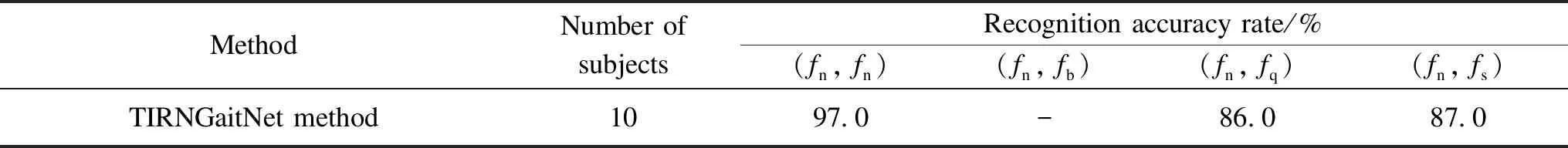
Table 4 Recognition accuracy rates for TIRNGaitNet approach on DHU night gait dataset
Besides, the proposed method's performance was tested by measuring subsets' effect to classify the gait mode classes for each subset,i.e., (fn,fb), (fn,fs), and (fs,fq). Table 5 shows the classification accuracy rates for subsets using two classes according to their body's dynamic velocity changes. On the CASIA C dataset, we adopted the gait period to classify normal walking (from 1 km·h-1to 3 km·h-1) and normal walking with a bag (from 6 km·h-1to 8 km·h-1), which was significantly changing the movement of dynamic body parts, especially when carrying the bag, and thus changing the walking speed accordingly. We also adopted the classification slow walking (from 1 km·h-1to 3 km·h-1) and quick walking (from 6 km·h-1to 8 km·h-1) conditions changed according to humans' speed walk. In contrast, we adopted the gait period to classify normal walking (from 1 km·h-1to 3 km·h-11) and slow walking (from 4 km·h-1to 6 km·h-1) conditions on the DHU night gait dataset, especially when the dynamic body of a person is changed according to movements of a person under slow walking condition. Besides, we adopted the classification of slow walking and quick walking when the person walks at different speeds.
Finally, it is concluded that the framework-based speed classification performance is evaluated on a big dataset (more TIR images) under different walking conditions. As a result, the TIRNGaitNet method achieves good performance based on different speeds and improves the results on the CASIA C and DUH night gait dataset.

Table 5 Correct classification accuracy rates for each subset by classifying the gait mode into two classes
4 Conclusions
This article has successfully performed the TIRNGaitNet approach with efficient network architecture for human gait recognition from thermal images at night. The approach aims to increase the accuracy rate for recognizing humans from their gait during night-time surveillances. The proposed NGaitNet is a new deep CNNs architecture to provide a trainable model for night gait recognition under various walking speed conditions. This network learns complex gait parameters (or features) extracted from TIR images. The performance was evaluated on the different night gait datasets based on multiple walking speeds at night. The gait recognition accuracy rates are updated on the different night databases. The experimental results indicate that the method achieves a satisfactory recognition accuracy rate on the CASIA C dataset under different walking conditions, especially under normal walking with a bag (98.0%) and slow walking (86.0%) conditions. Besides, the TIRNGaitNet approach provides a comprehensive experimental evaluation on the DHU night gait dataset, especially when many different videos of the same person under different walking conditions. The result indicates that the proposed method is robust and practical to recognize human gait at night based on multi-cross walking speeds, walking condition variations, and handling big data and process complex backgrounds. In the future, we will enhance our approach for monitoring at night by extracting more gait features under multi-view conditions to achieve higher accuracy rate.
 Journal of Donghua University(English Edition)2021年6期
Journal of Donghua University(English Edition)2021年6期
- Journal of Donghua University(English Edition)的其它文章
- Effect of Surface Energy of Electrospun Fibrous Mat on Dynamic Filtration Performance for Oil Particles
- Seam Damage Control and Image Analysis for Cuprammonium Fabrics
- Robust Waterborne Polyurethane/Wool Keratin/Silk Sericin Freeze-Drying Composite Membrane for Heavy Metal Ions Adsorption
- Textile-Based Capacitive Pressure Distribution Measurement System for Human Sitting Posture Monitoring
- Enhancing Accuracy of Flexible Piezoresistive Pressure Sensors by Suppressing Seebeck Effect
- Reduced Switching-Frequency State of Charge Balancing Strategy for Battery Integrated Modular Multilevel Converter