
基于贴真体验与建模的多模态口译教学语料库构建及应用*
2021-12-13 08:45:50同济大学黄立鹤
外语教学理论与实践 2021年4期
同济大学 黄立鹤 吴 贇
提 要: 口译活动是发言人、译员等在社会情境中的多模态亲历过程。口译教学可借助贴真建模思路,从参与者、活动和系统三个视角对口译活动录像与情境化影视片段进行观察分析、数据提取,构建可触发学生贴真体验的多模态口译教学语料库。教师利用语料库讲解口译现象、评估口译质量,要求学生模拟该口译任务进行练习,激发学生多种感官模态对情境化口译活动进行贴真体验。今后还可研发口译虚拟仿真实验教学,从而提升学生的情境口译能力。
1. 引言
目前,多模态翻译教学渐成热点,相关研究正尝试建构多模态翻译教学体系。但目前相关研究在语料处理、教学模式等问题上仍亟待深入,借助计算机辅助技术开展的口译教学还存在教学方法与技术工具没有充分整合的问题。
在现代教育技术条件下,口译教学的任务之一是多维度地提升学生的情境口译能力。真实口译活动是发言人、译员等在社会情境中的多模态亲历过程。口译活动录像是对社会情境下真实口译活动的贴真再现,情境化影视片段是对现实社会情境的模拟呈现,这两种音视频材料都是多模态口译教学的常用语料。选用这些语料的目的是利用它们的多模态属性,触发学生的多模态贴真体验。
本文首先探讨口译活动亲历过程与口译教学贴真体验的关系,随后介绍以贴真建模(stimulation modeling)的思路进行口译活动录像及情境化影视片段的特征提取方法,尝试构建真实口译活动录像及情境化影视片段的分析框架,以及基于多模态语料库的口译教学基本模式,并借以具体教学案例分析其适用性。
2. 亲历过程、贴真体验与口译教学
1) 口译活动与亲历过程
人最基本的行为就是亲历(experiencing)。亲历包括线上亲历和线下亲历,前者指与外部世界进行实时互动的当下亲历,后者指整人的内省活动(顾曰国,2016)。亲历者在亲历过程中构建了各种类型的数据,亲历者就好比一个大数据存放与集成库,亲历过程就是不断往该数据库填写数据(顾曰国,2016)。
因此,口译活动是发言人及译员在社会情境中的多模态亲历过程。口译是现场即席进行的翻译活动,是一种由发言人、译员等共同亲历并构建的、在一定社会情境中的现场即席话语。按照这个思路,我们可以发现: 亲历者(experiencer,包括发言人、译员及其他人员等)在现场口译活动中,调用多个感官同时参与言语交际过程(包括口译活动),通过多模态亲历(experiencing)形成了一种全方位充盈体验(total saturated experience)。这种全方位的充盈体验对于口译员来说,就是在大脑中形成的口译经验(interpretation experience)。发言人、口译员在现场口译过程中也不断填写数据,他们的亲历形成了一个个多模态数据库(1)需要指出的是,这个数据库其实包含了亲历者(发言人、译员及其他人员)的当下亲历与内心活动两种类型亲历的数据,只不过前者(当下亲历)可用音视频录像技术等尽量采集部分数据(但受到技术、方法甚至必要性的限制,不可能完全还原所有充盈数据),而后者从技术上说不易采集(但并非不可能,如通过脑电技术间接采集口译员脑部活动的数据等)。。
从亲历过程这一视角来审视口译过程,是本文对情境口译活动构建分析框架、建立数据类型、实施建库并实现教学应用的理论出发点。基于亲历过程的多模态口译教学就是利用现有科技手段,尽量贴近口译过程的充盈数据进行信息采集与呈现,在此基础上构建成库,用以触发学生的贴真体验,从而提供模拟口译亲历过程的教学活动。
2) 口译录像与影视片段的多模态属性及贴真体验的触发
口译教学材料包括书面文字、音频录音以及视频录像,至少是双模态的,更多是多模态的。这里讨论在口译教学中常用的两种视频材料,一为真实口译活动录像,一为情境化的影视片段。两者都是涵括多种类型数据的资源库,经过一定加工处理后,可形成多模态口译语料库用于教学。利用这种语料库进行口译教学,可向学生贴真展现真实情境中的口译活动,多维度地提升其情境口译能力。
真实口译活动录像指的是用摄像及录音设备连续记录现场口译活动中包括声音、动作、空间、场景等一系列信息,形成音视频数据,是目前对口译教学过程进行贴真呈现的方便可行、成本较低的方法。口译录像可向学生直观呈现比课堂口译训练更加复杂多变的真实口译现场,教师可对口译现象、口译现场、口译质量及口译礼仪进行讲解与评估,为学生提供真实口译活动的分析与评价案例,从中学习口译经验、避免口译失误,缩小课堂口译教学与实际口译活动之间的差异鸿沟。
情境化的影视片段指的是影视作为一种交流的镜像,借助画面、声音等综合视听的形象符号体系来塑造形象,反映生活,表现对生活的感受、认识和态度,具有直观在场性、动态瞬时性、双重文化性等鲜明特质(吴赟,2011),使影视成为对社会情境的贴真再现。一个影视片段通过多种符号模态的直接在场和迅速推进来展开冲突,呈现情节,形成连贯而有意义的陈述。需要特别指出的是,本文并非从翻译文本的视角看待情境化的影视片段(即并非将影视片段视为翻译对象),而是立足影视片段所反映的过程及情境视角,将其视为人们利用摄像及录音设备对各种社会情境下真实交际互动过程的模拟再现。情境化的影视片段旨在触发学生的视觉、听觉、触觉等多种感官模态,感知贴近真实情况的模拟社会情境再现,教师引导学生激发自己的直观体验、经验联想和理性反思,在影片的连贯叙事和完整结构中先领悟概念,再转而联想到具体的情境意味,形成并更新对具体词句的理解和感受,营造身临其境的氛围,触发多种感官模态实施口译训练。
下图展示了上述两种音视频语料中涉及的各种维度以及师生调用的模态情况:

图1. 音视频资料涉及模态及维度
基于多模态口译语料库中的丰富数据,教师可讲解分析真实口译活动中的各类口译现象及技巧,弥补仅从文字或音频材料提取信息,却丧失多种其他信息的局限。同时,还可利用同步声音与影像模拟口译场景,提供更多的口译实训机会,增强对口译现场的贴真体验,以期降低真实环境下的口译焦虑。
那么,如何挖掘数据、建设该类语料库呢?下面介绍基于贴真建模思路的建设方案。
3. 基于贴真建模思路的分析框架构建及数据提取
贴真建模是科学研究中常用方法之一,也是多模态语料库语言学的基本方法(黄立鹤,2018: 46-48)。口译活动录像和情境化影视片段都是对参与者亲历过程的贴真再现,我们可以借助贴真建模的思路来分析这些过程并提取数据。
1) 贴真建模与特征提取
在口译活动中,译员对副语言及非言语表意符号的解读与传递十分重要,尤其在机构性情境中(Pérez-Gonzlez, 2014: 123)。这些信息是重要的“情境化线索”(Mason, 2009),有利于解读发言人及其他角色的真实意图及交际活动。因此,在口译研究中,研究者有必要对包含语言、副语言及非言语行为等在内的各种符号资源进行整体性分析,才能对译员互动行为进行完整的、动态的解读(Pasquandrea, 2012: 150)。
在口译实践中,无论是成熟的口译员,还是课堂上的口译学员,都要面对各类具体的口译主题,也因此置身不同的口译情境。不同社会情境受各种口译活动主题的约束,如医疗卫生、国际关系、文化教育、科技发展等因内容属性不同,也构成了口译活动各不相同的特征结构、任务要求以及译员行为。各类情境下的发言者因情境、事件、个体等多种因素而呈现不同的、变化的主体特征,对这些主体特征的分析及理解与口译质量、恰当性等直接相关。因此,口译教学要培养学生分析情境及发言主体特征的能力。
以往口译教师对情境结构、主体特征等方面的分析和概括往往是经验式、主观性的,未能够在相对客观整一的框架下对情境与主体的结构、层次和特征进行提取和总结。为提升分析的科学性与客观性,就要构建一个分析框架。
对客观现象、事物或过程的特征、性质等方面数据的提取涉及贴真建模。本文以贴真建模为思路,介绍如何构建一个服务于口译教学的分析框架。对鲜活社会活动进行建模通常有三个视角: 活动、参与者与系统(如下图)。对口译活动录像及情境化影视片段的分析也可以参照社会活动建模的三个视角。
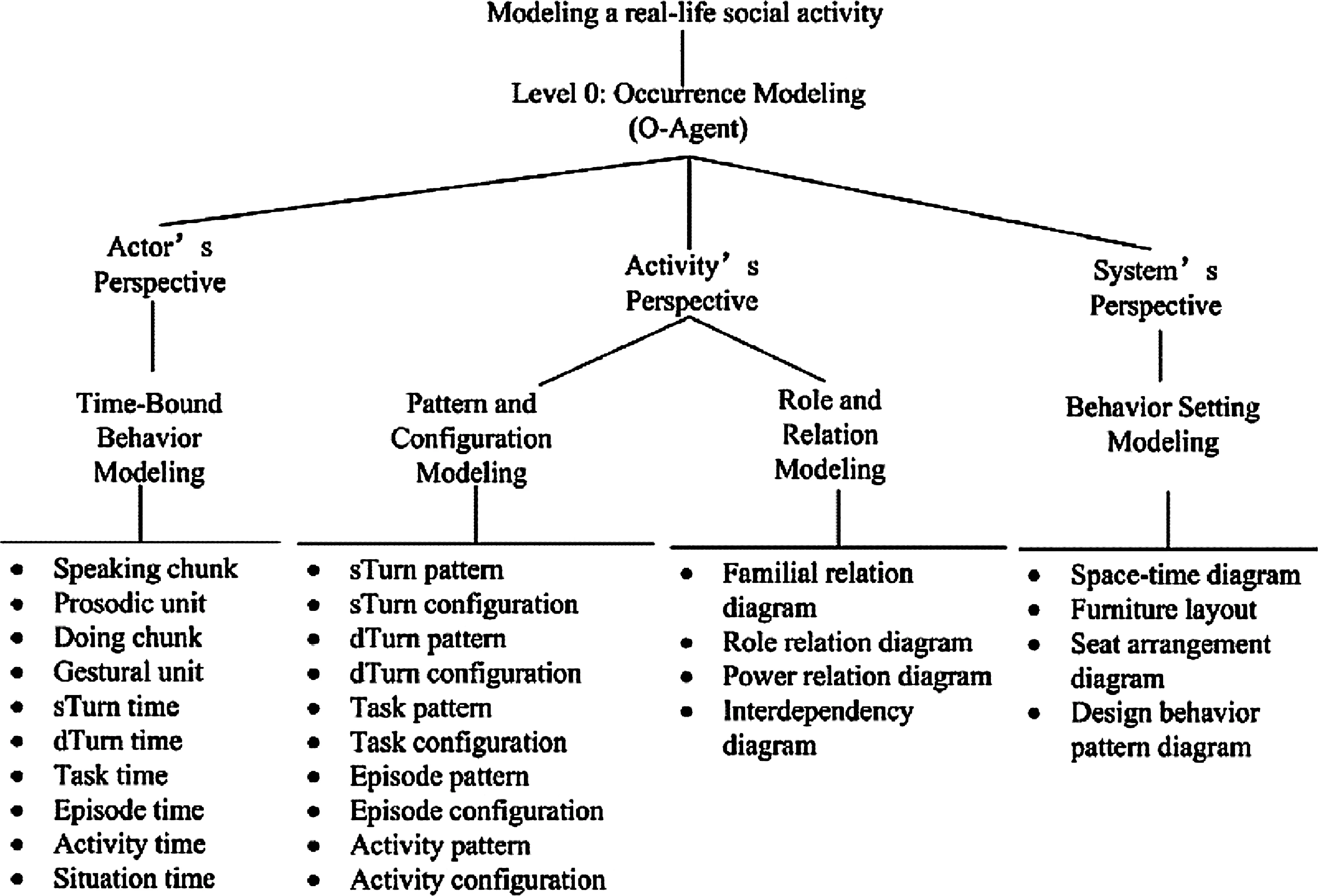
图2. 鲜活社会活动建模的三个视角(Gu, 2009)
2) 概念建模与数据建模
贴真建模分为概念建模、数据建模、实际操作与评估(可参考黄立鹤,2018: 48-51)。在本文中,概念建模是指对口译活动或情境化影视进行分析视角的确定,形成能够把握本质的概念模型;数据建模是针对概念建模建立的研究视角确定数据提取的类型与方式;实际操作与评估是指利用数字化技术根据先前的数据模型对分析对象进行模拟运行,检验结果是否符合概念模型。本节介绍如何对真实口译活动录像及情境化影视片段进行概念建模和数据建模。
(1) 参与者视角
参与者视角涉及多种角色,包括译员、发言人(翻译对象)、其他人员(非翻译对象)等,可以按照教学需要决定是否在具体分析中采用。参与者视角的主要分析对象包括: 译员及发言人的翻译或发言时间、其他活动时间、话轮、动作、任务行为、韵律等。每一个方面还可根据需要细分,例如: 话轮切分至何级单位(小句、词组、字词)、切分标准是什么;动作可细分为面部表情(根据需要还可进一步分为眉毛、嘴部等)、头部动作、手部动作、腿部动作、身体姿势等;韵律可包括韵律单位、调型调模以及包括笑声、咳嗽、清嗓等其他韵律特征。
(2)活动视角
活动视角主要是对口译过程所处社会情境、影视片段中社会情境及其下位结构进行分层分析,该视角还可以细分为结构组合视角以及角色关系视角,从而展现口译任务在整个情境中的地位、译员任务、多个活动之间的关系、口译过程中不同角色的地位及相互关系、口译内容依存性关系等。
(3)系统视角
系统视角是指将口译活动视为一个活动系统,主要针对口译活动所处社会场景、影视片段中社会情境的自身信息,包括时空间信息、家具及器具摆放、座次安排、灯光调节、背景布置等。这些信息是社会活动的重要组成部分,也是译员在口译工作时应当注意的重要信息。
以上是概念建模中的视角选取。在此基础上,可根据概念模型确定的视角,按照实际研究与教学需要,再细分下位层级,并最终确定数据模型。从多模态语料标注的角度而言,数据模型直接对应着标注层,确定了标注集及赋码。
这里,选用集合形式对标注集进行列举式介绍:
参与者视角_发言人_个人属性 {性别;年龄;身份;职务;本族语}
参与者视角_发言人_说话行为_话语内容 {语种;专业领域;说话内容}
参与者视角_发言人_说话行为_韵律特征_韵律单位 {说话停顿边界}
参与者视角_发言人_说话行为_韵律特征_调型调模 {平调;平调;升调;降调;凹曲调;凸曲调;高语阶;中语阶;低语阶}
参与者视角_发言人_说话行为_韵律特征_其他特征 {停延;重音;音质;咳嗽;清嗓;喘息}
参与者视角_发言人_动作姿态_任务行为 {站立说话;坐着说话;操作电脑}
参与者视角_发言人_动作姿态_非言语行为 {头部;表情;手部;腿部;身势}
参与者视角_发言人_情感意图_即席情感 {平静;愤怒;恐惧;悲伤;厌恶;惊奇;高兴;忧虑}
参与者视角_发言人_情感意图_意图状态 {意图;立场;态度;信念;愿望}
参与者视角_译员_个人属性 {性别;年龄;职业水准;本族语}
参与者视角_译员_翻译行为_口译内容 {语种;口译内容}
参与者视角_译员_翻译行为_处理策略 {口译策略分析}
参与者视角_译员_翻译行为_辅助材料 {译员速记内容;与口译任务相关的背景材料}
参与者视角_译员_翻译行为_韵律特征_韵律单位 {译员说话停顿边界}
参与者视角_译员_翻译行为_韵律特征_调型调模 {平调;平调;升调;降调;凹曲调;凸曲调;高语阶;中语阶;低语阶}
参与者视角_译员_翻译行为_韵律特征_其他特征 {停延;重音;音质;咳嗽;清嗓;喘息}
参与者视角_译员_动作姿态_任务行为 {站立说话;坐着说话;用笔记录}
参与者视角_译员_动作姿态_非言语行为 {头部;表情;手部;腿部;身势}
参与者视角_译员_情感意图_即席情感 {平静;愤怒;恐惧;悲伤;厌恶;惊奇;高兴;忧虑}
参与者视角_译员_情感意图_意图状态 {基本意图;态度;信念;愿望}
活动视角_结构组合_活动类型及结构关系 {类型名称;场景名称;结构关系}(2)口译是社会情境中的现场即席话语,可进行结构化切分。在活动视角中设置“结构组合”、“活动类型”及“结构关系”,就是为了解决口译活动的结构化切分问题。这种切分对于模拟情境口译教学、虚拟仿真口译教学技术开发等具有重要意义。
活动视角_结构组合_口译任务地位 {核心;边缘;辅助}
活动视角_角色关系_地位关系 {发言人、译员及其他人员之间的地位关系}
活动视角_角色关系_权势距离 {现场不同角色之间的权势距离大小}
活动视角_角色关系_依存性关系 {前后关系;现实关系;言行关系}
系统视角_时空间信息_时间信息 {口译任务所在的时间信息}
系统视角_时空间信息_空间信息 {口译任务所在的空间信息}
系统视角_现场布置_信息展现 {幻灯片内容;屏幕影像;音响播放}
系统视角_现场布置_整体氛围 {严肃;和谐;活泼;凝重}
系统视角_现场布置_灯光调节 {明亮;柔和;温馨;暗淡}
系统视角_现场布置_座位安排 {主席台—观众席型;圆桌围坐型;长条桌对坐型}
上述概念模型中视角及相应数据类型的确定,既是多模态口译教学中对情境化影视片段或真实口译录像进行多维度分析的整体框架,也是多模态口译教学语料库建设的切分与标注依据。
单个角度所提取的特征、数据是整个口译活动的某个方面,这叫“化整为零”;由多个角度的数据集成起来,就能尽量贴近口译活动的整体情况,从建模上叫“数据集成”(Gu,2009)。{...}里面的数据是根据口译活动的真实情况以及教学研究实际需要所提取的,在实际操作与评估阶段,对应着Praat或Elan等标注软件里标注层的数据。
需要注意的是,上述子结构应该细分到哪一层级,在建模上叫颗粒度。颗粒度的大小取决于建模者的研究需要。该分析框架在具体教学实践中如何设定、设定到哪一级,取决于教学需要及音视频情况,由口译教师或进行训练的学生决定。另外,某些层级可能在某些情境口译中并不适用,例如在陪同口译的录像材料中,可能没有系统视角_现场布置_灯光调节,系统视角_现场布置_座位安排等数据,此时这些层级属性为“缺省”,形式上用系统视角_现场布置_灯光调节 {default}以及系统视角_现场布置_座位安排 {default}表示。
另外,本文只论及基于贴真建模的口译活动及影视片段分析的思路,在此基础上构建语料库还涉及一系列技术细节以及效度和信度的验证等问题,此处不予讨论,感兴趣的读者可参考Gu(2009)、黄立鹤(2015)、Huang(2018)、黄立鹤(2018)的相关论述。
4. 基于多模态语料库的口译教学基本模式及案例分析
1) 模式构建
实际操作与评估是指口译教师验证、评估多模态口译教学语料库建设是否符合教学目标与实际需要,并进入基于该库的口译教学过程中。
在整个多模态口译教学过程中,存在着多模态语料库的构建和应用两个阶段:
在多模态口译教学语料库的构建阶段,教师确定符合教学目标的影视材料,包括需要考虑口译类型、情境类别、译员水准、发言人口音等多种因素,以保证教学材料的多样性。学生则可以根据教师要求提前准备相应的背景材料。随后,按照上述讨论的概念建模、数据建模,按照实际需求进行调整、修正,从参与者、活动及系统三个视角进行特征值的提取,教师和学生运用Praat、Elan等常用多模态语料库加工工具进行标注、建库。
语料库构建完成之后,即要投入应用。在该阶段,教师在语料库中定向检索相应语料,按照之前的分析框架向学生讲解该口译任务、译员翻译质量、发言人说话特点及其他口译现象,学生在活动类型、背景知识、专业词汇及其他方面进行学习。例如,教师可通过Elan的检索功能详细讲解口译过程中的停顿次数、时长、出现时间及其他共现信息(如译员对发言人说话特点的把握及相应翻译处理),分析停顿的原因;还可借助Praat呈现的参数分析语调、语阶等各类韵律特征,评估其在口译任务中的适合性。
之后,教师可要求学生模拟该口译任务进行练习。基于多模态语料库进行的模拟口译,可触发学生的多模态贴真体验,增强情境现场感。对于口译活动录像而言,教师可指导学生模拟现场口译,并与现场口译比较、进行质量评估;情境化影视片段则为学生提供模拟的口译现场(当然,语料的选择须符合口译教学需求),积累各种社会场景或专业领域的背景知识,以提升情境口译水平(下一节将做案例分析)。
最后,进入分析与反思评估阶段,师生对情境化影视片段与真实口译任务录像的整体情况、学生模拟练习情况等进行反思、评估,以促进语料库建设、总结口译实践经验。
需要注意的是,以上两个阶段是互相促进的,多模态语料库的构建是应用的前提;同时,师生在应用过程中会对之前构建的语料库进行补充、修正与完善,提升语料库建设质量、丰富语料库的语料构成。构建与应用的逻辑关系如下图:

图3. 多模态口译教学语料库的构建与应用
2) 案例分析
本文谈及真实口译活动录像及情境化影视片段两种语料对口译教学的作用。其中,对口译活动录像的分析已在教学课堂上很多见,上文介绍的分析框架很大程度上有助于口译教师避免对口译活动进行经验式、主观性的评价。限于篇幅,此处不再对口译活动录像进行逐一分析。
现以电影“Philadelphia”(费城故事)中的法庭论辩这一情境化片段为例,在上述分析框架下,运用Elan等工具对其进行标注,提取特征值,并阐述如何帮助学生建立口译过程的分析能力、提升口译技能。
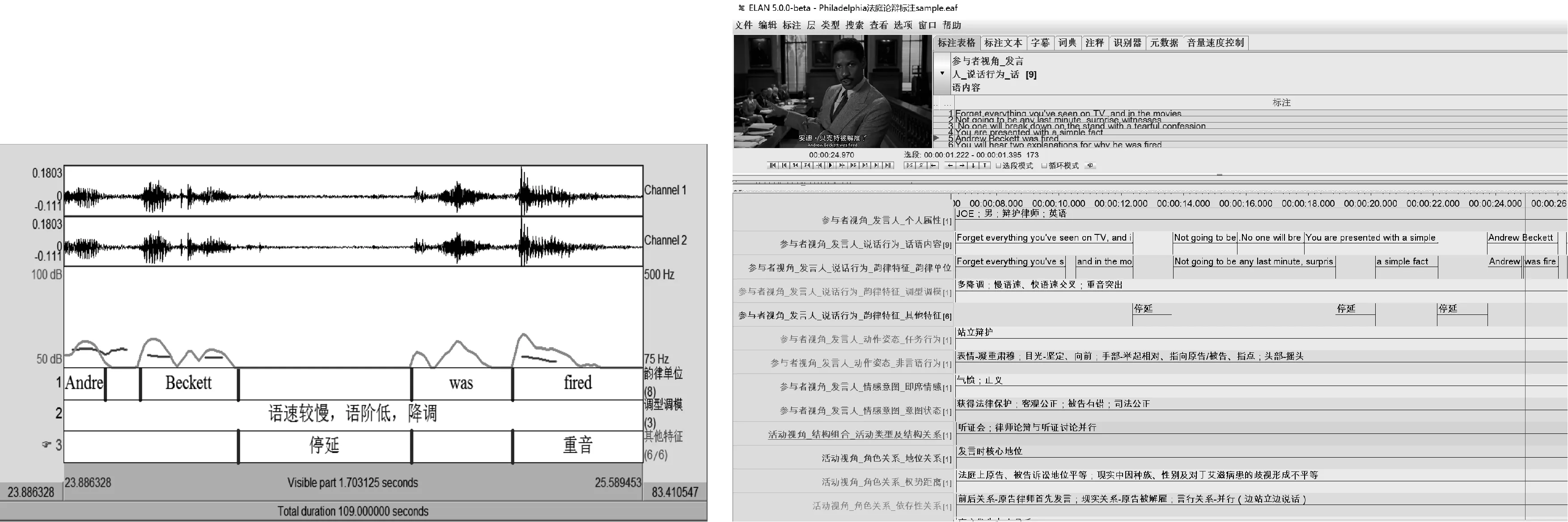
图4. 多模态口译语料库标注样例
从参与者视角来看,控辩双方身为执业律师,分别为艾滋感染者和律师事务所辩护。两人在陈词时,影视片段均以特写镜头呈现说话人的面部表情和手势姿态。多模态信息通过Praat与Elan加以标注呈现。
原告黑人男律师发言时间: 0′00″—2′00″
黑人男律师表情凝重肃穆、眼神坚定;在为原告陈情或指控被告时,不断辅以明确手势指向原告或被告席,说话语速时急时缓;触及关键信息时说话人语速明显降低,语气着重,语句多用降调,产生掷地有声的听觉感受。
被告白人女律师发言时间: 2′01″—3′44″
白人女律师一出场便带着极其轻蔑的微笑,不断挑眉、神情傲慢;在逐条辩护时,语气升降调变化丰富;夸张的语调与表情表明她对于被告作为艾滋感染者的不屑与厌恶。
在话语内容上,两位律师均是逐条列出事实论据,言语针锋相对。这种视听结合的情景语境是影视叙事中的重要环节,教师可以通过对这些视角的分析,帮助学生理解影视片段通过镜头、声音等直观的形态来表达意义的模态资源特征,在此基础上再现其中的语言、结构、情感、思想。电影在有限的时空表述中,意义完整、前后连贯、自成体系。任何对白、旁白的理解与口译都不是由单个字词简单叠加而成,孤立零散;相反,则应在视听的感官直接性中,由整体语境和语篇的有机衔接和交际功能而实现,在口译时一定要根据语篇的连贯和情境的制约与提示,适当地进行预测、补充或具体化。
从活动视角来看,以权势距离为例: 原告辩护律师的黑人身份和被告辩护律师的白人女性身份、原告身为艾滋病患者和被告身为大公司高管、证人身为公司小职员,多重身份之间出现权势的悬殊差异,种族、性别以及对于艾滋病患者的歧视形成激烈对抗,所有的冲突在控辩双方律师、律师与证人的攻讦与辩护之间针锋相对地展开。在这一模拟情境中,教师可指导学生立足影视片段所展现的多重活动维度,关注其节奏感与冲突特质,分析权衡包括源语语境、中文译语语境和译者所处口译语境中的各种相关因素,帮助学生站在宏观视角的同时关注词句的处理,实现对影视片段意义、文化、审美等多重元素的忠实重构。
以系统视角来看,美国法院的整体氛围庄严肃穆、端正凝重,内部灯光色调偏暗。法官、律师、原被告、证人及听众均身着职业装束,表情肃然;影视片段所特有的艺术语言铺陈出一个较为鲜明的认知环境,让学生理解口译并不仅取决于一个个字词和句子的转换,也不是一种互不关联的孤立作业,而是自上而下,有目的地倚赖于具体的情景语境。情境化影视片段在这方面提供了良好的教学工具和环境,可有效地让学生理解口译的交际价值和系统背景的暗示含义,也为口译语言用词指明了语域风格须温文尔雅、庄重得体,以切合说话人的律师身份。
可见,情境化影视片段中丰富的文化元素在单位时长里展开了更具象的冲突和矛盾,铺陈了更为鲜明的情节和结构,并辅以生动、直观的画面和声音,这样可以让学生对语篇的存在和约束具有更强的敏感性和解读力,并学习如何立足目的语,从受众的视角出发,顾及他们的接受程度和情感适应性,在原文和译文之间建立起来相似性和可通约性,选取与目的汉语最为贴切的自然表达。学生在对各类情境化的影视片段进行贴真亲历后,可在教师的帮助下建立相对固定的观察视角,在相对客观的框架下对影视情境进行分析,形成“元认知”,之后进行法庭情境模拟口译训练,并进行分析与反思,评估口译质量。
5. 展望与结语
本文介绍了基于贴真体验与建模的多模态口译教学模式,教学资源上通过多媒体技术和介质存储、分析与呈现多模态内容,教学方法上注重师生间、学生间互动与协作(如师生共同对音视频材料进行特征值提取),为学生提供交互式操作(Praat及Elan标注、检索与统计等),提供口译模拟情境,拓展学生口译实践的维度,激发学生多种感官模态进行贴真体验,并在教学设计、实现与教师要求上提出了更高要求。这是一种立体式教学法关照下的多模态口译教学模式(陈坚林,2011;康志峰,2012),是目前外语教学领域的前沿方法。但该领域仍然有不少问题尚待解决,例如:
1) 多模态口译教学语料库的建设与利用
语料库在翻译教学中日益受到重视(如李德超,Sara Laviosa, 2011),但国内多模态口译语料库建设与研究才起步(刘剑,2017)。相关标注体系较为简单,基本思路仍是双语对齐,加上语音、动作等信息标注,未能从口译活动的亲历本质出发并上升至从社会活动的高度看待情境口译,没有解决口译活动的结构化切分问题,对多模态口译数据挖掘的深度和广度尚需增强;且语料库的类型较为单一,多为现场会议,今后应当在陪同口译、多方研讨口译、试听翻译等方面增加语料类型,为多维度、多层次的口译教学提供基础数据库;此外,在基于多模态口译语料库的教学模式构建方面,虽已有学者提出了一些训练的方法,但今后仍需形成系统性的人才培养模式。
在技术方面,今后可使用知识本体技术对多模态口译教学语料库进行构建,实现图像及视频的语义检索;多模态语料库的范畴很广,还包括从多个维度对口译活动的各类数据进行采集,如译员脑电、眼动、肌电数据,或口译活动时PPT内容、备译材料等,形成立体多维的语料库。当然,一般语料库没有必要包含过多类型的数据,但这并不是说多模态口译语料库就仅限于文字、音频和视频。另外,在解决版权、成本等问题后,可考虑多模态口译语料库的网络开放。
2) 虚拟仿真口译教学模式与训练技术研发
随着虚拟现实技术的发展与虚拟仿真教学的推广,今后应当开发基于大数据的虚拟仿真口译教学与训练技术。通过影像、声音及各种类型的数据模拟,构拟出各种情境和类别的口译任务,如国际会议、商务谈判、生活陪同等,以提升贴真体验及情境化口译教学的真实度。上文构建了真实口译活动录像及情境化影视片段的分析框架,并尝试提取各类数据。在该框架指导下,可基于XML语言对文本进行切分与标注,为虚拟情境口译训练技术的研发提供准备。同时,应当研发基于网络的口译自主学习及自我评估系统,为学生提供口译的质量评估及学习建议。
3) 多模态口译教学效度的实证研究
目前的多模态口译教学研究多集中于宏观探讨,对该模式在教学中的实际效度考察不够,尤其是从实证角度对多模态口译教学中的学生认知过程研究十分鲜见。今后,可依托脑电、眼动等技术对学生的模拟口译过程、多模态口译教学效度等问题展开实证研究,审视翻译的认知过程与翻译教学实践之间的关系。
总之,口译活动是亲历过程,教师可以借助贴真建模思路来提取口译过程的各类特征,在此基础上建设多模态语料库,在教学中触发学生的贴真体验。这有别于从口译产出结果来看待口译现象,或将口译内容与非言语行为简单叠加的思路。多模态口译教学语料库的构建与应用超越了仅依靠文字及音频材料进行口译训练的传统模式,相关教学方法贴近口译活动的真实亲历,充分利用学生的多模态学习机制,触发贴真体验过程,能有效促进学生的情境口译技能发展。基于贴真建模思路,还可以进行口译虚拟仿真实验教学,由口译教师与工程师共同构建多种仿真的口译场景,触发师生多模态互动,开展虚拟仿真口译训练。
多模态范式为外语教学创新提供了主体性、系统性、动态性、协同性等方面的思维启示,师生互动的多模态亲历形式发生了改变,构建的多模态充盈意义也相应发生了变化(黄立鹤,2021)。在信息技术时代,探究如何充分调用多模态感官,贴近语言学习亲历过程,提升学习效率,是多模态教学研究的根本任务。本文从口译教学出发,尝试探讨了一些问题。当然,所构建的分析框架及教学基本模式还需通过更多教学实例来验证其适用性及效度。
猜你喜欢
甘肃教育(2021年10期)2021-11-02 06:14:22
企业改革与管理(2021年10期)2021-01-02 22:06:42
疯狂英语(双语世界)(2017年3期)2018-01-19 01:40:28
疯狂英语(双语世界)(2017年1期)2017-07-01 17:11:36
英语学习(2017年3期)2017-04-10 23:21:37
外语教学理论与实践(2016年2期)2016-06-11 01:49:42
外文研究(2016年3期)2016-03-17 12:41:05
疯狂英语(双语世界)(2015年1期)2016-01-08 06:07:29
天中学刊(2015年4期)2015-08-15 00:51:01
外语教学理论与实践(2014年1期)2014-06-15 06:40:32
