
Data Augmentation Based Event Detection
2021-12-21 05:51:08DINGXiangwuDINGJingjingQINYanxia
DING XiangwuDING JingjingQIN Yanxia
College of Computer Science and Technology, Donghua University, Shanghai 201620, China
Abstract: Supervised models for event detection usually require large-scale human-annotated training data, especially neural models. A data augmentation technique is proposed to improve the performance of event detection by generating paraphrase sentences to enrich expressions of the original data. Specifically, based on an existing human-annotated event detection dataset, we first automatically build a paraphrase dataset and label it with a designed event annotation alignment algorithm. To alleviate possible wrong labels in the generated paraphrase dataset, a multi-instance learning (MIL) method is adopted for joint training on both the gold human-annotated data and the generated paraphrase dataset. Experimental results on a widely used dataset ACE2005 show the effectiveness of our approach.
Key words: event detection; data augmentation; back translation; annotation alignment algorithm; multi-instance learning (MIL)
Introduction
In the automatic context extraction (ACE) event extraction program, an event is defined by a trigger word and described by a set of event participants (i.e., event arguments). This paper tackles the trigger identification task, namely event detection, which is a crucial component in event extraction. The goal of event detection is to identify event triggers and their corresponding event types from a given sentence. Event detection is modeled as a token-based classification task, which jointly identifies and classifies the event type of each token.
In recent years, most of the methods[1-2]are supervised models, which rely on human-annotated data to train the model, and most of them use the ACE2005 dataset. The performances of existing supervised methods in event detection are still not ideal. We blame the small scale of the existing labeled dataset for event detection, and the trained model does not understand the text well enough. The shortage of training data is a common problem when using deep learning to train models. There are two possible solutions for the challenge: hiring annotators to label more data, and adopting the distant supervision (DS) mechanism[3-4]to automatically label more data. However, the former costs lots of time and money, while the latter may result in a severe wrong labeling problem because of strong assumptions.
In this paper, a new solution is proposed to enlarge the scale of training data for event detection by automatically generating paraphrase sentences. Motivated by the recent success of deep neural networks in machine translation, a neural machine translation (NMT) system is adopted to generate possible paraphrase data via back-translation for each sentence in an existing event detection data. Back-translation is the procedure in which a system translates a sentence into another language, and then translates it back to the original language. However, the annotations of triggers are not conveyed during back-translation since word alignment information is unavailable. To solve the problem, a similarity-based annotation alignment algorithm is designed to align trigger words between human-annotated sentences and their corresponding paraphrase sentences. The human-annotated sentences combined with these paraphrases are regarded as new training data, which is called event detection paraphrase(EdP) data.
A joint learning method is proposed to train a neural model on the EdP data. To reduce the effect of possible noises in the paraphrase data, a multi-instance learning module is used to filter high-quality paraphrase sentences. A convolutional neural network (CNN) is adopted for feature extraction.
An event detection paraphrase data are built and labeled as the generated paraphrase dataset to express the information of event triggers. In the EdP data, there are 6 325 paraphrase sentences and 6 325 human-annotated sentences. The generated paraphrase data will be released for free download for research purposes. A joint learning method is proposed to train the model on the EdP data. To reduce the effect of the noise, a multi-instance learning method is proposed for weighting paraphrase sentences. Experimental results show that the proposed data can improve the performance of neural-based event detection models.
1 Related Work
Event detection is an important task in information extraction. Traditional feature-driven event detection methods rely heavily on hand-craft features such as syntactic and semantic features, which face laborious feature engineering and error propagation of some natural language processing tools. In recent years, with the development of neural networks, the neural models for event detection significantly advance the task. Some researchers firstly use a CNN for event detection[1]. This work is in line with neural-based event detection methods with a CNN model. Besides, there are also some work useing long-short term memory network (LSTM)[5-6]and graph convolutional network (GCN)[7-8]models for automatic feature extraction.
In addition to the development of models for feature representation, studies on generating additional event detection data from an available small-scale human-annotated dataset (e.g., ACE2005) are also popular. Distant supervision (DS) is proposed to automatically build labeled data from existing resources such as FrameNet[4]and Freebase[3,9]. Though distant supervision can help to generate large-scale labeled data, the quality of generated data is unsatisfying because of occurrence of a trigger word which may not indicate the occurrence of an event in a different context. Different from labeling data from extra unlabeled data resources in DS, the data augmentation technique is widely used to generate labeled data from existing labeled data. Wei and Zou[10]proposed four data augmentation techniques (random insertion, deletion, swap, and replacement) for boosting performance on text classification. Kobayashi[11]proposed to stochastically replace words with other words and retrofit a language model with a label-conditional architecture to augment labeled sentences. Yuetal.[12]generated paraphrase data with back-translation for improving relation extraction. Data augmentation techniques are uesed to generate labeled event detection data in order to ensure that generated data are in similar data distribution with original labeled data.
There is also some work to explore the effectiveness of data augmentation in event detection. Yangetal.[13]proposed to generate labeled event extraction data by rewriting non-trigger words with the cloze task of bidirectional encoder representations from transformers (BERT) and replacing argument with similar phrases. Luetal.[14]proposed to paraphrase labeled sentences with the English resource grammar (ERG) method and the sentence compression technique. None of them have explored data augmentation techniques on Chinese event data for Chinese event detection. In this paper, a simple and effective back-translation technique is proposed to generate paraphrase sentences for ACE2005 data, which improves the performance of the event detection model.
2 EdP Data
In this section, we will describe how to build the EdP data, which is a task-specific paraphrase data of event detection. As shown in Fig. 1, the EdP data is constructed by generating paraphrase sentences for human-annotated sentences from an existing event detection corpus via back-translation and labeling the paraphrase sentences. Our EdP data contains two parts: EdP-GOLD and EdP-AUTO. EdP-GOLD is the original training set of the existing ACE2005 dataset, and EdP-AUTO is the paraphrase data generated automatically. CN indicates Chinese, and EN indicates English. An example of EdP data is shown in Fig. 2, where case 1 is a human-annotated sentence and case 2 is a paraphrase sentence. Words with underlines are triggers.
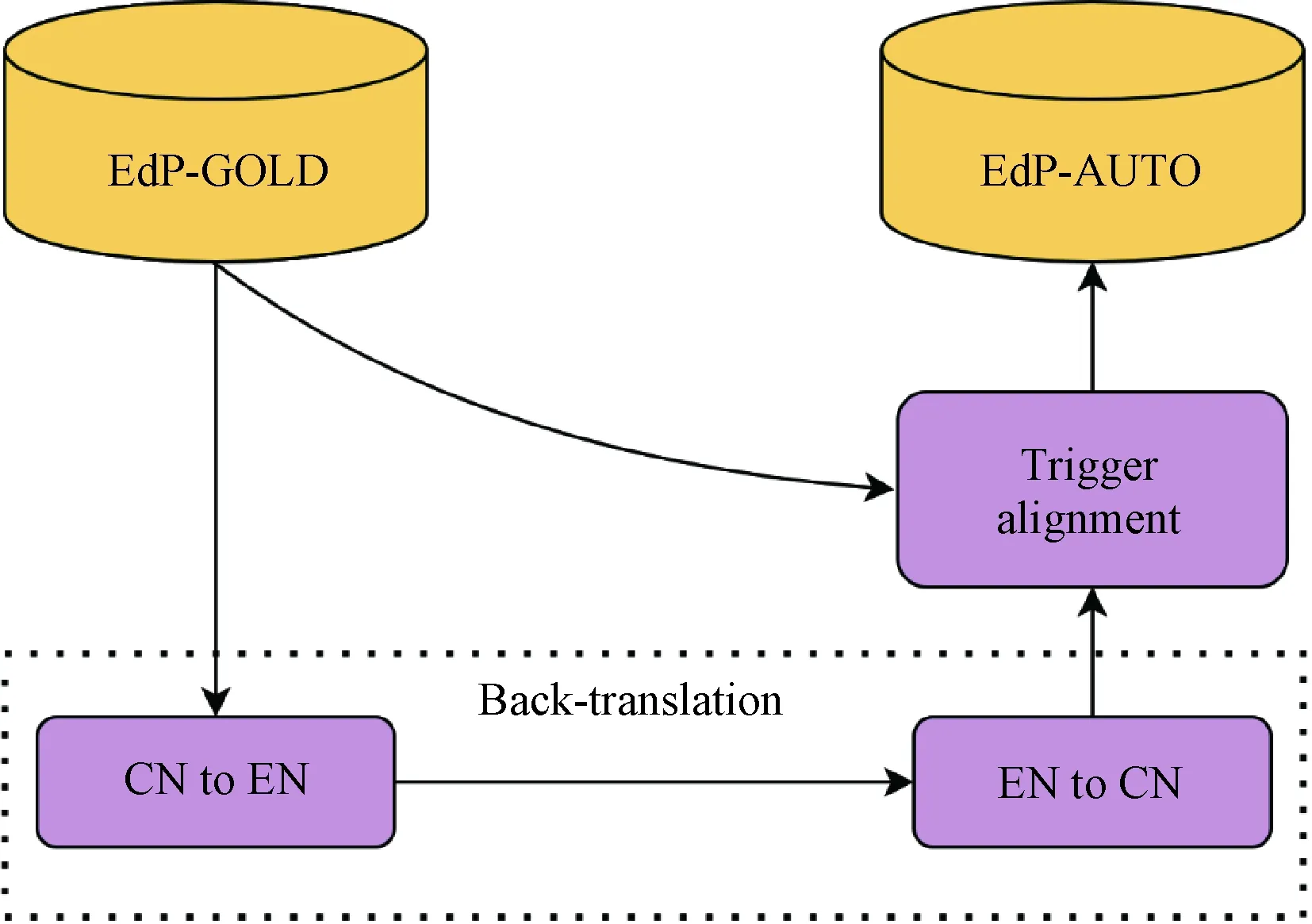
Fig. 1 Framework of building the event detection paraphrase data

Fig. 2 An example from EdP data
2.1 Human-annotated data
In this paper, the ACE2005 Chinese dataset is taken as our human-annotated data. It contains 6 325 sentences in total, and 5 045 sentences are used as the train set, 650 sentences as the development set, 630 sentences as the test set. Word segmentation is conducted as the first pre-processing step as we use Chinese words as tokens to be classified for event detection. ACE defines 8 event types and 33 subtypes, such as “die” and “attack”. Event detection is defined as a 34-class (33 event types and none) word-level classification task. Statistics of ACE2005 are shown in Table 1. Although there are more than 5 000 sentences in the train set, only 1 500 of them are positive sentences containing at least one trigger. Therefore, generating a paraphrase expression for each annotated sentence can enrich the original annotation data.

Table 1 Statistics of EdP data
2.2 Generating event detection paraphrase sentences
Back-translation method is utilized to help us automatically generate paraphrase sentences. Back-translation is an effective method to augment parallel training corpus in NMT[15]. After obtaining the paraphrase data, we face the problem of labeling triggers in the data. Most of the generated paraphrase sentences and original sentences have different tokens and sentence structures, which means that we can not convey the annotations of triggers during back-translation since word alignment information is unavailable. As shown in Fig. 2, the trigger "到" (went) in the original sentences should be aligned with "前往" (went) in the paraphrase sentences and the trigger "创办" (set up) should be aligned with "成立" (set up).
2.2.1Back-translation
Back-translation is a process of translating sentences from a source language into a target language, and then backing into the source language again. In this paper, the source language is Chinese, and English is utilized as the target language. To perform back-translation, the paper adopts a public NMT system: Baidu translation. As a result, we can obtain sentence pairs consisting of original sentences and their paraphrase sentences.
2.2.2Annotationalignmentalgorithm
In this paper, the purpose of annotation alignment is to find triggers in the paraphrase sentences and identify their event types. The input is an original sentenceSori, its labelsLoriand its paraphrase sentenceSpara. The output is the paraphrase sentence labelsLpara. Details of the proposed algorithm are shown in Fig. 3. TraverseSoriandLorito locate triggertori, and its event typelori. Calculate the similarity of the triggertoriand each wordwinSpara, as shown in Fig. 4. When searching for triggers, the Word2vec model is adopted trained on Wikipedia data set to calculate the cosine similarity oftoriandw. The similarity threshold empirically is set to 0.5. To be noted, if a word is an out-of-vocabulary word, the similarity value of the word and other words is set to -1.

Fig. 3 Annotation alignment algorithm

Fig. 4 An example of aligning trigger words
2.2.3StatisticsoftheEdPdata
An NMT system is adopted to get a paraphrase for each sentence in ACE2005. Please note that in the following experiments, the paraphrase sentences are not used generated from the test set data. The statistical data of EdP is shown in Table 1. The EdP data contains 5 045 human-annotated sentences as EdP-GOLD and 5 695 paraphrase sentences as EdP-AUTO, which contains paraphrase sentences for sentences in both the training and development sets of ACE2005.
3 Event Detection Model Based on Data Augmentation
This section introduces the event detection model first, and then two schemes use both the EdP-GOLD and the EdP-AUTO sets for model training.
3.1 Basic event detection model
In this paper, event detection is formulated as a multi-class classification task on each token of a sentence. The basic model consists of three parts: an embedding layer to convert each token into a low-dimensional real value vector, a neural module for automatic feature extraction for the vector, and a softmax classifier to determine its event type.
The embedding layer represents each token with both word embedding and position embedding. Word embedding is used to represent a token's semantic and syntactic information, and position embedding is used to express the relative position relationship between tokens and a candidate trigger. Unsupervised pre-trained word embedding is adopted to initialize word embedding. Position embedding is initialized randomly. Both embeddings are updated during the training process.
After representing each token with the concatenation of its word and position embeddings, a convolution module is used to extract its context information. The module consists of a convolutional layer and a max-pooling layer. Each token's contextual representationLis fed into a classifier to identify its event type. The classifier can be expressed as
O=softmax(WL+b),
(1)
whereWis a weight matrix,bis an offset term. The output vectorOrepresents the prediction probability of different event types. The probability of candidate trigger wordtbeing typejis shown in
P(j|t,θ)=Oj,
(2)
whereθis all the model parameters. ForNtraining instance pairs (yi,xi), the maximum log-likelihood function objective is used to train the model, as shown in
(3)
3.2 Model training based on EdP data
To effectively use the EdP dataset to improve the performance of event detection, two different training strategies are used to train the event detection model with both EdP-GOLD and EdP-AUTO datasets.
3.2.1Mixturedata
In the first method, the generatedMsentences are regarded as real annotation data, and this paper simply mixes the generatedMsentences in EdP-AUTO data withNsentences in EdP-GOLD data. The maximum objective function during training is shown in
Laugmentation=
(4)
3.2.2Multi-instancelearning
The second method is to adopt the idea of multi-instance learning[3, 16]for using paraphrase sentences, considering that the neural machine translation system may have translation errors and there are inevitable annotation alignment errors. To make full use of the paraphrase sentences in EdP-AUTO to relieve the translation or annotation noises, multi-instance learning method is used to assist model training.

(5)
wherenis the number of event types. And the objective of multi-instance learning is to discriminate bags rather than instances. Thus, the objective function of the bags is defined. Given all (T) training bags (Mi,yi), the objective function is defined by cross-entropy at the bag level as
(6)
whereλis a weight, andjis constrained as
(7)
As shown in Fig. 5, the objective function is trained based on EdP-GOLD data and the multi-instance objective function based on EdP-AUTO data for computing the network parameterθ. The paper maximizes the log-likelihoodLMILandLbasethrough stochastic gradient descent.

Fig. 5 Training framework
4 Experiments
4.1 Data and experimental settings
4.1.1Dataandevaluation
For baseline systems, the EdP-GOLD is used for training. For other experiments, the EdP is adopted for training. The development set of ACE2005 is used for parameter tuning and the test set is used for evaluation. Statistics of ACE2005 and the EdP data are described in Table 1. The 10-fold cross-validation is used in our experiments to eliminate data selection bias by using a fixed randomly selected test set[17]. Standard micro-averaged precision rateP, recall rateR, and comprehensive evaluation indexF1 are used as evaluation metrics. This paper uses evaluation settings the same as Chen and Ji[18].
4.1.2Hyper-parametersettings
For CNN parameters, the window size is set to be 2, and the number of the feature map as 200. The batch size is set to 100, the learning rate is 0.1, and the training epoch number is 200. The size of the word embedding is 200. To avoid overfitting, a dropout mechanism is used in the system, and the dropout rate is set to 0.3. The best model is selected by early stopping using theF1 values on the development set.
4.1.3Tuningofλ
Theλis tuned in Eq. (6) in the range of [0.01, 0.02, 0.03, 0.04, 0.05] on the development set. As shown in Table 2, the system withλ= 0.04 achieves the best performance. This also ensures that EdP-GOLD dominants the loss and EdP-AUTO is an auxiliary when we update the model parameters. Hence, theλis set to be 0.04 in the following experiments without an explicit statement.

Table 2 Results of tuning λ
4.2 Experimental results
4.2.1Comparisonwithpreviousmodels
Our model is compared with several previous methods. The baseline models are as follows.
(1) Dynamic multi-pooling convolutional neural networks(DMCNN)[1]put forward a dynamic multi-pooling CNN as a sentence-level feature extractor.
(2) Hybrid neural network(HNN)[19]designed a hybrid neural network model which incorporates CNN with Bi-LSTM.
(3) Hierarchical and bias tagging networks with gated multi-level attention(HBTNGMA)[20]put forward hierarchical and bias tagging networks to integrate sentence-level and document-level information collectively.
(4) Rich linguistic features networks(Rich-C)[21]were a traditional event detection system with rich linguistic features, including semantic role tagging, trigger word probability, zero pronouns, trigger word consistency, and so on.
The results are shown in Table 3. DMCNN performs better than CNN, and our model with CNN trained on EdP data(CNN+EdP) performs better than DMCNN by 1.24%, which shows the effectiveness of our method. Compared with HBTNGMA, CNN is higher by 4.26%. The result of the CNN model trained on EdP data is higher than that of HBTNGMA by 7.95%. The result of CNN+EdP is lower than that of HNN. Our view is that HNN reserves only 10% of the annotated data for testing and uses the rest for training. However, a more robust evaluation is provided via performing 10-fold cross-validation experiments in our system. The result is lower than that of Rich-C. The reason is likely to adopt rich linguistic features used in Rich-C.
4.2.2Resultsbyusingdifferenttrainingdata
The effectiveness of our generated paraphrase data is evaluated on a fixed CNN model. Experimental results are shown in Table 4. Firstly, the experimental result using only paraphrase sentences (EdP-AUTO) performs worse than the baseline of using human-annotated data. The reason might be that the noise in the EdP-AUTO harms the performance. After the whole EdP data is adopted, namely EdP-GOLD + EdP-AUTO, by directly merging them, we observe a higher increasingF1 (3.16%) than the baseline in trigger classification. This indicates that our proposed paraphrase data can improve the performance of event detection. In further, after multi-instance learning method (EdP-GOLD + EdP-AUTO+MIL) is applied on paraphrase sentences instead of direct merging, we observe a further performance improvement. This shows that the MIL strategy can alleviate the noise of EdP-AUTO data. In summary, EdP-GOLD + EdP-AUTO+MIL yields the best performance among all the settings.
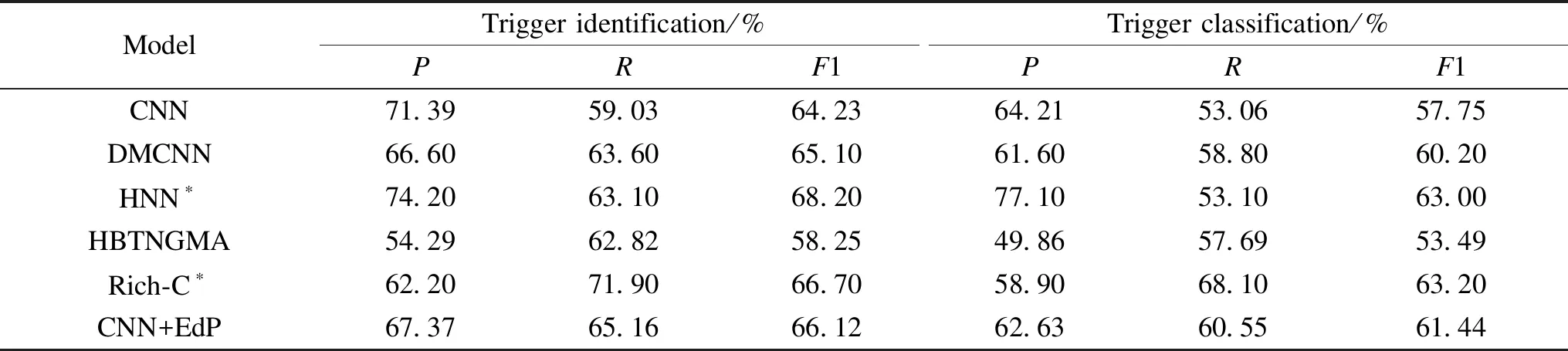
Table 3 Experimental results on ACE2005

Table 4 Comparison with baseline on test set
4.2.3Analysesanddiscussion
Here, this paper explored whether the generated paraphrase data can increase the model's understanding of the text. The following three cases are tested: no paraphrase data is added; the paraphrase sentences with trigger words are added; all paraphrase data are added. The results are shown in Table 5, CNN*means that the paraphrase sentences with trigger words are added to the training data set. CNN+ means that all paraphrase data are added to the training data set. The experimental results show that the paraphrase data with trigger words can improve the performance of the model, and the paraphrase data without trigger words are also helpful to the task. TheF1 value of the trigger words identification task increases by 1.99%, and theF1 value of the trigger classification task increases by 3.37%, which can be explained as increasing the diversity of text expression and making the model understand the text more deeply.
As shown in Fig. 6, the trigger word is wrongly predicted as non-trigger by the baseline, while our model predicts it as a trigger and outputs the correct event type. The reason is that the trigger "设立"(set up) in case 1 is generated the trigger "成立" (set up) in case 2 by back-translation, which is likely to predict correctly the trigger "成立" (set up) after our model trained in paraphrase sentences.

Table 5 Analysis of influence of paraphrase sentences

Fig. 6 Influence of paraphrase sentences addition on model prediction
5 Conclusions
The back-translation technique is proposed to generate paraphrase sentences of ACE2005 data for enriching the existing data expressions. An annotation alignment algorithm is proposed for labeling triggers in the generated paraphrase sentences. To reduce the effect of noises in the paraphrase data, a multi-instance learning module is proposed to use high-quality paraphrase sentences. The experimental results show that our approach is effective to improve the performance of event detection.
 Journal of Donghua University(English Edition)2021年6期
Journal of Donghua University(English Edition)2021年6期
- Journal of Donghua University(English Edition)的其它文章
- Strain Pseudomonas putida PAO-1 Isolate with Polyphosphate Accumulating and Elongation Ability
- Theoretical Model on Transformation Factors of Scientific and Technological Achievements under the Belt and Road Initiative
- Exploitation of Waste Heat from a Solid Oxide Fuel Cell via an Alkali Metal Thermoelectric Converter and Electrochemical Cycles
- Gait Recognition System in Thermal Infrared Night Imaging by Using Deep Convolutional Neural Networks
- Feature Fusion Multi_XMNet Convolution Neural Network for Clothing Image Classification
- Reduced Switching-Frequency State of Charge Balancing Strategy for Battery Integrated Modular Multilevel Converter