
基于时空特征的语音情感识别模型TSTNet
2021-12-14 06:15:48薛均晓黄世博王亚博张朝阳
郑州大学学报(工学版) 2021年6期
薛均晓, 黄世博, 王亚博, 张朝阳, 石 磊
(1.郑州大学 软件学院,河南 郑州 450002; 2.郑州大学 网络空间安全学院,河南 郑州 450002; 3.郑州大学 信息工程学院,河南 郑州 450001)
0 引言
语音情感识别是人机交互领域的重要技术,在安全驾驶、采集病人情绪状态、结合情感辅助发言等方面都有广泛的应用。现实生活中,由于语音多样性、环境多样性,以及说话者的说话习惯、性别、语气、音调、语速等问题,导致语音的情感识别成为一项具有挑战性的工作。
近年来,随着深度学习的迅速发展,研究人员在语音情感识别领域运用深度学习技术,取得了很好的成果[1-4],但仍存在一些需要改进的地方:①对于语音的分析中并没有全部关注到语音的空间特征、时序特征以及前后语义关系;②对于语音样本长度参差不齐的问题,填充长度过长会导致每个样本中增添很多冗余信息,过短则会导致数据丢失。
针对上述问题,本文提出一种基于时空特征的语音情感识别方法。该方法由空间特征提取模块、时间特征提取模块以及特征融合模块组成。空间特征提取模块关注语音的空间特征,时间特征提取模块关注语音的时间特征和语音信号中前后语义关系。为了解决语音长度不一导致填充时信息丢失或冗余问题,模型采用3种补零填充长度得到3个不同尺度的语谱图,分别提取它们的空间特征、时间特征以及前后语义关系,在特征融合模块中将提取得到的3个特征向量融合到一起。
1 相关工作
1.1 情感描述方式
目前主要有2种描述情感的方法:基于离散的方法和基于维度的方法。
情感的离散描述方法是将情感离散化,并进一步类别化。陈炜亮等[5]提出一种新的情感识别模型MFCCG-PCA,实现生气、高兴、害怕、悲伤、惊讶和中性6种情感的分类。离散的描述方式简单并且应用广泛,但是情感描述单一。
情感的维度描述方法是将情感状态描述为一种笛卡尔空间,空间的每个维度对应1种情感属性。Schlosberg[6]提出倒圆锥三维情感空间,从3个维度对情感进行描述,将情感描述成1个倒立圆锥形的空间模型。基于维度的情感描述方法利用多维的数值来表示情感,能够描述情感的微妙变化。
1.2 语音情感识别分类器
早期的语音情感识别模型主要有隐马尔可夫模型、支持向量机等传统的模型。Lin等[7]利用隐马尔可夫模型和支持向量机识别5种情绪。Pan等[8]探究线性预测频谱编码(LPCC)、梅尔频谱系数(MFCC)等特征,并在相关数据集上训练支持向量机。
近年来,基于深度学习的方法成为语音情感识别的研究热点。Mao等[9]提出使用卷积神经网络学习情感显著性特征;Trigeorgis等[10]结合卷积神经网络和长短期记忆网络,提出解决“情境感知”情感相关特征的方法;Badshah等[11]提出3个卷积神经网络结合3个全连接层的模型从语谱图中提取特征,并预测7种情感;Tzirakis等[12]利用卷积神经网络和长短期记忆网络,提出一种端到端的连续语音情感识别方法;Zhang等[13]利用预训练的AlexNet模型以及支持向量机预测话语级情绪。
2 方法
本文提出了一种基于卷积神经网络CNN和双向循环神经网络(BiGRU)的语音情感识别模型TSTNet,模型结构如图1所示。在数据预处理部分,首先对一个语音信号样本进行傅里叶变换,针对3种补零填充长度得到3个不同尺度的语谱图,然后将其依次输入空间特征提取模块和时间特征提取模块中,得到3个特征向量,最后将这3个特征向量进行特征融合和情感分类。
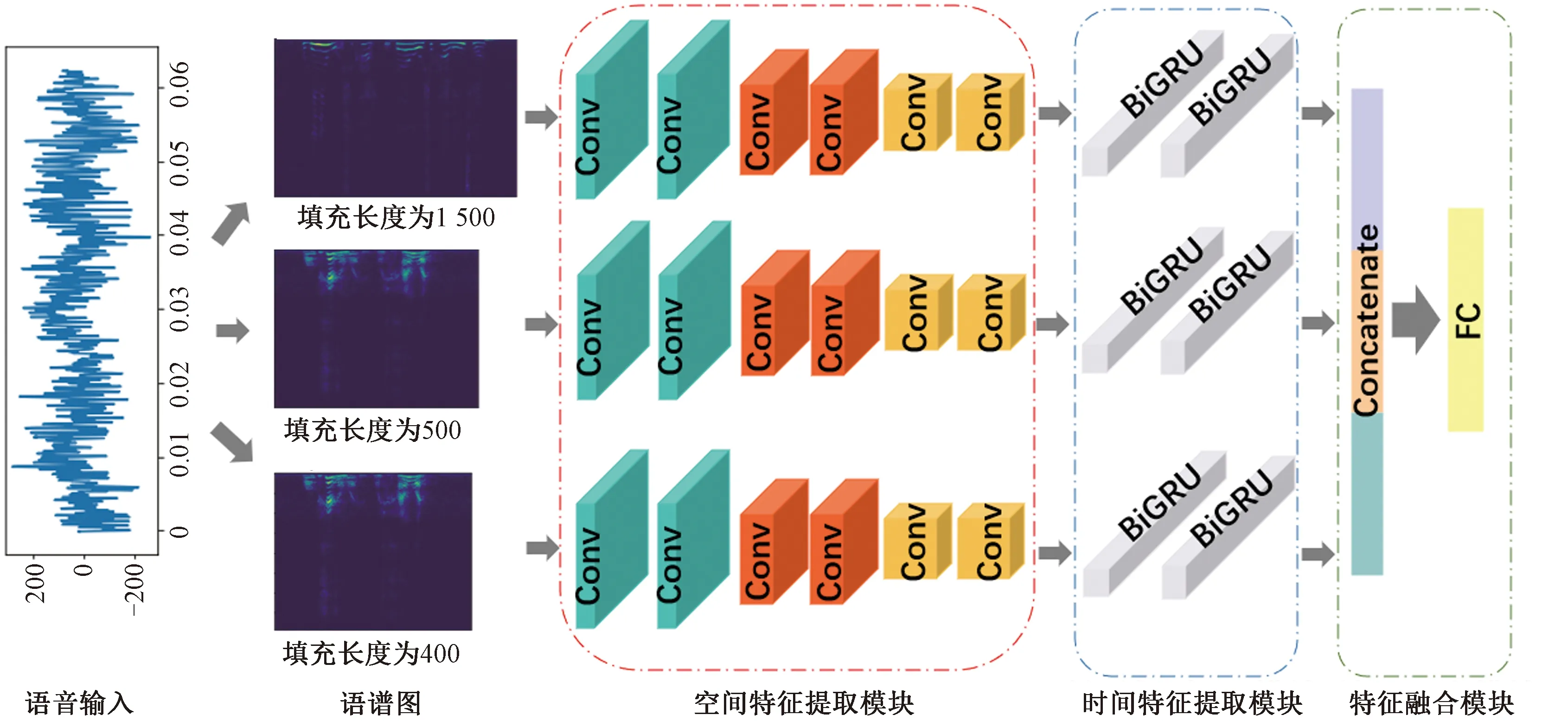
图1 TSTNet模型结构Figure 1 TSTNet model structure
2.1 语谱图
在预处理部分考虑到语音长度相差很大的问题,首先将普通的WAV语音信号采用3种补零填充长度进行填充,并转换为语谱图。基于对数据信号长度分布情况的分析,选择的3种填充长度分别为400、800、1 500。语谱图的转换过程如图2所示。

图2 语谱图转换过程Figure 2 Spectrogram conversion process
首先对语音信号进行采样、量化、编码处理,使之转变成数字信号。通过下采样,将语音信号的采样率由44.1 kHz转化为16 kHz。为避免在傅里叶变换操作期间出现数值问题,对模数转换后的数据帧预加重,并进行分帧、加窗以及短时傅里叶变换,得到需要的语谱图(spectrogram)。
2.2 空间特征提取模块
卷积神经网络(convolutional neural networks, CNN)对于图像和语音的特征提取有出色的表现。将2.1节中的3个不同尺度的语谱图其中之一(维度为 [L, 200, 1],L∈ (400, 800, 1 500)) 送入CNN中,利用CNN去捕获音频的局部特征,其他2个语谱图处理过程与此相同。卷积层的计算式为
Yi=f(Wi⊗X+bi)。
(1)
式中:X∈RL×200×1为语谱图矩阵;Wi为卷积核的权重值;⊗为卷积操作;bi为卷积核的偏置值,i为卷积核数;f(·)表示ReLU函数,其定义为
Yi=max(0,Zi)。
(2)
式中:Zi=Wi⊗X+bi。将得到的特征Yi输入平均池化层,一个池化区的计算式为
(3)
式中:Rj为池化区的像素点数;j为区域数;Pi为Yi一个通道中的池化区;i为池化区第i个像素点。
在空间特征提取模块,模型使用6层卷积神经网络,卷积核通道分别为32、32、64、64、128、128,卷积核大小均为3×3。3个语谱图经过空间特征提取模块得到3个特征向量,送入时间特征提取模块中。
2.3 时间特征提取模块
GRU[14](gate recurrent unit)是循环神经网络(recurrent neural networks, RNN)的变体。将空间特征提取模块中提取的3个特征向量展开,分别输入GRU,一个GRU单元的计算式为
zt=σ(Wt·[xt,ht-1]);
(4)
rt=σ(Wt·[xt,ht-1]);
(5)
(6)
(7)

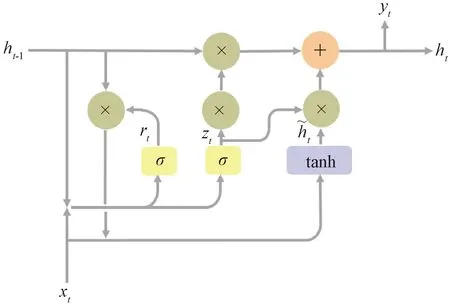
图3 GRU单元Figure 3 GRU unit


图4 BiGRU模型结构Figure 4 BiGRU model structure
At=f(ht-1,xt);
(8)
(9)
式中:f、f′分别表示GRU单元前向、后向传播;ht-1、ht+1分别表示前向传播中时刻(t-1)状态输入、后向传播中时刻(t+1)状态输入。
时间特征提取模块中BiGRU层数为2层,中间设置一层Dropout层,BiGRU序列长度设置为128。
2.4 特征融合模块
TSTNet模型利用CNN处理由语音生成的语谱图,提取出语音中的局部区域特征;BiGRU关注语音的时间特征以及前后语义关系,故将CNN与BiGRU结合搭建TSTNet模型。
3种尺度的语谱图经过空间特征提取模块、时间特征提取模块之后,得到3个特征向量。在特征融合模块中,将这3个特征向量拼接在一起,得到1个新的特征向量。将该特征向量输入1个FC层和1个Softmax函数,得到最终的语音情感识别结果。如图1中的特征融合模块所示。
3 实验分析
3.1 数据集
实验数据集来自科大讯飞,数据集总共有7 004个音频样本,详细描述如表1所示。样本标签分布如图5所示,可知标签数量分布均匀。实验按照8∶2的比例随机划分数据集,80%的样本作为训练集,20%的样本作为测试集。

表1 科大讯飞数据集Table 1 HKUST IFLYTEK data set

图5 数据集标签分布情况Figure 5 Data set label distribution
3.2 实验环境
实验使用Keras框架搭建TSTNet模型,所用到的硬件设备为NVIDIA RTX2080Ti。模型参数配置的详细情况如表2所示。

表2 模型参数配置Table 2 Model parameter configuration
3.3 实验结果分析
将TSTNet模型的实验结果和以下5个已有的情感识别模型的实验结果进行对比,实验指标为准确率、精确率、召回率和F1值。
(1)MFCC+随机森林。提取语音数据中的MFCC特征,将提取的MFCC归一化并求最大值得到语音特征向量,用随机森林去拟合提取的特征向量。
(2)语谱图+CNN。通过傅里叶变换将语音转化为语谱图,用CNN网络提取语谱图特征。
(3)MFCC+CNN。基于MFCC+CNN的方法已经被应用于多种领域中,比如在语音识别[15]领域,此方法获得了很好的效果。在语音情感识别任务中,提取语音中的MFCC特征,然后输入CNN网络中对情感进行识别。
(4)语谱图+CNN+RNN。在语谱图和CNN的基础上加上RNN,去捕捉语音的时序特征。
(5)语谱图+CNN+LSTM。LSTM广泛应用于语音识别[16]、文本情感分析[17]中。这里将CNN和LSTM结合应用于情感识别中。
TSTNet模型与后4种模型对比,得到实验的训练准确率曲线和损失值曲线,分别如图6、7所示。从图6、7中可知,相比于其他方法的模型,TSTNet模型在准确率和损失值上都表现良好,得到了较好的准确率;TSTNet模型训练的波动幅度相对平稳,对数据拟合程度较好。

图6 准确率曲线Figure 6 Accuracy curve

图7 损失值曲线Figure 7 Loss value curve
TSTNet模型和以上模型在准确率、精确率、召回率和F1上的测试集表现情况如表3所示。从表3中可以看出,基于深度学习的方法比传统方法效果好,并且TSTNet模型在准确率、精确率、召回率、F1值上都得到了较好的结果。

表3 不同模型在准确率、精确率、召回率、F1值上的表现Table 3 Performance of different models on accuracy, precision, recall, and F1 values %
本文方法采用不同的语音填充长度,分别为400、800、1 500,最后在特征融合模块将它们集成到一起。为了验证模型中集成方法的有效性以及BiGRU特征提取的有效性,训练了4个实验模型,填充长度分别为400、800、1 500以及填充长度为800但没有使用BiGRU,对比结果如表4所示,训练过程准确率曲线如图8所示。

表4 TSTNet模型消融实验Table 4 TSTNet model ablation experiment

图8 模型训练准确率曲线Figure 8 Model training accuracy curve
由表4和图8可知,填充长度为800的模型比没有使用BiGRU(填充长度为800)的模型的准确率高,集成3种填充长度的TSTNet比3个单一填充的实验效果明显。由此可验证TSTNet模型中的BiGRU可以关注到语音的前后语义关系。前后语义关系以及不同填充长度的集成方法对于语音情感识别准确率的提高有重要的意义。
4 结论
本文提出了一种语音情感识别模型TSTNet,该模型结合CNN和BiGRU,能够关注语音信号中的前后双向语义关系(two-way semantic relationship)以及时空特征(spatial-temporal features)。采用3种不同的填充长度进行特征融合,能较好缓解语音长度相差大导致填充时信息丢失或冗余的问题。本文方法在实验数据集上能够得到94.69%的识别准确率,相对于基于MFCC和随机森林等语音情感识别方法,本文方法在多项实验指标上效果显著。
猜你喜欢
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
小型微型计算机系统(2019年9期)2019-09-09 03:38:42
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
电子制作(2018年19期)2018-11-14 02:37:08
吉林大学学报(信息科学版)(2018年3期)2018-06-13 10:36:38
东北师大学报(自然科学版)(2017年2期)2017-06-13 10:43:55
自动化学报(2017年11期)2017-04-04 02:52:58
东南大学学报(自然科学版)(2015年5期)2015-03-15 00:54:56
