
融合点云和多视图的车载激光点云路侧多目标识别
2021-12-08 13:23方莉娜沈贵熙游志龙郭迎亚付化胜赵志远陈崇成
测绘学报 2021年11期
方莉娜,沈贵熙,游志龙,郭迎亚,付化胜,赵志远,陈崇成
1. 福州大学数字中国研究院(福建),福建 福州 350002; 2. 福州大学计算机与大数据学院,福建 福州 350002; 3. 福建省水利水电勘测设计研究院,福建 福州 350002
道路两侧行道树、车辆及杆状交通设施(路灯、交通标志牌)是重要的路侧设施和目标,其位置姿态、种类和语义信息是高精地图中描述静动态交通信息的核心要素[1],对于智能交通,导航与位置服务,自动驾驶和高精地图等行业具有重要作用。车载激光扫描系统作为快速发展的新型测绘技术,能够快速、准确地获取道路及其两侧地物高精度的三维空间信息,被广泛应用于城市交通信息的采集和更新[2-3]。由于车载激光扫描系统采集城市场景具有目标丰富、点密度分布不均、数据缺失以及路侧地物复杂多样等特点,从车载激光点云中自动且高精度分类路侧目标仍具有较大挑战[4]。
近年来,国内外研究学者分析行道树、车辆及杆状交通设施的局部或全局基础特征[5-6],将人工构建的高程、强度、法向量等特征利用决策树、随机森林、BP神经网络等机器学习模型进行行道树、车辆、建筑物等的提取与识别[7-8]。对于具有较大差异的路侧目标,这些基础特征能取得较好的识别精度;对于相似或部分缺失的路侧目标,这些基础特征经常表现不足[9]。随着人工智能技术快速发展[10],一些学者将分割后的目标进行体素化或转化为图像,利用深度置信网络(deep belief network,DBN)、深度玻尔兹曼机(deep Boltzmann machines,DBM)等深度模型提取行道树、车辆及杆状目标的高阶特征进行分类[11-12]。文献[13]则率先基于多视角图像进行物体分类研究,通过将3D目标投影成多视角图像,利用卷积运算模块(convolutional neural networks,CNN)构建多视角图像卷积神经网络(multi-view CNN,MVCNN)实现3D目标的准确识别。文献[14]为ModelNet数据集[15]中每个3D目标生成20个视角图像,采用预训练AlexNet[16]作为MVCNN-MultiRes模型的初始化网络,然后利用多视角数据进行模型参数微调,实现3D目标的识别分类。此外,文献[17]认为从内容相似的视图提取的特征具有相似性和冗余性,基于视图分组的思想提出了组视图卷积神经网络(group-view convolutional neural networks,GVCNN),对3D目标的多视图进行分组赋权以区分不同视图的重要性,实现对三维目标的准确识别。文献[18]则从多视图之间相似性度量的角度,利用双线性池化操作聚合视图的局部卷积特征以获取更具判别性的全局特征。这些方法将非结构化点云转换成规则表示,可以利用较为成熟的深度模型提升相似或部分缺失的路侧目标的识别精度,但需要利用视图间的关系,克服相似视图特征的冗余性对特征描述子可区分性的影响。
此外,部分学者基于物体原始点云展开分类研究,文献[19]提出PointNet,实现以原始点云作为模型输入,开启了点云端到端(end-to-end)深度学习模型的新纪元。受PointNet的启发,一些学者聚焦于如何逐点学习并聚合不同特征形成点云对象几何描述[20],相继提出PointNet++[21]、Mo-Net[22]、PointCNN[23]等模型。为解决点云邻域特征聚合难题,文献[24]在PointNet++网络的基础上,提出自适应特征调整(adaptive feature adjustment,AFA)模块,通过引入局部邻域的上下文特征自适应学习不同方向特征来聚合点云局部几何信息。文献[25]提出点云的空间卷积层(kernel point convolution,KPConv),利用一系列带有权重的核点(kernel points)构建3D卷积核,实现对点云数据的卷积操作进行空间域点云特征聚合。文献[26]提出动态图卷积神经网络(dynamic graph CNN,DGCNN),通过K近邻图建立点云局部邻域结构,引入图结构卷积层EdgeConv动态学习不同图结构中节点特征,增强网络的局部特征提取能力,取得较好的点云分割和分类结果。相对于视图而言,基于离散点的深度学习模型受点云卷积核大小和感受野的限制,能够较好地描述点云局部几何信息,但需要利用较深的网络结构提取目标全局特征,同时模型需要大量的逐点标记样本。近年来,一些学者研究将点云和图像(视图)数据进行融合,同步或分层次提取图像(视图)中目标全局特征和点云局部特征,聚合视图和点云特征进行目标分类[27-29]。这些研究利用不同模态的数据特点,促使深度模型能够学习更完备的多层次、多尺度目标特征,在公开数据集KITTI[30]、ModelNet40[15]和ScanNet[31]上取得了很好的分类效果。但这些方法未区分不同模态数据特征对目标识别的重要性,存在信息冗余现象,且大部分研究都围绕公开数据集展开,较少应用于车载激光扫描系统获取的实际大范围复杂城市场景点云。
针对城市场景中行道树、车辆及杆状交通设施等路侧地物形态各异、复杂多样,基于单一数据形态的深度模型对于相似或部分缺失的路侧地物较难取得很好的分类效果,而点云和视图融合的深度模型存在信息冗余等问题,本文提出一种融合点云和多视图的车载激光点云路侧目标识别模型PGVNet:①基于多视角图像分组融合思想,建立视图-组-形状(view-group-shape)的视图特征分组模块,学习不同道路场景中路侧目标点云与视图之间的关系,自适应学习视图的重要性,提取不同场景路侧目标最优视图特征。②引入注意力机制,构建视图-点云特征聚合机制,利用点云和视图之间的相关性,以最优视图特征动态指导PGVNet模型对不同点云局部结构的关注力度,融合视图和点云特征以学习路侧目标多层次、多尺度全局形状特征。
1 融合点云和多视角图像的深度模型PGVNet
PGVNet模型以独立路侧目标点云及其8个视角的图像作为输入,输出为各类别的预测概率值,其主要包括3个模块:①路侧目标点云特征提取,提取点云局部特征作为初始嵌入点云特征;②基于分组赋权的路侧目标最优视图特征提取,动态获取不同目标的最优视图特征;③基于注意力机制的点云-多视图特征融合,利用最优视图特征指导点云提取全局特征。最后PGVNet模型将嵌入式视图特征与点云全局特征输入全连接层(full connected layers,FC)构成的分类器进行行道树、车辆及杆状交通设施的识别,其网络结构如图1所示。为了将路侧目标从离散点云中分割出来,本文先采用布料模拟算法(cloth simulation filter,CSF)[32]滤除地面点云,然后利用基于连通分支(connected component)[33]的聚类算法和基于体素的归一化割(normalized cut,Ncut)[34]算法将面上点云分割成独立目标。
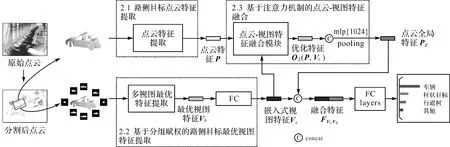
图1 融合点云和多视图的路侧多目标识别深度学习模型:PGVNetFig.1 Architecture of the proposed PGVNet
1.1 路侧目标点云特征提取
由于路侧地物复杂多样、形态各异,同时因遮挡、点云分割质量等因素的影响,会导致路侧地物存在不同程度的残缺,相同类别的地物在形状、姿态及完整度上都存在较大的差异。为了提取路侧目标可区分的局部几何信息,本文采用DGCNN中空间变换辅助网络(spatial transform network,ST)和EdgeConv模块作为骨架网络构建点云特征提取模块,如图2所示。ST网络位于网络前端,主要学习点云的空间置换不变性。该网络以路侧地物原始点云为输入,通过逐点构建K近邻图结构获取点云几何特征,并利用多层感知机进行姿态特征学习,输出变换矩阵(3×3)并与原始点云数据进行乘积获得经过对齐后的点云数据表示,确保深度网络能够识别旋转变换后的同一路侧目标点云。
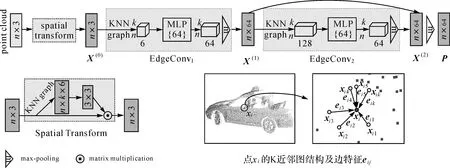
图2 基于EdgeConv的点云特征提取Fig.2 Point cloud features extraction based on EdgeConv module
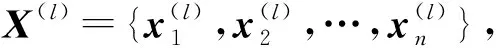
(1)
(2)
P=maxpool([X(1)‖X(2)])
(3)
式中,hΘ:RF×RF→RF′是由一组可学习的参数Θ构成的非线性函数;F及F′是特征维度;X(l)表示第l层EdgeConv模块提取的局部几何特征;‖表示矩阵拼接操作(concatenation operation)。
1.2 基于分组赋权的路侧目标最优视图特征提取
受限于车载激光点云点密度、感受野和模型效率等因素影响,EdgeConv模块可以较好地提取点云局部几何信息,但较难获取路侧目标全局信息。因此本文将路侧目标投影成多视角图像,利用卷积网络获取路侧目标最优视图特征作为全局特征,以此指导构建不同点云局部特征之间的关系,实现更精确的路侧目标识别。
对于给定的独立路侧目标,以其原始点云坐标系X轴正方向为初始视角方向,在垂直该方向的平面上对目标点云进行规则格网剖分,若格网中存在点则标记格网值为“1”,否则标记为“0”。基于此,以面向对象中心按逆时针旋转,等间隔生成个尺寸为224×224的多视角图像,如图3所示。
为了降低模型训练的样本、资源要求,本文采用基于微调的深度迁移方法,首先利用在ImageNet[35]数据集上预训练好的VGG16模型初始化多视角图像特征提取模块,然后利用多视角图像进行微调。在PGVNet中以VGG16的Conv4-3及之前的网络结构构建共享权重的视图卷积层(fully convolutional network,FCN),提取初始视图特征fi,其中i∈[1,],以VGG16中Conv5构建共享权重的多层感知机(multi-layer perceptron,MLP)提取路侧目标的视图特征Fi。
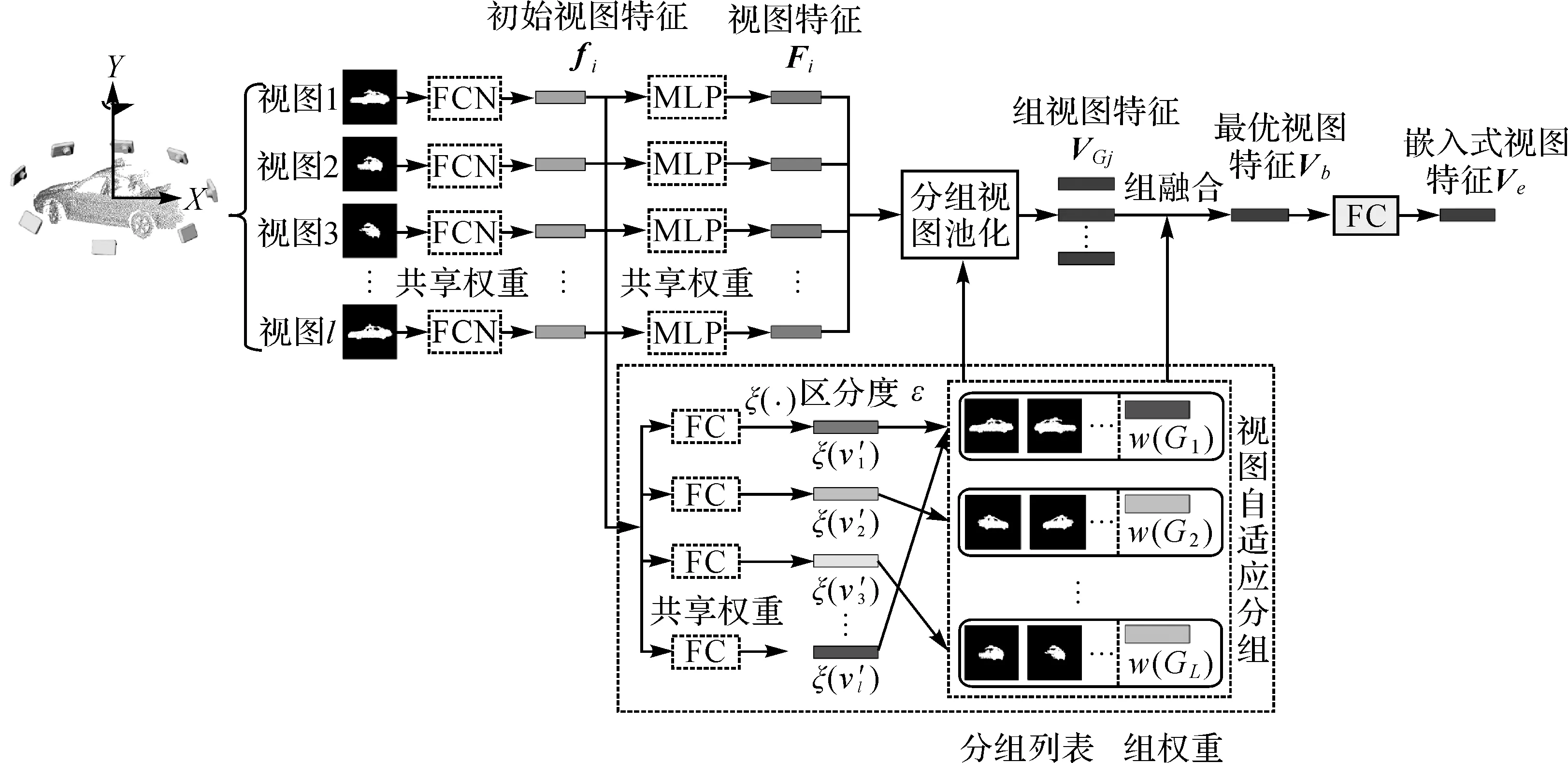
图3 基于视图分组的最优视图特征提取Fig.3 Optimal views feature extraction based on view grouping
1.2.1 视图分组与组权重w(Gj)
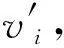
(4)
(5)
式中,ξ(·)∈(0,1);sigmoid(·)为全连接网络(FC)采用的激活函数;|Gj|表示视图组Gj中的视图数量;j∈[1,L]。
1.2.2 组视图特征VGj
为了聚合同一视图组内的视图特征信息,减少冗余信息,本文利用池化层将同一组内的视图特征融合成组视图特征VGj
(6)
式中,λi为判定系数,表示视图i是否属于视图组Gj,若视图i属于视图组Gj,则λi=1,反之,λi=0。
1.2.3 最优视图特征Vb
为了挖掘不同视图间的潜在关系,获取具有显著性的视图特征,本文将L个组视图特征VGj进一步融合,利用视图组权重w(Gj)及组视图特征VGj计算路侧目标的最优视图特征Vb
(7)
利用全连接层(FC)将路侧目标的最优视图特征Vb映射到点云特征空间生成嵌入式视图特征Ve,用于后续点云特征与视图特征的融合。
1.3 基于注意力机制的点云-视图特征融合
为了融合点云的空间几何特征和视图中高级全局特征,PGVNet融合注意力机制,以嵌入式视图特征Ve自适应指导点云局部特征P学习其关注的路侧目标不同局部结构的注意力度。随着网络的加深,注意力机制能指导网络更多地关注具有区分性的特征和区域[28],因此本文构建了两个注意力融合模块,如图4所示,注意力融合模块Ⅰ主要学习路侧目标中级几何特征,注意力融合模块Ⅱ则学习路侧目标高级几何特征。
(1) 注意力融合模块Ⅰ。如图4所示,假定输入是由n个点生成的点云局部特征P和嵌入式视图特征Ve,为了将不同维度的点云局部特征P和嵌入式视图特征Ve进行融合,本文将Ve重复n次后与点云局部特征P相连接,作为二者的关系特征φ1(P,Ve),并使用多层感知机对关系特征φ1(P,Ve)进行自适应学习;然后通过归一化函数ζ(·)将其转化到(0,1),从而生成软注意力掩膜Sa1(P,Ve),表征不同点云局部结构特征的重要性
φ1(P,Ve)=[n*Ve‖P]
(8)
ζ(·)=sigmoid(log(clip(abs(·))))
(9)
Sa1(P,Ve)=ζ(MLP(φ1(P,Ve)))
(10)
式中,clip(·)函数为约束函数,用于将输入中为零的值替换成极小值10-8,避免log(·)函数无意义。
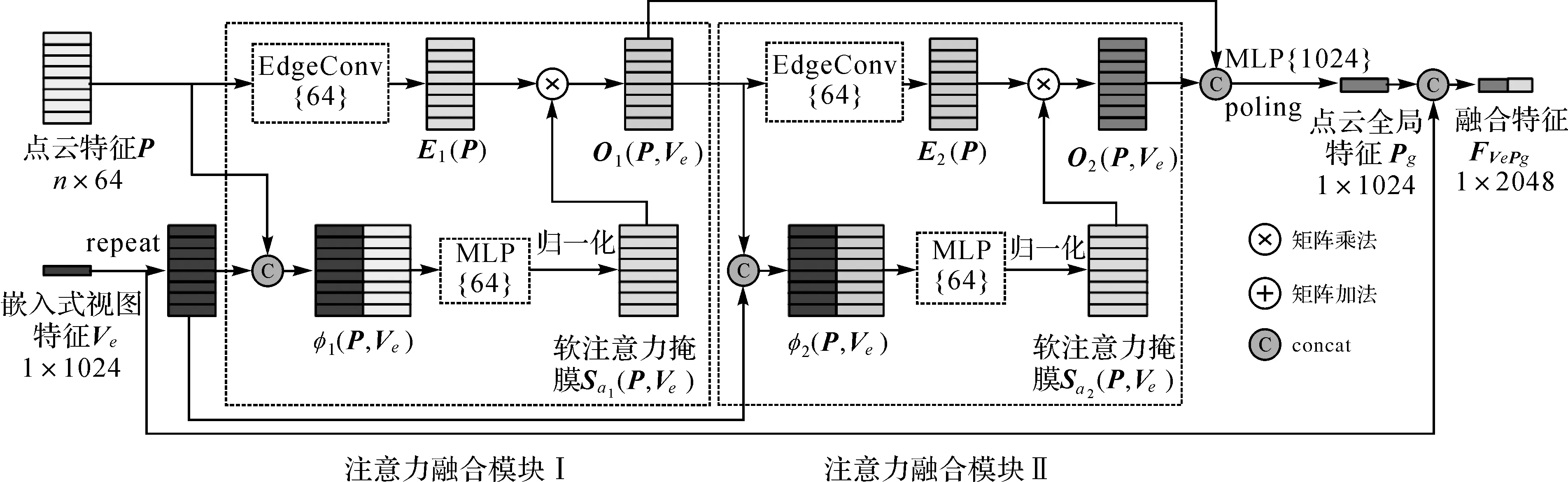
图4 基于注意力机制的点云-视图特征融合模块Fig.4 Point-view feature fusion block based on attention mechanism
此外本文在注意力融合模块Ⅰ中采用一层EdgeConv模块学习更深层的点云局部特征E1(P),将软注意力掩膜Sa1(P,Ve)以点乘的方式应用于E1(P)生成增强后点云特征O1(P,Ve),增强更具区分性的点云局部特征并抑制无用特征
O1(P,Ve)=E1(P)*Sa1(P,Ve)
(11)
(2) 注意力融合模块Ⅱ。为进一步学习路侧目标的高级几何特征,本文将优化后的点云局部特征O1(P,Ve)输入第2个注意力融合模块中,以相同的方式学习深层点云局部特征O2(P,Ve),然后将优化后不同层次的点云局部特征O1(P,Ve)与O2(P,Ve)合并,并利用多层感知机获取点云全局特征Pg
Pg=maxpool(MLP([O1(P,Ve)‖O2(P,Ve)]))
(12)
合并嵌入式视图特征Ve和点云全局特征Pg,作为当前路侧目标的点云-视图融合特征FVePg
FVePg=[Ve‖Pg]
(13)
1.4 损失函数
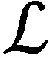
(14)
(15)
2 试验与分析
2.1 试验数据
为验证本文方法的有效性,本文选取了由不同激光扫描系统在不同区域获取的3份训练数据和5份测试数据对PGVNet模型进行训练和验证,具体信息见表1。本文预先利用文献[12]中的面上地物提取方法从选定数据集中分割出行道树、杆状交通设施和车辆等路侧独立目标,如图5所示。

图5 不同道路场景的训练数据集和测试数据集Fig.5 The training datasets and testing datasets of different road scenes
3份训练数据全部为车载激光扫描系统获取的城区场景,训练数据Ⅰ中车辆较多,且类型多样、方向姿态差异较大,同时存在不同程度残缺;训练数据Ⅱ来自公开数据集Paris-Lille-3D[36]的城市街区数据,数据量小但地物类别齐全、完整度高;训练数据Ⅲ中包含的各类地物数量较为均衡,同时行道树及车辆存在不同程度的残缺。3份训练数据中各类地物具有很好的代表性及完备性,能够满足本文模型训练要求。本文从分割后的训练数据中提取不同形状、 姿态的行道树、车辆、杆状交通设施作为正训练样本,其数量分别为113、190和146,提取行人、垃圾桶和自行车等105个地物作为负训练样本。同时通过平移、旋转、添加抖动噪声等数据增强操作,将基础样本扩增成每类地物500个样本作为训练数据,50个样本作为验证数据。
测试数据集在场景和数据质量上与训练数据具有一定差异,但都包含行道树、车辆以及杆状交通设施等路侧目标,如图5(b)所示。测试数据Ⅰ是所有测试数据中数据量最大的城区场景,道路两侧包含大量不同类别的行道树、车辆以及杆状交通设施;测试数据Ⅱ为郊区数据,道路一侧是高大修长的行道树,另一侧则是小型行道树及路灯;测试数据Ⅲ道路中间包含绿化带,存在较多地物遮挡导致点云残缺的情况;测试数据Ⅳ是围绕大型体育场周边场景的数据,车辆停放姿态各异,点云残缺的车辆较多;测试数据Ⅴ包含较多小型行道树,受遮挡影响存在较多仅含冠层的行道树。
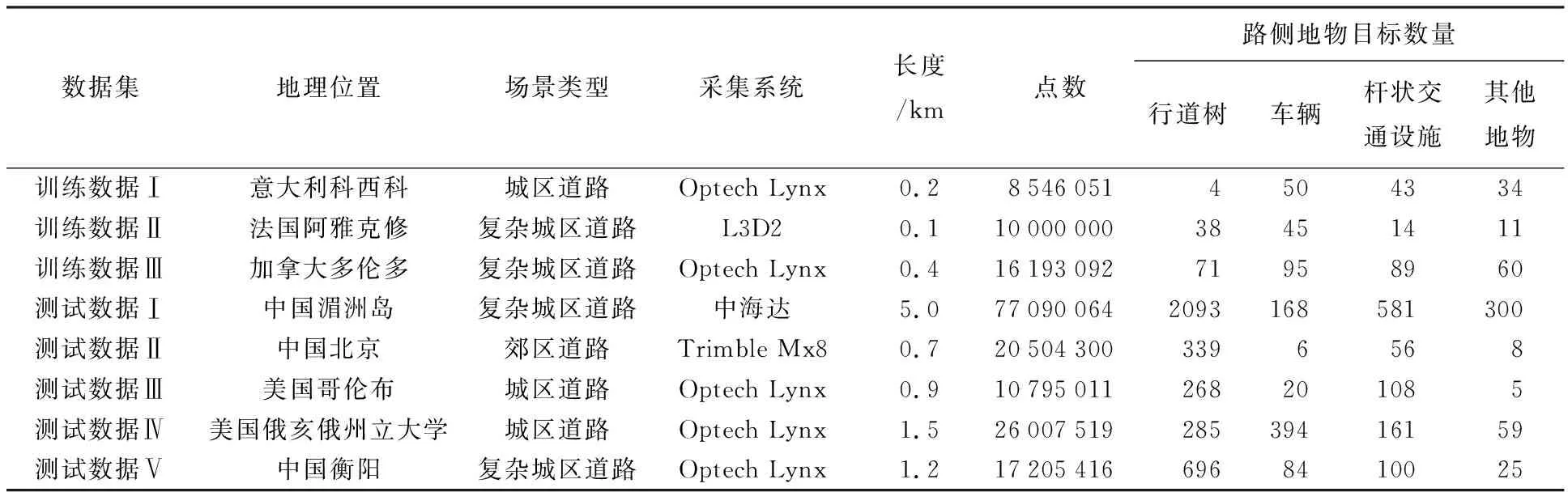
表1 试验数据集基本信息
2.2 模型配置及超参数设置
本文PGVNet模型基于Python 3.5构建,主要使用的库有Tensorflow_GPU 1.8.0,CUDA 9.0,cuDNN 7.0等,所有试验均在配置为NVIDIA GeForce GTX 1080ti 11 GB的环境上运行。由于PGVNet模型中视图特征提取模块由预训练的模型参数进行初始化,在模型训练初期具有较好的特征提取能力,因此本文采用交替训练的策略进行模型的训练:在前10轮次(epoch)训练中冻结最优视图特征提取模块的网络参数,仅更新其余网络层的参数;10轮次以后,开始更新模型的所有参数,让特征提取模块学习当前训练数据中特有的信息。受GPU限制,综合考虑训练精度与时间效率,本文将批处理大小(batch size)设置为32,初始学习率为0.001,训练轮次设置为30,采用带动量(momentum)的随机梯度下降(stochastic gradient descent,SGD)优化策略,对PGVNet网络进行训练和参数更新。
PGVNet模型训练过程中EdgeConv模块中K邻域值及多视图分组模块中分组阈值ε,对模型训练结果具有重要作用。对于路侧地物目标,k值过小或太大都难以提取有效的局部几何特征。对于分组阈值ε,取值过大会导致视图区间太大难以区分视图间的差异性,过小则无法有效削弱冗余信息。本文在分组阈值ε为0.1的前提下,采用对比试验,并以3份训练数据的总体精度作为评价指标,对不同k邻域大小进行测试。如图6(a)所示,当k邻域值为10时,本文方法分类效果最好,因此本文采用k=10进行路侧目标点云局部几何特征提取。在k=10的基础上,以不同分组阈值ε进行试验,结果如图6(b)所示,当分组阈值ε为0.1时,试验结果总体精度最优。因此本文将PGVNet模型超参数k和ε分别设置为10和0.1进行模型验证并统计试验结果。
2.3 试验结果
基于训练好的PGVNet模型,5份测试数据的路侧目标分类结果如图7所示。由图7可以看出,本文构建的融合点云和多视角图像的深度模型能够准确识别绝大多数路侧目标,不仅能够准确区分形状差异较大的行道树、车辆和杆状交通设施(场景D和F),对于具有不同形状、大小、姿态的同一类地物也能很好地识别,具有较强的稳健性(场景A和B)。对于因遮挡或分割处理导致的残缺车辆(场景E、F和G)以及一些缺失树干但冠层较为完整的行道树(场景H),本文方法均能准确的对其进行识别,在一定程度上克服了原始数据质量及分割结果对路侧多目标识别的影响。
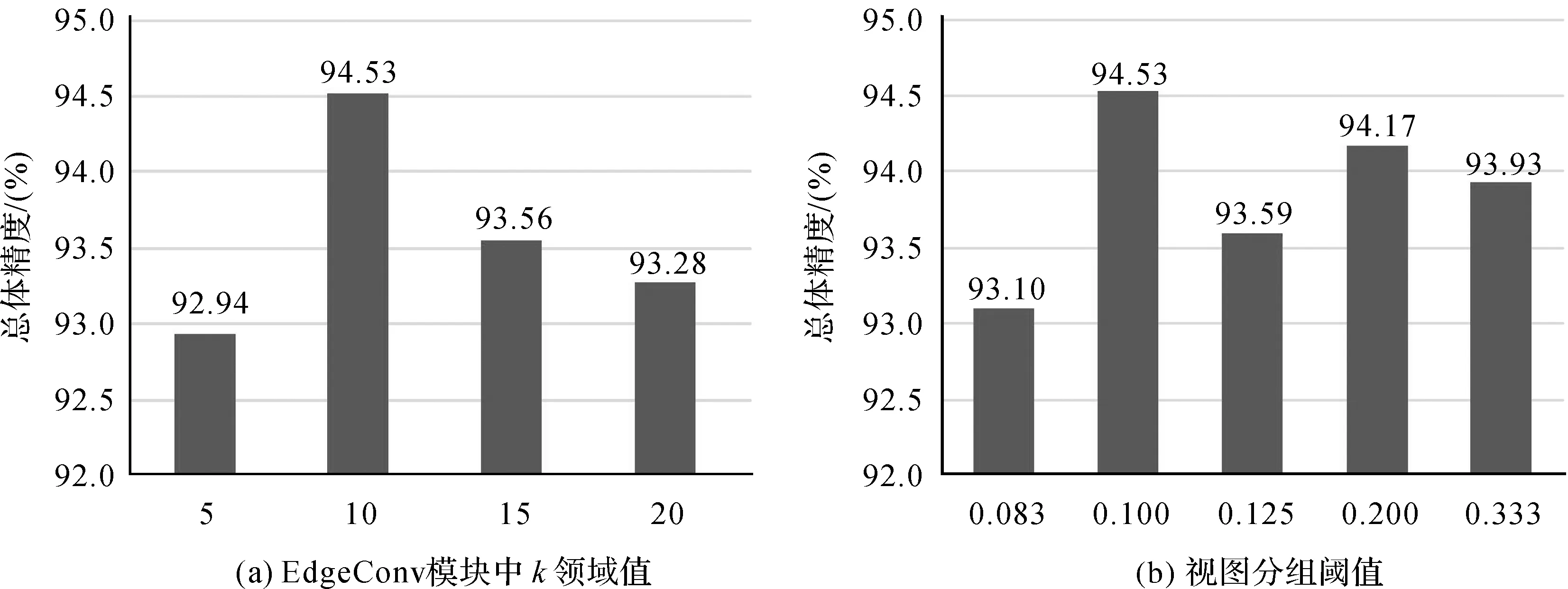
图6 PGVNet模型中超参数k和ε设置Fig.6 The configuration of parameters k and ε
2.4 试验结果分析与精度评价
由于测试数据缺少真实的地物类型参考数据,本文通过CloudCompare软件,从测试数据中人工标定出不同的地物类别标签。试验结果精度评价中将独立地物目标视为参考对象,采用如下4个公式作为评价指标
综合评价指标
式中,n为点云对象的类别数;TPi为网络对第i类地物预测正确的数量;FPi为网络对第i类地物预测错误的数量;FNi为网络未能识别的第i类地物的数量。分别统计5份数据中3类路侧目标的分类精度,结果见表2。
由表2可以看出,5份测试数据中行道树、车辆和杆状交通设施3类典型地物的平均准确率、平均召回率、平均精度和平均综合评价指标分别达到了(99.19%、94.27%、93.58%、96.63%),(94.20%、97.56%、92.02%、95.68%)和(91.48%、98.61%、90.39%、94.87%),表明本文方法能够精确识别城市场景中的大部分地物目标。
总体而言,本文方法对于行道树和车辆分类效果要好于杆状交通设施,主要原因在于大部分行道树和车辆的深层特征具有较高的区分度。测试数据Ⅴ中一些小型行道树或无冠树干与杆状交通设施形状较难区分,存在部分混淆的情况,导致行道树召回率相对较低。测试数据Ⅰ场景庞大,因遮挡等原因存在一些与训练数据集中样本相似性较低的地物;同时也存在路障等一些在训练样本集中没有的地物,导致这些地物被错分成车辆或者杆状交通设施(如图8场景A),从而降低了测试数据Ⅰ中车辆和杆状交通设施的准确率和召回率。相较而言,PGVNet模型在测试数据Ⅱ和Ⅲ中取得了较好的分类结果,4个分类指标均在94.91%以上,虽然两份数据中的行道树、杆状交通设施等地物差异较大,但本文方法在一定程度上能克服路侧地物形状差异带来的影响,具有较好的稳健性和泛化能力。在测试数据Ⅳ中,由于存在大量背向道路的车辆,部分车辆仅有少量头部或尾部区域的信息(如图8场景B),其形状、大小与负样本中的垃圾箱或电动车存在较大相似性,从而降低了场景中车辆的识别精度。在测试数据Ⅴ中存在一些因遮挡和过分割导致的缺失冠层的行道树或缺失树干的低矮灌木(如图8场景C和D)。缺失冠层的行道树易与杆状交通设施混淆,而缺失树干的低矮灌木和树冠与残缺的车辆或负样本中的垃圾桶等地物相似,因此容易被错误分类成车辆或负样本,从而导致本文方法对测试数据Ⅴ的分类中行道树的召回率及精度都相对较低。同时,由于训练数据与测试数据来自不同国家的城市道路场景,同一类地物存在多种形状以及空间分布,而人工标注的训练数据难以涵盖所有地物的样本空间,这也导致部分地物出现错误识别的情况。
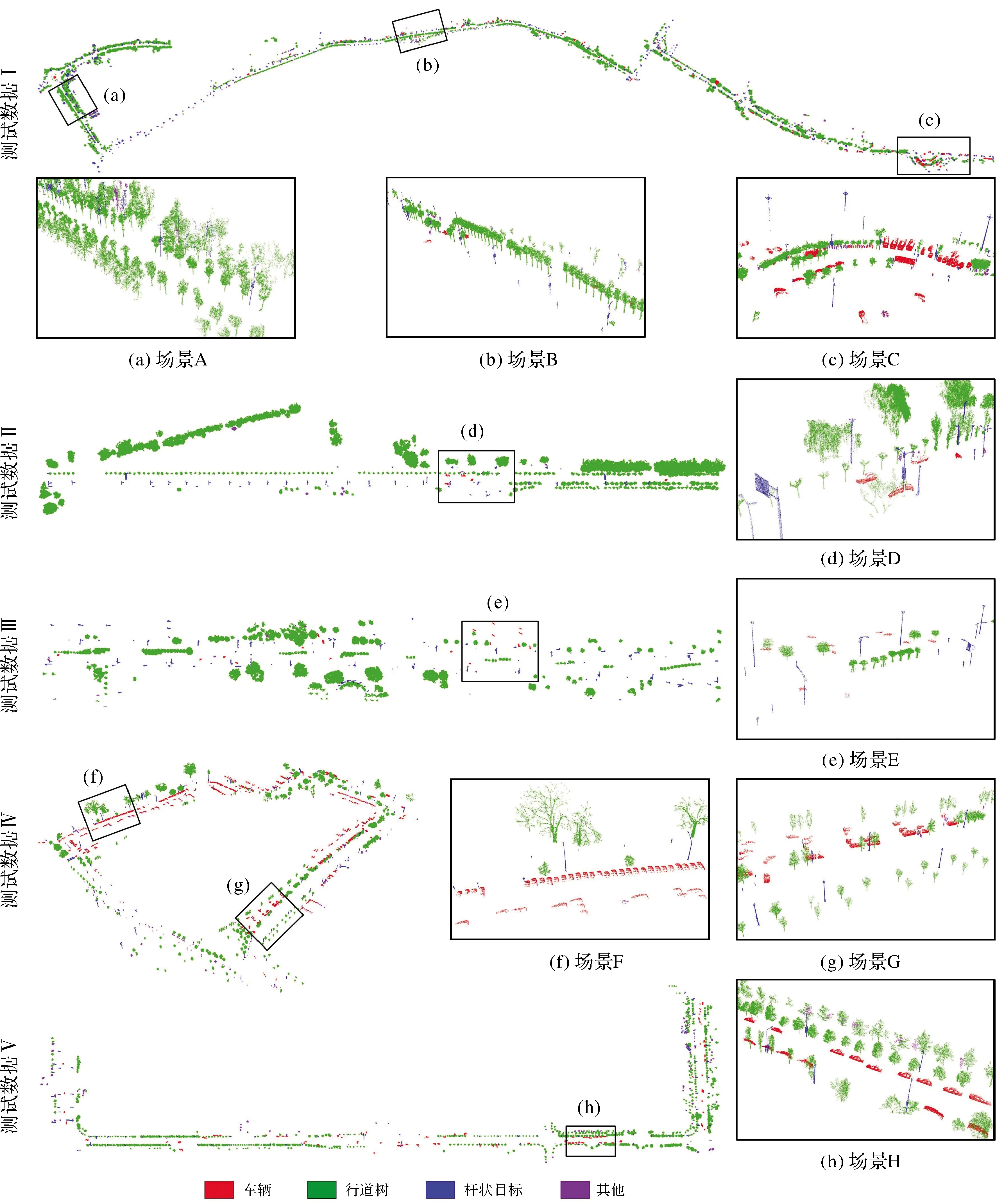
图7 路侧目标分类结果Fig.7 Classification results of roadside objects
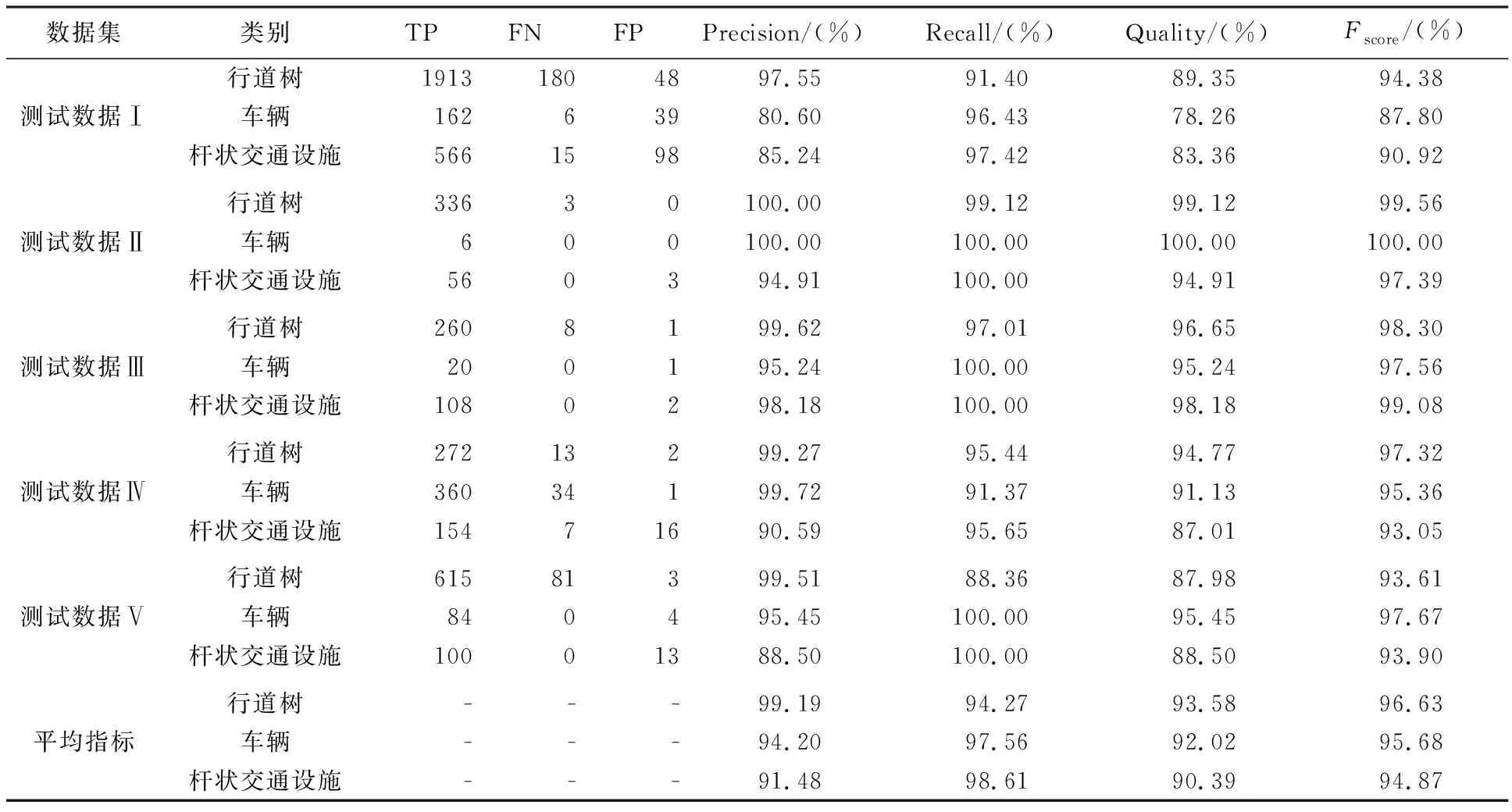
表2 测试数据分类结果精度
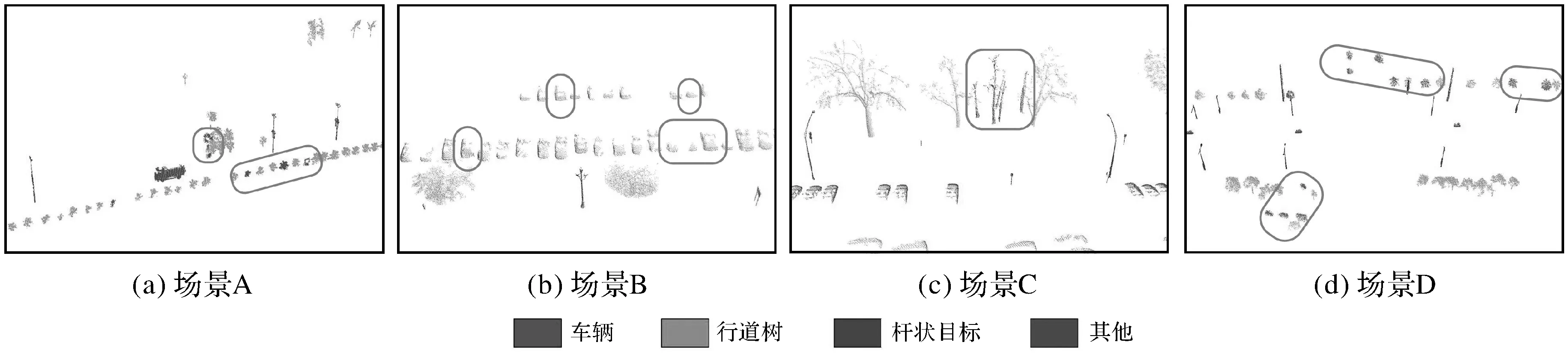
图8 部分错误分类场景Fig.8 Some misclassification cases
为了进一步验证本文方法的有效性,选取在点云目标识别方向取得较好效果的6类方法:DBN[12]、MVCNN[13]、GVCNN[17]、PointNet[19]、DGCNN[26]及PVNet[28]与本文方法进行对比分析。其中DBN、MVCNN和GVCNN方法都是先将独立对象转换成多视角特征或者多视角图像,再利用深度模型实现不同目标的识别。PointNet和DGCNN模型是以原始三维点云为输入的深度学习模型。PVNet则是第1个融合点云和多视角图像的深度模型。同时,为验证本文注意力融合模块的有效性,本文在PGVNet模型的基础上通过削减该模块构建无注意力融合模块模型(PGVNetno-A)、一层注意力融合模块模型(PGVNet1-A)。在对比和消融试验中,本文根据开源代码或者论文参数设置说明,采用相同的训练数据和测试数据进行试验,采用5份测试数据的平均准确率(average precision,AP)、平均召回率(average recall,AR)、平均精度(average quality,AQ)以及平均综合评价指标(averageFscore,AFscore)为评价指标进行精度对比,各方法试验结果列于表3和图9。
由图9和表3中可以看出,本文方法(PGVNet模型)在融合点云与视图特征的同时,兼顾了视图间的差异性和相似性,通过分组赋权的方式提取更具有区分性的最优视图特征,并利用最优视图特征自适应指导点云局部特征的学习,在测试数据上取得了最优的路侧目标分类结果。DBN模型输入为3张50×50二值图像组成的二值向量,存在较大的精度损失,因此该方法对拥有较大侧剖面的行道树和车辆的识别精度较高,但对于路灯、交通标志牌等侧剖面较小的杆状交通设施(场景D和场景E)则存在严重的错分情况,导致该方法对杆状交通设施的分类效果相较于其他方法偏低。MVCNN和GVCNN是基于多视角图像的模型,利用卷积神经网络提取视图全局特征进行目标分类。由于缺乏局部几何特征,这两类方法易于将一些树冠形状与车辆较为相似的行道树错分成车辆(场景A)。GVCNN采用视图分组融合的特征提取模式,获取更具代表性的全局特征,因而该方法对小型行道树(场景B)的识别要优于MVCNN。但是在视图分组过程中会丢失部分信息,因此GVCNN模型对存在较大形变的点云目标(场景C)识别能力较差。PointNet模型通过多层感知机逐点学习特征,并通过最大池化层聚合全局特征。最大池化层会导致点云局部特征缺乏,影响PointNet模型对残缺的小型行道树(场景A和场景B)、小型车辆点云(场景C)以及杆状交通设施(场景E)的分类效果。DGCNN则在PointNet模型基础上,构建局部邻域内的KNN图结构,能提取局部点云几何特征,因此其对小型路侧目标的识别效果要优于PointNet方法。但由于DGCNN并未建立不同局部特征之间的关系描述,导致其很难区分具有相似局部几何特征的地物,存在部分残缺较严重的车辆、行道树和杆状交通设施互相混淆情况(场景C和E)。相较于以上单模态方法,PVNet模型通过融合点云与多视图特征,在5份测试数据上也取得了较好的分类效果。但由于其未区分不同视图对识别当前目标的差异性与视图间的相似性,因此在一些场景下表现不如本文PGVNet模型,其对小型行道树的识别效果较差(场景B),同时容易将部分因遮挡或分割导致残缺的行道树错误分类成负样本(场景A)。
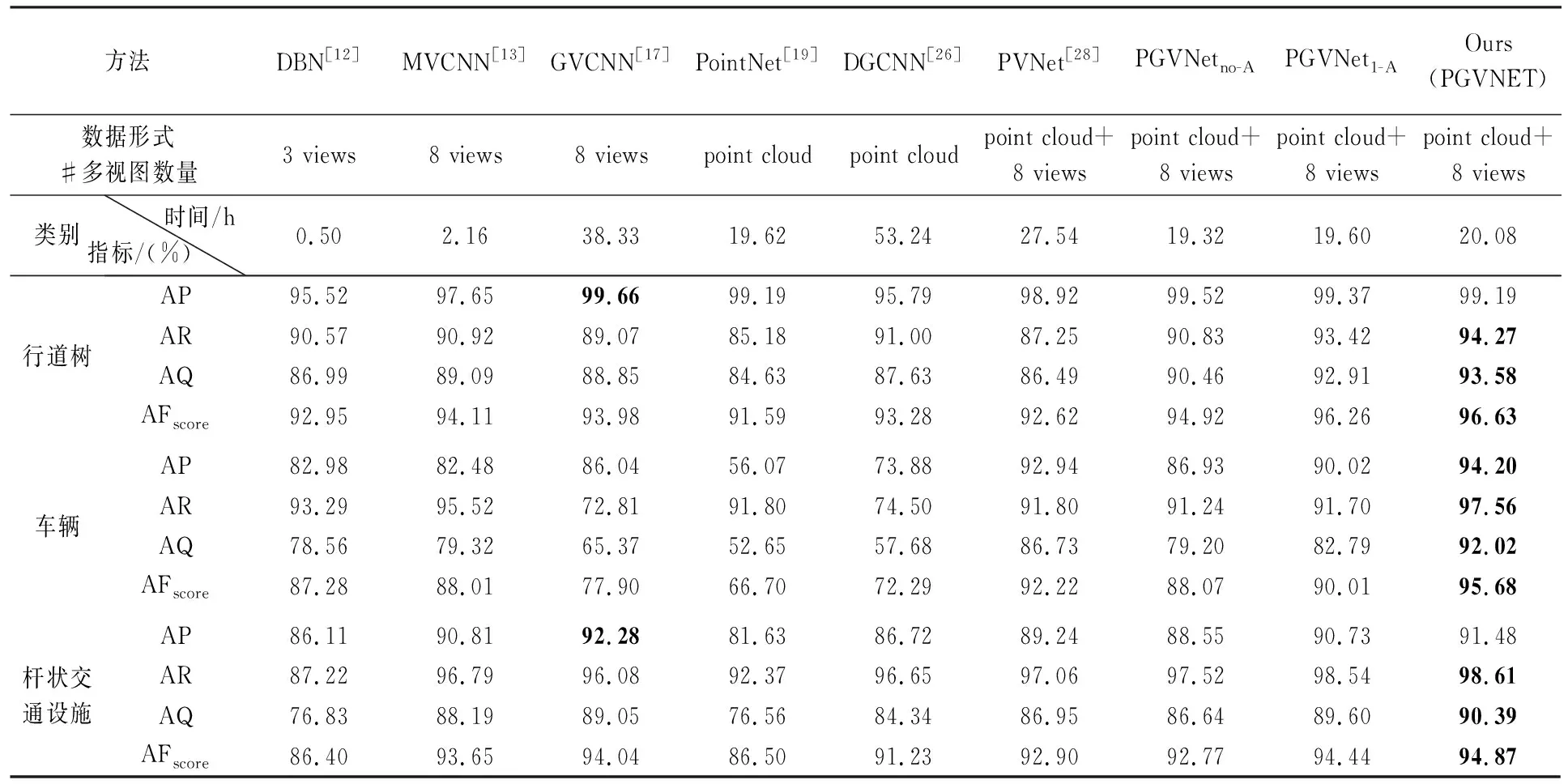
表3 本文方法与其他方法(含消融模型)的路侧目标分类精度对比分析
同时,相比于无注意力融合模块的PGVNetno-A模型和只含一层注意力融合模块的PGVNet1-A模型,本文PGVNet模型总体上识别效果更好,特别是对车辆的识别精度提升较大。通过可视化点云局部特征P和注意力融合模块中的注意力系数(如图10所示,特征P和模块中蓝色到红色分别表示每个点的特征从0到1的取值和权重)表明,提取的点云局部特征P中路侧目标的边缘几何特征更具区分性,但不够稳健,模块Ⅰ能增强这些小范围的边缘特征,但易受误差影响,而模块Ⅱ则能更加快速稳定的增强路侧目标大范围几何特征。因此堆叠两层注意力融合模块能够实现更加稳健的特征融合,提高模型对关键特征的提取能力,使PGVNet模型对车辆点云的识别效果(场景C)优于另外两种对比模型。综合考虑模型的分类效果和时间效率,本文在PGVNet模型中采用了两层注意力融合模块。
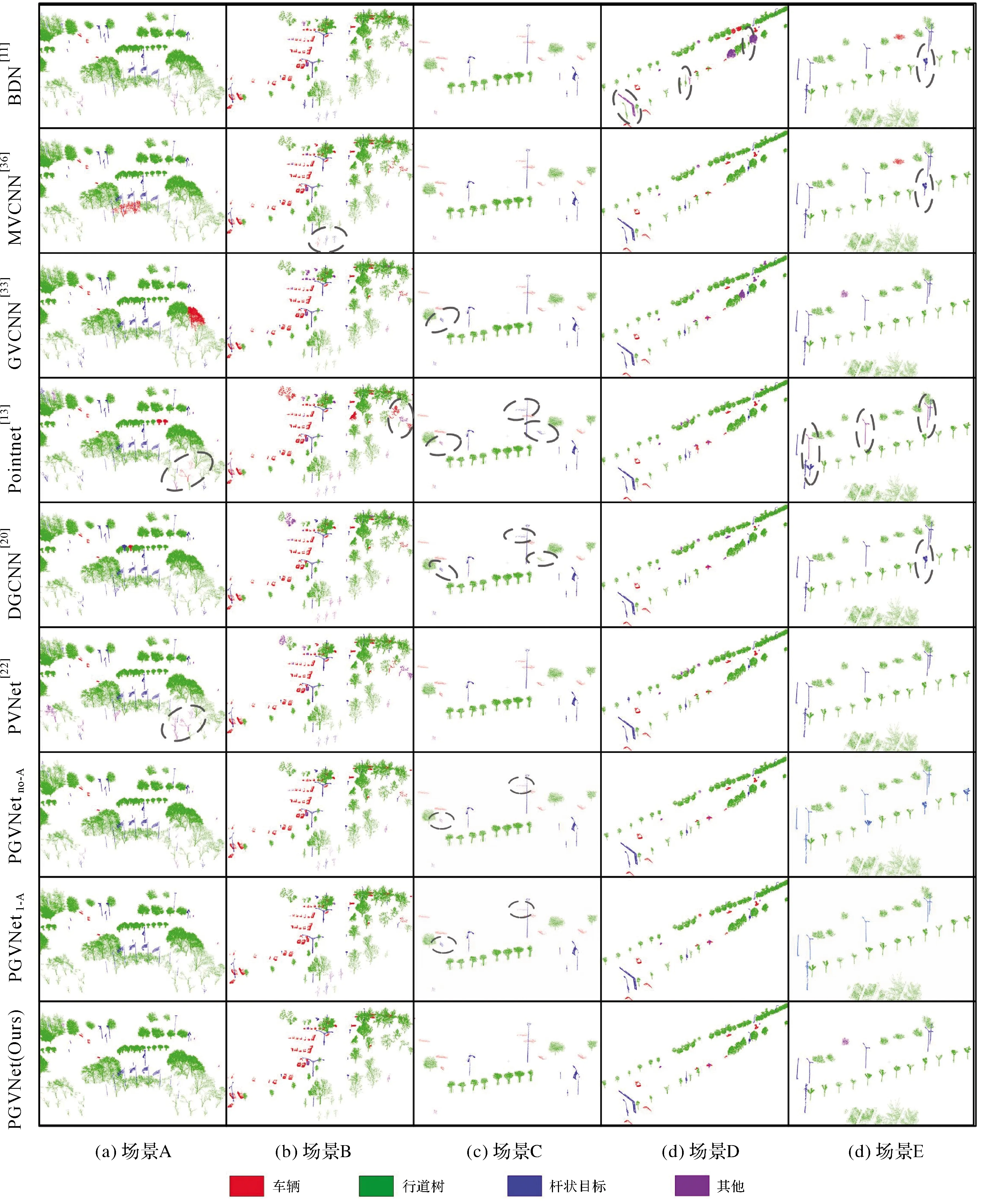
图9 本文方法与其他方法(含消融模型)在典型场景中路侧目标分类结果对比Fig.9 The comparison results of ours methods with some existing methods and ablation modelues on typical scenes
此外,为验证本文算法与对比方法在时间效率上的差异,笔者在相同条件下,统计不同模型训练达到拟合所需时间,结果见表3。对比方法中,DBN[12]和MVCNN[13]在时间效率上具有较大优势,但本文方法在路侧目标的分类精度上比这两种方法更具优势。同时与现有点云深度模型如PointNet和DGCNN相比,本文方法由于构建了注意力融合模块,能够通过视图特征加速模型对点云特征的学习,训练耗时相对较少。总体而言,本文方法在分类精度及算法效率上具有一定优势。
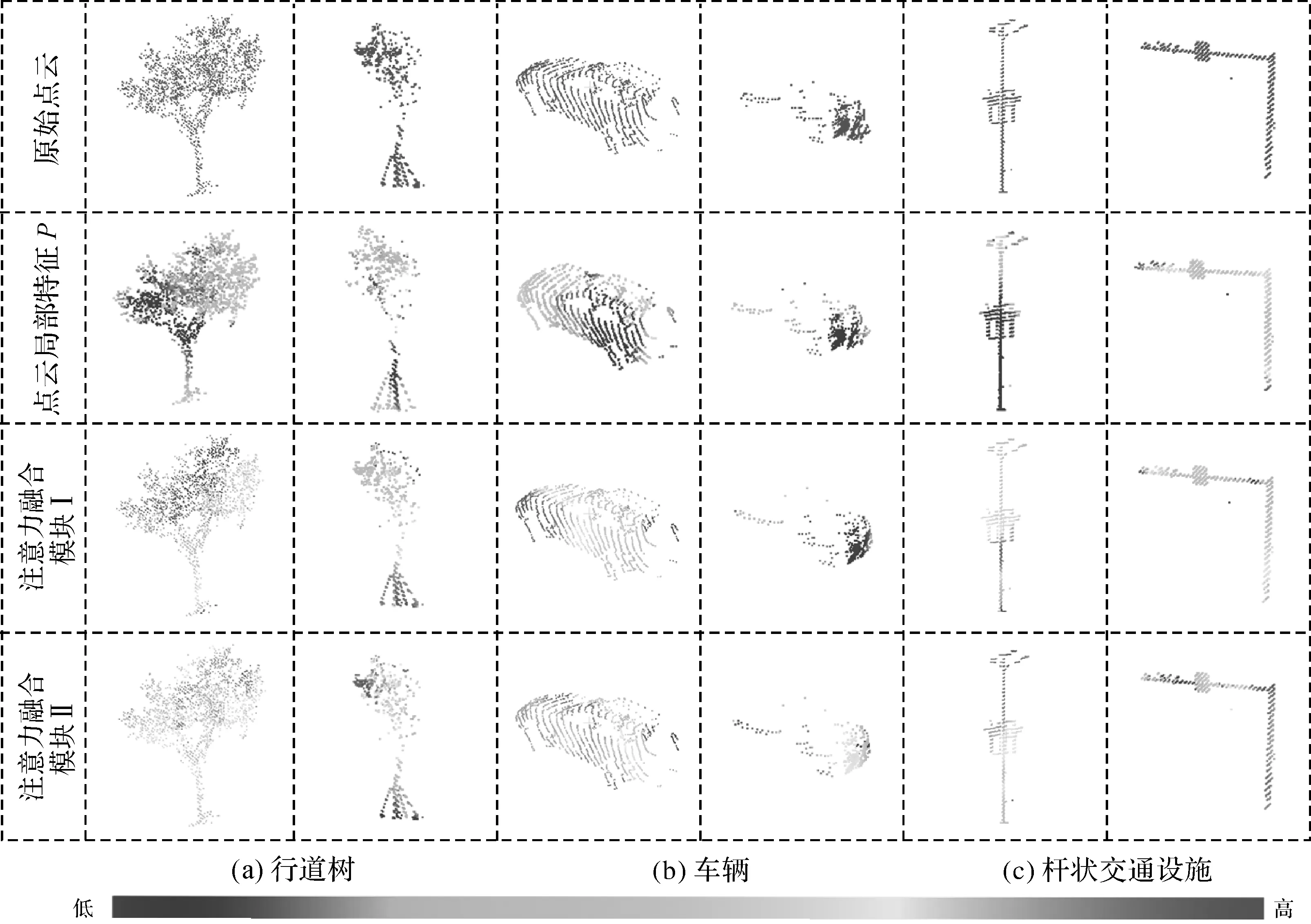
图10 PGVNet中点云局部特征P及注意力融合模块的注意力系数可视化结果Fig.10 The visualization of point cloud local features P and attention coefficients for attention fusion block in PGVNet
3 结 论
本文通过分析点云与多视角图像间的空间位置关系,提出一个融合点云和多视角图像的车载激光点云路侧多目标识别模型——PGVNet。该模型对每一个点云目标等角距获取多视角图像,首先通过构建视图特征分组赋权融合机制,描述不同视图对点云目标识别的重要性,然后基于注意力机制自适应地将最优视图特征嵌入点云特征,实现路侧多目标的精确识别与分类。本文采用5份测试数据对PGVNet模型进行测试,5份测试数据中3类路侧交通地物的平均准确率、平均召回率、平均精度和平均综合评价指标达到了91.48%、94.27%、90.39%和94.87%。与现有方法相比,本文直接面向车载激光点云对象构建了一个适用于点云及其多视角图像融合的路侧目标分类深度学习框架,在多视图特征提取的过程中,引入视图特征分组的思想,可区分不同视角图像对点云目标识别的重要性,减少相似视图间的冗余信息并提升有效的视图特征;同时通过最优视图特征指导PGVNet模型动态调整对目标点云不同局部结构的注意力度,形成融合视图和点云的多层次、多角度信息,实现路侧目标的精确识别,为车载激光点云路侧目标精细分类提取提供了一种新的研究方法。目前本文方法仍然存在一定的缺陷,分类精度一定程度上受到独立地物分割效果的影响,并且使用CNN提取特征,计算量较大。此外本文PGVNet模型容易混淆部分形状相似的树干和杆状交通设施,后续会加强该方面的研究。
猜你喜欢
公民与法治(2022年11期)2022-12-06
家教世界·创新阅读(2021年12期)2021-01-13
科学与财富(2018年30期)2018-12-28
现代园艺(2017年22期)2018-01-19
中学生数理化·中考版(2017年6期)2017-11-09
非公有制企业党建(2017年10期)2017-11-03
现代兵器(2017年4期)2017-06-02
现代兵器(2017年4期)2017-06-02
甘肃林业(2016年2期)2016-11-07
计算机应用(2016年9期)2016-11-01
