
基于图卷积网络的微博新闻故事线抽取方法
2021-12-07 10:08赵旭剑王崇伟
计算机应用 2021年11期
赵旭剑,王崇伟
(西南科技大学计算机科学与技术学院,四川绵阳 621010)
0 引言
互联网时代,Web信息的爆炸式增长以及迅速的更新,使得人们很难全面、准确、及时地从中获取事件的故事线演化脉络。作为社交网络的代表,微博为发现新闻事件及其演变提供了有价值的数据。但如何对这些零碎的数据进行深度挖掘和分析,形成能准确描述事件演化的故事线,已经成为网络用户的急切需求。此外,故事线抽取结果所描述的事件演化与新闻事件的大众舆论紧密关联,因此,故事线抽取对网络舆情研究同样具有重要意义。
目前故事线生成的相关研究工作以考虑事件的显式关联关系为基础,利用相似性将事件链接以构建故事线。传统相似性计算方法是链接事件的基础,例如Liu等[1]提出故事森林(Story Forest),利用事件关键词的Jaccard 相似系数链接事件并生成故事线,此外互信息[2]和余弦相似度[3]也是常用的相似性度量方法。研究人员也常常利用相似性把事件建模为图结构,将故事线抽取转化为图中树生成问题,常见有最大生成树[4]和斯坦纳树[5]等树生成算法构建故事线。但这两类方法都依赖丰富的事件语义信息,而这是目前微博数据所缺乏的,尽管有研究人员基于微博特征扩展,例如训练微博向量[6]。为解决这一问题,贝叶斯模型被使用来建立事件间的隐式关系,如Hua 等[7]将贝叶斯模型引入到故事线生成中,将故事线建模为包括故事线、事件和主题的三层结构;但贝叶斯模型参数推断复杂,时间复杂度较高。
总之,目前从微博中抽取故事线存在两个挑战性的问题:1)如何提取微博中的首要事件。现有的大部分故事线抽取工作忽略了提取首要事件的过程,基于图的算法把首要事件提取转化为图中关键节点提取,但也忽略了事件原本特征。2)如何学习事件关联关系并构建故事分支。事件相似度计算依赖丰富的事件信息,贝叶斯模型虽然一定程度上能学习事件隐式关系,但也带来了较高的时间复杂度。
针对以上问题,本文提出了一种从微博自动抽取故事线的方法,该方法通过挖掘微博事件影响力抽取首要事件,利用图结构建模事件关系,并设计一种改进的图卷积网络(Graph Convolutional Network,GCN)学习事件关系,最后链接事件并构建故事线。本文的主要工作如下:
1)提出了基于微博传播影响力的事件抽取模型。定义微博事件重要性元素,将事件重要性建模为微博的传播影响力,在此基础上抽取构建故事线的首要事件。
2)提出了一种异构图结构来建模事件关系。与考虑通过相似性关联建立事件关系的方法不同,本文对事件、关键词分别定义对象节点,并采用点互信息、词频-逆文本频率(Term Frequency-Inverse Document Frequency,TF-IDF)以及时间老化模型分别对节点间的关系进行建模。
3)提出了一种事件图卷积网络(Event GCN,E-GCN)模型,用于学习事件之间的隐式语义关系,以链接事件并预测事件的故事分支。此外,设计了一种基于差异度的方法来解决图卷积网络需要少量标签节点初始化的问题,避免人为构建标签对故事线抽取的干扰。
1 相关工作
自互联网兴起,故事线挖掘成为Web 数据挖掘领域的一个研究热点。Makkonen等[8]最早把故事线挖掘视为话题检测与追踪的子课题,用图结构表示故事线及其事件演化关系,后来Nallapati 等[9]提出了事件线索(Event Threading),为后来故事线自动抽取研究奠定了理论基础。总的来说,目前故事线抽取工作在新闻网站和社交网络上均有广泛影响力。
1.1 基于新闻文档的故事线抽取
社交网络兴起前,故事线抽取工作多数基于新闻文档,并且存在一些与故事线生成相关的会议和研讨会。例如,新闻媒体中故事线挖掘的系统研究可以追溯到文本检索会议(Text REtrieval Conference,TREC)。TREC 2013 要求研究人员从网络新闻语料库中提取事件时间轴,这是故事线生成的早期思想。随后,其他一些会议也举行了类似的评估任务,如2017 年由计算语言学协会主办的“新闻中的事件与故事”研讨会。此外,还有一部分相对独立的研究,根据方法不同可分为三类:聚类、贝叶斯模型和基于图的方法。
聚类算法将不同的故事分支视为不同的簇。研究人员提出一些事件操作来构建故事线,例如Liu 等[1]提出“故事森林”将数据流聚类成事件,并基于聚类的思想提出合并、扩展、插入三种事件操作将事件链接在故事线上。类似还有Laban 等[10]提出的链接、分裂、合并三种事件操作。然而,基于聚类算法构建故事线依赖于明确的语义信息,需要丰富的事件内容。
贝叶斯模型将故事线建模为事件特征的联合分布,通过参数推断得到事件的故事分支。与聚类算法相比,贝叶斯模型不考虑显式语义信息来生成故事线。例如佘玉轩等[11]将贝叶斯模型引入到故事线抽取中,将故事线建模为日期、时间、机构、人物、地点、主题以及关键词的联合分布。而Zhou 等[12]对事件命名实体进行细粒度划分,将故事线建模为命名实体和主题的联合分布,推导出每个事件所属的故事分支。然而,贝叶斯模型在推导参数时需要较高的时间复杂度。
基于图的方法将事件的语义特征与时序特性结合,把事件建模为图结构,根据图算法生成故事线,主要步骤为:1)通过相似度关系将事件建模为图结构;2)选择重要节点作为代表事件;3)通过生成树算法从图中生成故事线。例如Wang等[13]基于最小权重支配集选取代表性事件,利用有向斯坦纳树生成故事线。而Yuan 等[5]则是基于度和聚类系数选取代表性事件。然而,最小权重支配集和斯坦纳树均为NP-hard问题,即基于图的方法也需要较高的计算代价。
1.2 基于社交网络的故事线抽取
微博媒体的兴起掀起了社交网络文本挖掘的热潮。传统基于新闻文档的故事线抽取研究依赖新闻文档中丰富的文本内容来计算事件之间的相似关系,然而微博数据往往内容稀疏、表达隐含且缺乏上下文,对基于文本相似度度量的故事线抽取方法具有较大挑战。因此,研究人员针对社交网络的属性做了更多的扩展。
为了解决数据稀疏问题,Hawwash 等[6]把微博训练成事件向量,通过对事件进行聚类以生成故事线。Cai等[14]提出四种事件操作来捕获事件随时间的演化模式,并提出一种事件索引结构来解决大规模事件更新问题。“标签”是社交网络中最显著的特征,因此Hua 等[7]基于微博“标签”来识别故事线、事件类型和主题间的关系,并将贝叶斯模型引入到故事线生成中,将故事线建模为包括故事线、事件和主题的三层结构。
虽然基于图的算法在目前生成故事线中应用最广泛,但图算法是NP-hard问题,且社交网络中的数据规模远大于新闻数据,所以面向社交网络的故事线抽取研究也面临挑战。为了解决该问题,Lin 等[15]提出了一种动态伪相关反馈语言模型,在给定事件查询的情况下检索相关帖子,降低事件冗余度,通过最小权支配集和有向斯坦纳树生成故事情节。而李培等[16]则利用Top-K优化支配集算法,并利用时间窗口降低斯坦纳树算法的复杂度。此外,李莹莹等[4]把事件的演化表示为一个有向无环图,在图中识别弱连通分量形成弱连通分量集合,为每一个弱连通分量构造一个最大生成树得到故事线。
综上所述,由于社交网络数据存在内容稀疏、规模庞大和缺乏上下文等特点,传统基于新闻文档的故事线自动抽取研究较难直接应用于社交网络。目前,基于社交网络的故事线抽取研究相较传统基于新闻网站的抽取方法进行了一系列改进,包括训练微博向量、利用微博“标签”、应用时间窗口等,但仍旧存在局限性,特别是未能较好解决首要事件抽取与故事分支构建两个关键问题。
2 定义与框架
2.1 概念定义
定义1事件,指在特定时间和地点内发生的,有一个或多个对象参与,由一个或多个动作组成的事情。定义为E=,其中C是事件文本,TC是事件发生时间。
定义2首要事件,指事件演化过程中最具代表性的事件,是组成故事分支与故事线的基本事件单位。定义为Ep∈E。
定义3故事分支,指由多个相同主题的事件构成,并用事件关系串联起来的一条事件时间轴。定义为Branch=Event_set,TS,其中Event_set是组成故事分支的事件集合,TS是故事分支的时间段。
定义4故事线,是由一条或多条相关联的故事分支构成的表示事件间演化关系的树状结构。定义为Storyline=Branch_set,link,其中Branch_set是故事分支集合,link表示事件间的链接关系。
例如图1 展示了“长春长生疫苗事件”的部分故事线。图中,节点表示事件,深色节点为过渡节点,有向边表示事件的演化关系,节点序号表示时间维度上事件的演化顺序。图2展示了三条故事分支,故事分支1 讨论与“国家药品监督管理局”相关事件,故事分支2 讨论“朋友圈中民众反应”,故事分支3 讨论“疫苗管理法的实施过程”。通过建模事件演化构建故事线,用户能够轻松从中获悉社会事件的演化过程。
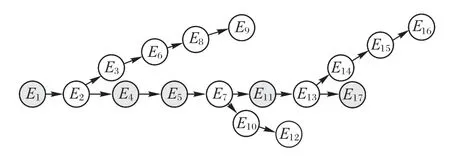
图1 “长春长生疫苗事件”部分故事线Fig.1 Part storyline of“Changchun Changsheng vaccine incident”

图2 故事分支示例Fig.2 Examples of story branch
2.2 问题定义
2.3 框架组件
微博新闻故事线抽取研究主要包括事件提取和故事线抽取两个主要模块。图3 展示了框架组件。首先,通过一系列机器学习方法对原始微博数据进行预处理,主要包括微博切分、时间表达规范化和冗余过滤;然后,基于微博事件的传播度对事件排序,提取首要事件;接着,使用异构图来建模事件之间关系,同时,为了识别初始故事分支,提出了一种基于差异度的方法;最后,利用事件图卷积网络来生成故事线。
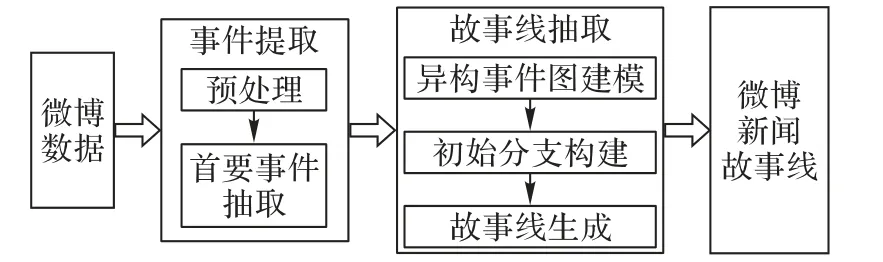
图3 框架组件Fig.3 Framework components
3 事件提取
事件提取旨在对微博进行数据清洗,并从微博中提取首要事件。首先,对微博进行预处理,包括微博切分、时间表达式规范化和冗余过滤三个步骤,得到粗粒度的事件集合;然后,基于微博的传播特性对微博事件进行排序筛选,基于事件的传播度排名提取首要事件。
3.1 预处理
预处理的具体操作如下:
1)微博切分。每一个完整的句子都能表示一种完整的语义信息,因此基于能表达句子结尾意思的标点符号对微博帖子进行切分,得到候选事件集合,然后考虑将每一个包含时间表达式的微博帖子视为一个事件,这些事件构成了故事线最初的事件集合。
2)时间表达式规范化。时间是事件的显著特征,而事件中往往存在诸如“3 月24 日”“24 日”等不够精确的模糊时间,以及“今天”“昨天”“本周五”等类似的隐式时间表达式。对于模糊时间,把微博的发布时间作为基准时间,采用一种顺序匹配的方法将模糊时间规范化;对于隐式时间,基于规则匹配的方法进行规范化。
3)冗余过滤。由于微博的“社交”特性,转发将导致大量的冗余微博,使得事件集合将存在大量冗余事件并且导致信息泛滥。本文提出使用两层相似度对事件集合进行冗余过滤,分别是句子层面和事件集合层面。其中,句子层面的相似度由最长公共子串计算,可以有效去除由转发带来的重复微博。而事件集合层面的相似度通过TF-IDF 算法建立事件向量、然后计算事件向量的余弦相似性得到,能够有效去除由相同事件带来的重复微博。最后总体相似度计算式为:

其中:vei和vej分别是事件ei和ej的向量表示;di和dj分别是事件ei和ej的原始文本。
3.2 首要事件抽取
经过预处理得到初始事件集合,然而,故事线致力于直观地展示事件随时间的演化。因此,用于构建故事线的事件必须能全面地代表事件的演化信息。对于社交网络而言,意见领袖对信息传播的影响更大,因为微博中的意见领袖通常比普通用户传递更多的关键信息。为此,意见领袖发布的微博更有可能是首要事件。
因此,提出使用微博的传播度来衡量事件是否为故事线中的首要事件,并利用微博的发布者粉丝量以及转发、评论和点赞的数量来量化事件的传播影响力。如果一条微博由更具权威的用户发布,并且拥有更多转发、评论和点赞,即认为该微博包含了众多用户都能认可的基本信息。因此,与那些转发、评论和点赞相对较少的微博相比,这条微博将更可能讨论首要事件。具体来说,把微博的传播度定义为四元组S=user_fansnum,forwardnum,commentnum,likenum,其中,user_fansnum指微博发布者粉丝数,forwardnum指微博转发量,commentnum指微博评论量,likenum指微博点赞量。事件的重要性得分计算式为:

其中,wi为S不同元素的权重值。由式(2)计算出事件的重要性得分后,依据得分对事件进行排序,删除排名靠后的事件,选取排名靠前的事件作为故事线抽取阶段的输入。
4 故事线抽取
故事线抽取主要分为三个步骤实现,即异构事件图构建、初始故事分支构建和事件图卷积网络(E-GCN)。首先,利用语义关系和事件的时间老化关系将事件及其特征词建模为异构图;然后,提出一种基于差异度的方法构建初始故事分支;最后,利用E-GCN模型识别故事分支并构建故事线。
4.1 异构事件图建模
图卷积网络(GCN)[17]是一种对图进行操作并完成图半监督学习的神经网络。基于GCN 模型,本文提出了一种事件图卷积网络(E-GCN)模型用于学习事件间的隐式语义关系。由于图可以表示复杂的节点关系,因此考虑基于事件特征把事件建模为异构事件图。考虑到基于相似性的方法难以学习事件间的隐式语义关系,本文提出使用事件和事件特征词两种节点,基于共现关系建模事件关系图。同时,基于事件的时间老化关系将事件时间特性融入异构图。
具体来说,构建了一个异构事件图G=(V,E)来表示事件之间的关系,每个节点v∈V包含部分事件信息。主要有两种类型的节点:特征词节点和事件节点,并把事件文本中的名词、动词、形容词和量词作为事件特征词。此外,每条边e=(v,v')∈E表示两个节点之间的关联关系。有三种类型的边:特征词-特征词、特征词-事件和事件-事件。
三种类型的边权重由不同的方法计算,其中特征词-特征词间的权重关系由点互信息计算,特征词-事件的权重关系由TF-IDF 算法计算。此外,在演变过程中,属于同一故事分支中的事件往往发生在有限的时间内,这意味着当两个事件的时间跨度较大时,这两个事件有极大可能性在不同故事分支中。因此,本文根据时间老化模型[18],提出了一种针对事件时间老化的关系来衡量两个事件之间的相关性:
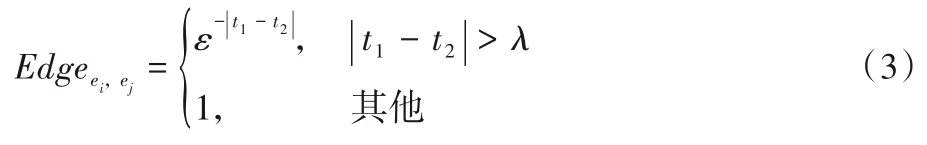
式中:ε为自然常数;λ为最大时间跨度因子;t1和t2分别为事件ei和ej的发生时间。
根据上述关系建立如图4 所示的异构事件关系,图中较大节点是事件节点,较小节点是事件特征词节点。其中,事件间是一种由时间老化关系衡量的全连接关系,而特征词间的关系、特征词和事件的关系是一种词共现关系。
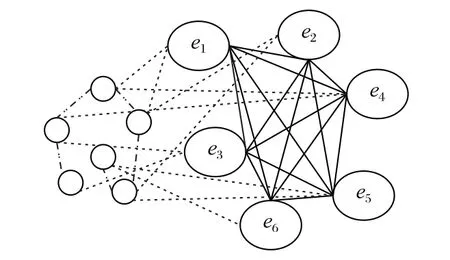
图4 异构事件关系Fig.4 Heterogeneous event relation
4.2 初始故事分支构建
图卷积网络是一种半监督学习算法,可以用于节点分类,但需要每种类别具有少量带标签节点。为了避免故事线构建过程中人为因素的干扰,本文设计了一种基于差异度的启发式算法来从每一个故事分支中识别一个事件,以此构建初始故事分支,并将其作为E-GCN 模型中的标签节点。该算法的主要目标是选择不在同一故事分支的事件作为初始故事分支,以提高后续故事分支构建的准确率。
首先,从事件集合E中选择第一个随机事件e1加入初始故事分支集合S并从E中删除e1;然后,计算S和E中剩余事件的相似度,选择最不相似的事件ei加入S并E中删除从ei,重复上述过程直到差异度大于设定的阈值,最后得到初始故事分支集合。算法1描述了构建初始故事分支的过程。
算法1 基于差异度的初始分支构建算法。

4.3 基于事件图卷积网络的故事线生成
事件图卷积神经网络模型的输入为邻接矩阵和特征矩阵,邻接矩阵由事件异构图模型得到,特征矩阵由TF-IDF 算法得到。本文建立了N×N的邻接矩阵A,N×d的特征矩阵X,其中,N为事件数量,d为事件特征维度。然后,提出E-GCN模型来学习事件间的隐式语义关系,即通过预测每一个事件所属的故事分支来学习事件关系。具体地说,建立多层GCN模型以及式(4)表示的传播规则[19]:
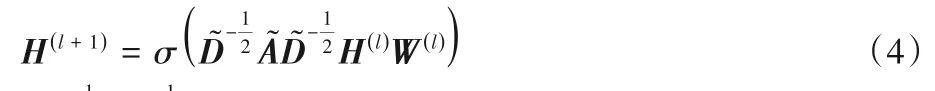

其中:yE是带标签事件节点集合,即初始故事分支;F是输出特征的维度,即故事分支数目;Yef是事件标签集合;Zef是故事分支集合。
E-GCN 模型的架构如图5 所示,首先事件被建模为异构事件图,其中异构事件图的邻接矩阵A和特征矩阵X是E-GCN模型输入,经过多层网络学习,输出每个事件节点的故事分支分类结果。
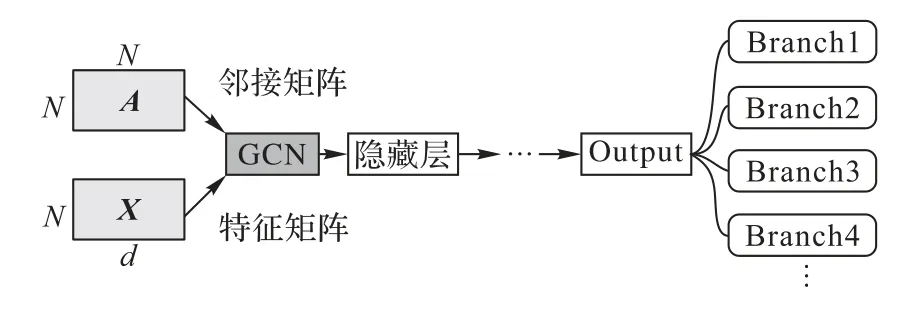
图5 E-GCN模型架构Fig.5 Architecture of E-GCN model
本文实现为三层模型,允许最远三个节点进行特征传递。如图6 所示,图中不同图案的事件节点表示每个事件节点所属的不同故事分支。值得注意的是,在训练之前,每个故事分支中只有一个带图案的标签节点,这是基于差异度的方法选择的初始故事分支。
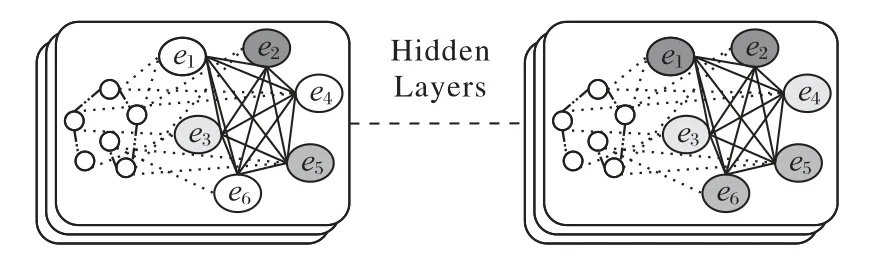
图6 事件图卷积网络实现Fig.6 Implementation of event graph convolutional network
经过事件提取和故事分支构建,得到事件和事件间的关系,在此基础上,进一步挖掘故事线的脉络结构。通常故事线具有一定的逻辑关联性,由故事分支和过渡节点构成,合理的过渡节点能够使得故事线更加流畅,结构完整。根据模型输出的故事分支,采用一种基于统计的方法识别过渡节点,即当存在同一节点被模型输出到不同的故事分支时,该节点可能属于过渡节点。最后,根据过渡事件节点和故事分支,基于事件时序关系,将过渡事件节点和故事分支串联起来,生成结构化的故事线。
5 实验与结果分析
5.1 数据集
为了评测本文方法的实验性能,在两个真实的微博新闻数据集(https://weibo.com)上进行了对比实验分析。爬取的微博帖子均为热门微博,数据集具体信息如表1所示。

表1 数据集具体信息Tab.1 Specific information of datasets
5.2 故事分支构建实验评测
本文在事件故事分支评价实验中设置了三个对照组,分别是贝叶斯模型[12]、斯坦纳树[16]和故事森林[1],详细信息如下所述:
1)贝叶斯模型(Bayesian Model):该方法对事件特征进行建模,并根据吉布斯采样结果推导出事件所属的故事分支。
2)斯坦纳树(Steiner Tree):该方法通过斯坦纳树算法生成故事线。由于在第3 章中提取的事件数量是固定的,而斯坦纳树问题允许在给定的点上添加额外的点。因此,本文对比过程中利用斯坦纳树的特殊情况,即最小生成树构建故事线。
3)故事森林(Story Forest):该方法通过提取事件关键字,利用事件关键字的Jaccard 相似系数衡量是否将事件聚类到某个故事分支。
为了评价故事分支,使用第3 章中提取的首要事件集合,并以人工构建结果为标准,通过计算预测故事分支结果Ep与标准结果Es之间的相似度,建立预测故事分支与其相似度最高的标准故事分支之间的映射。用准确率、召回率和F1值对故事分支进行评估。映射关系相似度计算式为:
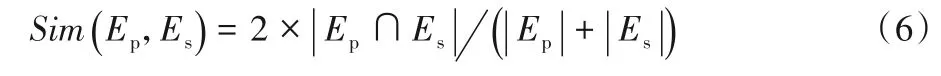
表2和表3分别展示了在Dataset1和Dataset2上故事分支构建的结果。其中,相较于贝叶斯模型、斯坦纳树和故事森林在F1 值上,本文方法在Dataset1 上分别高出28 个百分点、20个百分点和27个百分点,在Dataset2上分别高出19个百分点、12 个百分点和22 个百分点。在Dataset1 中本文的方法取得了最佳性能,而在Dataset2 上本文的方法在召回率上略低于斯坦纳树方法。经过分析发现,这是由数据集中事件的时间分布引起,Dataset1中事件的时间跨度约为1年,而Dataset2中事件的时间跨度仅3 个月,这直接影响了事件的时间老化关系建模。

表2 不同方法在Dataset1上的故事分支构建结果Tab.2 Story branch construction results of different methods on Dataset1

表3 不同方法在Dataset2上的故事分支构建结果Tab.3 Story branch construction results of different methods on Dataset2
5.3 故事线抽取实验评测
本文基于时序关系将故事分支构建为故事线,并设置三种结构的故事线对照组,分别是故事时间线、斯坦纳树[16]和故事森林[1],详细信息如下:
1)故事时间线:该方法将事件按照时间序列进行链接,是一种单分支故事线。
2)斯坦纳树:该方法生成的故事线为树状多分支结构,且故事分支上还有更细的演化分支。
3)故事森林:该方法生成的故事线为树状多分支结构,且故事分支上没有更细的演化分支。
为评价故事线,首先基于标准故事分支构建标准故事线,然后借鉴文献[1]的评测方法,把正确的边作为故事线的结构性评价指标,其中正确的边指同时存在于标准故事线Edges和生成故事线Edgeg中的边,准确率由式(7)计算:

表4 展示了故事线抽取中正确的边准确率结果。其中,相较于故事时间线、斯坦纳树和故事森林在正确的边准确率上,本文方法在Dataset1上分别高出33个百分点、23个百分点和17个百分点,在Dataset2上分别高出12个百分点、3个百分点和9 个百分点。由于故事线抽取的主观性,事实上正确的边链接性能表现并不好。故事时间线是将事件按照时序关系排列,因此性能最差。基于斯坦纳树和故事森林的方法都考虑了事件的显式语义关系,因此具有相似的性能。本文的方法考虑了事件的隐式语义关系,从而取得了最佳性能。

表4 不同方法的故事线抽取中正确的边准确率对比Tab.4 Accuracy comparison of correct edge in storyline extraction by different methods
6 结语
从社交网络中抽取故事线对于人们全面了解新闻事件具有重要意义。本文通过建模微博传播特性,提取微博新闻首要事件,并用异构图建模事件关系,提出了一种改进的图卷积神经网络模型学习事件间的隐式关系,以预测事件的故事分支并链接事件。在真实微博数据集上进行实验,结果表明,本文的方法能够抽取逻辑合理、结构清晰的故事线,帮助用户全面、准确地理解事件演化。
猜你喜欢
黑龙江大学自然科学学报(2022年1期)2022-03-29
计算机系统应用(2021年10期)2022-01-06
数理化解题研究·综合版(2021年11期)2021-12-22
小学教学研究(2021年5期)2021-09-29
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
奇闻怪事(2020年6期)2020-07-18
读者·校园版(2020年8期)2020-04-15
初中生世界·九年级(2020年2期)2020-04-10
学生天地(2019年28期)2019-08-25
中等数学(2018年8期)2018-11-10
