
海量不确定数据集中离群点快速检测方法仿真
2021-11-17 07:37林雪
计算机仿真 2021年6期
林 雪
(重庆师范大学涉外商贸学院,重庆 合川 401520)
1 引言
离散点检测作为数据挖掘中的一项重要技术,可为了解、分析数据提供参考和研究基础,被广泛应用于检测网络异常事件、物体监测等方面,可有效避免或降低不必要的数据损失[1],避免对结果造成影响。因此,离散点检测技术的研究得到广泛关注。现阶段离散点检测技术主要应用于传统数据库中,虽然存在一定的可信性,但在实际收集和处理数据的过程上会受到诸多因素的影响,数据的不确定性会降低检测速度和检测准确性。相关研究人员对此展开深入研究,试图在提高检测效率的同时,降低计算复杂程度。
曹科研等[2]人提出基于密度的局部异常检测中,根据不确定数据模型的异常点定义进行数据集局部检测。在无法精确计算概率的情况下,通过估计局部异常点因子检测算法(PUDOL),降低计算复杂程度。仿真证明该方法在计算能力方面性能较强,但检测精度较低。朱树才等[3]人针对实际系统中采集的数据流具有不确定性的问题,根据滑动基本窗口采样(Sliding basic window sampling,SBWS)算法以及高斯过程回归(Gaussian process regression,GPR)模型特征,提出了基于SBWS—GPR预测模型的不确定性多数据流的异常检测方法。在时间序列收集的历史数据集中,引入索引号进行聚类,分析数据集与索引号间的映射关系,通过滑动窗口实时匹配离散点,完成对单数据流的离散点检测。该方法经过实验验证,具有较高的检测精度,但检测速度无法达到标准。
由于上述传统方法无法确保检测精度,且检测速度慢、计算复杂度高,因此,提出一种新的海量不确定数据集中离群点快速检测方法。首先确定出不确定数据集中的离群点,通过OPTICS算法,计算出离群属性,再引入邻域密度,构建快速监测模型,充分考虑不确定数据集中离散点的确认,以确保离散点的检测精度,从而实现离群点的快速准确的检测。
本文所提出的方法会将数据挖掘和预处理的工作简化,为后续的研究提供准确的数据支持。
2 不确定数据集中离群点判定
在不确定数据集中,与样本点行为特征不一致的点,称为离群点。对其进行判定,要确保数据集中的离群点检测样本不会被误删,同时保证不确定数据集中离群点检测的精准度,针对不确定数据集中离群点判定过程如下:
假设数据集中待处理点表示为Q={qj|qj∈R3,j=1,2,…,M},代表需进行计算和处理的期望点为P={pi|pi∈R3,i=1,2,…,n},使用F表示期望点集的特征,O={oi|oi∈R3,i=1,2,…,m}则被看作点集Q的离群点,需满足下列条件:
1)当Q=P∪O时,数据集中任意一点均可被看作离群点;
2)当P∩O=∅时,离群点与内点无任何交集,其中一点属于离群点或者内点;
3)当P(F(pi))=TRUE时,通常数据集中的期望点集的行为特征具有一致性;
4)当∃D(Q)=D(P)时,D(x)表示适当观测数据,对Q与P的特征期望相同。
检测数据集中离群点的云数据可尽量降低测量误差等因素造成的数据错误,更加接近实际数值,提升了不确定数据集中离群点提取、计算、重构、可视化程度等的准确性及有效程度。
如表1所示,为初始数据集经过处理后得到的不确定数据集,用于描述概率维度对离群点检测的影响。Tuple用于表示不确定数据集中的标识,Value-1和Value-2代表其中的两种属性,Conf用于表示可信程度。
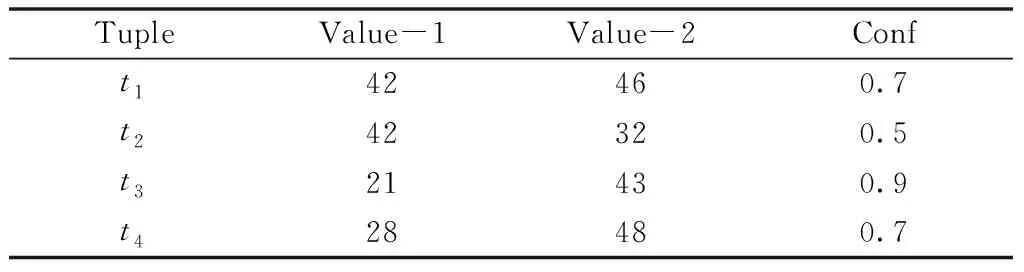
表1 不确定数据集
与判断确定数据集中离群点不同,在海量不确定数据集中,判断离群点需采用可能世界模型,其原理是将检测对象开展成为多个可能世界,再根据相关参数判断是否在数量阈值范围内,并对数据集中离散点进行逐个判定。
如表2所示,为检测对象t1数据集内所有构成可能世界部分的实例,假设t1范围参数设为d=20,相邻数据阈值离群点检测设k=2,在前5项数据中,t1的相邻数据小于k,在后续数据中,不小于k。因此可看出,仅依据范围参数和数量阈值无法判定得到的检测结果是否为离群点,一定要计算被测对象是否为离群点的可能性,作为判定海量不确定数据中离群点的重要依据。

表2 构成的可能事件及概率
假设数据集中的点分别独立,此时可得
p(w0)=(1-P)×(1-Q)×(1-O)×d
(1)
p(w0)表示离群点w0出现概率值,由表2可知,所有数据概率和不超过1.5,若t1符合检测要求,则t1为离群点。由此可看出,在进行海量不确定数据离群点检测时,不仅需要参数和数量阈值,同时还需获取到概率阈值。经过上述步骤,可准确判定出待检测的离群点。
3 离群点快速检测
3.1 局部待检测离群点定位
要实现离群点的快速检测,提高检测速度,对局部待检测离群点进行定位至关重要。通常运用扫描方式检测不确定数据集[4]中离群点,但由于密度误差导致检测速度过慢。在不确定数据集中每个点都包含了一定的信息向量,密集区域点的信息量大,而离群点属于无用的信息,去空间分布较小,信息含量少,因此,可设置适当倍数的标准差可作为判定离群点的阈值。
如图1所示,海量不确定数据集中有2个较为明显的簇群,现假设C1代表包含离群点的内点簇群,C2表示正常内点簇群,O1及O2均为离群点,采用任意检测方法,当阈值过大时,仅O1为正确的离群点,O2则被看作内点;当阈值较小时,O1、O2、C1经检测均为离群点。

图1 大量不确定数据集中局部离群点
传统离群点检测方式需要自行设置判定阈值,该阈值数据为整体判定阈值,随机可能性大,对检测结果会产生很大影响,误差较大[5]。同理,固定阈值判定检测方法对密集数据点的适应性较差,将不均匀特征考虑其中,在判断海量大数据集中离群点时进行调整,从而提高检测速度。
3.2 离群属性计算
针对海量不确定数据,对局部离群点的定位具有片面性及局限性,还需对立群属性进行计算。离群点通常仅在数据集中占据一小部分,为了提高计算速度,在确保检测结果准确程度的同时,还可降低检测算法的计算量,需使用OPTICS算法完成对初始数据的聚类,通过构建的数据集排序表示数据结构[6]。
在海量数据集中,所占比例较小的离群数据使整体数据集的不确定性增大,根据从数据集中判定出的离群点及不同离群对象与属性的权值关系[7],来提高离群点检测的准确程度。
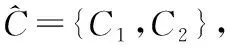
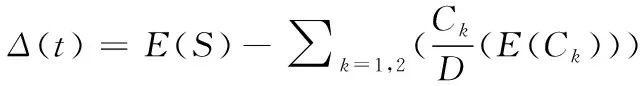
(2)
式中,Δ(t)为S被分解成D前后信息的变化,该部分减少的数值就是数据集S中被删除的不确定性,可知,当Δ(t)数值变大时,说明对象t从数据集S中分解删除后,海量不确定数据集中的“混乱”信息的减少也在增大。
当进行LCOF数值计算时,在利用信息熵的基础上,使用加权距离反映出不同属性对数据集中离群点的影响[9],以此提升检测速度。在数据集D中选取两个数据对象,使用p和q表示,设p在属性ai的数值为fai(p),则可得到数据对象p和q的加权值表达式为
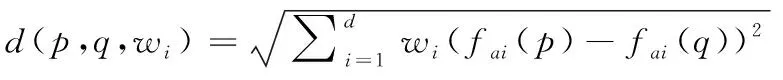
(3)
其中,wi表示数据对象p在i维中的权值,如果维度i不是离群属性,此时wi取值为1。
3.3 离群点快速检测模型构建
结合上述离群属性的计算结果,通过查询数据集中各点与领域点集间的距离[10],对统计结果进行检测。首先,需计算出查询点与邻域点集k的距离平均值,以及整体距离的平均值。然后,计算全部点与其域点集k的距离标准差[11]值。最后,设置一个标准差阈值,用于检测判定的离群点。
在海量不确定大数据集中,选取任意两点pi和pj,其坐标值分别表示为(xi,yi,zi)和(xj,yj,zj),其欧式距离可表示为


(4)
根据式(4),可得知点pi与其邻域点集k的平均距离可表示为


(5)
结合式(5)计算结果,则海量不确定数据集中存在n个点时,可得出各点与其邻域点集k的平均距离数值,表示为
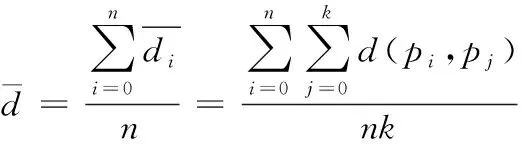
(6)
则海量不确定数据集中的邻域点集k的方差表现形式为
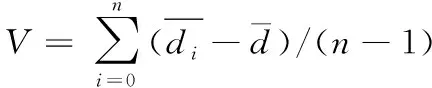
(7)
将式(6)所得结果代入式(7)中,可得:

(8)
因此,结合式(8),可求得海量不确定数据集中所有点的邻域点集k距离整体的标准差值δ,其方程为
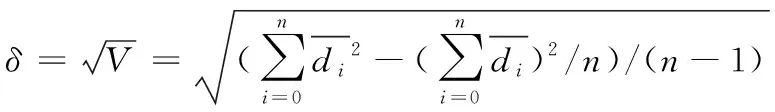
(9)
根据离散点判定原理,在一定条件下,如海量不确定随机变量以正态形式分布,与剩余概率的分布形式近似[12]。因此可判定本组数据满足正态分布条件。在需检测的海量不确定数据集中,随机一点pi的邻域点k为海量分布向量。
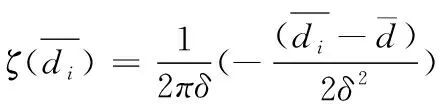
(10)
其中,δ表示标准差。
从图2可看出其分布曲线。

图2 数据集中邻域点k分布曲线
在海量不确定数据集中,内点集和离群点集在密度上存在较大的差距。将邻域点k的密度特征作为检测离群点的重要指标,运用对邻域密度特征进行动态调整,通过标准差阈值完成离群点的检测。因此,可看出在海量不确定数据集中,邻域密度直接影响离群点的检测结果。
综上所述,完成了海量不确定数据集中离群点快速检测方法。
4 仿真研究
针对海量不确定数据集离群点快速检测方法的有效性,使用基于邻域密度构建的检测模型,与传统方法进行对比实验验证,利用(up,ud,λ)离群点参数进行检测,同时海量不确定数据集要符合一定的函数分布规律。本次仿真使用Matlab构成数据,将其固定长度为1000*1000的矩形区域内,分布顺序根据不同的实验需求决定,在不确定数据集中的数据点可信度范围为(0~1,0),大体上为均匀分布。
通过对离群属性的计算,构建基于邻域密度的快速检测模型,将离群点参数up设为0.9995,ud设为20.2,λ设为0.8。
如下图3所示为文献[2]方法、文献[3]方法和所提方法的检测算法参数运行时间,随着ud数据量增大,所用时间也增加,对比三种不同方法的检测运算参数运行时间,得到对比结果如图3所示。
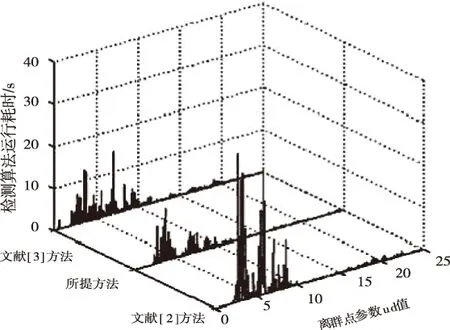
图3 三种不同方法的检测运算参数运行时间
分析图3结果可知,文献[2]方法的检测算法运行耗时平均约为22s,当参数ud的值为3.5时,出现最大耗时为30s;文献[3]方法的检测算法运行耗时平均约为10s,当参数ud的值为7.5时,出现最大耗时为17s;所提方法的检测算法运行耗时平均约为5s,当参数ud的值为5时,出现最大耗时为10s;对比三种方法的实验结果可得,所提方法的运行时间最短,更具优越性。
在对海量不确定数据离群点进行检测时,如图4不确定数据集所示,两条包含10个数据点的倾斜线相交于x轴原点a,b为其中一点,c为斜线至原点最远的点。可直观地看出点a和点c具有一定的分布模式,离群概率最高为点b。

图4 不确定数据集
基于图4海量不确定数据集,设置初始实验数据为15万、25万、45万、和65万。所提方法在数据集中直接进行计算,判断离群点区域后,采取代表点以及增量数据进行数值计算,从而判断是否为离群点。图5记录了文献[2]方法、文献[3]方法与所提检测方法的离群点判定准确度。

图5 三种不同方法的离群点判定耗时对比
根据图5得出,文献[2]方法无法判定出离群点,文献[3]方法可以判定出离群点,但判定准确度较低,而所提方法能够准确的判定出离群点,判定准确度较高。
漏检点和误检点是直接影响检测精度的两个重要指标,对文献[2]方法、文献[3]方法与所提检测方法的漏检点和误检点进行测试,得到三种不同方法的检测精度对比结果如表3所示。

表3 三种不同方法的检测精度对比
由上述表3的实验结果可看出,三种不同方法的检出离群点个数相差不大,文献[2]方法的漏检点约为200个,误检点约为41个;文献[3]方法的漏检点约为310个,误检点约为28个;所提方法的漏检点约为12个,误检点约为3个。对比结果可以得出,所提方法的漏检点和误检点远远小于文献[2]方法和文献[3]方法的漏检点和误检点,说明所提方法的检测精度最高。
由仿真结果表明,本文提出的方法在离群点检测时间、准确性及漏检误检方面的优势非常显著,本方法具有应用意义。
5 结论
在数据挖掘与数据预处理等领域,离散点检测具有关键作用被高度重视。提出的海量不确定数据集中离散点快速检测方法,对离散点进行优先判定,使用OPTICS算法进行离群属性的计算,并结合数据集中邻域点范围,完成速检测模型构建。通过与传统两种检测方法进行对比仿真,得到结果表明,在相同参数情况下,所提方法无论在算法运行时间上,还是在检测精度上,都更具优越性,实现了海量不确定数据离群点的快速、准确的检测。本方法为数据挖掘与数据预处理等领域提供了切实有效的处理方法,提高了数据处理的效率,数据的准确性及完整性保证了后续研究的有效性,在实际工作中可被广泛应用,具有一定的参考价值。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
农业工程学报(2022年7期)2022-07-09
计算技术与自动化(2022年1期)2022-04-15
导航定位学报(2022年2期)2022-04-11
当代陕西(2019年14期)2019-08-26
电子技术与软件工程(2019年8期)2019-07-16
意林(2019年11期)2019-06-30
诗选刊(2018年7期)2018-07-09
阅读(中年级)(2016年4期)2016-11-19
中学数学杂志(初中版)(2016年5期)2016-11-01
