
英语低元音与鼻音组构借入普通话的借词音系分析
2021-11-28 13:08王巍
现代语文 2021年8期
王巍

摘 要:主要对英语低元音与鼻音组构借入普通话的匹配情况进行探讨,研究发现:1.源词和借词倾向于保持元音音段的相似性,这是因为元音在语音听感上的显著性要高于鼻音;2.借入语固有的音系规则会影响到借词音系改造的结果,普通话具有韵母和谐的特征,即低元音部位同化,要求前低元音[a]与前鼻音[n]组构,后低元音[ɑ]和后鼻音[?]组构,从而直接排除了不合法的借词表层形式;3.源语、中介语和拼写形式等语法外因素,也会影响借词音系分析的结果。从整体上看,英语低元音与鼻音组构借入普通话的匹配模式符合最佳配对的借词音系分析模型。
关键词:低元音与鼻音组构;借词音系;听感相似性;固有音系规则;最佳配对
一、研究背景
目前,关于借词音系分析的理论模型主要有三种[1]、[2]。一是音系對应,认为借词改造(adaptation)的过程源于双语者在抽象的音系层面实现不同音段层级的对等,当音系层的对等难以完全实现时,在具体音位的对应上可以选取源语(source language,简称“SL”)和借入语(borrowing language,简称“BL”)中彼此距离最近——即最无区别性特征的一组音位相互对应[3]。二是语音对应,认为借词改造在很大程度上是源于单语者或双语者、多语者在L1和L2语音听觉感知上的趋同(perceptual assimilation),其改造过程实际上是语音解码(phonetic decoding)的过程,即BL中的借词在SL中寻找与之最为相似的语音信号,由音系表层的对应延伸至语音表层的对应[4]。三是基于音系与语音动因互动的“最佳配对”,认为纯音系语法和语音感知都难以作出跨语言的形式化解释,二者可以共谐于优选论(Optimality Theory,简称“OT”)的制约框架之中,将各种规则和限制转为针对输入—输出与输出项本身的两类制约条件,并行推导,而借词改造的最终形式是各种制约互动的结果[5]、[6]。
我们以英语低元音与鼻音组构借入普通话为例,探讨借词改造过程中音系和语音动因的互动关系。英语低元音与鼻音组构共有六个发音形式,借入普通话后,有两种可能的匹配情况,分别是音系匹配和语音匹配。具体如图1所示:
所谓“音系匹配”,是指韵尾鼻音的发音位置相近或相同,这是因为普通话低元音的前/后特征([+/-BACK])是一对非区别性特征,[a]和[ɑ]是/A/在不同语音环境中的音位变体,如图(1a)所示,输入与输出的语音序列(phonetic sequences)在鼻音发音位置上保持一致[7](P79-82)、[8]。所谓“语音匹配”,是指元音在语音听感上相似或相同,因为元音的响度远高于鼻音,并且普通话鼻音通常被认为是“半鼻音”,即使在单独发音时也常有脱落的情况,所以元音相同或相近意味着输入与输出的语音序列在语音听感上保持相似[9]、[10],如图(1b)所示。
问题是:现有的借词语料是支持音系对应、语音对应还是最佳配对?如何解释不同借入模式的成因?下面,我们将首先描述英语低元音与鼻音组构借入普通话的匹配情况,分析借入模式。接着,在OT的框架内,对借入模式的成因作出形式化的解释。最后,对上述研究发现进行总结。
二、英语低元音与鼻音组构借入普通话的匹配情况
这里,主要是对三对英语低元音和鼻音序列([?n]和[ɑ?]、[ɑn]和[??]、[?m]和[ɑm])借入普通话之后的匹配情况进行分析。
(一)英语[?n]和[ɑ?]借入普通话
本文共收录英语[?n]和[ɑ?]借入普通话的借词40例,其中,[?n]E"[an]M对应30例①,[?n]E"[ɑ?]M对应5例,[ɑ?]E"[an]M对应1例,[ɑ?]E"[ɑ?]M对应4例。具体如表1、表2所示:
我们又在表1、表2的基础上制作成列联表,具体如表3所示:
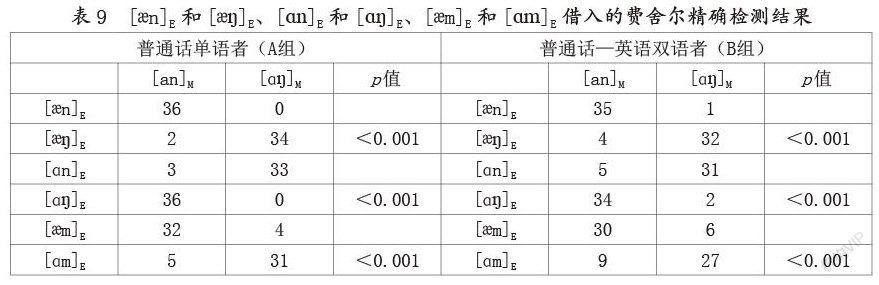
这里主要是通过费舍尔精确检验,来判断英语[?n]和[ɑ?]音段借入普通话时的主要对应音段,亦即列联表中的两列数字是否存在显著差异。结果表明,设定p值小于0.05的置信区间,差异显著。由此可以推测,普通话语者倾向于将英语中的[?n]音段改造为[an];同时,由于[ɑ?]是普通话中的固有音段,所以英语中的[ɑ?]音段在借入过程中很大程度上得以保留。
(二)英语[ɑn]和[??]借入普通话
本文共收录英语[ɑn]和[??]借入普通话的借词38例,其中,[ɑn]E"[V?]M对应18例,[ɑn]E"[an]M对应3例,[??]E"[an]M对应12例,[??]E"[ɑ?]M对应5例。具体如表4、表5所示:
我们又在表4、表5的基础上制作成列联表,具体如表6所示:
这里主要是通过费舍尔精确检验,来判断英语[ɑn]和[??]借入普通话时的主要对应音段。结果表明,在p值小于0.05的置信区间里差异显著。由此可以推测,普通话语者倾向于将英语中的[ɑn]音段改造为[V?],并且[V?]音段韵核元音[ɑ]、[u]和[?]的舌位都靠后;同时,英语[??]一般匹配普通话的[an]。
(三)英语[?m]和[ɑm]借入普通话
本文共收录英语[?m]和[ɑm]借入普通话的借词21例,其中,[?m]E"[an]M对应13例,[?m]E"[ɑ?]M对应2例,[ɑm]E"[an]M对应1例,[ɑm]E"[ɑ?]M对应5例。具体如表7、表8所示:
我们通过费舍尔精确检验,来判断英语[?m]和[ɑm]借入普通话时的主要对应音段。结果表明,在p值小于0.05的置信区间里,存在显著差异。由此可以推测,英语[?m]E借入普通话时倾向于匹配[an]M;而[ɑm]E借入普通话时,大多与[ɑ?]M匹配。
三、讨论分析
基于上文的借词语料,可以看出,英语[?n]和[?m]在借入普通话时,倾向于与[an]匹配;英语[ɑ?]在借入普通话时,则大多与[ɑ?]匹配,上述匹配情况既体现了音系对应,又体现了语音对应。因此,难以据此判断借入者对音系对应或语音对应模式的偏好。相比较而言,英语[ɑn]和[ɑm]借入时,一般与普通话的[ɑ?]匹配;而英语[??]借入时,大多匹配普通话的[an],上述匹配情况则反映出语音对应的借入模式。总的来看,英语低元音与鼻音组构借入普通话时是遵循了语音匹配的。下文将进一步解释借入模式背后的语音动因、音系和语音动因的互动,以及可能的语法外因素,是如何影响借词语音改造的结果的。
(一)语音动因
Chen曾对普通话中带鼻韵尾的音节进行了详细的分析,作者发现,其中
由于普通话中的低元音不区分前后,此时[+后]/[-后]就成为一对非区别性特征。而鼻音区分发音部位的前后,如发音位置靠前的双唇鼻音[m]和舌尖鼻音[n]为前鼻音,发音位置靠后的舌根鼻音[?]为后鼻音。研究结果表明,在低元音与鼻音组构的实际发音过程中,由于发音协同效应,鼻音发音部位的前后会影响前面低元音的舌位前后,这是因为普通话音段组构中音节韵腹—韵尾要求和谐,所以此处的低元音发生了后部性同化。Chen认为,这种同化仅仅发生在普通话的音节内部,无法跨越音节边界,而且英语中不存在类似的部位同化[11]。[后]对于/a/音是非区别性特征,但是它却包含着两个鼻韵尾发音部位对立的信息,起到了对整个音系对立的加强作用。在一定的语音条件下,如果鼻音的部位特征被删除,那么低元音的后部性特征可以在听觉上“恢复”失去的对立性,从而避免对立中和(neutralization)的发生,普通话鼻韵尾脱落(deletion)就是一个合适的例证[9]、[10]。Chen选取了四个带鼻韵尾的两字词,分别是
图4中,实线表示正确的判断,虚线表示错误的判断。从图4可以看出,在鼻音与元音临界点之前,也就是音节刚开始时,普通话母语者仅凭鼻化和元音共振峰的变化就可以确定鼻韵尾的部位,而不需要鼻音阻塞段的信息。同时,实线始终在虚线之上,这说明正确判断一直超过错误判断。也就是说,普通话语者对鼻音韵尾的分辨不是随机的,而是有规律的,听感上相对显著的元音是他们判断的主要依据。
由此,我们产生这样一个设想,普通话语者在英语/CVN/序列的听辨中,仍然会采用相同的判断策略,即先入为主地凭借鼻音前边的元音判定整个音节的韵尾鼻音。为了验证这一假设,我们设计了一个单音节鼻音韵尾的判定实验。由一位男性英语母语者(偏美式发音)录制音频,选取[ph]、[p]、[th]、[t]、[kh]和[k]作为音节首音,并与[?n]、[??]、[ɑn]、[ɑ?]、[?m]和[ɑm]分别组构,得到共计36个语音刺激作为实验材料。有6名只讲普通话的单语者与6名通晓英语和普通话的双语者参与本次实验,分别归入A组和B组。受试会随机依次听到36个语音刺激,需要立即判断听到的字音是以
研究结果表明,无论是普通话单语者,还是普通话—英语双语者,都可以明确地判断[an]M与[ɑ?]M韵尾。在这一基础上,分别对两组受试[an]M与[ɑ?]M韵尾的判定结果进行独立样本t检验,结果如下:[tA(5)=0.646,p<0.01],[tB(5)=0.646,p<0.01]。这说明两组受试在[an]M与[ɑ?]M韵尾的判断上也不存在显著差异。
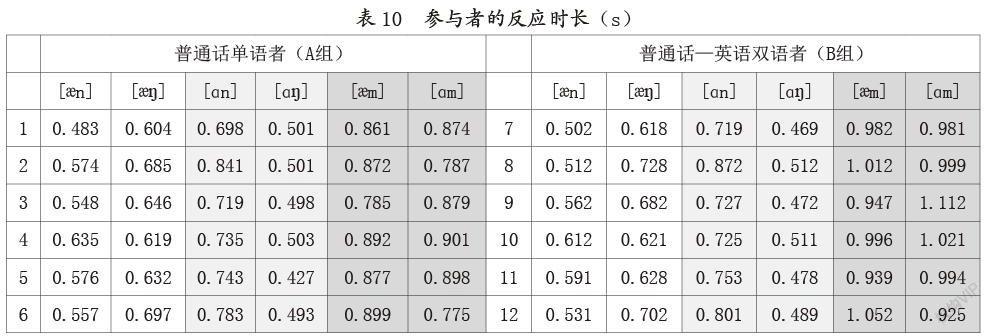
二是统计受试在进行韵尾判定时的反应时长(rt/s)。每名受试会听到以[?n]、[??]、[ɑn]、[ɑ?]、[?m]和[ɑm]结尾的语音刺激各6个,这里计算反应时长的均值,例如,第1名受试会听到6个以[?n]结尾的语音刺激,计算出其均值为0.483s,以此类推。实验结果如表10所示;我们还在这一基础上,绘制出更为直观的箱图,具体如图5所示:
研究结果表明,单语者与双语者在[?n]和[??]、[ɑn]和[ɑ?]韵尾判定的反应时长上,并不存在显著差异。值得注意的是,单语者在[?m]和[ɑm]韵尾判定的反应时长略低于双语者,结果如下:[t[?m](5)=0.000,p<0.05],[t[ɑm](5)=0.001,p<0.05]。
综上所述,单音节鼻韵尾的判定结果支持了我们的假设,即普通话语者会先入为主地依据英语中鼻音前边的低元音来预测和判定韵尾形式。在这个过程中,低元音的后部性同化发挥了关键作用,尽管英语中并不存在这一现象,但它仍然会影响到普通话语者的听感。不仅单语者会遵循上述规律进行韵尾判定,双语者也会依据韵母和谐规律对此进行判定,它们的主要区别是在于,双语者在英汉有差异的韵尾判定中耗时稍长,尤其是在[?m]E和[ɑm]E韵尾的判定上。
在上述分析的基础上,为了更加直观地解释为什么[??]E和[an]M、[ɑn]E和[ɑ?]M、[?m]E和[an]M、[ɑm]E和[ɑ?]M在听感上比较相似,我们分别提取了[an]M、[ɑ?]M、[??]E、[ɑn]E、[?m]E和[ɑm]E的频谱图。其中,[an]M和[ɑ?]M的发音人是标准普通话母语者,而[??]E、[ɑn]E、[?m]E和[ɑm]E是一位偏美式英语的母语者;同时,用白虚线标注F1和F2。具体如图6所示:
通过对6种不同韵尾频谱图的比较,可以发现,[an]M、[??]E和[?m]E在元音段的F1和F2比较接近,更为关键的是元音段的发音时长较为短促,约持续0.05秒左右。同时,[ɑ?]M、[ɑn]E和[ɑm]E的第一和第二共振峰趋同,并且元音稳定段的时长超过0.1秒。除此之外,我们还发现,所有鼻音[m]、[n]和[?]的主要声学特征(acoustic features),即第一共振峰频率F1均稳定在250—300HZ,而鼻音共振峰衰减较快,因此,第二共振峰F2较弱。鼻音的另外一项声学特征,即反共振峰(nasal zero)频率虽然存在明显差异,但由于整体上鼻音的能量值(dB)较弱,音强(intensity)随之减弱,于是在有干扰的情况下,各种鼻音之间的误听率很大。鼻音是不同语言中最无标记性的,在语言接触中,鼻音的转化和变异是比较容易的[11]、[14](P272-276)。总的来看,听感相对显著的元音与听感稍弱的鼻音组构,加之韵母后部性同化的影响,使得普通话语者认为[an]M、[??]E和[?m]E听起来比较近似,[ɑ?]M、[ɑn]E和[ɑm]E听起来比较近似。
(二)音系和语音动因的互动
这里主要是在优选论的框架内对英语低元音和鼻音组構借入普通话进行解释,分析音系的制约条件,尤其是借入语固有的音位组合限制(phonotactics)如何与语音制约互动,从而影响借词改造的结果。
从整体上看,[?n]E"[an]M和[ɑ?]E"[ɑ?]M基本保持了输入到输出音段的忠实性映射,而[??]E"[an]M、[ɑn]E"[ɑ?]M、[?m]E"[an]M和[ɑm]E"[ɑ?]M,从输入音段到输出音段则发生了一定变化。由于输出项在表层形式上发生了变化,那么,可以推断触发变化的标记性制约条件需要先于忠实性制约条件,因为一条忠实性制约条件本身无法促成对另一忠实性条件的违反,所以整体上制约条件的等级排序应该是标记性制约条件先于忠实性制约条件[15](P62-65)。基于输入项和优选项,我们提出如下制约条件:
AGREE[BACK]:范域内的音段应具有相同的后部性特征值标记;
OK-σ HIGH:改造后的音段需要符合借入语的音位组合限制;
IDENT[BACK]:输入与输出项的元音舌位前后要保持一致;
IDENT[CODA]:输入与输出项的鼻韵尾要保持一致。
上述制约条件中,“AGREE[BACK]”的适用性是在于,在普通话带有鼻韵尾的音节中,齿龈鼻音[n]具备前部性特征,在发音部位上要求舌尖或舌面附着在或尽量靠近前齿;而软腭鼻音[?]具备后部性特征,在发音部位上要求舌根部位抵住软腭。同时,鼻音前元音的舌位前后也是一对区别性特征,前元音舌位靠前,后元音舌位靠后。就此而言,前元音接具备前部性特征的齿龈鼻音最为容易实现;同理,后元音接具备后部性特征的软腭鼻音也最为容易实现,这样才符合发音省力的原则。类似的发音位置和谐还包括普通话中高元音与中元音的组构,即普通话里前高元音/i/和/y/只与前中元音/e/组构,后高元音/u/只与后中元音/o/组构。以上是普通话中韵母的后部性和谐[7](P79-82)、[16](P12-24)、[17]。作为触发音变的标记性制约条件,“AGREE[BACK]”在评估器中的等级排序应排在首位。接下来,在忠实性制约条件的排序中,输出候选项的音段需要严格遵循普通话的音位组合限制,对于该项制约条件的违反将直接导致该候选项成为败选项,所以其排序需要靠前。以上两项是针对输出项的制约条件(input-output constraint)。
由于借入过程遵循语音对应,那么元音输入与输出过程中的忠实性要高于鼻音。综上,制约条件的排序应为:AGREE[BACK]>>OK-σ HIGH>>IDENT-[BACK]>>IDENT-[CODA]。具体如表11、表12所示:
表11中有两个优选输出项,分别是[an]M和[?n]M,它们的元音同属于普通话低元音/A/在不同语音环境下的音位变体。其中,前低元音[a]通常与舌尖鼻音[n]组构,而[?]的分布环境是在前高元音[i]或半元音(无擦通音)[j]与舌尖鼻音中间,即[i?n]或[j?n]。我们的借词语料中没有收集到[??]M"[?n]E的实例,但不能因此而排除/??/改造成/?n/的可能性。按照相同的制约等级排序,输入项[ɑn]E的优选项是[ɑ?]M,如表12所示:
表11中的输入项[?m]E有两个优选输出项[an]M和[?n]M,其中,[?m]E"[?n]M在表13中没有实际的例子对应,但如果普通话英源借词中存在前高元音[y]与[?n]组构的情况,并且此时[?n]是由[?m]改造而来的,那么,[?n]M就是[?m]E借入后的优选输出项。表14中输入项[ɑm]E对应的优选输出项为[ɑ?]M,韵尾鼻音在输入与输出时的忠实性要低于元音。
综上所述,英语低元音与鼻音组构借入普通话时,基本上是遵循着语音对应的,同时,音系制约(如借入的音位组合限制)也发挥着关键作用,它不仅在借入的过程中促成音变,更直接决定合法借词的表层形式。就此来说,最佳配对模型对英语低元音与鼻音组构借入普通话更具有解释力。
(三)语法外因素
除了上述原因之外,语法外因素也在一定程度上影响到借词改造的结果,比如源语类别、拼写形式、中介语等[1]、[2]。因此,借词形式不遵循最佳配对的情况也时有发生。
首先是源语类别和拼写形式对借词借入的影响。虽然英式英语和美式英语在低元音的分布上存在着一定差异,不过,它们在与鼻音组构借入普通话时,有些借词的拼写形式却保持一致。具体如表15所示(见下页):
从表15可以看出,英式英语采用后低元音配长音与前/后鼻音构成[ɑ:n]或[ɑ:?],美式则采用前低元音配短音与前/后鼻音构成[?n]或[??]。同时,二者在圆唇特征上也具有一定差别,英式英语往往采用不圆唇的后低元音配短音与前鼻音组构为[?n],而美式英语往往采用圆唇的后低元音配长音与前鼻音组构为[ɑn][18](P67)。从我们收集到的借词语料来看,尽管发音舌位前/后和长/短存在系统的差异,但英式表15 英式、美式英语元音和鼻音组构的借词
英语的[ɑ:n]和美式英语的[?n]在实际借入时,一律与普通话音节中的[an]相匹配。根据先前的分析,英式英语的[ɑ:n]按照最佳配对的预测,应该匹配普通話中的[ɑ?]。这里有两种可能的解释:一是美式英语应该是借入的源语,不过,这一点很难考证;二是拼写形式的影响,当英语单词中某些发音形式所对应的书写形式与汉语拼音相同时,语者往往会直接借用[19]、[20]。比如,Pakistan中的
其次是中介语(interlanguage,简称“IL”)对借词借入的影响。由于历史原因,有些英源音译词先是借入粤语和吴语等方言区,然后再借入普通话,这类借词在方言中所对应的发音形式与英语更为接近。因为不同方言区使用相同的汉字书写形式,所以普通话往往会直接借用经过方言初次改造后的借词文字,普通话与上述方言音系则存在差异,这就使得这类音译借词在普通话中的字面读音与英语源词相去甚远。我们找到四个从粤语和上海话中借入,并且涉及低元音与鼻音组构的音译词,具体如表16和表17所示:
在表16中,“新地”里的英语发音[s?n]与粤语[s?n]接近,但英语[s?n]与普通话[?in]的差异较大,这是因为鼻音韵尾和元音的舌位高/低特征已经发生了变化。很明显,“新地”的粤语发音与英语接近,而普通话有可能是直接借用了“新地”的汉字形式。“沙朗”中的英语发音[l??n]与粤语[lo?]相似,而普通话中“朗”的读音是/lɑ?/,它的韵核元音为低元音,与英语[l??n]的发音差别较大。Macdonald中的第二个音节[d?n]的发音与粤语中对应的[to?]最为接近,元音舌位保持在中间位置;而普通话对应的是[tɑ?]音,它的韵核元音为低元音,与英语[d?n]的发音形式有显著差异。champagne中的[??m]音与上海话的[?ian]音在韵腹[?]—[a]和韵尾[m]—[n]部分的对应更为接近,而普通话[?iɑ?]的韵腹元音[ɑ]和韵尾鼻音[?]在发音位置上都比较靠后。
本文的研究表明,英语低元音与鼻音组构借入普通话的匹配模式体现了音系和语音制约的互动,源词与借词既需要保持语音听感上的相似性,也必须符合借入语的音位组合限制。与此同时,借词音系分析还需要预先摒除语法外因素(如源语、中介语和拼写形式)的干扰,它们在某种程度上也会影响到借词音系改造的结果。上述研究结论支持了借词音系分析的最佳配对模型。具体来讲,英语低元音与鼻音组构借入普通话时,先是遵循了语音对应——即元音对应,同时,普通话低元音和鼻音的组构存在部位同化,要求前低元音[a]与前鼻音[n]组构,后低元音[ɑ]和后鼻音[?]组构,也就是说,普通话固有的音位组合限制又直接限定了合法借词的表层形式。
参考文献:
[1]Kang,Y.Loanword phonology[A].In Van Oostendorp,M.,Ewen,C.,Hume,E. & Rice,K.(eds.). The Blackwell Companion to Phonology[C].Malden,MA:Wiley-Blackwel,2011.
[2]谢丰帆.借词音系学与汉语借词研究[J].当代语言学, 2014,(3).
[3]LaCharite?,D. & Paradis,C.Category preservation and proximity versus phonetic approximation in loanword adaptation[J].Linguistic Inquiry,2005,(4).
[4]Peperkamp,S.,Vendelin,I. & Nakamura,K.On the perceptual origin of loanword adaptations:experimental evidence from Japanese[J].Phonology,2008,(25).
[5]Yip,M.The symbiosis between perception and grammar in loanword phonology[J].Lingua,2006,(116).
[6]Kenstowicz,M.Salience and similarity in loanword adaptation:A case study from Fijian[J].Language Sciences,2007,(1).
[7]Duanmu,S.The phonology of standard Chinese(Second Edition)[M].Oxford:Oxford University Press,2007.
[8]Hsieh,F.F.,Kenstowicz,M. & Mou,X.Mandarin adaptations of coda nasals in English loanwords[A].In Calabrese,A. & Wetzels,W.L.(eds.).Loan phonology[C].Netherland:John Benjamins Publishing Company,2009.
[9]李智強.区别性特征理论的语音学基础[A].中国语言学会语音学分会.中国语音学报(第四辑)[C].北京:中国社会科学出版社,2013.
[10]李智强.音系对立与非区别性特[A].中国语言学会语音学分会.中国语音学报(第三辑)[C].北京:商务印书馆,2012.
[11]Chen,M.Y.Acoustic analysis of simple vowels preceding a nasal in Standard Chinese[J].Journal of Phonetics,2000,(28).
[12]王志洁.英汉音节鼻韵尾的不同性质[J].现代外语, 1997,(4).
[13]Keyser,S.J. & Stevens,K.N.Enhancement and overlap in the speech chain[J].Language,2006,(1).
[14]朱晓农.语音学[M].北京:商务印书馆,2010.
[15]马秋武.优选论[M].上海:上海教育出版社,2010.
[16]Cheng,C.C.A Synchronic Phonology of Mandarin Chinese[M].The Hague:Mouton de Gruyter,1973.
[17]Flemming,E.The relationship between coronal place and vowel backness[J].Phonology,2003,(20).
[18]McMahon,A.An introduction to English phonology[M].Edinburgh:Edinburgh University Press,2002.
[19]Lin,Y.H.Variable vowel adaptation in Standard Mandarin loanwords[J].Journal of East Asian Linguistics,2008,(17).
[20]Silverman,D.Multiple scansions in loanword phonology:Evidence from Cantonese[J].Phonology,1992,(9).
