
基于迁移学习的胶囊内镜图像分类
2021-11-17 08:37梁立媛吉晓东李文华
计算机仿真 2021年6期
梁立媛,吉晓东,2*,李文华,3
(1. 南通大学信息科学技术学院,江苏 南通 226019;2. 南通先进通信技术研究院,江苏 南通 226019;3. 江苏文络电子科技有限公司,江苏 南通 226019)
1 引言
消化道疾病[1],如出血、肿瘤和溃疡等,已成为一种高发病症并严重的危害人们的健康和生活质量。作为一种新型的消化道疾病检查技术,胶囊内镜[2,3](Wireless capsule endoscope,WCE)与传统的插入式消化道内镜相比,具有无创伤、安全、可全程检测等优越性能。医生通过系统传回的图像来诊断患者是否患病,然而,胶囊内镜自口至肛门的过程耗费6-8小时,检查过程产生的图片量高达43200-57600张[4],医生逐张诊断的方式耗时长,且极易使人疲劳、漏掉有用的信息,难于应对较大的检查量。因此,找到一种对胶囊内镜图像有良好分类效果的计算机辅助分析方法尤为重要。
目前,胶囊内镜图像的分类算法主要分为两类。一类是传统的基于图像特征提取的机器学习分类方法。设计者提取图像的颜色[5]、纹理[6]和统计特征[7],并通过支持向量机(Support Vector Machine, SVM)[4,8]、K-近邻(k-nearest neighbor,KNN)[6,7]等进行分类,受主观因素影响较大,极易漏掉有价值的信息。一类是采用卷积神经网络(Convolutional neural network, CNN)的分类方法。作为一种端到端的学习方法[9],卷积神经网络对输入的图像进行参数优化,在输出层给出所在分类,相比传统分类方法拥有更强的自动学习特征的能力。然而,设计一个有良好分类效果的卷积神经网络需要大量的数据优化网络中的参数。针对胶囊内镜图像数据量少的问题,本文提出一种基于迁移学习的胶囊内镜图像分类算法。首先对WCE图像进行预处理和数据扩增;接着,采用Alexnet、Googlenet、Inception-v3网络提取WCE图像的深层特征。最后,合并提取到的3个模型的特征向量并输入到SVM进行训练和分类。实验证明,相比手动提取特征的方法和构建卷积神经网络的方法,本文提出的方法具有更好的分类性能。
2 方法基本框架
本文所提方法的流程如图1所示。

图1 本文方法流程图
本文所提方法主要包括4个部分:1)数据预处理:WCE图像含有噪声,首先,对WCE图像进行真彩色增强及中值滤波去除噪声,改善图像质量。2)数据扩增:WCE数据集相对较小且存在健康、病变图像类别不均衡的问题。仿射变换方法增大样本,平衡健康、病变类别。3)迁移学习:CNN模型训练所需的参数量巨大,直接训练,易过拟合,因此采用ImageNet 数据预初始化Alexnet、Googlenet、 Inception-v3网络的模型参数。4)训练及分类:利用预初始化后的3个卷积网络提取囊内镜图像的深层特征并加以融合,作为SVM的输入进行训练和分类。
3 图像特征提取及分类算法设计
本文数据库由杭州华冲科技有限公司提供,包含分辨率为480*480的bmp格式胶囊内镜临床图像共1251张,其中病变图像135张,健康图像1116张,病变图像远小于健康图像,需要对数据进行扩增。图2给出了部分图像, (a)(b)为健康图像,(c)(d)病变图像。
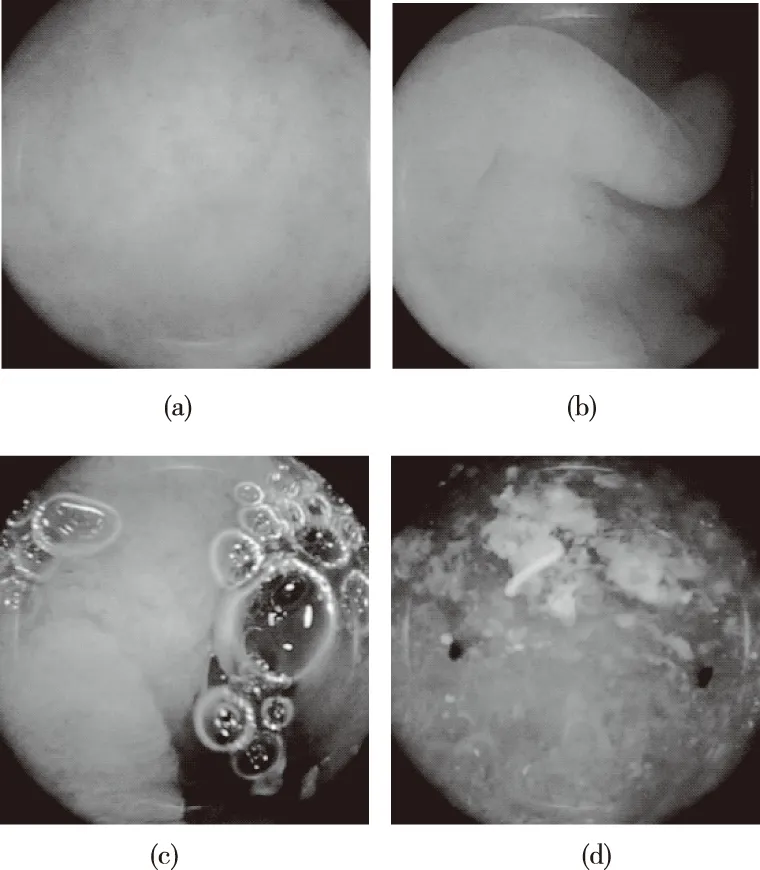
图2 健康与病变图像示例
3.1 数据预处理和数据扩增
由于胶囊内镜本身的CMOS摄像头聚焦不准,光学遮光罩受消化液污染,电源供电不足等限制,获得的WCE图像存在亮度低,受噪声污染的问题。针对WCE图像的自身特点,提出的预处理步骤如下。
1)真彩色增强:将图像由RGB(Red,Green,Blue)色彩空间转化到更符合人的视觉特性的HSI(Hue,Saturation,Intensity)空间。对S,I分量分别进行1.5、1.2倍的增强处理,并将处理后的H,S,I分量转换回RGB颜色空间。提升图像亮度,使边缘清晰,反差增强。图像RGB与HSI空间的转换算法如下:
算法1 RGB到HSI空间的转换
输入:R、G、B
输出:H、S、I
1)H∈[0°,120°]:
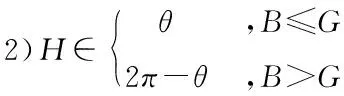
(注:S=0时,对应无色的中心点,H无意义,定义H=0;S=0时,对应黑色,H,S无意义,定义H=0,S=0)
2)中值滤波:用5×5的窗口对上面得到的图像的R,G,B分量进行中值滤波操作,去除噪声的同时保留边缘信息。
数据扩增用于解决数据集的类别不均衡和模型过拟合问题。采用仿射变换方法对数据集进行增强。主要通过将图像旋转 90°/180°/270°、裁剪、在水平和垂直方向作镜像,以及这些操作的组合操作将数据集1次扩增为原来的9倍,得到健康图像10044张,病变图像1215张。对1215张病变图像通过裁剪操作进行2次扩增为原来的8倍,得到9720张病变图像,与10044张健康图像数量均衡。
3.2 迁移学习
迁移学习[10]根据具体实现方法可分为:样本迁移、特征迁移、关系迁移和模型迁移,近年来,已经成为了卷积神经网络的发展趋势之一,它降低了CNN方法中对样本的要求,解决了传统机器学习方法中训练样本和测试样本必须独立同分布以及训练样本数目需求过大的问题[11]。本文在包含1000类,126万张自然图像的ImageNet 数据库上预初始化Alexnet、Googlenet、 Inception-v3的模型参数。自然图像与WCE图像不同但相关,采取迁移学习的方法可以在ImageNet 数据库上学到有助于WCE图像分类的如角点、边缘、颜色、纹理等特征,进而提高卷积神经网络在小样本的WCE图像上的分类性能。
3.2.1 Alexnet网络结构
Alexnet网络[12]在2012年ImageNet图像识别的比赛冠军,主要由5个卷积层,3个池化层,3个全连接层和softmax 层组成,基本网络结构如图3所示。
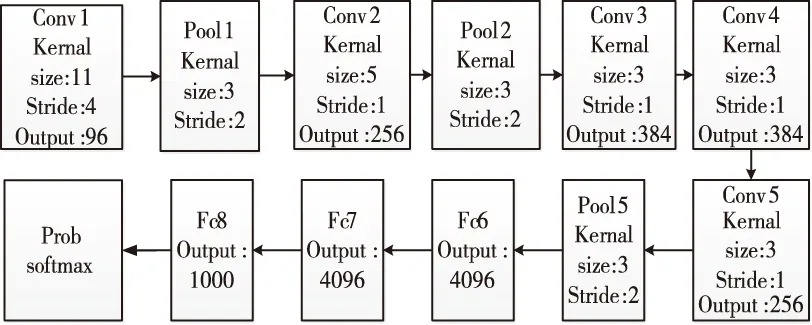
图3 Alexnet网络结构
3.2.2 Googlenet网络结构
Googlenet网络[13]主要包括2个普通卷积层、9个Inception层,3个池化层和softmax 层。模型通过 Inception结构,在增加网络宽度的同时,减少参数数量,降低计算复杂度。Googlenet基本网络结构如图4所示。
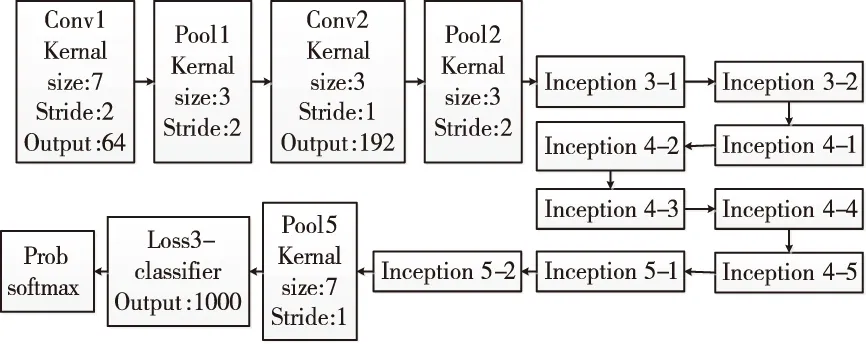
图4 Googlenet网络结构
3.2.3 Inception-v3网络结构
Inception-v3网络[14]由Google 2014年发布,模型中的Inception模块,在一个卷积层中同时选用多种较小尺寸的卷积核替换较大尺寸的卷积核,提取多种特征后合并到一起作为输出结果。Inception结构加入1×1卷积核实现降低特征维度,增强卷积操作的非线性表达能力的效果。Inception-v3基本网络结构如图5所示。
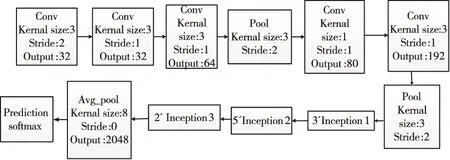
图5 Inception-v3网络结构
将3.1节得到的WCE数据输入到Alexnet、Googlenet、Inception-v3,输入数据时将图像尺寸调节成符合网络要求的227×227,224×224,299×299,提取Alexnet的“Fc7”层的4096维特征,Googlenet的“Loss-classifier”层的1000维特征,Inception-v3的“Ave_pool”层的2048维特征, 并将其合并为7144维的特征向量F。
F=[F1,F2,F3]
(1)
3.3 训练及分类
SVM[15]是由Vapnik等人运用统计学理论中的结构风险最小化准则和VC维理论提出的一种依赖核函数的机器学习分类算法,其原理是:寻找分类的最优超平面,使超平面两侧类别的边缘距离最大。样本集{(x1,y1),(x2,y2),…,(xn,yn)},分类函数为
f(x)=sgn(ω·x+b)
(2)
其中,ω是权值向量,b是偏移量。
依据结构风险最小化准则,等价为
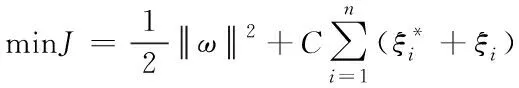
(3)
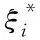
引入拉格朗日算子αi,分类阈值b*,最优分类函数为

(4)
样本集{(x1,y1),(x2,y2),…,(xn,yn)}线性不可分时,引入核函数K(xi·x)将样本转换到近似线性可分的空间,对应的最优分类函数为
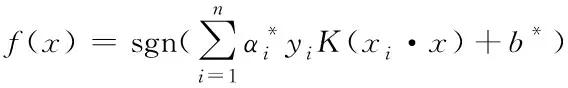
(5)
在SVM的训练阶段,利用2.2节得到的训练样本的7144维特征向量及对应的类别标签,选取径向基核函数对SVM分类器进行训练,得到用于后续分类的SVM分类器。径向基核函数的表达式如下[16]。
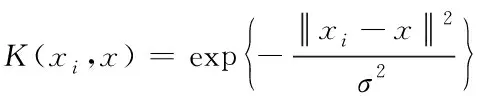
(6)
其中,σ为可调参数。
在SVM的分类阶段,将测试样本的特征向量输入到训练好的SVM分类器中进行分类识别。
4 实验
4.1 实验设置
本实验在Matlab 2018b下完成,实验硬件平台为:Intel(R)Xeon(R)Silver 4110处理器,32G内存,Nivida Quardo P2000显卡,5.032G显存。将增强后的数据集随机分成2部分:70%作为训练集用于训练SVM分类器,30%作为测试集用于测试模型的识别和泛化能力,训练与测试的数据互不交叉。为了对比不同方法对实验分类性能的影响,本文设置了4组实验。
实验1:为验证前期数据预处理和数据扩增的有效性,将增强前后的WCE图像数据均输入到Alexnet、Googlenet、Inception-v3进行对比实验。
实验2:为验证特征融合方法的有效性,分别选择提取Alexnet、Googlenet、Inception-v3对应的4096、1000和2048维特征和本文提出的特征融合方法作为对比。
实验3:为验证选择SVM作为分类器的有效性,本文选取随机森林(Random Forest,RF)、K近邻(K-nearest neighbor,KNN)和朴素贝叶斯(Naive Bayes,NB)3种分类器作为对比。
实验4:为验证本文方法的有效性,同现有其它方法的分类结果对比。
4.2 评价指标
对于医学图像的分类,可以从图像的分类准确率来判定该分类系统的性能。令TP表示被正确分类的病变图像,FP表示被错误分类的病变图像,TN表示被正确分类的健康图像,FN表示被错误分类的健康图像,本文使用敏感性(Sensitivity),特异性(Specificity)和准确率(Accuracy)作为方法的评价指标。
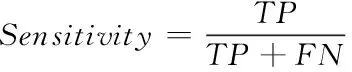
(7)
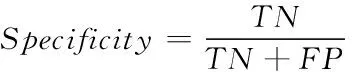
(8)
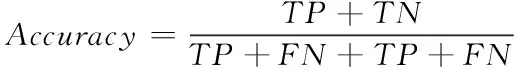
(9)
其中,敏感性Sensitivity,特异性Specificity和准确率Accuracy分别表示病变图像、健康图像以及总体WCE图像的分类准确率。
4.3 实验结果分析
4.3.1 第1组实验分析
实验1针对数据增强对实验结果的影响,采用增强前后的数据做了2组对比实验,实验结果如表1所示。从表1的实验结果可知,应用增强后的数据比原始数据的分类效果要好,说明在本文方法中,数据增强对于改善模型的分类效果是不可或缺的。
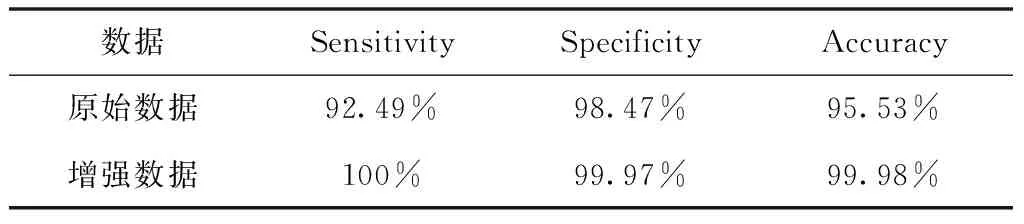
表1 数据增强前后的分类结果对比
4.3.2 第2组实验分析
对Alexnet、Googlenet、Inception-v3提取的特征进行合并是本文的贡献点之一。实验2对比了只提取单个网络的特征对分类性能的影响,结果如表2所示。从表2的实验结果可知,特征融合的方法更能有效的表示WCE图像的特征,因此提高分类的准确率。
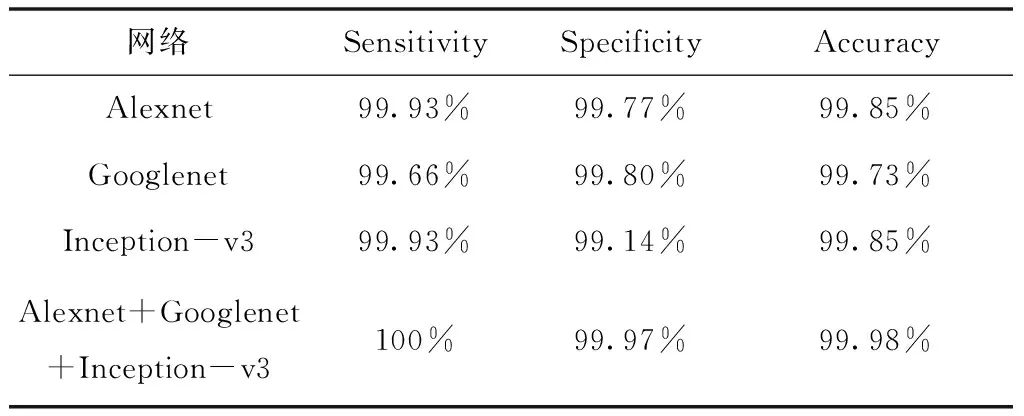
表2 迁移不同网络的分类结果对比
4.3.3 第3组实验分析
为了验证分类器对分类性能的影响,实验3对比了RF、KNN、NB、SVM 4个分类器,结果如表3所示,由表3可知,SVM在分类性能上表现最好。
4.3.4 第4组实验分析
实验4将本文方法同现存的图像分类方法进行对比,结果如表4所示。邓江洪[8]等人是根据特征的平均影响值对提取的颜色矩和灰度共生矩阵(Gray-level Co-occurrence Matrix)特征进行筛选,再用SVM进行分类。Xiuli Li[9]等人采用只增强病变图像,迁移Inception-v3网络并在网络最后添加1个全连接层的方法分类图像。由实验结果可知,本文方法在敏感性,特异性,准确率方面均高于其它2种方法,验证了本文方法的有效性。
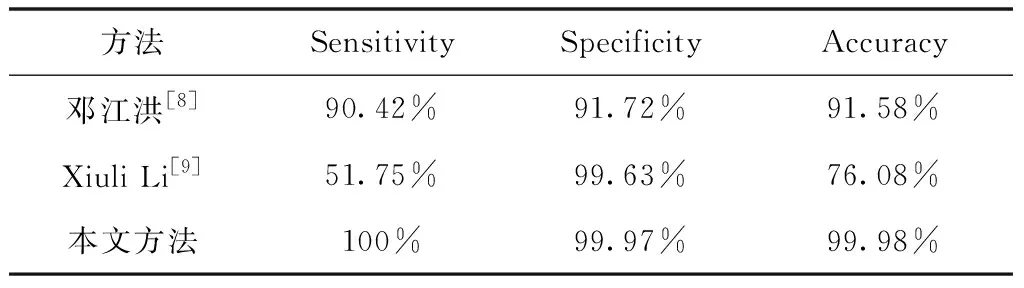
表4 本文方法与现有其它方法的分类结果对比
5 结论
为解决基于卷积神经网络的图像分类算法上存在的模型参数难以训练、易过拟合的问题,突破传统机器学习方法中训练样本和测试样本必须独立同分布的限制,本文提出一种结合迁移学习和SVM的方法,实现胶囊内镜图像的自动分类。在实验过程中,对胶囊内镜图像采取真彩色增强,中值滤波,数据扩增方法提升图像对比度、滤除噪声、平衡健康与病变图像数量。先用ImageNet 数据预初始化Alexnet、Googlenet、 Inception-v3网络,再基于迁移学习的思想,利用预初始化的3个网络提取胶囊内镜图像的深层特征并合并用于训练SVM分类器,实验结果表明,本文方法能够有效提取胶囊内镜图像的特征,提高分类准确率。
本文对胶囊内镜图像的分类仅为健康与病变两类。在今后的研究中,可以将病变图像细分为出血、肿瘤、溃疡等多个类别,尝试改进Alexnet、Googlenet、 Inception-v3的网络结构,进一步提高分类准确率。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
现代电子技术(2022年15期)2022-07-28
健康体检与管理(2022年4期)2022-05-13
中国典型病例大全(2022年12期)2022-05-13
电子产品世界(2022年4期)2022-04-21
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
现代仪器与医疗(2021年1期)2021-06-09
健康之家(2021年19期)2021-05-23
