
基于大数据模式分解的隐私信息保护方法仿真
2021-11-17 07:35从传锋
计算机仿真 2021年6期
从传锋,杨 桢
(重庆师范大学涉外商贸学院,重庆 401520)
1 引言
大数据的快速发展虽然给生活提供了极大的便利,可同样也伴随着巨大的风险。在大数据的环境下,隐私信息很容易泄漏,通过网络所留下的一些信息,有可能被一些人进行利用,对此造成的损失以及后果是无法挽回的[1]。而各领域之间的数据共享和交换,对数据隐私保护提出了更多的要求,以此来迫使发布的匿名数据隐私满足所有用户的需求。
潘明波[2]提出的大数据环境下网络数据隐私保护算法研究。先获取隐私数据的特征,然后随机生成一个变换函数,根据变换函数对隐私数据的特征值进行变换,实现隐私信息保护。该方法效率高,但保护效果不理想,存在较大误差。刘彦和张琳[3]提出了位置大数据中一种基于Bloom Filter的匿名保护方法。采用隐私度量技术划分匿名区,来隐藏隐私数据的真实位置。该方法保护效果好,但效率较低。
为此,提出一种基于大数据模式分解的隐私信息保护方法,利用网路数据隐私保护原理生成随机转化回答结果,再通过属性聚类的方式对准标识符属性类似值与敏感属性类似值进行聚类,接着完成等价划分,最终本文方法与MAH-ABE算法、CP-ABPRE两种算法对比,经过实验以后,本文方法具有优越性。
2 大数据模式分解
利用各种数据分解方法,以保证大数据满足隐私保护的要求,所有的数据都是通过等价类标识符进行连接的,因此需要建立数据模式矩阵,接着利用模式矩阵完成对大数据分解[4]。
数据模式分解:给定的数据集D与数据集合A={A1,A2,…,An},即D的一个模式分解M定义成若干个子模式的集合M={m1,m2,…,m},其中所有的子模式∀mi∈M,mi⊆A。
一个数据集会有很多种分解模式,依据不同的标准将这些模式分类[5]。可以分成满足安全模式与不满足安全模式两种。依据分解模式的子模式数目,会有很多种结果,至少可以分解出一张表,最多能够分解出n张表。
安全分解:给定的数据集D与属性集合A,M则是一个安全的模式分解,即M满足:∀mi∈M,∀rj∈R:mi满足rj;∀mi∈M:mi⊆A。
正确分解:给定的数据集D、属性集合A与D的隐私数据C,M是隐私数据的C一个正确分解模式。即M满足:∀mi∈M,∀rj∈C:mi满足cj;∀mi∈M:mi⊆A
一个正确模式分解一定会是一个安全分解模式[6]。
数据模式矩阵DMM:给定数据集D、属性集合A={A1,A2,…,An}与隐私要求集合R={r1,r2,…,rm},即D的数据模式矩阵DMM是m×n的矩阵,它的所有行都各自对应着隐私向量[v(r1)T,v(r2)T,…,v(rm)T]T,具体定义为:
1)DMM的所有行都各自对应着属性集合A的所有元素;
2)DMM的所有列都对应隐私要求的所有的要求;
3)DMM[i][j]代表第Ai(1≤i≤n)个属性在第ri(1≤j≤m)个隐私要求上取值,其中riQ(rj)→S(rj),Q(rj)={Q1,Q2,…,QnQ},S(rj)={S1,S2,…,Sn}。
4)Resp[i]代表第Ai(1≤i≤n)个属性在所有隐私要求上的综合权重,即取值的总和。

(1)
Resp[i]=(1,1,…,1)1×m×DMMm×n

(2)
式中:|rj|代表rj的准标识符属性个数与敏感属性的数量之和。
3 转换随机化回答下隐私数据处理和重构
转化随机回答网络隐私处理的中心思想是,随机生成一个给定条件的大数据,然后利用网络中的隐私数据特征进行函数的变换,在对原始的网络数据值转换以后,将转换以后的数据视为随机回答的结果[7],具体的过程如下:
在大数据的环境下,假如给定的网络数据集合为A={a1,a2,…,al},即网络隐私数据元素的均值与方差分别可用以下的公式进行表示

(3)

(4)
式中:l代表网络隐私数据中的属性值;i代表隐私数据中的特征向量;ai代表隐私数据中的损失信息。
针对数值x,其隐私化的数据随机函数公式为
r(x)=ax+b
(5)
式中:a∈A代表从隐私数据集合A内随机选取的一个元素;b∈B代表从隐私数据集合B内随机选取的一个元素,利用转换后结果能够利用下列公式进行计算,得出
y=r(x)
(6)
上式发布的网络隐私数据集D′内的n条记录相对应的敏感属性At取值公式
Y=R(X)
(7)
式中:R(X)代表网络隐私数据中的相似数据样本,并且yi=r(xi),i=1,2,…n。
通过上面的描述转换随机回答方法,可将初始的网络隐私数据x转变,其公式如下所示
y=r(x)=ax+b
(8)

(9)
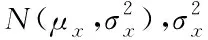

(10)


(11)

(12)
而初始网络隐私数据均值方差的计算公式为

(13)


(14)


(15)

4 基于属性聚类的隐私信息保护方法
敏感属性类似值聚类是数据隐私保护的主要方法:敏感属性(SA)的不相同取值间具有一些特定的联系,而且此联系是通过准标识符属性表现出来的,且具有特定的联系敏感属性取值,称作相似敏感属性值[8]。采用SA类似值聚类就能够有效的避免匿名数据遭受到近似的攻击影响[9]。
QI属性可以分成字符属性与数值属性,现有的方法采用数值计算的方式来对相对数值属性差异度进行处理;而相对字符属性通常是没有好的解决办法,只能利用QI属性值的聚类分析,可以计算出字符串之间的差异度,形成距离的字典,利用此方法对字符属性的取值进行比较时,查找距离字典就可以了。
随后采用两次聚类进行等价类划分与对数据的匿名操作。先分析敏感属性值聚类。其原理如下:使用三维矩阵针对所有的敏感属性取值聚类。通过这种方式来保护个人信息[10]。按照K-means的计算方法[11],随机抽取敏感属性S1的取值集合S1(Sv1,Sv2,…,Svd)内的K元素。作为K个簇的簇中心,其中d是敏感属性维数;分别计算剩下的元素到K簇中心的相异度,把这些元素经过划分各自最低簇的相异度,依据聚类的结果,对各自K簇的中心进行计算,直到把S1内的所有元素按照全新的中心进行聚类。一直到所有的SA聚类桶内的聚类中心收敛为止;就能够得到K个SA聚类桶。
完成许多敏感属性
D1×D2×…×Dd

(16)
接着完成所有的数据的聚类,首先对复合敏感属性
5 仿真与分析
仿真从隐私安全性以及算法的执行效率两方面进行,隐私安全可通过密码算法验证,而执行效率可通过服务系统计算时间,同时计算时间又可以分成加密算法钥匙的生成时间与解密时间,系统界面如图1所示。

图1 系统界面
为了进一步证明本文方法的有效性,通过传统的MAH-ABE算法、CP-ABPRE算法进行对比,以此验证本文方法的效果。
MAH-ABE算法的处理结果是只有用户本身能够获取解密以后的隐私信息,所以,这就需要利用敏感信息隐藏率计算。而敏感信息隐藏率是其加密后所占敏感属性信息属性比例得出的。因此,可以获得如图2所示的不同算法的隐私保护能力敏感信息隐藏率。
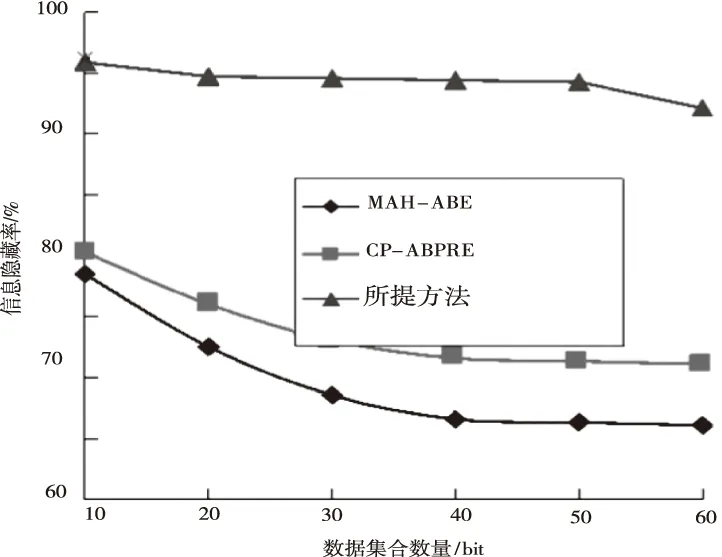
图2 不同算法敏感信息隐藏率对比图
通过上述图2能够看出。MAH-ABE对敏感信息的隐藏率最低,因为该方法面对选择性文本攻击时,隐私的保护能力较弱。同时CP-ABPRE隐藏率与MAH-ABE结果近似,都会随着总体数据量的增加而降低,而所提方法可以处理海量数据且处理效果较优秀,处理大量数据时会面临计算时间短、处理效率满,因此所提方法相比其它两种性能更加优秀。
执行效率是利用私钥的生成时间与加解密的时间的比值。其私钥的生成时间是分别围绕着属性个数和属性集合数量两个方面进行。首先私钥生成时间可采用两方面表示:数据属性个数、属性集合个数。表1是属性集合个数为1的情况下,几种算法的私钥生成时间和数据属性个数的关联。

表1 私钥生成时间/S和属性个数关联
根据上表能够看出,在属性集合个数一定情况下,所有算法的私钥生成时间都将会随着属性数目的增加而增加,且较为明显。相对而言,本文算法在数据属性个数较大情况下,要比另外两种方法私钥生成时间短,所以本文方法的执行效果更好。非常适合在大数据中使用,在相同的环境下数据的属性个数设为50的进行实验,结果如表2所示。
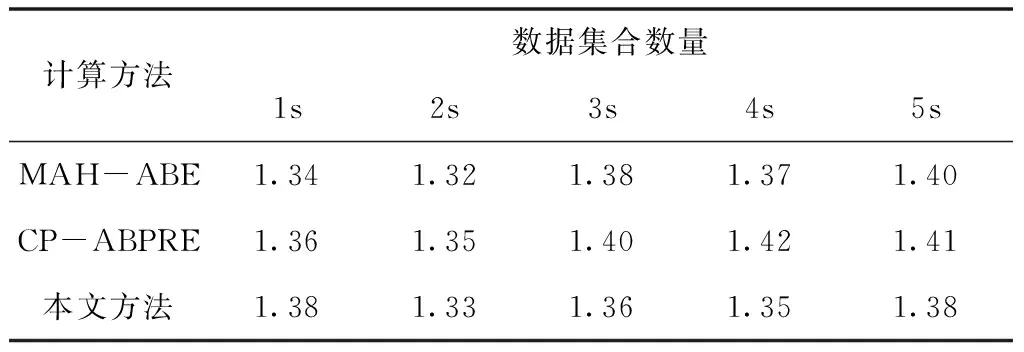
表2 私钥的生成时间/S和属性集合个数关系(集合50)
根据上表能够看出,在数据属性个数不变的情况下,私钥生成时间是随着集合个数增加而增加的。不过增长的速度较慢,根据不同结果可以看出本文算法在数据属性集合增加的情况下,其私钥生成时间相对另外两种算法要少。
接着利用实验进行验证,对不同方法的加密时间与解密时间分析。如表3所示。
根据表3中能够看出,本文保护方法具有更好的处理效率,加快数据加密与解密时间,使分级关联和处理机制能够更好对大数据进行保留。
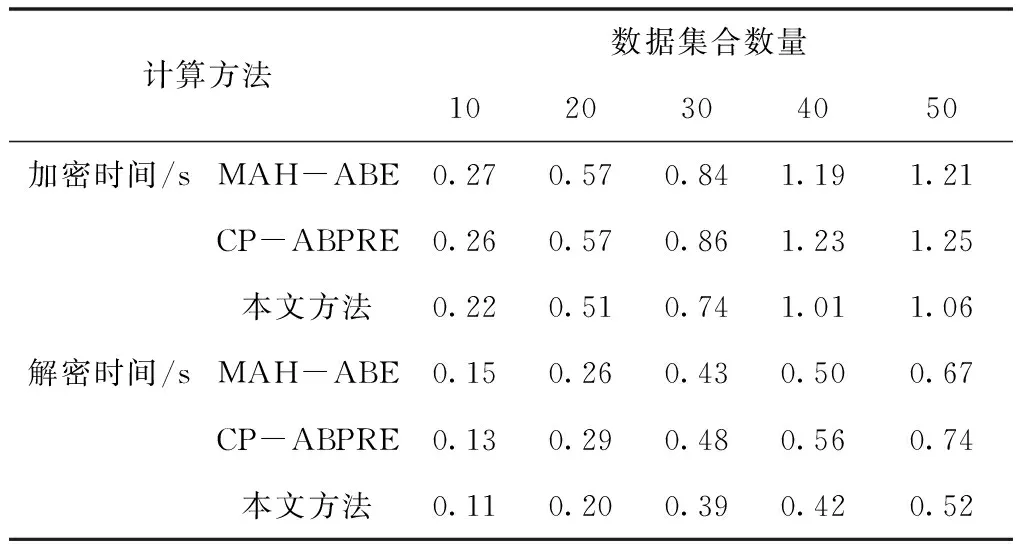
表3 加密与解密时间的对比/s
进一步验证加密后数据增量变化,进行如下实验,实验结果如图3所示。

图3 加密后的初始数据增量
根据图3能够看出,本文方法随着数据属性的增加所产生的数据要远远小于其它方法。这是因为公共数据对隐私保护的要求较低,所提方法利用公共数据的轻量级加密,导致数据的增加得较小。
6 结束语
提出一种基于大数据模式分解的隐私信息保护方法,利用随机生成转化的回答结果,通过聚类方式对准标识符属性类似值与敏感属性类似值进行聚类完成等价划分。最终通过实验证明,本文方法具有优秀的隐私效果,且可以保持高效率应对海量数据。不过未来还需要对其进行深入研究,通过分析其中的问题,并找出原因,制定更有效的措施,从而让网络的大数据环境得到安全性,使人们能够随意放心的通过网络享受生活的便利。
猜你喜欢
新高考·高三数学(2022年3期)2022-04-28
计算机与网络(2022年2期)2022-03-17
文萃报·周五版(2021年1期)2021-01-15
学生导报·东方少年(2019年27期)2019-01-14
中文信息(2017年12期)2018-01-27
成长·读写月刊(2017年4期)2017-05-16
读写算·小学低年级(2015年12期)2015-12-12
高中生·天天向上(2015年11期)2015-10-21
中学生数理化·七年级数学人教版(2014年6期)2014-09-18
中学教学参考·理科版(2014年4期)2014-08-21
