
基于层次注意力机制和门机制的属性级别情感分析
2021-11-16 09:13黎海辉赵洪雅唐婧尧
中文信息学报 2021年10期
冯 超,黎海辉,赵洪雅,薛 云,唐婧尧
(1.云南广电网络集团有限公司,云南 昆明 650100;2.深圳职业技术学院 工业中心,广东 深圳 518055;3.华南师范大学 物理与电信工程学院,广东 广州 510006)
0 引言
近年来,随着互联网的飞速发展,大量的消费平台和社交网络平台逐渐走进人们的生活[1]。在消费平台上,消费者消费之后往往会留下一段关于产品优劣的评论;在社交网络平台上,网民也会留下关于某个事件的看法。这些含有情感信息的评论无论对企业或者政府而言都是极具价值的,企业可以通过分析消费者的评论,了解产品的不足,以达到改善产品性能的目的;政府也可以通过总结网民对事件的看法以引导事件的发展方向。可见,如何从富含情感信息的评论中挖掘出有用的信息已成为自然语言处理领域的热点研究方向之一。
情感分析是自然语言处理中重要的子领域,可分为句子级别情感分析、篇章级别情感分析和属性级别情感分析[2]。句子级别情感分析对整个句子的单一情感极性(积极、中性和消极)进行判断。篇章一般由多个句子构成,所以篇章级别情感分析在于根据构成该篇章的多个句子判断其整体情感极性[3]。由此可知,句子级别和篇章级别情感分析均为对评论文本的单一情感极性进行判断,而在产品以及产品属性日益多样化的今天,消费者一般会留下一段关于产品多个属性评论的评论文本,例如“The food was extremely tasty,but the service was dreadful”。这是一段来自酒店的评论,通过分析可以看出属性词“food”和“service”的情感极性分别是积极和消极,而以获取整体情感极性为目的的句子和篇章级别情感分析明显不适合这种含有多个属性词且对每个属性词表达情感不一致的情况,所以,属性级别情感分析逐渐受到学术界和商业界的关注。
属性级别情感分析需要找出特定属性词在上下文(本文将评论中属性词之外的部分称作属性词的上下文)中所关联部分以达到判断特定属性词情感倾向的目的[4]。因此,属性级别情感分析需要充分利用属性词和上下文的关系,即不同属性词在上下文中关注的词也有所不同[5],如当识别属性词picture quality情感极性的时候,clear-cut自然能与属性词picture quality产生联系。除此之外,在属性级别情感分析中,不同词对于不同属性词情感极性判断的作用也是不一致的,如情感词。因此,在近些年属性级别情感分析工作中,如何通过上下文和属性词的交互式学习,从而达到识别出上下文中对属性词、重要词的目的已经成为了研究重点。常见的交互方式有如下几种:第一,将属性词向量与上下文向量进行拼接;第二,设计上下文和属性词之间的交互注意力机制。但是简单的拼接并不能达到识别出上下文中对属性词重要词的效果。因此,设计上下文和属性词之间的注意力机制成为了学术界研究热点之一,但是单层的注意力机制难以达到将上下文和属性词相互关联的目的。而且,大多数属性级别情感分析工作将上下文与属性词之间的注意力机制直接作为上下文和属性词的表达,本文认为该做法在一定程度上忽略了原上下文和属性词表示的作用。因此本文提出使用层次注意力机制和门机制(Aspect-level Sentiment Analysis Based on Hierarchical Attention and Gate Networks,HAG)来处理属性级别情感分析任务,主要贡献如下:
首先,本文认为单层交互注意力机制并不能很好地将上下文和属性词相互关联,而且难以识别出上下文中对于属性词比较重要的词。例如,在对“The food is average and dreadful serving speed”中的“The food”进行情感分析的时候,单层交互注意力机制会同时加大“average”和“dreadful”的权重,而“dreadful”的情感强度通常更大,“dreadful”的权重一般会大于 “average”,而多层交互注意力机制将进一步对词语进行加权,调节“average”和“dreadful”的权重。本文使用层次注意力机制先获取上下文对属性词的影响矩阵,更新属性词的表示,进一步得到上下文的表示。此方式利用上下文与属性词之间的注意力机制使属性词的表达更加准确,再利用新的属性词表示与上下文的注意力机制,使得上下文的表达更加准确,通过层次注意力机制的设计在上下文和属性词之间进行了充分的关联,同时对不同词进行了加权以达到判断属性级别情感分类的目的。
其次,在以往属性级别情感分析的研究工作中,通常将属性词对上下文的影响矩阵当作是上下文的最终表示,将上下文对属性词的影响矩阵当作是属性词的表示,该做法忽略了上下文和属性词原表示的作用。本文认为影响矩阵只能作为对原表示调整的依据,而不能直接作为上下文和属性词的直接表示,因此,本文将二者相加,在一定程度上保留了原始信息。
最后,本文认为门机制的选择作用能够用于选择对于不同属性词上下文中重要的词,因此本文通过门机制改变上下文的表达,丰富上下文的表示。实验结果表明门机制在一定程度上提高了模型的准确率。
1 相关工作
从Hu等[5]提出需要关注产品不同属性的情感表达起,便出现了大量属性级别情感分析工作,这些工作大致可以分为基于传统机器学习的属性级别情感分析方法、基于深度学习的情感分析方法、深度学习与注意力相结合的方法和其他混合的方法。本文提出的基于层次注意力机制和门机制的属性级别情感分析属于近几年成为研究热点的深度学习和注意力机制相结合的方法,本节将从注意力机制和门机制两部分具体介绍属性级别情感分析的相关工作。
1.1 注意力机制
近些年来,神经网络的发展加快了属性级别情感分析的研究,CNN、RNN、LSTM、GRU等经典的神经网络更是在提取文本隐藏特征方面有着显著的效果;另一方面,在自然语言处理中,注意力机制能够选择出有助于特定自然语言处理任务的词,在减小计算量的同时,可以大大减少噪声的引入。因此,在近些年的自然语言处理任务中,神经网络与注意力机制相结合成为了主流方法。在属性级别情感分析上,注意力机制的使用一定程度上可以选择出有助不同属性情感分类的词,从而提高了实验准确率,因此深度学习与注意力机制相结合的方法也成为了属性级别情感分析的主要研究方法。Wang等[6]在处理属性识别情感分析任务时提出了两个模型。第一个模型通过平均池化将属性词矩阵表示转化成属性词词向量,然后通过属性词词向量与上下文隐藏表示之间的注意力机制对上下文表示进行加权。相对于第一个模型,第二个模型在上下文进入LSTM之前先将属性词向量与上下文矩阵表示进行拼接。由于使用了注意力机制,两个模型都取得了较好的实验结果,后者通过拼接进一步加大了上下文和属性词之间的关联性,因此实验效果也有一定的提升。自此,在处理属性级别情感分析任务的大多数工作中都引入了注意力机制。
Ma等[7]将上下文和属性词之间的关联定义为交互,并认为不仅属性词对上下文具有选择作用,而且上下文对属性词也有选择作用,因此提出使用二者之间的交互注意力机制来处理属性级别情感分析任务。Huang等[8]提出使用Attention-over-Attention来增强上下文和属性词之间的交互程度。Zhang等[9]提出运用协同注意力机制处理属性级别情感分析任务,具体为:将评论句子分成属性词上文、属性词和属性词下文,然后将三部分两两进行协同注意力机制。Huang等[10]通过语法感知和图注意力机制得到属性级别情感极性分布。以上工作均通过单层注意力机制加深上下文和属性词之间的交互。Li等[4]先通过协同注意力机制在上下文和属性词的表示中分别融入彼此之间的影响,然后通过自注意力机制进一步对自身表示进行加权。Li等[11]将上下文向量与位置向量进行拼接,经过GRU之后再与通过注意力机制得到的属性词向量进行拼接,最后再通过注意力机制得到含有属性词情感信息的最终表示。该工作通过多层注意力机制使得上下文的表示能够更加准确地表达出属性词对应的情感信息。Song等[12]分别将上下文词嵌入与属性词词嵌入输入到多头注意力机制,分别得到上下文和属性词的表示,然后通过二者之间的注意力机制得到二者之间的交互向量,通过分类器进一步得到属性词对应情感极性分布。Zheng等[13]先将属性词隐藏表示与属性词上文和属性词下文运用注意力机制,得到属性词上文向量和属性词下文向量,然后将属性词上文向量和属性词下文向量分别与属性词隐藏表示进行注意力机制。该工作先通过注意力机制更新了属性词上文和属性词下文的表示,使得属性词上文和属性词下文的表示更加准确,然后进一步获取属性词的表示,层次注意力机制的交互和互相选择作用使实验效果得到进一步的提升。
1.2 门机制
属性级别情感分析在于从上下文中选择出针对当前属性词情感分析有用的词,从而改变上下文表示,以达到判断属性词情感极性分布的效果,而门机制在选择和提取信息时有显著的效果。因此,也存在大量的使用门机制处理属性级别情感分析的任务。Xue等[14]先使用CNN提取属性词和上下文的信息,然后通过门机制(gating mechanisms)选择上下文和属性词中的有用信息。Liang等[15]处理属性级别情感分析任务时设计了两种不同的门机制,使上下文的表示融入了属性词信息,同时提取和选择出了有用的上下文的信息,该方法在两个数据集上也取得了较好的实验效果。故本文使用了门机制选择出上下文中有用的信息,以此丰富了上下文的表达,实验结果证明,门机制的设计在一定程度上丰富了上下文的表达,对实验准确率的提高有一定的作用,进一步提高了模型的有效性。
2 模型

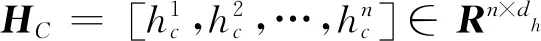

图1 总体模型结构
2.1 层次注意力机制
层次注意力机制为本文的两个核心之一,其目的在于通过层次注意力机制的加权,使上下文和属性词相关联,表达更加准确。本文先通过上下文对属性词运用注意力机制,得到上下文对属性词的影响矩阵,从而更新属性词的表示;然后通过属性词新的表示,进一步对上下文进行注意力机制,得到属性词对上下文的影响矩阵,进一步更新上下文的表示。注意力机制的层次设计,先获取属性词的表示,再获取上下文的表示,使属性词和上下文获取了更加准确的表示,同时加深了上下文和属性词之间的关联性;通过对原表示与影响矩阵相加再加权的结构设计,在一定程度上保留了原有信息,丰富了新表示的信息,通过多次加权结构,进一步体现了上下文和属性词中不同词对于属性级别情感分析不同作用性的思想,具体结构如图2所示。

图2 层次注意力机制结构图
在通过GRU得到属性词隐藏状态HT和上下文隐藏状态HC之后,为了在属性词与上下文之间运用注意力机制,首先需要得到属性词与上下文之间的注意力权重矩阵,如式(1)所示。

(1)

首先利用上下文对属性词进行加权,进而得到新的属性词表示,如式(2)所示。



2.2 门机制


图3 门机制结构图

然后通过门机制对上下文的表示进行调整,并把调整后的上下文表示当作是属性词对上下文表示的影响矩阵,具体门机制计算如式(9)~式(11)所示。
其中,wA∈Rdh、wg∈Rdh、ws∈Rdh为参数向量,relu、tanh为激活函数,Pi∈Rdh为属性词向量通过门机制对上下文中第i个向量进行选择后的表示,因此可以得到属性词向量对上下文中每个向量进行选择后的表示P∈Rn×dh。P为经过属性词经过门机制对上下文进行选择后表示,本文这部分看作是属性词对上下文的影响矩阵。因此将P与上下文原表示进行相加,并通过参数矩阵进行调整,如式(12)所示。

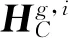
将上下文向量表示1、属性词向量表示和上下文向量表示2进行拼接之后得到r∈R3dh,并通过分类器得到属性词在上下文对应的情感极性分布,具体如式(15)~式(16)所示。
其中C为情感分类的总数,在本文中C=3,即积极、中性和消极,gi为属性词在评论中真实的情感分布,yi为通过模型对属性词情感的预测,Θ为所有参数的集合,λr为L2正则化的参数,λl为更新参数的学习率。
3 实验
为验证基于层次注意力机制和门机制的模型的性能,本节将主要对实验设置、实验结果与分析和案例分析进行详细介绍。
3.1 实验设置
数据集:本文使用的数据集为公开的英文属性级别情感分析数据集SemEval 2014 Task 4[16]和Twitter[17]数据集,其中SemEval 2014 Task 4由两部分组成,分别是笔记本领域和餐厅领域。数据集的具体分布情况如表1所示。
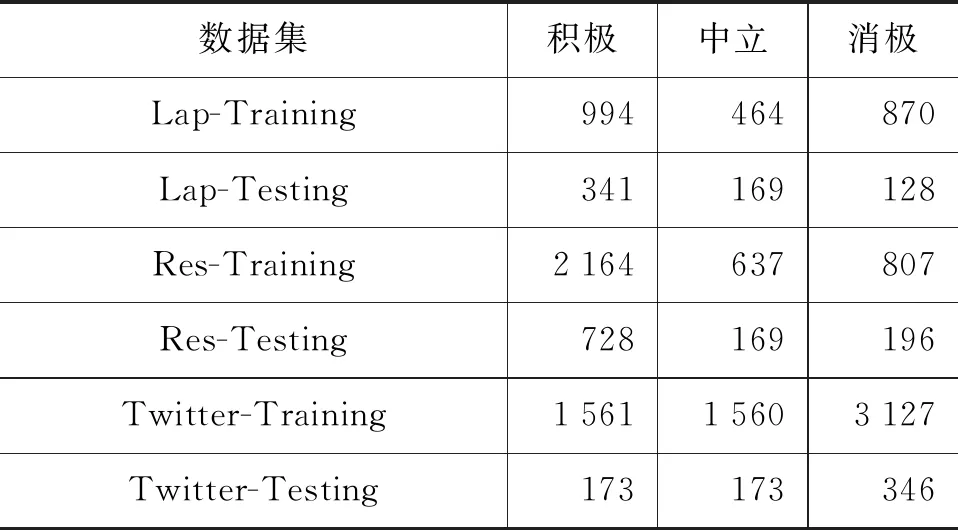
表1 数据集统计
评价指标:本文使用平均准确率来衡量基于层次注意力机制和门机制的属性级别情感分析模型的性能,具体平均准确率计算如式(17)所示。
其中,TP表示为真实类别为正例,预测类别也为正例;TN表示为真实类别为反例,预测类别也为反例;FP表示为真实类别为反例,预测类别为正例;FN表示为真实类别为正例,预测类别为反例。
超参数:本文通过使用GloVe词向量对词进行初始化,词向量维度为200,同时GRU隐藏层的维度也设置为200;对于不在GloVe词典中的词均在[-0.1,0.1]之间随机取值,所有参数矩阵和向量的初始值均在[-0.1,0.1]之间随机选取,偏置的初始值均设置为0;为对参数进行调整,本文使用的优化器是Adam,学习率设置为0.01,同时为了防止过拟合,dropout设置为0.5。
3.2 实验结果与分析
为了衡量本文提出的基于层次注意力机制和门机制模型(HAG)的性能,本选取了7个基准模型与之进行比较,具体如下:
SVM:通过简单的特征工程提取特征之后,再使用SVM分类器进行分类。
TD-LSTM:将评论分成属性词上文与属性词、属性词与属性词下文两部分,然后将两部分分别经过两个LSTM之后的最后一个隐藏向量进行拼接,再通过softmax分类器分类[18]。
ATAE-LSTM:将平均池化后的属性词向量与上下文中每个词向量进行拼接,得到新的上下文矩阵,然后将新的上下文矩阵通过LSTM得到上下文隐藏状态,再与属性词向量拼接;接下来,通过注意力机制选择出对于属性词而言上下文中较为重要的词,最后通过softmax分类器分类[6]。
MemNet:通过上下文和属性词之间的多层注意力机制加大有助于属性级别情感分析词的权重[19]。
IAN:通过上下文和属性词之间的交互注意力机制加大对于属性词而言上下文中重要词的权重和加大对于上下文而言属性词中重要词的权重[7]。
RAM:将评论句子输入双向LSTM之后,利用多层注意力机制综合句子中的重要特征[20]。
Co-attention:首先将评论分为属性词上文、属性词和属性词下文,然后通过属性词上文与属性词、属性词与属性词下文和属性词上文与属性词下文之间的协同注意力机制得到6个向量表示,将这6个向量进行拼接之后输入到softmax分类器得到属性词的情感分布[9]。
7个基准模型与HAG的对比实验结果如表2所示。

表2 实验结果
表2中,“*”表示作者根据原论文描述复现后的实验结果。根据实验结果可以看出,传统机器学习的SVM在三个数据集上的效果较差。相对于SVM,TD-LSTM由于使用了LSTM提取特征同时考虑了属性词信息,因此在三个数据集上的实验效果有所提高。ATAE-LSTM通过注意力机制进一步选择出针对不同属性词而言,在上下文中不同词的重要性,因此在一定程度上提高了实验的准确率。MemNet通过上下文和属性词之间的多层注意力机制进一步调整了上下文的表示。IAN认为上下文和属性词是相互选择,因此利用交互注意力机制,通过上下文对属性词的表示进行加权、属性词对上下文进行加权。与MemNet相比,IAN更加充分地利用了属性词信息,并通过上下文对属性词的表示进行调整,使得实验结果更加准确。Co-attention通过属性词上文与属性词、属性词与属性词下文和属性词上文与属性词下文之间的协同注意力机制,使得属性词上文、属性词和属性词下文三者之间相互选择。本文使用层次注意力机制,在属性词的表示中加入了上下文的影响,进一步得到属性词的表示,使得属性词的表示更加准确;在更新属性词表示之后再更新上下文的表示,层次性注意力机制结果设计使得上下文的表示更加准确,相对于使用自注意力机制,层次注意力机制的增加在一定程度上提高了准确率。其次,本文利用门机制进一步地丰富了上下文的表示。实验结果表明,HAG在Restaurant和Twitter数据集上取得了较好的实验结果,在Laptop数据集低于RAM,这是由于Laptop数据集中含有如否定转移、转折等结构较为复杂的评论,RAM运用多重注意力机制综合难句结构中的重要特征,提高了实验的准确率。
3.3 案例分析
本节从餐厅领域选取了一条评论作为案例进行分析,通过注意力机制系数的可视化以验证模型的有效性。如图4所示,图的左侧为属性词,右侧为属性词对应的上下文,图中颜色的深浅分别代表了注意力机制系数α和β+γ的大小。通过分析可知,当属性词“place”在上下文中所关注的词为“cool”,而在案例中“so cool and”三个词的系数较大,当属性词变为 “service”的时候,“is prompt and curious”几个词的权重加大,“cool”的权重降低,由此可见模型的合理性。

图4 案例分析
4 结论
本文提出了一种基于层次注意力机制和门机制的属性级别情感分析方法,通过层次注意力机制先利用上下文对属性词进行选择作用,并将选择后的属性词表示看作是上下文对属性词的影响矩阵,从而更新属性词的表示,在得到属性词新的表示之后,再更新上下文的表示,以此在属性词的表示中融入上下文,在上下文的表示中融入属性词信息,层次性的注意力机制结构设计使得上下文和属性词的表示更加准确。其次,本文通过门机制选择出针对于属性词而言上下文中有用的信息,进一步丰富了上下文的表示,实验结果证明本文提出的HAG模型的有效性。未来的工作中,我们将会考虑利用更多的信息以丰富词的嵌入表示,如加入一些词性信息、情感信息和位置信息等,在词向量的使用上将会考虑信息更加丰富的BERT词向量,同时会对复杂句式的属性级别情感做进一步研究。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
基层中医药(2021年8期)2021-11-02
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
家庭影院技术(2018年5期)2018-06-29
家庭影院技术(2018年3期)2018-05-09
中学生(2017年13期)2017-06-15
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
