
朴素贝叶斯与Softmax回归在文本分类上的对比研究
2021-11-28 02:24李咏豪李伦波
电脑知识与技术 2021年28期
李咏豪 李伦波


摘要:文本分类问题是自然语言处理中的重要任务。本文将机器学习中的朴素贝叶斯模型以及Softmax回归应用于自动文本分类中,在清华新闻分类语料数据集上实现了基于多项分布与类条件分布假设实现了朴素贝叶斯模型,并使用BOOL、TF、IDF、TF-IDF四种特征权重训练了Softmax回归模型。最后,将两种模型在训练集与测试集上的性能进行对比。
关键词:朴素贝叶斯;Softmax回归;自然语言处理;文本分类
中图分类号:G642 文献标识码:A
文章编号:1009-3044(2021)28-0131-02
开放科学(资源服务)标识码(OSID):
A Comparative Study of Naive Bayes and Softmax Regression in Text Classification
LI Yong-hao*, LI Lun-bo
(College of Computer Science and Engineering, Nanjing University of Science & Technology, Nanjing 210094, China)
Abstract: Text classification is an important task in natural language processing. In this paper, the Naive Bayes model and Softmax regression in machine learning are applied to automatic text classification. The naive Bayes model is implemented on the Tsinghua news classified corpus data set based on the assumption of multinomial distribution and class conditional distribution. And the Softmax regression model is trained with four feature weights including BOOL, TF, IDF, and TF-IDF. Finally, we compare the performance of the two models on the training set and the test set.
Key words: naive bayes; softmax regression; natural language processing; text classification
1 引言
自然語言处理中的文本分类指的是给定文档,将文档归为n个类别中的1个。文本分类在现实生活中的用途十分广泛,比如,将社交媒体中短文按照其讨论内容分为不同的类别;在情感分析问题中,提取文档中人物表露的态度;在邮箱管理中,自动区别垃圾邮件与非垃圾邮件。
文本分类任务通常由传统的机器学习模型完成,如支持向量机[1]、朴素贝叶斯[2],也可由深度学习方法[3]实现。无论哪种统计学习模型,数据集对于模型性能都有着巨大的影响,本文中的模型使用了清华新闻分类语料数据集[4],它是根据新浪RSS订阅频道2005年至2011年间的历史数据筛选过滤生成的,包括74万篇新闻文档,10余个类别标签,数据集中句子已经过准确的分词,比如: 他 和 与 他 同辈 的 一 批 科学家 是 我国 计算机 技术 逼近 国际 先进 水平 的 希望 。同时,该数据集中包括一系列停用词,“我”“自己”等停用词十分常用,反而会影响新闻分类的精确度。由于数据规模过大,在CPU上训练速度缓慢,所以,在所有类别中,选择体育、政治、教育、法律、电脑与经济共6个主题的数据,每个子类中进行500条新闻的随机抽样。
2 模型介绍
2.1 朴素贝叶斯
机器学习模型可分为判别式模型与生成式模型。判别式模型对给定观测值的标签的后验概率[p(y|x)]建模,而生成式模型对观测值和标签的联合概率[p(x,y)]建模,然后用贝叶斯法则[p(y|x)=p(x,y)/p(x)]进行预测。朴素贝叶斯模型是一种生成式模型。
朴素贝叶斯采用词袋表示。在词袋模型中,不考虑文档中单词的位置,词与词之间是互相独立的,就像将所有词语装进一个袋子里一样。
朴素贝叶斯文本分类的步骤如下:
(1) 计算先验概率,即[p(y=cj)],每个样本对应的先验概率等于所属类别样本数占所有样本数目的比例。
(2) 计算条件概率,令N为文档个数,V为词表大小,[N(ti,x(k))]表示第i个词在第k个文档中出现的次数,[cj]表示第j个类别:
[θi|j=Nk=1I(y(k)=cj)N(ti,x(k))+1i'=1VNk=1I(y(k)=cj)N(ti,x(k))+V](多项式分布假设) (1)
[μi|j=Nk=1I(y(k)=cj)I(ti∈x(k))+1Nk=1I(y(k)=cj)+2](多变量伯努利假设) (2)
[μi|j]与[θi|j]表示一个文档中的第i个词属于第j个类别的概率,对于多项式分布假设,分母为所有文档总词数,分子为文档第i个词在第j类所有文档中出现的总次数;对于多变量假设,分母为所有文档中出现过第i个词的文档数目,分子为第j类所有文档中有第i个词出现的文档数目。为了防止零概率问题,需要进行拉普拉斯平滑处理。
(3) 计算后验概率[p(x|y=cj)=i=1V[I(ti∈x)μi|j+I(ti∈x)(1-μi|j)]],去后验概率最大时对应的类别作为预测类别。
2.2 Softmax回归
Softmax回归[5]是一种多分类模型,也称作多类logistic回归,在NLP中,与最大熵模型是等价的,Softmax回归作为一种广泛使用的分类算法,常常作为深度学习分类模型最后一层执行分类预测。与朴素贝叶斯不同,Softmax模型是一种判别式模型。
模型假设如下:
[p(y=j|x;θ)=hj(x)=eθTjxk=1CeθThx,j=1,2,…C,where θC=0] (3)
[p(y=j|x;θ)]表示给定参数[θ]时,样本x属于第j类的概率。值得注意的是,样本x通过特征权重法构造,对于每一个文档,特征权重法构建一个词表,词表中的每个词具有一个固定的下标以及一个特征值。在使用TF特征(Term Frequency)时,某一文档的特征向量中对应词的特征值等于词在文档中出现的次数,其他特征权重方法有BOOL、IDF、TF-IDF等。
Softmax回归模型使用梯度下降法更新权重:[?l(θ)?θj'=k=1N(1y(k)=j'-hj'(x(k)))x(k)]。
3 实验
所有模型中,朴素贝叶斯(多项式分布)在测试集上的准确率最高,训练时间最短。Softmax回归模型使用TF权重时,测试集上的准确率最高。
朴素贝叶斯(多项式分布)实验结果如图1所示。
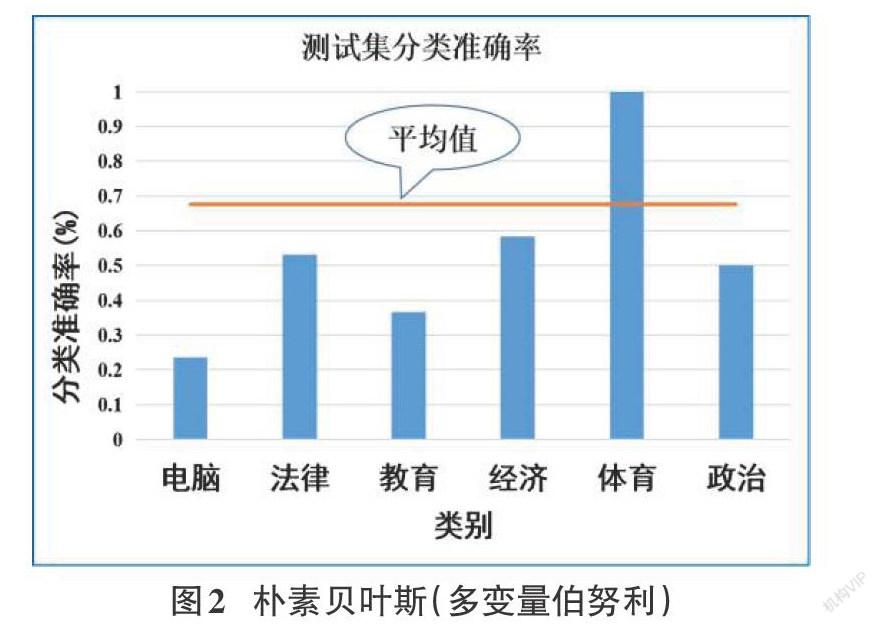
朴素贝叶斯(多变量伯努利)[6]实验结果如图2所示。
Softmax(GD+TF)实验结果如图3所示。
Softmax模型对于训练集的拟合效果更好(准确率达到100%),但在测试集上,朴素贝叶斯分类准确率更高。我们观察到Softmax的具体分类准确率与训练集的文档数目存在联系,某一类别在训练集中的文档数目越多,则测试集上该类的分类准确率越高。Softmax模型不需要词袋假设,适用范围更广泛。而在数据集较小的文本分类中,朴素贝叶斯模型的速度快、识别准确率高。时间成本上,朴素贝叶斯低于Softmax回归。原因如下:朴素贝叶斯模型直接统计得到频率与概率表格,不需要使用梯度下降进行参数优化。
基于多项式假设的朴素贝叶斯模型准确率远高于多变量假设。这是因为在多项式模型的类条件概率计算中,对于一个文档d,多项式模型中,只有在d中出现过的单词,才会参与后验概率计算。Softmax(bool)模型在本问题中优于多变量伯努利模型。
分类准确率:TF > IDF > BOOL > TF-IDF。BOOL特征权重具有实现简单,速度快的优点,但是忽视了词频。TF权重以词频度量词的重要性,词频越高,认为该词越重要。对于大部分词,词频高,说明词重要。然而,有一些词(如“方面”、“中国”)在文档中大量出现,此时,词频无法有效描述文档的特征。
4 结束语
本文将对朴素贝叶斯模型和Softmax回归進行了对比研究,并在清华新闻分类语料数据集上进行了文本分类实验,实验结果表明,从时间复杂度来看,朴素贝叶斯低于Softmax回归,Softmax模型适用范围较广。
参考文献:
[1] 岳文应.基于Doc2Vec与SVM的聊天内容过滤[J].计算机系统应用,2018,27(7):127-132.
[2] 苏莹,张勇,胡珀,等.基于朴素贝叶斯与潜在狄利克雷分布相结合的情感分析[J].计算机应用,2016,36(6):1613-1618.
[3] 孙志远,鲁成祥,史忠植,等.深度学习研究与进展[J].计算机科学,2016,43(2):1-8.
[4] 蔡巍,王英林,尹中航.基于网上新闻语料的Web页面自动分类研究[J].情报科学,2010,28(1):124-127,136.
[5] 刘亚冲,唐智灵.基于Softmax回归的通信辐射源特征分类识别方法[J].计算机工程,2018,44(2):98-102.
[6] 吴皋,李明,周稻祥,等.基于深度集成朴素贝叶斯模型的文本分类[J].济南大学学报(自然科学版),2020,34(5):436-442.
【通联编辑:唐一东】
猜你喜欢
计算机应用(2016年12期)2017-01-13
电子技术与软件工程(2016年22期)2016-12-26
电脑知识与技术(2016年23期)2016-11-02
科教导刊·电子版(2016年23期)2016-10-31
科技视界(2016年24期)2016-10-11
电脑知识与技术(2016年10期)2016-06-16
求知导刊(2016年10期)2016-05-01
电脑知识与技术(2016年5期)2016-04-14
科技视界(2016年5期)2016-02-22
