
基于改进级联金字塔网络的人体骨架提取算法
2021-12-07 03:38黄友张娜包晓安
智能计算机与应用 2021年7期
关键词:注意力机制
黄友 张娜 包晓安


摘 要: 由于背景复杂和人体容易被遮挡等情况的发生,导致人体骨架关键点的定位精度不高。针对这一问题,本文提出一种基于改进级联金字塔网络的人体骨架提取算法。该算法将注意力模块加入到级联金字塔特征提取网络的每一个残差块之后,根据特征图的不同部分和不同特征圖的重要性程度分配不同的权重。同时将原来级联金字塔网络的2次上采样操作改为一次,以减少上采样过程中产生的冗余背景特征。实验结果表明:该算法可以较好地改善原CPN网络在遮挡、背景复杂等情况下定位不精准的问题。
关键词: 级联金字塔网络; 注意力机制; 多层次特征提取; 特征融合; 困难关键点挖掘; 目标关键点相似度
文章编号: 2095-2163(2021)07-0054-06中图分类号:TP391.41文献标志码: A
Human skeleton extraction algorithm based on improved cascaded pyramid network
HUANG You, ZHANG Na, BAO Xiao'an
(School of Informatics Science and Technology, Zhejiang Sci-Tech University, Hangzhou 310018, China )
【Abstract】Due to the complex background and the easy occlusion of the human body, the positioning accuracy of the key points of the human skeleton is not high. Aiming at this problem, this paper proposes a human skeleton extraction algorithm based on an improved cascaded pyramid network. The algorithm adds the attention module to each residual block of the cascaded pyramid feature extraction network, and assigns different weights according to different parts of the feature map and the importance of different feature maps. At the same time, the two upsampling operations of the original cascaded pyramid network are changed to one to reduce the redundant background features generated in the upsampling process. Experimental results show that the algorithm can better improve the problem of inaccurate positioning in the original CPN network under occlusion and complex background conditions.
【Key words】cascaded pyramid network; attention mechanism; multi-level feature extraction; feature fusion; hard keypoints mining; object keypoint similarity
0 引 言
人体骨架提取(也被称为人体骨架关键点检测)算法主要是检测人体的鼻子、左右眼、左右耳、左右肩、左右手肘、左右手腕、左右臀、左右膝、左右腿等关键点,使用这些关键点描述人体的骨架信息[1]。人体骨架关键点检测算法被广泛应用在人机交互、智能视频监控、智能安防、行为识别、任务跟踪和步态识别等领域[2]。
早期的基于人体骨架的行为识别方法主要是通过手工设计特征的方式来对行为进行表征[3]。然而,这些手工特征只在一些特定的数据集上表现良好,可能无法迁移到其它数据集上,不具有普适性[4]。随着深度学习的出现,一些使用基于深度神经网络对人体骨架进行行为识别的方法越来越受到人们的欢迎[5]。
基于深度学习的人体骨架关键点检测算法主要有2个方向。一种是自上而下,一种是自下而上。自上而下的人体骨架关键点检测算法主要包含2个部分:人体目标检测和单人人体骨架关键点检测[6]。首先通过目标检测算法将人体目标检测出来,然后在此基础上对单个人做人体骨架关键点检测,其中代表性算法有G-RMI[7]、CFN[8]、RMPE[9]、Mask R-CNN[10]和 CPN[11]。目前,自上而下的人体骨架关键点检测算法在MSCOCO数据集上最好的检测精度是72.6%。自下而上的人体骨架关键点检测算法也包含2个部分:关键点检测和关键点聚类[12]。首先需要将图片中所有的关键点都检测出来,然后根据关键点之间的关系对所有的关键点进行聚类得到不同的个体,其中对关键点之间关系进行建模的代表性算法有PAF[13]、Associative Embedding[14]、Part Segmentation[15]和Mid-Range offsets[16]。自下而上的人体骨架关键点检测算法目前在MSCOCO数据集上最好的检测精度是68.7%。
自上而下的人体骨架提取方法定位精度比自下而上的方法高,但是该方法比较依赖检测到的人体目标框。由于图片中人体容易被遮挡和干扰[17],导致对人体关键点的定位精度不高。针对这一问题,本文提出一种基于改进级联金字塔网络的人体骨架提取算法。该算法将注意力模块加入到级联金字塔的特征提取网络中,通过模型学习对不同的特征信息分配权重系数。以增强网络对重要特征信息的关注同时减弱无用的复杂背景特征信息,进而提高对遮挡的人体关键点的定位精度。同时将原级联金字塔网络的2次上采样过程改为一次,以减少在上采样过程中产生的背景特征。
1 相关研究
1.1 级联金字塔网络
级联金字塔网络(Cascaded Pyramid Network, CPN)网络包括2个部分:粗略检测关键点的GlobalNet网络和微调RefineNet网络,其网络结构如图1所示。GlobalNet网络使用残差网络提取多尺度特征图,通过特征金字塔网络融合多尺度特征图,实现对人体关键点的初步定位。RefineNet网络以沙漏网络为基础,对由GlobalNet网络检测的关键点中损失较大的关键点进行修正,进而实现对人体关键点的精确定位。
GlobalNet网络采用ResNet50残差网络提取多层次的特征,再使用FPN对这些多尺度特征进行融合,利用L2损失函数计算关键点定位损失。采用Resnet50的第3、7、13和16个Bottleneck块的输出作为多尺度特征图,分别记为C_2, C_3, C_4和C_5。对每一层特征图,利用一个3×3的卷积滤波层去生成一组热力图,每张热力图对应一个关键点,分别记为H_2,H_3,H_4和H_5。
这些特征图中,浅层特征图具有较高的空间分辨率,但是其中包含的语义信息较少,而深层特征图具有较多的语义信息,但是空间分辨率较低。单一层的特征图无法兼顾空间分辨率和较多的语义信息,故采用FPN网络来对这些特征图进行融合,使得融合后的特征图中既包含丰富的语义信息,同时也包含由于不断降采样而丢失的底层细节信息。FPN通过对底层特征进行上采样,再与上层特征进行融合,实现浅层特征与深层特征之间的融合,实际上是浅层特征生成的热力图与深层特征生成的热力图之间的融合。利用L2损失函数计算这些生成的热力图与真实关键点坐标生成的热力图之间的误差,根据误差对网络进行训练。
GlobalNet网络对于一些简单的、可见的、容易检测的关键点(比如眼睛)的定位精度较高,可是对于一些隐藏的关键点(比如臀部)的定位精度较低。对于这些难以检测的关键点的定位通常需要利用更多的语义信息,单独使用GlobalNet网络无法直接识别这些“困难”关键点。
RefineNet网络就是为了处理这些“困难”关键点,RefineNet接收来自GlobalNet网络提取的多层次特征,对于不同层的特征图后加入不同数量的Bottleneck残差模块进一步提取更深层的特征,再对这些特征图进行上采样并通过concat層把这些信息拼接起来。这样就综合利用了FPN所有层的特征,可以获取到更多的语义信息。
而随着网络训练的进行,网络会更倾向于关注可见的“简单”关键点,但是其重要性不及“困难”关键点。因此,网络需要在两者的关注之间取得一个平衡。为此,RefineNet采用带有在线困难关键点挖掘(Online Hard Keypoints Mining, OHKM)的L2函数作为计算关键点预测损失函数,根据训练损失显式地选择“困难”关键点,并且只对这些“困难”关键点反向传播梯度进行训练。
1.2 注意力机制
注意力机制(Convolutional Block Attention Module, CBAM)[18]是通过学习对图像不同特征信息和不同特征层分配权重系数,以便能够强调对学习目标有用的信息抑制无用的信息。注意力模块一般可分为通道注意力模块和空间注意力模块两部分,两者的侧重点不同。
通道注意力模块是通过池化操作学习每个通道的重要性程度,将输入特征图分别经过最大池化和平均池化,之后用多层感知机(Multilayer Perceptron, MLP)进行学习,将学习的结果叠加之后经过sigmoid函数激活得到通道注意力(如图2左半部分所示)。空间注意力模块是学习特征图中不同位置对于学习目标的重要性程度,将输入特征图经过最大池化和平均池化后,将二者的输出按照第一维度进行拼接,再经过一个3×3的卷积层,之后经过sigmoid函数激活得到空间注意力(如图2右半部分所示)。
2 本文设计
CPN网络是一种自上而下的关键点定位算法,需要先检测到人体目标框再对人体目标做单人骨架关键点定位。由于图像背景复杂,会导致检测到的[CM(22]人体存在遮挡和干扰等情况,进而影响到被遮挡的
关键点的定位准确度。同时在原CPN网络中,采取了2次上采样操作,而上采样操作会带来更多的背景特征。
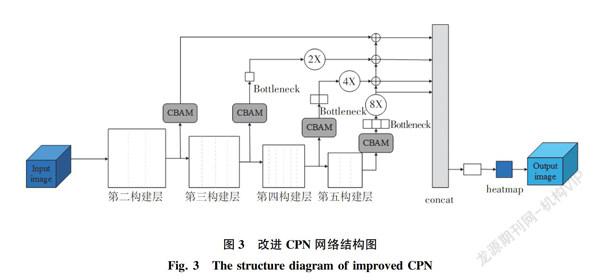
针对检测到的人体被遮挡问题,本文提出了一种基于改进CPN的人体骨架提取算法。该算法是将CBAM加入到CPN网络中,其网络模型结构如图3所示。采用在ResNet50网络的第3、7、13和16个Bottleneck块的输出之后分别加入CBAM模块,CBAM可以在不改变网络的整体架构的基础上作用于深浅不同的多层次特征图上。通过不同的权重分配使网络能够着重学习有用的特征而抑制无用的特征,也即是加强对关键点的特征图的关注而减少对复杂背景的关注。这样可以较好地提高复杂背景下人体关键点的定位精度。
针对上采样过程中产生的冗余背景特征问题,本文采用将2次上采样修改为一次。具体实现过程为对经过CBAM处理之后的多层次特征图进行上采样,其中特征图由浅到深分别上采样的倍数为1、2、4和8。
再对经过上采样之后的特征图进行融合,使得融合之后的特征图中既包含丰富的语义信息,同时也包含由于不断降采样而丢失的底层细节信息。
3 实验结果及分析
本文实验所用的计算机配置如下:CPU为Intel(R) Xeon(R) Silver 4110 CPU @ 2.10 GHz;GPU为15 G NVIDIA Corporation TU104GL [Tesla T4]显卡;主频为4.00 GHz;系统为CentOS 7.7。采用Python3.6作为编程语言,深度学习框架选取Pytorch1.4.0。
3.1 实验数据集
为评估本节所设计算法的性能,采用COCO数据集进行实验验证。COCO数据集对人体的17个骨架关键点进行标注,共计有58 945张图片,有15 K个标记的人物,有171 K个标记的关键点。由于数据集中一部分图像的质量不高,采用图像标准化、随机调整亮度和对比度等操作对图像进行处理,改善图像的视觉效果,使得图像能够更适合分析和处理的需求。
采用其中44 208张包含人体骨架关键点标注信息的图片作为实验训练集,其余的14 737张图片作为实验测试集。同时选用在实际场景下采集的几张图片验证本文改进算法的性能。
3.2 性能评价指标
人体骨架关键点检测算法的预测值无法与真实值一一对应,不能像分类问题那样采用一些常用指标(如:精度、召回率等)进行性能评价。因此,需要构建一个合适的人体骨架关键点相似度的度量指标,以此来判断某个关键点的预测是否正确,从而评价算法的优劣。目前,最常用的就是OKS(Object Keypoint Similarity)指标,这个指标启发于目标检测中的IoU指标。其计算公式如下:
其中,OKSp表示图像中第p个人的相似度指标;p为人工标注的真实人体的编号;i为人体骨架关键点的编号;dpi为第p个人的第i个关键点的预测位置与真实位置之间的欧氏距离;Sp为第p个人的尺度因子,定义为此人在人工标注框中所占面积的平方根;σi是第i个骨架关键点的归一化因子,是通过对已有的数据集中这个关键点的计算标准差得到的。該值越大,表示这个关键点越难标注;值越小,表示这个关键点越容易标注;vpi为第p个人的第i个关键点的状态; δ(vpi=1)为克罗内克函数,即只有被标注为可见的人体骨架关键点(vpi=1)才计入评价指标,其计算公式如下:
由公式(2)可知,2个关键点之间的相似度取值在[0, 1]之间。选定一个阈值t后,通过将图中第p个人的相似度值(即OKSp)与t作比较。如果当前的OKSp大于t,那就说明当前这个人的骨架关键点成功检测出来了,并且检测对了。如果小于t,则说明检测失败或者误检漏检。再统计图中所有人的OKS,计算其中大于t的比值。该比值是阈值为t时的人体骨架关键点检测算法的平均精度(Average Precesion, AP),其计算公式如下:
最后再根据不同的阈值t,计算平均值,即为mAP(mean Average Precesion)。一般情况下阈值是在[0.5, 0.95]的范围内以0.05为步长递增选取,mAP计算公式为:
3.3 模型参数设置
本节设计算法设置网络输入图像大小为256×192(宽×高),利用公开数据集ImageNet的预训练参数进行模型初始化,利用Adam优化器优化学习率,进而调整网络的参数。训练的批次大小为16,max_epoch为12。这里采用预热(warm up)学习率策略,学习率在前500次迭代中线性增加至初始学习率0.001,之后在epoch7和epoch10的时候衰减为之前的1/3。
3.4 实验结果及分析
为了验证本文提出的改进CPN网络对人体骨架关键点的检测精度优于原CPN网络,使用COCO数据集进行训练并做对比试验。采用平均准确率mAP、阈值为0.5,0.75的平均准确率AP@0.5和AP@0.75、中等尺度目标的平均准确率APM和大尺度目标的平均准确率APL作为对比指标,试验结果如图4所示。从图4中可以看出,本节提出的改进的CPN网络的mAP为73.2,相较于原CPN网络提高了1.8。而且在其他阈值及不同尺度目标情况下的AP也都有一定的提升。
为了进一步分析在网络的不同位置添加CBAM模块对人体关键点检测精度的影响,分别采用在ResNet50网络的第3、7、13和16个Bottleneck块的输出之后加入CBAM模块以及只在ResNet50网络的16个Bottleneck块的输出之后加入CBAM模块进行对比试验。同样地,采用平均准确率mAP、阈值为0.5,0.75的平均准确率AP@0.5和AP@0.75、中等尺度目标的平均准确率APM和大尺度目标的平均准确率APL作为对比指标,试验结果如图5所示。从图5中可以看出,采用在ResNet50网络的第3、7、13和16个Bottleneck块的输出之后加入CBAM模块的mAP为73.2,相较于只在ResNet50网络的16个Bottleneck块的输出之后加入CBAM模块提高了0.9,而且在其他阈值及不同尺度目标情况下的AP也都有一定的提升。
同时为了验证本节提出的改进CPN网络对人体骨架关键点的检测精度优于当前主要的关键点检测方法,选取当前主流的关键点检测方法做对比试验。主要有CMU-Pose、Mask R-CNN、G-RMI和PersonLab,其中CMU-Pose和PersonLab是自底向上的方法,Mask R-CNN和G-RMI是自顶向下的方法。实验结果如图6所示。从图6中可以看出,本文提出的改进CPN网络对关键点的定位精度明显优于CMU-Pose和PersonLab,较同类方法Mask R-CNN和G-RMI也有一定的提高。
为了验证本文设计的算法在不同背景情况下的检测效果,选取在影院复杂背景情况中的一张单人图片和一张多人图片分别在有无遮挡情况下做实验进行检测。对人体的17个不同的关键点用不同的颜色进行标记,并将有联系的关键点用直线连接起来。检测结果如图7所示。从图7中可以看出,不管是单人图片、还是多人图片的关键点检测精度都很高。在遮挡情况下,也能很好地定位人体的关键点。
4 结束语
本文提出了一种基于改进CPN的人体骨架关键点检测算法,采用在ResNet50网络的第3、7、13和16个Bottleneck块的输出之后加入CBAM模块,以提高在遮挡和复杂背景情况下人体关键点的定位精度。研究中,为了减少在上采样过程中产生的冗余背景特征,将原CPN的2次上采样过程改为一次。通过实验可知,本文设计的算法的人体关键点定位精度比原CPN高,同时在遮挡情况下,也能对人体关键点进行精确定位。由于在原CPN模型中加入了CBAM,会增加模型的参数量和计算量。后期的研究方向是在不影响模型定位精度的基础上,减少模型的参数量,提高网络的运行速度。
参考文献
[1]郭天晓, 胡庆锐, 李建伟, 等. 基于人体骨架特征编码的健身动作识别方法[J]. 计算机应用,2021,41(5):1458-1464.
[2]田志强, 邓春华, 张俊雯. 基于骨骼时序散度特征的人体行为识别算法[J]. 计算机应用,2021,41(5):1450-1457.
[3]蔡强, 邓毅彪, 李海生, 等. 基于深度学习的人体行为识别方法综述[J]. 计算机科学, 2020, 47(4): 85-93.
[4] 边缘, 孔小莹, 张莉, 等. 基于卷积神经网络的植物叶片树种识别研究与实现[J]. 智能计算机与应用, 2020, 10(10): 23-26.
[5]李扬志, 袁家政, 刘宏哲. 基于时空注意力图卷积网络模型的人体骨架动作识别算法[J]. 计算机应用,2021,41(7):1915-1921.
[6]CAO Z, SIMON T, WEI S E, et al. Realtime multi-person 2d pose estimation using part affinity fields[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu,HI,USA:IEEE,2017: 7291-7299.
[7]CHEN L C, HERMANS A, PAPANDREOU G, et al. Masklab: Instance segmentation by refining object detection with semantic and direction features[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT, USA:IEEE, 2018: 4013-4022.
[8]LI Jiahao, LI Bin, XU Jizheng, et al. Fully connected network-based intra prediction for image coding[J]. IEEE Transactions on Image Processing, 2018, 27(7): 3236-3247.
[9]FANG Haoshu, XIE Shuqin, TAI Y W, et al. Rmpe: Regional multi-person pose estimation[C]//Proceedings of the IEEE International Conference on Computer Vision.Venice:IEEE, 2017: 2353-2362.
[10]HE K, GKIOXARI G, DOLLR P, et al. Mask r-cnn[C]//Proceedings of the IEEE International Conference on Computer Vision. Venice:IEEE,2017: 2961-2969.
[11]CHEN Yilun, WANG Zhicheng, PENG Yuxiang, et al. Cascaded pyramid network for multi-person pose estimation[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Salt Lake City,UT:IEEE, 2018: 7103-7112.
[12]SUN Ke, XIAO Bin, LIU Dong, et al. Deep high-resolution representation learning for human pose estimation[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Long Beach, CA, USA:IEEE, 2019: 5693-5703.
[13]CAO Z, HIDALGO G, SIMON T, et al. OpenPose: realtime multi-person 2D pose estimation using Part Affinity Fields[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2019, 43(1): 172-186.
[14]YU Zehao, ZHENG Jia, LIAN Dongze, et al. Single-image piece-wise planar 3d reconstruction via associative embedding[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.Long Beach, CA, USA:IEEE, 2019: 1029-1037.
[15]XIA Fangting, WANG Peng, CHEN Xianjie, et al. Joint multi-person pose estimation and semantic part segmentation[C]// Proceedings of the IEEE conference on computer vision and pattern recognition. Honolulu, HI, USA:IEEE,2017: 6769-6778.
[16]PAPANDREOU G, ZHU T, CHEN L C, et al. Personlab: Person pose estimation and instance segmentation with a bottom-up, part-based, geometric embedding model[M]//FERRARI V, HEBERT M, SMINCHISESCU C, et al. Computer Vision-ECCV 2018. Lecture Notes in Computer Science. Cham:Springer,2018,11218:282-299.
[17]葉飞, 刘子龙. 基于改进YOLOv3算法的行人检测研究[J]. 电子科技, 2021, 34(1): 5-9,30.
[18]WOO S, PARK J, LEE J Y, et al. Cbam: Convolutional block attention module[M]//FERRARI V, HEBERT M, SMINCHISESCU C, ET AL. Computer Vision-ECCV 2018. Lecture Notes in Computer Science. Cham:Springer, 2018, 11211: 3-19.
基金项目: 国家自然科学基金(620705014;1); 浙江省自然科学基金青年基金(LQ20F050010); 浙江省重点研发计划项目(2020C03094)。
作者简介: 黄 友(1995-),男,硕士研究生,主要研究方向:图像处理、深度学习; 张 娜(1977-),女,副教授,主要研究方向:智能信息处理;包晓安(1973-),男,教授,主要研究方向:软件测试、智能信息处理。
通讯作者: 包晓安Email: baoxiaoan@zstu.edu.cn
收稿日期: 2021-03-24
猜你喜欢
计算机应用(2019年3期)2019-07-31
无线互联科技(2019年9期)2019-07-29
无线互联科技(2019年9期)2019-07-29
智能计算机与应用(2019年3期)2019-07-01
智能计算机与应用(2019年3期)2019-07-01
智能计算机与应用(2019年3期)2019-07-01
电子技术与软件工程(2019年5期)2019-06-20
软件导刊(2019年1期)2019-06-07
数字技术与应用(2019年2期)2019-05-14
现代电子技术(2018年8期)2018-04-13
