
基于深度学习的语义SLAM关键帧图像处理
2021-12-08 13:23李宏伟许智宾肖志远
测绘学报 2021年11期
邓 晨 ,李宏伟,张 斌,许智宾,肖志远
1. 郑州大学信息工程学院,河南 郑州 450052; 2. 郑州大学地球科学与技术学院,河南 郑州 450052; 3. 郑州大学水利科学与工程学院,河南 郑州 450001
随着人工智能应用的进步与深度学习的兴起,在同时定位与地图构建(simultaneous localization and mapping,SLAM)中加入机器学习的思想已然成为探索未知环境自主建图方面极有潜力的研究点。文献[1]提出了HOG算子作为特征,并选择支持向量机(SVM)当作试验过程中的分类器,从而进行运动中的行人个体检测,2012年之前,目标检测与识别的过程是采用人工的方式进行图像特征的训练,再选择一种分类器以完成最终的分类任务。经典的物体目标检测任务通常具有3个关键点:①在图像中标记出一定数量不同的候选区;②对标出的候选区进行特征的提取工作;③采用高效的分类器完成分类任务。
伴随深度学习算法和技术的迅速发展,结合卷积神经网络的目标检测算法在大多数场景下均具有良好的检测效果和较强的实时性能。近年来,有学者尝试将融合了深度学习算法的目标检测技术加入视觉SLAM算法过程中,进行实例级的语义建图。文献[2]提出一种实例级的语义地图构建方法,利用SSD目标检测和3D点云分割算法完成帧间目标的检测和数据关联,构建实例级的语义地图。文献[3]设计了一种基于YOLOv3目标检测算法的语义地图构建方案,通过YOLOv3目标检测和GrabCut点云分割法实现实例级的语义建图。文献[4]提出一种实时的移动机器人语义地图构建系统,利用不同帧之间特征点的匹配关系完成物体之间的目标关联,最终构建增量式的语义地图。文献[5]提出了基于Faster R-CNN网络的多物体检测,利用单独的RPN网络进行区域选择,并结合Fast R-CNN网络对不同区域进行分类和回归实现对多物体的检测。文献[6]提出了基于单次拍摄多边界框检测(SSD)的目标检测算法,这种算法能够一步到位地预测出物体的类别,速度更快且效率更高。相较于Faster R-CNN网络,该算法没有基于RPN的区域选择部分,因此提高了检测速度。然而,上述目标检测算法只能获取物体的矩形框,不能很好地实现对物体边界进行精准分割。文献[7]提出了目标实例分割框架Mask R-CNN,其算法框架的创新来源于Faster R-CNN,算法的思路是在Faster RCNN算法中边界框之外补充了一个分支部分,这个模块的主要作用是计算生成目标对象的掩码,从而实现像素级别的物体分割。文献[8]是一个实时分割、跟踪和重建多个物体的语义SLAM框架,通过结合基于条件随机场的运动分割和语义标签来对图像进行实例化的分割,实现重建实例级的语义地图。Mask-Fusion[9]采用了类似的策略,不同的是Mask-Fusion选择直接使用Mask R-CNN算法的网络结构,完成关键帧目标中的语义分割任务,从而获得实例对象的语义信息,最后通过文献[10]中的算法对目标实例进行跟踪并同时构建实例级语义地图。以上工作结合深度学习算法和视觉SLAM技术对采集的图像或视频帧进行目标检测、帧间目标跟踪和语义地图构建,实现了实例级的语义SLAM算法。然而总览已有的各种开源系统,并未发现有科研团队及人员将最新ORB-SLAM3系统进行创新融合或改进,大部分研究和试验仅结合了前代经典ORB-SLAM系统,因此缺乏应用的丰富度和创新性。本文聚焦于最新深度学习与视觉SLAM系统的融合框架构建,完成了新系统中涉及的算法优化和改进,提升SLAM技术的应用丰富性,扩展了其应用范围。
本文针对经典SLAM系统的前端视觉里程计部分,在暴力匹配的基础上使用RANSAC[11]对去除产生的误匹配并通过试验验证了此方法的可行性;提出一种基于Lucas-Kanade光流法[12]的相邻帧特征状态判别法;采用YOLOV4[13]目标检测算法和融合全连接条件随机场CRF[14]的Mask R-CNN语义分割算法对ORB-SLAM3[15]中的关键帧的图像处理。最后,将以上两部分作为独立的新线程中融入ORB-SLAM3系统中,形成一个优化改进后的完整视觉框架。
1 融合语义信息的ORB-SLAM3系统设计
1.1 基于特征点法的视觉里程计
ORB-SLAM是一种使用ORB特征点实现同时定位与制图的方法模型,ORB-SLAM3是在ORB-SLAM系统的基础上经过了两次方法迭代,实现了集视觉SLAM、视觉惯导融合SLAM以及混合地图的开源SLAM系统,并且支持多种视觉传感器。基于特征法的视觉里程计充分利用了图像中特征点对光照强度和环境尺度的稳健性,并且得益于众多成熟的特征匹配[16]算法,是目前视觉SLAM中稳健性较高的视觉里程计的主流方法。
特征匹配是通过在相邻两个图像帧之间比较特征点描述子的方法实现SLAM问题中数据关联和运动跟踪。通过特征匹配可以在相邻图像帧之间得到正确的匹配点对,有利于提高SLAM系统位姿估计的精度。由于特征点仅仅是图像中局部灰度值变化较大的像素点,将会导致在特征匹配的过程中产生一些误匹配,影响SLAM系统的位姿估计精度。因此,去除误匹配是实现特征匹配的一项重要工作。
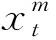
由图1可以看出,暴力匹配得到较多的匹配点对,同时也存在较多的误匹配点对。而且当图像中特征点的数量较多时,使用暴力匹配将会占用较多的计算资源。对于误匹配可以使用快速近似最近邻[18](FLANN)、随机一致性采样(RANSAC)等方法进行误匹配的剔除,得到正确的特征匹配点对。本文使用RANSAC方法进行误匹配的剔除。采用ORB特征和RANSAC算法进行剔除误匹配后的结果如图2所示。

图1 暴力匹配Fig.1 Schematic diagram of violence matching

图2 改进后的匹配结果Fig.2 The improved matching result
1.2 ORB-SLAM3系统概述
ORB-SLAM3是第1个能够用单目、立体和RGB-D相机,并使用针孔和鱼眼镜头模型进行视觉惯性和多地图SLAM的系统,主要创新表现在两个方面:①它是一个基于特征的紧密集成视觉惯性SLAM系统,它完全依赖于最大后验概率估计,包括在IMU[19]初始化阶段也是如此;②它是一个多地图系统,依赖于一种新的位置识别方法和改进的召回,这种改进方法使得ORB-SLAM3能够长时间在较少视觉信息的环境下运行,当保存的地图丢失时,它会启动一个新的地图,然后在重新访问地图区域时,将其与以前的地图无缝地合并。
之前已被广泛应用的ORB-SLAM2由3个平行的线程组成、跟踪、局部建图和回环检测。在一次回环检测后,会执行第4个线程,去执行BA优化。跟踪线程在双目或RGB-D输入前进行,剩下的系统模块能够与传感器模块独立运行。相比ORB-SLAM2系统,ORB-SLAM3新增部分如下。
(1) 地图集。如图3所示,地图集包括一系列分离的地图组成的多地图表示,包括活动地图和非活动地图。活动地图表示当前位置的地图,跟踪线程向其中传入图像帧,并由局部建图线程不断优化及增加新的关键帧扩大规模,其他地图为非活动地图。
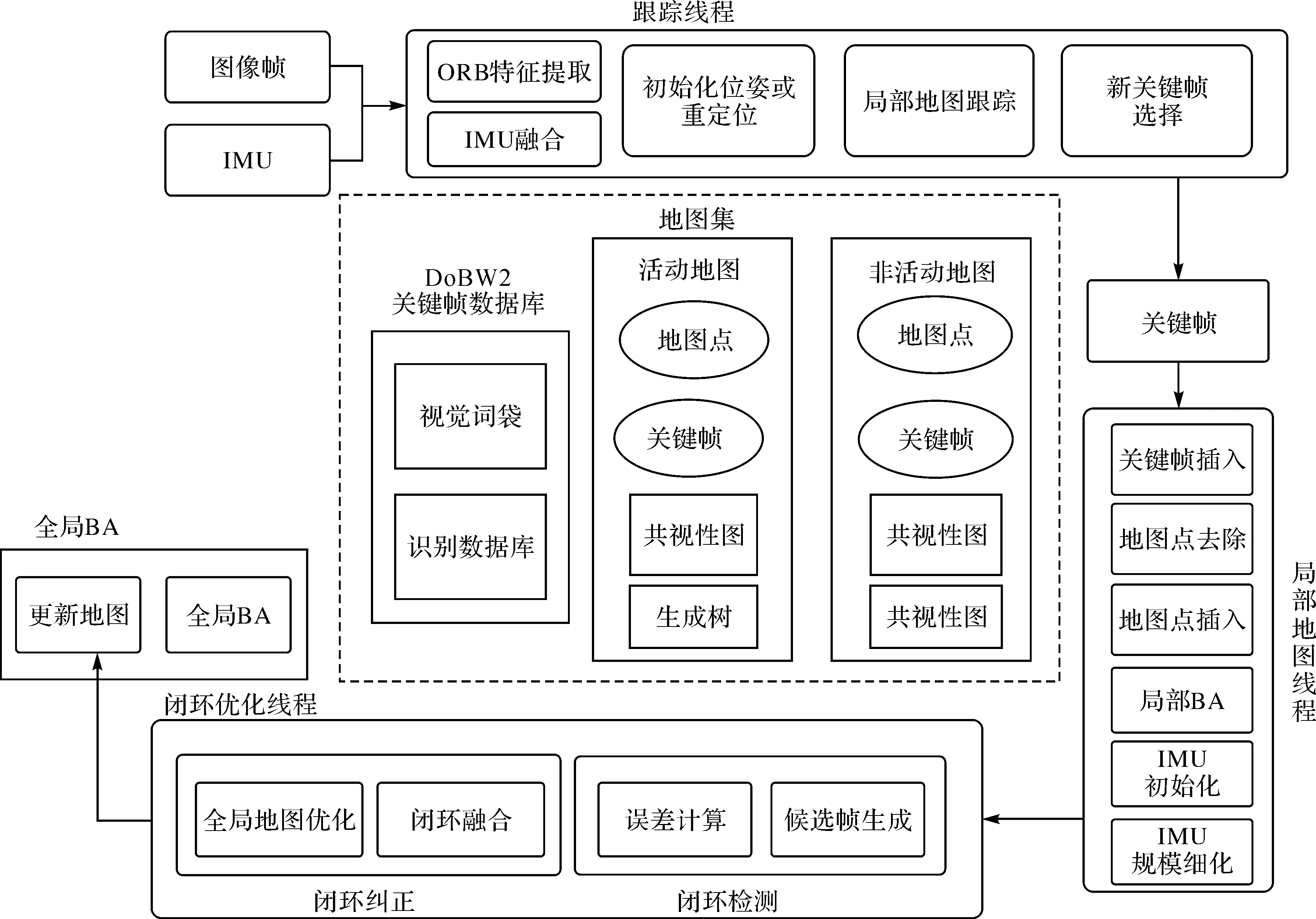
图3 ORB-SLAM3经典框架Fig.3 ORB-SLAM3 classic framework
(2) 跟踪线程。判断当前帧是否为关键帧;实时处理传感器信息并计算当前姿态;最大限度地减少匹配地图特征的重投影误差;通过加入惯性残差来估计物体速度及惯性测量单元偏差。
(3) 局部建图线程。将关键帧和地图点添加到活动地图,删除多余关键帧,并使用视觉或视觉惯性BA优化[20]地图。另外此线程也包括惯性情况下,利用地图估计初始化和优化IMU参数。
(4) 回环和地图融合线程。基于关键帧的速度,对地图集中的活动地图和非活动地图进行相似性度量。每当建图线程创建一个新的关键帧时,就会启动位置识别,尝试检测与地图集中已经存在的任何关键帧的匹配。
1.3 基于Lucas-Kanade光流的动态物体判别法
1.3.1 Lucas-Kanade光流
在Lucas-Kanade光流(图4)中,可以把相机采集到的图像当作是关于时间的函数,在图像中位于坐标(x,y)出的像素点在t时刻的灰度值可以写成I(x,y,t)。图像中t时刻位置为(x,y)的像素点,在t+1时刻它在图像中的位置将会变为(x+dx,y+dy),而这两个位置的像素灰度值应该是相同的,即I(x+dx,y+dy,t+dt)=I(x,y,t)。
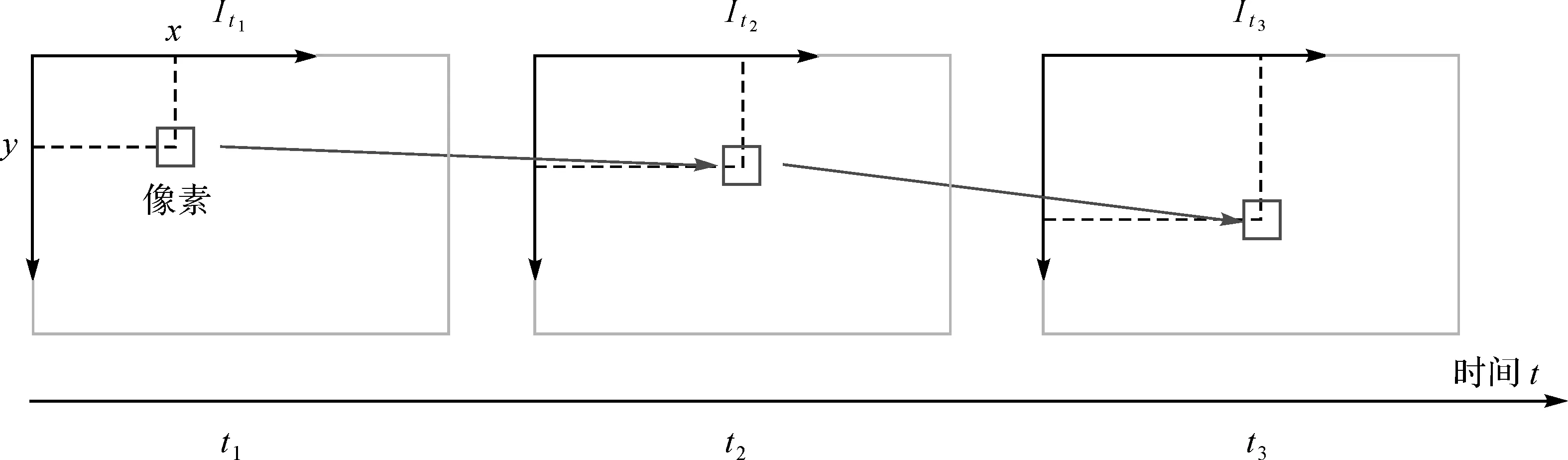
图4 Lucas-Kanade光流Fig.4 Lucas-Kanade optical flow
由于灰度不变,则有
I(x+dx,y+dy,t+dt)=I(x,y,t)
(1)
对左边进行泰勒展开,保留一阶项,得
I(x+dx,y+dy,t+dt)≈
(2)
由于有灰度不变假设[21]这个前提条件,于是下一个时刻的灰度等于之前的灰度,从而
(3)
两边同除以dt,得
(4)
(5)
式中,Ix是像素点在图像中x方向的梯度;Iy是像素点在图像中y方向的梯度。
当t取离散时刻时,通过多次迭代运算后就可以估计部分像素在若干个图像中出现的位置,从而实现像素点得跟踪。
1.3.2 相邻帧特征状态判别法
为了在室内场景中相邻图像帧间进行动态特征的检测和辨别,本文设计了一种基于Lucas-Kanade光流的帧间特征状态判别法:首先,采用光流法进行特征匹配,获得匹配点的像素坐标;然后,根据相机模型得到上一帧相机坐标系下空间点的三维坐标,之后利用坐标变换求出该空间点在下一帧相机坐标系下的三维坐标,再进行投影变换得到该空间点在下一帧图像中的像素坐标;最后,计算匹配点与投影点间的距离。认定当该距离超过阈值时,判定此特征点为动态点,即特征状态发生了改变。
这里记p1、p2为一对匹配正确的点对,它们在图像中的像素坐标记为
(6)
根据相机模型,恢复得到上一帧图像中相机坐标系下空间点的三维坐标P
(7)
利用坐标变换,可得空间点在下一帧相机坐标系下的三维坐标P′
P′=TP
(8)
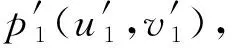
(9)
若距离d大于一定阈值时,即可判定此特征点为动态点。具体算法过程如图5所示。
1.4 语义信息的融合
在本文涉及的视觉SLAM范围内,语义信息反映的是图像中特征点属于不同事物类别的概率情况,语义信息获取的途径是采用计算机视觉技术对图像内容进行检测并识别。在对图像的语义信息进行捕捉和提取时, 有多种相互关联又存在一定区别的任务,本文仅对比目标检测、语义分割和实例分割3种任务过程,如图6所示。
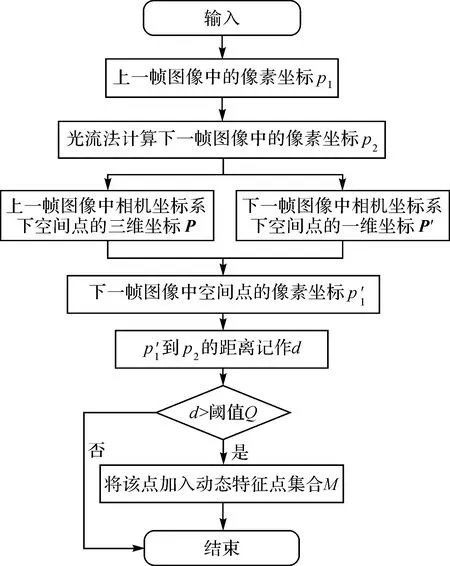
图5 基于Lucas-Kanade光流的帧间特征状态判别法Fig.5 Inter-frame feature state discrimination method based on Lucas-Kanade optical flow
以图6为例,目标检测的主要过程是检测出图中所包含的人和动物,再对其进行逐个标注,然后用矩形框圈出以展示其边界所在;语义分割是实现对人和动物像素级的分类任务, 为了更为直观地展示分割效果,通常使用不同的颜色对其进行填充和覆盖;而实例分割则能够具体标出每只羊,并且精确到每个羊实体的边缘,而不是将图像中的所有羊视为一个整体进行定位和分类。
目标检测、语义分割和实例分割这3种方法均可为经典的视觉SLAM系统及建图结果提供较丰富的语义信息,因此本文研究在ORB-SLAM3的3个线程基础之上加入了两个线程,分别是动态特征检测线程和图像处理线程,语义信息与传统ORB-SLAM3的融合系统架构如图7所示。动态特征检测线程位于图像IMU输入端与跟踪线程之间,该线程首先采用RANSAC算法完成了剔除特征匹配过程中产生的误匹配点,随后结合Lucas-Kanade光流设计了相邻帧特征状态判别法,以实现在室内场景中对相邻图像帧间进行动态特征的检测和辨别,从而减轻动态特征点对前端视觉里程计的干扰和影响程度。图像处理线程则接收来自跟踪线程筛选出的关键帧,采用基于深度学习的YOLOV4目标检测算法对关键帧语义信息进行分类和标注,然后运用基于Mask-RCNN和CRF的算法策略对图像进行语义分割和边缘优化操作,最后将经过图像处理线程后的图像映射到经闭环优化后的点云地图上进行语义融合,最终形成一张完整的三维语义点云地图。

图6 图像识别的3种类型[22]Fig.6 Three types of image recognition[22]
1.5 基于深度学习的室内场景图像检测与分割
1.5.1 Mask R-CNN算法
从网络结构上来看,相比于Faster R-CNN,Mask R-CNN增加了一个用于预测Mask的模块,Mask的作用是为输入的目标对象添加编码,采用正方形的矩阵对每一个ROI[23]进行预测,这是为了维持ROI中的信息完整且避免发生丢失。
Mask-RCNN使用Resnet101作为主干特征提取网络,对应着图8中的CNN部分。ResNet101有两个最基础的模块,分别为Conv Block和Identity Block[24],二者的结构如图9和图10所示,Identity Block输入和输出的维度是相同的,因此可以串联多个;而Conv Block输入和输出的维度是不相同的,因此不能连续串联,原因是它的作用就是为了改变特征向量的维度[25]。
1.5.2 YOLOV4算法
YOLO是一个能实现端到端目标检测的算法,算法内部仅包含一个独立的卷积网络模型(如图11所示,效果图来自开源目标检测算法试验)。YOLO算法经过了多次迭代,如今已经发展到YOLOV4,其作为前代版本YOLOV3的改进版,在YOLOV3的基础上增加了非常多的细节技巧,并且很好地结合了速度与精度。且实际效果上,YOLOV4在YOLOV3的基础上,保证FPS不下降的情况下,使mAP提升到了44%(在MS COCO数据集上的验证)。
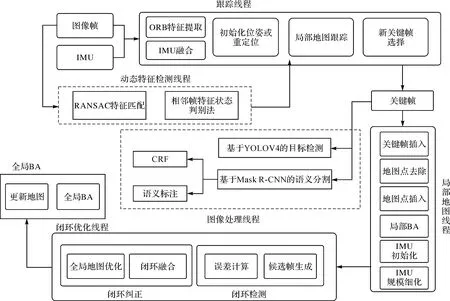
图7 融合语义信息的ORB-SLAM3系统架构Fig.7 ORB-SLAM3 system architecture integrating semantic information
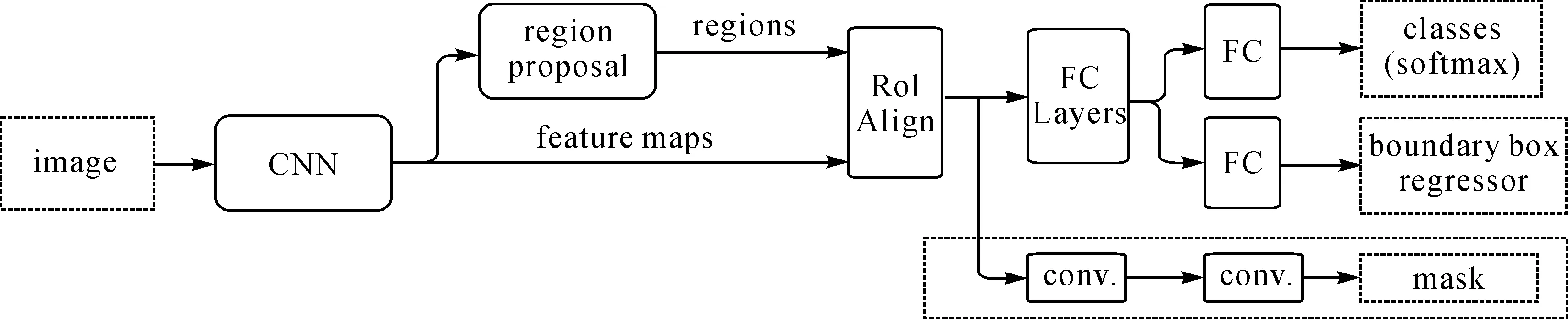
图8 Mask-RCNN网络结构Fig.8 Mask-RCNN network structure
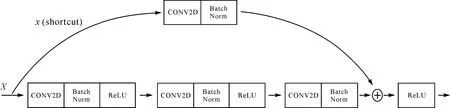
图9 Conv Block结构Fig.9 Conv Block structure
YOLOV3采用的是Darknet53结构,它由一系列残差网络[26]构成,在Darknet53中存在一个resblock_body模块,它由一次下采样和多次残差结构的堆叠构成,而在YOLOV4中,其对该部分进行了一定的修改:①将DarknetConv2D的激活函数由LeakyReLU修改成了Mish,卷积块由DarknetConv2D_BN_Leaky变成了DarknetConv2D_BN_Mish;②将resblock_body的结构进行修改,使用了CSPnet结构。此时YOLOV3当中的Darknet53被修改成了CSPDarknet53,则当输入是608×608时,其特征结构如图12所示。
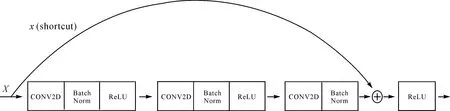
图10 Identity Block结构Fig.10 Identity Block structure
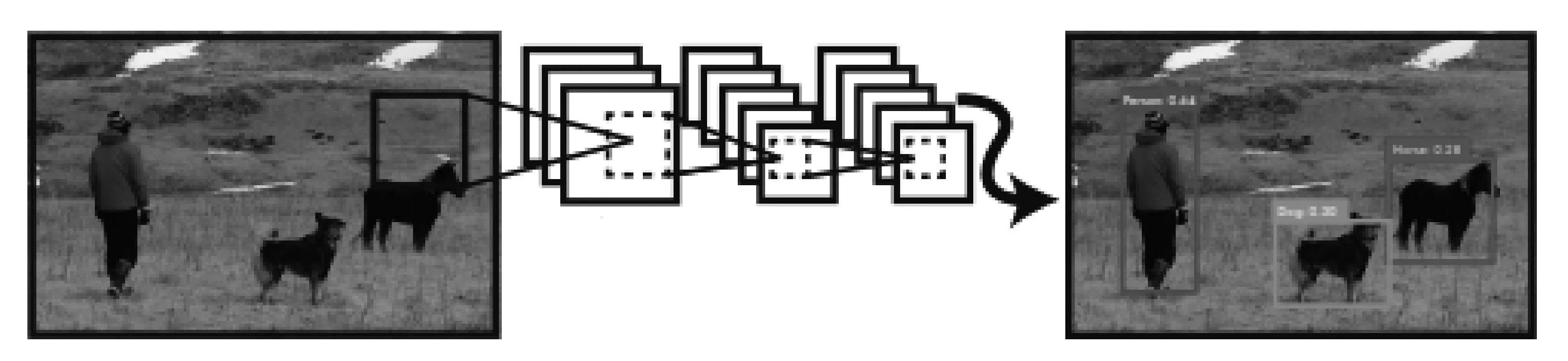
图11 YOLOV4算法实现[25]Fig.11 YOLOV4 algorithm implementation[25]
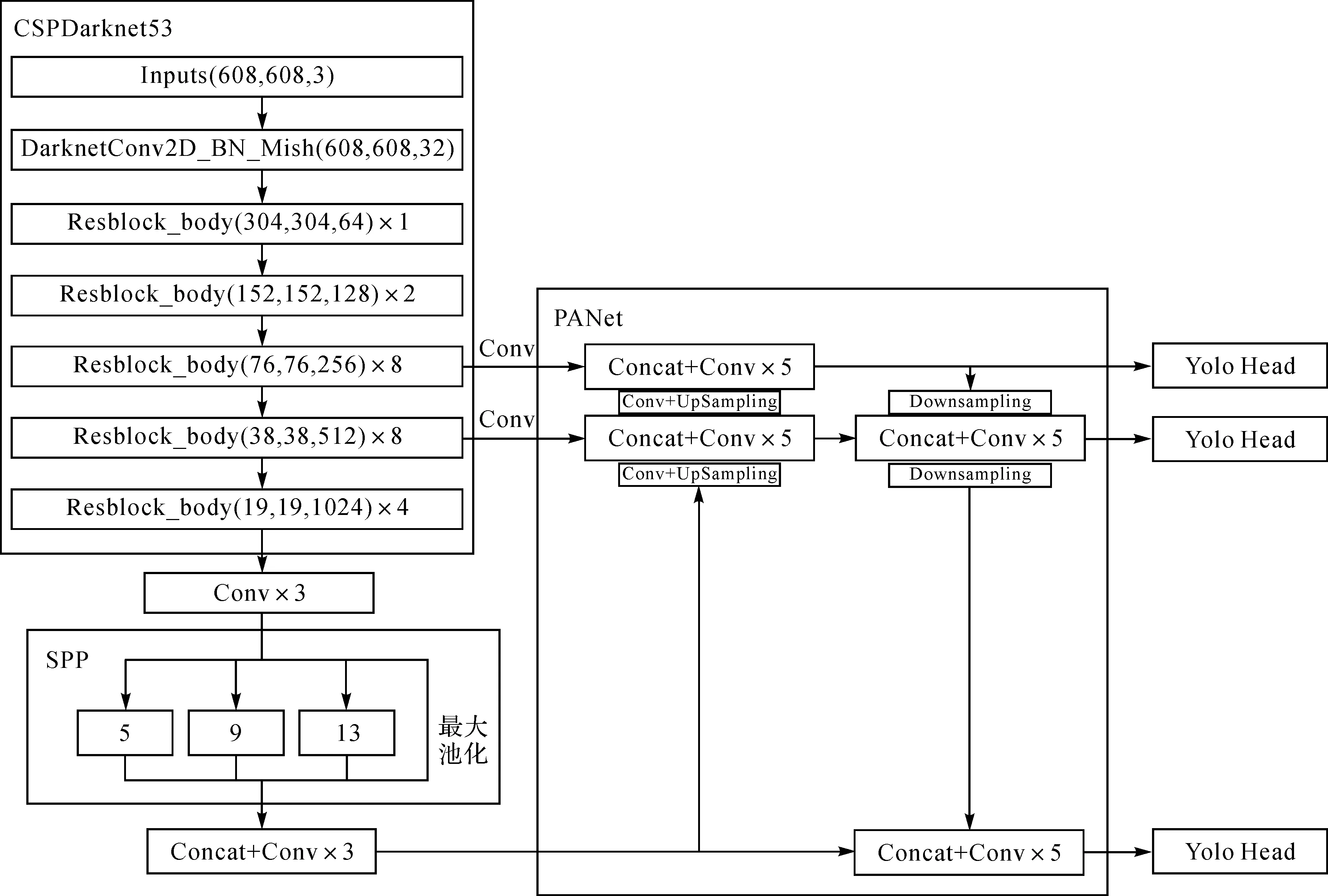
图12 YOLOV4网络结构Fig.12 YOLOV4 network structure
YOLOV4的CIOU将目标对象与锚框间的距离、覆盖率及惩罚类都加入了计算结果的范围内,使得目标框的回归计算更加精准,而不会如IOU或GIOU一般出现训练过程无法收敛的情况,CIOU公式如下
(10)
式中,ρ2(b,bgt)分别为预测框和真实框的中心点的欧氏距离;c为能够同时包含预测框和真实框的最小闭包区域的对角线距离;α是权重函数;影响因子αv把预测框长宽比拟合目标框的长宽比考虑进去。α和v的公式如下
(11)
(12)
则对应的LOSS为
(13)
2 目标检测和语义分割试验
2.1 试验环境及数据集
试验环境:处理器为Intel(R) Core(TM)i7-8700 CPU @3.20 GHz,配有8 GB RAM和Windows10系统,硬盘容量1TB SSD,配置Tensorflow的深度学习框架、OpenCV及其他依赖库。本文试验基于Windows平台,通过Python语言编程实现,应用深度学习框架Tensorflow作为后端的Keras搭建网络模型,下载安装对应版本的CUDA和CUDNN。
试验数据集:MS COCO[27]数据集,其来自微软2014年出资标注的Microsoft COCO数据集,它是一个体量巨大且内容丰富的用于物体检测分割的数据集。该数据集注重对环境内容的理解,全部从复杂的日常环境中获取,图像中目标对象的标定是采用精准分割确定的具体位置。COCO数据集平均每张图片包含3.5个类别和7.7个实例目标,仅有不到20%的图片只包含一个类别,仅有10%的图片包含一个实例目标。因此,COCO数据集不仅数据量大,种类和实例数量也多。
2.2 评价指标
对于多分类目标检测模型而言,分别计算每个类别的TP(true positive)、FP(false positive)及FN(false negative)的数量。TP代表预测框分类预测正确并且CIOU大于设定阈值的预测框数量;FP代表预测框与真实框分类预测错误或者分类预测正确但是两者CIOU小于阈值的预测框数量;FN代表未被预测出来真实框的数量。
精确率Precision代表预测框中预测正确的比例,公式如下
(14)
召回率Recall代表所有真实框中被预测出的比例,公式如下
(15)
AP代表某一分类的精度,即在0~1之间所有Recall值对应的Precision的平均值。mAP代表多分类检测模型中所有类别的AP均值,mAP的值越大,表示该模型的定位与识别的准确率越高。mAP50表示当检测框与目标框CIOU值大于0.5时,算正类样本,本文的评价均使用mAP50作为评价指标来判别模型的效果。
2.3 YOLOV4目标检测试验结果分析
试验采用经典目标检测数据集对YOLOV4模型进行训练并得到训练权重,然后对使用ORB-SLAM3系统跟踪线程处理过的关键帧图像进行目标检测,得到的结果如图13所示,可以看出室内场景的检测效果更好,关键帧中的每个对象拥有更高的置信度。
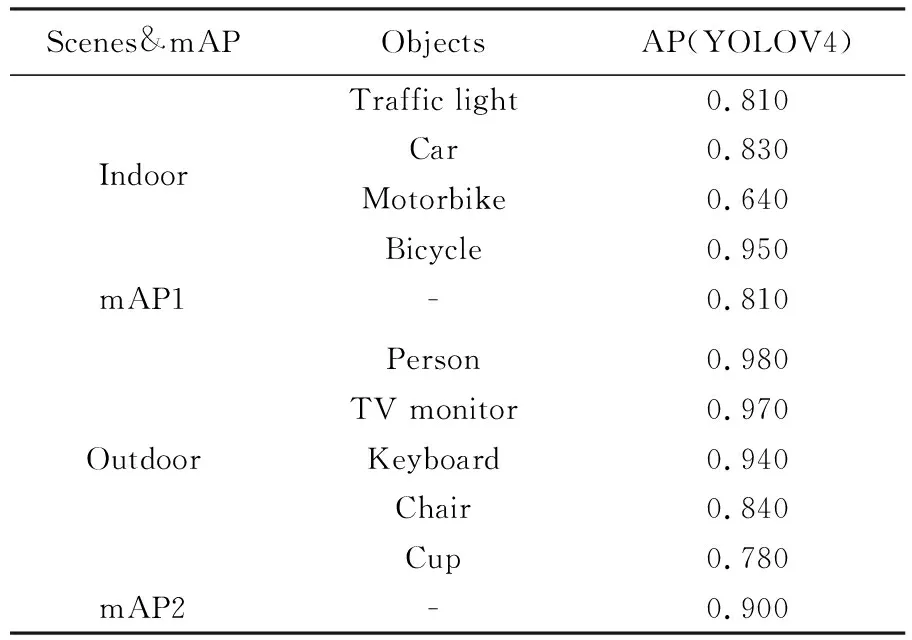
表1 目标检测试验分析
室外图像的平均精度值mAP1值为0.810,室内图像的平均精度值mAP2值为0.900,可以认为YOLOV4模型算法对室内场景下采集到的关键帧图像目标检测试验效果更好。

图13 室内外目标检测试验Fig.13 Indoor and outdoor target detection experiment
2.4 Mask R-CNN语义分割试验结果分析
为了更好地完成对关键帧图像的语义分割试验,本节专门针对图像中物体的分割边缘进行了优化策略,即融合全连接条件随机场CRF的Mask R-CNN算法。在传统研究中,全连接条件随机场CRF通常被用于优化并完善带有部分噪声的分割图像,全连接条件随机场的能量函数为
(16)
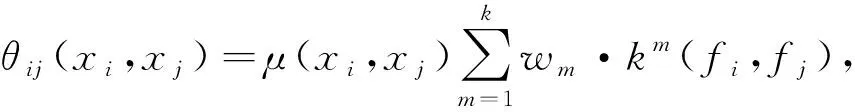
(17)
试验首先将数据集放在系统中一个具体目录下,下载MS COCO 2012数据集,并对Mask R-CNN网络进行预训练,得到卷积神经网络的初始权重;然后运行train.py,使用数据集对网络进行训练,训练后的网络权重;在预测阶段,使用训练后的Mask R-CNN模型融合全连接条件随机场CRF对使用ORB-SLAM3系统跟踪线程处理过的关键帧图像进行语义分割,得到的结果如图14其中虚线部分是预测的物体的边界框,同时在上方标出了每个物体标示出的类别名称和置信度,图14分别对比了室内外场景下融合全连接条件随机场CRF的语义分割和未融合的分割效果,可以明显看出目标对象边缘的细节部分当属融合算法的效果更好。
同样观察mAP的值对试验结果进行分析和评价,则对于所有检测对象类,分析结果见表2。
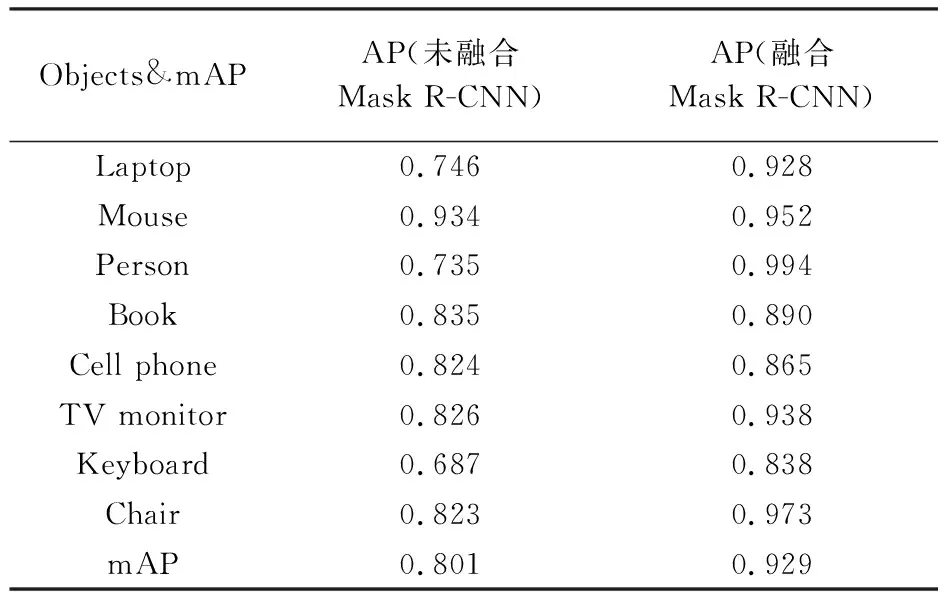
表2 语义分割试验分析
最终融合后的分割mAP值为0.929,大于未融合算法的mAP,则可认为融合后的Mask R-CNN模型算法对采集到的关键帧图像语义分割效果更好且精度更高。
3 结 语
本文针对经典SLAM系统的前端视觉里程计部分,完成基于RANSAC算法的剔除误匹配点试验,验证其良好的匹配和优化效果;研究ORB-SLAM3系统的各个线程模块后提出一种基于Lucas-Kanade光流法的相邻帧特征状态判别法;使用YOLOV4目标检测算法和融合全连接条件随机场CRF的Mask R-CNN语义分割算法对ORB-SLAM3中的关键帧图像进行处理,将以上两部分作为两个独立的新线程中融入ORB-SLAM3系统中,形成一个优化改进后的完整视觉框架。
最终的试验结果表明本文提出的改进算法对关键帧图像的处理精度较高,且每个对象的语义标注效果较好,极大程度地丰富了图像语义信息。在此基础之上的研究可以更好地进行三维点云语义地图的构造与建立,有效提高机器人等智能设备对室内环境的感知能力。
猜你喜欢
开放教育研究(2020年2期)2020-03-31
网络安全技术与应用(2020年1期)2020-01-07
大连理工大学学报(2017年4期)2017-08-07
环球市场(2017年36期)2017-03-09
现代语文(2016年21期)2016-05-25
重庆交通大学学报(自然科学版)(2016年1期)2016-05-25
西北工业大学学报(2015年3期)2015-12-14
大连民族大学学报(2015年2期)2015-02-27
电子设计工程(2011年21期)2011-07-13
外语学刊(2011年1期)2011-01-22
