
基于改进SSD和Jetson Nano的口罩佩戴检测门禁系统
2021-12-14 06:16毛晓波徐向阳魏刘倩刘玉玺董梦超焦淼鑫
郑州大学学报(工学版) 2021年6期
毛晓波, 徐向阳, 李 楠, 魏刘倩, 刘玉玺, 董梦超, 焦淼鑫
(1.郑州大学 电气工程学院,河南 郑州 450001; 2.郑州大学 机械与动力工程学院,河南 郑州 450001)
0 引言
佩戴口罩是人们保护身体健康的简单而有效的途径,而人脸佩戴口罩的智能识别可以高效监督人们是否佩戴口罩,是抑制疾病传播和降低损失的重要技术手段[1]。针对该问题,有以下3类检测方法。
第1类是基于深度学习的方法。特点是将图像送入计算量很大的卷积神经网络,再加上各种后处理,能够检测到复杂环境中的人脸是否佩戴口罩,检测精度高但速度慢。Tang 等[2]提出了PyramidBox检测算法,该算法是一种上下文辅助的单阶段检测算法,设计了一种新的锚点(anchors),将高低维特征融合在一起。Tian 等[3]先检测人脸,再使用Attention机制关注口罩区域,以判定是否佩戴。有学者提出了使用k-means聚类算法生成若干个Anchors Boxes,再结合YoLo-V3网络检测人脸是否佩戴口罩[4-6]。管军霖等[7]提出了基于CSP-Darknet53的YoLo-V4检测框架检测人脸是否佩戴口罩。陈国特等[8]提出了先检测人头信息,再用Restnet34和Softmax进行分类。但两级检测网络降低了检测速度。
第2类是基于传统的图像检测方法进行检测。该方法对输入图像要求严格,不能掺杂多余的背景区域,也不能检测1张图像中的多个人脸,并且在面对门禁通道中排队的情况时,无法提取队伍队首人脸图像(因为门禁系统开门与否由排队队伍队首的人是否佩戴口罩决定),检测速度快,但检测精度低。金钰丰等[9]提出了将人脸关键点和口罩纹理等特征相结合的方法检测行人是否佩戴口罩。杨子扬等[10]提出了将RGB色彩空间转换到YCrCb色彩空间,并结合二值化等传统的图像处理方式,判断上半部分人脸和下半部分人脸像素平均值的异同,从而判定行人是否佩戴口罩。此检测方法遇到的挑战是人脸和口罩颜色接近时很难判定。
第3类方法主要是检测模式的创新,特点是现场图像采集工作线下进行,图像处理工作线上进行。李超等[11]提出树莓派和云平台联合进行工作的模式,即利用嵌入式设备采集图像,然后将图像上传至云服务器进行检测并返回检测结果。该类方法需要稳定快速的网络、高性能的GPU服务器集群,成本很高,且结构复杂、延时大,降低了系统的鲁棒性。
本文构建了一个大型数据集,并对其进行数据增强,且将SSD[12](single shot multibox detector)目标检测框架中的特征提取网络VGG[13]替换为轻量化的特征提取网络MobileNet-V3[14],使之适用于计算能力有限的边缘计算系统。本文设计了平行四边形连杆折叠结构的挡板,便于安装和部署,兼具广告信息播放功能,最终构成一个完整高效的门禁系统。
1 神经网络模型设计及训练
1.1 数据标注及预处理
由于口罩数据集少且佩戴场景多元化[15],因此本文选择开源、权威的MAFA和WIDER FACE这2个数据库的部分图片,每1张均包含戴口罩的和未佩戴口罩的人脸,并且规定未戴口罩的人脸数据标签为face,佩戴口罩的人脸数据标签为face_mask,大约8 000张图片数据,其中训练数据6 000余张,测试数据约2 000张。训练数据标注示例如图1所示。

图1 数据标注示例Figure 1 Example of data annotation
由于SSD是密集采样算法,所以数据增强是SSD目标检测算法中的重要环节,使用数据增强的训练模型明显优于未使用数据增强的模型[12]。数据增强包括随机扩展、随机颜色空间模型变换(HSV和RGB模型)等内容。其中,随机扩展可以显著提高SSD算法对小目标的检测能力,如图2所示。图2(a)为原始标注图像,图2(b)和2(c)为随机扩展的2种随机效果示意图。其他变换可以有效应对尺寸变化、光线变化等问题,具有很好的鲁棒性和泛化性能。魏宏彬等[16]用均值聚类算法对标注框进行聚类,得到合适的先验框宽高比例。

图2 随机扩展Figure 2 Random expansion
1.2 原始特征提取器
原始SSD使用的是在ImageNet上预训练好的VGG[13]模型,并且替换掉了VGG模型中的全连接层,改用全卷积层,最后又添加了一些新的卷积层,继续提取图像特征。以SSD300_VGG(300表示输入图像的尺寸为300×300×3)为例,其选用的6个特征图的具体信息如表1所示,每一层特征图上的先验框尺寸为
(1)
式中:sk为第k个特征图上先验框的最大尺寸占原始图像边长的比例;smin、smax均为超参数,取值分别为0.2、0.9;m表示选取的检测特征图的数量减去1;k为特征图的序号。
从表1可以得出,6个特征图上先验框总数为8 732个。每个先验框都具有一个类别得分和相应的坐标,SSD目标检测算法的任务就是找出包含这2种目标的先验框,并给出正确的类别。原始SSD目标检测框架如图3所示。
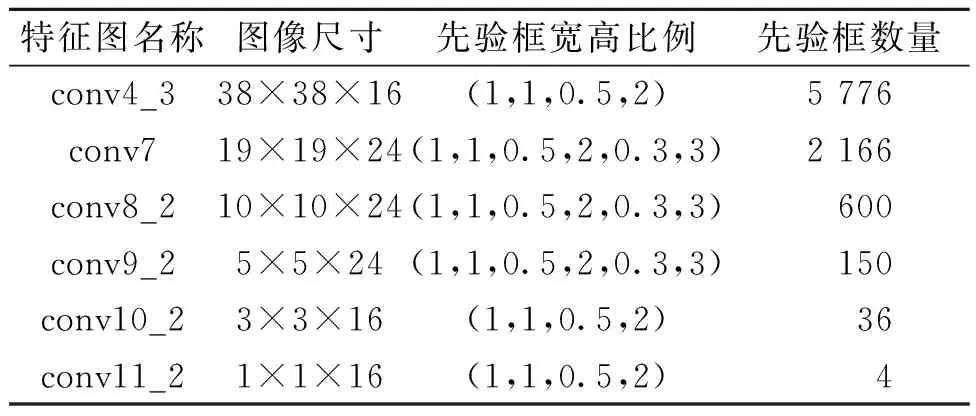
表1 SSD300_VGG特征图具体信息Table 1 Specific information of SSD300_ VGG feature map
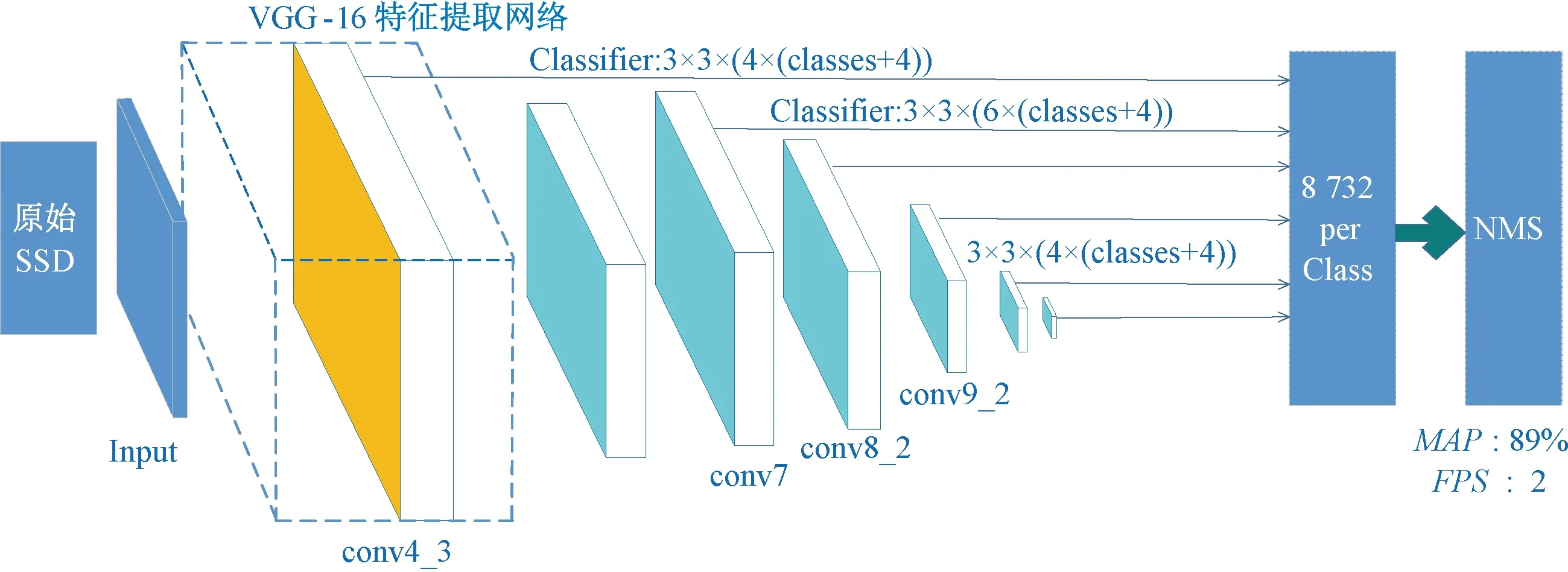
图3 原始SSD目标检测框架Figure 3 Original SSD object detection framework
1.3 改进的特征提取器
由于VGG卷积层多、运算速度慢,因此,本文将其替换为适用于移动端运行的轻量化特征提取网络MobileNet-V3[14](输入图像的尺寸为320×320×3),相比于原始SSD采用的VGG网络,模型大小从201 MB减至29.9 MB,约为原始模型大小的1/7。MobileNet-V3(Large)模型有19层,第2~15层为集成模块(bneck模块),按顺序包含2D卷积层、BN层、H-Swish激活函数层、SE(squeeze and excite)层[17]、2D卷积层、BN层,如图4所示。
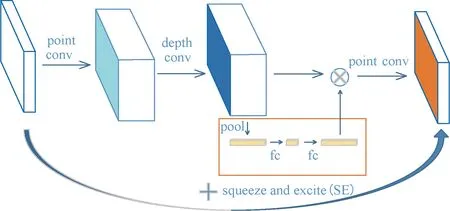
图4 MobileNet-V3特征提取网络的bneck模块Figure 4 The bneck module of MobileNet-V3 feature extraction network
但是将其嵌入到SSD目标检测框架中,就需要移除一些只适用于分类任务的层。这里移除MobileNet-V3(Large)中的第17层及以后的层,并在其后添加4层bneck,共20层,为SSD提供不同尺度的检测特征图,称为MobileNet-V3-SSD,如图5所示。尽管其具有更多的卷积层,但每层都经过了精心设计,加入了深度可分离卷积、倒置的残差结构、轻量级的注意力机制、利用H-Swish代替计算量巨大的Swish激活函数等。深度可分离卷积将标准的卷积核进行分解,减少了计算量,提高了训练推理速度。例如,输入特征图的通道数为M,卷积核数量为N,卷积核尺寸为DF×DF,输出特征图尺寸为DO×DO,则使用普通卷积的计算量G为
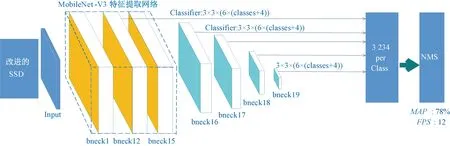
图5 MobileNet-V3-SSD目标检测框架Figure 5 MobileNet-V3-SSD object detection framework
G=DF×DF×M×N×DO×DO。
(2)
使用深度可分离卷积的计算量H为
H=M×(DF×DF×1)×DO×DO+
N×(1×1×M)×DO×DO。
(3)
G和H的比值为
(4)
在深度学习中,N一般为32、64、128、256、512、1 024等,DF2一般为1、4、9,因此,式(4)的值通常远大于1,即:普通卷积的计算量比深度可分离卷积的计算量高得多,因而深度可分离卷积的运算速度比普通卷积快得多。
此网络结构中选择的特征图的具体信息如表2所示。其中,先验框的总数为3 234,远少于表1中的总数8 732,这就为训练和推理速度的提高提供了理论基础。

表2 SSD320_MobileNet_V3特征图具体信息Table 2 Specific information of SSD320_MobileNet_V3 feature map
这6个特征图上的先验框的最小、最大尺寸按照式(1)计算。将计算得到的sk与输入图片的尺寸相乘,即可得到该层特征图上的先验框的最大尺寸。在特征图bneck12中先验框的最小尺寸选择32,最大尺寸由式(1)计算可得64,特征图bneck15~bneck19中先验框的最小/最大尺寸分别为64/109、109/154、154/198、198/243、243/332。
1.4 训练编码
值得注意的是,SSD算法并不是对目标框的位置进行直接输出,而是对其进行编码(offset):
(5)
式中:lcx、lcy分别表示编码后的预测边界框位置信息的中心坐标的横、纵坐标;bcx、bcy分别表示预测边界框的中心坐标的横、纵坐标;dcx、dcy分别表示先验框的中心坐标的横、纵坐标;dw、dh分别表示先验框的宽、高;vw、vh为超参数,其值均为0.2;lw、lh表示编码后的预测边界框位置信息的宽、高;bw、bh表示预测边界框的宽、高。
1.5 损失函数
为了使网络能够进行端到端的训练,也需要将标注好的Ground Truth按照式(5)进行编码。
SSD的损失函数是一种联合损失函数,即将分类损失和定位损失求和,同时进行反向传播,优化相关参数。由于交叉熵损失函数能够准确表达2个概率分布之间的关系,因此这里采用交叉熵损失函数求得分类损失,交叉熵损失函数为
(6)
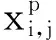
由于正负样本数量相差很大,若让所有的负样本损失全部参与反向传播、更新梯度是不合理的,因为这会淹没为数不多的正样本损失。因此,SSD采用了难负样本挖掘技术,即:将负样本的损失按照大小降序排列,只取前面一部分损失最大的负样本。负样本损失的具体数量则根据正样本个数来确定,一般选择正样本个数的3倍为宜。其中,正负样本的划分规则:若先验框与Ground Truth的交并比IoU≥ 0.5,则将此先验框划分为正样本,反之划分为负样本。IoU为
(7)
式中:A为标注框;B为先验框。
对于定位损失,采用SmoothL1函数,将编码后的矩阵与网络输出矩阵的相应位置作差,将差值x作为SmoothL1的自变量,然后输出结果作为定位损失。
(8)
不同于分类损失的是,定位损失中不含有负样本定位损失,因为负样本是背景,定位没有意义。
1.6 网络训练
训练采用的深度学习框架为Pytorch(1.6)、torchvision(0.7.0),其他的依赖包为yacs、tqdm、opencv-python、vizer、tensorboardX、six等,在Ubuntu 18.04 LTS、电脑配置为Intel(R) Xeon(R) Gold 5218 CPU @ 2.30 GHz,GeForce RTX 2080ti GPU下,设置batch_size为32,初始学习率为0.01,在第10 000次迭代和第20 000次迭代时减小学习率,每次迭代学习率缩小为前一次学习率的1/10,采用SGD优化器,Gamma值为0.1进行网络训练,总训练次数为25 000次。
2 结果分析
目标检测模型性能的主要评价指标包括:平均精度均值MAP和FPS(每秒处理的图片数量)。MAP随迭代次数而变化的曲线如图6所示。MAP值等于每个类别的Precision-Recall曲线所围成的面积:
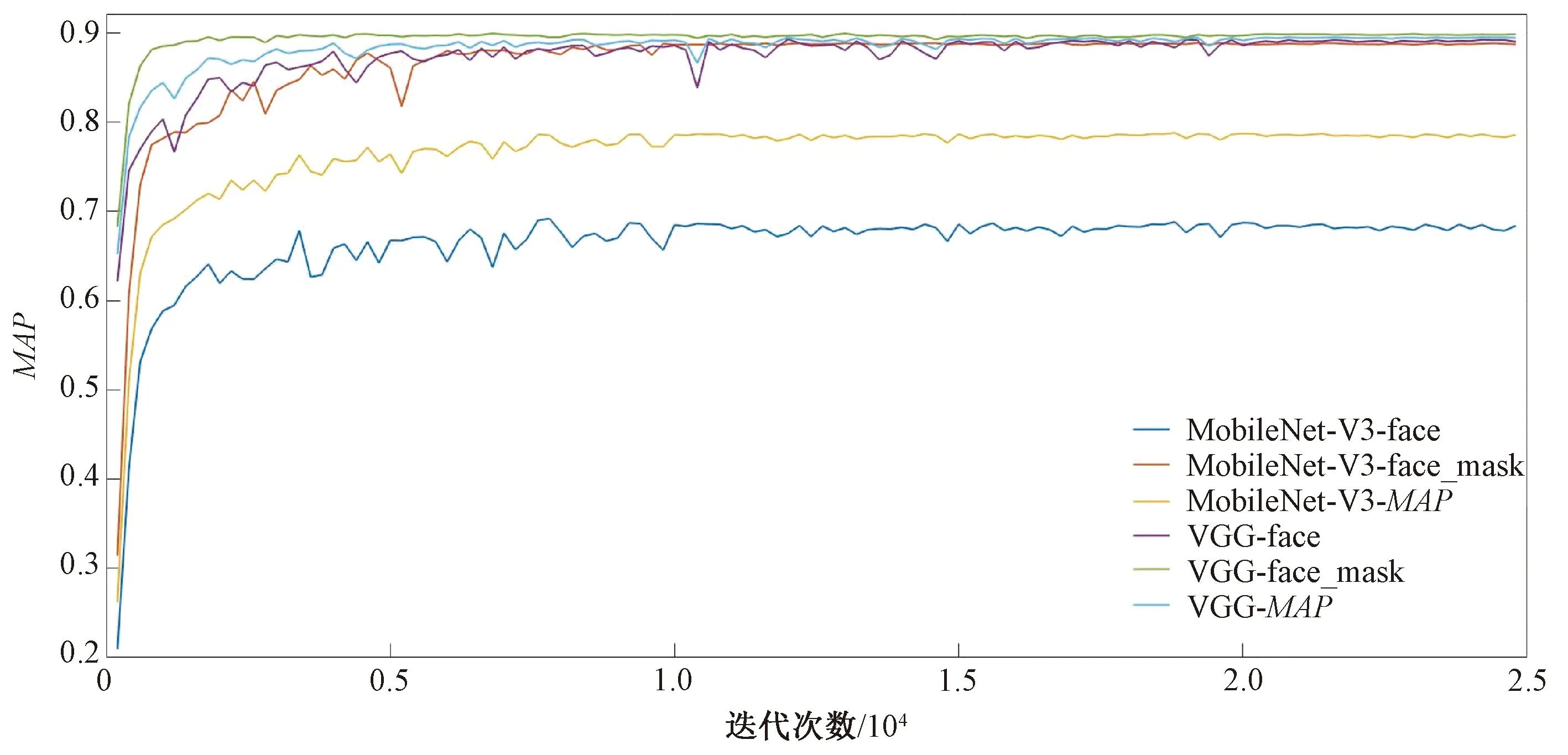
图6 MAP随着迭代次数而变化的曲线Figure 6 Curve of MAP changing with the number of iterations
(9)
式中:TP指预测为正样本实际为正样本的数量;FN指预测为负样本实际为正样本的数量;FP指预测为正样本实际为负样本的数量[18]。
模型改进前后,不同检测网络的算法性能结果如表3所示,推理速度测试环境为Jetson Nano开发板。在表3中,MAP指综合MAP,即戴口罩人脸和不戴口罩人脸2种类别MAP的平均值;face_MAP、face_mask_MAP分别指不戴口罩的人脸类别的MAP、戴口罩的人脸类别的MAP;训练耗时指从头开始训练本数据集至MAP收敛时所用的时间;FPS指Jetson Nano控制器每秒处理1×320×320×3图像的数量。
表3显示,以VGG16为特征提取网络的SSD检测框架的综合MAP为89.40%,略高于以MobileNet-V3为特征提取网络的SSD检测框架(78.49%),这可能是轻量化的特征提取网络在一定程度上丢失了部分信息所造成的。但是本文的主要目的是将其运行在边缘计算设备上,实时性更重要,因此算法更注重速度的提高。前者训练至MAP收敛时的耗时为3.88 h,是后者的2.27倍;前者的FPS为2(Jetson Nano平台),是后者的1/6,即实际效果上,改进后的网络检测速度是前者的6倍。主要原因是①轻量型Mobilenet-V3减少了参数量和计算量;②深度可分离卷积优化了普通卷积的计算形式,加速效果为SSD+VGG16的1~9倍,参见式(4)。
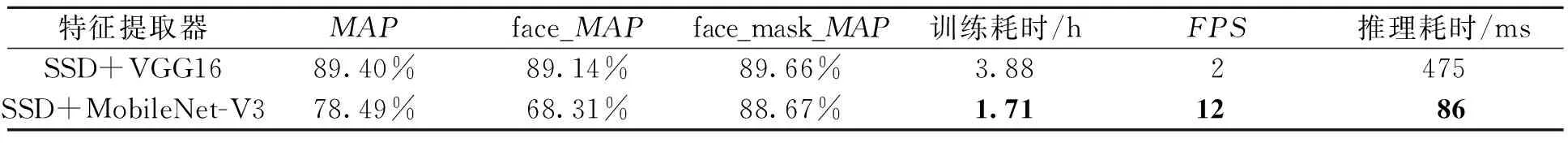
表3 不同检测网络的算法性能Table 3 Algorithm performance of different detection networks
图6为在不同的特征提取网络(VGG16和Mobilnet-V3)下,face和face_mask的MAP以及综合MAP随着迭代次数的变化曲线。可以看出,MobileNet-V3的MAP(改进后的变化曲线)收敛速度更快,过程更加平坦,这可能是因为参数量和计算量较少,从而使网络更加容易训练,单步迭代耗时少。
表4展示了不同特征提取网络下,显存占用量、GPU占用率等指标的具体数值。改进后的SSD(以MobileNet-V3为特征提取网络)指标值均为该类最低,有利于减少模型存储空间、减弱对硬件资源的依赖以及对GPU的损耗。以VGG16为特征提取网络的SSD检测框架和YoLo-V3检测框架的计算量分别是以MobileNet-V3为特征提取网络的SSD检测框架的63和321倍。因此, YoLo-V3和原始SSD均无法胜任嵌入式平台应用的需求。

表4 不同检测网络的性能指标Table 4 Performance indicators of different detection networks
3 模型移植及机械部件设计
3.1 中央控制器选择
MobileNet-V3-SSD网络在输入1×320×320×3时,计算量以总浮点数运算操作次数GFLOPs表示,为0.483 7(FP32)。选择Jetson Nano作为中央处理器,半精度(FP16)浮点数的计算速度以每秒钟浮点数运算操作次数TFLOPS表示,为0.5。NVIDIA官网的Jetpack 4.4.1系统作为基础系统环境。
3.2 外围电路
3.2.1 光电开关输入信号
选择漫反射三线PNP常开型光电开关,额定电压为5 V,额定电流为30 mA。仅当检测到人脸,中央控制器才会调用GPU进行推理检测,以减少不必要的GPU和CPU损耗及电量消耗,延长元器件使用寿命。
3.2.2 USB摄像头图像信号
当控制器收到光电开关高电平信号后,立即调用USB摄像头(480 P,60°,焦距为3.6 mm)捕捉图像信息,进行推理检测。持续检测大约20帧图像,如果超过10帧均检测到该行人佩戴了口罩,即认为“佩戴口罩”,打开挡板;否则,语音提示“您好,您未佩戴口罩,请佩戴口罩后通行”。为了在人流量大的时候依然保持鲁棒性,将检测到的人脸框按照面积大小排序,取面积最大的作为排队队伍的第1个人的人脸,是否放行依据此人是否佩戴口罩。
3.2.3 动力输出
挡板的动力由伺服电机提供,转动范围为0°~180°,扭矩为60 kg·cm。依据摄像头中的人是否佩戴了口罩,通过python编程提供的脉宽调制PWM信号,经I2C—GPIO口和PCA9685模块输出控制伺服电机旋转。
3.3 折叠挡板设计
常见的挡板类型如三锟闸、摆闸和翼闸等,均不能自动调整挡板长度。采用平行四边形连杆折叠设计,当伺服电机驱动挡板上升时,由于重力的影响,挡板展开,形成一张网状的门,如图7(a)所示;当伺服电机驱动挡板下降时,由于外壳壁的阻力影响,折叠机构收缩在外壳壁内,如图7(b)所示。
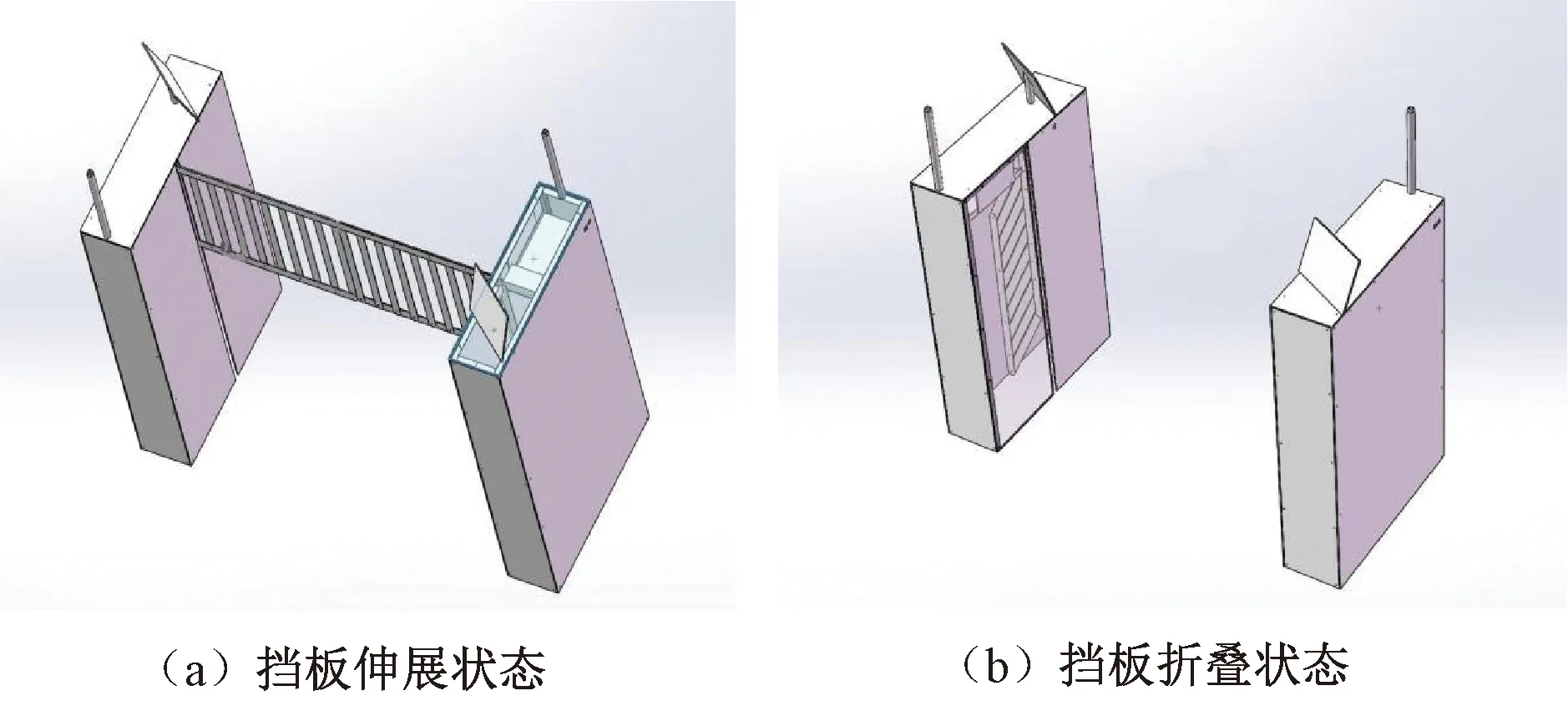
图7 挡板的工作状态Figure 7 Working states of baffles
4 结论
本文设计了一种新型门禁系统,以MobileNet-V3为特征提取网络改进SSD检测算法检测公共场所出入口行人是否佩戴口罩,平行四边形连杆折叠挡板节约占地空间,留有以太网接口方便修改配置、更新神经网络模型。将原始VGG特征提取网络替换成轻量化MobileNet-V3,MAP虽有所下降,但FPS却从2提高到了12,检测速度是原始SSD算法的6倍,在保证了精度的同时提高了速度。如何在MAP保持不变的情况下提高检测速度依然是一个值得研究的问题。下一步研究工作会尝试将门禁系统接入互联网,利用云计算在云端进行监控,实现集中统一管理和维护。
猜你喜欢
客联(2021年9期)2021-11-07
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
海外文摘·艺术(2020年22期)2020-11-18
矿山测量(2020年2期)2020-05-17
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
动漫星空(2018年9期)2018-10-26
