
无线协作中继网络多层不良数据辨识方法
2021-11-17 07:35周莉,闫攀
计算机仿真 2021年6期
周 莉,闫 攀
(重庆邮电大学移通学院,重庆 401520)
1 引言
现代社会中,互联网的应用越来越广泛,青少年的日常和学习生活离不开网络提供的数字教育资源[1],但网络中会混杂一些色情、暴力的不良数据荼毒青少年,对青少年的身心健康造成极大的危害[2-3]。因此,辨识网络中的不良数据是保护网络学习者、净化学习内容乃至维护社会和谐的重要措施[4-5]。
李永攀[6]等人提出基于多视角低秩分析的电力状态不良数据检测方法,采集观测数据估计电力系统的运行状态,通过低秩模型挖掘观测源数据之间的共享本真数据,采用稀疏模型针对不良数据进行建模。利用基于交叉迭代的优化算法实现对不良数据的检测与辨识。实验结果表明,该方法没有在辨识网络多层不良数据的过程中提取不良数据特征点,在辨识网络多层不良数据时可能忽略一些不良数据,导致对网络多层不良数据辨识的准确率低。汪少敏[7]等人提出利用深度学习融合模型对网络多层不良数据辨识的方法,该方法利用基于深度学习的融合识别模型,将数据集中不良数据与优质数据分开,通过模型融合算法确认不良数据,实现对网络多层不良数据的辨识。实验结果表明,该方法没有利用LFM信号充当网络多层不良数据的训练集对不良数据进行特征提取,导致不良数据召回率低。李志欣[8]等人针对微博中的垃圾评论提出基于Co-Training的网络多层不良数据辨识方法,该方法构建AdaBoost分类器和支持向量机分类器,通过Co-Training算法进行协同训练,判断其是否为不良数据,实现网络多层不良数据的辨识。实验结果表明,该方法没有利用信号处理办法提取不良数据特征点,存在F1比值下降的问题。
为了解决上述方法中存在的问题,提出无线协作中继网络多层不良数据辨识方法。
2 构建网络多层不良信息特征提取模型
2.1 模型构建的优化
利用决策树模型构建无线协作环境下网络多层不良数据存储和传输模型[9],在模型中采用根节点、内部节点和叶节点三种节点模式进行组建。并通过ID3决策树算法对传统不良数据存储和传输模型进行改进,改进后的模型优势为:
1)可以将连续网络多层不良数据集的属性进行离散化处理。
2)可以同时进行不良数据的聚类和决策树剪枝,以便构建决策树的同时剪枝决策树。
3)利用Hilbert变换对网络多层不良数据信息通道进行均衡处理。
利用Hilbert变换后的系统输出如下
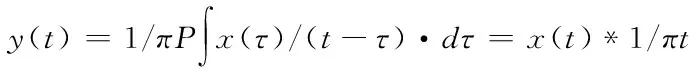
(1)
式中,y(t)代表无线协作系统输出;P代表多层网络不良数据传输信息通道的离散数据解析值;τ代表网络信息传输的延时;x(t)代表原始信号。
根据网络多层不良数据存储和传输模型,分析网络多层不良数据在无线协作环境下的存储和传输特点,建立网络多层不良数据特征提取模型,提取网络多层不良数据的特征。
2.2 网络多层不良数据特征提取模型
信号处理方法是识别网络多层不良数据的最佳办法,因此,在辨识网络多层不良数据前需建立信号模型[10]。使用网络终端下载数据信息,将上传数据信息时产生的时间序列分为线性时间序列和非线性时间序列,这些时间序列振荡数据的特征点是具有高斯宽带信号。通过分析非线性时间序列并处理宽带信号来构建无线协作环境下网络多层不良数据信号幅度-频率(角频率)曲线模型,模型如下
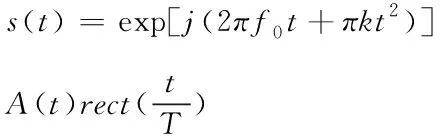
(2)

无线协作环境下网络多层不良数据的决策树局部交叉信息链公式如下
f(t)=f0+kt
(3)
则无线协作环境下网络多层不良数据的信号解析模型代表式如下
z(t)=iy(t)+x(t)=a(t)eiθ(t)
(4)
式中,z(t)代表不良数据的带宽;y(t)代表不良数据固定的模态函数;x(t)代表不良数据频带内的频谱。
不良数据的瞬时频率和时间之间是线性关系,第kk个不良数据的状态函数用无线协作环境下网络多层不良数据存储和传输模型来描述,获取无线协作环境下网络多层不良数据特征提取模型,如图1所示。

图1 网络多层不良数据特征提取模型
图1中,网络多层不良数据特征空间中产生校验位,则第k个网络多层不良数据在校验位的拓扑结构如下
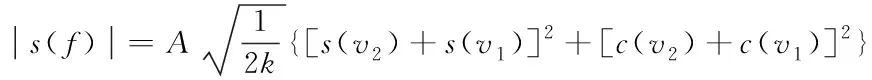
(5)
式中,c代表不良数据特征的概率密度;s(v1)代表尺度信息;A代表幅值。
由于网络多层不良数据训练集的标识具有确定性,导致不能全面提取网络多层不良数据特征,因此,选用LFM信号充当不良数据的训练集,全面实现对网络多层不良数据特征的提取。
3 多层网络不良数据辨识
3.1 基于COPS算法的层次聚类
COPS算法的实现流程为:第一阶段是在凝聚型层次聚类思想的基础上,从下往上划分出不同层次的数据,第二阶段是在数据划分的同时利用有效性指数Q(Ck)组成对应的聚类质量曲线,Q(Ck)曲线的极小点正是最佳聚类结果。COPS算法的优点是可以一次性划分全部数据,不需要反复聚类数据,而且最佳聚类数量也可以自动划分,因此,其适用于数量大且复杂的数据集聚类。
若X={x1,x2,…,xn}表示已经分类的网络多层不良数据集合,Xj=(xj1,xj2,…,xjs),(j=1,2,…n)表示在X中提取的特征值。通常情况下在数量大且复杂的网络多层不良数据集中,需要对网络多层不良数据集进行kmax-kmin+1次聚类才可使用划分数据集的聚类方法计算不同聚类个数下的网络多层不良数据集的聚类质量,这种传统方法会严重影响计算效率。若利用COPS算法,可在凝聚型层次聚类思想的基础上,对网络多层不良数据以从下往上划分的方式聚类。将每个网络多层不良数据点视为一个簇,在相似准则的基础上将不相同的网络多层不良数据点的簇合并在一起,直到所有不相同的簇归一后结束,即所有网络多层不良数据归为一类。在合并的同时采用有效性指标Q(Ck)计算出聚类质量,获取最佳的划分C*。
不良数据点间相似度定义为:
在密度聚类算法中点的邻域半径定义的基础上设定阈值tm≥0(1≤m≤s),在算法中任取两点xi和xj,且这两点满足tm≥|xim-xjm|,即经过tm的xi和xj在第m维相似。假设xi与xj在所有维度上都相似,已知阈值T={t1,t2,…,ts},则称经过T的xi与xj相似,将相似的不良数据点构成一类。
从T=0开始聚类,这时每个不良数据点都是单独的簇,每个不良数据点都不相似,为使不相似的不良数据点变得相似,每计算一步给每个簇增加一个量Δ(Δ={Δ1,Δ2,…Δs}),最终合并全部不相同的簇,使所有不相同的不良数据点归成一个簇。
下列为确定参数Δ的方法,其方法可以得出不良数据之间维度属性值的分布差异。
1)将原始不良数据归一化处理

(6)
式中,x′im代表不良数据点xi在第m维特征的归一化值。
2)运算出归一化处理后的不良数据的标准偏差σm。
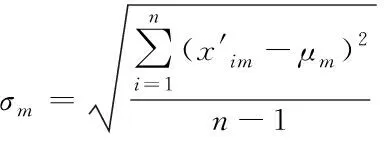
(7)
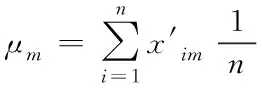
(8)
式中,σm代表归一化处理后的不良数据在第m维的标准偏差;μm代表归一化处理后的不良数据在第m维的均值。σm可用来反映第m维不良数据的稀疏度,σm值越小,m维特征值越紧密,与之相关类型的数据点越少,同理反之。
3)增量Δm求解公式为:

(9)
式中,ε代表控制算法精度,ε大于0。ε的大小与COPS算法的搜索步数有关,ε越大,搜索步数越少,ε越大,步数越多,结果就越接近于最优值,但同时消耗的时间会更多。
由于上述方法的时间消耗过长,导致算法的计算效率下降,因此,对查找相似点算法进行改善:先从大到小排列每个不良数据点在每个维度的特征值,可知第m维特征值的序列为Am(m=1,2,…,s)。在COPS算法中搜索经过tm的xi在第m维相似点时,只需在tm≥|xim-xjm|区间内按顺序扫描Am即可搜索出相似点。若阈值tm增量Δm时,用于搜索的区间也随之增量,即区间为tm+Δm≥|xim-xjm|≥tm,此时,只需将区间增量,不需重新扫描所有不良数据。
3.2 确定最优聚类结果
在最优聚类结果中,其类间是分离的,而子类内部是紧凑的,因此,在最优聚类结果中存在一个平衡类内紧凑和类间分离的点。评价聚类结果的指标需要考虑到类内紧凑度和类间分离度,用Q(CK)表示基于不良数据集的几何结构,其符合评价要求,可作为评价聚类质量的标准,即Q(CK)中包含所要求的聚类最优解。
假设将不良数据集X划分成k类,此时Ck={C1,C2,…,Ck}正是与不良数据集对应的聚类划分结果,设Ci中不良数据点的个数为|Ci|,利用Scat(Ck)表示类内紧凑度,Scat(Ck)的值越小,代表类内越紧凑,同理反之。Sep(Ck)代表类间分离度,Sep(Ck)的值越大,代表类间分离度越强,同理反之,则Scat(Ck)与Sep(Ck)的表达式为
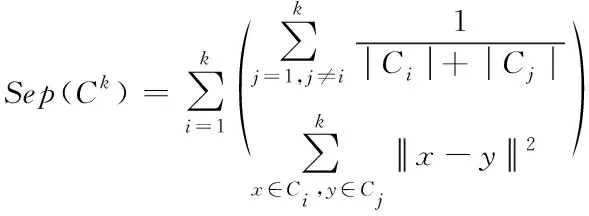
(10)
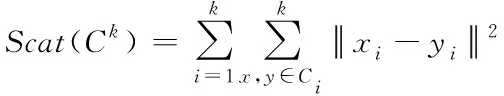
(11)
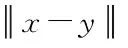

(12)
式中,β与α分别代表平衡类间分离度和类内紧凑度间的组合参数。由此可知Sep(Ck)为单调减函数,Scat(Ck)为单调增函数,所以聚类质量指标Q(CK)在区间n>k>1中取极小值时就是所要求的聚类最优解,从而实现对网络多层不良数据的辨识。
4 实验结果与分析
为了验证所提方法的整体有效性,在Weka平台中对所提方法进行测试。选取TAN、economy、social以及star文档数据集作为实验数据,分别采用无线协作中继网络多层不良数据辨识方法(方法一)、利用深度学习融合模型对网络多层不良数据辨识的方法(方法二)和基于Co-Training的网络多层不良数据辨识方法(方法三)进行测试。
将不良数据的分类准确率作为测试指标,准确率越高,说明对不良数据的特征点种类提取得越多,辨识的不良数据也越多,分类准确率(Accuracy)为正确分类不良数据文档数与不良数据文档总数的比值。图2为不同方法对不良数据分类的准确率对比结果。
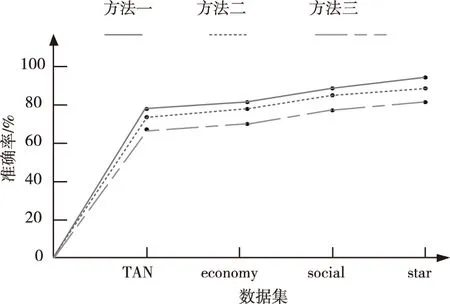
图2 不良数据文档分类准确率
图2中选取了参数及内容均不相同的文档,可看出三种方法中方法一对不良数据的分类最准确,这是由于方法一在辨识网络多层不良数据时在决策树模型的基础上确定了网络多层不良数据特征提取模型,提取出网络多层不良数据的特征点,将不良数据根据特征点进行准确的分类,提升了网络多层不良数据分类的准确率,即提高了不良数据辨识的准确率。
比较三种方法对不良数据辨识的召回率,召回率(Recall rate)为不良数据正确分类的文档数与待分类不良数据的文档数的比值,在同样环境下,召回率越高说明正确分类的不良数据文档越多,对不良数据的辨识效果越好。图3为不同方法的召回率对比结果。
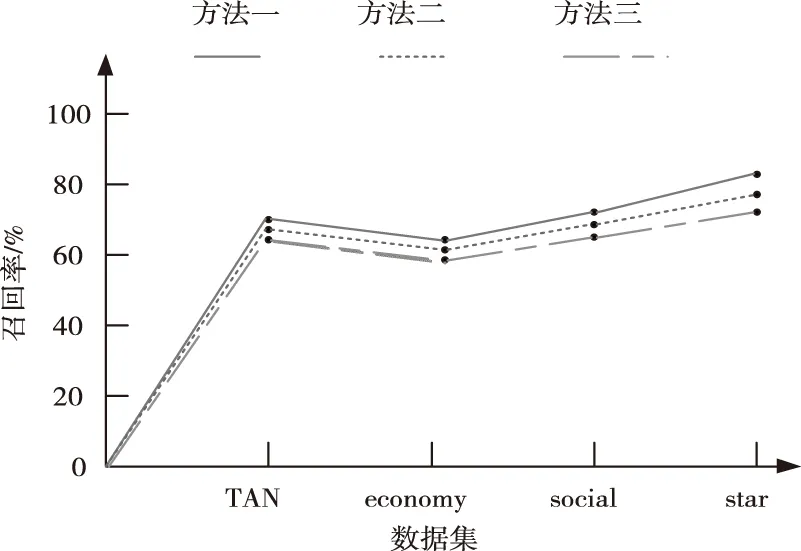
图3 不同方法召回率对比
在对三种方法的召回率进行比较后可以看出,选取的数据集无论如何复杂,方法一对不良数据召回率都是最高的,因为方法一利用LFM信号充当不良数据的训练集,而不是利用具有确定性的网络多层不良数据充当训练集,因此提取出网络多层不良数据的特征点更加广泛,即对不良数据辨识地更全面,验证了方法一的有效性。
将F1比值作为测试指标,采用方法一、方法二和方法三进行测试,比值越大,表明方法对不良数据的辨识越详细,相反,比值越小不良数据的辨识越简略,F1比值为
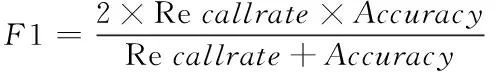
(13)
图4为不同方法的F1值对比结果。

图4 不同方法的F1比值
由图4可知,方法一在测试过程中获得的F1比值均高于方法二和方法三获得的F1比值,因为方法一通过信号处理办法提取网络多层不良数据特征点,从多个方面对不良数据进行辨识,避免了忽略一些不良数据的情况,提高了网络多层不良数据的辨识能力,进而提高了F1比值。
5 结论
目前,网络多层不良数据的辨识方法存在准确率低,召回率低和F1比值低的问题,因此,提出无线协作中继网络多层不良数据辨识方法。在无线协作环境下,基于信号模型建立网络多层不良数据的特征提取模型对网络多层不良数据进行特征提取,采用COPS算法对不良数据特征点聚类,聚类后利用聚类最优结果评价指标,获得聚类最优解实现网络多层不良数据辨识,提高了不良数据辨识的准确率、召回率及F1比值。在今后的研究,结合不良图片信息进行不良数据特征提取会更加准确地辨识无线协作中继网络多层不良数据。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
北京航空航天大学学报(2022年8期)2022-08-31
南京理工大学学报(2022年1期)2022-03-17
汽车实用技术(2022年4期)2022-03-07
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
电机与控制学报(2018年9期)2018-05-14
广东教育·高中(2018年1期)2018-01-31
计算机应用(2016年10期)2017-05-12
中学生数理化·教与学(2017年4期)2017-04-22
新高考·高一物理(2015年4期)2015-08-20
