
融合情感词交互注意力机制的属性抽取研究
2021-11-16 08:14尉桢楷姚建民
中文信息学报 2021年10期
程 梦,洪 宇,尉桢楷,姚建民
(苏州大学 计算机科学与技术学院,江苏 苏州 215006)
0 引言
属性级情感分析(Aspect Based Sentiment Analysis,ABSA)任务致力于识别特定实体或属性所表达的情感,并判断情感的褒贬极性,是一种细粒度的情感分析任务。
属性级情感分析主要分为三个子任务[1]:属性抽取(Aspect Extraction),也叫作评价对象的抽取(Opinion Target Extraction),主要目标是识别出给定句子中关联于特定情感表述的实体或属性;属性归类(Aspect Category Detection),主要目的是将被抽取的实体或属性归并至一组预定义的类别集合;属性情感极性(Aspect Polarity)判断,主要目的是判断关联于属性或实体的情感极性(一般分为正向、负向和中性)。本文主要聚焦于属性抽取子任务。
属性抽取任务定义为:对用户所评论的文本,抽取该用户评价的实体或属性。该实体或属性代表用户的评价对象。评价对象通常为一个单词或短语,比如,例1下划线标定的名词短语即为属性抽取的目标样本。
[例1]
评论句子:Fish burgeris the best dish,it tastes fresh.
(译文:鱼汉堡是最好的菜,它的口感新鲜。)
传统属性抽取方法主要采用基于监督学习的自动标记方法,该类方法将属性抽取任务转化为序列标记任务。其中,Jakob等[2]将条件随机场(Conditional Random Fields,CRF)模型首次应用于评价对象抽取的研究,该方法在融入多种手工特征的条件下,在属性抽取的任务上取得了较好的效果,在电影评论数据集[3]上F1值达到了70.2%。近期,大量研究将神经网络模型应用到属性抽取任务,包括循环神经网络(Recurrent Neural Network,RNN),双向循环神经网络(Bi-directional Recurrent Neural Network,Bi-RNN),基于长短时记忆单元(LSTM)的RNN网络,以及双向长短时记忆网络(Bi-LSTM)。这类方法均取得了显著的性能提升[4]。在此基础上,Toh等[5]将Bi-RNN与CRF结合,并加入多种手工特征,进一步优化属性抽取的性能,并于2016年语义评测(Semantic Evaluation,SemEval)属性级情感分析评测任务中[6]综合成绩排名第一。
目前,注意力机制[7](Attention Mechanism)在多种自然语言处理任务上均取得了显著的性能提升,其突出的优势在属性抽取任务上也得到学者的关注。例如,Wang等[8]使用成对多层注意力机制进行属性与情感词的联合抽取。Li等[9]利用窗口化的历史注意力机制捕获与属性词相关的局部历史信息。该类方法在加入注意力机制的前提下可显著提升属性抽取的性能。然而,Wang等[8]分别建模属性抽取通道和情感词抽取通道的全局注意力,Li等[9]建模局部的历史注意力信息,均未能较好地利用文本中所包含的情感词信息辅助注意力的建模。
[例2]
评论句子:The service is excellent and the decor is great.
(译文:服务非常好,装饰很棒。)
评价属性:service (服务),decor (装饰)
在属性抽取任务中,待抽取的属性词大多存在若干与其具有强相关性的情感词,比如,例2中属性“service”存在与其强相关的情感词“excellent”,属性“decor”存在与其强相关的情感词“great”。因此,可利用上述强相关性,将情感词信息融入待抽取文本的每个词项,从而通过文本中的情感词“excellent”和“great”辅助属性词的抽取。
本文提出一种融合情感词的交互注意力机制,并将其应用到基于Bi-LSTM的CRF模型中。该注意力机制将文本中所有的情感词按序排列,并与原始文本建模交互注意力。从原始文本的每个目标词项角度出发,可获取被排列的情感词的重要程度,从被排列的情感词角度出发,可得知文本中哪些词项与情感词相关,进而通过以上两种相关性,将情感词融入文本表示中,促进属性词的抽取。在排列情感词的编码过程中,为了尽量保证情感词与原始文本的语义空间相似性,本文利用高速网络[10](High Way Network)将情感词映射到与原始文本相似或相同的语义空间。此外,本文引入“是否情感词”向量,以标识文本中每个词项是否为情感词,从而为原始文本和排列的情感词建立初始弱相关性。
本文对融入了上述交互注意力机制的属性抽取系统进行测试。在国际公开数据集SemEval 2014[1]和2015[11]上进行测试,均获得了性能的提升。在三个基准数据集上,F1值分别提高了5.53%、2.90%和5.76%。
全文组织结构如下:第1节回顾属性抽取相关工作;第2节介绍融合情感词交互注意力的LSTM模型;第3节给出实验数据,并进行结果分析;第4节总结全文。
1 相关工作
在属性级情感分析任务中,属性抽取子任务已经积累了大量优秀研究成果。早期研究制定多种规则进行属性抽取研究。Hu等[12]首次制定一系列依存的关联关系规则进行评价对象抽取研究。Zhuang等[3]针对影评中的评价对象—评价观点二元组,通过二者之间的依存关系实现抽取工作。Blair等[13]将主观句中的名词和名词短语按其出现的频率加权排序,并按照权重选取所需抽取的属性。Wang等[14]将用户的评价对象和观点使用Bootstrapping方法进行交替识别。
此外,对于主题模型,学者发现在特定的条件下,比如限定抽取评价对象类别的情况下,可运用主题模型抽取评价对象。Mei等[15]在评价对象抽取的研究中发现,概率潜在语义模型(Probabilistic Latent Semantic Analysis,PLSA)可促进评价对象的抽取。Titov等[16]针对评价对象抽取的粒度问题,在潜在狄利克雷分配(Latent Dirichlet Allocation,LDA)模型的基础上,提出一种多粒度的LDA模型。Lin等[17]针对主题和情感词的联合抽取任务,提出一种联合主题模型,用于同时抽取主题和情感词。Mukherjee等[18]收集评价对象的种子集合,利用半监督的方法建立联合主题模型用于评价对象抽取。
在监督学习应用方面,可制定多种标签模式,通过标签所在的位置标识出文中存在的评价对象,因此,序列标记方法逐渐成为属性抽取的主流方法。Jin等[19]使用隐马尔科夫模型(Hidden Markov Model,HMM)学习标签的序列表示,通过序列标签标记评价对象。Jakob等[2]首次将CRF模型单独用于评价对象抽取研究。Li等[20]发现评价文本的结构有助于评价对象的抽取,比如链式结构、连接结构和句法结构,因此,可将文本结构特征化,并融入CRF模型中。
近期,由于神经网络模型的广泛应用,大量研究开始将其应用到属性抽取任务中。Xu等[21]使用递归自动编码器模型,同时抽取观点词、评价对象,以及它们之间的关系。Liu等[4]使用基于LSTM的循环神经网络(RNN),同时融入了词性的分布语义表示、自动学习词语之间的关联,并且在多个数据集上证明其优于CRF方法。Toh等[5]将Bi-RNN与CRF结合,并加入多种手工特征,以此优化属性抽取的性能。Wang等[22]通过RNN对依存树进行编码,学习单词的特征表示,并将表示学习的结果输入到CRF进行序列标注。Wang等[8]通过一种成对多层注意力机制(Coupled Multi-layer Attentions),捕获句子中各个单词之间的直接依存关系和间接依存关系,进行属性词和情感词的联合抽取。Li等[23]利用双通道LSTM与记忆力机制,实现属性和情感词的联合抽取。Xu等[24]使用卷积神经网络(Convolutional Neural Networks,CNN),并同时利用领域词向量和通用词向量提升属性抽取性能。Li等[9]利用窗口化的历史注意力,借此关注每个目标词项的局部历史信息。Ma等[25]探究了端到端模型在属性抽取任务中的应用。Dai等[26]使用规则扩充训练数据,并利用基于BiLSTM的CRF模型进行属性抽取。
其中,上述研究与本文研究工作最为相关的是Toh等[5]以及Xu等[24]的研究,本文以Toh等[5]的系统为基线系统,并将融合情感词的交互注意力机制融入该系统中。由于传统的RNN难以处理长期依赖关系,而LSTM相比于RNN能更加有效地学习长期依赖关系,因此我们在Toh等[5]基线系统的基础上,以更适宜于学习长期依赖关系的LSTM代替系统中的埃尔曼型(Elman-type)RNN。在系统的输入层,本文利用Xu等[24]提出的双词向量思想,并引入“是否情感词”向量,以标识文本中每个词项是否为情感词。在系统的输出部分,本文采用Luo等[27]提出的堆叠RNN(stacked RNN),在交互注意力计算的下游堆叠一层双向门控循环单元(Bi-directional Gated Recurrent Unit,Bi-GRU),用于建模交互注意力的输出向量。最后,输出层使用CRF解码出真实预测标签。与Wang等[8]使用成对多层注意力机制建模文本的全局注意力和Li等[9]使用历史注意力建模局部历史信息不同,本文所提融合情感词的交互注意力机制能利用文本本身存在的情感词辅助注意力建模,通过交互注意力实现文本和情感词排列之间的交互,从而将情感词融入文本的表示中,提高属性抽取的效果。此外,本文利用高速网络将情感词映射到与原始文本相似或相同的语义空间,使情感词与原始文本能在相同语义空间中进行计算。
2 融合情感词交互注意力的LSTM模型
本文采用序列标记方法处理属性抽取任务,使用的标签模式为BIO标签。其中,B代表属性短语的开始,I代表属性短语的中间词或结尾词,O代表非评价对象(例3)。
[例3]
句子:Best spicy tuna roll,great Asian salad.
标签:O B I I O O B I O
(译文:最好的辣金枪鱼卷,美味的亚洲沙拉。)
本文针对属性抽取任务,利用原始文本存在的情感词辅助注意力的建模,提出一种融合情感词的交互注意力机制。本文模型如图1所示,分别为:词向量层、编码层、融合情感词的交互注意力层、堆叠Bi-GRU层以及CRF解码层。下面将对每一层的计算模型给出详细介绍。其中融合情感词的交互注意力层为本文重点。

图1 融合情感词的交互注意力机制图
2.1 词向量层

2.2 编码层



其中,式(6)为使用tanh函数激活的全连接网络计算,式(4)和式(5)为高速网络的计算,t表示转移门,使用sigmoid激活函数,(1-t)表示携带门,g表示激活函数,本文使用的RELU激活函数,⊙表示对应元素相乘。
2.3 融合情感词的交互注意力层
本节为本文重点,在编码层分别编码原始文本和排列的情感词之后,使用交互注意力进行原始文本和情感词之间的交互建模(下文简称情感交互层)。
情感交互层首先使用原始文本编码H和情感词编码HS计算注意力相似度矩阵A∈Rm×n,其中A的每个元素Ai,j由原始文本和情感词交互计算获得,计算如式(7)所示。
(7)
在此之后,使用注意力相似度矩阵分别从两个角度计算原始文本注意力向量和情感词注意力向量,并将此二者注意力向量进行融合。

从情感词看文本角度:对于所有的情感词,取注意力矩阵中每列的最大值a′i∈a′,获取原始文本对于所有的情感词的注意力得分a′={a′1,a′2,…,a′n},并使用softmax函数归一化该注意力得分,从而获得原始文本对于所有情感词的重要程度a。利用归一化的重要性程度和原始文本加权求和,计算从情感词看文本角度的注意力c∈C,并将c复制n次获得C={c1,c2,…,cn}。计算如式(10)~式(12)所示。
注意力向量融合:本文将从文本看情感词角度的注意力向量和从情感词看文本角度的注意力向量进行交互融合,获得融合情感词的交互注意力向量R=(r1,r2,…,rn)。如此,对于每个词项,其注意力向量ri均融合了情感词信息,从而以情感词信息辅助属性的抽取。计算如式(13)所示。
(13)
2.4 堆叠Bi-GRU层
参考Luo等[27]的堆叠RNN,本文在情感交互层的输出后堆叠一层Bi-GRU,用于对情感交互层的输出进行进一步的建模。在实验过程中,本文尝试使用BiLSTM网络进行堆叠,由于其效果与Bi-GRU相近,因此,本文选取参数相对较少的Bi-GRU作为堆叠的RNN网络。与编码层使用的BiLSTM类似,将前向GRU的输出与反向GRU的输出拼接,获得堆叠Bi-GRU的建模表示U={u1,u2,…,un}。堆叠Bi-GRU层的计算如式(14)~式(16)所示。

2.5CRF解码层
本文将U输入到CRF进行解码,获取句子中每个单词的预测标签L={l1,l2,…,ln},其中,li∈{B,I,O}。将U由全连接层进行降维,获取CRF输入的发射分数E={e1,e2,…,en},通过优化CRF的序列对数似然损失函数训练本文的属性抽取模型,其损失函数如式(17)所示。
(17)
其中,WE为CRF层的转移矩阵,bE为偏置。预测时,使用维特比算法根据发射分数E和转移矩阵WE推算出预测标签。
3 实验
3.1 实验数据及设置
为了验证本文方法的有效性,本文在2014、2015 SemEval属性级情感分析的三个不同数据集上进行实验分析。该数据集包含电脑(laptop)领域和餐馆(restaurant)领域。其来源如下:2014年语义评测任务四(1)http://alt.qcri.org/semeval2014/task4/电脑领域(SemEval 2014 task 4 laptop,14 LAPT),2014年语义评测任务四餐馆领域(SemEval 2014 task 4 restaurant,14 REST),2015年语义评测任务十二(2)http://alt.qcri.org/semeval2015/task12/餐馆领域(SemEval 2015 task 12 restaurant,15 REST)。其中,各个数据集中均标注了每个句子存在的属性词。
实验数据设置如下:三个数据集中,训练样本数量分别为3 045、3 041和1 315。测试样本数量分别为800、800和685。实验过程中,参考Xu等[24]随机从训练数据中选取150条样本作为开发集。经过开发集的划分后,各个数据集的训练集、开发集以及测试集样本数量如表1所示。

表1 语料统计
3.2 评价方法
与Wang等[8]相同,本文采用F1值作为评价指标。评价过程中,只有当模型预测结果与标准答案完全一致,才能计算为一个正确的预测答案。例如,标准答案为“spicy tuna roll”,如果模型预测结果为“tuna roll”,则不是正确答案。只有当模型预测结果与标准答案完全匹配,才为正确的预测答案。
3.3 参数设置
在双词向量中,通用词向量使用100维的GloVe词向量(3)https://nlp.stanford.edu/projects/glove/,领域词向量使用Xu等[24]分别使用电脑领域和餐馆领域数据训练出的100维电脑领域词向量和餐馆领域词向量(4)https://github.com/howardhsu/DE-CNN,“是否情感词”向量使用20维随机初始化的向量。实验过程中,词向量固定,训练过程中不更新,“是否情感词”向量随着训练过程不断更新。对于领域词向量的未登录词,本文使用fastText(5)https://github.com/facebookresearch/fastText获取其词向量,对于通用词向量的未登录词,本文随机初始化100维向量作为其词向量。本文使用Wang等[8]手工标注的情感词,为每个句子提取出其中存在的情感词。学习率(Learning Rate)固定为0.001,批量(Batch Size)输入的大小设为64。BiLSTM隐层维度和堆叠的Bi-GRU隐层维度均设置为128。为了避免过拟合,本文在词向量层和交互层之后加入dropout,在上述两层之后加入部分dropout(partial dropout)[28],其中dropout比率(dropout rate)设置为0.5。为了避免神经网络初始化的随机性引起的实验性能波动,本文在实验中以相同的超参数(hyper-parameters)训练出5个模型进行测试,并选取5个模型测试结果的平均值作为最终的实验性能。
3.4 实验配置
为了与本文所提融合情感词的交互注意力机制(Sentiment Words Incorporated Interactive Attention,以下简写为SIIA)作对比,本文将对比实验分为三组。第一组为单任务属性抽取系统:
CRF:使用基础模板,并利用crfsuite(6)https://sklearn-crfsuite.readthedocs.io/en/latest/tutorial.html工具训练CRF,用于属性抽取。
IHS-RD[29]和DLIREC[30]:分别为14 LAPT和14 REST属性抽取第一名评测系统。二者均为融入多种手工特征的CRF方法。
WDEmb:Yin等[31]提出将词向量、线性上下文以及依存句法作为特征输入CRF模型,来优化属性抽取的性能。
EliXa[32]:15 REST属性抽取第一名评测系统。该系统使用多种不同的手工特征,并利用开源工具(7)https://github.com/ixa-ehu/ixa-pipe-nerc训练属性抽取模型,是一种HMM方法。
LSTM:Liu等[4]提出将预训练的词向量输入LSTM,并通过全连接得到各个单词标签的概率分布,最终得到预测标签。
DE-CNN:Xu等[24]提出同时使用通用词向量和领域词向量,并利用多层CNN进行属性抽取,可大幅提高属性抽取的性能。
Seq2Seq4ATE:Ma等[25]首次提出使用端到端模型进行属性抽取,并在实验过程中使用了融入位置的注意力机制。
第二组为多任务联合学习系统。包括:①属性与情感词联合抽取的多任务学习系统,其利用情感词抽取任务与属性抽取任务相互促进,从而提升属性抽取性能,且同时提高情感词抽取性能;②属性及其情感极性联合学习系统,通过属性抽取任务与情感极性判断任务相互促进,提升属性抽取的性能。
RNCRF:Wang等[22]通过RNN对依存树进行编码,学习单词的特征表示,并将表示学习的结果输入到CRF进行序列标注。
MIN:Li等[23]利用双通道LSTM实现属性和情感词的联合抽取,并利用记忆力机制实现双通道LSTM的记忆交互。
CMLA:Wang等[8]提出通过一种成对多层注意力机制(Coupled Multi-layer Attentions),捕获句子中各个单词之间的直接依存关系和间接依存关系,进行属性词和情感词的联合抽取。
HAST:Li等[9]提出使用局部的历史注意力(Truncated History-Attention)和选择转移网络(Selective Transformation Network)进行属性与情感词的联合抽取。
RINANTE:Dai等[26]使用规则扩充训练数据,并使用共享的BiLSTM进行属性与情感词的联合抽取。
DORE:Luo等[27]提出交叉共享单元,并将其应用到堆叠的对偶RNN网络上,同时使用额外的属性长度预测和词典引导的情感极性预测任务进行属性及其情感极性联合抽取。该模型在输入部分同时参考了Xu等[24]提出的双词向量的思想。
第三组为本文所提融合情感词的交互注意力机制的SIIA系统及其各部分拆解系统。
G+BCRF、D+BCRF和GD+BCRF:基线系统使用基于BiLSTM的CRF系统(下文简写为BCRF)。LSTM的细胞单元使用Greff等[33]提出的LSTM单元,其中G+BCRF代表使用通用词向量GloVe,D+BCRF代表使用领域词向量,GD+BCRF同时使用通用词向量和领域词向量。
GD+BCRF+IA:在GD+BCRF的基础上加入交互注意力,其中情感词编码过程中未使用高速网络进行语义空间的映射,且未使用“是否情感词”向量。
GD+BCRF+IA+H:在GD+BCRF的基础上加入交互注意力,且情感词编码过程中使用高速网络进行语义空间的映射,未使用“是否情感词”向量。
GD+BCRF+IA+H+S(SIIA):本文完整的属性抽取系统,在GD+BCRF的基础上加入交互注意力,其中情感词编码过程中使用高速网络进行语义空间的映射,并同时使用“是否情感词”向量。
SIIA+DICT:在本文完整系统SIIA的基础上,将Wang等[8]手工标注的情感词替换为MPQA(8)http://mpqa.cs.pitt.edu/词典,本文选取词典中强主观词语,构成最终的情感词典,并以此词典来获取数据集中每个句子包含的情感词。
3.5 实验结果与分析
3.5.1 总体实验结果分析
本文总体实验结果如表2所示,其展示了第一组和第二组以及本文SIIA系统的实验结果。由表2可发现,本文系统SIIA在三个数据集上均取得了最优的性能。
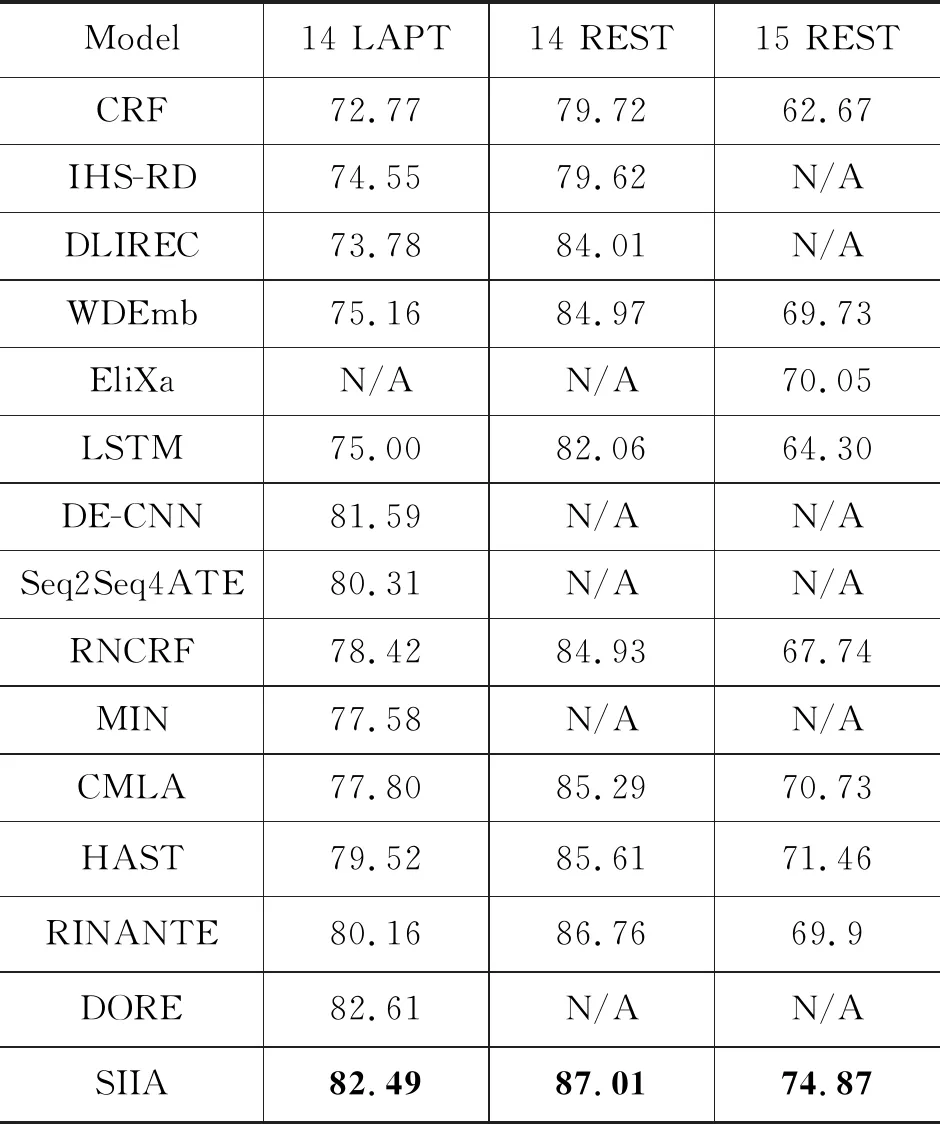
表2 不同模型实验结果对比 (单位:%)
分析第一组单任务学习系统实验结果可知,基础的CRF模型在三个数据集上的表现都较差,而相比于其他加入大量手工特征的模型IHS-RD,DLIREC,加入手工特征的模型都较基础的CRF模型有所提升,由此可说明手工特征可在一定程度上促进属性抽取。WDEmb进一步使用词向量作为CRF模型的输入,性能得到进一步的提升,因此词向量对于属性抽取任务来说是一项重要的输入表示。
对于深度学习模型LSTM,其在各个数据集上的表现均未能取得较好的效果,而加入双词向量的多层CNN模型和融入位置注意力的端到端神经网络模型均能取得较好的效果,由此可说明双词向量和注意力对于属性抽取的有效性。
分析第二组属性与情感词联合抽取模型可发现,相比融入依存树编码的RNCRF,使用双通道注意力的MIN,使用多层成对注意力的CMLA以及使用历史局部注意力的HAST,在未加入任何手工特征的条件下均能取得与RNCRF可比的性能或更优的性能。而DORE在设计的交叉共享注意力的基础上,在14LAPT上取得了最优的效果。由此可说明,设计能捕获特定信息的注意力模型有利于属性抽取。此外,RINANTE利用规则扩充训练数据进行属性抽取的研究,并在14 REST上取得了最优的性能,由此可说明数据量对于深度学习模型的重要性。
其中,相比于第一组单独使用LSTM的单任务模型,第二组使用RNN编码依存树的RNCRF联合学习模型以及双通道的LSTM联合学习模型效果均优于单独使用LSTM的单任务模型。由此可发现,属性与情感词的联合抽取有助于属性的抽取,由于二者呈现出一种相互促进的关系,使得属性抽取与情感词抽取都能取得较单任务学习更优的效果。而DORE同时利用了双词向量、注意力机制以及多任务联合学习,该模型在结合以上三个研究点优势的基础上,于14LAPT上取得了最优的性能。
本文系统SIIA相较于14 LAPT最优系统DORE取得了可比的效果,相较于14 REST最优系统RINANTE和15 REST最优系统HAST取得了最优的性能,其属性抽取性能分别提升0.25%和3.41%。由于本文系统SIIA在输入层使用了通用词向量和领域词向量,且本文系统融入情感词的交互注意力,使其可在情感词的辅助建模中促进属性抽取,如本文引言例2所示,可利用情感词“excellent”和“great”辅助模型发现属性词“service”和“decor”。此外,本文同时结合双词向量思想和融入情感词的交互注意力思想,可在少量的数据上取得较好的效果,相较于属性与情感词联合抽取系统,并使用大量数据的RINANTE具有一定的优越性。
3.5.2 系统拆解实验结果分析
表3展示了本文系统各部分拆解实验结果,即第三组实验结果。由拆解实验结果对比分析发现,相较于使用通用词向量的G+BCRF与使用领域词向量的D+BCRF,同时使用通用词向量和领域词向量的GD+BCRF性能得到较大程度的提高,以此可进一步验证上一节所提到的双词向量的有效性。原因在于,使用双词向量可使句子中的通用词汇和领域词汇得到更加精确的表示,比如,对于通用词汇“and”,使用大量数据训练出的通用词向量可更加精确地表达其含义,而对于领域词汇“speed”(电脑领域)和“drink”(餐馆领域),则更加倾向于使用领域数据训练出的领域词向量精确地表达其含义。对于电脑领域的词汇“speed”,其表达的意义为电脑或处理器的速度,而在通用领域,其表达的速度一般为每小时多少公里;对于餐馆领域的词汇“drink”,其表达的意义为饮料,而在通用领域,其表达的意义一般为喝。因此,针对上述分析,本文同时利用通用词向量和领域词向量,以精确地表达句子中不同词汇的意义。

表3 系统拆解实验结果对比 (单位:%)
为了验证本文所提融合情感词的交互注意力机制的有效性,本文在GD+BCRF的基础上加入交互注意力,并且不使用高速网络进行语义空间的映射,同时在网络的输入层,不使用“是否情感词”向量(见GD+BCRF+IA)。实验结果证明,加入交互注意力之后,GD+BCRF+IA比基础模型GD+BCRF在三个数据集上F1值分别提升0.8%、0.76%和2.09%。由此可证明融入情感词的交互注意力机制的有效性。该注意力机制将句子中所有的情感词按顺序排列,并利用文本与情感词的交互注意力,通过注意力权重,捕获情感词对于文本中每个词项的重要程度,将情感词信息融入文本的每个词项表示中,从而达到以情感词辅助属性词抽取的效果。例如,本文引言例2中将情感词“excellent”和“great”融入“service”和“decor”的表示中,从而实现以情感词辅助发现属性词。
为了进一步验证本文所提高速网络进行语义空间映射的有效性,在GD+BCRF+IA+H实验中,对于排列的情感词编码过程,使用高速网络进行语义空间的映射,以将其转换为与原始文本使用LSTM编码后相同或相似的语义空间,从而使注意力相似度矩阵来自相同的语义空间向量。由于在编码的过程中,待判别句子使用BiLSTM进行编码,该编码考虑了时序的信息,而对于排列的情感词,由于各个单词之间没有联系,因此无法使用考虑时序信息的BiLSTM进行编码,而使用tanh函数激活的全链接神经网络进行编码。考虑到不同的编码方式可能会导致语义空间的不同,因此,本文使用高速网络进行排列情感词的语义空间映射,以期望将其转化为与带判别句子相同或相似的语义空间。实验结果证明了高速网络语义空间映射的有效性,相较于未使用高速网络的GD+BCRF+IA模型,在三个基础数据集上F1值分别提升0.41%、0.27%和0.93%。
在本文完整的系统GD+BCRF+IA+H+S(简写为SIIA)中,其进一步在输入层使用了“是否情感词”向量,相较于未使用“是否情感词”向量的模型GD+BCRF+IA+H,SIIA在三个数据集上F1值分别提升0.56%、0.76%和0.82%。使用“是否情感词”向量,在编码过程中让句子知道哪些位置的词为情感词,从而起到类似于位置信息的作用,例如,例2中,通过“是否情感词”向量,模型可感知在第四时刻和第九时刻的单词为情感词,且模型在学习的过程中可间接感知属性词与情感词之间的距离,从而使二者建立初始弱相关关系。同时,经过观察与分析发现,原始数据中大多数的属性词都不含有情感词,只有少部分属性词会包含情感词,例如“fresh mozzarella”包含情感词“fresh”。因此,可利用“是否情感词”在编码过程中捕获上述信息,以达到促进属性抽取的效果。
为了进一步验证本文所提方法的有效性,本文在SIIA+DICT实验中将Wang等[8]手工标注的情感词替换为MPQA情感词典,本文选取MPQA词典中的强主观词构成情感词典,以此获取数据集中每个句子中所包含的情感词。实验结果表明,使用情感词典获取的情感词方法相较于基础模型GD+BCRF,在三个数据集上F1值分别提升1.1%、1.13%和3.22%。相较于其他前沿方法,使用情感词典的方法能达到最好的效果(15REST)或可比的效果(14LAPT和14REST)。由于在实际使用情况中,多数情况下只能部分标注情感词或不能手工标注情感词。因此,本文增设此组实验证明,在无法完全手工标注情感词的情况下,使用情感词典获取句子中包含的情感词可成为一种更加方便的选择,并能达到与手工标注情感词可比的效果。
综合以上各部分实验,在原始使用通用词向量的G+BCRF基础模型上,本文同时在输入层使用通用词向量和领域词向量,在建模过程中,加入本文所提融入情感词的交互注意力,同时使用高速网络进行语义空间的映射,并在输入层加入“是否情感词”向量。最终,本文所提完整的模型相较于基础模型G+BCRF在三个数据集上F1值分别提升5.53%、2.90%和5.76%。
3.5.3 注意力矩阵可视化分析
[例4]
评论句子:The service is excellent,the decor is great,and the food is delicious and comes in large portions.
(译文:服务非常好,装饰很棒,食物美味并且量多。)
评价属性:service (服务),decor (装饰),food (食物),portions(分量)
本文将注意力相似度矩阵可视化,以此分析融合情感词的交互注意力的作用。图2展示了例4的注意力相似度矩阵,其中图中横坐标代表待测试句子,纵坐标代表该句子中所有的情感词。图中颜色的深浅代表注意力相似度分数的大小,颜色越深代表相似度分数越高。

图2 注意力相似度矩阵图
从图中可发现,在情感词“excellent”“great”“delicious”和“large”的辅助下,文本中属性词与情感词相对于排列的情感词相似度得分呈现两个极端的表现,其中属性词与排列的情感词相似度得分普遍很低(如图2中的属性词“service”“decor”“food”和“portions”颜色最浅。),与之相反的是,情感词与排列的情感词之间会得到最高的相似度得分(如图2中的情感词“excellent”“great”“delicious”和“large”颜色最深。)由此现象可发现,属性词与情感词呈现出一种负相关性,二者为一种对立的极端。因此本文利用这种对立的相关性,在注意力建模过程中,将与属性词对立相关的情感词信息融入文本的表示中,在此过程中,属性词会融入较少的情感词信息(属性词对应的颜色较浅)而文本中其他词会融入较多的情感词信息(其他词对应的颜色较深),从而达到以情感词辅助发现属性词的目的。
3.5.3 显著性检验分析
为了检验模型性能提升的显著性,本文进行了显著性检验分析实验。本文选取14 REST和15 REST最优上表现最优的模型RINANTE和HAST,14 LAPT上表现次优的DECNN(由于DORE实验以属性及其情感极性对为主要实验结果进行分析,其实验数据的设置与本文不同,且对于属性抽取,该论文未汇报其基础模型的属性抽取实验结果,因此,本文选取14 LAPT上表现次优的DECNN模型进行显著性检验分析)以及本文模型SIIA和其可选的替代模型SIIS+DICT进行显著性检验分析。实验中,计算各个模型的基础模型与最终模型在其所使用数据集上的显著性得分P值[34],如表4所示。

表4 显著性得分表
分析表2可发现,除HAST外,本文模型SIIA和SIIA+DICT显著性P值均优于其他模型(P值小于0.05代表性能提升显著,P值越小,效果越优),且均小于0.05,由此可说明本文所提模型对性能的提升是显著的,同时可证明,本文所提模型在实际使用中的效果优于DECNN和RINANTE。除此之外,SIIA和SIIA+DICT的显著性P值较为接近(相差0.006),说明二者的性能提升效果较为相似。由此可证明,在实际使用过程中,可使用更加方便的情感词典代替手工标注的情感词,从而达到模型效果的提升。
4 总结与展望
本文提出一种融合情感词的交互注意力机制,旨在通过交互注意力机制,以文本中所包含的情感词辅助属性词的抽取。此外,为了保证情感词和原始文本语义空间的一致性,本文使用高速网络进行情感词语义空间的映射。实验证明,本文所提方法在三个基准数据集上均能得到一定程度的性能提升。然而本文方法仍然存在一定的局限性,例如,需要使用情感词,在未来的工作中,考虑使用自动发现的情感词来辅助属性词的抽取。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
开放教育研究(2020年2期)2020-03-31
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
现代语文(2016年21期)2016-05-25
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
大连民族大学学报(2015年2期)2015-02-27
