
基于超体素的区域聚类的复杂场景分割
2021-12-07 05:29刘德儿王有毅施贵刚
激光与红外 2021年11期
李 文,刘德儿,王有毅,刘 鹏,施贵刚
(1.江西理工大学土木与测绘工程学院,江西 赣州 341000;2.安徽建筑大学土木工程学院,安徽 合肥 230601)
1 引 言
随着三维激光扫描技术的发展,不仅能快速、非接触式的获取物体的相关信息,而且获取的坐标、颜色和反射强度信息的精度越来越高,广泛应用到文物古迹的保护[1]、自动驾驶[2-3]、城市规划[4]、变形监测[5-7]及医学应用[8]等领域中。点云分割是点云处理的关键步骤,分割质量的好坏直接影响目标识别、三维重建[9]和定位,因而成为了当下三维领域的研究热点。
国内外学者对此进行了大量的研究,刘慧等[10]把获取的植物深度图像和彩色图像转换为显著性点云,通过Mean-shift算法生成超体素,最后利用LCCP算法融合聚类,对树木实现了精确的枝叶分离;胡文庆等[11]通过使用点云的坐标和反射率作为为聚类条件的模糊C均值算法对建筑和椅子进行了分割,其分割精度较低;黎荣等[12]提出把点云的坐标、法向量、平均曲率和高斯曲率组成八维特征向量,然后使用遗传算法联合模糊聚类算法对汽车零件进行分割,获得了合理的分类,同时解决了FCM 算法陷入局部解的问题;张瑞菊等[13]通过分析古建筑的结构特性,提出了使用欧式聚类、模型拟合和基于包围盒的算法对古代亭子分割,虽然把每一个结构部件都准确的分割出来了,但是需要提前知道建筑的尺寸信息;Rabbani等[14]提出选择最小残差值的点作为种子点,并采用表面平滑性和局部连通性为约束条件,对工业机械点云进行区域生长分割,其分割结果较为理想;Lu等[15]首先使用区域生长对点云进行过分割,然后在此基础上再一次使用区域生长算法进行聚类合并,该方法对具有平滑的墙面的建筑的分割取得了较好的结果;Qi等[16]人提出Point Net++点云分割网络框架,并对点云数据集打标签后用此网络进行训练分割,最终取得了精确的分割结果,其分割操作较为繁琐。
上述分割算法皆是针对于简单场景或单一物体的分割,且各自具有局限性,难以适用于复杂的大场景的聚类分割。本文通过对采集的学校图书馆周围的点云数据的分析,提出一种基于超体素的改进的区域增长分割算法,并通过实验证明了该算法对起伏较大的面分割较好,并可以对复杂的场景实现有效的分割。
2 研究方法
本研究采用的超体素过分割及改进的区域融合算法对场景分割的流程图如图1所示。

图1 算法流程图Fig.1 Flow chart of proposed algorithm
2.1 点云数据获取及预处理
本文采用RIEGL VZ-1000三维激光扫描仪获取学校图书馆及周围的点云数据,采用的扫描仪扫描的范围广,获取的数据密度大,采集的数据通常有上千万个点,除此之外扫描时操作方式和周围环境的影响产生噪声,这两者给后续的数据处理造成极大不便,因此需要对数据进行去适当的精简和去噪[17]。本文利用Compare Cloud软件的点云裁剪功能、统计滤波算法、八叉树下采样算法共同完成数据的预处理。
采用的统计滤波算法可以将稀疏分散在空间中的离群点噪声去除,其算法原理较为简单,只需统计每个点与其邻域点的平均距离,确定其高斯分布,将不在标准距离阈值内的点视为噪声点,将其去除。
2.2 点云超体素过分割
超体素过分割是超像素分割在三维空间中的创新应用,其通过无监督分割把具有相同几何属性的点划分为同一小块中。目前超体素被广泛使用在点云分割、边界提取、三维识别的预处理阶段中[18]。本文所使用的超体素分割是Yang等[19]2018年提出的直接在点上而非在体素上执行的过分割算法,其优点在于不需要种子点的选取,直接对点云中的每个点进行相似性距离度量,其具体原理如下文所述。
2.2.1 点云法向量计算
点云的法向量是三维空间中重要的几何特征,应用到点云处理(点云滤波、点云分类、点云分割、点云重建、点云配准)的各个方面。三维空间中的法向量不同于二维平面的法向量计算,其通过目标点的邻域内所有点拟合平面,把平面的法向量当作点的法向量。针对于此,可以采用主成分分析算法计算图书馆及周围每个点的法向量。首先利用KD-Tree数据结构搜索点的K个邻域点构建协方差矩阵:
(1)
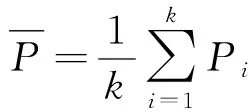
(2)
其中,λ1>λ2>λ3>0 为特征值,v1、v2、v3分别为λ1、λ2、λ3对应的特征向量,分别代表目标点的3个主方向,其中最小特征值对应的特征向量就为所求点的法向量。
2.2.2 超体素初次分割
本文采用的超体素过分割算法在首次的粗分割过程中,首先把图书馆及周围的整个场景的每个点都初始化为一个小的超体素块及对应超体素的代表点,随后在每次的迭代合并中采用公式(3)计算相邻两个超体素假如合并时能减少的能量,如果减少的能量大于零,就执行合并操作,其示意图如图2所示,深色和浅色点分别为超体素Si、Sj,箭头指向的点分别为两个超体素的代表点,经过计算合并可以减少能量,最终把超体素Sj合并到Si。
上面提到的是无任何干扰频率情况下的匹配网络,也可以说是理想状态下的匹配网络,由于土地资源和其他方面的原因,一个发射台往往同时发射多个频率,存在着双频共塔或多频共塔的情况,频率与频率之间相互干扰严重,特别是共塔频率会存在严重的高频倒送干扰,为了消除共塔频率的相互影响,必须增加一个或多个抑制网络——阻塞网络。阻塞网络的主要作用是抑制共塔频率的相互影响,最大限度地阻止共塔频率对本频的影响。图2是三种常见的阻塞网络组成形式原理图。
Δ′=λ-cjD(ri,rj)
(3)

图2 两个超体素合并示意图Fig.2 Schematic diagram of merging two supervoxels
其中,λ是一个正则化参数,为了减少人工的干预,增加算法的鲁棒性,通过公式(4)计算λ代替人为设定其初始值值,具体思想为首先计算每个点与其邻域点内的最小相异距离,然后再取其中值,之后在每轮的迭代中λ的值翻倍;cj为超体素Sj内的点数;D为两点之间的相异距离;其计算方法如公式(5)所示;ri,rj分别为代表超体素Si、Sj的点 。
λ0=median{minp(D(p,Ni))|p∈P}
(4)
式中,Ni是点p的近邻点点集;P为整个场景的点云:
(5)
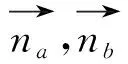
2.2.3 细化边界
为了使最终得到的超体素的边界形状更加规整,避免在边界处的分割出现越界现象,本文进行了重新分配相邻超体素之间的边界点的方式细化边界。具体方法为:如果点与近邻点分别归属于不同超体素,则认为这两点是边界点,然后通过这一方法找出所有边界点,随后分别计算两个相邻的超体素的代表点与其边界点的相异距离,并判断其大小关系,如果边界点与邻接超体素的代表点之间的距离小于同属于一个超体素的代表点的相异距离,就把这个边界点重新分配给邻接超体素。
2.3 改进的区域生长融合
在超体素的基础上,采用区域生长方式进行区域融合,使其最终聚类成为与现实物体对应的有意义的区域。为了使图书馆的不平整墙面、散乱的枝叶、路灯、楼梯、假山尽量合并,避免被当作噪声去除,本文对融合算法加以改进:通过计算每块区域聚类的种子超体素与其第一个邻接超体素块的高程差,与给定的阈值比较,把将要合并聚类成的区域预判为竖直或倾斜面和地面或与其平行平面,前一种面类型起伏较大,后一种面是表面比较光滑的平面,分别给定不同的法向量阈值进行生长聚类;采用K均值聚类算法的均值思想,当每次有新的超体素加入到当前合并区域里,就更新当前合并区域的法向量等几何信息,随后分别通过公式(6)和公式(7)计算与邻接超体素块的法向量夹角和正交距离作为区域聚类的融合条件。
(6)

(7)
式中,Ci为邻接超体素的质心;Cq为当前聚类区域的质心。
本文改进后的基于超体素的区域聚类算法具体步骤如下:
1) 对每个超体素内的每个点遍历其所有近邻点,如果当前点与其某个近邻点属于不同的超体素,就把近邻点所属的超体素标记为当前超体素的邻接超体素;
2) 根据上文所述的方法计算高程差。并设置不同的法向量夹角阈值;
3) 采用改进的方式计算区域间的法向量夹角和正交距离度量相邻超体素的相似性,进行合并操作,直至合并区域与所有其邻接超体素不满足条件为止;
4) 重复2)、3)步骤直至所有超体素都划分到相应区域;
5) 计算合并得到的每个区域内的点数,将小于阈值的区域视为噪声点去除。
3 实验与分析
本文的算法的实验环境:Intel(R)Core(TM)i7-4770 CPU @3.40 GHz、运行内存为8 GB,在Microsoft Visual Studio 2017开发平台上采用C++实现。采集的数据预处理后,点数为302646,其如图3所示。

图3 预处理后点云数据Fig.3 Point cloud data after preprocessing
对数据进行过分割时,设置求法向量的邻域值K为7,超体素分辨率设置为2。初次过分割和细化边界后的最终超体素分割图如图4所示。在图4(a)中每个超体素的边界线非常不规则,并且相邻超体素之间出现跨越边界的现象,经过细化边界操作后,每个超体素的形状规则,其之间的边界也定义明确。


图4 超体素过分割Fig.4 Supervoxel oversegmentation
在区域生长合并时,首先根据超体块的大小设置高程差为0.25,如果大于0.25的就判定将要生成的区域为竖直或倾斜面,将其聚类的法向量夹角阈值参数设置为70,将小于0.25的,就提前认定为地面或者与地面平行的平面,由于地面很平整,将其设置一个较小的法向量夹角阈值15;其正交距离阈值在聚类过程中动态获取。为了更加直观地体现本文提出的算法的分割效果的优良性,本文采用PCL库里的区域生长分割算法、改进前的超体素分割融合算法与其对比。对于两种对比算法使用的KD-tree中的k邻域搜索、法向量夹角阈值和最小聚类点数关键参数均与本文改进算法设置的参数一样。三种算法分割的结果如图5所示。为了更加清晰的显示分类结果,现把每类地物单独提取出来显示,如图6~图11所示。



图5 各算法分割效果图Fig.5 Segmentation effect diagram of each algorithm



图6 路灯提取Fig.6 Street light extraction

(a)区域生长车

(b)改进前算法车

(c)本文算法车图7 车辆提取Fig.7 Vehicle extraction

(a)区域生长楼梯

(b)改进前算法楼梯

(c)本文算法楼梯图8 楼梯提取Fig.8 Stair extraction
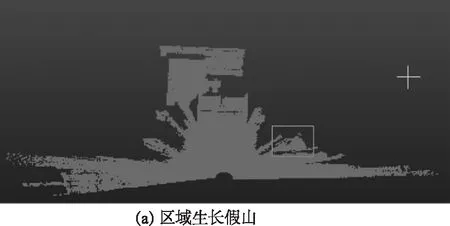

图9 假山提取Fig.9 Rockery extraction



图10 墙面提取Fig.10 Wall extraction

图11 小树木提取Fig.11 Small tree extraction
对于算法分割的结果,本文把不同的类别赋予不同的颜色,从图5的3种算法各自分割的整体结果图,可以看出区域生长算法的地面与其他物体分为了一类,改进前算法及本文算法均把地面单独分为了一类。从图6可以看出,区域生长算法分割只提取得到了6根路灯,缺失了2根,并且由于分割结果中点数小于阈值,造成部分路灯的下部分、灯头部分或整个灯头的缺失;改进前的算法虽然得到了8根路灯,但是该算法把其中的4根路灯分为了上下两截,同时提取的路灯中也存在路灯的下部分和灯头部分的缺失的现象;本文算法把8根路灯都完整地提取出来了。从图7中的车的提取,可以看出区域生长算法把两辆车的正面和侧面均分为了一类,并且其中一辆车的侧面还存在欠分割;改进前算法提取的两辆车的其中一辆的正面和另外一辆的顶部均分为了两类;本文算法均把两辆车的正面、侧面和顶部各自分为了一类。从图8的楼梯提取的结果中可知,区域生长算法把楼梯与墙面、地面、假山分为了一类;改进前算法把楼梯分为了多个类;本文算法虽然在楼梯的一侧扶手的边缘处存在欠分割现象,但把楼梯的其余部分分为了一类,提取效果理想。从图9的三幅图可以看出,区域生长算法没有把假山从其他物体中分割出来;改进前的算法把假山分为了4类;只有本文算法把假山分割成了一个整体。从图10中可以看出,区域生长和改进前的算法均对图书馆的墙面的分割存在欠融合想象,并且区域生长算法把凹凸的墙面与地面等物体分为了一类,同时避雷针也没有分割出来;本文的算法均把凹凸的墙面、避雷针、上部的墙面、其余墙面各自分为了一类。图11的三幅图为三种算法对一棵扫描较好的小树的提取的图,可以很清楚的看出区域生长和改进前的算法对树的树冠超体素没有很好的融合,并且区域生长算法提取的小树的树根和部分树叶缺失了;本文算法把小树的叶子和树根超体素融合为了一个整体,提取出来了。同时结合图5的各算法的分割效果图,可以进一步看出区域生长算法对树木的点云信息损失与其他两种算法相比较为严重;图5(b)改进前的算法结果图可知,树叶存在欠融合现象;从图5(c)可以看出虽然提出的算法没有把各棵树都完整的单独分割为一类,但是也尽量的把具有相似的几何信息的枝叶超体素生长融合为了一类。
本文采用分割后得到的区域数量和通过分割前后的点数计算的点云损失率,定量地对比这三种算法,如表1所示。从表1中可以看出,虽然PCL库里的区域生长算法对场景的分类数为853,在三者中最小,但是这是由于过度聚类造成的,同时点云损失率为55.7 %,为三者最高,点云几何信息损失极为严重;改进前后算法的点云损失率比较接近,分别为6.9 %和4.3 %,但是改进前算法出现了欠聚类现象,最终分割得到2653块区域,是改进后算法的区域数量的2.49倍。综上所述本文提出的算法无论从视觉上还是两项指标的衡量上,均优于改进前和区域生长算法。
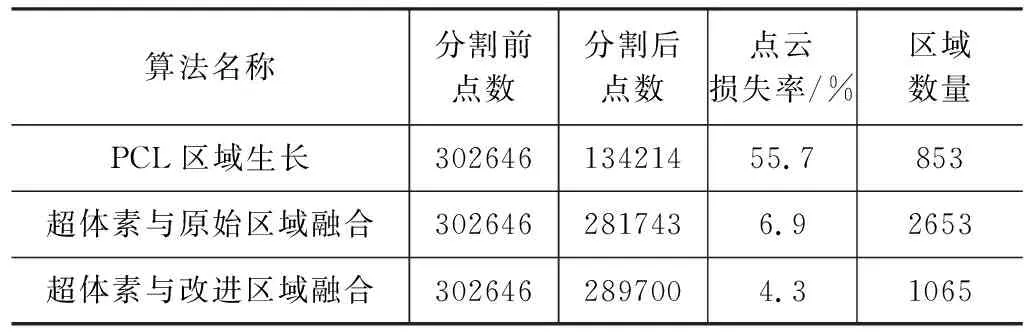
表1 不同分割算法下的损失率和区域块数Tab.1 Loss rate and number of regions under different segmentation algorithms
4 结 论
针对复杂场景分割较难的现状,本文提出了一种基于超体素的区域生长算法,该算法不需要对图书馆及周围场景的先验知识,仅计算点云固有的几何属性,就能完成精确分割。首先使用了最新的超体素分割算法,减少了跨越边界的现象的发生,使最终的每块区域的边界与真实边界相吻合。其次为了避免属于同一类的复杂物体被分割为多个类别,同时减少因欠分割而被当作噪声去除的现象的发生,对区域生长算法进行了两点改进:①对平滑的平面和起伏较大的面分别使用不同的法向量夹角阈值进行聚类合并;②在生长过程中,当当前合并区域改变时,就重新计算其法向量等几何信息。改进后的算法与区域生长算法和改进前的算法对自行采集的数据进行分割,实验结果表明,只有本文提出的算法对场景的各个物体进行了正确的分割,同时在点云损失方面优于后两种算法。总的来说本文的算法对复杂场景分割具有准确性和可靠性,为后续的三维重建、目标识别、物体的分类奠定了良好的基础。
本文的算法的不足之处在于引入了新的参数,使在分割过程中自动化程度降低,且过分割得到的超体素的好坏,直接影响最终的区域聚类分割效果,在未来的学习研究中可以消除此参数和减小依赖程度,增加算法的自适应能力。
猜你喜欢
计算机集成制造系统(2022年11期)2022-12-05
新高考·高一数学(2022年3期)2022-04-28
家庭医学(2022年3期)2022-04-07
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
计算机集成制造系统(2020年4期)2020-05-08
铁道通信信号(2019年6期)2019-10-08
中国惯性技术学报(2019年1期)2019-05-21
雷达学报(2017年6期)2017-03-26
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
