
Remaining Time Prediction for Business Processes with Concurrency Based on Log Representation
2021-12-03 01:25RuiCaoWeijianNiQingtianZengFamingLuCongLiuHuaDuan
China Communications 2021年11期
Rui Cao,Weijian Ni,Qingtian Zeng,*,Faming Lu,Cong Liu,Hua Duan,*
1College of Computer Science and Engineering,Shandong University of Science and Technology,Qingdao 266510,China
2School of Computer Science and Technology,Shandong University of Technology,Zibo 255000,China
Abstract:Remaining time prediction of business processes plays an important role in resource scheduling and plan making.The structural features of single process instance and the concurrent running of multiple process instances are the main factors that affect the accuracy of the remaining time prediction.Existing prediction methods does not take full advantage of these two aspects into consideration.To address this issue,a new prediction method based on trace representation is proposed.More specifically,we first associate the prefix set generated by the event log to different states of the transition system,and encode the structural features of the prefixes in the state.Then,an annotation containing the feature representation for the prefix and the corresponding remaining time are added to each state to obtain an extended transition system.Next,states in the extended transition system are partitioned by the different lengths of the states,which considers concurrency among multiple process instances.Finally,the long short-term memory(LSTM)deep recurrent neural networks are applied to each partition for predicting the remaining time of new running instances.By extensive experimental evaluation using synthetic event logs and reallife event logs,we show that the proposed method outperforms existing baseline methods.
Keywords:business process monitoring;remaining time prediction;LSTM;feature representation;concurrency
I.INTRODUCTION
Business process remaining time prediction[1,2]is one of the important challenges of predictive business process monitoring[3],and its goal is to predict the remaining time of running business process instances.Given a running business process instance(called case or trace),accurate prediction of its remaining time can not only allocate resources reasonably and balance resource utilization,but also effectively achieve business goals to increase user experience.
In general,there are two basic factors that may affect the remaining time of running process instances.One is the structural information,e.g.,the cyclic structure,of single process instance;the other one is the interaction or resource competition among concurrent process instances.For instance,time prediction on multi-perspective declarative business processes is proposed in[4],first,a multi-perspective constraintbased language is used to model the scenario.Then,remaining time predictions are performed on model which be only based on concurrent process instance.In[5],a new predictive business process monitoring technique for the next activity and timestamp prediction based on time-aware LSTM(T-LSTM)cells is introduced.However,the authors did not consider concurrent process instances in their approach.In[6],a technique that leverages the sentiments of online news for the task of remaining time prediction is developed.They found that the approach based on the Before algorithm performs consistently better than a baseline,therefore proving that an external context is influential for the process.However,the authors rarely consider the structural information within the trace and concurrent process instances in their approach.Although researchers have done a lot of work to predict remaining time of process instances,existing work rarely consider both factors.To address this issue,a new prediction method based on trace representation is proposed.
specifically,the proposed method firstly generates a prefix set from an event log,and associates each prefix to a different state of the transition system.Then,the attribute encoding(feature vector)and the corresponding remaining time(label)of prefix in state are calculated,and each state of the transition system is annotated.In this way,an extended transition system containing the annotated states is obtained.Finally,according to the different lengths of the annotation states,the annotation states of the extended transition system are partitioned and the prediction model is trained separately for each partition.Furthermore,the weighted average of the evaluations by multiple prediction models is obtained.
Generally,the remaining time prediction method of business processes can improve prediction performance by enhancing the encoding of the event log,partitioning the event log,and constructing a prediction model.The innovation of this paper is summarized as follows:
(1)Trace encoding includes information about trace execution,such as the duration of the activities,the maximum position of activity,and so on.The advantage of trace encoding is that the structure information of each trace is fully considered.
(2)The set of running traces(prefixes)is partitioned according to the state length of the transition system.Each partition is composed of prefixes of the same activities,including multiple concurrent prefixes.Train the prediction model separately for each partition,which can effectively take into account the concurrency of multiple process instances.
(3)The LSTM prediction models are used to predict the remaining time of the business process for each partition in the event log.Our method integrates the transition system and deep neural network to realize the remaining time prediction,which is a model & data-driven prediction method.
The remainder of the paper is structured as follows.Section II provides related work.Section III reviews essential technical concepts.Section IV introduces the proposed remaining time prediction method.Section V presents an experimental evaluation of our approach and compares it with existing baseline methods.Section VI concludes the paper and outlines future work directions.
II.RELATED WORK
Existing prediction methods of business process instances can be divided into model-driven methods,data-driven methods,and model & data-driven prediction methods.
2.1 Model-driven Prediction
The model-driven remaining time prediction method refers to mining business process models on the historical event log to predict the remaining time.In[7],a configurable method to construct a process model is proposed.The time information obtained from the event log is added to the process model,and the model is used to predict the remaining time.In[8],activity duration time is calculated by analyzing historical event logs and a general distributed transition stochastic Petri net(GDT_SPN)model is constructed.According to the GDT_SPN model,the completion time of the simulated partial traces(samples)is calculated.The simulated sample comes from the truncated distribution conditioned on the current time,instead of sampling from the original transition distribution.Finally,the completion time of all simulated samples is collected and the average to predict the remaining time is calculated.In[9]and[10],delay prediction for different types of customers in single-class or multi-class settings are proposed.The prediction illustrates online delay prediction of queue mining based on queue information and different techniques.
2.2 Data-driven Prediction
The data-driven business process remaining time prediction method directly mines the prediction models from event logs,and then the remaining time of running cases is predicted.
A general framework for associating business process characteristics is proposed in[11].The framework defines analysis use cases based on event logs,which include a dependent characteristic,a set of independent characteristics,and an event-selection filter.By performing an analysis use case,a decision tree or regression tree that depends on characteristics can be derived from the set of independent characteristics.Further,a method of clustering event log traces based on decision trees or regression trees is introduced in[12].The supervised machine learning methods to predict the remaining time of business processes are developed in[13].A bi-dimensional state space representation feature encoding by analyzing intra-case and inter-case characteristics of a specific data set is presented.The first dimension of feature coding reflects the dependency relationship of activities within the case,and the second dimension reflects the dependency to represent shared information among running cases.In[14],a method to predict the remaining execution time in a process instance based on bayesian neural networks is proposed.In[15],using the deep neural network with entity embedding to predict the remaining time of the running case,it combines a deep neural network with fully connected layer and entity embedding technology to significantly improve the accuracy of the remaining time prediction.In[16],the method of LSTM neural network has been studied.specifically,the historical event log is featurecoded and the encoded event log is used as input to train the remaining time prediction model.In[17]a method for predicting the remaining execution time of a business process instance based on deep transfer learning is proposed.This method uses a multi-layer recurrent neural network to train remaining time prediction model,and introduces a deep transfer learning mechanism to establish multiple prediction models.In[18],the remaining time prediction using bidirectional recurrent neural networks with attention is proposed.specifically,the bidirectional recurrent neural networks based on attention was used to train the remaining time prediction model,and the remaining time prediction was further improved using the deep transfer learning.In[19],a method of process remaining execution time prediction based on stacking strategy is developed,which combines naive bayes classifier,support vector regression and long short-term memory networks to establish remaining time prediction models.
2.3 Model & Data-driven Prediction
The model & data-driven business process remaining time prediction methods refer to the combing machine learning or deep neural network technology to achieve prediction of the remaining time based on the process model from the event logs.
In[20],the annotated transition system that combines classification and regression models to predict the remaining time of business processes.specifically,an annotated transition system is established through the event logs,in which a naive bayes classifier is added for each state,and a support vector regressor is added for each transition.In[21],a white-box approach is proposed to predict the remaining time of running process instances.The key idea is to predict the remaining time at the level of activities,and to aggregate these predictions at the level of a process instance by means of flow analysis techniques.In[22],two types of queue-based predictors are proposed,namely internal queue-based predictors reporting the current state of the emergency department enabled by process mining and arrivals-based predictors for the near-future crowding state of emergency department.A method to predict the outcome of a new case by analyzing business processes and the remaining time to complete the case is introduced in[23].First,a transition system is built based on the event log,and then two models of data mining are developed for each state of the transition system,one model predicts the results,and the other model predicts the remaining time before completion.Finally,using the cases in the same state to train the remaining completion time prediction model for the running cases.In[24],a remaining execution time prediction of business process instance via auto-encoded transition system is proposed which integrated process modeling and deep learning techniques.
The main limitations of the above-mentioned approaches are that the trace encoding does not sufficiently express the information about the traces,and the predictions are based on a single process instance(trace).However,the structural features of trace and concurrency among multiple process traces are the key factors affecting the remaining time of business processes.In this paper,we propose a method for predicting the remaining time of business processes with concurrency using trace representation.The proposed method combines transition system and the deep neural network to realize the prediction of the remaining time,which is a kind of model & data-driven prediction method.
III.PRELIMINARIES
Basic concepts related to business process remaining time prediction,including events,traces,event logs,prefixes,and transition systems,are given below.
Definition 1.(Event)[2]An event refers to an execution instance of an activity in a business process,which is denoted by e=(a,c,ts,te,(d1,v1),(d2,v2),···,(dn,vn))(n≥1),where a is the activity name of event e and c is the identifier of the process instance which event e belongs to.Then,tsand teare the time attribute(time stamp)of event e,indicating the execution start and end time of the event respectively.In addition,(d1,v1),(d2,v2),···,(dn,vn)describes other attributes of the event(for example,the executor of the event),d1,d2,···,dnrepresent the attributes of the event,and v1,v2,···,vnrepresent the values corresponding to each attribute,respectively.
In this paper,only the end time tsin the process instance is considered.
Definition 2.(Trace,event log)[2]A trace(case or process instance)σ=<e1,e2,···,em>(m≥1)is a non-empty sequence generated by the events and the time in the trace is non-decreasing,i.e.,ei.te≤ei+1.te(1≤i<i+1≤m)The event log is a set of traces,i.e.,L={σj|σj∈ U,1 ≤j≤K},where U is the universe of all possible traces and K is the number of traces in the event log L.
Definition3.(prefix)Given a trace σ=<e1,e2,···,em>(m≥1),the prefix of the trace σ can be expressed as the execution sequence of the first k events in the trace σ.
For example,given a trace σ=<a,b,c >,both<a > and<a,b> are prefixes of σ.
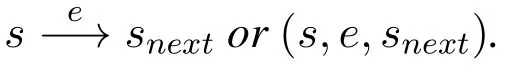
States in a transition system involve three abstractions,namely set,multi-set,and sequence,respectively.In this paper,the remaining time of the business process is predicted using the transition system based on the set abstraction.We choose the transition system using the set abstraction as the process model,because the set abstraction of the states has the characteristics of mutual dissimilarity and disorder,and makes it possible to consider the structural information(for example,the cyclic structure)and concurrency in the traces for the prediction of the remaining time for business process.
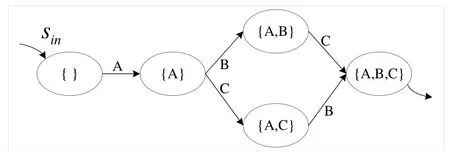
Figure 1.The transition system using the set abstraction.
For example,given two process instances σ1=<A,B,C > and σ2=<A,C,B >,the specific transition system using the set abstraction is shown in Figure 1.
It was March 29, 1944, and the twentieth mission for our B-17 crew. We were assigned to the 401st Squadron of the Mighty1 Eighth Air Force and flying out of a former Royal Air Force base at Bassingbourne, England. On that day, we were to lead an attack against an aircraft factory near Brunswick, Germany. On previous missions to this area, we had encountered fierce fighter opposition2 and were briefed now to expect more of the same. At this point in the war, our strategy was to destroy the Luftwaffe-in the air, on the ground and in the factories-in preparation for the planned D-Day landings.
IV.BUSINESS PROCESS REMAINING TIME PREDICTION
The framework of the method is given at first.Then,the key parts of the proposed method are presented one by one.
4.1 Framework Overview
The proposed method first explores the event log to generate its prefixes,and associates each prefix to a different non-empty state of the transition system.Then the prefix in each state is annotated(the annotation takes into account the structural information within the process instance)and the extended transition system is built.The states in the extended transition system(the partitions consider the concurrency among multiple process instances)are partitioned by the different lengths of the states,and the prediction model is trained on each partition.Finally,the evaluation of the remaining time prediction of business processes is realized.The framework is shown in Figure 2.
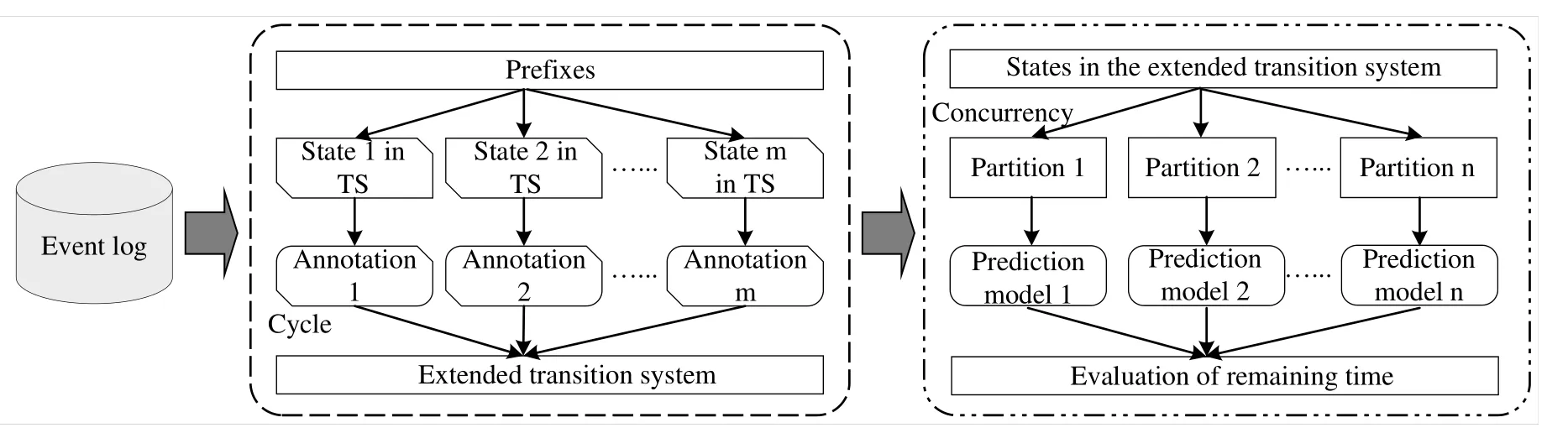
Figure 2.A framework of the proposed approach.
4.2 Methodology
This section introduces the proposed remaining time prediction method in detail,which includes remaining time prediction task,extended transition system,partitioning of states in extended transition system,and LSTM models.
4.2.1 Trace Feature Representation with Structural Features
The structure information(also called attributes or features)of event trace is the measurement of the state of the annotated transition system[7].For example,the complete timestamps of running process instances be a measurement.Encoding the features of the trace can take into account the structure features within the trace.In this way,the prediction accuracy of remaining time of business processes is effectively improved.In this section,we will introduce seven attributes of trace[26],namely the number of occurrences of the activity,the largest sequence of the activity,position,the number of single activities that have no cycle,distance,the number of repeated occurrences of the sequence,and the number of changes.The attributes of traces are shown in Table 1.
The attributes involved describes the structural information within the trace,where Occurrence,Cycle,Distance and Duple are closely related to the cyclic structure and intuitively explain the cyclic behavior in traces.Position,Single,and Change are closely related to the variation of trace.
Regarding the feature representation of the trace,a vector is formed by the concatenation operation of all the attribute values in the trace.The process of constructing the trace vector is shown in Algorithm 1.
Algorithm 1 describes the process of trace representation.First,VR is initialized in line 1.The loop in line 2 iterates all the traces in event logs,and prefixes of event log are obtained in line 3 and line 4.Then,lines 5 to 9 encode each prefix in event log,and lines 6 to 8 sequentially add each attribute value of the prefix to a vector to realize the encoding of the prefix.Finally,the vector of each prefix is returned in line 10.Note that the event logs in this paper is preprocessed to remove incomplete traces and noises.
Given a trace σ=<A,B,B,B,A,A,B,A,B >,which consists of two activities A and B.For its attributes,Occurrence,Cycle,Position,and Distance respectively correspond to two attribute values,Single and Change respectively correspond to one attribute value,and attribute Duple corresponds to four attribute values.Therefore,trace σ has a total of 14 attribute values.The attributes information is shown in Table 2.According to the order of each attribute value in Table 1,the feature vector of the trace is obtained and it can be expressed as VR(σ)=[4,5,1,2,8,9,0,1,1,1,3,2,2,5].
4.2.2 Remaining Time Prediction Task
The remaining time of trace refers to the difference between the end time of the trace and the current time(the time of the prediction point).Given a trace σ=<e1,e2,···,em> (m≥1),we define the remaining time of the trace as rem(σ,i)=t(em)-t(ei)(1 ≤i≤m),where emrepresents the end time of the trace and t(ei)represents end time for the execution of the event ei.
Under the machine learning framework,the remaining time prediction task is mainly composed of the training and application phases.The goal of the training phase is to construct remaining time prediction models based on event log.In the application phase,the models are used to predict the remaining time of running process instances.

Table 1.Attributes of traces.
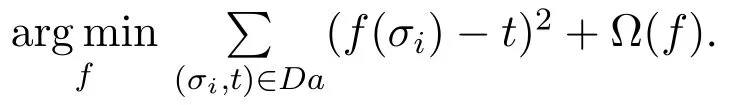
In the model application phase,a running process instance σi,which i represents the number of events in which σ have occurred,the mapping is used to estimate its remaining time,i.e.f(σi).
4.2.3 Extended Transition System
Transition system is introduced in section III,and the annotated transition system in[8]is added by the measure values to each of states in transition system,which further introduces the extended transition system.


Table 2.Attributes of a trace σ=<A,B,B,B,A,A,B,A,B >.
Definition 5.(Extended transition system)Let L is an event log,P is a set of prefix for L,and TS=(S,E,T,sin)is a transition system using the set representation.∀s ∈ S,the annotations of each state s is composed of the vector representation of each prefix in state s and its corresponding remaining time,namely List(s){(VR(σ),RT(σ,i))|∀s ∈ S,∀σ ∈ P}.And adding the annotations to the corresponding state,which is called extended transition system,where VR(σ)refers to the vector representation of prefix in the state,and RT(σ,i)refers to the remaining time corresponding to the vector representation of prefix in the state.
In Algorithm 2,lines 1 to 3 initialize the List(s)which are associated to each state s of the ETS.The loop(in lines 4 to 7)iterates all prefixes,first,associate each prefix to a different state in line 5.Then,the vector representation of each prefix of the state and the corresponding remaining time together are formed an annotation of a state in line 6.Lines 8 and 9 annotate all the state and construct the extended transition system.Finally,the extended transition system is returned in line 10.
Given an event log contains three traces(as shown in Table 3),and each trace contains three activities A,B,and C.First,the 17 prefixes are generated according to the event log,and the prefixes are divided into the different states.Then separately encode the pre-fixes in the transition system.It is known from Section 4.2.1 that for prefixes contain only one activity in state{A},and each prefix in state{A}has 7 attribute values.There are 14 attribute values for the prefixes in the states({A,B},{A,C})containing two activities.The reason is that the attributes Occurrence,Cycle,Position and Distance have two attribute values,Single and Change have 1 attribute value,and Duple has 4 attribute values.There are 23 attribute values for each prefix in a state containing three activities.Because the attributes Occurrence,Cycle,Position,and Distance have 3 attribute values,Single and Change have 1 attribute value,and Duple has an attribute value.In addition,according to Section 4.2.2,the remaining cycle time of each prefix is calculated and added to the corresponding prefix code.In this way,the prefix encoding and its corresponding remaining time constitute a training sample(VR(σ),RT(σ))for training prediction model.Finally,the extended transition system can be obtained by adding the list List(s)composed of training samples to each state s.The extended transition system is shown in Figure 3.


Table 3.An event log with three traces.
4.2.4 State Partitioning in Extended Transition System
Each non-empty state in the extended transition system based on the set abstraction is composed of different activities,except for the states of one activity.The length of each state can be considered as the number of the different activities in the states.According to the different lengths of the states,all the non-empty states in the extended transition system can be partitioned,and the states of the same length can be placed in the same partition.Finally,the prediction model can be trained on each partition.
Compared with using all training samples to train a single prediction model,using multiple prediction models on each partition can effectively improve the relevance of the remaining time prediction.Furthermore,the partitioning of all states in extended transition system according to the length of the states can take into account the concurrent relationship of multiple process instances,which helps to further improve the accuracy of the remaining time prediction of business processes.
In Algorithm 3,line 1 initializes each partition.Lines 2 to 5 divide all non-empty states in the extended transition system into different partitions.Line 3 calculates the length of each state.Line 4 is to classify the prefix representation of the state in length k and the corresponding remaining time into the partition Pk.The partitions of all states are realized in line 6 and the entire partitioning list is returned in line 7.
An example of state partitioning is shown in Figure 3.There are four non-empty states of the extended transition system,which are{A},{A,B},{A,C}and{A,B,C}.The length of each state is|{A}|=1,|{A,B}|=2,|{A,C}|=2 and|{A,B,C}|=3,respectively.According to the length of the states,it can be divided into three partitions,and,corresponding to class 1,class 2 and class 3 in Figure 3,respectively.In class 2,there is a concurrency between activity B and activity C, which reflects the concurrency between the prefixes(also called traces)of the two states{A,B}and{A,C}
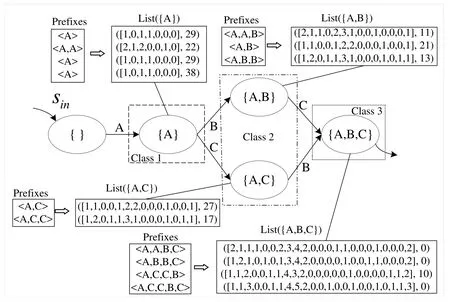
Figure 3.An extended transition system with states partitioning.

4.2.5 Long Short-Term Memory Model
Before introducing LSTM,a recurrent neural network is introduced.Recurrent neural network[27](RNN)is a type of deep neural network model used for sequence processing.Its characteristic is that the output of each neuron at time t will be part of the input at time(t+1),which can realize the modeling of variable-length sequence.The function of the neuron in RNN is to receive the current time information xtin the sequence represented by the vector and the output ht-1at the previous time as an input,and perform nonlinearity on it to obtain the output htat the current time.
LSTM[28]is a special recurrent neural network architecture that has powerful modeling capabilities for long-term dependencies.Compared with regular recurrent neural networks,LSTM has more complex neurons st,which replace the original state s′.The formulas for LSTM neurons are:
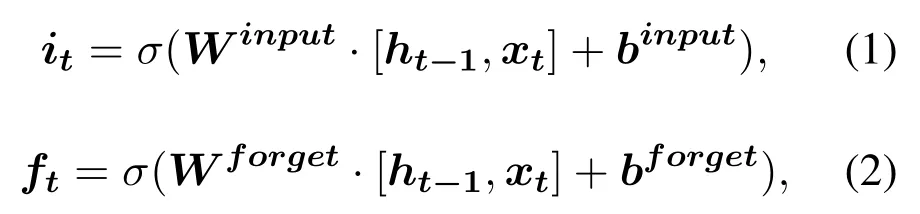
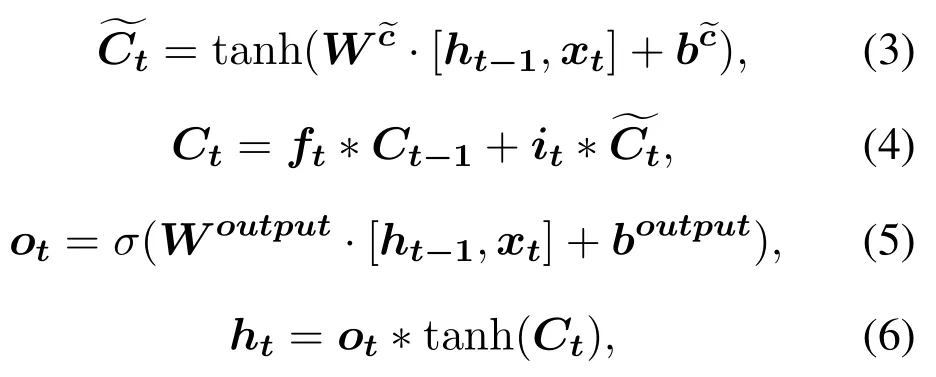
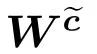
4.2.6 Algorithm for Predicting Remaining Time of Running Traces
Remaining time prediction of running traces is described in Algorithm 4.First,for the running trace,line 1 associates the trace to a different non-empty state of the extended transition system.Line 2 calculates the length of state.Then,lines 3 to 8 query the corresponding partition in the partitioning list returned by Algorithm 3,and train the LSTM model for each partition,respectively.Finally,the weighted average of the estimations with the prediction models is obtained in line 9,and the RTP is returned in line 10.
V.EVALUATION
In this section,the proposed method for predicting the remaining time of the business processes is evaluated by both synthetic and real-life event logs.First,the basic statistical information of the event logs used in the experiment and the experimental setup are introduced.Then,the proposed prediction method is compared with the LSTM prediction method[16]and the deep transfer learning method[17].Finally,the proposed business process remaining time prediction method is analyzed in detail.
5.1 Event Logs
The experiments in this paper used five public event logs,namely Loan_application_C1(a),Loan_applicati on_C2(b),Loan_application_C3(c),Loan_application_C4(d),Helpdesk(A)and Road_Traffic_Fine_Manage ment(B).They can be downloaded at https://data.4tu.nl/repository/collection:all.
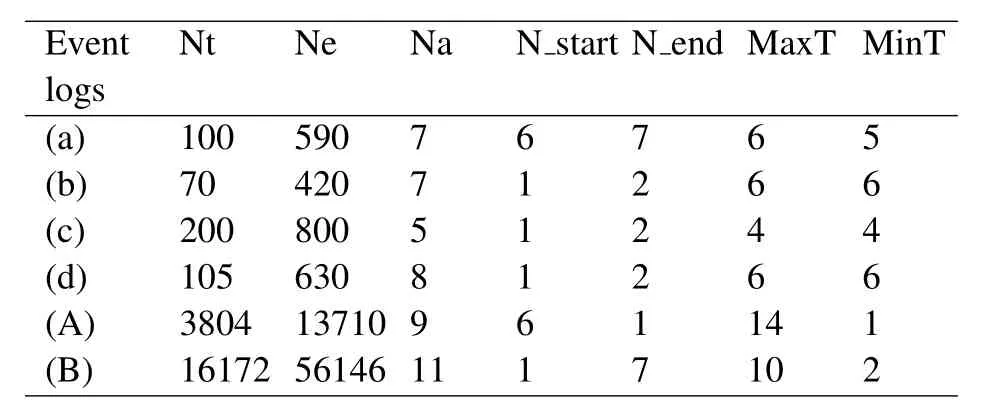
Table 4.Basic statistics of the event logs.
The event logs(a),(b),(c)and(d)are synthetic event logs.A collection of synthetic event logs describing 4 variants of a simple loan application process.(a)is the most complex process with parallelism and choices.The other 3 synthetic event logs have a simpler and more sequential process.(A)is a real-life event log that contains events from a ticketing management process of the help desk of an Italian software company.(B)is a real-life event log of an information system managing road traffic fines.
The infrequent behaviors(for example,incomplete traces)or noises(for example,outliers)in event logs are filtered,which can improve the accuracy of the remaining time prediction.The statistical information of the event log after preprocessing is shown in Table 4,where start.acti and end.acti represent start activities and end activities,respectively.Note that Nt represents number of traces,Ne represents number of events,Na represents number of activities,N_start represents number of start.acti,N_end represents number of end.acti,and MaxT represents maximum length of traces,and MinT represents minimum of traces.Furthermore,the statistics can reflect the framework of the business process to a certain extent.For example,the loop structures of the structure information in the trace of the event log(A)are reflected.
5.2 Experimental Setup
To assess the accuracy of the proposed method,wellknown error metrics are mean absolute error(MAE)and root mean squared error(RMSE).MAE is the measurement distance of the difference between the real value and the predicted value.The calculation for-mula is:

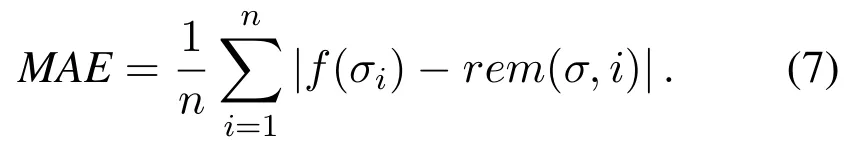
RMSE is also a measure of the distance between the true value and the predicted value,which can be sensitive to outliers.The calculation formula is:
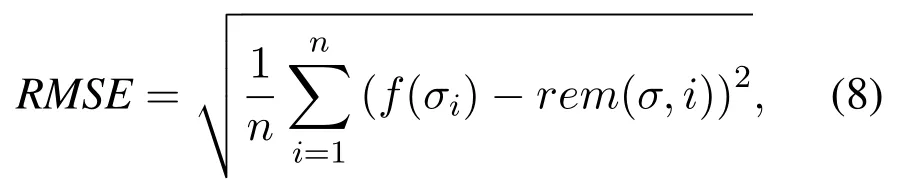
where n is the size of predicted samples,f(σi)is the predicted remain time value in the running trace σi,and rem(σ,i)is the actual value of the time in the trace.Moreover,the lower the MAE and MSE values,the higher the accuracy of remain time prediction for business processes.
5.3 Results
The methods based on LSTM[16]and deep transfer learning[17]are used as the baseline methods.Because it has been confirmed that the methods based on LSTM deep neural network and deep transfer learning are superior to remaining time prediction methods based on transition systems[7],stochastic Petri nets[8]and other traditional machine learning methods in many studies on the remaining time prediction of business processes.
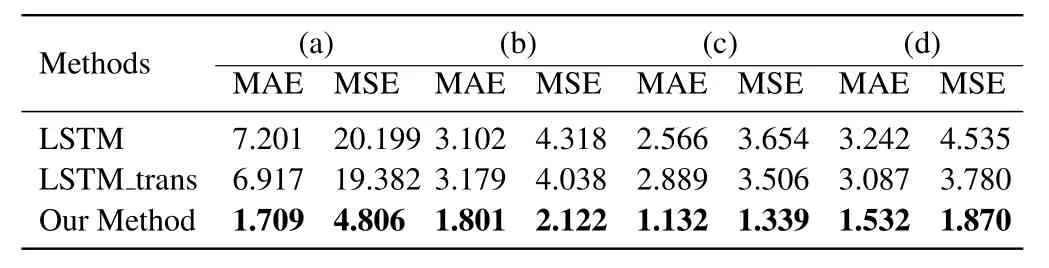
Table 5.MAE and RMSE values(in minutes)of experimental results for the synthetic event logs.
The proposed method and the baseline methods are implemented using PyTorch 1.3.1.In this section,the experimental results on the synthetic event logs and the real-life event logs are analyzed,respectively.
5.3.1 Results on Synthetic Event Logs
The process models discovered based on the synthetic event logs for(a),(b),(c)and(d)are shown in Figure 4(from top to bottom).It can be found that the business process of(a)with parallelism(concurrency)and choices,however,the business process of(b),the business process of(c)and the business process of(d)without parallelism(concurrency).
The MAE and RMSE values on the synthetic event logs of methods are shown in Table 5.The experimental results show that our proposed method is superior to the method based on LSTM deep neural network and the method using deep transfer learning for all the synthetic event logs.Further,the evaluation results of the event log(a)is the most obvious.The results show that the proposed method has a significant advantage in predicting the remaining time of business processes with concurrent behavior.
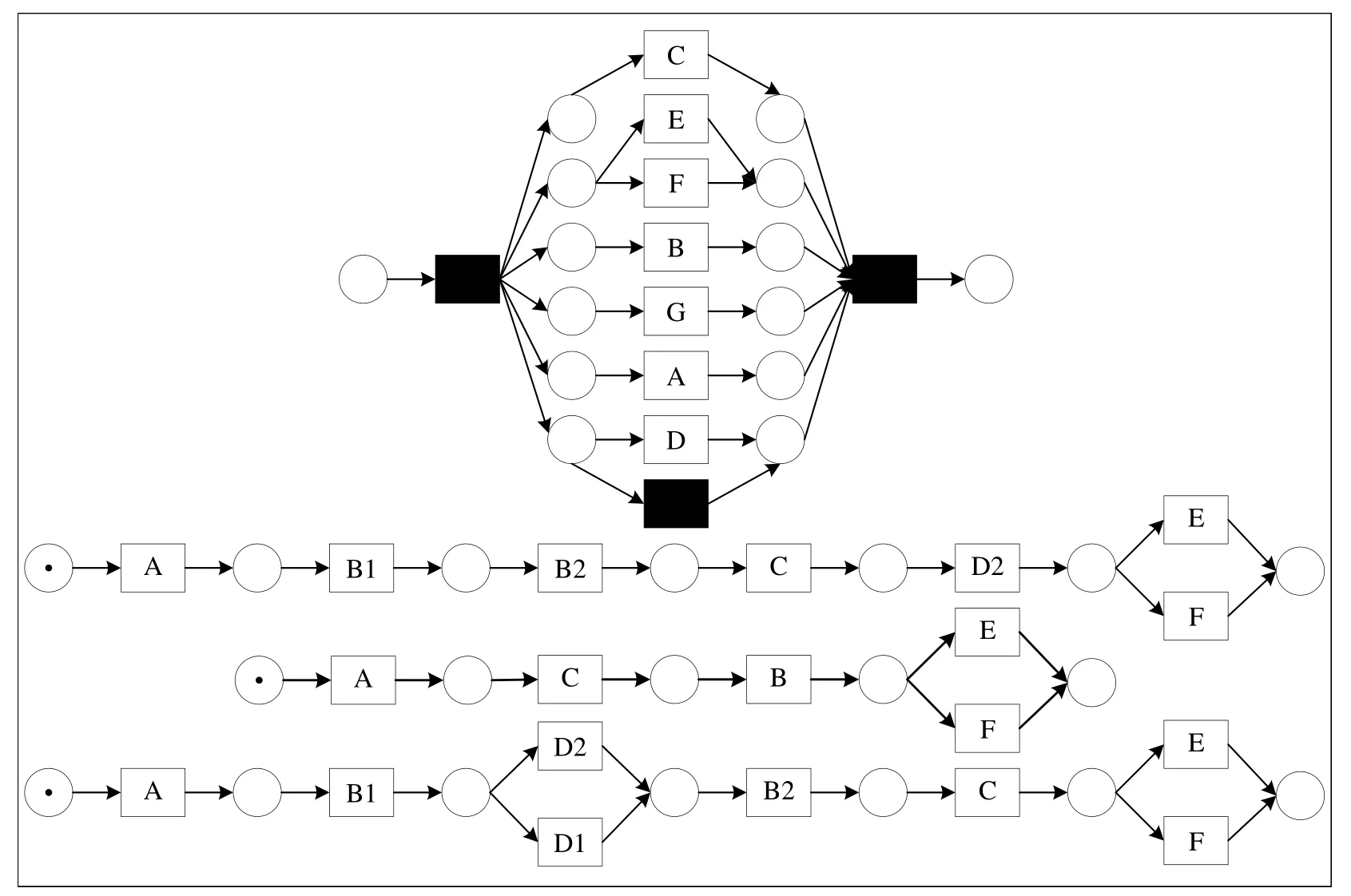
Figure 4.Business processes for the synthetic event logs.
There are three main reasons.The first reason is that the data structure of synthetic event logs has the characteristics of relatively stable and low noise.Secondly,the proposed method efficiently encodes the structural information within the traces.Thirdly,the LSTM deep neural network targeted training for the partition of states in the extended transition system based on the abstract representation can effectively handle the concurrent behavior of multiple process instances.However,for business processes of(a),(b),(c)and(d)with sequences and choices,effective encoding of trace structure information is an important factor to improve the accuracy of the remaining time prediction for process instances.
The MAE and RMSE values at different lengths of the states in the extended transition system are shown in Figure 5.For each synthetic event logs,the MAE and RMSE values to decrease when increasing the length of the states(also called the number of different activities).The main reasons for this phenomenon are that as the process instance runs,the number of different activities may increase,the prefix length of the traces also becomes larger,and the uncertainty of the remaining time prediction is decreasing.However,its prediction accuracy is constantly increasing.
5.3.2 Results on Real-life Event Logs
To better analyze the experimental results,statistical analysis of the real-life event logs is first performed.In Figure 6,the curve of states should be very close to the curve of the prefix within a certain length.As the length of states and prefixes increase,the number of states and prefixes is decreasing.However,in the upper right corner of(A),the number of running instances(prefixes)of state is slightly greater than the number of its prefixes for the different lengths in the event log,which reflects that the event log contains concurrent behavior.For(B),the curve representing the number of states perfectly coincides with the curve representing the number of prefixes,which shows that the event log contains almost no concurrent behavior.
Table 6 presents the MAE and RMSE values of experimental results for the two real-life event logs.It can be found that the proposed method outperforms the methods based on LSTM deep neural network and deep transfer learning.The experimental results confirm that encoding of structural information in traces and the partition of states in the extended transition system using the set abstraction effectively improve the accuracy of the remaining time prediction in business processes.
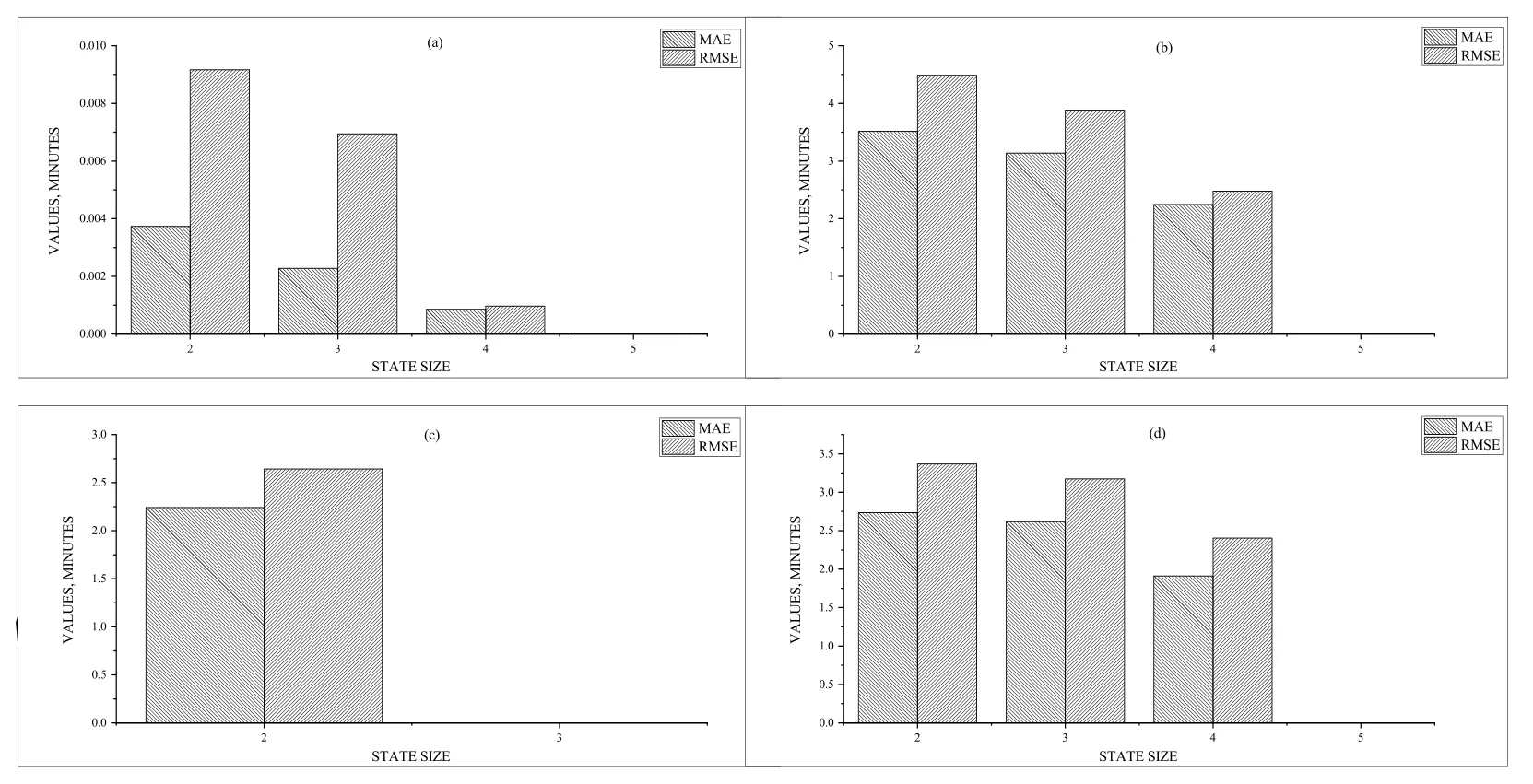
Figure 5.MAE and RMSE values using states of different lengths for(a),(b),(c)and(d).

Figure 6.Number of traces,prefixes and running instances of state in different lengths for(A)and(B).
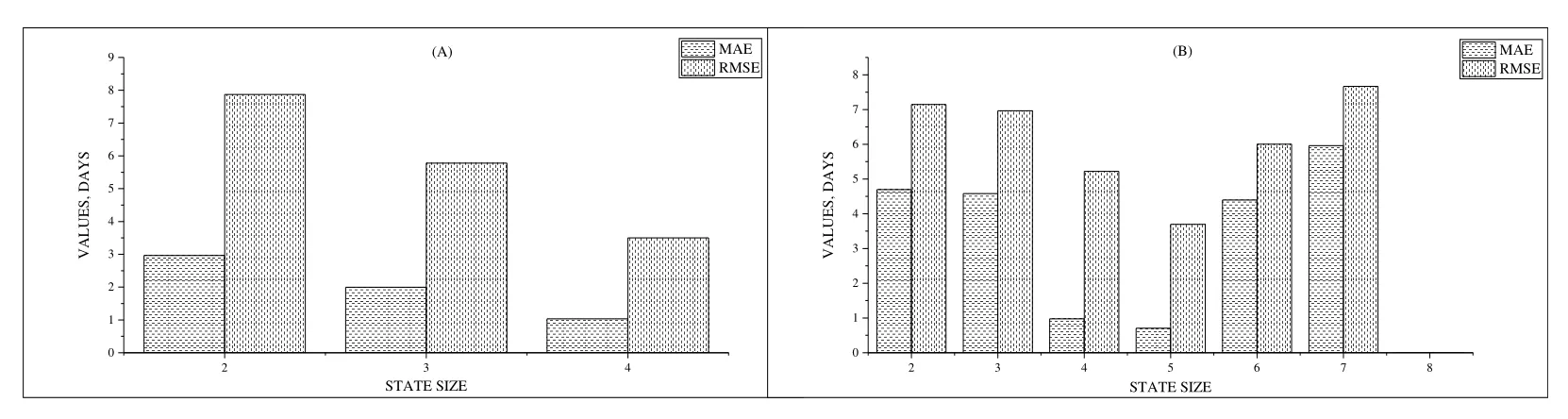
Figure 7.MAE and RMSE values using states of different lengths for(A)and(B).
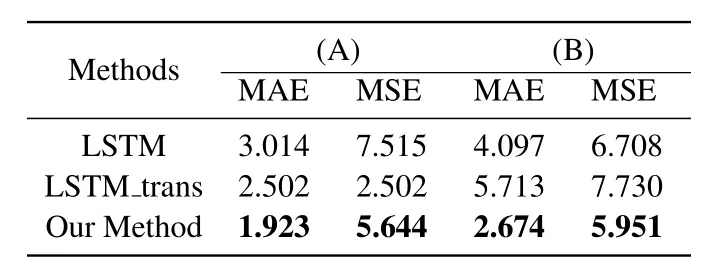
Table 6.MAE and RMSE values of experimental results for the real-life event logs(A)(in day)and(B)(in month).
The MAE and RMSE values using states of different lengths for(A)and(B)in Figure 7.First,there is no training prediction model for a state of zero length,because no non-empty trace can be mapped to an empty state.Then,there is no training prediction model for the state of length 1,because the trace has just started,which is full of too much uncertainty.Finally,the remaining time prediction model is not trained for running traces with a large state length as the number of running traces in a state with a large length is quite small.
In addition,as the length of the state increases,the MAE and RMSE values are decreasing while the accuracy of the remaining time prediction is continuously improving in(A).However,in(B),the values in states with lengths 4 and 5 are smaller than those in states with other lengths,which is caused by the uneven distribution of event logs.This phenomenon is firstly caused by the uneven distribution of the event log,and secondly,the event log contains the short traces,these short traces belong to smaller partitions divided by the length of the state,and it is easy to accurately predict the remaining time.These short traces are not in the later prediction points,as they have already finished by that time.Therefore,for the longer traces only in larger partitions by the length of the state,which appear to be more challenging for the business process remaining time prediction,hence increasing the MAE and RMSE values on larger partitions.
VI.CONCLUSION
In this paper,a new method for predicting the remaining time of business processes is proposed.First,the prefix traces generated by the event log is partitioned and features are encoded,and the extended transition system is obtained.Then,the remaining time prediction models are constructed according to the length of the state in the extended transition system,which makes it possible to consider the concurrent behavior among multiple traces.Finally,a group of experiments are conducted on the synthetic event logs and the reallife event logs,and the results illustrate that the proposed method can significantly improve the prediction accuracy of business process remaining time.
In future,the proposed method can be extended to other prediction tasks,such as the next activity execution of running traces or outcome prediction.For example,we can extend attribute coding as well as other partitioning to predict the execution of the next activity or outcome.Moreover,the proposed prediction method can not only be applied to the field of predictive business process monitoring,but can also be extended to other research fields,such as mobile edge computing[29–31].
ACKNOWLEDGEMENT
This work was supported by National Natural Science Foundation of China(No.U1931207 and No.61702306),Sci. & Tech.Development Fund of Shandong Province of China(No.ZR2019LZH001,No.ZR2017BF015 and No.ZR2017MF027),the Humanities and Social Science Research Project of the Ministry of Education(No.18YJAZH017),Shandong Chongqing Science and technology cooperation project(No.cstc2020jscx-lyjsAX0008),Sci. & Tech.Development Fund of Qingdao(No.21-1-5-zlyj-1-zc),the Taishan Scholar Program of Shandong Province,and SDUST Research Fund(No.2015TDJH102 and No.2019KJN024).

- China Communications的其它文章
- A Key Management Scheme Using(p,q)-Lucas Polynomials in Wireless Sensor Network
- Pilot Allocation Optimization Using Enhanced Salp Swarm Algorithm for Sparse Channel Estimation
- Put Others Before Itself:A Multi-Leader One-Follower Anti-Jamming Stackelberg Game Against Tracking Jammer
- DCGAN Based Spectrum Sensing Data Enhancement for Behavior Recognition in Self-Organized Communication Network
- On Treatment Patterns for Modeling Medical Treatment Processes in Clinical Practice Guidelines
- Hybrid Recommendation Based on Graph Embedding