
非结构化大数据云存储稳定性优化评定
2021-11-17 07:36甯佐斌阳广元
计算机仿真 2021年6期
甯佐斌,阳广元
(西南民族大学,四川 成都 610041)
1 引言
诸如网络搜索、电子邮件、微博共享以及视频上传等新数据,正以指数倍级别的速度迅速增长,如何便捷、稳定地完成数据存储,日益成为各相关领域的热点研究问题之一。当前存储形式效率低、稳定性差,无法满足越来越高的用户需求,故高效智能、稳定安全的云存储[1]形式应运而生,作为从云计算概念[2]引申、发展出来的新型策略,云存储技术的核心理念是利用分布式系统、网络以及集群等多项技术,集合分布在网络里不同方位的多类型存储设备,采用软件管理手段令存储设备共同完成业务访问、数据存储等任务。简而言之,云存储就是把用户存储的数据缓存在云端里,让用户能够在云端任意存取数据,但实现的前提条件是将云端与用户的联网设备连接起来。
综上所述,本文对非结构化大数据云存储稳定性优化评定展开研究,通过最小化home节点与系统中所有节点的总距离差值,最小化非结构化大数据的存储能量消耗,使云存储系统运行更加平稳;优化云存储系统中所有子区域的内部存储,提升云存储稳定性;利用粒度率控制数据弹性,降低存储空间占用率,提升存储稳定性与流畅度。
2 非结构化大数据云存储稳定性优化
为优化非结构化大数据云存储的稳定性,分别从并行处理与安全容错两个方面进行提升。
2.1 并行处理
假设home节点的坐标方位为(x,y),在非结构化大数据云存储系统中随机选取一个节点,其二维坐标为(xi,yi),网络分布圆形范围的半径是R,通过最小化home节点与系统中所有节点的总距离D(x,y)差值,来最小化非结构化大数据的存储能量消耗,使云存储系统运行更加平稳。则home节点与系统中所有节点的总距离D(x,y)表达式如下所示
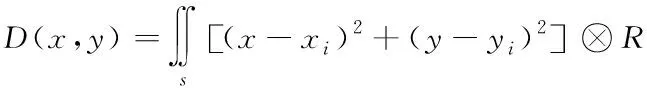
(1)
将第i环的活动时间设定为ti,云存储系统在该时段中把所有生成的大数据传输至第i环中的任意节点上,完成存储操作。假定活动环以外Ci中存在任意节点n1与n2,当其中一个节点发现有数据需要存储时,该节点将沿着系统中心与自身的连线轨迹,将大数据传输至当前活动环内,当数据包在活动环中与任意节点n3或者n4相遇后,云存储操作才得以实现,数学描述如下列表达式
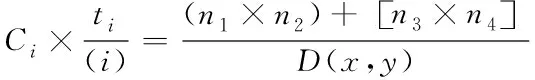
(2)
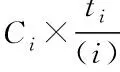
云存储系统中大数据存储位置的发生概率具有均等性,故大数据在ti时段中能够被均匀储存于活动环中的每个节点上。
根据环的大数据存储协议,云存储系统的节点状态仅含有非活动与活动状态,所以,可利用此状态组成存储能量消耗,不同消耗能量的计算方法描述如下:
1)若i-1,…,2,1环属于活动状态,环i将为活动状态的环提供存储与查询信息,假定(t1+t2+…+ti-1)为环i输送查询与存储信息所用的时间总和,那么,环i输送信息过程中所消耗的能量计算公式如下所示
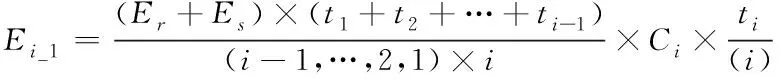
(3)
式中,Er为i环映射至活动环中的存储与查询轨迹,Es为非结构化大数据进行云存储时的映射弧长。
2)下列表达式为环i属于非活动状态时的总消耗能量计算公式
Ei_inactive=Ei_1+Ei_3
(4)
式中,Ei_3为各节点的初始能量。
3)若环i为活动状态,则云存储消耗能量的计算公式如下所示

(5)
式中,Si为云存储系统的平均密度,S为环宽度。
4)下列表达式为求解环i处于活动状态下的整体消耗能量计算公式
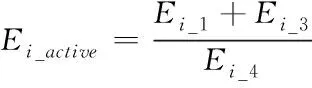
(6)
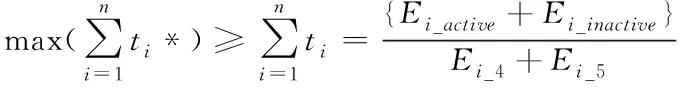
(7)
将优化核心设定为上式得到的云存储环活动时间,根据内部节点、边界节点的编号顺序,完成所有区域云存储平衡函数的并行架构,表达式如下所示
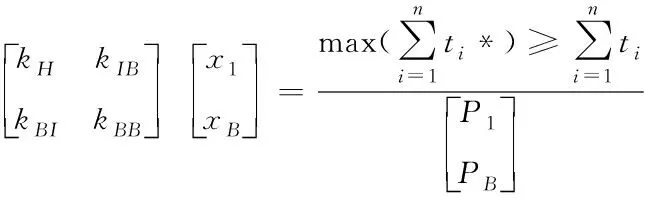
(8)
式中,x1、xB分别是云存储系统内部节点与边界节点的相应位移,P1、PB分别为各节点对应的外部荷载矢量,kH、kIB、kBI以及kBB分别表示系统刚度矩阵[3]分块矩阵则。
通过缩聚上式所有子区域,可并行去除云存储系统内部的自由度[4],构建仅存有边界自由度未知量的界面函数方程,如下所示

(9)
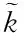
根据解得的节点边界自由度,采用下列表达式完成云存储系统中所有子区域的内部存储优化,提升云存储稳定性
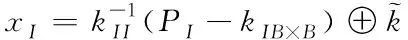
(10)
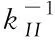
2.2 安全容错
依据非结构化大数据的存储形式,制定以下约束条件,进一步优化云存储系统的稳定性:
1)令整个数据存储中的数据流动性呈透明状态,即最终数据存储节点不关注中间数据传输链路,将云特性赋予整个中间链路;
2)非结构化大数据网络中没有固定的控制中心,所以,只有经过数据库检索,才能完成数据调度时的传输与存储;
3)当数据存储的任意中继节点[7]失效时,均可以通过剩余中继节点接力完成数据存储。
综上所述,云存储时的数据容错性能可以有效提升其稳定性,云存储容错程度的表达式如下所示
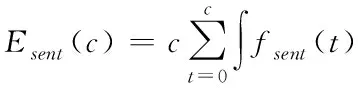
(11)
式中,c为存储数据量,fsent(t)为传输映射函数。
通过上式可以看出,关于非结构化大数据的云存储传输链路,整体的存储容错系数有诸多影响因素。
在存储节点接收存储请求后,云存储则表现为不间断请求状态,利用下列各式求取存储梯度[8]与存储强度[9]指数,若结果符合式(17),则完成数据存储;否则,对下列各式展开迭代操作。假设Π(x)是非结构化大数据的利用概率,且利用概率期望值EΠ(x)与弹性期望值E[T(x)]互为倒数,则
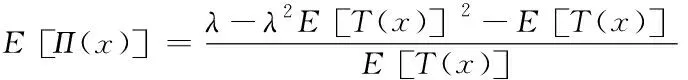
(12)
式中,λ为服从指数。若得到的期望值是负数,则存储拥塞与流程程度呈负相关,继续进行存储;若得到的是正数,控制存储质量,通过调控数据粒度提升稳定性。
由于流畅度与期望值呈反函数关系,故利用粒度率p控制数据弹性,降低存储空间占用率,提升存储稳定性与流畅度,表达式如下所示
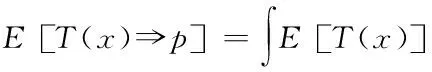
(13)
由上式设定当前存储接入粒度率仍为p,则下一时刻的数据弹性应符合下列等式关系
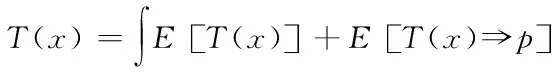
(14)
非结构化大数据云存储的点带宽具有一定的限制性,存储梯度能够高效覆盖数据弹性[10],因此,与随机时刻Δt对应的覆盖关系需符合下列等式关系
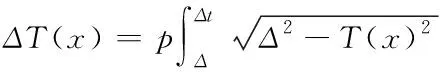
(15)
由上式推导出云存储强度指数Δλ应满足的等式
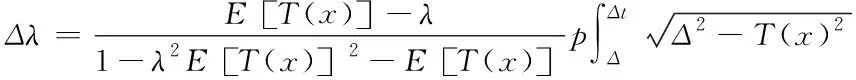
(16)
结合上列两式,令大数据存储梯度与弹性满足下列表达式,完成数据云存储与稳定性优化
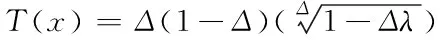
(17)
3 实验结果分析
3.1 实验环境及参数
为有效评定本文方法的优化效果,共设定三个实验环境,基于不同环境的相同条件,将云存储吞吐量、丢包率与平均占用率作为稳定性优化的评定指标,展开优化前与优化后的效果评定仿真。模拟环境的具体情况如下表1所示。

表1 模拟环境具体设定情况
上表1中的低优先级样本权重与高优先级样本权重分别呈1到2与3到5的均匀分布。
假设最后状态概率ρm+N表示丢包率,则丢包率D与吞吐量γ的表达式分别如下所示:
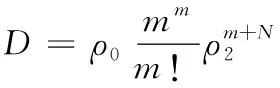
(18)
γ=λ1(1-D)
(19)
根据状态概率推导出下列平均占用率ν的表达式:
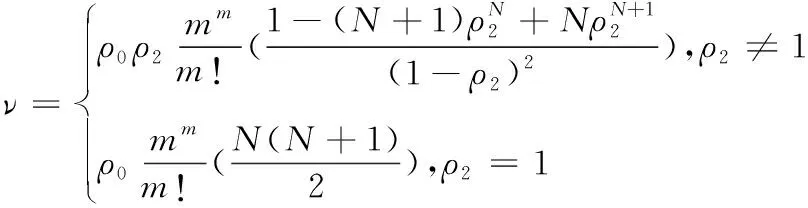
(20)
3.2 吞吐量评定分析
通过筛选处理10组实验数据,得到在同一请求到达率下的均值。图1所示为不同实验环境下,基于吞吐量的本文方法优化前后效果。
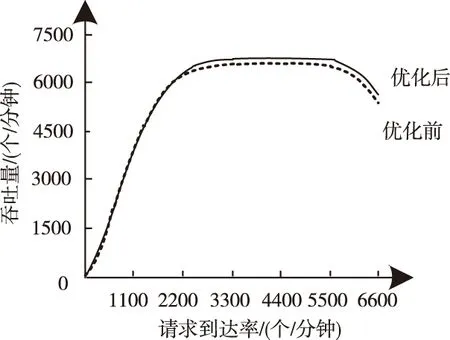
图1 基于环境1的优化前后吞吐量曲线图
从图1可以看出,当非结构化大数据的用户初始优先级较低时,优化前后差异不太明显,但由于对home节点与系统中所有节点的总距离差值做了最小化处理,所以,经本文方法优化后的云存储吞吐量性能仍略有提升。
从图2中曲线走势可知,在吞吐量到达峰值前,优化前后无明显差异,但当请求到达率增加至2400左右时,优化前后的吞吐量值开始出现差别,由于构建了不同活动状态下的消耗能量计算形式,故优化后的吞吐量值始终处于较高位置,在请求到达率约为5600时,优化前吞吐量值呈下降趋势,而优化后吞吐量值则在请求到达率是6300左右时才开始下降,且降幅相对平缓。
这话对何北来说还是比较有效的,何守四给了他一套房单住,他有条件跟老爸保持一定的空间距离,尽量不让老爸惦记他,想起他,至于谁吃他老爸他不管,但他最怕最烦老爸数叨他。听了何西这话,他决心保守这秘密了。可怀里揣着这么大的秘密不告诉个人,他有点寝食难安。所以,从医院出来,他开车把何西在家门口放下,第一件事他就是给唐娇打电话,把这事传了出去,才踏实下来。
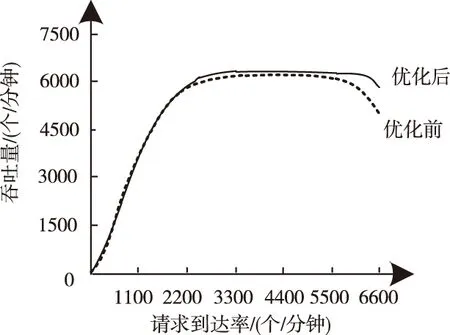
图2 基于环境2的优化前后吞吐量曲线图
根据图3所示的优化前后吞吐量曲线图,发现出现差异的请求到达率值并没有发生太大变化,仍为2400左右,且优化前吞吐量的下降点仍是5600请求到达率,但降幅有明显增加,而经过本文方法优化的吞吐量指标因并行架构了所有区域云存储平衡函数,故在请求到达率约为7800时才呈现下降趋势,且降幅相对平缓。这说明当初始优先级较高时,本文方法的吞吐量展现出了更强的优势。
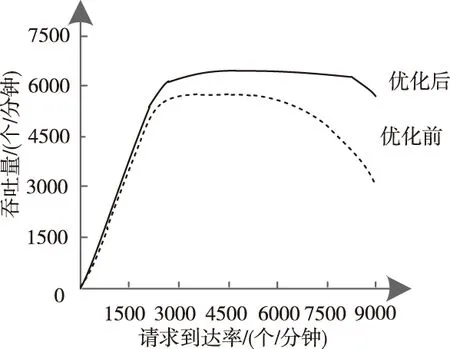
图3 基于环境3的优化前后吞吐量曲线图
3.3 丢包率评定分析
基于不同环境的相同条件,优化前后的丢包率实验结果分别如图4所示。
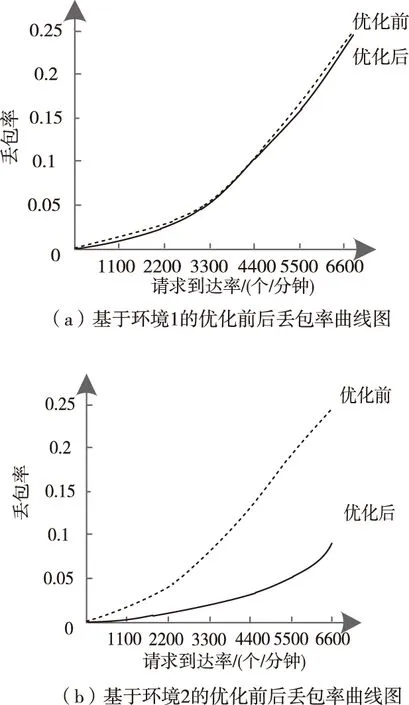
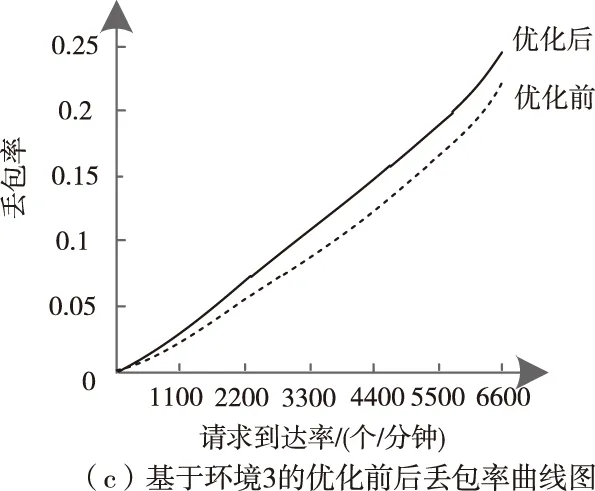
图4 优化前后丢包率实验结果
从图4(a)中的曲线走势与吞吐量的初始优先级较低情况相似,优化前后无太大差异性,但因为缩聚了云存储的所有子区域,去除了内部的自由度,经本文方法优化后的云存储丢包率性能仍略有提升;根据图4(b)所示,在丢包率突增前优化前后的丢包率均小于0.05,当请求到达率约为2400时,优化前丢包率增至0.05,并呈不断上升趋势,而在请求到达率约为5600时,经本文方法优化的丢包率才刚增加到0.05,尽管随着请求到达率的增加,两种趋势均在升高,但优化后的丢包率一直低于优化前数值,且增幅比较缓慢;通过图4(c)可知,在请求到达率为2400左右时,两种丢包率数据均大于0.05,随着请求到达率的不断递增,优化后丢包率一直高于优化前数据,这说明当初始优先级较高时,可以通过放弃丢包率指标来保证云存储的稳定性。
3.4 平均占用率评定分析
在相同条件下的三个不同预设环境中,模拟优化前后的平均占用率性能,实验结果如图5所示。
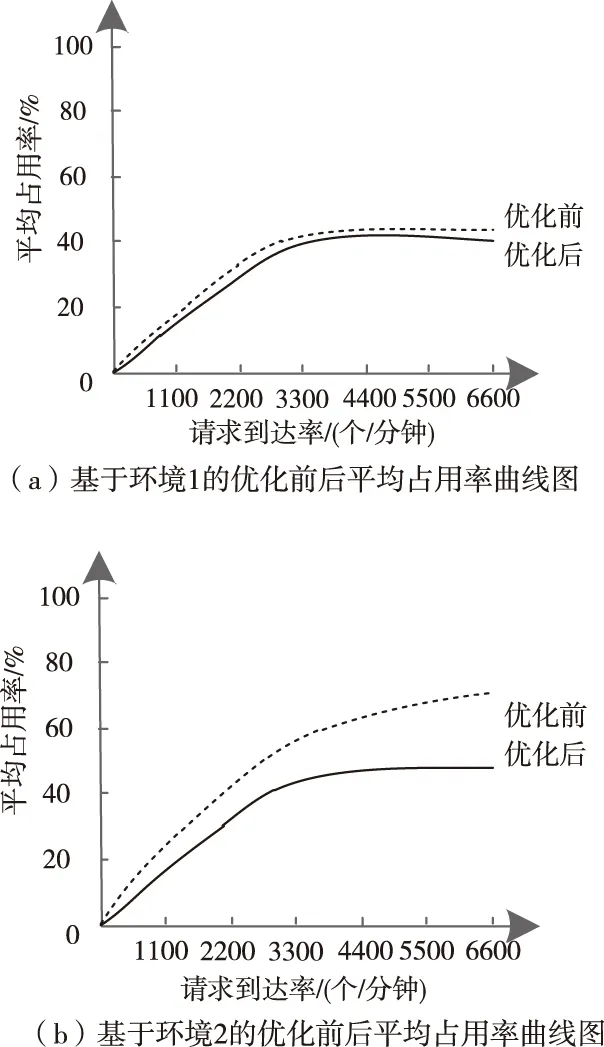

图5 优化前后平均占用率实验结果
从图5(a)中曲线走势可知,初始优先级较低情况下的优化前后平均占用率差异较小,无明显区别;根据图5(b)可以看出,请求到达率2900为平均占用率指标的拐点,两趋势均呈线性增长趋势,随着请求到达率的继续增长,优化前后的平均占用率逐渐拉开差距,后者因提升了大数据的云存储容错性能,故表现出显著的优越性;通过图5(c)能够发现,该环境下的优化后平均占用率较环境2更低,在请求到达率还未到达2900时,优化后趋势就已经趋于平稳,且始终大幅度低于优化前平均占用率。
4 结论
社会信息量的暴涨令存储量需求越来越高,这为云存储发展提供了一定的契机,使其演变为最快被接受的云服务形式之一,用户范围也从最初的互联网相关行业逐渐扩展至企业机构、个人用户等多种领域,服务规模的与日俱增为云存储系统的运营与维护带来了诸多挑战性问题,比如存储费用、存储安全性与稳定性等,因此,本文以非结构化大数据为背景,提出一种云存储稳定性优化方法,并对其展开评定。由于个人水平与研究条件存在局限性,故本文方法还有许多地方有待改进,并将以下方面作为后期工作的研究方向与重点:并行处理优化方法中的集群主节点仅有一个,若主节点发生异常,则云存储整个系统都将停止运行,故需要在所有节点上赋予主节点功能,并根据集群动态选取主节点;扩展稳定性优化切入点,积极探索可以进一步提升稳定性的其它方向;从非结构化大数据云存储平台向更多云存储平台延伸,并在真正的云存储环境中进行实践。
猜你喜欢
初中生世界·九年级(2020年12期)2020-03-10
发明与创新·大科技(2019年12期)2019-03-17
传播与制作(2018年9期)2018-11-15
集装箱化(2017年4期)2017-05-17
集装箱化(2016年11期)2017-03-29
集装箱化(2016年12期)2017-03-20
初中生之友·中旬刊(2015年4期)2015-06-10
集装箱化(2014年2期)2014-03-15
商(2012年11期)2012-07-09
中学生数理化·八年级数学华师大版(2008年1期)2008-08-19
