
数据驱动下的人工智能知识生产
2021-11-17 12:34:06巴特尔
中国科技论坛 2021年11期
苏 明,陈·巴特尔
(1.汕头大学高等教育研究所,广东 汕头 515063;2.南开大学周恩来政府管理学院,天津 300350)
0 引言
图灵奖得主Jim Gray认为,今天在科学的很多领域里,科学家们已不再透过望远镜观察,而是由仪器采集或模拟产生数据,再通过软件处理,将产生的信息或知识存储在计算机里,在数据采集、数据处理、知识存储、知识应用等数据化知识生产的全链条中,人所发挥的作用越来越小,人智对科学发明的决定性作用正在消失,许多科学研究已经不再苛求于科学家的亲力亲为和灵光一现,而是更加重视数据系统的硬件和软件建设,进而把知识生产转变为程式化、规范化、智能化的机械流水线[1]。Gray把知识生产总结为四种范式 (不同于库恩定义的范式):第一范式是以简单数量关系与通则论为基础的定性研究;第二范式是以小样本数据外推复杂因果关系的定量研究;第三范式是以有限数据模拟科学结论的仿真研究;第四范式是以全样本大数据驱动的数据密集型研究[2]。传统知识生产范式对大数据时代的海量数据束手无策,长期面临 “数据很丰富,缺乏分析能力”的问题,以深度学习为核心的新一代人工智能使得基于大数据的知识生产成为现实。本文分析了新一代人工智能与人脑知识生产的比较优势和人工智能知识生产的问题,并提出改进建议。
1 新一代人工智能与人脑的比较
新一代人工智能是以深度学习为代表的人工神经网络方法,本质上是一种对生物神经元的模拟而形成的数据分析技术,主要包括数据训练过程和模型应用过程,如图1所示。
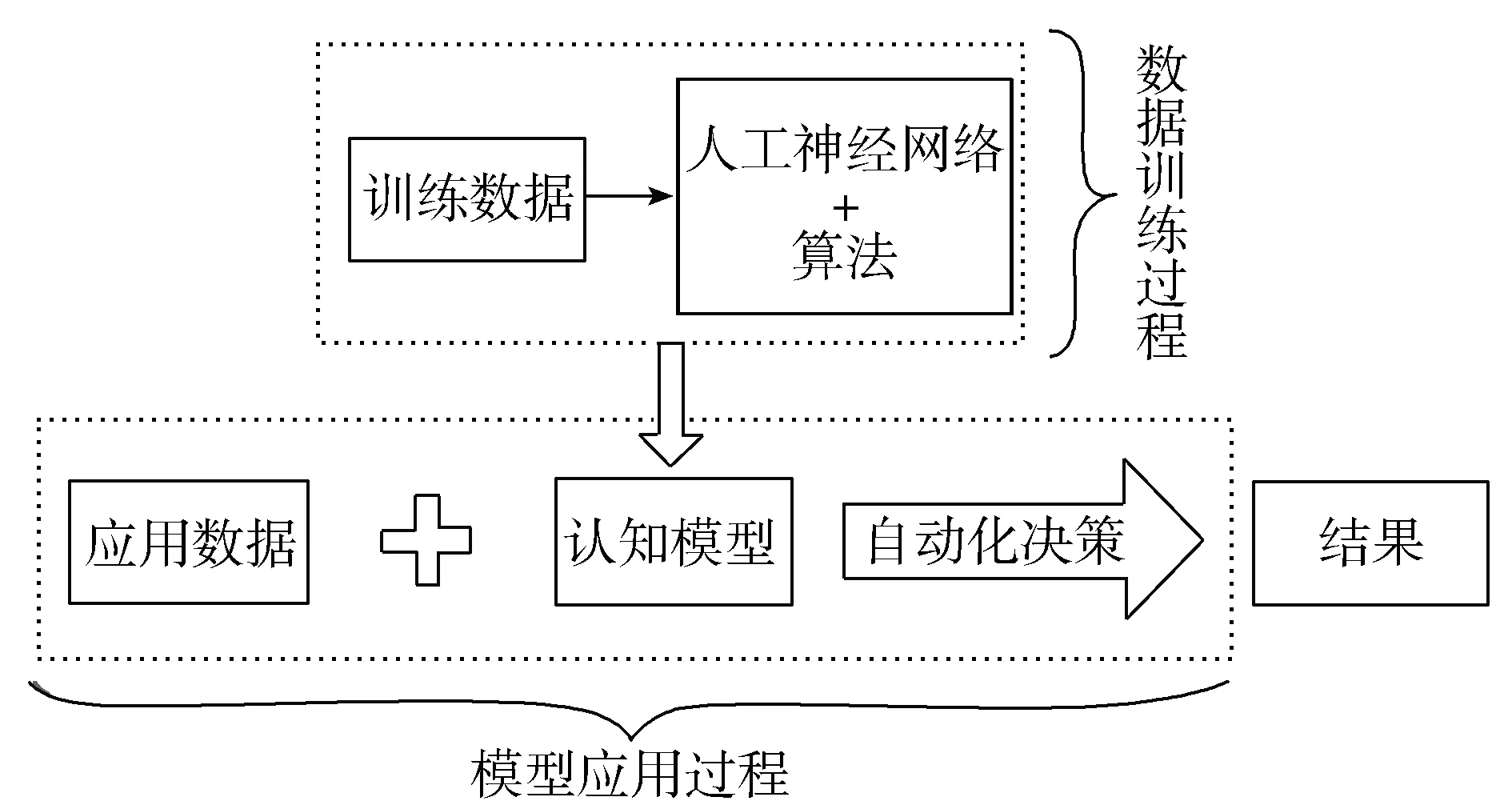
图1 深度学习的运行流程
人脑是一个功能非常强大的信息处理器,有860亿个神经元,仅仅人的眼睛每秒处理的数据量就高达140.34GB,而且能够同步处理图像、声音、温度、气味等数据,每秒大脑神经网络处理数据达1000亿次,相当于50亿本书的存储容量[3]。人工神经网络中的神经元数量在近些年中快速增长,但是也没有超过人脑的水平。目前人工神经元数量最多的是2020年浙江大学与之江实验室研发的 “达尔文二代”人工脑,共含有1.188亿个人工神经元,但也只是达到小鼠的大脑神经元水平。尽管如此,人工智能还是具有很强的优势,主要是因为人脑存在以下两方面的局限:
其一,人脑对数字数据的处理能力极差。Hans Moravec发现,驾驶等人类很容易做到的事情人工智能做起来却很困难,同时也有一些人工智能做起来容易的事情人却很困难,这个特点最显著的领域就是数字计算。普通人计算两个两位数的相乘就已经很困难,机器却能够快速准确地计算非常复杂的数据,同时,数字数据早已取代书籍、报纸等媒介数据,成为数据的主要形式。在2000年,数字数据仅占全球数据总量的25%,到2007年这一占比就达到了93%,越来越多的数据是以数字的形式存储,而人类所能理解的书籍、报纸等媒介数据占比大幅下降[4]。面对数十ZB级的数字数据,人工智能可以弥补人脑无法处理大数据的缺陷,将人脑无法利用的海量数字数据自动化地搜集、分析和可视化呈现,把人脑无法分析的数字数据可视化为人脑可以分析的媒介数据。
其二,人脑的信息存储能力不足。遗忘是人脑的显著特征,人脑24小时的遗忘率高达66.3%,回忆或提取信息非常困难,而对于短期记忆,如果输入的信息量太大,人脑也很难保存。因此,人脑在信息处理中总是使用片段数据,无法处理数据的全景,再加上人脑的数据获取会受到个体经历差异的影响,导致人的知识生产常常带有主观性,甚至是片面性,而网络中的数据具有 “永久记忆”的特征,即使经过再长的时间也不会被遗忘,信息损耗较小。
人工智能非常擅长模仿生成一种与数据训练样本风格相似的作品,而且在许多领域的应用中有超越人的表现,如表1所示。人工智能程序的运算效率比人更快、信息获取更便捷,能够时时刻刻关注到动态数据,并在第一时间进行数据分析和处理。人工智能搜集信息、加工信息和推送信息的衔接更流畅,各知识生产环节衔接的间隔时间很少。
2 人工智能知识生产的问题
人工智能知识生产具有很大的比较优势,同时产生了新的问题,主要体现在以下方面:
其一,人工智能知识生产的理解困境。可理解性是知识的基本要求,知识加工就是一个知识理解的过程,人无法从自己不理解的知识中建构和生长出新的知识,也无从知晓其价值和可靠性,更无法在知识分享中让他人获得理解。人在知识生产中会形成 “如果A,那么B”的产生式规则,而人之所以能够在A和B之间建立联系,一定是基于自己对A和B两个事物或行为的理解之上。而人工智能只是按照算法规则将数据处理之后输出一个结果,由于缺乏先验的知识定义,人只能知道数据处理中有哪些维度以及各维度的参数,却无法理解为何输出这一结果,其知识生产过程是不可理解的黑箱。美国已有一半以上的州使用COMPAS、PSA、LSI-P等智能量刑评估软件来裁定犯人的量刑,但是人工智能对犯人信息的运算过程不可理解,法官和犯人都不知道为何会输出这样的结果,只能接受程序的输出结果就是如此,而人工智能的算法是否有效、结果是否准确、量刑的依据是否可靠都存在疑问,法律的程序正义受到极大挑战[6]。
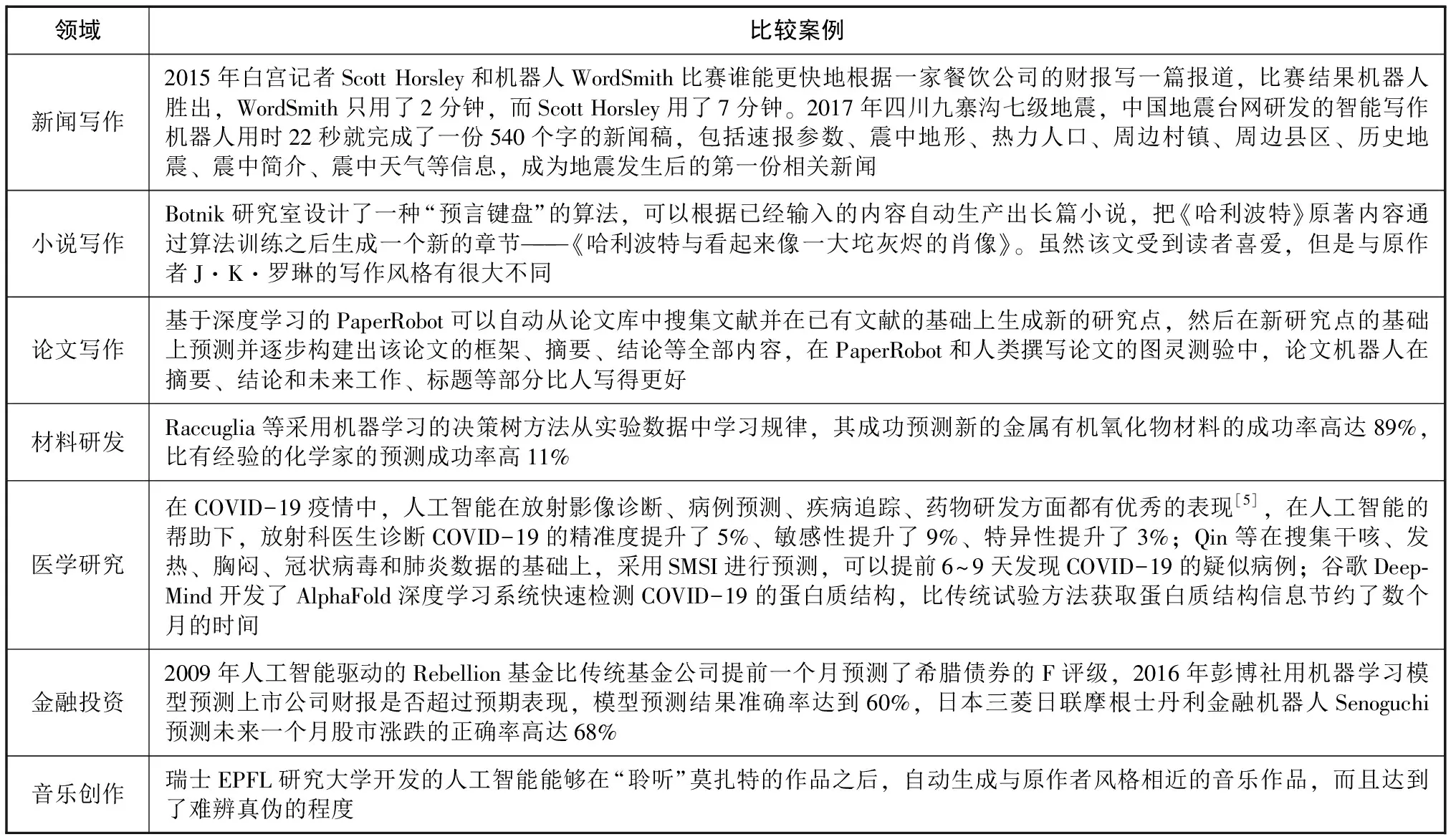
表1 人工智能与人的比较
其二,人工智能与精英权力的弱化。在某种程度上,精英在高深知识生产中具有垄断性,在知识解释和知识应用中具有权威性。权力来自于施加影响的能力,精英在高深知识生产中具有不可替代的作用,也因此获得与职能相匹配的软性或硬性权力。随着人工智能应用的加深,在金融等许多领域人工智能的能力已经超过了精英,人工智能生产的知识替代了专家知识,打破了精英知识生产的垄断性,专家成为知识生产和企业决策的可替代品,而数据的价值显著扩大,各个社会领域中的重要决策不再向外仰赖于专家指导,而是向内挖掘数据的价值。
其三,人工智能知识生产的约束问题。知识生产是在已有知识结构上生长,但是这种生长不是自然生长,而是受约束的生长。一方面,知识生产的目的是为人服务,人的价值选择和现实需要引领知识生产的大方向,人的需求是知识生产的主要牵引力;另一方面,人的伦理观念限制了恶的知识生长,由于知识结果的不可预知性,生产出的新知识既可能对人的公共利益有所损害和威胁,也有可能违反人的伦理纲常,因此人必须对知识生产进行强力干预来约束知识生产的过程,并通过人的价值选择来引导技术的社会化改造,从而保障知识真正具有造福于人的功能。人工智能的知识生产难以受到人的约束,虽然人设定了人工智能知识生产的目标,但却无法干预知识生产的过程,也无法预测知识生产的结果,人工智能的程序设计和开发者并不具有对智能产品的完全控制力,很有可能造成人工智能的歧视等问题。机器学习让人工智能产品具有独立的判断、学习和决策能力,程序设计者只是制定了学习规则而无法准确判断其具体影响,人工智能甚至可以突破原有设定而学习到新的规则。如果生产的知识侵犯了人的利益,该知识生产者需要承担相应的法律责任,法律机制是约束知识生产的主要方法。但是人工智能知识生产却难以受到法律约束,智能算法的黑箱化让人们难以分辨清楚造成损失的具体原因,难以制定人工智能法律评判的标准,而且人工智能的知识生产过程具有一定的自主性,难以将人工智能知识产品的缺陷归咎于程序设计师,对人工智能知识产品本身施加法律处罚也没有任何意义,通过法律约束人工智能的知识生产非常困难。
其四,人工智能知识生产的数据垄断问题。数据是人工智能知识生产的必备原料,数据垄断直接导致人工智能知识生产的垄断。数据的质量差异、搜集成本以及分析能力都会使得数据具有很强的排他性。数据驱动的人工智能知识生产最需要解决的问题是数据的可得性问题,在智能制造领域这主要体现为需要通过高昂的费用布置传感器来搜集生产过程中的大数据,而在互联网领域这主要体现为需要通过建立对用户的吸引力来诱使规模化的用户自愿成为互联网平台中的数据生产者,尤其是互联网平台的双边市场特征决定其必然存在走向垄断的趋势,基于垄断数据生产的知识也必然是垄断性的知识。生产知识的目标是为了获取企业更大的竞争优势,而其中所附带生产的公共价值也很难被共享,无法形成知识生产的带动效应。
3 人工智能知识产品的产权及归属
(1)人工智能知识产品是否具有知识产权?知识产权是一种针对智力劳动的财产权,其确权的主要依据在于判断该知识产品是否有别于纯粹自然状态的创造物[7]。显然,人工智能的知识生产过程也是一种智力活动过程,人工智能知识产品也具有很强的独创性,而且人工智能的知识产品已经达到与自然人的知识产品难辨真假的程度。既然自然人生产的知识产品符合知识产权保护的要求,那么人工智能的知识产品也应该符合知识产权的保护要求。但是人工智能的知识生产活动是否是劳动存在极大争议,知识产权既是一种私权,也是一种人权,设立知识产权是为了保护人的智力劳动所形成的非实体成果,使知识产品的生产者获得智力劳动的应有收益而免遭剽窃者的侵害,并以此来激发人的创造精神。因此,知识产权一定是自然人的知识产权,而人工智能却不是自然人。所有的知识产权理论都强调被保护的知识产品必须是自然人的智力劳动成果,美国版权局规定作品的法律保护必须符合人类创作的条件,包括所有动物等非自然人使用工具生成的作品都不受版权保护。2011年印尼森林中的一只猿猴使用斯莱特的摄影机拍摄了一张照片,斯莱特认为他应当享有该照片的版权,但是版权局拒绝对该照片进行版权登记,法院上诉也被驳回[8]。从这个角度看,人工智能的知识产品肯定没有知识产权,尽管人工智能知识产品符合知识产权保护的独创性要求,但是由于人工智能不是自然人,现有法律并不认可人工智能的知识产权。
如果人工智能的知识产品不受法律保护,那么人工智能的知识产品必然会被滥用,鉴于人的知识产品和人工智能知识产品在消费市场中处于竞争关系,人工智能知识产品的滥用必然会导致人的知识产品毫无竞争优势,直接威胁到人的智力劳动的应有收益,当人的知识产品失去市场和获益价值,针对自然人的知识产权法律保护也就失去了其存在的意义。另一方面,如果人工智能知识产品不受法律保护,随着人工智能知识产品越来越多,由人工智能知识生产所带来的财富应该如何分配也成为一个亟待解决的问题。总体上,现有的法律体系非常强调知识产权的人权属性,并不认可人工智能知识产品具有知识产权,但是由此引发的社会问题要求法律界对知识产权制度进行检讨和改变,近些年中国、日本、欧盟等国家或地区都在激烈讨论人工智能知识产品的产权保护问题,仍然没有达成共识,鉴于人工智能区别于一般工具的特殊性,法律界存在一种针对人工智能单独立法的倾向。
(2)如果人工智能的知识产品具有知识产权,那么人工智能知识产权应该归属于谁?目前只有英国明确规定了人工智能知识产品的法律地位和归属问题,其1988年 《版权、设计和专利法》规定,对计算机所生成的作品进行必要的程序设计的人员,视为计算机生成作品的作者。本法中的计算机生成是指作品完全由计算机创作,不存在任何人类作者[9]。可以看出,法律设定了一种特殊情况下的人工智能知识产品归属方案,即当人工智能完全自主地进行知识生产的情况下,人工智能知识产品的产权明确归属于程序设计者。然而,当前的人工智能仍然不具备完全自主的知识生产能力,人总是需要或多或少地参与到人工智能的知识生产过程中,因此,英国法律虽然进行了明确的规定,但是却缺乏实际应用场景。在一般知识产权归属的认定中,人对知识生产的掌控能力是知识产品具有创造性的根本原因,所以,明确谁具有知识产品生产过程的直接掌控能力是确定谁具有该知识产权的关键。例如,当摄影师使用相机拍摄照片时,摄影师对取景、光线等内容的控制对该照片的独创性起决定性作用,那么该摄影师享有该照片的版权,而不是相机的制造者。基于知识生产中的掌控力,按照一般知识产权归属的认定规则,人工智能知识产品的产权应该归属人工智能的使用者,如果该使用者是被雇佣人员,那么该人工智能知识产品的产权应该归属于雇主。这种人工智能知识产品的产权归属认定办法存在几个问题:
其一,相对于一般的机械工具,人工智能知识生产的自动化水平更高,其独创性来源于人工智能程序本身,而人对于人工智能知识产品的独创性没有任何实质性的贡献,这使得人在人工智能知识生产中所发挥作用的程度远小于其他工具的知识生产。因此,把人工智能知识产品的产权归属于使用者会高估使用者的实际贡献,进而造成权益不平衡和知识生产中过高的收益-投入比率,形成一种 “不劳而获”的现象。
其二,人工智能知识生产中最核心的资源是数据,如果把人工智能知识产品的产权完全归于使用者,那么数据生产者的权益就被忽视了。例如在网络购物中,互联网数据的获得仍然具有 “绑架”性质,消费者只是自愿地在网络平台中购物,但却不自愿被平台 “搜集数据” “存储数据” “分析数据”,作为数据的生产者,其数据权力完全被漠视了,消费者只能为了能够进行网络购物而不得不妥协。
其三,许多人工智能知识产品是在人的知识产品基础之上生成的模仿产品,这使得如果将人工智能知识产品归属于使用者会构成对被模仿人知识产品的侵权。例如,巴黎索尼计算机科学实验室使用巴赫的歌曲训练人工智能系统,所生成的作品具有鲜明的巴赫风格,而且达到了以假乱真的程度,专业音乐家都分辨不出人工智能的歌曲并不是巴赫的歌曲。显然,人工智能学习了人类作品的风格,所创作的作品很难判定为抄袭,而更像是对先有作品的演绎。因此,人工智能知识产品应该视为演绎作品,其权力归属按照演绎作品制度处理[10]。可以看出,人工智能的知识产权问题非常复杂,对原知识产权法律体系的逻辑自洽构成极大挑战,需要对人工智能知识产权进行细分规定。
4 总结与建议
本文分析了新一代人工智能和人脑知识生产的比较优势,以及人工智能知识生产所带来的理解困境、权力弱化、缺乏约束、数据垄断和产权不明等问题。人工智能区别于一般技术的最大特征就是其能够自动化地生产知识,知识生产最能够体现人工智能 “智”的方面,新一代人工智能带动了数据驱动知识生产的新范式,既提升了知识生产的效率,也带来了新的问题。无论人们欢欣抑或踟蹰,人工智能时代已经向我们走来,技术的井喷式发展和法律的滞后性造成了目前人工智能 “无法可依”的局面[11]。总体上,现代社会在享受人工智能的技术红利之时也需要谨慎人工智能带来的问题,真正 “用好”人工智能可以从以下三方面着手:
其一,建立人工智能知识产权的分级共享机制。人工智能知识生产的三要素是数据、算法和硬件,这使得在人工智能知识生产过程中总共有三个利益相关者,分别为数据生产者、程序设计者、程序使用者。由于人工智能程序本身并不具有法律主体地位,因此,人工智能知识产权一定归属于某个或某些利益相关者。人工智能知识生产是多主体的协同过程,如果把人工智能知识产品的产权仅归属于某一个利益相关者,就难以发挥知识产权激励创新的作用,可以按照人工智能程序知识生产的自动化程度划分不同的等级,不同等级下人工智能知识产权的分配比率不同,通过分级共享机制让数据生产者、程序设计者和程序使用者获得与贡献相匹配的产权比率。
其二,加强人工智能知识生产的可靠性评估和标准建设。由于人工智能知识生产过程的黑箱化和知识生产结果的不可理解性,人工智能知识产品的可靠性、歧视性和安全性都存在疑问且难以控制。人工智能标准建设既可以强化人工智能的可靠性和质量,又可以降低人工智能检测评估的成本。2019年美国国家标准与技术研究院发布了 《人工智能标准制定计划》,强调人工智能的安全风险和伦理标准。2020年中国国家标准化管理委员会发布了 《国家新一代人工智能标准体系建设指南》,同样强调了人工智能的安全和伦理标准。但是,截至目前中美都尚未制定出明确的人工智能标准体系。
其三,加强人工智能的跨学科合作和领域交叉人才的培养。人工智能知识生产问题的解决有赖于人工智能、法学等多领域的知识,而人工智能学家 “法盲”、法学家 “技术盲”使得他们必须要跨界合作,更好的方法是培养兼具法学和人工智能技术知识的跨学科专业人才。目前西南政法大学等高校已经建设了人工智能法学院,设置了人工智能法学二级学科,随着人工智能技术的不断扩散,人工智能法学人才的需求将不断增加,会有更多的高校加强人工智能法学交叉人才的培养工作,当前人工智能的法律困境也许会由新型交叉人才破解。
猜你喜欢
学苑创造·A版(2022年3期)2022-03-29 19:48:53
商界(2019年12期)2019-01-03 06:59:05
IT经理世界(2018年20期)2018-10-24 02:38:24
初中生世界·七年级(2017年5期)2017-06-10 01:45:22
小康(2017年16期)2017-06-07 09:00:59
领导决策信息(2017年9期)2017-05-04 04:04:50
知识产权(2016年5期)2016-12-01 06:58:32
南风窗(2016年19期)2016-09-21 16:51:29
学生天地(2016年20期)2016-05-17 05:46:44
中国当代医药(2015年9期)2015-03-01 02:02:00
