
基于增强的双向树表示的推特谣言立场检测模型
2021-11-16 08:14杨利君
中文信息学报 2021年10期
杨利君,滕 冲
(武汉大学 国家网络安全学院 空天信息安全与可信计算教育部重点实验室,湖北 武汉 430040)
0 引言
随着互联网的飞速发展,未经证实的信息传播速度非常快,尤其是在微博、Twitter这样的社交媒体上,越来越多的用户喜欢在网上浏览、转发热点信息,并发表自己的观点,从而使得谣言和虚假信息得以广泛传播[1]。谣言会引起公众恐慌和社会动荡,而有效检测谣言和扼制谣言的传播有助于社会的安定和健康发展,具有重要的现实意义[2],因此大量针对社交网络上的谣言自动检测研究开始出现[3-6]。一些学者指出,从谣言所引发的讨论中挖掘出用户的立场,有助于确定该谣言的真实性[7]。所以,近年来,谣言立场检测任务也得到了越来越多的关注。
谣言立场检测旨在利用自然语言处理技术,分析用户发表的文本,挖掘出其对谣言的支持、反对或者中立的态度。Twitter等社交媒体上的评论通常以嵌套的对话形式出现,具有时序性和结构性,而且文本也具有简短、用词不规范、表达灵活、常采用反讽和隐喻等修辞手法的特点,往往需要利用更广泛的语境识别有效特征,以便于推断文本立场[8]。已有的方法证明,利用对话中的传播信息有助于提升立场检测的效果[9]。然而,以往的模型仅考虑对话中的局部上下文信息,例如,交互(评论或回复)的推文、时间线上相邻的推文,而忽略了全局信息,而且传播方向也是单一的。目标推文不仅依赖于所回复的文本内容,其下方回复的评论对目标推文也有一定的影响,例如,支持或评论类型的回复能够增强目标推文的立场,而否定和询问类型的回复则会削弱目标推文的立场。另外,对话进行得越深入,目标推文与谣言,即源推文的距离就越远,很容易在长距离的传播过程中丢失源推文的重要语义信息,从而无法正确判断目标推文针对源推文谣言的立场。
针对以上问题,本文提出了一种增强的双向树表示模型BiTreeInfer,该模型利用双向的树形网络改进了单方向的传播信息的提取,另外,引进了一个局部推理模块以解决源推文语义信息丢失的问题。本文的贡献如下:
(1)利用社交媒体上对话的树形结构特征,将单向的传统树形长短时记忆神经网络(TreeLSTM)拓展成双向结构;
(2)有效融合自底向上和自顶向下的两个传播方向上学习到的上下文信息,丰富了目标推文的语义和结构信息。
(3)加强了目标推文与源推文之间的语义关系,从而更有效地提取目标推文对于源推文的立场。
1 相关工作
随着国内外语义评测比赛NLPCC-2016 Task 4[10]、SemEval-2016 Task 6[11]、RumourEval 2017[12]、RumourEval 2019[13]等的陆续开展,社交媒体上的谣言立场检测研究吸引了越来越多的参与者。目前,国内外的立场检测方法主要分为基于特征工程的机器学习方法和基于神经网络的深度学习方法。
传统机器学习方法对立场分析的研究工作主要集中在特征工程的构造上。Mohammad等[14]从推文中提取了字符级和单词级N-grams特征、序列标注特征(POS)、词向量特征和情感特征等,并且使用支持向量机作为分类器。郑海洋等[15]利用“情感词+主题词”组合构建立场检测特征,进行立场分类。Zubiaga等[16]创建了两种分类器——线性条件随机场(Linear-Chain CRF)和树形条件随机场(Tree CRF)来学习对话中的树形结构特征。为了进一步提升结果,部分模型还融合了多种机器学习算法,例如,奠雨洁等[17]融合基于词频统计的特征字向量、词向量等特征,使用加权平均的方法融合多个分类器,如支持向量机(SVM)、随机森林(RF)和梯度提升决策树(GBDT)模型的分类结果。但上述方法都过于依赖领域知识,需要耗费大量的人力、物力在特征工程的构造上。
相比过于依赖特征工程的机器学习方法,深度学习方法由于其具有自动学习文本特征的能力,而受到了广泛的关注和使用。例如,Vijayaraghavan等[18]利用卷积神经网络(CNN)对推特立场检测数据集进行单词级和字符级的训练,最后融合两种模型进行立场分析。Dey等[19]在长短时记忆网络(LSTM)模型基础上引入注意力机制,通过强化文本中关键词的语义表示,提升模型立场分类性能。Kumar等[20]将卷积核引入TreeLSTM的记忆单元,从对话树中获取了更丰富的传播信号。王安君等[21]采用Bert[22]来获取具有上下文语义信息的句向量,设计出基于BERT-Condition-CNN 的中文微博立场检测方法。Yang等[23]按对话结构顺序组织文本,输入到强大的预训练语言模型进行微调,以获取全局上下文信息。
已有的工作都未研究对话树中双向的传播信息所带来的影响。在基于方面的情感分析任务中,Luo等[24]证明了利用双向树形网络结构提取方面术语的有效性。该任务从句子中提取了依存树的结构信息,而谣言立场检测任务将句子级别的结构特征提取扩展到了文档级别,需要从对话中提取有用的结构信息。针对这一特性,如何科学合理地设计出可以学习到丰富的语义和结构特征表示的模型是本文研究的重点。
2 推特谣言立场检测模型BiTreeInfer
图1展示了Twitter上两组树形结构的对话示例,每组对话通常由一条源推文(可能为谣言)以及多条嵌套的回复推文所组成。每条推文都有其回复的对象或获得的评论,可以视作其父节点和子节点。句首的斜体表示目标推文在对话中所处的深度,句尾的粗体表示目标推文基于源推文的立场标签。假设一组对话被定义为T={t1,t2,…,tN},N为对话中推文的数量,ti表示对话中第i条推文。立场标签集合为Y={support,deny,query,comment}。

图1 Twitter对话示例
本文提出一种基于增强的双向树表示的立场检测模型BiTreeInfer。模型的总体框架如图2所示,该框架主要由四部分组成:输入表示、双向树模型、局部推理模块和分类器。首先,通过组合不同的特征初始化每条推文的输入表示;接着,使用双向树模型更新每个节点的表示;然后,利用局部推理模块增强节点的语义表示;最后,将每个节点的最终表示输入到分类器中,获得预测的标签。

图2 BiTreeInfer模型框架
2.1 输入表示
文本的输入表示分为两个部分。首先,对文本进行预处理,将推文中的url链接以及@的用户名称全部替换成“$url$”和“$mention$”字符,同时,将所有的单词转换成小写形式。然后,利用BERT模型获得预训练的词向量,取句子中所有词的平均向量作为输入表示的一部分。另一部分,则参考李峤等[25]的工作,人工提取最相关的文本特征和对话特征,如表1所示,其中文本之间的相似性特征由余弦相似度(Cosine Similarity)计算。最后,将BERT向量与人工提取的特征向量拼接,获得目标推文ti的初始化输入表示xti。

表1 人工特征
2.2 双向树结构
双向树模型的整体结构如图3所示。树中每个节点的隐层状态由自底向上和自顶向下的两种传播方式分别进行更新。然后使用一种特定的交互方式对两个方向上的信息进行有效融合。以下将先对两种传播过程分别进行介绍,随后介绍所提出的一种双向扩展结构。

图3 双向树模型
2.2.1 自底向上的树形结构
Tai等[26]证明了树形长短时记忆神经网络(TreeLSTM)能有效捕捉到结构信息和长距离信息。其核心思想是通过递归访问底部的叶子节点到顶部的根节点,为每个子树生成特征向量。实验将它扩展到文档级别的谣言立场检测任务中,树形网络中的每一个节点代表一个句子,而不仅仅是一个单词。图3展示了自底向上传播模块的细节。令C(j)表示节点j的所有子节点的集合,j节点在自底向上树模型中更新的过程如式(1)~式(7)所示。

2.2.2 自顶向下的树形结构
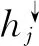
这与标准LSTM单元更新类似,只是将上一步的隐层状态替换成了父节点的隐层状态。
2.2.3 双向树的扩展结构
由于单向网络结构在捕捉全局上下文时具有局限性,本文提出了一种双向的TreeLSTM扩展结构,以此来更好地融合两个传播方向上的信息。推文ti最终的隐层状态输出hti由式(14)计算得到:


表2 交互作用函数列表
2.3 局部推理
尽管双向树模型能够使得目标节点包含丰富的全局上下文信息,但在深度很大的树中,叶子节点离源节点越远,其关于源节点的信息越模糊,而立场检测任务的目标在于判断目标推文基于源推文谣言的立场。所以,本文引入了一个局部推理模块以增强目标推文与源推文之间的语义关系。源推文的隐层状态hts和目标推文的隐藏状态hti之间的推理分数s(i)由端对端的双线性模型计算得出,如式(15)所示。


2.4 分类器

3 实验设置
3.1 数据集
本文使用的数据集来自于RumourEval 2017评测任务,该数据集从Twitter上爬取了325组对话集合,为5 568条推文标注了立场标签。这些表达舆论的推文围绕9个不同的突发新闻事件展开,例如巴黎枪击事件、德国之翼飞机坠毁事件等。数据集被划分成了训练集、开发集、测试集。推文的分布与统计结果如表3所示,S表示支持,D表示否定,Q表示询问,C表示评论。可以看到,这是一个不平衡的数据集,评论类型的标签数量远大于其他标签数量,这对模型的训练来说是一个挑战。

表3 数据集的统计信息
3.2 训练
本文使用多分类交叉熵作为损失函数,定义如式(20)所示。

实验表明,模型训练迭代次数达到50轮时,网络的交叉熵损失值基本保持不变。所以最大迭代次数设置为50,将一组对话作为一个批次(batch)输入模型进行训练。实验使用Adam[28]更新参数,初始学习率设置为0.001,每10轮下降0.1%进行更新。加载的预训练词向量为768维的BERT模型(BERT-base-uncased)。自顶向下和自底向上树形神经网络的隐层状态都设置为64维,交互作用函数选择了门机制,分类器中的前向神经网络有2层,每层64维。实验搭建于PyTorch框架。
3.3 基线
SVM[29]:该模型提取单个推文的情感特征和对话特征输入到线性支持向量机中,得到分类结果。
BranchLSTM[30]:该模型将树形对话中处于同一分支的推文组织成语序序列,输入到LSTM网络中,推文的输入特征由Google News Word2Vec词向量和人工特征组合而成。
TemporalATT[31]:该模型根据对话中每条推文发表的时间线,使用注意力机制学习相邻推文的上下文权重信息,丰富当前推文的语义特征。
Conversational-GCN[32]:该模型利用图卷积神经网络将树形对话中推文之间的关系进行建模,以更新推文节点的特征。
HierachicalTransformer[33]:该模型将一段对话分解成几组子对话,分别输入到预训练BERT模型中,以获得子对话集合中推文的交互信息和局部上下文信息,然后将它们输入到Transformer层进行融合,使每条推文获得全局交互信息和上下文信息。
4 实验结果
4.1 结果比较
数据集标签分布的不平衡使得准确率不足以衡量一个模型的综合表现,所以本文使用宏观平均F1值(macro-averagedF1)[34]作为最终的评价指标,对不同类别的F1值求平均,以下简写为macro-F1。
表4给出了不同模型的实验结果,可以看到,本文提出的BiTreeInfer模型在所有模型中表现最佳,获得了0.525的 macro-F1值。表4还列出了分类评估结果,由于数据集中否定类别的推文数量最少,该类别的立场检测最具挑战性,大部分模型的识别效果欠佳,而BiTreeInfer模型在否定类别上获得了最高的macro-F1值0.283,这对于该领域的研究具有很大的意义,因为否定立场对于谣言的真实性判别提供了至关重要的线索。在模型分析模块中,会对该类别效果提升的原因进行进一步探究。

表4 不同模型的结果对比
4.2 模型分析
4.2.1 消融实验
表5所示的消融实验证明了不同模块在Bi-TreeInfer 模型中的作用。将交互作用函数替换成相加、拼接和多层感知机后,macro-F1值分别下降了3.5%、1.8%、2.8%,证明了门机制在筛选、提取和融合两个方向上信息的有效性。去除局部推理模块后,macro-F1值下降了3.2%,这表明该模块对语义信息的增强有明显帮助。如果继续将预训练的BERT向量替换成Google News Word2Vec向量,macro-F1值会再次下降1.8%。

表5 消融实验
4.2.2 双向树结构分析
为了进一步研究BiTreeInfer模型是否得益于其双向树结构,实验对不同深度的推文进行了分析。表6统计了测试集中推文深度的分布情况,观察到大部分推文集中在1~3的深度,最大的深度可达到13,为了方便分析,将不低于6的深度的推文统计成了一组。
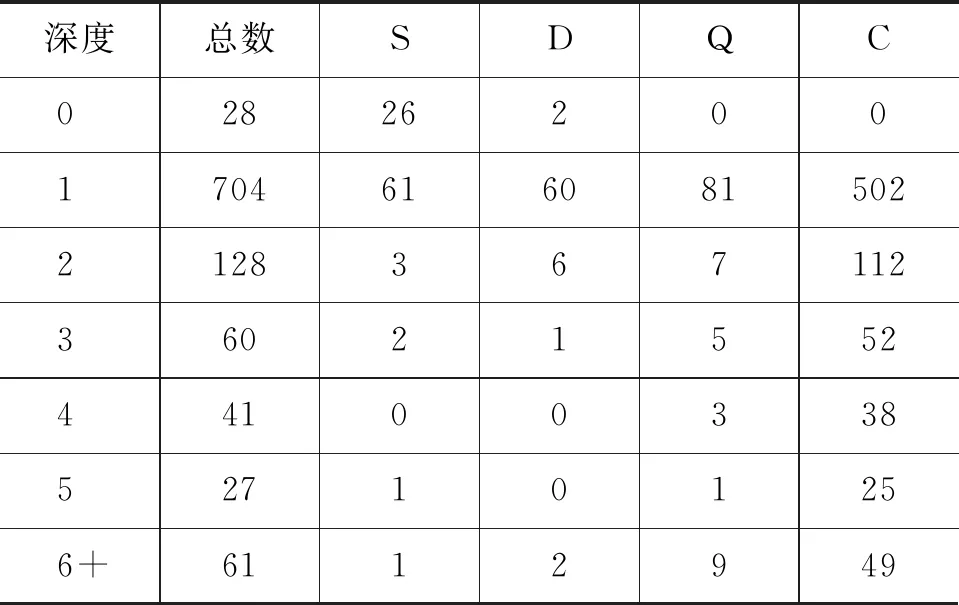
表6 不同深度的推文统计
实验做了两个对比模型BUTreeInfer和TDTreeInfer,除了树的传播方向以外,其他设置与BiTreeInfer相同,分别表示自底向上(bottom-up)和自顶向下(top-down)的树形结构。图4中的对比结果显示,不同模型有其擅长识别的深度,而能识别出更多小数据量类别中推文的模型获得的macro-F1值更高,所以在0深度上,BUTreeInfer模型的 macro-F1值最低,因为其无法检测出否定立场的推文,但在1深度上,它的综合识别能力有所提高。TDTreeInfer在识别0~3深度上推文的效果尚佳,但推文位置加深后,它的识别能力稍显逊色。

图4 不同推文深度上的模型结果对比
总体来看,BiTreeInfer在大部分位置上都取得了最佳的结果,而且在大于5的深度的推文集合中,仍然保持较高的检测水平,优于任何单向的网络结构。这说明双向树结构能够在长距离中捕捉到更多的语义和结构信息。
4.2.3 局部推理模块分析
图5展示了对话中具有不同立场标签回复推文的推理分数。背景颜色代表它们与源推文之间的二元关系,颜色越深,说明两者之间关系越紧密。在第一个例子中,否定类型的推文与源推文在语义上相悖,所以它们之间的局部距离较远,推理分数较低。第二个例子中,支持类型的推文通过转发或者重复描述源推文的谣言显示出了与源推文语义关系上的一致性,所以获得了较高的推理分数。分析结果与4.1节中的实验结果一致,证明了局部推理模块有助于识别否定这类数据量少但语义关系明显的标签。
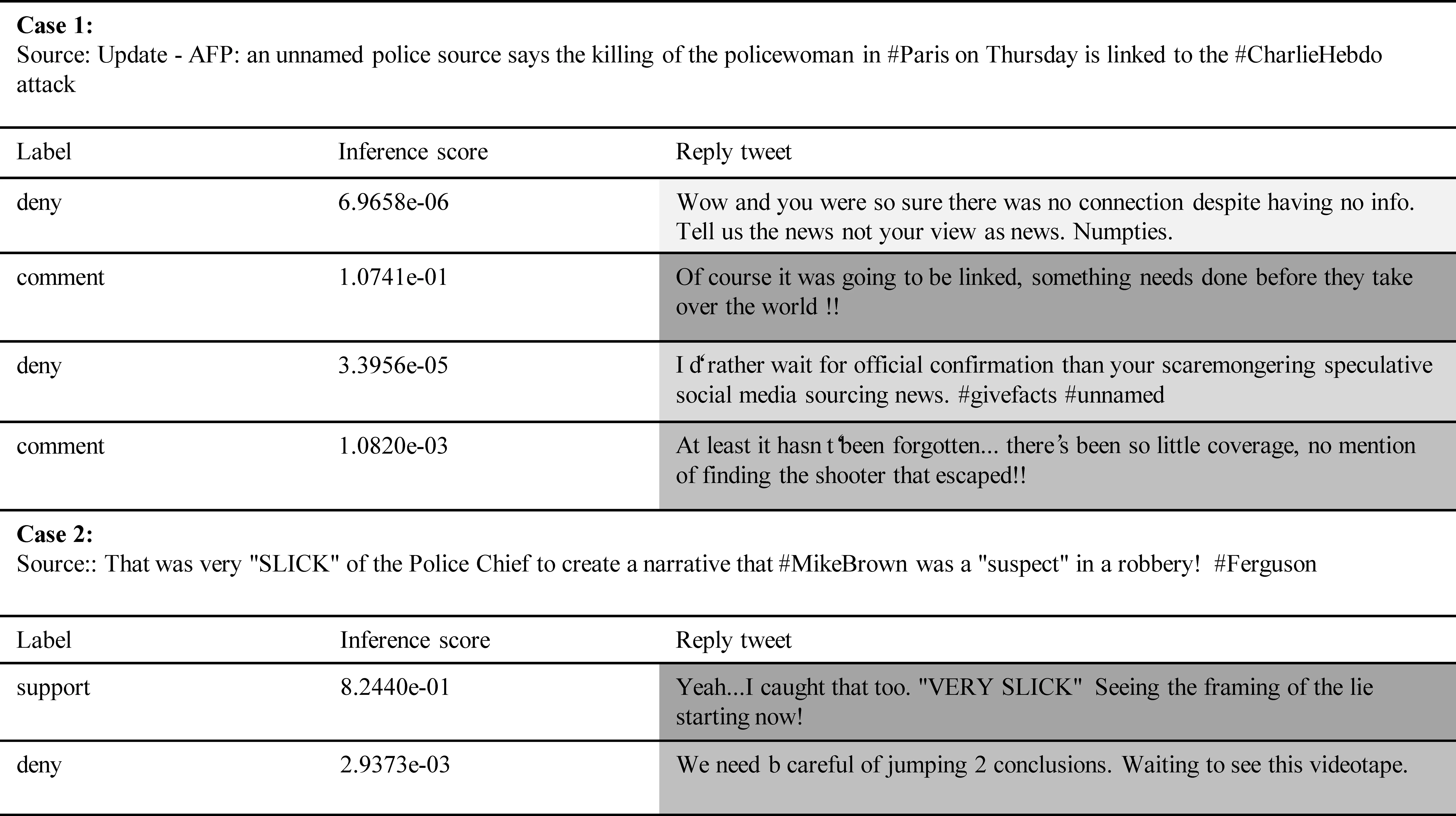
图5 两组对话案例中回复推文的推理分数
5 结语
本文提出了一种端对端的立场检测框架Bi-TreeInfer。该框架通过双向的树形神经网络对Twitter对话进行建模。节点的初始输入表示由预训练BERT模型获得的句向量特征和人工提取的特征组合而成。改进的树形递归神经网络能够有效地提取自底向上和自顶向下两个传播方向上的语义和结构信息,并且通过不同的交互作用函数融合了双向表示。实验证明,双向树结构有助于捕捉长距离信息,并且检测出对话深处的推文的立场。另外,模型还引入了一个局部推理模块以加强源推文和回复推文之间的语义联系,结果证明该方法能够检测出数据量最少、最具挑战性的否定立场。在未来的工作中,我们将进行立场检测和谣言判别的多任务实验,以进一步探究社交平台中谣言的传播规律。
猜你喜欢
河北果树(2022年1期)2022-02-16
烟台果树(2021年2期)2021-07-21
河北画报(2020年10期)2020-11-26
武术研究(2020年3期)2020-04-21
中外文摘(2019年20期)2019-11-13
文萃报·周五版(2019年46期)2019-09-10
环球时报(2018-01-26)2018-01-26
现代园艺(2017年19期)2018-01-19
现代园艺(2017年13期)2018-01-19
中国青年(1949年20期)1949-08-17
