
基于FPGA的Faster-RCNN改进算法实现目标检测
2021-12-10 02:48胡晶晶
现代计算机 2021年30期
胡晶晶
(东北大学计算机科学与工程学院,沈阳 110819)
0 引言
基于嵌入式端设备的实时目标检测和识别系统是计算机视觉方向研究的热点和基础性工作[1],同时目标检测也被广泛应用于医疗、农业、监控等各种领域。随着深度学习的发展,基于深度学习的目标检测方法被大量研究,有较多算法被相继提出,比如R-CNN(region-based convolutional neural network)模型、Fast R-CNN模型、Faster R-CNN模型、YOLO模型、SSD(single shot multi⁃box detector)模型等[2-5]。为了应用到特定化的场景中,对这些算法的改进和加速方案也是层出不穷,目标检测更趋向于精细化和背景复杂化,比如监控、交通人脸识别和手势识别以及轻小异物等目标较小分辨率低的场景,对准确度和实时性要求高,研究者们主要通过对这些算法进行改进以提高实时性或准确性,或者通过对特定的算法进行硬件设计而实现良好的算法性能。
由于CNN需要较大的计算量、并行操作和存储空间。而FPGA芯片能够以并行化的方式高速处理数据,能够以流水线的思想设计并有着充足的逻辑资源和较高的运行速度[6],且具有低功耗的特点,FPGA往往可以拥有超过GPU的处理速度,同时兼顾能效比,能够满足对CNN的硬件加速条件,因此可用于实现目标检测的实时性要求。文献[7]提出了面向小目标的多尺度Faster-RCNN算法,提升了以低层特征为主要检测依据的小目标检测任务的精度,比原始的Faster-RCNN提高约5%,但是在实时性上略有损失;文献[8]实现了基于Faster-RCNN的快速目标检测,将最后的目标识别阶段的全连接层替换为卷积层实现算法素的提升,损失了部分精确度。Faster-RCNN算法在检测准确度上性能良好,在检测实时性上有待提高,因此文章考虑到实际开发需求,在保证精确度的同时,对Faster-RCNN算法进行加速用于嵌入端设备进行目标检测。
文章在上述工作的基础上对Faster-RCNN算法进行改进,在实时性和准确性之间进行权衡。为提高运算效率并充分利用FPGA的并行计算和流水线技术的优势,将Faster-RCNN算法最后的目标识别阶段的全连接层改为卷积层,实现卷积层的硬件加速,同时在是识别小目标的精度方面采用多尺度的方法,使用标准的区域建议网络(RPN)生成建议区域,并结合较浅层卷积特征图(即conv3和conv4)的特征图用于ROI池。该方法识别准确率高、速度快、模型的鲁棒性高,可以提供高效准确的中小目标检测算法。为此改进的Faster-RCNN设计相应的FPGA加速电路,实现精度和准确度均有所提升的端设备目标检测。
1 算法实现Faster-RCNN算法
Faster-RCNN神经网络利用“区域建议算法”生成位置。但是,传统区域方案算法的计算成本仍然很高,使得其运行时间慢,对实时应用不切实际。一般来说,Faster-RCNN由两个主要部分组成:生成建议区域的RPN和RCNN网络,对区域进行分类[4]。区域建议网络RPN在2D图像中提取可能包含目标的一系列感兴趣区域(ROI)。RPN与目标检测网络共享一些卷积层。最终通过末尾的几个卷积层和全连接层进行最终预测位置框的回归和框内目标的分类。RPN在Faster-RCNN通道中起着重要作用,因为它对分类器[4]的准确性产生重大影响。Faster-RCNN网络结果如图1所示。

图1 Faster-RCNN网络结果
2 改进的Faster-RCNN算法
Faster-RCNN在PASCAL VOC数据集上实现了最先进的性能。它们可以探测人、动物或车辆等物体。这些对象通常占据图像的大部分[9]。然而,在实际的问题中,比如监控拍摄和行人识别手势识别等,检测的物体通常是较小的和低分辨率的物体。Faster-RCNN中的检测网络很难检测到分辨率低的小目标。因为ROI池层仅从一个深层特征图映射构建特征,感受野太大,VGG-16模型从“CONV5”层进行ROI池,经过该层后,矩阵的长和宽均为原来的1/16,如果目标大小小于16个像素,那么即使建议的区域是正确的,投影的ROI池区域也小于“CONV5”层中的1个像素。因此,检测器将很难根据仅来自一个像素的信息来预测对象类别和分类框位置。当然不考虑较为极端的情况,对于中小目标的检测应该做到利用多层信息实现更精准的识别定位。
因此,在Faster-RCNN网络中,采用特征金字塔FPN[10]的思想,结合全局和局部特征(即多尺度)来增强全局上下文和局部信息,利用不同分辨率特征图做融合来提升特征的丰富度和信息含量来检测不同大小的目标,可以帮助鲁棒地检测我们感兴趣的目标。为了增强网络的能力,结合了来自较浅卷积特征图的特征图,即conv3和conv4,用于ROI池化,使得网络可以检测到ROI区域中包含较高比例信息的较低级别特征。同时对于目标分类时的全连接层用卷积层进行替换,增加前向传播的速度,在确保精度的同时可实现卷积层的并行计算,提升算法整体的速度,并在整体设计上采用流水线技术实现资源最大利用。改进的模型图如图2所示。

图2 改进的Faster-RCNN模型
在模型的前两个卷积层中,每个卷积层会连接一个ReLU层、一个LRN层和一个Max-pooling层。在接下来的三个卷积层中,在每个卷积层之后只连接一个ReLU层,并且它们的输出也被用作三个对应的ROI池化层和归一化层的输入,如图2所示。将这些做L2正则化输出级联并收缩,以用作下最后改进的一个卷积层的输入。模型的最后,连接一个用于对象分类的softmax层和一个负责边界框细化的回归函数。
3 面向Faster-RCNN目标识别的FPGA加速器设计
对于目标检测算法,最耗时的部分就是其中的卷积神经网络的卷积运算,尤其是在特征提取阶段的3×3卷积操作占了95%以上的计算量[11]。因此硬件加速部分对Faster-RCNN中的CNN部分进行加速。同时将Faster-RCNN算法最后的目标识别的卷积层在FPGA的PE单元上做处理,提高算法速度。
FPGA是可编程芯片,因此FPGA的设计方法包括硬件设计和软件设计两部分。硬件包括FPGA芯片电路、存储器、输入输出接口电路以及其他设备;软件即是相应的HDL程序以及最新的基于高层次综合的程序方法,底层语言采用Verilog硬件描述语言,高层次语言采用C语言进行开发,开发工具为Xilinx公司推出的Vivado HLS,并实现相应电路的转换,降低开发难度。
硬件FPGA选择ZYNQ UltraScale+MPSoC开发板,该系列是Xilnx公司推出的首款全可编程异构多处理SoC,集成了处理系统(PS)和可编程逻辑(PL)。硬件参数如表1所示。

表1 Zynq UItraScale+MPSoc硬件参数
3.1 整体软硬件协同设计
在进行算法的软硬件实现方案时[12],由于图像预处理和识别结果输出部分与应用的前后端联系紧密,且对计算能力要求低,故可在PC端实现;而目标检测前向计算和识别操作需要计算量大且并行度高,任务内的数据吞吐量相对较高[13],因此该部分通过硬件加速,以充分发挥FPGA的计算优势。系统整体设计如图3所示。
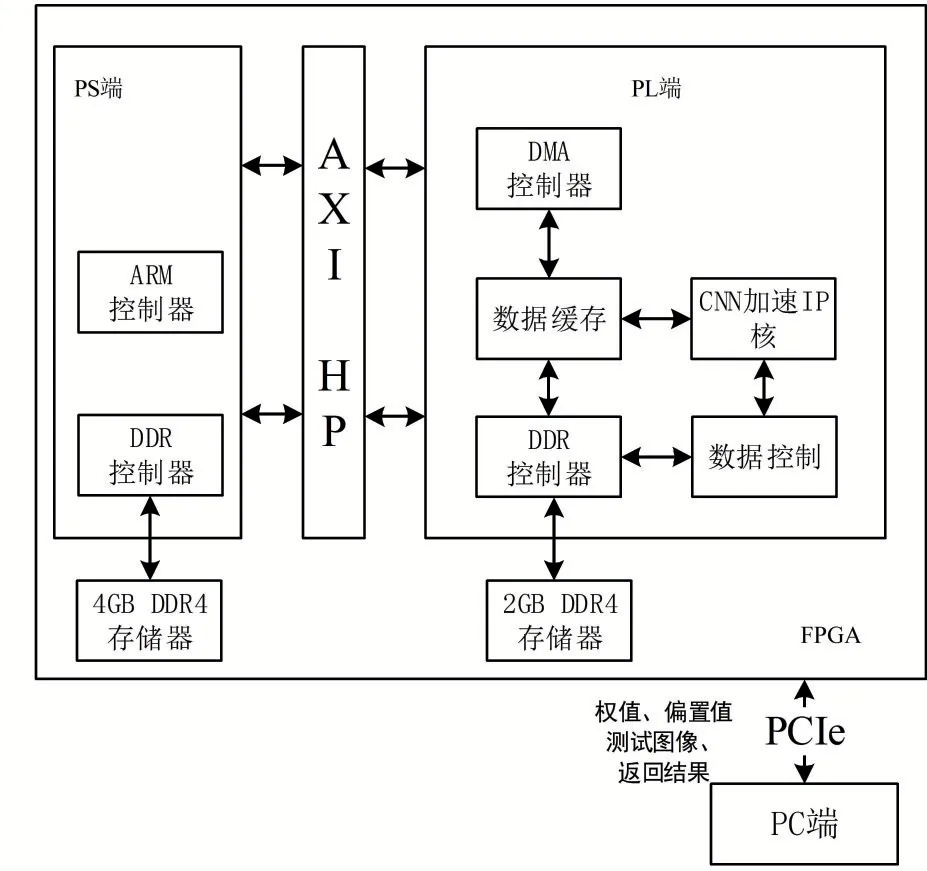
图3 硬件整体设计
在图3中,目标检测总体架构由PC和FPGA两部分组成,PC端承担神经网络训练和调试任务,FPGA承担神经网络的加速任务。其中,外部存储器DDR用于存储目标图像数据与权值,PS与PL协同工作,两者通过AXI_HP口进行数据通信,从而实现各个模块数据与权值的传输。DDR控制器作为数据图像处理的核心,利用AXI4_memory_map获取数据图像信息,经由AXI4_streaming对信息流格式加以处理,以此实现信息统一管理。经过处理后的数据转入加速器完成片上缓存操作,在加速器作用下,缓存区信息得以快速处理,而后通过AXI4总线返回DDR模块[14]。
3.2 CNN加速设计
CNN加速器的基本模型是处理单元(process element,PE)从输入缓冲寄存器获取输入特征,从保存权重值的缓冲寄存器获取权重值,然后从输出缓冲区获取中间结果与本次计算结果累加写回输出缓冲区。结合优化的Faster-RCNN模型和FPGA上的有限资源,设计CNN的硬件加速器部分。由于模型中的参数量大,且中间的特征图数量也很多,网络所有的权值参数和特征图存储在片外存储器。因此,在数据传输中需要设计片上缓存区(FIFO)。计算单元也从缓冲区读取,虽然会减少片上存储资源地占用,但是也会加大带宽和计算时延。因此,文章设计选择将输出特征图的中间结果存储在片上BRAM中,并且对于3×3卷积先进行通道循环,计算完成部分卷积核,再继续计算下一部分的卷积核。
文章优化的Faster-RCNN模型主要包括3×3卷积层、1×1卷积层、最大池化层。在3×3卷积层后直接进行池化计算,输出特征图。在3×3卷积计算出输出特征图的部分通道后,将输出结果缓存在片上BRAM,与1×1卷积层卷积核的对应通道计算,在1×1卷积层计算完成后再将输出特征图缓存在片外存储器,实现各通道并行计算。偏置功能和激活功能在卷积层内部实现。因此将计算分块,并采用流水结构方式实现不同模块并行计算,如图4所示。
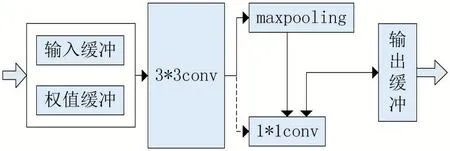
图4 并行模式计算数据流向
对5层conv网络均采用结构内并行和网络间并行的方式设置多个PE单元并行处理,整体加速结构如图5所示。

图5 CNN加速结构设计
在PC端的模型训练完成后,将权重值、偏置值和测试图像通过PCIe接口发送到FPGA端;数据分别存储到DDR4中,DDR4控制器向IP核输入数据,启动加速,IP核则依据流水线的方式计算每层conv网络的中间结果,保存至FIFO缓存单元,CNN加速IP核中所有层运算结束后输出最终识别结果,PL端将该结果以直接内存读取(direct memory access,DMA)方式发送至PS端的DDR4中完成整个神经网络的硬件加速。
4 实验
4.1 实验数据集与网络模型
本实验的数据集采用分辨率较小的Small Ob⁃ject Dataset[15],数据集中包含了小目标的测试数据集:合成细胞、行人、鱼、海鸥、蜜蜂以及苍蝇。图像中的目标只有10~30像素高(图6)。选取其中的honeybee数据集进行测试。

图6 实践数据集
训练所用的图片在输入模型前,统一缩放为1000×600大小,并根据训练集颜色分布的均值和方差进行归一化。对于VGG16网络每个尺度的特征图对应候选区域建议网络的锚点尺寸不同,conv1_2层对应的尺度参数为2,4;conv2_2和conv3_3为4,8;conv4_3和conv5_3为8,16;其余参数均与原始Faster-RCNN一致。
4.2 实验结果
将训练数据分为两部分,一部分用于评估模型的性能,一部分用于模型训练。识别结果如图7所示。

图7 honeybee数据集识别结果
在低分辨率和较小的目标检测实验中,模型给出了较好的实验性能,在准确度和速度上均表现良好。表2是传统的Faster-RCNN与我们改进后的Faster-RCNN的识别结果性能对比。

表2 识别精度和时间对比
从以上实验结果可以看出:采用的改进的Faster-RCNN算法在精度上有明显的提升,对检测目标的定位精度很高,对比原有Faster-RCNN的检测效果有了明显的提升。同时其识别速度较快,在单张GeForce RTX 2080 Ti上的平均识别用时为0.5 s,达到了实时检测的效果,可以运用此方法将该模型应用于日常的较低分辨率的嵌入式目标检测设备中。提高检测的工作效率和准确性。
5 结语
文章采用了软硬件协同的方式基于端到端的Faster-RCNN算法实现了中小问题的目标检测,由于文章是针对特定数据集进行的识别,模型的训练也需要在PC端完成,对于数据的清洗和处理也需要花费时间,因此文章只提出对一种比较典型的与农业生产有关的蜜蜂数据集进行了目标检测的测试。但是考虑到该数据集具有的代表性作用,因此将论文中提出的目标检测方式用于其他生活中类似的目标检测是合理的。而文章中采用FPGA实现算法的加速,同时由于FPGA的可编程和可移植特性,能够用于嵌入式的端检测设备,在该项目的后期工作中,项目组成员会在其他较为典型的小目标数据集上进行进一步的测试,提高算法的鲁棒性和通用性。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
计算机仿真(2022年7期)2022-08-22
计算技术与自动化(2022年1期)2022-04-15
上海师范大学学报·自然科学版(2019年5期)2019-12-13
阅读与作文(英语初中版)(2019年8期)2019-08-27
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
中学生数理化·高一版(2017年1期)2017-04-25
