
采用复合知识蒸馏算法的黑皮鸡枞菌图像分级方法
2021-11-25 13:26:06赵明岩李一欣宋天月李焕然
农业工程学报 2021年17期
赵明岩,李一欣,徐 鹏,宋天月,李焕然
(1.中国计量大学机电工程学院,杭州 310018;2.中国计量大学理学院,杭州 310018)
0 引 言
黑皮鸡枞菌(Oudemansiella raphanipes)作为一种高档菌菇,富含蛋白质、氨基酸等多种营养物质,在降血糖、降血脂、抗癌等方面具有独特的生理功效[1],具有较高的研究与开发价值。近年来随着消费水平的提高,其市场规模逐年扩大。鸡枞菌各级别之间的价格可相差数倍,为使经济效益最大化,须将品相饱满、外形匀称的鸡枞菌与丛生菇、无伞菇区分开来。然而传统的人工分选方式存在效率低、一致性差等问题。随着云南、贵州等地的大面积种植和产量大幅提高,人工分选方式已经不能满足生产需求。
机器视觉技术[2-5]在特定的环境条件下可快速、高精度地检测单一目标,但当外界因素如光照等发生变化时,检测结果会出现一定偏差。而基于深度学习的图像检测系统可学习识别不同环境下的目标,目前被广泛用于谷物[6-7]、畜牧[8-10]、蔬果[11-13]等诸多领域。在搭建蘑菇数据集方面,袁培森等[14]在基于生成式对抗网络(Generative Adversarial Networks, GAN)的基础上使用Wasserstein距离和带有梯度惩罚的损失函数构建菌菇数据模型,为后期解决珍稀菌菇分类数据非均衡的问题提供了研究基础。在蘑菇分级系统方面,Lin等[15]采用长短期记忆网络(Long Short-Term Memory,LSTM)对蘑菇进行实时跟踪分级,可准确定位蘑菇,并能预测蘑菇在摄像机视野之外的位置,但分级时间长,效率低。Lu等[16]采用基于计分惩罚算法(Score-Punishment algorithm)的YOLOv3进行蘑菇的估计分级,对于不同时期采集的蘑菇图像,该算法具有很强的鲁棒性,能够克服颜色偏差对估计精度的影响,但不适用于黑皮鸡枞菌的品质分选。
综上,国内外学者基于深度学习技术对农产品的精选分级进行了广泛研究,但目前针对黑皮鸡枞菌的研究以营养方面[17-18]为主,图像分级识别方面的研究未见述及。目前深度学习领域的研究主要分为两类[19]:第一类模型参数量大,精度高,但单幅识别时间长;第二类模型参数量小,识别速度快,但精度低。由于黑皮鸡枞菌分级特征不显著,对深度学习模型要求高,而现有网络模型适用性低,无法满足鸡枞菇分级需求。近年来知识蒸馏算法[20-23]在解决优化模型效率的问题中颇受青睐,该算法通过大参数模型去训练小参数模型,可在不提高资源占用的前提下,提升小参数模型精度。本文针对黑皮鸡枞菌特征分级的实际需求,构建Resnet18基础网络结构,并通过复合知识蒸馏优化模型,以实现鸡枞菌自动品质分级,为鸡枞菌分级生产线的应用提供技术支持。
1 材料与图像采集
选用由贵州省水城县营盘乡鸡枞养殖基地(26°8′~26°15′N,140°40′~140°47′E)提供的黑皮鸡枞菌作为试验材料,其收获时间为2020年11月1日。参考菇业标准[24],按照菇柄、菇盖、色泽等因素将鸡枞菌分为4类:一级菇、二级菇、无伞菇、丛生菇,如图1所示。一级菇为菇柄饱满且菌帽未开张的鸡枞菌;二级菇为菇柄细长、菌帽平展的鸡枞菌;而无伞菇及丛生菇均存在一定的缺陷,属于次品菇。
采用工业相机(有效像素为2 592×1 944)垂直拍摄鸡枞菌样本,拍摄条件为室内环形灯光照,将待分级鸡枞菌随机摆放,拍摄4个品类(均为750根)鸡枞共3 000幅图像,图像采集装置如图2所示。
使用Python语言对得到的鸡枞图像进行预处理。首先计算图像中每一根鸡枞菌的最小外接矩的二维坐标,从而在原始图像中分割出每一个鸡枞菌的RGB图像。由于卷积神经网络的输入图像一般为正方形,因此将单根鸡枞菌图像扩展为正方形。采用Retinex算法对鸡枞菌图像进行色彩平衡、归一化、增益及偏差线性加权处理。Retinex算法的目的是突出显示选定的特征及弱化其他无关特征,通过对缺陷进行补偿,可改善低质图像,并能使其更清晰地被观察到[25-26]。
式中x为像素点的行坐标,y为像素点的列坐标,F(x,y)为中心环绕函数,λ为尺度值,c为高斯环绕尺度,Ri(x,y)为反射图像,Ii(x,y)为原始图像,Li(x,y)为图像亮度,ri(x,y)为输出图像。
随后进行数据增强操作,对样本数据按任意顺序随机添加下列三种扩充方法:旋转、随机裁剪、增加图像高斯噪声来丰富数据集,将3 000幅图像扩充为6 000幅,同时按照8:2的比例,将4 800幅鸡枞菌图像作为训练集,其余1 200幅图像作为验证集。
2 卷积神经网络基本框架
2.1 ResNet神经网络基本框架
卷积神经网络模型与传统网络模型相比,一方面降低了训练的参数量,另一方面降低了模型的复杂度,且提取的图像特征(如颜色、纹理、形状及图像的拓扑结构)具有更高的准确性[27]。早期的卷积模型如LeNet5[28]、AlexNet[29]、VGGNet[30]等在网络层数较低的情况下,可以有效对整个网络的参数矩阵进行不断调整。但随着网络层数不断加深,来自结果的误差信号在传播过程中会逐渐消失,模型准确率反而下降。而Resnet引入了残差网络结构(residual network),通过这种残差网络结构,在加深网络层的同时,最终的分类精度也得到提升[31]。
残差网络的基本结构如图3所示,通过捷径连接的方式将输入x添加到输出,即输出结果为H(x)=F(x)+x。区别于早期神经网络结构,Resnet的学习目标不再是单一的输出,而是残差块F(x),即H(x)和x的差值。当进行链式求导来求得某个参数的偏导数时,传统模型仅对一层网络求偏导时的更新公式为
式中Loss为损失值,X为样本,W为权值,b为偏置数。
当网络足够深的时候,求偏导的结果趋近于0,使得前端网络得不到有效更新:
式中Xi(i∈1…N)为第i层样本值,Wi(i∈1…N)为第i层权值,bi(i∈1…N)为第i层偏置数,Fi(i∈1…N)为第i层非线性映射残差函数。
而当增添残差块之后,偏导结果如下所示:
此时,参数反馈中的梯度弥散问题得到解决,并且函数拟合F(x)=0会比F(x)=x更加容易,使得网络结构对参数的变化更加敏锐。
本文主干网络是在Resnet18网络结构基础上改进而来,如图4所示。网络采用了残差网络结构且在每2个卷积层接1个残差链接,网络共包括17个卷积层,1个池化层,1个全连接层。其中卷积核尺寸为3×3,池化层采用Avg Pool。
2.2 函数选取及网络优化
Adam优化器来源于自适应矩估计(Adaptive Moment Estimation),其迭代参数的学习率有一定的范围,不会因梯度变化而大幅偏移设定值,参数值相对比较稳定。
式中t为时间步数,θt为更新梯度,ft(θ)为关于θ的随机目标函数,∇θ为对θ求偏导,gt为梯度值,β1,β2∈[0,1)为指数衰减率,mt为一阶矩的估计值,ˆtm为经过偏差修正的一阶矩估计值,vt为二阶矩的估计值,vˆt为经过偏差修正的二阶矩估计值,α为步长,ε为任意小的正数。
训练精度曲线可以检测模型的运行情况,优化器分别选用Adam和Adadelata,其他参数保持初始状态,对验证集进行1 000次迭代训练后的精度变化曲线如图5所示,预测精度为预测标签是正确标签的概率。可得Adam优化器的训练速度以及精度明显优于Adadelata优化器,可使神经网络模型收敛速度加快,缩短模型训练时间。
3 复合知识蒸馏算法
随着Resnet卷积神经网络提出残差网络结构,网络深度不断延伸,大网络模型逐渐投入使用。虽然大网络模型拥有较高的准确性,但在部署阶段需占用巨大的内存资源,且运行极其耗时。而农业领域针对农产品识别时,要求神经网络模型资源占用少、响应速度快。为实现上述目的,需将大参数模型压缩成小参数量模型,且保证模型准确率。知识蒸馏算法的提出为解决上述问题提供了一种新的思路。
3.1 知识蒸馏基本结构
知识蒸馏方法用教师模型(大参数模型)去训练学生模型(小参数模型),提供学生模型在hard label(硬标签)上无法习得的soft label(软标签)信息。相比于学习单一正确标签,通过知识蒸馏学生模型能学习到预测目标的类别权重,这些类别权重是学生模型提取不到而教师模型可通过训练得到的,从而在不提高资源占用的情况下,使得学生模型精度得到提高,知识蒸馏基本结构如图6所示。
3.2 复合知识蒸馏算法提取模型
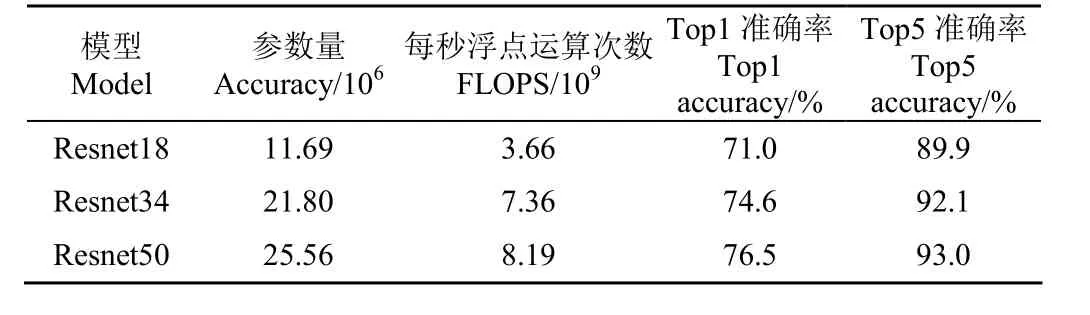
本研究数据测试选用ImageNet-1k训练集,通过对Resnet18、Resnet34、Resnet50 3个模型进行训练得到各自模型信息如表1所示,FLOPS为每秒浮点运算次数,Top1准确率为预测标签中概率最大的标签是正确标签的概率,Top5准确率为预测标签中概率排列前五的标签中出现正确标签的概率。已知教师模型采用更深的网络层数,能使学生模型更加有效地提高其预测准确率[20],本文选用Resnet18为学生模型,即本文主体网络;Resnet50为教师模型,负责优化学生模型参数。
?
卷积操作可在降低图片尺寸的前提下,提取鸡枞菌形状特征,减少卷积神经网络的运算量。本文采用截留网络输入层传输至中间层的参数信息方法,观察Resnet18第9层及Resnet50中第25层的图像特征信息,所得结果如图7所示。
通过对比第9次卷积操作和第25次卷积操作后提取的图像特征,能够发现随着卷积层的加深,网络模型更容易提取到鸡枞的深层特征。目前知识蒸馏算法仅通过输出的soft label信息更新整体学生模型,导致模型更新信息在传递过程中仍存在一定程度的失真现象。为更加充分利用特征信息,本文提出了一种基于复合知识蒸馏提取模型的黑皮鸡枞菌分级检测方法,同时在模型的不同位置使用知识蒸馏,其网络结构如图8所示。
首先使用训练集对教师模型(Resnet50)进行1 000次训练,直到其预测准测率达到最大值,随后截留Resnet50第25次卷积操作的输出对学生模型(Resnet18)的前9层卷积模型进行参数训练。学生模型能够在训练过程中通过学习教师模型的输出不断地调整权重信息,使其获得较优结果。最后将经过预训练的学生模型的前9层卷积模型与其后半部分进行拼接,进行整体模型的知识蒸馏。
4 试验与结果分析
4.1 试验平台
对一级菇、二级菇、无伞菇、丛生菇等4种品质进行分级,测试硬件为Intel Core i7-9700F 3.00 GHz,内存16GB,配备NVIDIA GeForce RTX 2060 GPU加速试验进程,试验运行环境为Windows 10(64位)操作系统,PyCharm2019版本,Python 3.7版本, Tensorflow 2.1版本。
4.2 试验参数设置
每次训练选取的样本数量为4 800幅,迭代共1 000次,采用Adam优化器,初始学习率为0.001。在每层之间添加BatchNormalization层[32],BN层可以使得非线性变换函数的输入值落入对输入比较敏感的区域。同时在输入层之后和全连接层之前分别添加Drop-out层,Drop-out虽会影响整个模型的训练速度,但可提升鲁棒性,使最终准确率得到提高。
4.3 结果分析
为验证复合蒸馏提取模型的有效性,将其与改进前的Resnet18与Resnet50模型在训练集上进行鸡枞菇识别结果比较,具体定量识别结果如表2所示,其中准确率为预测值与真值相符合的概率。由表2可知,经过复合蒸馏的Resnet18识别准确率为96.89%,识别单幅图像所用时间为0.032 s。本文模型相比Resnet50识别单幅图像所用时间缩短68.93%,同时相比于未经过知识蒸馏以及经过单次知识蒸馏的Resnet18模型,准确率分别提升了0.97和0.52个百分点。准确率改善的原因在于:传统神经网络反向传播参数更新时,每经过一层卷积层就存在一定的失真现象。随着网络结构的加深,模型前几层往往得不到有效的更新信号,而本文Resnet网络使结构对参数的变化更加敏锐,且知识蒸馏技术可以给学生模型提供在hard label上学不到的soft label信息。本文提出的复合知识蒸馏技术让学生模型的前半部分预先学习高阶特征信息,然后再对模型整体进行参数调整。可使其更加充分地吸收教师模型中的知识,改善反馈参数在传递过程中梯度弥散现象。因此,本文提出的基于复合蒸馏的Resnet18可在不增加硬件配置以及运行时间的前提下,显著提升鸡枞菌识别及分级精度。

表2 训练集下模型使用复合知识蒸馏与未使用知识蒸馏的对比Table 2 Comparison between the training set model by compound knowledge distillation and that without knowledge distillation
混淆矩阵是用于评估深度学习分类模型性能的矩阵,它将实际目标值与深度学习模型预测的目标值进行比较,有助于分析分类模型的性能情况。本文模型分类的混淆矩阵如图9所示,使用数据集为验证集,图像总数为1 200幅,4类鸡枞菌数量均为300幅,通过混淆矩阵可以看出,模型对4类鸡枞菌的识别准确率都处于较高水平,其平均准确率为96.58%。其中无伞菇及丛生菇准确率较高,分别为97.67%、99.00%,说明形状特征差异越显著,越利于模型学习,而参数训练误差产生了少数错误预测样本;一级菇及二级菇准确率相对较低,分别为95.33%、94.33%,这是由于二者形状特征重叠度高,不易于区分造成的。进一步增强不同鸡枞菇特征之间的可区分性是下一步研究重点。
Kappa系数是一致性检验指标,可用于衡量分类效果,由混淆矩阵数据计算得出。
式中po表示模型准确率,pe表示各自类别的实际数量与其预测数量乘积的总和除以样本总数的平方。
本研究中不同网络模型的Kappa系数如表3所示,其中经过双蒸馏的学生模型的模型准确率为0.968 9,各自类别的实际数量与其预测数量乘积的总和除以样本总数的平方为0.242 2,Kappa系数为0.959 0,优于其他方法训练的学生网络,仅次于教师网络,可得模型预测结果和实际分类结果近乎完全一致。
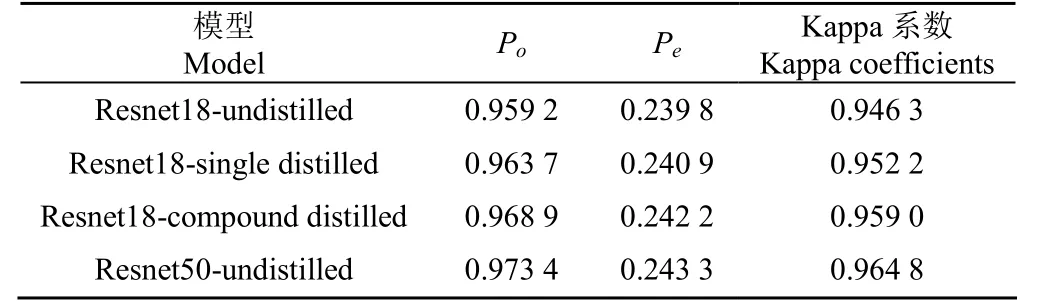
表3 不同网络的Kappa系数对比Table 3 Comparison of Kappa coefficients of different networks
综上可知,本文所提出的复合知识蒸馏算法对不同品质鸡枞菌的识别效率有显著提升,能够实现鸡枞菇形态的有效识别,符合智能分级需求。
5 结 论
本文提出了一种基于卷积神经网络和复合知识蒸馏优化算法的黑皮鸡枞菌分级模型,一定程度上解决了农产品领域要求神经网络识别精度高、模型部署规模小的需求。让学生模型的前半部分预先学习特征信息,然后再对模型整体进行参数调整,通过复合学习可使学生模型充分获得高阶特征。主要结论如下:
1)通过使用复合知识蒸馏算法优化,模型在训练集中对鸡枞菌的检测准确率为96.89%,较初始Resnet18模型提升0.97个百分点,同时较传统知识蒸馏模型提高了0.52个百分点;单幅图像检测时间为0.032 s,较Resnet50模型缩短68.93%。
2)采用混淆矩阵校核本文模型在验证集中的分类预测准确率,得出模型对4类鸡枞菌的识别准确率均较好,4类平均准确率为96.58%,尤其是对丛生菇的识别,准确率达到了99.00%,证明本文所提出的方法能够对4类鸡枞菌图像进行准确识别。
本文提出的复合知识蒸馏算法可在不增加运行时间及额外硬件占用的前提下,使小模型的准确率逼近大型网络训练准确率。研究结果可为实际鸡枞菌分级生产线的应用提供技术支持,进一步推动基于神经网络技术的农产品视觉快速检测与分选的发展。
猜你喜欢
今日农业(2021年4期)2021-11-27 08:41:35
食品安全导刊(2021年20期)2021-08-30 06:40:14
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
作文周刊·小学三年级版(2019年16期)2019-06-20 11:27:14
中国交通信息化(2018年5期)2018-08-21 03:37:40
中国医疗保险(2017年6期)2017-07-18 11:28:19
中国卫生(2016年5期)2016-11-12 13:25:50
中国卫生(2015年10期)2015-11-10 03:14:22
